融合多Prompt模板的零样本关系抽取模型
2024-01-09许亮张春张宁田雪涛
许亮,张春,张宁,田雪涛
融合多Prompt模板的零样本关系抽取模型
许亮*,张春,张宁,田雪涛
(北京交通大学 计算机与信息技术学院,北京 100044)(∗通信作者电子邮箱20120467@bjtu.edu.cn)
Prompt范式被广泛应用于零样本的自然语言处理(NLP)任务中,但是现有基于Prompt范式的零样本关系抽取(RE)模型存在答案空间映射难构造与模板选择依赖人工的问题,无法取得较好的效果。针对这些问题,提出一种融合多Prompt模板的零样本RE模型。首先,将零样本RE任务定义为掩码语言模型(MLM)任务,舍弃答案空间映射的构造,将模板输出的词与关系描述文本在词向量空间中进行比较,以此判断关系类别;其次,引入待抽取关系类别的描述文本的词性作为特征,学习该特征与各个模板之间的权重;最后,利用该权重融合多个模板输出的结果,以此减少人工选取的Prompt模板引起的性能损失。在FewRel(Few-shot Relation extraction dataset)和TACRED(Text Analysis Conference Relation Extraction Dataset)这两个数据集上的实验结果显示,与目前最优的模型RelationPrompt相比,所提模型在不同数据资源设置下,F1值分别提升了1.48~19.84个百分点和15.27~15.75个百分点。可见,所提模型在零样本RE任务上取得了显著的效果提升。
关系抽取;信息抽取;零样本学习;Prompt范式;预训练语言模型
0 引言
随着互联网技术的迅速发展,文本数据规模呈指数级增长。为了更好地使用这些数据,学术界和工业界涌现了很多新兴的研究和应用。关系抽取(Relation Exaction, RE)是自然语言处理(Natural Language Processing, NLP)领域的一项重要的基础工作,旨在从非结构化文本数据中提取实体对之间的关系,支撑了包括知识图谱构建、智能问答和阅读理解等多个下游任务[1]。目前,许多有效新颖的RE方法被提出,例如融合长短记忆(Long Short-Term Memory, LSTM)[2]的RE方法PFN(Partition Filter Network)[3]、基于令牌(token)对链接预测的RE模型TPLinker(Token Pair Linker)[4]、结合带噪观测模型与深度神经网络的基于带噪观测的远监督神经网络RE模型[5]、结合卷积神经网络(Convolutional Neural Network, CNN)与预训练语言模型的全词掩模的双向变形编码器CNN(Bidirectional Encoder Representation from Transformers and CNN based on whole word mask,BERT(wwm)-CNN)[6]等。这些方法拥有非常好的性能,但是在训练过程中通常需要充足的标注数据;同时,它们只能识别在训练过程中已知的关系类别。然而在现实世界中无法为所有的关系都收集好充足的训练样本,为了解决这一问题,零样本学习(Zero-Shot Learning, ZSL)应运而生。
Lampert等[7]提出了ZSL的概念,核心思想是希望计算机模拟人类的推理方式,进而识别从未见过的新事物。在一般的有监督学习任务中,测试阶段的类别必须存在于训练阶段,即所有类别可见;而在ZSL的任务中,训练和测试阶段中分别为可见类和不可见类,通过训练阶段的学习,需要识别测试阶段的不可见类的样本。尽管ZSL应用潜力巨大,但目前这一具有挑战性的任务研究较少。为了使模型能够预测不可见类,既有的研究聚焦任务的建模过程,通常的方法是将零样本RE任务设计成不同的任务形式,例如:Levy等[8]将任务设计成问答的形式;Obamuyide等[9]将任务设计成文本蕴含问题。但是这种方法无法形成有效的关系语义表示空间,且任务之间存在较大差距,模型性能通常较差。近几年,预训练语言模型缓解了文本语义空间表示不充分的问题,NLP领域中ZSL任务的研究重心也逐渐转移为更好地使用预训练语言模型。
以基于Transformer的双向编码器技术BERT(Bidirectional Encoder Representations from Transformer)[10]为代表的预训练语言模型使NLP领域进入了一个新的发展阶段,NLP任务开始采用在下游任务中微调预训练语言模型的范式。在该范式中,由于预训练语言模型和下游任务的训练目标不同,训练过程存在一定的不稳定性。Prompt是一种通过给预训练模型提示的方式激发模型处理下游任务所需隐藏知识的技术。通过将原始任务转换成预训练模型的训练任务减小预训练阶段和下游任务阶段这两个阶段的差距,以此在特定任务上部署预训练语言模型。Razniewski等[11]通过完形填空的形式测试预训练语言模型中蕴藏的知识,证明了预训练模型可以有效地保存事实知识。类似地,Scao等[12]证明了Prompt范式在低资源环境中可以有效地提高样本使用效率。但是,目前零样本环境下Prompt模板的构建大部分为手动[13-14],费时费力。Zhao等[15]表明Prompt模板的选取是反直觉的。此外,Hu等[16]还提出手工设计和梯度下降得到的答案映射会带来覆盖范围不全导致的高偏差和高方差的问题。综上,传统Prompt范式高效应用在零样本RE任务上存在Prompt模板依赖手动选择和难构造答案映射这两个问题。
针对上述问题,本文提出了一种基于多Prompt模板的零样本RE模型。该模型把零样本RE任务转化为关系的表示生成任务,直接舍弃传统的答案空间映射,对齐词向量空间和关系的表示空间。通过比较预训练语言模型输出的[MASK]词向量和关系描述文本的词向量的相似度判断所属的关系类别,从根本上解决不可见类的映射构造困难的问题。此外,针对不同模板生成的表示空间差异较大、模板选择依赖人工选择的问题,本文提出了一种多Prompt模板融合方法,根据关系描述文本的词性赋予不同Prompt模板的权重,由这些权重融合多Prompt模板,以此提高模型RE能力。最后,在TACRED(Text Analysis Conference Relation Extraction Dataset)[17]和FewRel(Few-shot Relation extraction dataset)[18]这两个数据集上进行验证,实验结果表明了本文模型的有效性。
1 相关工作
1.1 零样本RE
ZSL的目标是在训练集中可见类和测试集中不可见类的特征空间中建立一种可以连接彼此的中间语义。Levy等[8]首次阐明了ZSL在RE上的概念,将目标任务建模为问答问题,通过让模型回答预定义的问题模板对不可见类进行归类;然而,该方法对于新出现的类别需要手动创建额外的问题,即在测试时需要增加新出现的类别实例,偏离了ZSL的测试集不可见的前提。Obamuyide等[9]将目标任务建模为文本蕴涵任务,由于关系的描述通常是公开的,通过判断输入的句子是否蕴含对应的关系描述识别关系类别,契合ZSL的任务定义;然而,该模型无法建立一个有效的语义表示空间,难以实现关系之间的比较。随着BERT[10]等预训练语言模型的出现,文本的语义表示能力得到进一步发展。Chen等[19]分别对输入文本和关系描述文本使用不同的投影函数,将二者转换到同一语义空间,并基于此空间下的表示进行关系分类;该方法较好地建立了语义空间且实现了类间比较,但由于测试集不可见,该方法的投影函数对测试集中的关系类别的映射能力有限。
1.2 Prompt范式
Prompt范式的思想是将下游任务的输入输出形式转换为预训练任务中的形式,即掩码语言模型(Masked Language Model, MLM)等任务,以降低模型与任务之间的差异。早在GPT-1(Generative Pre-trained Transformer 1)[20]中就开始在情感分析等任务上探索Prompt的应用。随着GPT-3[21]的Prompt方法成果显著,越来越多研究[22-24]尝试将Prompt范式引入较小的语言模型。Prompt模板可以将输入的普通文本转化为满足预训练任务输入的字符序列,例如在句子中加入[MASK]令牌([MASK]令牌表示BERT待预测位置的占位符,没有实际含义)使输入满足MLM任务需要的数据形式。如图1所示,根据预训练语言模型和Prompt模板的使用方式,Prompt范式的训练策略可以概括为4种不同情况。除了训练策略的多变,Prompt范式中模板的构造与选择也是主要的研究方向。Liu等[25]总结了相关研究。灵活的Prompt范式在信息抽取领域发展迅速,然而它在RE任务上的相关研究较少,特别是ZSL的特殊情况。
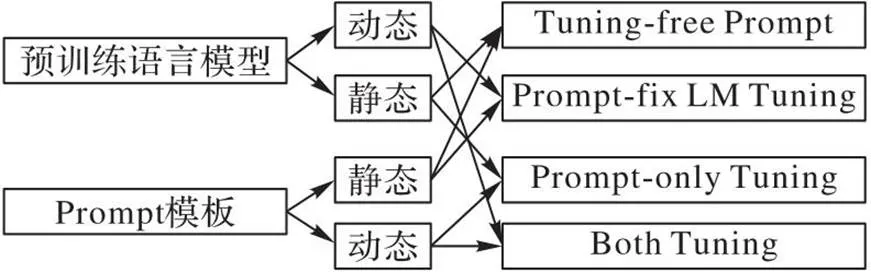
图1 Prompt的不同使用形式
2 基于多Prompt模板的零样本RE模型
2.1 问题定义与解决方案
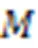
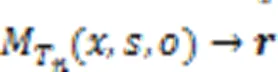
2.2 基于单Prompt模板的RE模型
零样本RE的核心目的是链接句子、主体和客体与对应的关系描述。由于测试集中的关系在训练集中不存在,因此通常需要大量的数据或者复杂的模型获得描述文本的表征能力;然而,零样本的任务特性又无法提供充足的数据以有效支持模型训练。针对上述问题,直接使用语言模型的词向量空间能确保模型在有限的训练样本下建立较好的语义表征。本文利用Prompt范式生成关系的表示,以实现句子、主体和客体与对应的关系描述之间的链接。
2.2.1Prompt模板设计和MLM预测
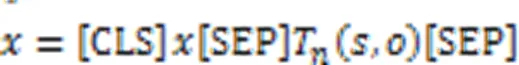
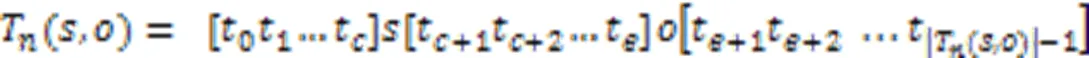

图2 基于Prompt范式的RE模型
2.2.2关系比较
值得注意的是,在零样本RE任务中,关系对应的描述就是token序列,而完形填空生成的词可以直接与关系描述在词向量空间中进行比较。例如,在将关系类别“P177”中的句子实例以Prompt方式输入预训练语言模型中时,“[CLS]…Mississippi River bridge to replace the deteriorating Cape Girardeau Bridge. [SEP]The cape Girardeau bridge [MASK] the Mississippi River.[SEP]”模型输出填充被掩盖位置的词是“crosses”,这与标签关系类别的名称完全重合,说明直接使用关系描述文本的词向量空间也可以较好地充当类表示空间。综上所述,为了尽可能减少RE下游任务和预训练语言模型之间的差异,本文舍弃构造答案空间映射,直接将生成的词向量作为关系表示,并将这个表示与关系描述经过预训练语言模型后生成的词向量进行比较。如式(4)所示,使用欧氏距离对MLM生成的词向量与关系描述文本的词向量进行比较:
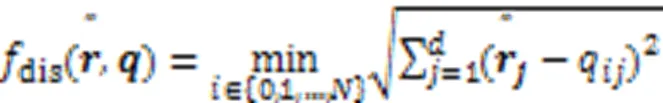
2.3 基于词性的多Prompt模板融合方法
实验发现,将相同的实例输入不同的Prompt模板后,模型的输出存在差异,这种差异一般体现在模型对不同关系的抽取能力。Prompt模板的选择对模型的表现起着非常关键的作用;然而,现有的自动模板选取算法需要一定的数据量,不适合零样本任务,手动选取模板费时费力。为此,本文提出一种适合零样本任务的多Prompt模板融合方法。如图3所示,通过引入可见类与不可见类通用的词性信息融合多个模板的输出结果。
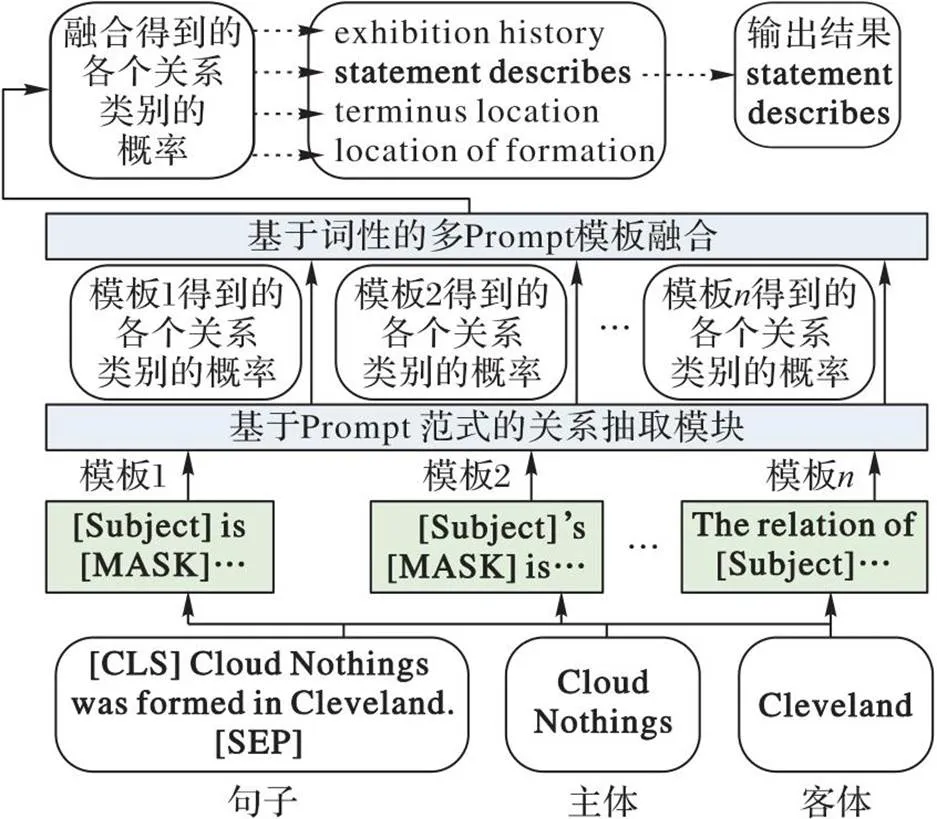
图3 基于词性的多Prompt模板融合方法
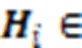
式(5)表示不同模板对不同关系类别的权重:
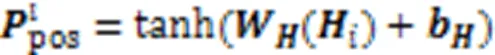

表1 NLTK库中部分词性及其缩写的含义
3 实验
3.1 数据集
FewRel数据集[18]包含80个关系,其中65个关系用于模型训练,15个关系用于模型测试。每种关系具有700个远程监督生成的样本实例,这些实例中包含主体和客体构成的实体对。此外,每个关系的文本描述由关系名称和关系描述构成。TACRED数据集[17]是一个拥有106 264个实例的大规模RE数据集,共有42个关系类别。该数据集中的数据样本呈长尾分布,关系类别的样本实例间差距达到10倍以上。该数据集缺少关系的文本描述,本文在实验中使用了TAC-KBP(Text Analysis Conference Knowledge Base Population)关系本体指南中对这些关系的描述。
3.2 实验设置
本文实验采用Transformers库[27],使用BERT-base和BERT-large预训练语言模型进行模型实现。预训练语言模型的token表示维度为768或1 024。FewRel和TACRED数据集中句子最大长度分别为110和250。模型训练初始学习率为2×10-5,batch size大小为2,选用AdamW[28]作为优化器。实验环境为RTX3090Ti显卡。评估指标选取精确率(Precision, Prec)、召回率(Recall, Rec)和宏平均(Macro-F1, F1)。
3.3 基线模型
3.3.1有监督的RE模型
监督学习范式构建的RE模型通过不同方式从句子中提取特征进行预测,包括Att-Bi-LSTM(Attention-based Bidirectional LSTM)[29]和R-BERT(Relational model with Bidirectional Encoder Representations from Transformer)[30]。前者结合注意力机制和双向长短记忆(Bi-directional LSTM, Bi-LSTM),是有监督RE中非常经典的算法,可以有效地在句子中抽取对应的关系与实体,本文将它应用到零样本RE任务中,并作为基线进行比较;后者是针对零样本RE任务优化后的有监督RE模型,它通过将模型最后的Softmax层转换为具有tanh激活函数的全连接层,并利用最近邻搜索找到关系描述的向量的方式,生成关系类别的预测。
3.3.2文本蕴含模型
将零样本RE任务转换为文本蕴涵任务,通过判断句子和关系描述是否有语义蕴含的关系决定所属关系类别。ESIM(Enhanced long Short-term memory Inference Model)[31]是一种使用Bi-LSTM 对输入序列进行编码并评估蕴含关系的模型。
3.3.3关系的表示生成模型
利用模型生成代表关系的句子表示,将句子的表示和类的表示进行距离比较,进而选出最合适的类别。ZS-BERT(Zero-Shot BERT)[19]通过学习投影函数,将句子与词向量空间中的关系对齐,从而能够预测在训练阶段未见的关系类。
3.3.4基于Prompt的模型
利用Prompt激活预训练语言模型中的内部知识进行零样本RE任务。RelationPromt(Relation label Prompt)[32]是基于GPT-2的文本生成模型与BART(Bidirectional and Auto-Regressive Transformer)[33]的RE模型组合而成的,前者结合文本生成模型和Prompt,生成不可见的关系类的训练样本;后者利用这些训练样本对抽取模型进行有监督的训练。通过这种方式抽取未见的关系类。MFP(zero-shot relation extraction Method Fusing multiple templates based on Prompt)[34]是使用梯度回归让模型自己学习模板的词性特征向量的方法。该方法在通过预训练语言模型得到词向量后,构建了一个新的映射输出关系表示,并且模型由梯度回归自动学习词性的特征表示。
3.4 实验结果与分析
3.4.1性能对比实验
表2展示了在FewRel和TACRED数据集上的性能对比实验结果,其中为测试集的不可见类别种类数,是训练的数据量。本文在不同参数规模的BERT上进行了实验。实验结果直观地展示了参数量越大的预训练语言模型的性能表现越好。此外,与目前最优的模型RelationPrompt相比,本文模型在两个数据集的不同训练数据量设置中分别提高了1.48~19.84个百分点和15.27~15.75个百分点,说明了本文模型的有效性。一般地,数据量越充足,模型的效果越出色。但是从表2中可以看出,本文模型在低资源的数据量下也可以有很好的效果。
事实上,根据数据集的不同,本文模型在低数据资源的情况下甚至与其他对比模型在充足训练数据(=all)下的效果更接近。具体地,在TACRED数据集中,本文模型在=100条件下相较于其他对比模型,F1指标至少提升了15.27个百分点;同时,在该资源条件下与其他对比模型在充足数据的条件下F1指标有只有3.30个百分点的性能差异。以上实验结果验证了Prompt范式确实可以提高数据的利用效率。RelationPrompt[32]通过将Prompt与文本生成模型相融合生成零样本数据资源的方式也有不错的性能表现;但是由于它的预训练模型GPT-2与BART都是通过更多参数与更多训练数据得到的,两个预训练模型的差异会造成较大的误差传递。在TACRED中20的实验设置下,RelationPrompt会出现无法生成需要的训练数据的现象,从而无法训练需要的不可见RE模型。值得注意的是,MFP通过梯度回归学习关系描述文本的词性特征的方法增大了需要学习的参数量,却导致了模型表现的下降,特别是训练样本数减少时,表现更加明显。这是因为额外的参数学习需要新的数据保证模型的表现,本质上,Prompt范式的使用就是为了最大限度不引入新的参数变量。本文使用了语言学的统计学的特征,一定程度上减少了模型的参数量,使模型更加适合零样本RE任务。

表2 不同数据集和不同不可见关系种类数在不同训练数据量下的性能对比 单位: %
本文对齐词向量空间和语义关系的表示空间,缓解了上述MFP存在的问题。值得注意的是,本文模型召回率较高,精确度却较低。这说明了本文模型对某些类特别敏感,可以很好识别该目标类,但同时也会导致将其他不属于该类的实例识别成该类的问题。文献[35-37]中提到预训练语言模型有表示退化问题,模型更倾向输出高频词,导致模型的词嵌入空间呈圆锥分布。这种情况是普遍的,同样也是进一步研究的方向。
3.4.2消融实验
如表3所示,在TACRED和FewRel数据集上进行消融实验以探究模型各个部分的影响。为了更关注模型的整体效果,消融实验在充足的训练数据(all)和使用BERT-base的条件下进行。首先探究各个模板对模型的影响。本文通过手工的方式设置了36个Prompt模板作为模板库,表3随机展示了5个不同的模板在单模板情况下的模型性能。可以看到在不同模板的情况下,虽然模型性能不同,但是同条件下与表2中除RelationPrompt和MFP的其他基线模型性能相比,FewRel和TACRED数据集中F1指标分别至少提升了14.90个百分点和5.94个百分点。这说明了将[MASK]位置的词向量空间与类表示空间对齐的方法是有效的。
图4为不同模板中预测的[MASK]位置的词性的统计(词性缩写含义见表1),其中Prompt模板是表3中的5个模板,轴的缩写的解释说明如表1所示,具体信息可以参考NLTK库中的函数说明。可以看出在不同模板中,预训练语言模型预测的[MASK]位置的单词的词性有着特殊的规律。例如,在其他条件相同的情况下,模板4预测的词的词性集中在NN;类似地,模板1在预测[MASK]位置单词的任务中,输出了更多的VBN词性的词汇。这说明了Prompt模板与输出单词的词性是相关的。不同模板的效果有差异,但是差异的变化范围有限。实验结果表明,不能通过简单地修改手工设计的模板实现效果的巨大提升。
为了深入地探究基于词性的融合方法的优势,研究还比较了平均融合、加权融合和基于词性梯度回归的融合方法。平均融合是将多模板的参数进行均值处理,加权融合是利用梯度回归让模型自己学习各个模板的权重。
从实验结果看,尽管在TACRED数据集中,不同的融合方法都比单独使用一种模板模型的效果好,但是在FewRel数据集中,却出现了模型效果下降的情况。这说明了多模板融合的方法会对不同数据集产生不同的影响,但是这种影响是不确定的,无法稳定地提高效果。此时,词性作为桥梁的作用就得到了体现,相较于其他融合方法,即使数据集不同,基于词性的融合方法都明显优于其他方法。无论是单Prompt模板RE方法还是将多模板通过其他不同的方法融合的方法,效果都低于基于词性的多Prompt模板融合方法。
表3TACRED和FewRel数据集上的消融实验结果 单位: %

Tab.3 Ablation experimental results on TACRED and FewRel datasets unit: %
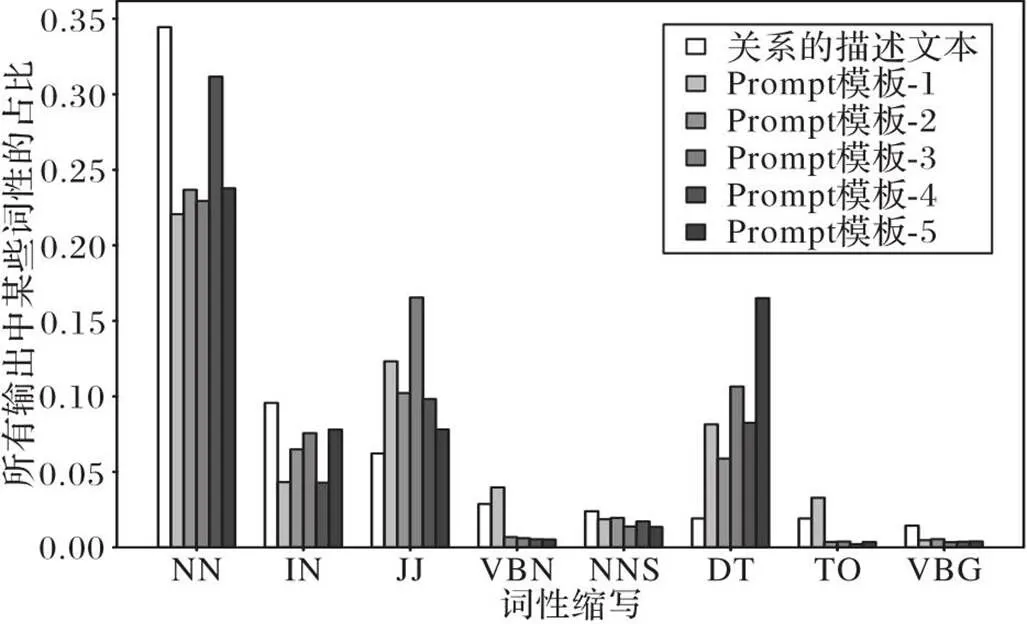
图4 不同模板预测的词的词性部分统计
3.4.3交叉域研究实验
为了深入研究模型的泛化性,本文还进行了交叉域的研究。本文将FewRel和TACRED数据集的训练集与测试集进行了调换,用FewRel训练集训练的模型预测TACRED中的测试集和用TACRED训练集训练的模型预测FewRel的测试集,并将得到的结果与其他模型进行了比较,实验结果如表4所示。显然,本文模型的性能表现出色。在对比原训练集时,RelationPrompt在两个数据集上分别比原有的F1指标下降了28.36个百分点和12.5个百分点;而在相同条件下,本文模型的F1指标只下降了5.84个百分点和7.58个百分点,这说明了本文模型优秀的鲁棒性。
3.4.4模板个数对模型性能的影响
本节研究模板数对多Prompt模板RE模型的实验效果的影响。从模板库中随机抽取1~5个不同数的模板,并对基于词性的多Prompt模板融合方法在不同模板数上进行性能评估。考虑到不同模板对实验也有影响,因此本节实验中采用重复5次实验取平均值的实验设置。图5分别为在两个数据集中的实验结果。基于词性的多Prompt模板融合方法需要一定数量的模板才能发挥较好的效果;但是它对模板数的需求有限,当模板数超过一定值时,模型的效果开始下降;同时,针对不同的数据集的最优模板数参数并不相同。值得注意的是,无论Prompt模板数为多少,本文模型的效果始终超过单Prompt模板,这说明基于词性的多Prompt模板融合方法是稳定有效的。
表4交叉域实验结果 单位: %

Tab.4 Results of cross domain experiments unit: %
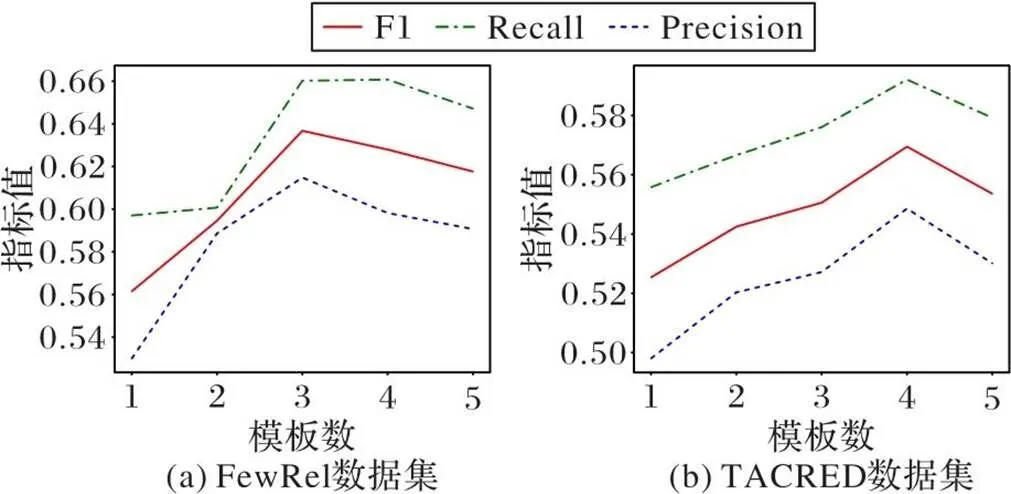
图5 不同模板数的性能比较
4 结语
在RE领域中,存在着无法为全部关系标注足量训练数据的问题,因此ZSL在该任务上具有较大的研究价值。现有基于Prompt范式的RE算法由于答案空间映射问题难构造与自动构建模板有一定的数据资源需求的问题,无法较好地应用在零样本RE任务。本文提出了一种融合多Prompt模板的零样本RE模型,该模型通过对齐类表示空间与词向量空间和利用词性融合多个Prompt模板解决上述问题,将Prompt范式引入零样本RE任务。最后,在FewRel和TACRED数据集进行了多组实验,验证了本文模型的具有优秀的性能表现。目前Prompt在零样本RE任务中还是具体表现为离散的单词,未来将进一步研究如何自动化地构建连续且能够高效激活预训练语言模型的Prompt,进一步提高零样本RE的性能。
[1] ZHANG F, YUAN N, LIAN D, et al. Collaborative knowledge base embedding for recommender systems [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2016: 353-362.
[2] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[3] YAN Z, ZHANG C, FU J, et al. A partition filter network for joint entity and relation extraction [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA: Association for Computational Linguistics, 2021: 185-197.
[4] WANG Y, YU B, ZHANG Y, et al. TPLinker: single-stage joint extraction of entities and relations through token pair linking [C]//Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg, PA: International Committee on Computational Linguistics, 2020: 1572-1582.
[5] 叶育鑫,薛环,王璐,等. 基于带噪观测的远监督神经网络关系抽取[J].软件学报,2020,31(4):1025-1038.(YE Y X,XUE H,WANG L, et al. Distant supervision neural network relation extraction base on noisy observation[J]. Journal of Software, 2020, 31(4): 1025-1038.)
[6] 武小平,张强,赵芳,等. 基于BERT的心血管医疗指南实体关系抽取方法[J]. 计算机应用, 2021, 41(1): 145-149.(WU X P, ZHANG Q, ZHAO F, et al. Entity relation extraction method for guidelines of cardiovascular disease based on bidirectional encoder representation from transformers [J]. Journal of Computer Applications, 2021, 41(1):145-149.)
[7] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer [C]// Proceedings of the 2009 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 951-958.
[8] LEVY O, SEO M, CHOI E, et al. Zero-shot relation extraction via reading comprehension [C]// Proceedings of the 21st Conference on Computational Natural Language Learning, Stroudsburg, PA: Association for Computational Linguistics, 2017: 333-342.
[9] OBAMUYIDE A, VLACHOS A. Zero-shot relation classification as textual entailment [C]// Proceedings of the First Workshop on Fact Extraction and Verification, Stroudsburg, PA: Association for Computational Linguistics, 2018: 72-78.
[10] DEVLIN J, CHANG M, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[11] RAZNIEWSKI S, YATES A, KASSNER N, et al. Language models as or for knowledge bases [EB/OL]. (2021-10-10)[2022-07-14]. https://arxiv.org/pdf/2110.04888.pdf.
[12] SCAO T L, RUSH A M. How many data points is a prompt worth?[EB/OL]. (2021-03-15)[2022-07-14]. https://arxiv.org/pdf/2103.08493.pdf.
[13] SAINZ O, DE LACALLE O L, LABAKA G, et al. Label verbalization and entailment for effective zero-and few-shot relation extraction [EB/OL]. (2021-09-08)[2022-07-14]. https://arxiv.org/pdf/2109.03659.pdf.
[14] LIU X, ZHENG Y, DU Z, et al. GPT understands, too [EB/OL]. (2021-03-18)[2022-07-14]. https://arxiv.org/pdf/2103.10385.pdf.
[15] ZHAO J, HU Y, XU N, et al. An exploration of prompt-based zero-shot relation extraction method [C]// Proceedings of the 21st Chinese National Conference on Computational Linguistic. Beijing: Chinese Information Processing Society of China, 2022: 786-797.
[16] HU S, DING N, WANG H, et al. Knowledgeable prompt-tuning: incorporating knowledge into prompt verbalizer for text classification [EB/OL]. (2021-08-04)[2022-07-14]. https://arxiv.org/pdf/2108.02035.pdf.
[17] ZHANG Y, ZHONG V, CHEN D, et al. Position-aware attention and supervised data improve slot filling [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017: 35-45.
[18] HAN X, ZHU H, YU P, et al. FewRel: a large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 4803-4809.
[19] CHEN C-Y, LI C-T. ZS-BERT: towards zero-shot relation extraction with attribute representation learning [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2021: 3470-3479.
[20] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2022-07-14]. https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
[21] BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook:Curran Associates Inc., 2020: 1877-1901.
[22] SCHICK T, SCHÜTZE H. Exploiting cloze questions for few shot text classification and natural language inference [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2021: 255-269.
[23] SCHICK T, SCHÜTZE H. It’s not just size that matters: small language models are also few-shot learners [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA: Association for Computational Linguistics, 2021: 2339-2352.
[24] GAO T, FISCH A, CHEN D. Making pre-trained language models better few-shot learners [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 3816-3830.
[25] LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing [EB/OL]. (2021-07-28)[2022-07-14]. https://arxiv.org/pdf/2107.13586.pdf.
[26] WAGNER W .Natural language processing with Python: analyzing text with the natural language Toolkit [J]. Language Resources and Evaluation, 2010, 44(4):421-424.
[27] LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2019-01-04)[2022-07-14]. https://arxiv.org/pdf/1711.05101.pdf.
[28] WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2020: 38-45.
[29] ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 207-212.
[30] WU S, HE Y. Enriching pretrained language model with entity information for relation classification [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 2361-2364.
[31] CHEN Q, ZHU X, LING Z, et al. Enhanced LSTM for natural language inference [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1657-1668.
[32] CHIA Y K, BING L, PORIA S, et al. RelationPrompt: leveraging prompts to generate synthetic data for zero-shot relation triplet extraction [EB/OL]. (2022-03-17)[2022-07-14]. https://arxiv.org/pdf/2203.09101.pdf.
[33] LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [EB/OL]. (2019-10-29)[2022-07-14]. https://arxiv.org/pdf/1910.13461.pdf.
[34] 北京交通大学. 一种基于Prompt多模板融合的零样本关系抽取方法: CN202211082703.4[P]. 2023-02-03.(Beijing Jiaotong University. A zero-shot relation extraction method fusing multiple templates based on Prompt: CN202211082703.4[P]. 2023-02-03.)
[35] WANG L, HUANG J, HUANG K, et al. Improving neural language generation with spectrum control [EB/OL]. (2022-03-11)[2022-07-14]. https://openreview.net/attachment?id=ByxY8CNtvr&name=original_pdf.
[36] GAO J, HE D, TAN X, et al. Representation degeneration problem in training natural language generation models [EB/OL]. (2019-07-28)[2022-07-14]. https://arxiv.org/pdf/1907.12009.pdf.
[37] LI B, ZHOU H, HE J, et al. On the sentence embeddings from pre-trained language models [EB/OL]. (2020-11-02)[2022-07-14]. https://arxiv.org/pdf/2011.05864.pdf.
Zero-shot relation extraction model via multi-template fusion in Prompt
XU Liang*, ZHANG Chun, ZHANG Ning, TIAN Xuetao
(,,100044,)
Prompt paradigm is widely used to zero-shot Natural Language Processing (NLP) tasks. However, the existing zero-shot Relation Extraction (RE) model based on Prompt paradigm suffers from the difficulty of constructing answer space mappings and dependence on manual template selection, which leads to suboptimal performance. To address these issues, a zero-shot RE model via multi-template fusion in Prompt was proposed. Firstly, the zero-shot RE task was defined as the Masked Language Model (MLM) task, where the construction of answer space mapping was abandoned. Instead, the words output by the template were compared with the relation description text in the word embedding space to determine the relation class. Then, the part of speech of the relation description text was introduced as a feature, and the weight between this feature and each template was learned. Finally, this weight was utilized to fuse the results output by multiple templates, thereby reducing the performance loss caused by the manual selection of Prompt templates. Experimental results on FewRel (Few-shot Relation extraction dataset) and TACRED (Text Analysis Conference Relation Extraction Dataset) show that, the proposed model significantly outperforms the current state-of-the-art model, RelationPrompt, in terms of F1 score under different data resource settings, with an increase of 1.48 to 19.84 percentage points and 15.27 to 15.75 percentage points, respectively. These results convincingly demonstrate the effectiveness of the proposed model for zero-shot RE tasks.
Relation Extraction (RE); information extraction; Zero-Shot Learning (ZSL); Prompt paradigm; pre-trained language model
This work is partially supported by the National Key Research and Development Program of China (2019YFB1405202).
XU Liang, born in 1997, M. S. candidate. His research interests include natural language processing.
ZHANG Chun,born in 1966, M. S., research fellow. Her research interests include railway information, intelligent information processing.
ZHANG Ning,born in 1958, Ph. D., research fellow. His research interests include railway information, intelligent information processing, embedded system.
TIAN Xuetao,born in 1995, Ph. D. His research interests include natural language processing.
TP391.1
A
1001-9081(2023)12-3668-08
10.11772/j.issn.1001-9081.2022121869
2022⁃12⁃22;
2023⁃03⁃27;
2023⁃03⁃28。
国家重点研发计划项目(2019YFB1405202)。
许亮(1997—),男,安徽芜湖人,硕士研究生,主要研究方向:自然语言处理;张春(1966—),女(满族),北京人,研究员,博士生导师,硕士,主要研究方向:铁路信息、智能信息处理;张宁(1958—),男,北京人,研究员,博士生导师,博士,主要研究方向:铁路信息、智能信息处理、嵌入式系统;田雪涛(1995—),男(蒙古族),内蒙古通辽人,博士,主要研究方向:自然语言处理。
