基于改进单点多盒检测器的麻醉复苏目标检测方法
2024-01-09罗荣昊程志友汪传建刘思乾汪真天
罗荣昊,程志友,汪传建,刘思乾,汪真天
基于改进单点多盒检测器的麻醉复苏目标检测方法
罗荣昊,程志友,汪传建*,刘思乾,汪真天
(安徽大学 互联网学院,合肥 230039)(∗通信作者电子邮箱wcj_si@ahu.edu.cn)
麻醉复苏目标检测模型常被用于帮助医护人员检测麻醉病人的复苏。病人复苏时面部动作的目标较小且幅度不明显,而现有的单点多盒检测器(SSD)难以准确实时地检测病人的面部微动作特征。针对原有模型检测速度低、容易出现漏检的问题,提出一种基于改进SSD的麻醉复苏目标检测方法。首先,将原始SSD的主干网络VGG(Visual Geometry Group)16更换为轻量级的主干网络MobileNetV2,并把标准卷积替换成深度可分离卷积;同时,通过对病人照片的特征提取采用先升维再降维的计算方式减少计算量,从而提高模型的检测速度;其次,将SSD提取的不同尺度特征层中融入坐标注意力(CA)机制,并通过对通道和位置信息加权的方式提升特征图提取关键信息的能力,优化网络的定位分类表现;最后,闭眼数据集CEW(Closed Eyes in the Wild)、自然标记人脸数据集LFW(Labeled Faces in the Wild)和医院麻醉病患面部数据集HAPF(Hospital Anesthesia Patient Facial)这3个数据集上进行对比实验。实验结果表明,所提模型的平均精度均值(mAP)达到了95.23%,检测照片的速度为每秒24帧,相较于原始SSD模型的mAP提升了1.39个百分点,检测速度提升了140%。因此,所提模型在麻醉复苏检测中具有实时准确检测的效果,能够辅助医护人员进行苏醒判定。
麻醉复苏;面部特征识别;单点多盒检测器;MobileNetV2;注意力机制
0 引言
麻醉复苏室(PostAnesthesia Care Unit, PACU)是为全麻手术患者从麻醉状态到完全意识清醒提供相关护理监测操作的场所。目前多数医院的全麻患者术后多转入PACU,在此进行拔管、复苏等护理操作的同时被严密监测生命体征,需要投入大量的人力物力。由于麻醉药物的作用,全麻手术后处于苏醒监测期的病人会感到不适,加上身体机能未能恢复完全,很容易造成循环和呼吸系统的并发症问题,对术后恢复产生不良影响。麻醉或手术都会对患者产生生理功能上的障碍,特别是较高的手术侵入性会导致较高程度的应激反应,这与术后麻醉并发症相关[1-4]。手术后并发症会使病人的复苏质量恶化,同时给医院增加负担[5-7]。郭清厚等[8]指出,对PACU的病人采取有效的管理办法能够提前发现手术和麻醉相关并发症,促进麻醉复苏。
现阶段麻醉复苏监测主要依靠有经验的专业护士定期监视病人的身体状态。随着医学技术的发展和外科手术适应症范围的扩大,人们对手术治疗的需求日益增长;但由于医疗资源紧张、人力监控主观性较强、专业性要求高等原因,传统监测方法容易产生疏忽误判等情况,耗时且效率低,在当前复杂繁多的复苏室环境已无法满足医院的需求。
麻醉病人苏醒的前兆特征有睁眼、张口和吞咽等微动作,可以由摄像机采集病人的面部图像,通过检测病人的眨眼、嘴巴开合判断病人是否属于苏醒状态。Soukupová等[9]提出眼睛纵横比(Eye Aspect Ratio, EAR)的概念,通过定位眼睛的12个关键点计算纵横比,设定一个阈值判定眼睛的状态。Nousias等[10]采用DeepLabv3+分割采集图像中的双眼虹膜和眼睑,计算每只眼睛的眼睑之间的距离和相应的虹膜直径,然后经过自适应阈值处理,识别眨眼并确定它的类型。De La Cruz等[11]提出一种基于长期递归卷积网络的眨眼检测方法Eye LRCN(Eye Long-term Recurrent Convolutional Network),采用卷积神经网络(Convolutional Neural Network,CNN)对眼睛图像提取特征,结合双向递归神经网络执行序列学习和眨眼检测。Chen等[12]通过多任务级联CNN(Multi-Task CNN,MTCNN)实现人脸关键点的定位,再用VGG(Visual Geometry Group)16进行眼睛状态的分类识别。 Wang等[13]通过深度CNN(Deep CNN, DCNN)提取眼睛的虹膜和瞳孔像素,再用结合了Unet和Squeezenet特点的像素级高效CNN进行分类。Prinsen等[14]使用基于区域的更快CNN(Faster Region-based CNN,Faster R-CNN)算法对预先训练的残差网络(Residual Network,ResNet)进行微调,再用CNN定位评估儿童的眼睛图像。以上方法尽管有不错的效果,但大多数方法网络模型较大、检测速度较慢,不符合麻醉病人复苏这一应用场景。
针对麻醉病人复苏检测的具体问题,方法的时效性和准确度是关键。本文提出一种基于改进单点多盒检测器(Single Shot multibox Detector, SSD)[15]的麻醉复苏目标检测方法。本文采用基础模型SSD检测麻醉病人面部微动作变化,即通过检测病人的眼睛睁闭、嘴巴开合判定病人是否有自我苏醒意识;由于实际检测的图像中可能存在特征图像尺度较小、背景复杂等因素,本文改进SSD,更换了轻量级的主干网络,融合了注意力模块,在降低计算量、维持高效、准确的前提下,提高检测精度。
1 SSD结构
SSD是经典的多尺度单目标检测算法模型,用VGG[16]作为主干特征提取网络,SSD的结构如图1所示。SSD通过主干网络抽取6张从大到小的特征图,预先在每个尺度的特征图上设置不同长宽比的锚框,根据不同尺度的物体大小(小目标对应浅层特征图、大目标对应深度特征图)进行检测,并使用自定义的非极大抑制(Non-Maximum Suppression,NMS)去除重复的预测框,保留最好的结果。SSD是最早采用浅层网络探测小目标、深度网络探测大目标的多尺度预测方法。浅层网络虽然几何信息丰富,定位也较准确,但感受野小,表达语义信息的能力不强;深度网络的感受野更大,语义信息丰富,但分辨率较低,显示几何信息的能力更弱,所以SSD在实际检测时会出现较严重的遗漏、错误现象。另外,SSD作为一种单阶段的深度学习目标检测算法,在高精确度的情况下检测速度也较高,但是模型参数量大,对硬件算力要求高,在麻醉复苏检测的应用中不满足实时性的要求。
2 改进SSD
为了改善SSD存在复杂目标检测困难、定位不准确的问题,进一步提高SSD的检测速度以满足麻醉复苏检测的需求,首先将主干网络VGG替换成轻量级网络MobileNetV2[17],在不降低精确度的前提下,极大地减少参数量和运算量,提升检测速度;其次在原始的模型中融入了注意力机制模块,将SSD提取的6个尺度不同的特征层输入注意力机制模型,增强特征图提取关键信息的能力,优化网络定位分类的表现。改进后的SSD的结构如图2所示。
2.1 主干网络替换
使用MobileNetV2替换SSD主干网络VGG,通过对比目标大小与检测单元大小,调整主干网络特征抽取层的大小,由原本的38×38改为19×19,通道数减少至96,在不降低精确度的情况下减少了计算量。MobileNetV2采用线性激活函数(Linear)避免特征丢失,同时堆叠基于深度可分离的卷积块即将通道、空间相关性完全分离,用深度可分离卷积代替传统卷积,对输入的特征图先进行升维,使用卷积得到更多的特征信息,再降维输出。图3为MobileNetV2的卷积结构。

图2 改进的SSD结构

图3 MobileNetV2卷积结构
由于MobileNetv2结构采用了大量的深度可分离卷积结构提取特征,对模型的精确度影响较小且参数量较少,使计算量下降明显,因此,更换模型的主干网络不仅保证了精确度,也提升了计算速度,符合麻醉复苏实时检测的条件。
2.2 深度可分离卷积
深度可分离卷积主要将传统卷积提取特征的运算过程替换为逐通道卷积(DepthWise convolution,DW)和逐点卷积(PointWise convolution,PW),联合这两个部分进行语义特征提取。结构如图4所示。
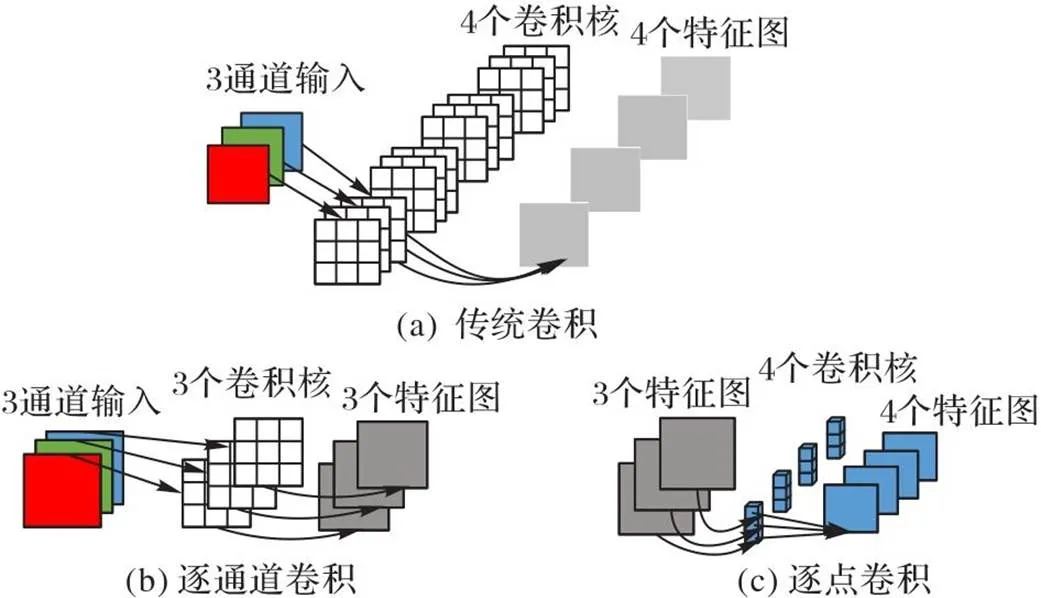
图4 深度可分离卷积

传统卷积的参数量为:
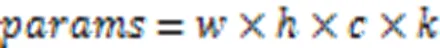
深度可分离卷积的参数量为:

其中:为卷积核的长和宽,为输入的通道数,为卷积核的具体个数。
以RGB 3通道的一个图像为例,经过一个卷积层输出4个特征图,它们的大小与输入图像一样;再计算传统卷积的卷积层参数为108,替换为深度可分离卷积参数量为39,约为原来的1/3。减少深度可分离卷积的参数量,极大地降低了计算量,从而提高了模型特征检测的速度。
2.3 注意力机制引入
人类视觉的本能特性就是看到物体的时候,不自觉地会将注意力放置在关键信息上,同时忽略其他信息。这种注意力的机制会提高提取特征的效率,而计算机视觉想要模拟人类视觉的这种能力就需要引入注意力机制。注意力机制的核心是让网络聚焦到更需要关注的地方。面对图像处理任务,使CNN自适应地注意重要的物体是关键。
根据加权的方式不同,注意力机制通常可分为空间域注意力、通道域注意力和混合域注意力等。挤压-激励网络(Squeezeand-Excitation Network, SE-Net)[18]是一种通过对各通道分别进行全局平均池化计算各通道重要性,并赋予不同权重的常用通道域注意力机制。高效通道注意力的DCNN(Efficient Channel Attention for deep convolutional neural Network, ECA-Net)[19]是SE-Net的改进版,通过使用一维卷积替代原SE-Net模块中的全连接层,减少计算量和运算量,提高跨通道互动的覆盖率。通道注意力对提升模型的效果显著,但通常忽略了产生空间选择性注意力图像的位置信息。
坐标注意力(Coordinate Attention, CA)机制[20]是一种将位置信息嵌入通道注意力的移动网络注意力机制。它使移动网络在增加感受野的前提下,避免了一大笔计算开销。CA模块的结构如图5所示。
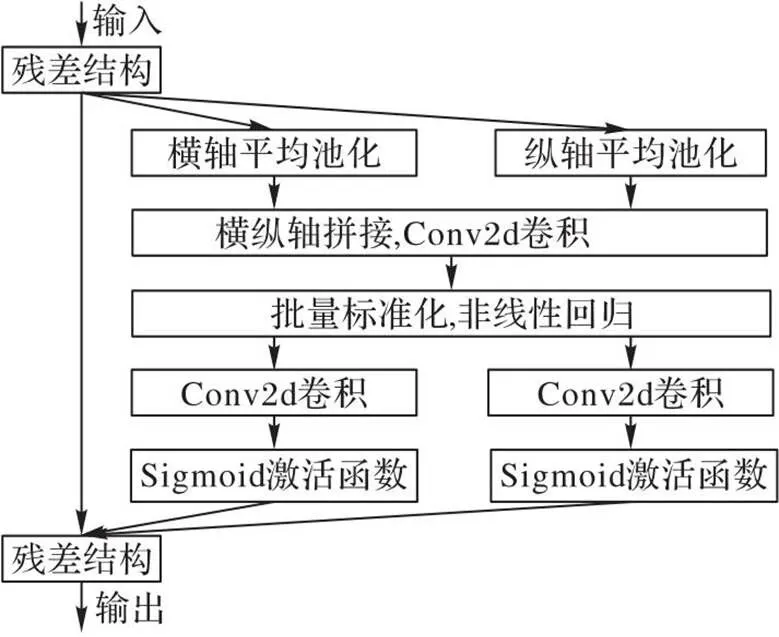
图5 CA模块的结构
CA将通道注意力分解为沿宽度和高度两个方向分别进行全局池化,获得在宽度和高度两个方向的特征图,优点是可以沿着一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,它们可以互补地应用于输入特征图,增强感兴趣的目标表示,提高模型的定位准确性。
3 实验与结果分析
3.1 实验环境与数据集
本次实验的硬件环境为:显卡为NVIDIA GeForce RTX 3090, CUDA(Compute Unified Device Architecture)版本为 CUDA11.3, Python 3.8.13,深度学习框架为PyTorch 1.11.0。
实验的数据集选用CEW(Closed Eyes in the Wild)公开数据集[21]全部1 192张闭眼照片、LFW(Labeled Faces in the Wild)数据集[22]1 100张睁眼照片和安徽省立医院拍摄采集的1 000张患者面部照片,共计3 292张照片。如图6所示,用labelimg软件对选取的数据集进行VOC(Visual Object Classes)格式的四分类标注,分别为:睁眼、闭眼、张嘴和闭嘴。再将数据集按照8∶1∶1分成训练集、测试集和验证集。

图6 数据集图像标注
3.2 迁移学习策略
本文使用迁移学习方法[23]训练网络,主干网络MobileNetV2的18层为特征提取层,先冻结主干网络,使用在公开数据集上预训练好的权重对后续网络粗略训练,仅对模型微调,提取适应检测特征;再解冻特征提取层,进行完全训练,模型所有的参数都发生改变。通过上述方法,在缩短模型训练时间的同时,也能在数据集较少的情况下提高模型泛化能力。
3.3 训练过程
模型一共训练300个epoch,其中前50个epoch为主干网络的冻结训练,后250个epoch为解冻之后全部一起训练,训练的结果如图7所示。损失函数在第250个epoch后的训练集和验证集中逐渐收敛并稳定下来。

图7 网络训练结果
3.4 检测结果
使用本文模型检测测试数据集,模型检测睁眼、闭眼、张嘴和闭嘴的精确度分别是97.15%、97.35%、98.25%和95.45%。检测结果表明改进后的模型可以准确识别人面部微动作的变化。
模型实际用摄像头预测的结果如图8所示。由图8可见,模型预测结果中定位框和置信度都较准确。图8(b)在眼睛微睁的状态下仍然判定为睁眼的行为,考虑到麻醉病人复苏这一特定应用场景,病人的眼睛由完全闭合到微睁这一状态的改变本身就是苏醒的前兆行为,所以在数据集制作时,把微睁的状态标注为睁眼状态。从检测结果可知,模型能准确地识别眼睛的状态。

图8 实际预测结果
4 模型评估
4.1 评价指标
本文采用目标检测常见的评价指标平均精确度均值(mean Average Precision, mAP)进行对比。平均精确度(Average Precision ,AP)由精确度(Precision)/召回率(Recall)曲线与坐标轴围成的面积计算,反映模型在该类别下的精确度;mAP是所有类别的AP求均值,反映模型在所有类别下的精确度。具体计算公式如下:

其中:(True Positive)表示预测正确的正样本数;(False Positive)表示预测错误的正样本数;(False Negative)表示将正样本预测错误为负样本的数量。
模型除了需要满足一定的精度要求外,也要满足实时性的要求,具有工程应用的能力,所以模型参数量和图片每秒传输帧数(Frame Per Second, FPS)也是模型需要对比的指标。
4.2 对比实验
分别对SSD[15]、CA-SSD(Coordinate Attention -Single Shot multibox Detector)、MobileNetV2-SSD(MobileNetV2-Single Shot multibox Detector)和本文模型在自制的数据集上训练相同的epoch,针对人脸状态的四分类识别效果进行对比实验,得出每一类的AP和mAP。其中:SSD表示主干网络为VGG的原模型,CA-SSD表示在原模型的基础上在6个回归预测层上引入CA的模型,MobileNetV2-SSD是将主干特征提取网络更换为MobileNetV2的模型。实验结果如表1所示。
表1不同模型的检测精确度对比 单位:%
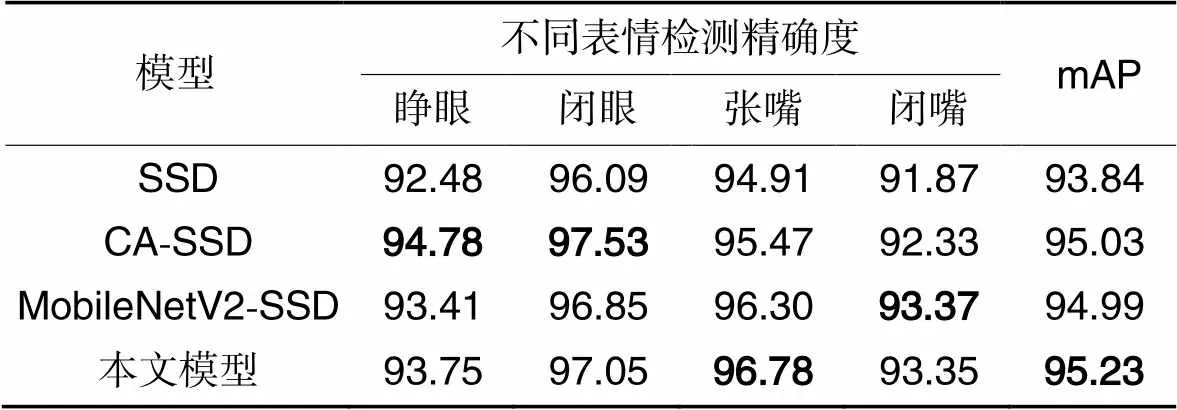
Tab.1 Comparison of detection precision of different models unit:%
相较于SSD,本文模型的mAP提高了1.39个百分点,同时每一类的识别精确度都有提升。相较于CA-SSD,本文模型的mAP提高了0.2个百分点,对嘴巴状态的识别精确度有所提高,而对于眼睛状态识别精确度有所降低,这是因为在小尺度的检测下,网络提取特征层越深则效果越好。相较于MobileNetV2-SSD,本文模型的mAP提高了0.24个百分点。另外,对比CA-SSD与SSD、本文模型和MobileNetV2-SSD可以看出,加入CA模块对于模型整体精确度的提高有正向作用。SSD与CA-SSD对比、本文模型与MobileNetV2-SSD对比,这两组对比结果可以看出,更换了更轻量级的主干网络可以提高模型的精确度。总体地,本文模型在人脸各部位的状态识别中有最好的检测性能,可以满足麻醉病人复苏这一应用场景下的检测要求。
为了验证本文模型在精确度提升的同时检测速度也满足实时性的要求,进行对比实验,实验结果如表2所示。SSD虽然有较高的性能,但是模型较大,不符合现代化工程应用轻便的需求。将主干网络更换为MobileNetV2后,模型大小约为原来的1/6,准确率也相应提高,本文模型在加入CA模块后达到了最高性能。从表2中看出,更换为轻量级网络的MobileNetV2-SSD和本文模型显卡上的检测速度分别为81 frame/s、74 frame/s,相较于SSD和CA-SSD的检测速度153 frame/s、125 frame/s,降低至原来的1/2。在处理器上,MobileNetV2-SSD和本文模型检测速度分别达到了25 frame/s和24 frame/s,约为SSD和CA-SSD的2.5倍。说明了基于深度可分离卷积的MobileNetV2在显卡上并不能完全适配,得到绝对的计算加速。这验证了网络计算的速度不仅取决于计算量,还取决于诸如存储器访问成本和平台特性的其他因素[24]。由于一般视频流为25 frame/s,所以本文模型在对目标检测精确度提升的同时,也达到了实时性的要求。
表2不同模型的大小和检测速度对比

Tab.2 Comparison of size and detection speed of different models
综合上述分析可知,本文模型比SSD的睁眼检测精确度提升了1.27个百分点;闭眼检测精确度提升了0.94个百分点;张嘴检测精确度提升最高,为1.87个百分点;闭嘴检测精确度提升了1.48个百分点,AP提升1.39个百分点;可以更精确地识别病人的面部特征。本文模型参数减少至原始SSD参数量的1/6,检测速度是原始SSD的2.4倍,即检测速度提升了140%,对病人的面部特征的检测更实时。
4.3 数据分析
在临床医学中灵敏度(sensitivity)和平均对数漏检率(Log-Average Miss Rate, LAMR)更具有实际参考价值。灵敏度指在所有的正样本中模型预测对的比重,与模型的评价指标召回率Recall等同,灵敏度越大,模型的检测越准;平均对数漏检率指计算每张图片误检数(False Positives Per Image,FPPI)和漏检率(Miss Rate,MR)同时衡量模型性能。MR的计算如式(5)所示:
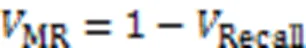
通过绘制MR-FPPI(Miss Rate- False Positives Per Image)曲线,取9个FPPI值下的平均漏检率,记为MR-2,其中9个点是在对数区间[10-2,102]上的均匀采样。MR-2表示在指定误检率的情况下检测器的漏检率。MR-2越低,表示模型漏检率越低,检测性能越好。对模型的实验结果数据进行计算比较,结果如图9、表3所示。
由图9可见,模型的优劣顺序为本文模型、CA-SSD、SSD和MobileNetV2-SSD。本文模型检测闭眼的灵敏度比原始SSD略低,是由于更换了主干网络的轻量化网络模型对小尺度特征图检测不全面;在对睁眼、张嘴和闭嘴的检测中,本文模型的灵敏度均为最高值、覆盖最全面,综合评估本文模型具有更好的灵敏度。

图9 不同模型的灵敏度对比
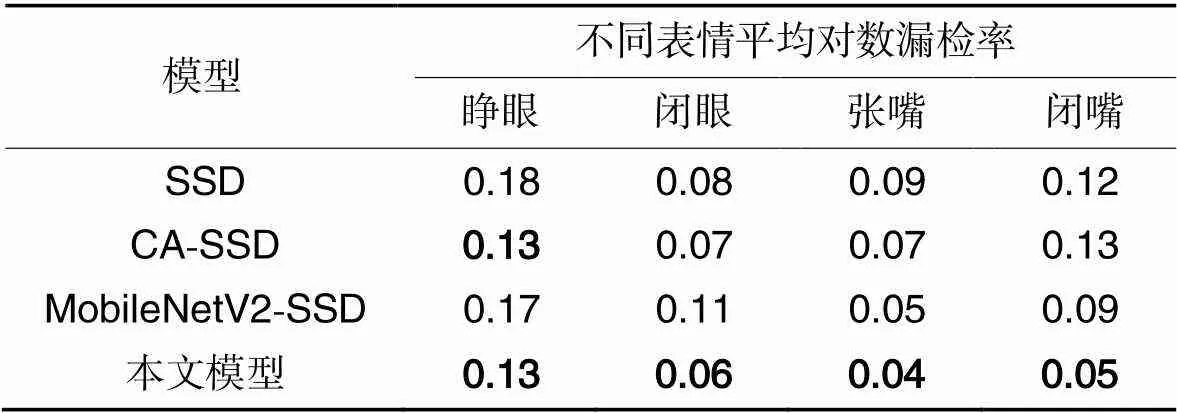
表3不同模型的平均对数漏检率对比
Tab.3 Comparison of log-average miss rate of different models
由表3可见,本文模型在每个分类检测的平均对数漏检率都为最低值,检测性能最好。
综上分析可知,本文模型具有更优的灵敏度和极低的平均对数漏检率,可以准确地检测麻醉病人复苏期的面部特征,对麻醉病人检测识别的遗漏少,这对麻醉复苏检测识别具有较大的实际意义。
4.4 麻醉复苏判定方法
根据本文模型检测的结果,先检测每帧图像中病人的面部特征,再引入是否复苏的逻辑算法进行麻醉复苏检测。设定一个苏醒状态评价值由式(6)计算:


测试集选用的病人照片为235张,分为两类(清醒和昏迷),其中清醒的照片为100张,昏迷的照片为135张。对检测结果绘制受试者特征曲线(Receiver Operating Characteristic curve, ROC),如图10所示。

图10 受试者特征曲线
ROC的曲线下面积(Area Under Curve, AUC)值为0.88,验证了本文模型的有效性及面部特征对麻醉复苏判定具有较高的预测价值。
5 结语
本文提出一种基于改进SSD的麻醉复苏目标检测方法。将SSD的主干网络VGG16更换为MobileNetV2,减少了特征提取网络模块的参数量,在保证模型精确度的情况下提高检测速度;引入注意力模块,通过注意力机制模块,使模型将更多的关注点放在关键信息,增强模型对目标的识别能力。在医院麻醉病患面部数据集HAPF上验证了本文方法的可行性。实验结果表明,本文模型(CA+MobileNetV2-SSD)具有较高的精确度和实时性,同时也满足移动计算设备的应用需求,具有实际工程应用的潜能。下一步,将围绕实际应用场景进行针对性的研究优化。
[1] DESBOROUGH J P. The stress response to trauma and surgery[J]. British Journal of Anaesthesia,2000,85(1):109-117.
[2] DOBSON G P. Addressing the global burden of trauma in major surgery[EB/OL].[2022-12-20]. doi:10.3389/fsurg.2015.00043.
[3] CUSACK B , BUGGY D J . Anaesthesia, analgesia, and the surgical stress response[J]. BJA Education, 2020,20(9): 321-328.
[4] HIROSE M, OKUTANI H, HASHIMOTO K, et al. Intraoperative assessment of surgical stress response using nociception monitor under general anesthesia and postoperative complications: a narrative review[J]. Journal of Clinical Medicine, 2022,11(20): No. 6080.
[5] PENSON D F. Re: relationship between occurrence of surgical complications and hospital finances[J]. The Journal of Urology, 2013, 190(6): 2211-2213.
[6] DOBSON G P . Trauma of major surgery: a global problem that is not going away [J]. International Journal of Surgery, 2020, 81:47-54.
[7] LUDBROOK G L. The hidden pandemic: the cost of postoperative complications [J]. Current Anesthesiology Reports, 2021, 12(1):1-9.
[8] 郭清厚,钟娆霞,莫玉林.靶向预控护理在全麻手术患者复苏期躁动管理中的应用[J].齐鲁护理杂志,2019,25(6):92-94.(GUO Q H, ZHONG R X, MO Y L. Application of targeted pre-control nursing in restlessness management of patients undergoing general anesthesia surgery during recovery [J]. Journal of Qilu Nursing, 2019, 25(6): 92-94.)
[9] SOUKUPOVÁ T, CECH J. Real-time eye blink detection using facial landmarks [EB/OL].[2022-12-20]. https://vision.fe.uni-lj.si/cvww2016/proceedings/papers/05.pdf.
[10] NOUSIAS G, PANAGIOTOPOULOU E-K, DELIBASIS K, et al. Video-based eye blink identification and classification[J]. IEEE Journal of Biomedical and Health Informatics, 2022, 26(7): 3284-3293.
[11] DE LA CRUZ G, LIRA M, LUACES O, et al. Eye-LRCN: a long-term recurrent convolutional network for eye blink completeness detection[J/OL]. IEEE Transactions on Neural Networks and Learning Systems, 2022[2022-11-29]. https://ieeexplore.ieee.org/abstract/document/9885029.
[12] CHEN Y, ZHAO D, HE G. Deep learning-based fatigue detection for online learners[C]// Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence. Piscataway: IEEE, 2022 : 924-927.
[13] WANG Z, CHAI J, XIA S. Realtime and accurate 3D eye gaze capture with DCNN-based iris and pupil segmentation [J]. IEEE Transactions on Visualization and Computer Graphics, 2021,27(1):190-203.
[14] PRINSEN V, JOUVET P, OMAR S A, et al. Automatic eye localization for hospitalized infants and children using convolutional neural networks [J]. International Journal of Medical Informatics, 2021, 146: 104344.
[15] LIU W,ANGUELOV D,ERHAN D,et al. SSD:single shot multibox detector [C]// Proceedings of the 2016 European Conference on Computer Vision,LNCS 9905. Cham: Springer,2016: 21-37.
[16] SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[EB/OL].[2022-12-20]. https://arxiv.org/pdf/1409.1556.pdf.
[17] SANDLER M , HOWARD A , ZHU M , et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:4510-4520.
[18] HU J , SHEN L , ALBANIE S , et al. Squeeze-and-excitation networks.[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8):2011-2023.
[19] WANG Q , WU B , ZHU P , et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020 :11531-11539.
[20] HOU Q , ZHOU D , FENG J . Coordinate attention for efficient mobile network design[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2021 :13708-13717.
[21] ZHAO L, WANG Z, ZHANG G,et al.Eye state recognition based on deep integrated neural network and transfer learning[J].Multimedia Tools and Applications, 2018, 77(15):19415-19438.
[22] HUANG G B, MATTAR M, BERG T,et al.Labeled faces in the wild: a database for studying face recognition in unconstrained environments [EB/OL].[2022-12-22].https://inria.hal.science/inria-00321923/document.
[23] TAN C, SUN F, KONG T, et al. A survey on deep transfer learning [C]// Proceedings of the 2018 International Conference on Artificial Neural Networks and Machine Learning. Cham: Springer, 2018:270-279.
[24] MA N, ZHANG X., ZHENG H T,et al. ShuffleNet v2: practical guidelines for efficient cnn architecture design [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham:Springer, 2018 :122-138.
Anesthesia resuscitation object detection method based on improved single shot multibox detector
LUO Ronghao, CHENG Zhiyou, WANG Chuanjian*, LIU Siqian, WANG Zhentian
(,,230039,)
The target detection model of anesthesia resuscitation is often used to help medical staff to perform resuscitation detection on anesthetized patients. The targets of facial actions during patient resuscitation are small and are not obvious, and the existing Single Shot multibox Detector (SSD) is difficult to accurately detect the facial micro-action features of patients in real time. Aiming at the problem that the original model has low detection speed and is easy to have missed detection, an anesthesia resuscitation object detection method based on improved SSD was proposed. Firstly, the backbone network VGG (Visual Geometry Group)16 of the original SSD was replaced by the lightweight backbone network MobileNetV2, and the standard convolutions were replaced by the depthwise separable convolutions. At the same time, the calculation method of first increasing and then reducing the dimension of the extracted features from patient photos was used to reduce computational cost, thereby improving detection speed of the model. Secondly, the Coordinate Attention (CA) mechanism was integrated into the feature layers with different scales extracted by the SSD, and the ability of the feature map to extract key information was improved by weighting the channel and location information, so that the network positioning and classification performance was optimized. Finally, comparative experiments were carried out on three datasets:CEW(Closed Eyes in the Wild), LFW(Labeled Faces in the Wild), and HAPF(Hospital Anesthesia Patient Facial). Experimental results show that the mean Average Precision (AP) of the proposed model reaches 95.23%, and the detection rate of photos is 24 frames per second, which are 1.39 percentage points higher and 140% higher than those of the original SSD model respectively. Therefore, the improved model has the effect of real-time accurate detection in anesthesia resuscitation detection, and can assist medical staff in resuscitation detection.
anesthesia resuscitation; facial feature recognition; Single Shot multibox Detector (SSD); MobileNetV2; attention mechanism
This work is partially supported by National Natural Science Foundation of China (82272225).
LUO Ronghao, born in 1997, M. S. candidate. His research interests include object detection, micro-action recognition.
CHENG Zhiyou, born in 1972, Ph. D., professor. His research interests include analysis and control of power quality.
WANG Chuanjian, born in 1977, Ph. D., professor. His research interests include computer vision, medical artificial intelligence.
LIU Siqian, born in 1997, M. S. candidate. His research interests include object detection.
WANG Zhentian, born in 1999, M. S. candidate. His research interests include object detection, optical character recognition.
TP391.41
A
1001-9081(2023)12-3941-06
10.11772/j.issn.1001-9081.2022121917
2023⁃01⁃04;
2023⁃04⁃05;
2023⁃04⁃06。
国家自然科学基金资助项目(82272225)。
罗荣昊(1997—),男,安徽滁州人,硕士研究生,主要研究方向:目标检测、微动作识别;程志友(1972—),男,安徽安庆人,教授,博士,主要研究方向:电能质量分析与控制;汪传建(1977—),男,安徽安庆人,教授,博士,CCF会员,主要研究方向:计算机视觉、医学人工智能;刘思乾(1997—),男,安徽巢湖人,硕士研究生,主要研究方向:目标检测;汪真天(1999—),男,安徽铜陵人,硕士研究生,主要研究方向:目标检测、光学文字识别。
