融合局部结构学习的大规模子空间聚类算法
2024-01-09任奇泽贾洪杰陈东宇
任奇泽,贾洪杰,陈东宇
融合局部结构学习的大规模子空间聚类算法
任奇泽,贾洪杰*,陈东宇
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)(∗通信作者电子邮箱jiahj@ujs.edu.cn)
常规的大规模子空间聚类算法在计算锚点亲和矩阵时忽略了数据之间普遍存在的局部结构,且在计算拉普拉斯(Laplacian)矩阵的近似特征向量时存在较大误差,不利于数据聚类。针对上述问题,提出一种融合局部结构学习的大规模子空间聚类算法(LLSC)。所提算法将局部结构学习嵌入锚点亲和矩阵的学习,从而能够综合利用全局和局部信息挖掘数据的子空间结构;此外,受非负矩阵分解(NMF)的启发,设计一种迭代优化方法以简化锚点亲和矩阵的求解过程;其次,根据Nyström近似方法建立锚点亲和矩阵与Laplacian矩阵的数学联系,并改进Laplacian矩阵特征向量的计算方法以提升聚类性能。相较于LMVSC(Large-scale Multi-View Subspace Clustering)、SLSR(Scalable Least Square Regression)、LSC-k(Landmark-based Spectral Clustering using k-means)和k-FSC(k-Factorization Subspace Clustering),LLSC在4个广泛使用的大规模数据集上显示出明显的提升,其中,在Pokerhand数据集上,LLSC的准确率比k-FSC高28.18个百分点,验证了LLSC的有效性。
子空间聚类;局部结构学习;非负矩阵分解;大规模聚类;低秩近似
0 引言
聚类作为一种无监督数据分析工具,一直是机器学习和数据挖掘领域中非常重要的研究课题。随着信息技术的不断发展,高维数据无处不在。高维数据具有低维的子空间结构,因此传统聚类算法在处理高维数据时性能较差,使用相似性度量方法的效率低下,可视化和理解输入变得困难。为解决上述问题,通常使用降维技术,但该技术会引发“维度诅咒”,即随着维度增加,所有子空间的完整枚举变得难以处理;其次,数据的多个维度之间可能不相关,在有噪声的数据中可能屏蔽现有的聚类。因此,子空间聚类作为一个基本的问题,已经成为了热门话题。近些年,很多经典的子空间聚类算法被提出,在这些算法中基于稀疏自表示模型的算法[1]、基于低秩近似的算法[2]都取得了成就。稀疏自表示模型发现了数据的稀疏表示,低秩近似发现了子空间低秩的结构。这些子空间算法在各大领域中被广泛应用,如信息安全[3]、图像聚类[4]、大数据分析和图像检测[5]等。研究人员在这些领域利用子空间聚类实现检测数据、识别图片和过滤噪声样本等功能。
现有的子空间聚类算法需要精确估计底层子空间的维度,会提高子空间聚类计算复杂度,多种情况下无法使用;此外,相关的优化问题都是非凸的,良好的初始化对找到最优解非常重要[6]。现有的子空间聚类通常使用谱聚类算法解决问题:通过观测样本得到一个相似矩阵,然后对这个矩阵进行谱聚类获得最终的聚类结果。谱聚类是一种基于图划分的聚类算法,能够处理具有复杂非线性结构的真实数据,在非凸模式和线性不可分簇中表现良好;但是谱聚类需要计算拉普拉斯(Laplacian)矩阵的特征向量,内存需求非常大,计算复杂度也很高,面对大规模数据时适用性受限。He等[7]设计一种大规模的谱聚类,通过使用随机傅里叶特征显式地表示核空间中的数据。Kang等[8]提出一种具有线性复杂度的大规模子空间聚类(Large-Scale Subspace Clustering,LS2C)算法处理大规模数据。这些算法通过计算并使用较小的锚点亲和矩阵的特征向量逼近Laplacian矩阵的特征向量,不仅规避了大规模构图的问题,而且在避免计算复杂度过高的同时降低了聚类复杂度。
虽然现有的LS2C已经取得较大成果,但它通常忽略局部相似性的重要性。在变换后的低维空间中,保持高维数据的内在信息非常重要,使用单一的特征无法完全表示数据底层结构,而全局和局部的特征都是重要的。局部的特征对近邻大小敏感,不同子空间交点周边的点也具有较强的捕获能力,因为它依赖成对距离的相似矩阵;而且数据的局部几何结构可被视作数据相关的正则化,有助于避免过拟合[9]。
此外,已有的LS2C算法将锚点亲和矩阵优化问题视作凸二次规划问题,但很多凸二次规划求解方法不能始终满足锚点亲和矩阵的非负限制。非负矩阵分解(Nonnegative Matrix Factorization, NMF)中使用的迭代优化方法可以帮助解决锚点亲和矩阵的优化问题[10]。NMF将原始的非负数据矩阵分解为非负基矩阵和非负系数矩阵,使它们的乘积能够最接近原始非负数据矩阵。而非负拉格朗日松弛[11]作为一种受NMF启发产生的非负松弛方法,通过将非负约束吸收到目标函数,保证锚点亲和矩阵的计算过程是非负的。
LS2C获得锚点亲和矩阵后,通常需要计算Laplacian矩阵的特征向量,用于聚类分析。已有的LS2C使用学习的锚点亲和矩阵构造了一个矩阵逼近Laplacian矩阵;但该方法无法保证最佳的低秩近似,也难以有效地捕获子空间结构。Fowlkes等[12]采用Nyström近似方法[13],用较小的样本子矩阵的特征向量逼近较大的原Laplacian矩阵的特征向量。Nyström近似方法可以保证最佳的低秩近似,且计算复杂度较低。
综上,已有的LS2C算法的缺点包括:1)只考虑全局性的结构,忽略数据之间的普遍存在的局部结构;2)锚点矩阵的优化过于昂贵;3)使用亲和矩阵构造的一个矩阵逼近Laplacian矩阵,无法保证最佳的低秩近似,难以有效地捕获子空间结构。针对以上缺点,本文提出一种融合局部结构学习的LS2C算法(LS2C algorithm with Local structure learning, LLSC)。
本文的主要工作如下:
1)在LS2C的目标函数中加入局部结构项,使学习的锚点亲和矩阵能同时保留数据的局部特征和全局特征。
2)利用非负拉格朗日松弛[11]的特性,设计了一种类似于NMF的迭代更新规则优化目标函数。利用非负拉格朗日松弛计算锚点亲和矩阵,可以更有效地捕获子空间结构,从而反映数据之间的真实联系。
3)引入Nyström近似方法求解Laplacian矩阵的特征向量,保证最佳的低秩近似,改善聚类结果。
4)通过在有挑战的数据集上进行实验,验证了所提算法的有效性。
1 相关工作
1.1 LS2C
子空间聚类因良好的性能而得到了广泛的研究[14],被众多的领域关注。子空间聚类的重点是计算表示系数矩阵。从高维数据中搜寻一个最具有代表性的低维子空间一直都是机器学习和计算机视觉领域的一个重要课题。子空间聚类作为一种在不同子空间发现聚类的技术,在信息采集和数据处理技术中得到广泛应用。随着大数据时代的发展,研究人员从不同的角度提高聚类精度和降低处理相似性矩阵的时间复杂度,许多LS2C算法被相继提出。Li等[15]开发了一个可学习的子空间聚类,有效地解决LS2C问题,该算法选择学习一个参数函数将高维子空间划分为它底层的低维子空间。Huang等[16]提出一种基于大规模稀疏子空间聚类(Sparse Subspace Clustering, SSC)的聚类算法,在不牺牲聚类精度的前提下高效地处理大规模高光谱图像集。Zhou等[17]提出一种基于克罗内克(Kronecker)积的子空间聚类算法,根据块对角矩阵与其他矩阵的Kronecker乘积仍然是块对角矩阵的性质,有效地学习由个更小矩阵的Kronecker乘积构成的表示矩阵(为簇类个数)。Li等[18]通过考虑一个LS²C问题,即用百万维度划分百万数据点,通过划分大数据变量矩阵和正规化的列和行,设计一个独立的分布式并行的框架。Fan等[19]提出一种LS2C的k因子分解子空间聚类算法k-FSC(k-Factorization Subspace Clustering)。k-FSC通过在矩阵分解模型中追求结构化稀疏性,将数据直接分解为个,并学习亲和矩阵和特征值分解,在大数据集上具有较低的(线性)时间和空间复杂度。Feng等[20]提出一种使用SSC挖掘鉴别特征的算法,解决大规模图像集分类问题,并使用两两线性回归分类完成最终的分类任务。Si等[21]提出一种新的具有结构约束的一致且多样性多视图子空间聚类算法(Consistent and Diverse Multi-view Subspace Clustering algorithm with structure constraint, CDMSC)。CDMSC首先使用排他性约束项增强不同视图之间特定表示的多样性,其次通过将学习的子空间自表示分解为聚类质心和聚类分配,将聚类结构约束施加到子空间自表达,获得面向聚类的子空间自我表示。对于无法准确描述样本之间的线性关系与难找到理想的相似性矩阵的问题,Xu等[22]提出一种线性感知子空间聚类算法(Linearity-Aware Subspace Clustering algorithm, LASC),通过使用线性感知度量学习相似性矩阵。LASC将度量学习和子空间聚类结合到一个联合学习框架,并用自表达策略获得初始子空间结构以探索原始数据的低维表示。
1.2 大规模谱聚类
谱聚类是最流行的聚类算法之一,具有良好的性能,但计算复杂度高,对大规模问题的适用性一直受限。为了将谱聚类算法扩展到大规模的数据,近年来,研究者们提出了许多加速谱聚类的算法。Wang等[23]提出结构化低秩表示描述不同数据视图的聚类结构,并使用多视图共识结构提高聚类性能。崔艺馨等[24]提出一种大规模谱聚类的并行化算法处理大规模数据。Zhu等[25]提出了一种低秩SSC算法,将原始数据投影到低维空间,并从新空间动态学习相似矩阵。Hu等[26]设计一种结合非负嵌入和谱嵌入的无参数聚类算法,降低多视图谱聚类的高计算成本。为了加速大规模问题的谱聚类,Wang等[27]提出了一种基于随机游走Laplacian方法的快速谱聚类算法,利用随机游走Laplacian算子明确地平衡锚的普及性和数据点的独立性。Yang等[28]提出了一种大规模谱聚类算法,该算法将超图扩展成一种通用格式,以捕获复杂的高阶关系,并解决大规模超图谱聚类中的可扩展性问题。Zhao等[29]提出了一种可扩展的多级算法用于大型无向图的谱嵌入,该算法使用一种接近线性时间的谱图粗化方法计算一个更小的稀疏图,同时保留原始图的关键谱(结构)特性。El Hajjar等[30]提出了一种基于一步图的多视图聚类算法,使用与数据空间关联的图的聚类标签相关性构建额外的图,并对聚类标签矩阵施加平滑约束,使它与原始数据图和标签图更一致。Inoubli等[31]提出了一种基于结构图聚类的分布式图聚类算法。针对大规模多视图总是遇到高复杂性和昂贵的时间开销的问题,Wang等[32]提出一种基于二部图框架的灵活高效的不完全大规模多视图聚类算法,通过将多视图锚学习和不完全二分图形式转化为一个相互协调统一的框架以提高聚类算法的性能。He等[33]提出了一种新的结构化锚推断图学习算法(Structured Anchor-inferred Graph Learning algorithm, SAGL)。SAGL不仅可以解决具有挑战性的不完全多视图谱聚类问题,还能处理任意视图缺失情况;此外,SAGL能够捕获多视图数据之间的隐藏连接信息,从而提高聚类性能。
1.3 NMF
NMF作为流行且重要的矩阵分解之一,是一种分析非负数据的线性降维技术。NMF起源于Paatero等[34]提出的正矩阵分解,此后Lee等[35]为NMF开发了一种简单有效的乘法更新算法。Lu等[36]提出了一种子空间聚类约束稀疏的NMF算法(Subspace Clustering constrained sparse NMF, SC-NMF)用于高光谱分解,以更准确地提取端元和相应的丰度。但是一些NMF算法严重受到噪声数据的影响,既无法保留数据的几何信息,也无法保证稀疏部分的表示。针对上述问题,Peng等[37]提出了一种基于相关熵的双图正则化局部坐标约束NMF算法(correntropy based Dual graph regularized NMF algorithm with Local Coordinate constraint, LCDNMF),将数据流形和特征流形的几何信息和局部坐标约束合并到基于相关熵的目标函数。Zhang等[38]提出了一种具有自适应权重的多图正则化半监督NMF算法,以捕获判别数据表示。Peng等[39]提出了一种新的NMF算法,以相互增强的方式学习局部相似性和聚类。Gillis等[40]设计了一个基于乘法更新的简单算法,解决多目标NMF问题。Leplat等[41]针对任意散度的多分辨率NMF问题提出了一种基于乘法更新的新算法。Liu等[42]提出了一种鲁棒多视图NMF聚类算法,可以解决大多数多视图聚类难以充分探索邻域信息等问题。Fan等[43]提出一种水印算法,将经过加密的二维码版权水印嵌入NMF基矩阵,以提高水印在不可见条件下的抗攻击能力。
2 本文算法
表1是本文所用符号的描述。

表1 符号及其描述
2.1 问题定义





本文将式(1)中的正则化函数修改为局部学习项,引入局部学习可以更有效地捕获子空间结构,借用锚的思想,将视为字典。最后利用式(3)学习锚点亲和矩阵:
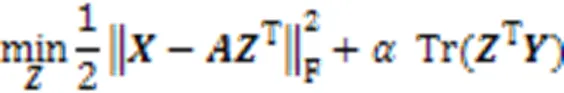
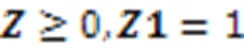

2.2 迭代求解矩阵Z
通过非负拉格朗日松弛的方法优化目标函数。使用式(5)更新式(4)并求解式(4),元素更新如下:

更新的正确性和收敛性证明如下。对于式(5)的更新规则,本文给出了以下两个主要结论:1)收敛时,式(5)极限解满足KKT(Karush-Kuhn-Tucker)条件,KKT条件是非线性规划最优解的必要条件;2)式(5)迭代收敛。本文将在定理1中正式建立上述结果。
定理1 在更新矩阵时,式(5)中更新规则的极限解满足KKT条件。
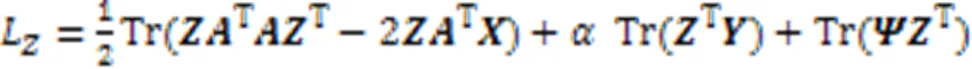
由式(6)的转换,得到式(7):



式(10)提供了极限解应满足的不动点条件。可以看到,式(5)的极限解满足式(9),描述如下:

式(10)被简化为式(11):


2.3 Nyström近似




为了构造Laplacian矩阵,需要计算度矩阵,为×的对角矩阵,由式(15)计算:
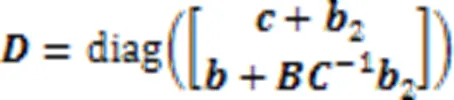


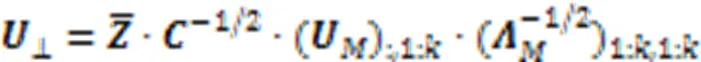

算法1是的本文算法LLSC的总体流程。
算法1 LLSC。
输出 聚类结果。


3 实验与结果分析
3.1 评估指标
实验使用4个聚类指标评估聚类性能,包括聚类准确率(Accuracy,Acc)、归一化互信息(Normalized Mutual Information, NMI)、纯度(Purity)和运行时间(Time)[46]。Acc衡量每个类簇包含来自同一类的数据点的准确率;NMI使用信息熵衡量类簇标签与真实标签的相符程度;Purity衡量每个簇中的数据点来自同一类样本的程度。以上指标的值越高,表明聚类质量越好。运行时间(Time)衡量聚类的速率,运行时间越少,表明聚类效率越高。
给定一个聚类结果标签和对应的真实标签,Acc的计算公式如下:



NMI的计算方式如下:


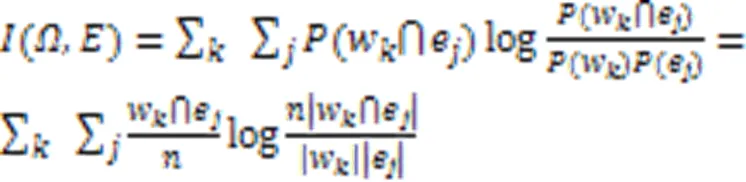
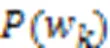

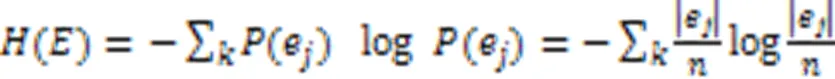
Purity的计算方式如下所示:

实验过程中,需要根据不同的数据集调整聚类算法的参数,以获得最佳性能。很多LS2C算法的聚类性能取决于采样的结果。因此,每次参数运行20次,每次使用不同的采样率,并记录最佳聚类结果。所有实验都在一台4.6 GHz Intel CPU和64 GB RAM、Matlab R2019b的惠普工作站上实现。为了公平比较,实验过程中严格遵循相关论文中描述的实验设置,调整参数以获得最佳性能。
3.2 小规模数据集上的实验和结果分析
首先在几个小型数据集上进行测试:RCV1_4和Tr45是文本语料库,USPS是手写数据。表2总结了这些数据集的具体信息。
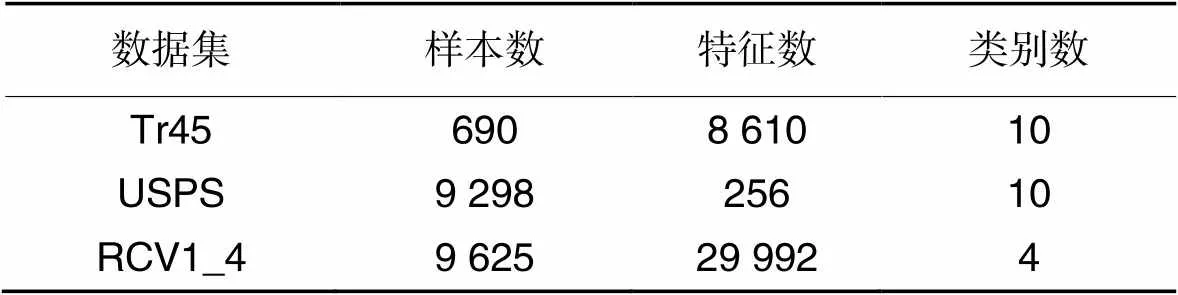
表2 小规模数据集的具体信息
将LLSC与以下聚类算法进行比较:
1)LMVSC(Large-scale Multi-View Subspace Clustering)[8]。最先进的大规模聚类算法之一。
2)SGL (Structured Graph Learning)[47]。一种结构化图学习可伸缩的子空间聚类算法。
3)FNC (Fast Normalized Cut)[48]。一种直接求解归一化切割算法,具有较低的计算复杂度。
4)KMM (K-Multiple-Means)[49]。基于二分图划分的K-多重均值算法。
LLSC中一共有和两个参数。首先,在小规模数据的采样上,对比算法统一在[100,1 000]搜索最优平均解进行对比;但由于Tr45过小,采样区间设置在[100,300]。的参数在[0.001,100]选择。
不同的数据集的样本分布有很大差异,不同算法在不同的数据集上运行时间和聚类结果也有差异。针对小规模数据集进行实验和结果分析。表3展示了LLSC和对比算法在不同小规模数据集上的聚类结果。

表3 小规模数据集上的聚类结果
注:粗体表示最佳性能值。
在Acc和Time上,LLSC明显优于对比算法。在Tr45数据集上,LLSC的NMI和Purity比LMVSC高4.91和11.74个百分点。在Tr45数据集上,LLSC的Acc结果是77.24%,SGL和KMM的Acc分别是74.41%和73.8%,数值上LLSC的提升较低,这是因为LLSC主要针对大规模数据集,在具有挑战的小规模的数据集上的聚类优势不明显。在Acc、Purity和NMI方面,LLSC在USPS数据集上都高于对比算法。例如:LLSC在USPS上Acc、NMI和Purity比LMVSC高12.25、14.97和8.04个百分点。此外,LLSC在USPS上的Time也是所有算法中最少的,仅使用了1.00 s。在RCV1_4数据集上,LLSC用时0.17 s,远低于LMVSC的585.00 s。KMM虽然效率高,但是聚类结果较差。在RCV1_4上,SGL的NMI和Purity最优,但是它的Time较差,LLSC仅用0.17 s,而SGL则需要98.86 s。因此,在小规模的数据集上LLSC优于对比算法。
3.3 大规模数据集上的实验和结果分析
表4总结了大规模数据集的具体信息。MNIST和EMNIST(digits)是图像数据,Postures是手写数据,Pokerhand是牌手数据。
LLSC将与以下大规模的聚类算法进行比较:
1)LMVSC[8]。最先进的大规模聚类算法之一。
2)LSC-k(Landmark-based Spectral Clustering using k-means)[50]。最传统的大规模谱聚类算法之一。
3)SLSR(Scalable Least Square Regression)[51]。最传统的大规模数据子空间聚类之一。
4)k-FSC[19]。一种最新的LS2C。
在这些数据集中,LLSC和对比算法的采样数都在[500,3 000]搜索最优解。参数在[0.001,100]选择最优值。
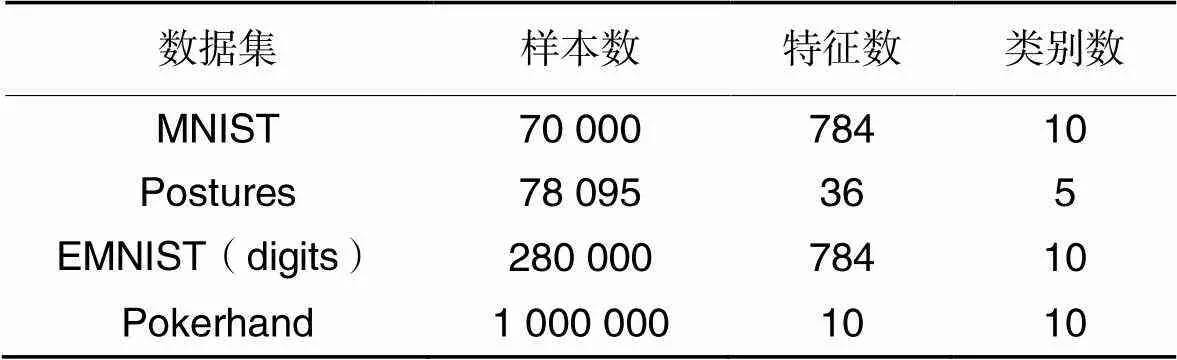
表4 大规模数据集的具体信息
表5显示了各种算法在MNIST和Postures数据集上的聚类结果,由表5可以看出,在Acc和Time上,LLSC在大多数情况下明显优于其他对比算法。在MNIST上,LLSC用时最少,表明LLSC聚类效率高于其他对比算法,例如:LMVSC用了73.33 s,而LLSC只用了3.71 s。在MNIST上,LLSC的Acc比LMVSC仅提高了2.39个百分点。虽然LSC-k的Acc高于LLSC,但是LLSC的Time远低于LSC-k。在Postures上,LLSC表现出来的效果要比所对比的算法好许多,在Acc和NMI这两个指标上,LLSC比LMVSC和SLSR高28.10、31.11个百分点和11.01、3.06个百分点。且LLSC的聚类效率也得到了很大的提升。k-FSC在Postures上的聚类效果次优。LLSC的Time也是所对比中最少的。虽然SLSR的Time次优,但是聚类效果比LLSC和k-FSC差。

表5 MNIST和Postures数据集上的聚类结果
表6展示了LLSC和对比算法在Pokerhand和EMNIST(digits)数据集上的聚类结果。此外,LLSC的Acc比LMVSC、LSC-k分别高出36.32、37.68个百分点。在Pokerhand数据集上,虽然LLSC和k-FSC的Time相差较小,但LLSC的Acc比k-FSC高28.18个百分点,在Pokerhand上面LLSC具有一个比较好的提升。尽管SLSR在Pokerhand数据集上的Time最优,但是它的Acc并不理想。在EMNIST(digits)上,LMVSC由于采样数为300时聚类需要消耗7 867 s,因此放弃对LMVSC采样1 000,LLSC比LMVSC和SLSR在Acc和NMI上分别高15.26、17.4个百分点和8.7、22.68个百分点。此外,LLSC的Time非常低,如:LLSC用时12.54 s,SLSR用时182.52 s。对比算法都基于锚图,这些算法在近似求解Laplacian矩阵的特征向量时使用奇异值分解(Singular Value Decomposition, SVD)方法,这种方法计算复杂度过高,聚类的Time将提高,而LLSC使用的Nyström可以解决这个问题。虽然SLSR在Pokerhand上的效率高于LLSC,但是SLSR的聚类精度要远低于LLSC。可以得出LLSC在大规模数据集上实现了较好的性能。

表6 Pokerhand和EMNIST(digits)数据集上的聚类结果
3.4 参数分析
对于无监督学习算法,确定最优参数仍然是一个有待解决的问题。为了研究参数对LLSC最终聚类性能的影响,在实验中记录了参数变化带来的不同聚类结果,以分析LLSC对不同参数值的敏感性。从实验结果中发现LLSC对输入参数非常敏感。图1为根据LLSC在不同数据集上参数变化而得到实验结果,设置了不同的横坐标刻度,能够更加清晰且直观地分析参数变化对算法的影响。如图1所示,在Tr45数据集上,最优解的α值为0.8;在MNIST数据集上,最优解的值为0.5。

图1 不同数据集上不同锚点数时α取值在[0.001 100]的实验结果
从图1可见,在Tr45数据集和MNIST数据上,当>10时,越大,性能指标的数值越小且具有明显的降低趋势;当取值太小时,得到的结果略逊于最优结果,这可能是取值太小时迭代的作用变小了。因此,可以得出LLSC不仅对输入参数敏感,也对数据集的复杂度具有极高的依赖性。在一般情况下,的取值应在[0.01,10]区间,寻找不同的数据集的最优值。由图1可知,如果采样锚点数太小,则所选样本可能不具有代表性。理论上,更具代表性的锚定将有助于得到更精确的矩阵近似;但是从图中分析可知,增加参数并不一定会获得代表性的锚点,得到更好聚类结果。这是因为当增加时,集群性能有时会降低;此外,锚点数越大,算法所需要的Time会越长,为了使矩阵迭代收敛,迭代过程会消耗大量的时间。
4 结语
本文提出一种融合局部结构学习的大规模子空间聚类算法(LLSC),LLSC可以保持较高的聚类精度和较低的Time。LLSC首先修改LS2C的目标函数,同时学习全局和局部结构信息;其次通过非负拉格朗日松弛方法优化目标函数,使用迭代的方法得到最优的锚点亲和矩阵;最后使用Nyström近似方法,通过较小的样本子矩阵的特征向量近似Laplacian矩阵的特征向量。在真实数据集上的大量实验结果验证了该算法的有效性和效率。未来,将考虑将LLSC应用到图像检测、语音识别等领域。
[1] ELHAMIFAR E, VIDAL R. Sparse subspace clustering: algorithm, theory, and applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2765-2781.
[2] XUE X, ZHANG X, FENG X, et al. Robust subspace clustering based on non-convex low-rank approximation and adaptive kernel[J]. Information Sciences, 2020, 513: 190-205.
[3] ZHAO D, LIU J. Study on network security situation awareness based on particle swarm optimization algorithm[J]. Computers and Industrial Engineering, 2018, 125: 764-775.
[4] LI J, KONG Y, FU Y. Sparse subspace clustering by learning approximation ℓ0codes[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 2189-2195.
[5] ZHENG M, GAO P, ZHANG R, et al. End-to-end object detection with adaptive clustering transformer[C]// Proceedings of the 2021 British Machine Vision Conference. Durham: BMVA Press, 2021: No.709.
[6] LIPOR J, HONG D, TAN Y S, et al. Subspace clustering using ensembles of K-subspaces[J]. Information and Inference: A Journal of the IMA, 2021, 10(1): 73-107.
[7] HE L, RAY N, GUAN Y, et al. Fast large-scale spectral clustering via explicit feature mapping [J]. IEEE Transactions on Cybernetics, 2019, 49(3): 1058-1071.
[8] KANG Z, ZHOU W, ZHAO Z, et al. Large-scale multi-view subspace clustering in linear time[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 4412-4419.
[9] LIU X, WANG L, ZHANG J, et al. Global and local structure preservation for feature selection [J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(6): 1083-1095.
[10] PENG C, ZHANG Z, KANG Z, et al. Nonnegative matrix factorization with local similarity learning[J]. Information Sciences, 2021, 562:325-346.
[11] DING C, HE X, SIMON H D. Nonnegative Lagrangian relaxation of K-means and spectral clustering [C]// Proceedings of the 2005 European Conference on Machine Learning, LNCS 3720. Berlin: Springer, 2005: 530-538.
[12] FOWLKES C, BELONGIE S, CHUNG F, et al. Spectral grouping using the Nyström method[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(2): 214-225.
[13] FRANGELLA Z, TROPP J A, UDELL M. Randomized Nyström preconditioning[J]. SIAM Journal on Matrix Analysis and Applications, 2023, 44(2): 718-752.
[14] HUANG W, YIN M, LI J, et al. Deep clustering via weighted k-subspace network[J]. IEEE Signal Processing Letters, 2019, 26(11): 1628-1632.
[15] LI J, LIU H, TAO Z, et al. Learnable subspace clustering [J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(3):1119-1133.
[16] HUANG S, ZHANG H, PIŽURICA A. Sketched sparse subspace clustering for large-scale hyperspectral images [C]// Proceedings of the 2020 IEEE International Conference on Image Processing. Piscataway: IEEE, 2020: 1766-1770.
[17] ZHOU L, BAI X, ZHANG L, et al. Fast subspace clustering based on the Kronecker product[C]// Proceedings of the 25th International Conference on Pattern Recognition. Piscataway: IEEE, 2021: 1558-1565.
[18] LI J, TAO Z, WU Y, et al. Large-scale subspace clustering by independent distributed and parallel coding[J]. IEEE Transactions on Cybernetics, 2022, 52(9):9090-9100.
[19] FAN J. Large-scale subspace clustering via k-factorization [C]// Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2021: 342-352.
[20] FENG Z, DONG J, GAO X, et al. Subspace representation based on pairwise linear regression for large scale image set classification[C]// Proceedings of the SPIE 12083, 13th International Conference on Graphics and Image Processing. Bellingham, WA: SPIE, 2022: No.1208318.
[21] SI X, YIN Q, ZHAO X, et al. Consistent and diverse multi-view subspace clustering with structure constraint[J]. Pattern Recognition, 2022, 121: No.108196.
[22] XU Y, CHEN S, LI J, et al. Linearity-aware subspace clustering[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 8770-8778.
[23] WANG Y, WU L, LIN X, et al. Multiview spectral clustering via structured low-rank matrix factorization [J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(10): 4833-4843.
[24] 崔艺馨,陈晓东.Spark框架优化的大规模谱聚类并行算法[J]. 计算机应用, 2020, 40(1): 168-172.(CUI Y X, CHEN X D. Spark framework based optimized large-scale spectral clustering parallel algorithm [J]. Journal of Computer Applications, 2020, 40(1): 168-172.)
[25] ZHU X, ZHANG S, LI Y, et al. Low-rank sparse subspace for spectral clustering [J]. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(8): 1532-1543.
[26] HU Z, NIE F, WANG R, et al. Multi-view spectral clustering via integrating nonnegative embedding and spectral embedding [J]. Information Fusion, 2020, 55: 251-259.
[27] WANG C L, NIE F, WANG R, et al. Revisiting fast spectral clustering with anchor graph [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2020: 3902-3906.
[28] YANG Y, DENG S, LU J, et al. GraphLSHC: towards large scale spectral hypergraph clustering [J]. Information Sciences, 2021, 544: 117-134.
[29] ZHAO Z, ZHANG Y, FENG Z. Towards scalable spectral embedding and data visualization via spectral coarsening[C]// Proceedings of the 14th ACM International Conference on Web Search and Data Mining. New York: ACM, 2021: 869-877.
[30] EL HAJJAR S, DORNAIKA F, ABDALLAH F. One-step multi-view spectral clustering with cluster label correlation graph [J]. Information Sciences, 2022, 592: 97-111.
[31] INOUBLI W, ARIDHI S, MEZNI H, et al. A distributed and incremental algorithm for large-scale graph clustering [J]. Future Generation Computer Systems, 2022, 134: 334-347.
[32] WANG S, LIU X, LIU L, et al. Highly-efficient incomplete large-scale multi-view clustering with consensus bipartite graph [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 9766-9775.
[33] HE W, ZHANG Z, CHEN Y, et al. Structured anchor-inferred graph learning for universal incomplete multi-view clustering [J]. World Wide Web, 2023, 26(1): 375-399.
[34] PAATERO P, TAPPER U. Positive matrix factorization: a non-negative factor model with optimal utilization of error estimates of data values [J]. Environmetrics, 1994, 5(2): 111-126.
[35] LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788-791.
[36] LU X, DONG L, YUAN Y. Subspace clustering constrained sparse NMF for hyperspectral unmixing [J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(5): 3007-3019.
[37] PENG S, SER W, CHEN B, et al. Robust nonnegative matrix factorization with local coordinate constraint for image clustering[J]. Engineering Applications of Artificial Intelligence, 2020, 88: No.103354.
[38] ZHANG K, ZHAO X, PENG S. Multiple graph regularized semi-supervised nonnegative matrix factorization with adaptive weights for clustering[J]. Engineering Applications of Artificial Intelligence, 2021, 106: No.104499.
[39] PENG C, ZHANG Z, KANG Z, et al. Nonnegative matrix factorization with local similarity learning[J]. Information Sciences, 2021, 562: 325-346.
[40] GILLIS N, HIEN L T K, LEPLAT V, et al. Distributionally robust and multi-objective nonnegative matrix factorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(8): 4052-4064.
[41] LEPLAT V, GILLIS N, FÉVOTTE C. Multi-resolution beta-divergence NMF for blind spectral unmixing[J]. Signal Processing, 2022, 193: No.108428.
[42] LIU X, SONG P, SHENG C, et al. Robust multi-view non-negative matrix factorization for clustering [J]. Digital Signal Processing, 2022, 123: No.103447.
[43] FAN D, ZHANG X, KANG W, et al. Video watermarking algorithm based on NSCT, pseudo 3D-DCT and NMF[J]. Sensors, 2022, 22(13): No.4752.
[44] KANG Z, PENG C, CHENG Q. Twin learning for similarity and clustering: a unified kernel approach [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 2080-2086.
[45] PENG R, SUN H, ZANETTI L. Partitioning well-clustered graphs: spectral clustering works![C]// Proceedings of the 28th Conference on Learning Theory. New York: JMLR.org, 2015: 1423-1455.
[46] CHEN X, CAI D. Large scale spectral clustering with landmark-based representation [C]// Proceedings of the 25th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2011: 313-318.
[47] KANG Z, LIN Z, ZHU X, et al. Structured graph learning for scalable subspace clustering: from single view to multiview [J]. IEEE Transactions on Cybernetics, 2022, 52(9): 8976-8986.
[48] CHEN X, HONG W, NIE F, et al. Spectral clustering of large-scale data by directly solving normalized cut [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2018: 1206-1215.
[49] NIE F, WANG C L, LI X. K-multiple-means: a multiple-means clustering method with specified k clusters [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 959-967.
[50] CAI D, CHEN X. Large scale spectral clustering via landmark-based sparse representation[J]. IEEE Transactions on Cybernetics, 2015, 45(8): 1669-1680.
[51] PENG X, TANG H, ZHANG L, et al. A unified framework for representation-based subspace clustering of out-of-sample and large-scale data [J]. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(12): 2499-2512.
Large-scale subspace clustering algorithm with Local structure learning
REN Qize, JIA Hongjie*, CHEN Dongyu
(,,212013,)
The conventional large-scale subspace clustering methods ignore the local structure that prevails among the data when computing the anchor affinity matrix, and have large error when calculating the approximate eigenvectors of the Laplacian matrix, which is not conducive to data clustering. Aiming at the above problems, a Large-scale Subspace Clustering algorithm with Local structure learning (LLSC) was proposed. In the proposed algorithm, the local structure learning was embedded into the learning of anchor affinity matrix, which was able to comprehensively use global and local information to mine the subspace structure of data. In addition, inspired by Nonnegative Matrix Factorization (NMF), an iterative optimization method was designed to simplify the solution of anchor affinity matrix. Then, the mathematical relationship between the anchor affinity matrix and the Laplacian matrix was established according to the Nyström approximation method, and the calculation method of the eigenvectors of the Laplacian matrix was modified to improve the clustering performance. Compared to LMVSC (Large-scale Multi-View Subspace Clustering), SLSR (Scalable Least Square Regression), LSC-k (Landmark-based Spectral Clustering using k-means), and k-FSC(k-Factorization Subspace Clustering), LLSC demonstrates significant improvements on four widely used large-scale datasets. Specifically, on the Pokerhand dataset, the accuracy of LLSC is 28.18 points percentage higher than that of k-FSC. These results confirm the effectiveness of LLSC.
subspace clustering; local structure learning; Nonnegative Matrix Factorization (NMF); large-scale clustering; low-rank approximation
This work is partially supported by National Natural Science Foundation of China (61906077).
REN Qize, born in 1997, M. S. candidate. His research interests include large-scale subspace clustering.
JIA Hongjie, born in 1988, Ph. D., associate professor. His research interests include clustering, machine learning.
CHEN Dongyu, born in 2000. His research interests include subspace clustering.
TP181; TP311.13
A
1001-9081(2023)12-3747-08
10.11772/j.issn.1001-9081.2022111750
2022⁃11⁃24;
2023⁃04⁃30;
2023⁃05⁃12。
国家自然科学基金资助项目(61906077)。
任奇泽(1997—),男,河南许昌人,硕士研究生,主要研究方向:大规模子空间聚类;贾洪杰(1988—),男,河北衡水人,副教授,博士,CCF会员,主要研究方向:聚类、机器学习;陈东宇(2000—),男,广西柳州人,主要研究方向:子空间聚类。
