基于多层次注意力的语义增强情感分类模型
2024-01-09曹建乐李娜娜
曹建乐,李娜娜
基于多层次注意力的语义增强情感分类模型
曹建乐,李娜娜*
(河北工业大学 人工智能与数据科学学院,天津 300401)(∗通信作者电子邮箱linana@scse.hebut.edu.cn)
由于自然语言的复杂语义、词的多情感极性以及文本的长期依赖关系,现有的文本情感分类方法面临严峻挑战。针对这些问题,提出了一种基于多层次注意力的语义增强情感分类模型。首先,使用语境化的动态词嵌入技术挖掘词汇的多重语义信息,并且对上下文语义进行建模;其次,通过内部注意力层中的多层并行的多头自注意力捕获文本内部的长期依赖关系,从而获取全面的文本特征信息;再次,在外部注意力层中,将评论元数据中的总结信息通过多层次的注意力机制融入评论特征中,从而增强评论特征的情感信息和语义表达能力;最后,采用全局平均池化层和Softmax函数实现情感分类。在4个亚马逊评论数据集上的实验结果表明,与基线模型中表现最好的TE-GRU (Transformer Encoder with Gated Recurrent Unit)相比,所提模型在App、Kindle、Electronic和CD数据集上的情感分类准确率至少提升了0.36、0.34、0.58和0.66个百分点,验证了该模型能够进一步提高情感分类性能。
情感分类;自然语言处理;词嵌入;注意力机制;神经网络
0 引言
情感分析是自然语言处理(Natural Language Processing,NLP)领域的一个热门研究方向,它的目的是从用户发布在网络的主观信息中提取和分析知识。情感分类是情感分析的研究主题之一,旨在根据情感极性对文本进行分类[1],近年来受到了众多研究者的密切关注,并取得了许多进展。随着互联网产业的快速发展,用户在网络上发表的观点和评论越来越多。利用情感分类技术分析这些用户评论信息,可以推测用户的情感和心理状态,有助于研究机构掌握社会情绪的动态[2]。
目前的情感分类方法主要分为传统方法和基于深度学习的方法。传统方法通常使用大量的人工特征[3]和浅层学习方法进行分类,如支持向量机[4]和朴素贝叶斯[5]等。然而,传统方法的特征提取过程需要花费大量的人力和时间,并且会导致情感表达不完整,处理复杂任务的能力有限。基于深度学习的方法能够避免人工特征提取,降低了模型开发成本。常用的深度学习方法,如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、双向门控循环单元(Bidirectional Gated Recurrent Unit, BiGRU)和双向长短期记忆(Bidirectional Long Short-Term Memory, BiLSTM)网络等,已广泛应用于情感分类任务[6-7]。目前,大多数文本情感分类方法主要集中在生成丰富的文本特征表示,以提高模型的性能。研究者通常采用结构复杂的编码器以及注意力机制[8]生成语义丰富的特征表示。虽然这些方法在一定程度上解决了相关问题并改善了性能,但仍存在以下问题:1)使用预训练的静态词嵌入,无法处理单词的复杂语义,缺乏在不同文本中表达不同词义的能力;2)使用大量的序列模型,顺序编码的方式导致时间复杂度高,且难以捕获全面的文本特征信息;3)一个句子中可能存在多个对句子情感倾向产生重要影响的词,而传统的注意力机制无法完全学习句子的情感信息,不能有效地获取文本的情感语义特征。
针对上述问题,本文提出了一种基于多层次注意力的语义增强情感分类模型。模型采用BERT(Bidirectional Encoder Representation from Transformers)[9]预训练模型构建文本的动态词嵌入向量,并且通过多层次的内部注意力层和外部注意力层生成包含丰富情感语义信息的文本特征表示,使用增强的文本特征进行情感分类。为了验证该模型的有效性,在4个亚马逊评论文本数据集上进行实验。实验结果表明,本文模型在情感分类任务上的性能优于大多数先进模型。
本文的主要工作如下:
1)使用动态词嵌入技术构建文本的语境化的上下文词嵌入,有效地挖掘词汇的多重语义信息。
2)使用多层次的内部注意力层,引入多头注意力机制并行地从不同特征子空间中学习语义特征,能够降低模型时间复杂度并捕获文本中的长期依赖关系,获取全面的文本特征信息。
3)考虑到模型各层具有不同的句法和语义信息处理能力,本文模型的内部注意力层设计了两种并行层次组合策略,用于获得单层输出结构无法捕获的额外信息。
4)外部注意力层采用多层的注意力机制,利用元数据的总结信息增强评论特征的情感语义表达能力,实验结果表明该模型有效提升了情感分类的性能。
1 相关工作
1.1 词嵌入技术
大多数词嵌入方法都依赖于语言分布结构的假设,具体地,相似上下文中的词通常具有相似的语义,而词的语义由它们的上下文决定。Mikolov等[10]利用单词语义以及单词之间的关系提出了Word2Vec(Word to Vector)模型,该模型包括连续词袋模型(Continuous Bag-Of-Word model, CBOW)和连续Skip-gram(Continuous Skip-gram Model)两种算法。这两种算法都基于元模型,该模型假设一个单词只与它周围的个单词相关;但这一假设使得该方法对全局信息利用不足。Pennington等[11]提出了GloVe(Global Vectors for word representation)模型,考虑全局信息和局部信息的全局向量词表示;但这种嵌入方法是一种静态嵌入,无法用于一个词具有多种含义的情况。
Peters等[12]通过使用BiLSTM,提出来自深层语言模型的嵌入(Embeddings from Language MOdels, ELMO),不仅能生成动态词嵌入,而且可以利用单词的深层语义。基于Transformer[13]强大的特征提取能力,Radford等[14]提出一种生成式预训练(Generative Pre-Training,GPT)模型,使用Transformer代替ELMO中的长短期记忆(Long Short-Term Memory, LSTM),在当时取得了多个NLP任务中的最好结果。Devlin等[9]提出了BERT模型,使用双向语言模型替换单向语言模型,并结合CBOW算法的技巧。BERT作为近年来词嵌入模型的代表,在多项NLP任务中取得了最优的表现。本文模型利用BERT获得词嵌入,更具体地,通过使用BERT为情感分类模型提供输入文本序列的上下文感知嵌入。
1.2 情感分类方法
早期工作多使用数据挖掘[15]和机器学习[16-17]等方法在情感分类领域进行研究。随着深度学习的发展,CNN和RNN在NLP领域取得了显著的成功。Kalchbrenner等[18]提出动态CNN,使用宽卷积和池化捕获单词关系,通过构造类似解析树的结构提取长距离的信息。Rezaeinia等[19]基于CNN模型和改进的单词嵌入进行文档情感分类,通过改进词嵌入的词汇、位置和句法特征,提高了情感分类中词嵌入的准确性。与CNN相比,RNN引入了记忆单元,能够考虑文本之间的长期依赖。Zhou等[20]采用堆叠的BiLSTM网络,提高了对序列特征中长期依赖的学习能力。Chatterjee等[21]提出了多通道LSTM模型,通过结合语义和基于情感的表示提高情感检测能力。
为结合CNN和RNN各自的优点,一些研究尝试结合这两种结构。Hassan等[22]将CNN与RNN串行连接,使用CNN提取情感特征,LSTM实现上下文语义的建模,该模型能减少局部信息的丢失,并捕获长期依赖关系;Batbaatar等[23]将CNN与RNN并行连接,使用BiLSTM捕获上下文信息并专注语义关系,同时使用CNN提取情感特征并侧重文本中单词之间的情感关系;Tam等[24]使用卷积层解决BiLSTM的局限性,使用一维卷积提取文本不同位置的局部特征并降低其维度,之后使用BiLSTM提取文本的上下文信息,该方法通过获取句子上下文中的局部和全局相关性,有效地提高了文本情感分类性能。
1.3 基于注意力的模型方法
注意力机制能使模型关注文本中的重要信息,因此常被用于增强文本的特征。Bahdanau等[8]在机器翻译任务中使用了注意力机制,首次将注意力机制应用于NLP领域。Liu等[25]提出基于注意力的卷积层BiLSTM模型,解决了文本数据的高维和稀疏性问题,并通过捕获短语的局部特征和全局句子语义,有助于处理自然语言的复杂语义。自注意力机制[13]充分考虑句子中不同词语之间的语义以及语法联系,能够进一步地捕获上下文之间的联系。Li等[26]提出了具有自注意力机制和多通道特征的BiLSTM模型。该模型对语言知识和情感资源进行建模,形成不同的特征通道,并利用自注意力机制增强情感信息;然而该模型不适用于处理长文本信息。Liu等[27]组合两层具有注意力的BiGRU模型获得长文本的组合语义,并应用二维卷积捕获句子特征之间的依赖关系;然而该方法仅强调句子的重要性,缺少对单词价值的关注。
Kamyab等[28]提出了基于双通道CNN和双向RNN(Bidirectional RNN, Bi-RNN)的深度模型,应用注意力同时强调单词和文本的重要性,并采用零填充策略使模型同样适用于长文本数据,输入层使用高斯噪声和随机失活作为正则化防止过拟合。Zhu等[29]利用自注意力机制捕获文本上下文全局信息,关注文本的关键词和句子信息,通过并行的空洞卷积和标准卷积获得多尺度特征信息,提高了情感分类的性能。然而,单一的注意力机制无法从文本中提取多语义的情感信息,不能有效地获取文本的情感语义特征;因此本文提出一种基于多层次注意力的语义增强情感分类模型,从多个层次提取文本的语义信息,丰富文本的特征表示,进而提升模型的情感分类性能。
2 本文模型
本文模型的流程如图1所示。模型主要包括4个部分:输入嵌入层、内部注意力层、外部注意力层和分类输出层。其中表示评论文本序列,表示总结文本序列。
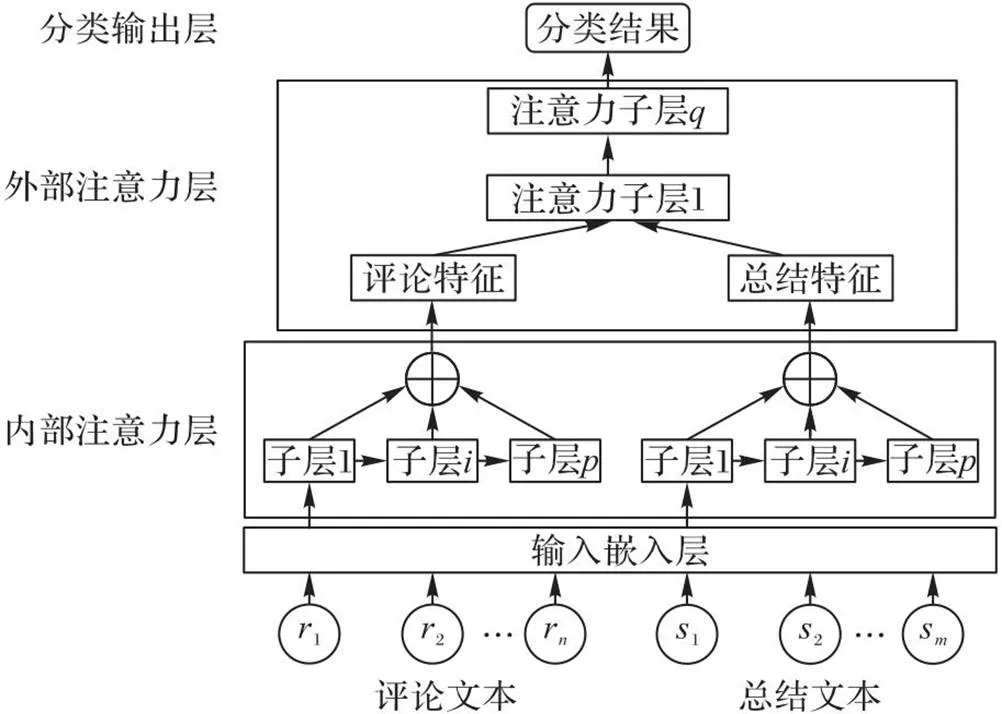
图1 模型框架
首先,输入嵌入层利用BERT词嵌入技术为文本生成对应的上下文动态词嵌入;其次,内部注意力层采用多层次的结构生成文本的全面特征表示,当中的每一层都包含一个多头自注意力机制和前馈全连接层,内部注意力层中采用了两种并行的层次组合策略,即连续层次组合和间隔层次组合;再次,外部注意力层通过在评论特征和总结信息之间应用多层注意力机制,获得情感语义增强的评论特征表示;最后,分类输出层对最终的评论特征使用全局平均池化操作和Softmax激活函数,获得评论文本的情感分类结果。
2.1 输入嵌入层
词嵌入技术用于将文本中的每个词映射到低维实值向量空间中。与上下文无关的静态词嵌入技术相比,BERT模型可以生成上下文感知的动态词嵌入表示,能够更好地对上下文语义进行建模。本文模型利用BERT为文本中的每个单词生成词嵌入向量。输入嵌入层的结构如图2所示,表示单词对应的词向量。
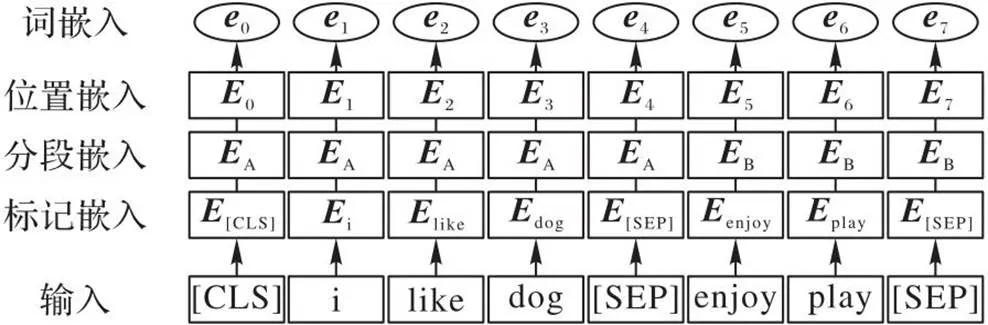
图2 输入嵌入层

2.2 内部注意力层
获得每个单词的词嵌入向量后,模型使用内部注意层来生成文本的特征表示。内部注意力层采用了多层的结构,每一层主要包括两部分:多头自注意力机制和前馈全连接层。本文设计了两种并行的层次组合策略:连续层次组合和间隔层次组合。内部注意力层的结构如图3所示。
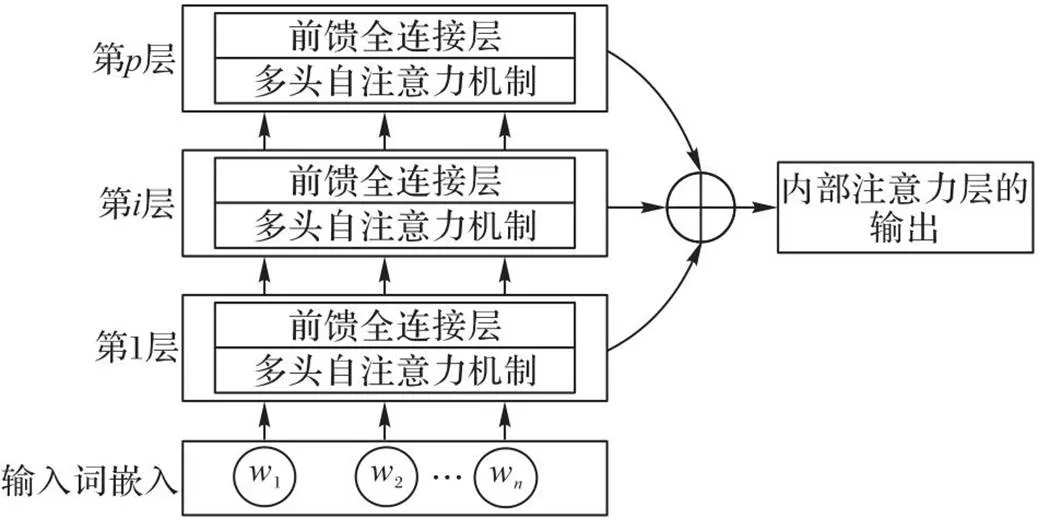
图3 内部注意力层
2.2.1多头自注意力机制
多头自注意力利用多个并行的注意力机制获得句子中每个单词的加权注意力分数。这种结构设计能让每个注意力机制优化每个词的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有更多元的表达能力。多头注意力中的“头”是一种特殊的注意力机制,由多个并行的缩放点积注意力机制组成;因此在介绍多头注意力之前,需要先介绍缩放点积注意力。缩放点积注意力和多头注意力的结构如图4所示。

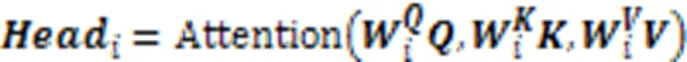
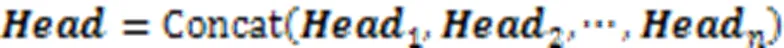


2.2.2前馈全连接层
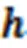
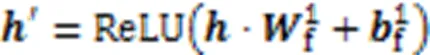
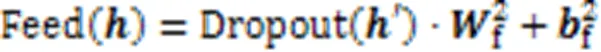
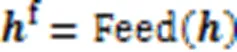
2.2.3层次组合策略
考虑到单个内部注意力层难以完全提取句子中单词之间的语义特征,本文模型采用多层次的内部注意力层捕获文本内部的长期依赖关系,并获得全面的上下文特征信息。本文设计了两种并行的层次组合策略,包括连续层次组合策略和间隔层次组合策略。
在连续层次组合策略中,将内部注意力层的最后层的输出进行组合,获得内部注意力层最终的特征输出。对于间隔层次的组合策略,内部注意力层最终的特征输出表示由间隔的层内部注意力的输出组合获得。两种方式的计算如式(10)和式(11)所示:
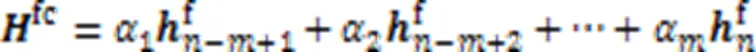
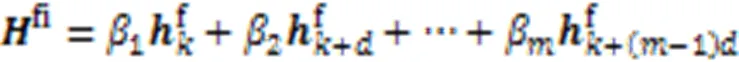
2.3 外部注意力层
外部注意力层利用总结信息增强评论文本特征的情感语义信息。外部注意力层的结构如图5所示,包括多个堆叠的注意力子层。外部注意力子层使用注意力机制捕获评论与总结之间的情感依赖关系,通过在评论特征表示中查询总结特征表示,增强评论特征的情感信息和语义信息。多个注意力子层堆叠有利于获得更精细的特征表达能力。
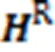
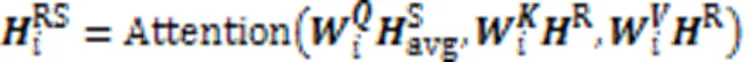
其中:为第i个外部注意力子层输出的评论特征;、和是需要训练学习的线性变换矩阵。注意力子层的计算方式也可以使用多头注意力。
2.4 分类输出层
分类输出层的目的是将模型学习的分布式特征表示映射到样本标记空间。模型的输出层采用全局平均池化层和Softmax层替代传统的池化层和全连接层,减少了模型的参数量,避免过拟合。

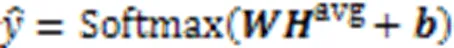
模型的训练目标是最小化预测标签和真实标签之间的交叉熵损失,损失函数的计算如式(15)所示:

3 实验与结果分析
3.1 实验设置
3.1.1数据集
本文在4个亚马逊产品评论数据集上对模型的有效性进行实验评估,数据集分别为:安卓应用程序数据集(App)、Kindle商店数据集(Kindle)、电子产品数据集(Electronic)和光盘与黑胶唱片数据集(CD)[30]。
数据集的详细统计情况如表1所示。原始数据集中的每篇评论数据主要包括一个纯文本评论、一个用户总结文本和一个从1~5的总体情感评分。每个数据集都是类别数量不平衡的数据集,本文将它们构造成积极数据与消极数据同等数量的平衡数据集。本文将情感评分为1和2的数据作为消极数据,情感评分为4和5的数据作为积极数据。考虑到积极数据的数量远多于消极数据的数量,本文从积极数据中选择与消极数据同等数量的数据作为平衡数据集中的积极数据,消极数据直接作为平衡数据集中的消极数据。本文按照7∶1∶2将构造的平衡数据集划分成训练集、验证集和测试集,并且所有数据集中的积极数据和消极数据各占一半。
表1数据集的详细信息

Tab.1 Details of datasets
3.1.2实现细节
本文的模型是在PyTorch 1.7.0和Python 3.8的环境下实现的。利用GPU对模型进行训练,以加速计算过程。GPU类型为RTX 2080 Ti。
3.1.3评估指标
本文使用精确率(Precision)、召回率(Recall)、F1分数(F1)和准确率(Accuracy)四种评估指标来评估模型的性能,这些评估指标的定义公式如下:
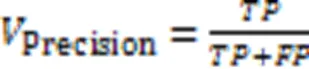
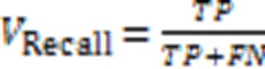
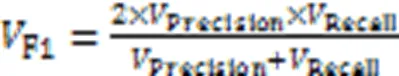
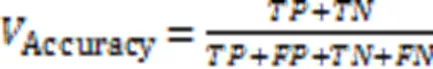
其中:表示将正样本预测为正类的数目,表示将正样本预测为负类的数目,表示将负样本预测为正类的数目,表示将负样本预测为负类的数目。
3.2 基线模型
为验证本文模型的有效性,将本文模型与以下几种基线模型进行实验比较。
1)IWV(Improved Word Vector)[19]。结合单词词性、词典方法和Word2Vec方法改进词向量,使用3个卷积层、1个最大池化层和1个用于情感分类的完全连接层组成模型结构。
2)SS-BED(Sentiment and Semantic Based Emotion Detector)[21]。在两个不同的词嵌入矩阵上应用两个平行的LSTM层学习语义和情感特征表示,利用具有隐藏层的全连接网络预测情感类别。
3)AC-BiLSTM(Attention-based BiLSTM with Convolution layer)[25]。通过卷积层提取局部特征,之后使用BiLSTM捕获前后两个方向的上下文表示。通过引入注意力机制,对隐藏层输出的信息给予不同的关注,该模型既能捕获短语的局部特征,又能捕获句子的全局语义。
4)ACR-SA(Attention-based deep model using two Channel CNN and Bi-RNN Sentiment Analysis)[28]。使用具有最大池化层的CNN提取上下文特征并降维,随后应用两个独立的Bi-RNN捕获长期依赖关系,并且将注意力机制应用于RNN层的输出,以强调每个单词的注意力水平。
5)BiGRU-Att-HCNN(BiGRU-Attention and Hybrid CNN)[29]。结合BiGRU和自注意力机制获取全局信息,并补充关键信息权重,之后使用两个并行的空洞卷积和标准卷积,以较少的参数获得多尺度特征信息,最后采用全局平均池化层替代池化层和全连接层,预测情感倾向。
6)ABCDM(Attention-based Bidirectional CNN-RNN Deep Model)[31]。该模型由两个双向独立的RNN层组合而成,用于提取前向和后向的特征,结合注意力机制对信息给予不同程度的关注,接着对每层的输出分别应用两个独立的卷积层,进行特征降维并提取位置不变的局部特征。
7)BERT-CNN(BERT with CNN semantic extraction layer)[32]。该模型首先在BERT模型的输入表示层对评论文本进行编码,之后使用CNN语义提取层提取评论文本向量的局部特征,BERT语义提取层提取评论文本向量的全局特征,语义连接层融合两个模型提取的特征。
8)MCBAT(MIX-CNN-BiLSTM-Attention-Transformer)[33]。通过CNN捕获词的固定搭配特征,通过BiLSTM获取上下文特征,利用自注意力机制判断每个词在文本中的重要性。3种特征拼接后,分类器通过全连接层获得情感分类结果。
9)TE-GRU(Transformer Encoder with Gated Recurrent Unit)[34]。模型结合Transformer的全局特征提取能力和循环模型的序列特征提取能力。Transformer编码器获得文本的全局语义信息,可以更好地处理长序列信息丢失的问题,采用GRU的最终状态作为分类的输入,输出预测的分类概率。
3.3 实验结果及分析
3.3.1对比实验
本文模型与上述基线模型在4个数据集上进行实验比较。按照内部注意力层不同的层次组合策略,本文模型分为两种,即连续层次组合模型(Our_Model_1)和间隔层次组合模型(Our_Model_2)。4个数据集上的对比实验结果如表2所示。从实验结果看,在4个评论数据集的情感分类任务中,本文的两种模型的分类效果都优于其他基线模型。
表24个数据集上的对比实验结果 单位:%

Tab.2 Comparative experimental results on four datasets unit:%
IWV通过改进词向量提高性能,SS-BED利用平行的LSTM学习语义和情感表达。与这两者相比,本文模型应用注意力机制对重要的信息给予更多的关注,提高了模型的情感表达能力。AC-BiLSTM和ACR-SA使用序列编码器提取特征并结合注意力机制提高情感分类性能;而本文模型采用了多层次注意力机制,内部注意力层并行地从不同特征子空间中学习语义特征,能够降低模型时间复杂度并捕获文本中的长期依赖关系,获取全面的文本特征信息。BERT-CNN和TE-GRU利用Transformer框架结构提取全局语义信息并结合CNN或RNN,以此提高模型的特征表达能力;然而,模型的多层结构未得到有效利用。本文模型的内部注意力层设计了两种并行层次组合策略,能够获得多层结构的丰富信息。本文模型在外部注意力层中采用了多层的注意力机制,使用总结信息对评论数据进行语义增强,与BiGRU-Att-HCNN、MCBAT等模型相比,评论特征具有更强的情感语义表达能力,因而模型的情感分类效果更好。另外,Our_Model_1的各项指标均高于Our_Model_2,这表明当模型的内部注意力层采用连续层次组合策略时拥有比间隔层次组合策略更好的性能。这可能是由于间隔层次中的低层和中层网络擅长学习低级的信息表征,而连续层次中的高层网络更能捕获高级的语义信息特征。
总体上,与基线模型中表现最好的TE-GRU相比,Our_Model_1在App、Kindle、Electronic和CD数据集上的情感分类准确率分别提高了0.65、0.75、0.63和1.01个百分点,Our_Model_2的情感分类准确率分别提高了0.36、0.34、0.58和0.66个百分点。对于F1分数,Our_Model_1相较于TE-GRU在4个数据集上分别提高了0.66、0.72、0.63和0.96个百分点,Our_Model_2在4个数据集上分别提高了0.39、0.31、0.58和0.64个百分点。这些结果表明本文模型能够很好地处理情感分类任务。
值得注意地,对于CD数据集,模型的性能提升效果最明显,这可能与该数据集中评论文本的数据长度有关。如表3所示,CD数据集中的长文本数据占比更高,平均数据长度更长,本文模型中使用多层次的内部注意力层提取文本中的长期依赖关系,而这种长期依赖关系在长的评论文本中更加明显,表明本文模型在处理长文本时具有更好的效果。
3.3.2消融实验
为了研究不同模块对模型性能的影响,对本文模型进行消融实验分析。内部注意力层和外部注意力层是本文模型的最重要的结构,因此,本节将重点分析内部注意力层和外部注意力层对模型性能的影响。
表4展示了针对内部注意力层的消融实验的实验结果,其中:Model-A为没有使用内部注意力层的模型,Model-B为仅使用最后一层内部注意力层的模型,Model-C表示本文提出的连续层次组合策略模型,Model-D表示本文提出的间隔层次组合策略模型。根据Model-A与其他3组的比较结果,应用内部注意力层的模型在4个数据集上的准确率分别提高了至少3.65、2.99、3.70和3.93个百分点,这表明内部注意力层能够很好地捕获文本内部的依赖关系,极大地提高模型的情感分类性能。
另外,通过表4中Model-B与Model-C、Model-D的对比可以发现,模型Model-C和Model-D在4个数据集上的准确率分别提高了至少0.30、0.61、0.47和0.64个百分点。上述结果表明,本文提出的内部注意力层的并行层次组合方法,包括连续层次组合模型和间隔层次组合模型,能够获得单层结构无法捕获的额外信息,比仅使用最后一层内部注意力层的模型性能更好。
为研究外部注意力层对模型性能的影响,本文在内部注意力层使用连续层次组合策略的前提下针对外部注意力层进行了实验分析。实验结果如表5所示,实验设置了有外部注意力层模型和无外部注意力层模型。通过结果可以看出,使用外部注意力层的模型性能均优于无外部注意力层的模型,在App、Kindle、Electronic和CD这4个数据集上的情感分类准确率分别提高了1.33、1.47、0.87和1.45个百分点,F1分数分别提高了1.42、1.55、0.96和1.54个百分点。这些指标的提升说明了外部注意力层能够有效地增强评论文本中的情感语义信息,有利于提高模型的情感分类性能。
表5外部注意力层的消融实验结果 单位:%

Tab.5 Ablation experimental results of external attention layer unit:%
本文模型的外部注意力层也采用了多层次的结构,注意力子层数是影响外部注意力层性能的重要因素。表6为针对不同注意力子层数的实验结果,其中,Model-N1、Model-N2、Model-N3和Model-N4分别表示外部注意力子层数分别为1~4的模型。结果显示,不同层数的外部注意力层在4个数据集上的表现不同。具体地,层数为1~2的模型在4个数据集上的表现更好,对于App和Electronic数据集,Model-N2的准确率高于Model-N1;对于Kindle和CD数据集则是Model-N1的表现更好。但总体而言,Model-N2在4个数据集上的平均表现要优于Model-N1。
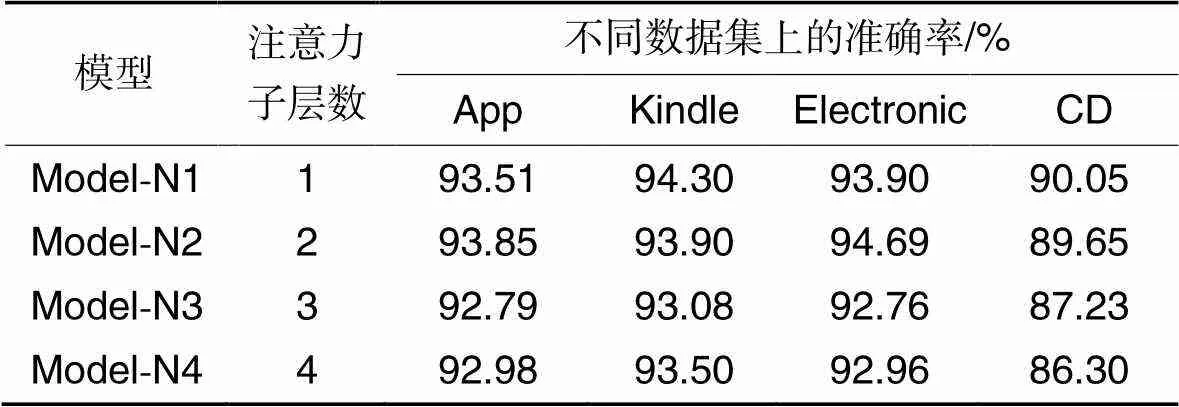
表6 外部注意力层的子层数对准确率的影响
另外可以发现,模型的性能并没有随着子层数的增加而进一步提高,当层数为3~4时,模型在各数据集上的表现均有下降,这可能是因为高层次的外部注意力为评论文本引入了过多的噪声,进而影响了模型的情感分类性能。上述结果表明,外部注意力层数能够影响模型性能,针对不同的数据集使用合适的子层数能够使模型有效地学习评论和总结之间的潜在联系,进而提升模型的性能。
4 结语
本文提出了一种基于多层次注意力的语义增强情感分类模型。首先,模型通过构建上下文感知的动态词嵌入,能够更好地对文本的上下文语义进行建模。其次,使用内部注意力层和外部注意力层生成文本的隐藏特征表示:内部注意力层采用并行的多层次结构,引入了连续层次组合和间隔层次组合两种策略,用于捕获文本内部的长期依赖关系,获得单层结构无法捕获的额外信息;外部注意力层利用总结信息增强评论文本包含的情感语义信息,外部注意力层也采用了多层次的结构,以获得更精细的评论特征表示。最后,使用分类输出层对评论特征进行情感分类。在4个亚马逊评论数据集上进行了多组实验。实验结果表明,本文模型提高了情感分类的性能。本文主要研究情感分析中的情感分类问题,未来将进一步研究在其他情感分析任务中的有效性。此外,本文模型以英语数据为基础开发,但它可以扩展到其他语言,我们接下来也会将研究方向扩展到跨语言文本情感分类,验证提出的模型能够适用于多种语言。
[1] 张公让,鲍超,王晓玉,等. 基于评论数据的文本语义挖掘与情感分析[J]. 情报科学, 2021, 39(5): 53-61.(ZHANG G R, BAO C, WANG X Y, et al. Sentiment analysis and text data mining based on reviewing data[J]. Information Science, 2021, 39(5): 53-61.)
[2] HU R, RUI L, ZENG P, et al. Text sentiment analysis: a review [C]// Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications. Piscataway: IEEE, 2018: 2283-2288.
[3] ZHANG S, WEI Z, WANG Y, et al. Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary[J]. Future Generation Computer Systems, 2018, 81: 395-403.
[4] VIJAYARAGAVAN P, PONNUSAMY R, ARAMUDHAN M. An optimal support vector machine based classification model for sentimental analysis of online product reviews[J]. Future Generation Computer Systems, 2020, 111: 234-240.
[5] WANG Y. Iteration-based naive bayes sentiment classification of microblog multimedia posts considering emoticon attributes[J]. Multimedia Tools and Applications, 2020, 79: 19151-19166.
[6] 赵宏,王乐,王伟杰. 基于BiLSTM-CNN串行混合模型的文本情感分析[J]. 计算机应用, 2020, 40(1): 16-22.(ZHAO H, WANG L, WANG W J. Text sentiment analysis based on serial hybrid model of bi-directional long short-term memory and convolutional neural network[J]. Journal of Computer Applications, 2020, 40(1): 16-22.)
[7] GAN C, FENG Q, ZHANG Z. Scalable multi-channel dilated CNN-BiLSTM model with attention mechanism for Chinese textual sentiment analysis[J]. Future Generation Computer Systems, 2021, 118: 297-309.
[8] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2016-05-19)[2022-12-22]. https://arxiv.org/pdf/1409.0473.pdf.
[9] DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [EB/OL]. (2019-05-24)[2022-08-27]. https://arxiv.org/pdf/1810.04805.pdf.
[10] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [EB/OL]. (2013-10-16)[2022-06-19]. https://arxiv.org/pdf/1310.4546.pdf.
[11] PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543.
[12] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [EB/OL]. (2018-03-02)[2022-04-09]. https://arxiv.org/pdf/1802.05365.pdf.
[13] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. (2017-06-30)[2022-07-14]. https://arxiv.org/pdf/1706.03762v4.pdf.
[14] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. (2018-06-18)[2022-07-18]. https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
[15] KHEDR A E, SALAMA S E, YASEEN HEGAZY N. Predicting stock market behavior using data mining technique and news sentiment analysis [J]. International Journal of Intelligent Systems and Applications, 2017, 9(7): 22-30.
[16] NANDAL N, TANWAR R, PRUTHI J. Machine learning based aspect level sentiment analysis for Amazon products [J]. Spatial Information Research, 2020, 28: 601-607.
[17] BUDHI G S, CHIONG R, PRANATA I, et al. Using machine learning to predict the sentiment of online reviews: a new framework for comparative analysis [J]. Archives of Computational Methods in Engineering, 2021, 28: 2543-2566.
[18] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences [EB/OL]. (2014-04-08)[2022-03-22]. https://arxiv.org/pdf/1404.2188.pdf.
[19] REZAEINIA S M, RAHMANI R, GHODSI A, et al. Sentiment analysis based on improved pre-trained word embeddings[J]. Expert Systems with Applications, 2019, 117: 139-147.
[20] ZHOU J, LU Y, DAI H-N, et al. Sentiment analysis of Chinese microblog based on stacked bidirectional LSTM [J]. IEEE Access, 2019, 7: 38856-38866.
[21] CHATTERJEE A, GUPTA U, CHINNAKOTLA M K, et al. Understanding emotions in text using deep learning and big data[J]. Computers in Human Behavior, 2019, 93: 309-317.
[22] HASSAN A, MAHMOOD A. Convolutional recurrent deep learning model for sentence classification[J]. IEEE Access, 2018, 6: 13949-13957.
[23] BATBAATAR E, LI M, RYU K H. Semantic-emotion neural network for emotion recognition from text[J]. IEEE Access, 2019, 7: 111866-111878.
[24] TAM S, SAID R B, TANRIÖVER Ö Ö. A ConvBiLSTM deep learning model-based approach for Twitter sentiment classification[J]. IEEE Access, 2021, 9: 41283-41293.
[25] LIU G, GUO J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification[J]. Neurocomputing, 2019, 337: 325-338.
[26] LI W, QI F, TANG M, et al. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification [J]. Neurocomputing, 2020, 387: 63-77.
[27] LIU F, ZHENG J, ZHENG L, et al. Combining attention-based bidirectional gated recurrent neural network and two-dimensional convolutional neural network for document-level sentiment classification [J]. Neurocomputing, 2020, 371: 39-50.
[28] KAMYAB M, LIU G, RASOOL A, et al. ACR-SA: attention-based deep model through two-channel CNN and Bi-RNN for sentiment analysis[J]. PeerJ Computer Science, 2022, 8(4): e877.
[29] ZHU Q, JIANG X, YE R. Sentiment analysis of review text based on BiGRU-attention and hybrid CNN [J]. IEEE Access, 2021, 9: 149077-149088.
[30] McAULEY J, LESKOVEC J. Hidden factors and hidden topics: understanding rating dimensions with review text [C]// Proceedings of the 7th ACM Conference on Recommender Systems. New York: ACM, 2013: 165-172.
[31] BASIRI M E, NEMATI S, ABDAR M, et al. ABCDM: an attention-based bidirectional CNN-RNN deep model for sentiment analysis[J]. Future Generation Computer Systems, 2021, 115: 279-294.
[32] DONG J, HE F, GUO Y,et al. A commodity review sentiment analysis based on BERT-CNN model [C]// Proceedings of the 2020 5th International Conference on Computer and Communication Systems. Piscataway: IEEE, 2020: 143-147.
[33] TAN Z, CHEN Z. Sentiment analysis of Chinese short text based on multiple features [C]// Proceedings of the 2nd International Conference on Computing and Data Science. New York: ACM, 2021: Article No. 65.
[34] ZHANG B, ZHOU W. Transformer-Encoder-GRU (TE-GRU) for Chinese sentiment analysis on Chinese comment text [EB/OL]. (2021-08-01)[2022-11-18]. https://arxiv.org/pdf/2108.00400.pdf.
Semantically enhanced sentiment classification model based on multi-level attention
CAO Jianle, LI Nana*
(,,300401,)
The existing text sentiment classification methods face serious challenges due to the complex semantics of natural language, the multiple sentiment polarities of words, and the long-term dependency of text. To solve these problems, a semantically enhanced sentiment classification model based on multi-level attention was proposed. Firstly, the contextualized dynamic word embedding technology was used to mine the multiple semantic information of words, and the context semantics was modeled. Secondly, the long-term dependency within the text was captured by the multi-layer parallel multi-head self-attention in the internal attention layer to obtain comprehensive text feature information. Thirdly, in the external attention layer, the summary information in the review metadata was integrated into the review features through a multi-level attention mechanism to enhance the sentiment information and semantic expression ability of the review features. Finally, the global average pooling layer and Softmax function were used to realize sentiment classification. Experimental results on four Amazon review datasets show that, compared with the best-performing TE-GRU (Transformer Encoder with Gated Recurrent Unit) in the baseline models, the proposed model improves the sentiment classification accuracy on App, Kindle, Electronic and CD datasets by at least 0.36, 0.34, 0.58 and 0.66 percentage points, which verifies that the proposed model can further improve the sentiment classification performance.
sentiment classification; Natural Language Processing (NLP); word embedding; attention mechanism; neural network
TP391.1
A
1001-9081(2023)12-3703-08
10.11772/j.issn.1001-9081.2022121894
2023⁃02⁃01;
2023⁃03⁃05;
2023⁃03⁃08。
曹建乐(1998—),男,山东潍坊人,硕士研究生,主要研究方向:文本分类、情感分析;李娜娜(1980—),女,河北保定人,副教授,博士,主要研究方向:数据挖掘、机器学习。
CAO Jianle, born in 1998, M. S. candidate. His research interests include text classification, sentiment analysis.
LI Nana, born in 1980, Ph. D., associate professor. Her research interests include data mining, machine learning.
