真实复杂场景下基于残差收缩网络的单幅图像超分辨率方法
2024-01-09李颖黄超孙成栋徐勇
李颖,黄超,孙成栋,徐勇*
真实复杂场景下基于残差收缩网络的单幅图像超分辨率方法
李颖1,2,黄超1,2,孙成栋1,2,徐勇1,2*
(1.哈尔滨工业大学(深圳) 计算机科学与技术学院,广东 深圳 518055; 2.深圳市视觉目标检测与判识重点实验室(哈尔滨工业大学(深圳)),广东 深圳 518055)(∗通信作者电子邮箱laterfall@hit.edu.cn)
真实世界中极少存在成对的高低分辨率图像对,传统的基于图像对训练模型的单幅图像超分辨率(SR)方法采用合成数据集的方式得到训练集时仅考虑了双线性下采样退化,且传统图像超分辨率方法在面向真实的未知退化图像时重建效果较差。针对上述问题,提出一种面向真实复杂场景的图像超分辨率方法。首先,采用不同焦距对景物进行拍摄并配准得到相机采集的真实高低分辨率图像对,构建一个场景多样的数据集CSR(Camera Super-Resolution dataset);其次,为了尽可能地模拟真实世界中的图像退化过程,根据退化因素参数随机化和非线性组合退化改进图像退化模型,并且结合高低分辨率图像对数据集和图像退化模型以合成训练集;最后,由于数据集中考虑了退化因素,引入残差收缩网络和U-Net改进基准模型,尽可能地减少退化因素在特征空间中的冗余信息。实验结果表明,所提方法在复杂退化条件下相较于次优BSRGAN(Blind Super-Resolution Generative Adversarial Network)方法,在RealSR和CSR测试集中PSNR指标分别提高了0.7 dB和0.14 dB,而SSIM分别提高了0.001和0.031。所提方法在复杂退化数据集上的客观指标和视觉效果均优于现有方法。
超分辨率;复杂场景;图像退化模型;残差收缩网络
0 引言
图像超分辨率(Super-Resolution, SR)方法旨在提高图像的分辨率,在医学成像、遥感勘测与视频监控等领域具有重要的研究和应用价值[1]。早期的单幅图像超分辨率方法多采用插值算法,其中较为常用的是最邻近插值、双线性插值和双三次插值[2];然而,插值算法依赖定义好的线性插值核进行重建,通常会导致重建图像丢失高频信息。
近年来,随着计算能力的提升与深度学习的发展,研究者将深度学习引入图像超分辨率领域并且取得了比传统方法更好的表现[3]。由于真实世界中很少存在成对数据集,现有的图像超分辨率方法通常采用高分辨率图像和双线性下采样后合成的低分辨率图像作为成对的数据训练模型。Dong等[4]首次提出了基于卷积神经网络的图像超分辨率网络SRCNN(Super-Resolution Convolutional Neural Network),SRCNN模型简单,只需要3个卷积层,但是加深网络会导致模型难以收敛。Dong等[5]随后提出了速度更快、重建效果更好的网络模型结构FSRCNN(Fast SRCNN)。为了解决网络加深导致感受野不足的问题,Kim等[6]利用递归神经网络设计了DRCN(Deeply-Recursive Convolutional Network),递归神经网络避免了网络加深导致的梯度爆炸和消失,最终通过加深网络层数的方式改善图像超分辨率的重建效果。VDSR(Very Deep Super-Resolution)方法[7]和EDSR(Enhanced Deep Super-Resolution)方法[8]在网络模型中引入了残差连接[9],并进一步加深网络以弥补感受野的不足。受生成对抗网络(Generative Adversarial Network, GAN)的启发,Ledig等[10]首次提出基于GAN的网络模型SRGAN(Super-Resolution GAN),并提出了更关注图像真实感的感知损失函数,增强了重建图像的真实感。ESRGAN(Enhanced SRGAN)模型[11]使用残差连接与密集连接改进生成网络,并且进一步优化了损失函数,取得了更好的重建效果。
尽管现有超分辨率方法在已知退化模型的超分任务上取得了很好的进展,但是仅基于双三次下采样方法合成的数据集训练的模型对于真实世界中未知退化的图像效果不佳。因此,研究者重点关注盲图像的超分辨率方法,即面向退化未知的真实图像的超分辨率方法[12]。一方面,SRMD(SR network for Multiple Degradations)方法[13]将退化的关键因素作为额外输入,进而增强网络的泛化能力。Wei等[14]提出的DASR (Domain-distance Aware SR)方法训练了一个退化预测网络用于预测低分辨率图像的退化,并将预测的退化融入超分辨率重建网络中用于减小退化带来的影响。另一方面,RWSR(Real-World SR)方法[15]根据低分辨率图像数据集预测图像的退化参数,并根据预测参数构建图像退化模型合成额外数据集进行模型训练。然而在上述方法中,当输入或预测的退化与输入图像不一致时,重建效果急剧降低。Zhang等[16]提出的BSRGAN(Blind SRGAN)方法通过退化模型的参数随机化和扩充退化过程设计图像退化模型,并使用模拟退化后的数据集训练模型,在训练的过程中,模型隐式地学习图像的复杂退化过程;然而,BSRGAN方法只是沿用了传统超分辨率重建网络,没有在网络中减小退化带来的影响。为了解决上述不足,本文提出面向真实复杂场景的基于残差收缩网络的单幅图像超分辨率方法。
本文的主要工作如下:
首先,针对当前仍然缺乏真实的高低分辨率图像对数据集的问题,本文实地采集了一个高低分辨率图像对数据集CSR(Camera SR dataset)。具体地,通过固定相机位置、镜头角度与相机参数,使用镜头的不同焦距拍摄了同一景物的两幅图像,对两幅图像中的同一景物配准后得到高低分辨率图像对。该数据集共包含461对高低分辨率图像对,场景多样且纹理丰富。
其次,针对图像在存储和传输等操作可能发生的退化,使用了一种非线性图像复杂退化模型模拟图像的真实退化过程。该模型由随机参数的模糊、下采样和噪声这3个关键因素组成,并且使用两次非线性组合退化策略设计退化因素的次序。
最后,针对高低分辨率图像对和图像退化带来的影响,训练数据集以CSR和图像退化模型结合的方式生成。为了减小图像中退化因素对重建效果的影响,首次引入信号处理领域的残差收缩网络改进基准模型,最终设计了一种面向真实复杂场景下基于残差收缩网络的单幅图像超分辨率方法。实验结果表明,本文方法在复杂退化的数据集上取得了最优的超分辨率重建效果。
1 相关研究
1.1 残差收缩网络
在信号处理领域,信号通常充斥着多种来源的、各不相同的噪声或者冗余信息,而噪声或冗余信息会使网络模型的识别结果偏离预期,因此,如果能在卷积网络中消除这部分噪声或冗余信息,将大幅提升网络模型的能力;然而,对于不同的样本,它们的噪声来源不同,必须在网络中自适应地处理。为解决这一问题,Zhao等[17]提出了基于可学习软阈值化函数的残差收缩网络,它的核心思想为:对于特征图中的各个通道,可学习地生成通道阈值,使用通道阈值软阈值化特征图中的通道,达到减少噪声和冗余信息的目的。软阈值化函数见式(1):
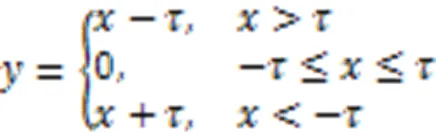
1.2 超分辨率重建评价指标
峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)以分贝作为基本单位,被广泛地应用于重建领域中评价图像的像素级失真程度,计算见式(2):
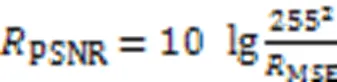
2 相机图像对数据集采集
现有的真实高低分辨率图像对数据集主要有City100[18]和RealSR[19],但仍存在一定的局限性:City100使用手机拍摄,通过调整手机与贺卡之间的距离拍摄了同一贺卡的高低分辨率图像对,共采集了100对城市建筑贺卡的图像对;RealSR使用Canon相机,通过调整相机镜头焦距的方式采集了200对图像对,其中仍然包含了部分贺卡,并且场景比较单一。为了扩充真实的高低分辨率图像对数据集,本文实景采集了场景丰富多样的461对图像对,完成图像对齐后得到高低分辨率图像对数据集。
2.1 图像拍摄
本文图像拍摄任务选址为深圳,相机型号为Canon EOS M200,相机镜头焦距为18~55 mm,相机分辨率固定为3 456×2 304,拍摄采用的长焦距与短焦距分别为55 mm和28 mm。为了避免手持相机的镜头抖动,使用相机三脚架固定相机,在固定位置和镜头角度的情况下调整焦距拍摄得到同一景物的两幅图像。由于焦距的不同,这一景物在两幅图像中的占比有所差异,焦距越长,视角更广阔,景物成像更大,因此这一景物在两幅相同分辨率的图像中的分辨率不同。拍摄所得图像对的一个实例如图2所示,图2(a)和图2(b)两幅图像分辨率一致。可以看到图2(a)中的矩形框选中区域与左图景物一致,但分辨率较低。利用以上原理,即可得到相机在不同镜头焦距下的同一景物图像对。考虑到景物的多样性以及环境变化的影响,本次拍摄的图像对中的景物包括但不限于家居用品、现代建筑、植物、广告牌、水果和贺卡;此外,拍摄所得的图像对数据集中仍有部分存在物体移动、模糊的情况,对不符合要求的图像进行了丢弃。
2.2 图像配准
在收集上述两种镜头焦距下所得的同一景物图像对后,需要将图像中的景物配准后才能作为超分任务中的高低分辨率图像对。首先,用尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)算法计算两幅图像中的关键点,具体步骤为:构建两幅图像的高斯差分金字塔,减少图像低频信息,凸显图像的特征;为了保证关键点的尺度不变性,筛选高斯差分金字塔中的极值点作为关键点;为了保证关键点的旋转不变性,通过关键点在邻域内的方向信息计算关键点的主方向,得到关键点并以向量表示,它包含了位置、尺度以及方向信息。其次,根据关键点的信息匹配图2中两幅图像中的关键点,建立景物中配对特征的对应关系,拍摄图像对的关键点匹配结果如图3所示。

图2 相机以不同焦距拍摄的图像对示例

图3 SIFT算法关键点匹配结果
根据SIFT算法关键点的匹配结果将短焦距拍摄图像进行变换使之与右图配准,即可得到同一景物的两幅分辨率不同的图像。由于相机镜头焦距的不同导致曝光程度不同,两幅图像的色彩也有区别,因此需要校正两幅图像的色彩。本文使用OpenCV中基于标准色卡的颜色校正方法对两幅图像进行色彩校正。最终获得同一景物的高低分辨率图像对,示例如图4所示,由图4(a)和图4(b)中右下角矩形区域的放大图像可以看到两幅图像在分辨率上的差异。最后,由于图像配准存在严重模糊和配准不齐等失败案例,故手工完成图像对的筛选工作。重复以上步骤,最终获得了包含461对场景多样、纹理丰富的真实高低分辨率图像对的CSR。
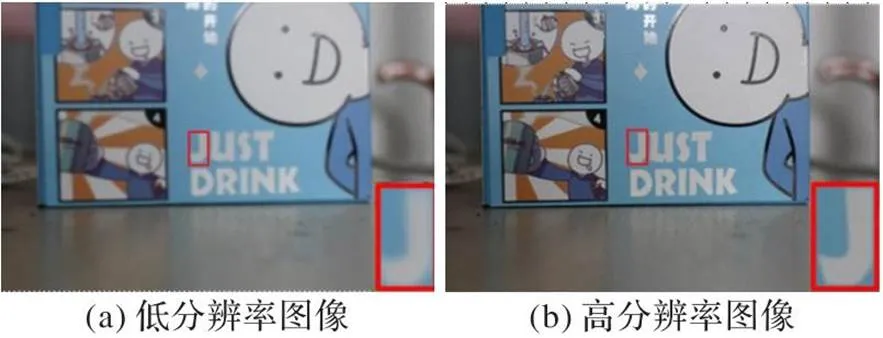
图4 高低分辨率图像对示例
3 基于残差收缩网络的生成对抗网络模型
3.1 图像退化模型
图像退化模型通常包含模糊、降采样和噪声这3个关键因素,线性退化模型通常表达为式(4):

传统的退化模型较简单且线性,现有工作仅使用双三次下采样或者固定参数的线性退化模型对高分辨率图像进行退化以得到成对图像对,难以模拟真实低分辨率图像的退化过程[20];然而,在真实世界中,一幅图像在经过压缩、传输和编辑等操作后,它的退化可能是多重且非线性的。具体地,一幅来自网络的图像在拍摄过程中会产生相机模糊与传感器噪声,在图像压缩过程会引入压缩噪声,在上传至媒体软件过程中会引入传输噪声,因此,现有的退化模型难以完全模拟复杂的图像退化过程。为了解决上述问题,受文献[16,21]的启发,本文采用了非线性组合退化的复杂图像退化模型,并将退化模型的模糊、下采样和噪声这3个关键因素的参数随机化。


下采样操作在最邻近下采样、双线性下采样和双三次下采样方法中随机选择。

此外,非线性组合退化由高斯模糊、下采样、高斯噪声和泊松噪声随机次序组合而成,考虑到JPEG压缩的常用性,在非线性组合退化的最后都加入1个JPEG压缩。由于噪声的出现频率不同,将非线性组合退化中高斯噪声和泊松噪声的出现概率分别设置为0.8和0.2。
最终,本文的图像退化模型由两次非线性组合退化组成,由于两次连续的非线性组合退化过程过于复杂,发生的概率较小,因此将第二次非线性组合退化的概率设置为0.2。图像复杂退化模型如图5所示。
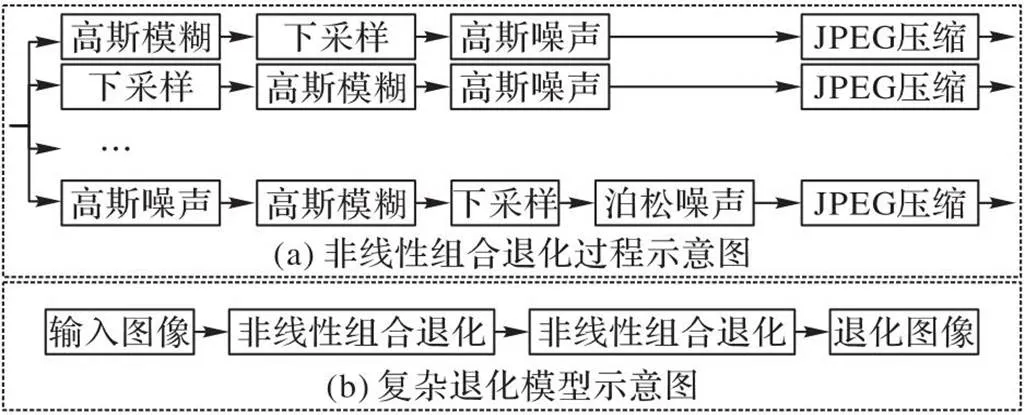
图5 图像复杂退化模型
值得注意的是,两次非线性组合退化中退化因素的参数不相关。尽管复杂退化模型不能完全模拟真实世界的退化空间,但两次非线性组合退化策略和各种退化因素中参数的随机化能够模拟绝大多数的图像退化过程。
3.2 网络模型改进点
3.2.1合成数据集
在基于成对训练的单幅图像超分辨率方法中,一种思路是使用相机拍摄的成对数据集,为了获得场景多样的成对数据集,本文实景拍摄了相机成对数据集CSR;另一种思路是仅采用双三次下采样或者线性退化模型合成成对的高低分辨率图像对数据集,但是该思路较简单导致难以模拟真实世界中的退化过程,因此本文提出了更贴近真实图像退化过程的图像复杂退化模型。
为了充分考虑相机拍摄在高低分辨率图像对之间的差异和图像在真实世界中的退化过程,本文在数据集方面首次以真实相机数据集CSR与图像复杂退化模型结合的方式合成数据集,具体的做法是:对于一对相机采集的高低分辨率图像对,对相机采集的低分辨率图像进一步地使用图像复杂退化模型模拟在真实世界中发生的退化。
3.2.2基于残差收缩的特征提取
本文以ESRGAN方法的模型[11]作为基准模型,ESRGAN中仅使用双线性下采样的方式合成数据集,对于真实世界中具有噪声和模糊的图像的重建效果较差。为了从数据集层面提升网络的泛化能力,本文提出了结合相机数据集与退化模型的合成数据集,然而数据集的复杂性也给网络模型带来了新的挑战,模糊和噪声等退化因素在特征空间中的表达将直接影响最终的超分辨率重建效果,因此本文针对性地改进了ESRGAN。
为了抑制模糊和噪声等冗余信息在特征空间中的表达,本文引入残差收缩网络和密集连接,提出了残差密集收缩网络(Residual Shrinkage Dense Network, RSDN)作为基本特征提取网络。此外,在RSDN的基础上,本文提出了生成网络中特征提取的结构——残差密集收缩块(Residual Shrinkage Dense Block, RSDB)。
3.2.3基于U-Net的判别网络
受文献[21-22]的启发,本文基于U-Net模型[23]作为判别网络。判别的目标是评价输入的超分重建图像是否与真实的高分辨率图像一致。ESRGAN以VGG模型[24]输出的二分类结果整体性地评价超分辨率图像,而VGG模型的评价只考虑了全局相似度,实际上超分重建图像存在部分区域重建表现好而其他区域表现差的情况,VGG模型输出的二分类结果难以体现,导致生成网络从判别网络接收的评价信息不够具体,限制了生成器的优化。U-Net通过多个卷积层和下采样的组合逐步获得输入图像的深层特征,再通过多个卷积层和上采样的组合提高特征的分辨率。此外,使用跳跃连接的方式融合各层的特征,最终使得输出的多尺度特征图的分辨率与输入图像保持一致,特征图上的每个点值代表了对输入图像对应像素点的评价。相较于VGG模型,U-Net模型对特征进行了多尺度融合,结果更可靠,并且提供了像素级的评价。
3.3 网络模型结构
本文使用的超分辨率倍数为4,提出了名为CSRGAN(Complex SRGAN)的模型,它的网络结构如图6所示。每个卷积层的核大小和步长分别为3和1,卷积层的输出通道数标注在图像下方。
在生成网络中,对于输入低分辨率图像,通过复杂退化模型生成退化的低分辨率图像,退化图像在特征提取模块中通过1个卷积层生成图像的浅层特征,浅层特征继续使用23个RSDB块和1个卷积层生成图像的深层特征,维度与浅层特征一致。通过跳跃连接将浅层特征和深层特征以相加的形式融合作为图像的最终特征。获得图像的特征后进一步使用图像重建模块将特征映射为超分辨率图像,本文的图像重建模块为亚像素卷积上采样方法Pixel Shuffle[8]。

图6 CSRGAN模型的结构
在判别网络中,对重建的超分辨率图像与原始高分辨率图像的相似程度进行评价。传统GAN采用的VGG模型只能从整体评价,无法具体地评价每个像素点的相似程度。因此,本文使用基于U-Net的判别网络,在卷积层中通过填充的方式使输出特征的尺寸与输入保持一致,最终使U-Net输出特征图的尺寸与原始图像保持一致。其中:用于特征下采样的最大池化层(Max Pool)的核大小为2×2;用于特征上采样的卷积层(Up Conv)是使得特征的宽度和高度均扩大2倍的转置卷积。最终,U-Net输出的特征图维度与输入图像的维度保持一致,特征图上每个像素点值代表了输入图像对应位置像素的评价。


图7 RSDN的结构

图8 RSDB的结构
3.4 损失函数

像素损失使用L1损失,通过将与逐像素进行对比的结果定义,计算如式(7):

感知损失认为两幅相似的图像在同一模型中提取的特征空间仍然保持相似性,逐一在VGG模型每一层的每个卷积输出的特征图上度量每个点值的均方误差,计算如式(8):
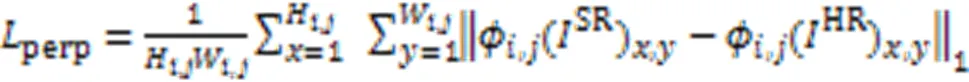
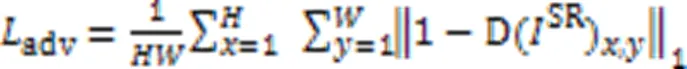
4 实验与结果分析
4.1 实验环境及配置
本文所有实验的实验环境及配置如下:GPU为Nvidia GTX 3090,CUDA版本为11.3,Python版本为3.8.12且PyTorch版本为1.10.1,使用重建评价指标PSNR和SSIM客观评价超分辨率实验结果。
4.2 CSRGAN实验结果及分析
为了验证CSRGAN的有效性,将它与以下模型在相同测试集上进行实验。对比模型包含RRDB(Residual in Residual Dense Block)[11]、ESRGAN[11]、EDSR[8]、RWSR-DF2K(Real-World Super Resolution-DIV2K and Flickr2K)[16]、SRMD[13]、DASR[14]和BSRGAN[16]。
4.2.1预处理及训练细节
CSRGAN中网络模型使用的训练集结合CSR相机数据集和图像复杂退化模型生成,具体地,对于CSR中的一对高低分辨率图像对,在高分辨率图像中随机裁剪一个288×288的图像块作为参考图像;在低分辨率图像对应位置上裁剪一个72×72的图像块,并用图像复杂退化模型模拟退化得到的图像块作为模型的输入。
在测试集方面,由于本文方法面向真实的复杂场景,因此选择了不同退化条件下的相机采集的RealSR测试集和CSR测试集,退化条件包含D1、D2和CD,其中D1由随机参数的高斯模糊、双线性下采样和随机参数的高斯噪声顺序组成,D2由D1中的退化因素随机顺序组成,CD即为本文设计的图像退化模型。
在训练的过程中,Batch Size统一设置为16,优化器采用Adam优化器[26],学习率设置为10-4,学习衰减率设置为0.999。此外,由于GAN结构在训练的过程存在难以收敛的问题,为了避免CSRGAN在早期训练中陷入局部最优导致难以获得最佳效果,第一步仅使用L1像素损失预训练一个生成网络,尽可能地提高预训练生成网络的超分辨率重建性能。由于图像的像素损失会导致图像存在一定的平滑,所以第二步加载预训练生成网络作为CSRGAN中的生成网络训练CSRGAN,此时使用的损失函数为引入感知损失和对抗损失的生成网络损失,最终在GAN中训练得到最终的CSRGAN模型。
4.2.2实验结果及分析
各模型在不同退化条件的测试集中超分辨率重建指标对比见表1,CSRGAN在不同退化的两个测试集上基本都取得了最高的PSNR和SSIM,仅在CD退化条件下的RealSR测试集中的SSIM评价指标略低于BSRGAN。比较各模型在3种不同退化条件下的平均PSNR和SSIM指标,相较于次优BSRGAN,CSRGAN模型平均平均PSNR指标分别提高了0.7 dB和0.14 dB,平均SSIM指标分别提高了0.001和0.031。
各模型在不同退化条件下的超分辨率视觉效果分别如图9所示。
表1各模型在RealSR和CSR测试集上的重建指标对比

Tab.1 Comparison of reconstruction indicators of different models on RealSR and CSR test sets

图9 各模型在不同退化条件下的视觉效果对比
RRDB、ESRGAN和EDSR模型仅使用了双线性下采样对图像进行模拟退化,对于未知退化条件下的超分辨率任务不具备泛化能力,生成的超分辨率图像中仍然存在大量的噪声和模糊。RWSR-DF2K根据低分辨率图像集估计图像的高斯模糊和噪声,然而图像的退化过程复杂多样,当退化参数不匹配时,重建效果较差。SRMD模型手动将模糊核和噪声作为超分辨率重建网络的额外输入,然而当退化因素与图像退化因素不一致时,重建效果仍然较差。DASR模型训练了一个退化预测网络用于预测低分辨率图像的退化表达,并将预测的退化表达融入超分辨率重建网络中以缩减退化因素的表达;然而低分辨率图像的退化是多样的且难以预测的,因此在复杂场景下的重建质量难以保证。BSRGAN模型对图像退化模型进行了改进用于合成图像对数据集,从训练数据集的角度增强了复杂场景下的超分辨率效果;然而只是沿用了基准的超分辨率网络,没有在网络结构中减小图像退化因素带来的影响,虽然超分辨率视觉效果相较于以前的模型好,但仍存在一定的伪影和色差问题,图像的真实感较差。最后,CSRGAN模型一方面将高低分辨率图像对数据集CSR与改进的图像退化模型结合生成数据集,从数据集方面提升网络模型在真实场景下的泛化能力;另一方面为了减弱退化因素带来的影响,引入了残差收缩网络和U-Net改进模型。实验结果表明,CSRGAN模型在视觉和客观指标上均取得了较好的效果。
4.2.3消融实验结果及分析
为了验证3.2节提出的改进点的有效性,在相同的实验配置下依次加入改进点设计对比实验,其中:M1在基准模型ESRGAN的基础上引入了成对数据集在图像退化模型下合成的退化数据集进行训练;M2则在M1的基础上引入了残差收缩网络提取特征;CSRGAN模型则是在M2的基础上进一步引入了U-Net作为判别网络。
各模型在不同退化条件的测试集中超分辨率重建指标对比见表2。M1得益于增强的模拟退化数据集,已经大幅提升了不同退化条件下的重建质量指标PSNR和SSIM。M2引入了残差收缩网络减少特征提取过程中的冗余信息,重建质量指标相较于M1更高。
表2在测试集RealSR和CSR上的消融实验结果对比

Tab.2 Comparison of ablation experimental results on RealSR and CSR test sets
最后,CSRGAN模型在M2的基础上进一步引入了U-Net作为判别网络,使得判别网络可以为生成网络的优化提供像素级的评价,因此在整体上得到了较高的重建质量指标。
各模型在不同退化条件D1、D2和CD合成的测试集中的超分辨率视觉效果对比分别如图10所示。从图10中可以看到,M1的重建视觉效果在D1退化条件中出现了图像细节纹理丢失,而在图D2和图CD退化条件中仍然存在大量噪声,因为M1尽管依赖于模拟退化的合成数据集进行训练,但受限于特征提取的过程中没有甄别特征中的冗余信息,导致部分纹理特征的丢失和噪声的保留。M2引入了残差收缩网络改进特征提取,重建视觉效果优于M1,重建图像的纹理更清晰且残余的噪声更少。最后,CSRGAN模型进一步引入了U-Net作为判别网络,原始的VGG仅能从全局去评价重建图像的质量,而判别网络U-Net则是对每一个像素点进行评价,为生成网络的优化提供了更精确的信息,因此在图像的视觉质量上取得了最佳的效果。本文提出的各个改进点的引入都进一步提升了图像超分辨率重建的质量指标和视觉效果,验证了各个改进点的有效性。

图10 不同退化条件下的消融实验视觉效果对比
5 结语
本文提出一种面向真实复杂场景的单幅图像超分辨率方法。针对当前缺少真实高低分辨率图像对数据集的问题,构建了一个相机拍摄的高低分辨率图像对数据集,它具有场景多样且纹理丰富的特点;针对真实低分辨率图像中的未知退化问题,采用退化关键因素的参数随机化以及非线性组合退化策略改进图像退化模型,尽可能地模拟图像在传输和存储等过程中可能发生的退化;为了减弱低分辨率图像中的退化因素在特征空间中的表达,引入残差收缩网络优化基准网络模型,进一步改善了超分辨率重建效果。实验结果表明,本文提出的方法在模拟退化的数据集上的性能优于当前方法。下一步将在不同的图像领域(如医学图像、遥感成像等领域)中构建更符合实际的图像退化模型与设计适应的超分辨率网络模型,最大限度地提升真实图像的超分辨率效果。
[1] 王一宁,赵青杉,秦品乐,等. 基于轻量密集神经网络的医学图像超分辨率重建算法[J]. 计算机应用, 2022, 42(8): 2586-2592.(WANG Y N, ZHAO Q S, QIN P L, et al. Super-resolution reconstruction algorithm of medical image based on lightweight dense neural network[J]. Journal of Computer Applications, 2022, 42(8): 2586-2592.)
[2] KEYS R. Bicubic interpolation[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(1): 1153-1160.
[3] 王汇丰,徐岩,魏一铭,等. 基于并联卷积与残差网络的图像超分辨率重建[J]. 计算机应用, 2022, 42(5): 1570-1576.(WANG H F, XU Y, WEI Y M, et al. Image super-resolution reconstruction based on parallel convolution and residual network[J]. Journal of Computer Applications, 2022, 42(5): 1570-1576.)
[4] DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 184-199.
[5] DONG C, LOY C C, TANG X, et al. Accelerating the super-resolution convolutional neural network[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 391- 407.
[6] KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1637-1645.
[7] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1646-1654.
[8] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1132-1140.
[9] TARG S, ALMEIDA D, LYMAN K. ResNet in ResNet: generalizing residual architectures [EB/OL]. (2016-03-25)[2021-12-12]. https://arxiv.org/pdf/1603.08029.pdf.
[10] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 105-114.
[11] WANG X, YU K, WU S, et al. ESRGAN: enhanced super-resolution generative adversarial networks [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11133. Cham: Springer, 2019: 63-79.
[12] LIU A, LIU Y, GU J, et al. Blind image super-resolution: a survey and beyond [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 5461-5480.
[13] ZHANG K, ZUO W, ZHANG L. Learning a single convolutional super-resolution network for multiple degradations[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3262-3271.
[14] WEI Y, GU S, LI Y, et al. Unsupervised real-world image super resolution via domain-distance aware training [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13380-13389.
[15] JI X, CAO Y, TAI Y, et al. Real-world super-resolution via kernel estimation and noise injection [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1914-1923.
[16] ZHANG K, LIANG J, VAN GOOL L, et al. Designing a practical degradation model for deep blind image super-resolution[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 4771-4780.
[17] ZHAO M, ZHONG S, FU X, et al. Deep residual shrinkage networks for fault diagnosis [J]. IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
[18] CHEN C, XIONG Z, TIAN X, et al. Camera lens super-resolution[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1652-1660.
[19] CAI J, ZENG H, YONG H, et al. Toward real-world single image super-resolution: a new benchmark and a new model[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3086-3095.
[20] 刘丛,王亚新. 基于双并行残差网络的遥感图像超分辨率重建[J]. 模式识别与人工智能, 2021, 34(8): 760-767.(LIU C, WANG Y X. Remote sensing image super-resolution reconstruction based on dual-parallel residual network [J]. Pattern Recognition and Artificial Intelligence, 2021, 34(8): 760-767.)
[21] WANG X, XIE L, DONG C, et al. Real-ESRGAN: training real-world blind super-resolution with pure synthetic data[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2021:1905-1914.
[22] SCHÖNFELD E, SCHIELE B, KHOREVA A. A U-Net based discriminator for generative adversarial networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8204-8213.
[23] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
[24] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2021-12-12].https://arxiv.org/pdf/1409.1556.pdf.
[25] JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 694-711.
[26] AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1122-1131.
Single image super-resolution method based on residual shrinkage network in real complex scenes
LI Ying1,2, HUANG Chao1,2, SUN Chengdong1,2, XU Yong1,2*
(1,,,518055,;2(,),518055,)
There are very few paired high and low resolution images in the real world. The traditional single image Super-Resolution (SR) methods typically use pairs of high-resolution and low-resolution images to train models, but these methods use the way of synthetizing dataset to obtain training set, which only consider bilinear downsampling as image degradation process. However, the image degradation process in the real word is complex and diverse, and traditional image super-resolution methods have poor reconstruction performance when facing real unknown degraded images. Aiming at those problems, a single image super-resolution method was proposed for real complex scenes. Firstly, high- and low-resolution images were captured by the camera with different focal lengths, and these images were registered as image pairs to form a dataset CSR(Camera Super-Resolution dataset)of various scenes. Secondly, to simulate the image degradation process in the real world as much as possible, the image degradation model was improved by the parameter randomization of degradation factors and the nonlinear combination degradation. Besides, the dataset of high- and low-resolution image pairs and the image degradation model were combined to synthetize training set. Finally, as the degradation factors were considered in the dataset, residual shrinkage network and U-Net were embedded into the benchmark model to reduce the redundant information caused by degradation factors in the feature space as much as possible. Experimental results indicate that compared with the BSRGAN (Blind Super-Resolution Generative Adversarial Network)method, under complex degradation conditions, the proposed method improves the PSNR by 0.7 dB and 0.14 dB, and improves SSIM by 0.001 and 0.031 respectively on the RealSR and CSR test sets. The proposed method has better objective indicators and visual effect than the existing methods on complex degradation datasets.
Super-Resolution (SR); complex scene; image degradation model; residual shrinkage network
This work is partially supported by National Natural Science Foundation of China (61876051), Project of Shenzhen Science and Technology Innovation Committee (JSGG20220831104402004).
LI Ying, born in 1998, M. S. candidate. His research interests include computer vision, super-resolution.
HUANG Chao, born in 1991, Ph. D. candidate. His research interests include pattern recognition, deep learning.
SUN Chengdong, born in 2002. His research interests include computer vision, super-resolution.
XU Yong, born in 1972, Ph.D., professor. His research interests include pattern recognition, computer vision, deep learning, video analysis.
TP391.4
A
1001-9081(2023)12-3903-08
10.11772/j.issn.1001-9081.2022111697
2022⁃11⁃24;
2023⁃07⁃06;
2023⁃07⁃07。
国家自然科学基金资助项目(61876051);深圳市科创委资助项目(JSGG20220831104402004)。
李颖(1998—),男,四川成都人,硕士研究生,主要研究方向:计算机视觉、超分辨率;黄超(1991—),男,河南信阳人,博士研究生,主要研究方向:模式识别、深度学习;孙成栋(2002—),男,湖北黄冈人,主要研究方向:计算机视觉、超分辨率;徐勇(1972—),男,广东深圳人,教授,博士,CCF会员,主要研究方向:模式识别、计算机视觉、深度学习、视频分析。
