DRG支付制度中低码高编行为实证分析研究
2022-10-11程文炜常维夫
程文炜 常维夫
(中南大学湘雅三医院医务部 长沙 410013)
国家医保局于2019年全面推进DRG支付制度改革,截至2021年底,30个DRG国家试点城市已全部进入实际付费阶段。由于卫生经济学中的信息不对称等原因,DRG实施过程中也可能发生一些道德风险问题,包括低码高编、选择病人、分解出院等[1]。低码高编行为指的是医方为获取更高的支付水平,将患者的诊断进行不适当的编码和分类,从而分入比原本DRG组更复杂的组,是最常见的医疗欺诈行为之一[2,3]。有研究表明,美国每年因为低码高编行为带来数十亿美元的额外不当公共支出[4]。黄昊等人以医院病例数据模拟更改主要诊断选择,发现82.5%的病例经过转换诊断后权重升高[5]。我国因全国统一开展DRG支付试点工作时间较短,针对DRG支付制度实施后带来的低码高编行为的实证研究较少,仅见方金鸣等人选择某付费试点城市的典型病组数据进行DRG实施前后低码高编行为分析一篇研究,但其仅采用卡方检验对实施前后进行比较分析,不能有效识别低码高编行为的变化类型和表现形式[6]。间断时间序列分析(interrupted time-series analysis, ITSA)是在综合考虑事物自然发展变化的基础上,通过收集干预措施实施前后多个时间点的数据,评估分析干预措施效果,已被证实为评估卫生系统政策干预纵向效果最强的实验研究设计[7,8]。本研究采取间断时间序列分析方法对我国某DRG付费试点城市低码高编行为开展实证分析研究,探索存在的问题,对完善DRG支付政策提出建议。
1 资料与方法
1.1 研究资料
本研究选择某DRG国家试点城市中首批8家试点医院作为研究对象,研究的时间跨度为2021年1月—9月。分为两个阶段,2021年1月—5月为第一阶段,这一阶段该DRG试点城市未实行DRG支付制度,表示实施DRG付费前的各指标基线水平;2021年6月—9月为第二阶段,这一阶段该城市实行DRG实际付费,表示实施DRG支付制度后各指标的变化情况。研究共纳入8家试点医院参加基本医疗保险的住院患者的病案首页数据和医保结算数据188256例,经对字段缺失、不准确以及病案首页与医保结算无法关联的数据进行预处理,最终纳入分析的病例量为169778例,占总数据量的90.18%。
1.2 研究方法
1.2.1 一般统计方法
采用频数和构成比对计数资料统计描述,采用X2检验比较DRG实施前后各DRG组构成比差异。
1.2.2 间断时间序列分析
间断时间序列的分段回归模型分析是通过建立多元回归方程,设置虚拟变量对干预实施前后的指标数据进行标记,分别对干预前后时间段的指标数据进行多元同归分析,从而估算干预前后时间分段指标值的水平和趋势变化[7,8]。将政策实施节点作为干预点,以纳入的时间点作为自变量,以DRG组病例数构成比指标作为因变量,分段构建线性回归方程,模型表达公式如下[9]。
Yt=β0+β1×time+β2×DRG+β3×timeDRG+et
式中,Yt代表各时间点因变量指标的平均水平,本研究中DRG组中病例数构成比,β0为该指标的基线值,即因变量指标在研究初期的水平估计值;β1为基线斜率估计值,即DRG实施前,观察指标随时间变量t变化的趋势估计值;time为时间的连续性变量,以每半月为一个观测周期,共设立18个数据时间标的,其取值为1—18;β2为DRG 政策引起观察指标的水平变化估计值,即DRG支付制度实施后,实施前时间分段末端与实施后时间分段起始端观察指标的水平值差值,是一种瞬时的取值变化,体现DRG政策实施的瞬时作用;β3为DRG引起的观察指标的趋势变化估计值,即实施DRG支付制度后时间分段趋势值与实施前时间分段趋势值的差值,体现实施DRG支付制度后因变量变化趋势的变动;timeDRG在政策实施前赋值为0,政策实施后赋值为1—8;et为误差项,即无法用模型里上述参数来解释的随机误差。
以上分析均采用SAS9.4实现,检验水准为0.05,采用双侧检验。考虑到样本量较大,容易出现有统计学意义的结果,对结果解释时不仅考虑其是否具有统计学意义,也考虑其结果的临床实际意义。
2 结果
2.1 DRG支付制度实施前后同一ADRG组下各DRG组病例数及构成比分析
8家医院在实施DRG支付制度之前的5个月中,所有病例数为97192例,这些病例被分入393个DRG组,归属于202个ADRG组。在实施DRG支付制度改革后的4个月,所有病例数为72586例,这些病例被分入391个DRG组,归属于201个ADRG组。对实施前后同一ADRG组下含有2个及以上DRG组(127个ADRG组)的病例数及构成比进行X2检验,并将伴有“严重合并症或并发症的DRG组(DRG代码中第四位数为1)”或伴有“一般合并症或并发症(DRG代码中第四位数为3)”的DRG组的构成比在实施DRG支付制度后出现增长,并且P值<0.05的数据筛选出来(见表1)。结果显示,在ADRG组ET1中,其细分为ET11和ET15的2个DRG组,在实施DRG支付制度后,ET11的病例数构成比由实施前的36.96%上升到实施后的63.16%,构成比增长了26.20%,而ET15组的病例数构成比由实施前的63.04%下降为实施后的36.84%,其构成比降低了26.20%,并且通过卡方检验,其P值<0.05,具有统计学意义。而在ADRG组SR1中,其细分为SR11、SR13和SR15等3个DRG组,在实施DRG支付制度后,SR11的病例数构成比由实施前的49.22%上升到实施后的57.55%,增长了8.33%,SR13的病例数构成比由实施前的22.92%上升到实施后的30.82%,增长了7.90%,而SR15的病例数构成比由实施前的27.86%下降实施后的11.63%,下降了16.23%,并且通过X2检验,其P值<0.05,具有统计学意义。
2.2 DRG支付制度实施前后伴有严重并发症或合并症的DRG组中病例数构成比的间断时间序列分析
根据表1结果,可以了解在ED1、ER1、ES1、ET1、FM3、FW1、LV1、QS4、RW2和SR1等10个ADRG组中,其细分所对应的伴有严重合并症或并发症的DRG组在DRG支付制度实施后,其病例数出现了增长,并经X2检验,具有统计学意义。而在ED1、ET1、FW1、QS4、SR1等5个ADRG组中,其细分的DRG组中病例数变化较大,超过了10%,因此我们对上述变化较大的5个ADRG组中所对应的DRG组进行间断时间序列分析(见表2)。
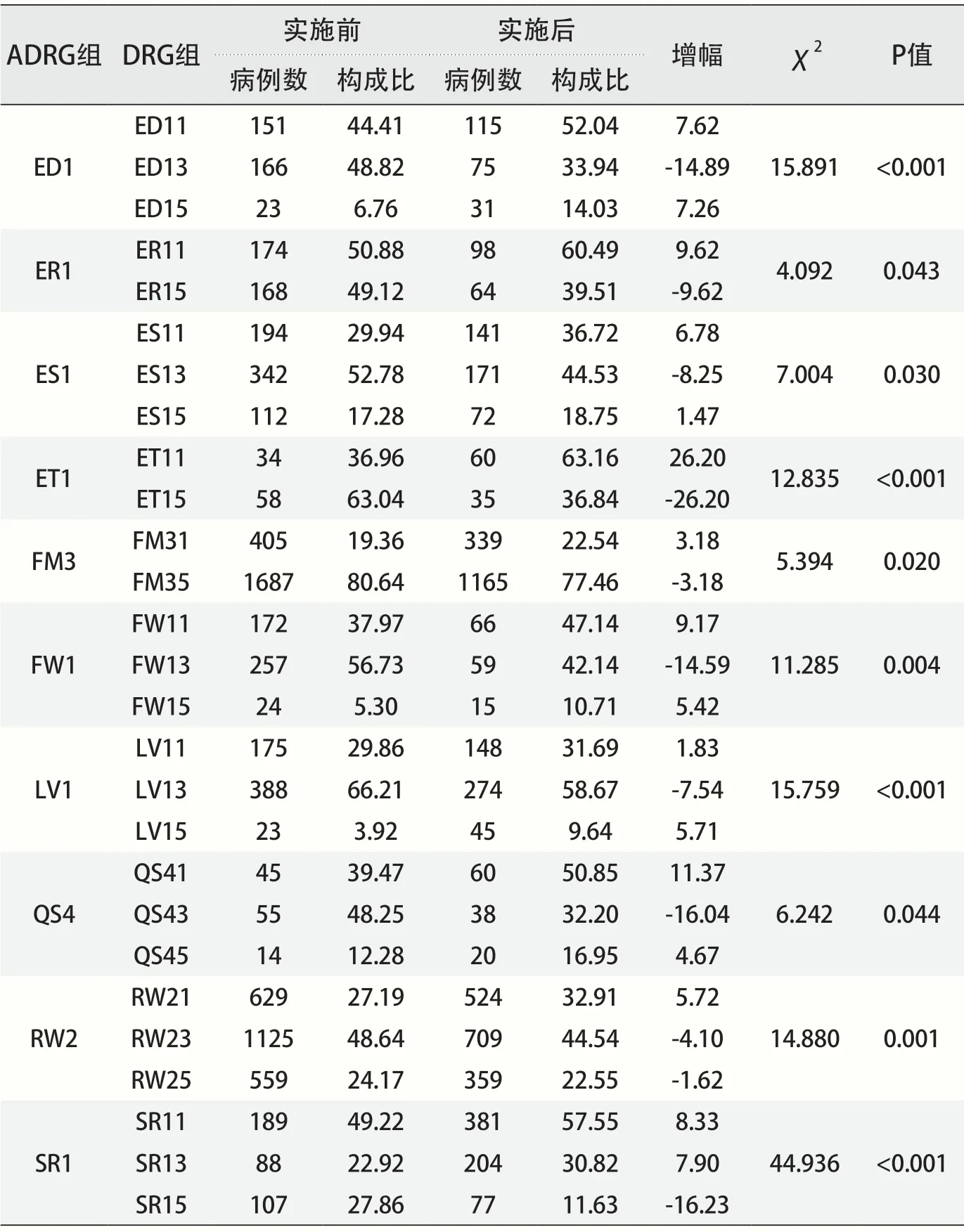
表1 实施前后同一ADRG组下不同DRG组病例数及构成比分析
从表2中可以看出,ED11组的病例数构成比基础斜率值β1为-0.005(P=0.647>0.05),表示在实施DRG支付制度前,ED11组病例数构成比呈下降趋势,但无统计学意义。 ED11组病例数构成比的水平变化量β2的估计值为-0.053(P=0.611>0.05),表示ED11组构成比在实施DRG支付制度的瞬时降低了5.3%,但无统计学意义。ED11组病例数构成比的趋势变化量β3的估计值为-0.010(P=0.622>0.05),表示ED11组构成比在实施DRG支付制度后呈下降趋势,每半个月构成比降低1.5%,无统计学意义。在ET11和FW11组中,其趋势变化量β3的估计值分别为-0.023和0.022,但是P>0.05,不能排除存在抽样误差。
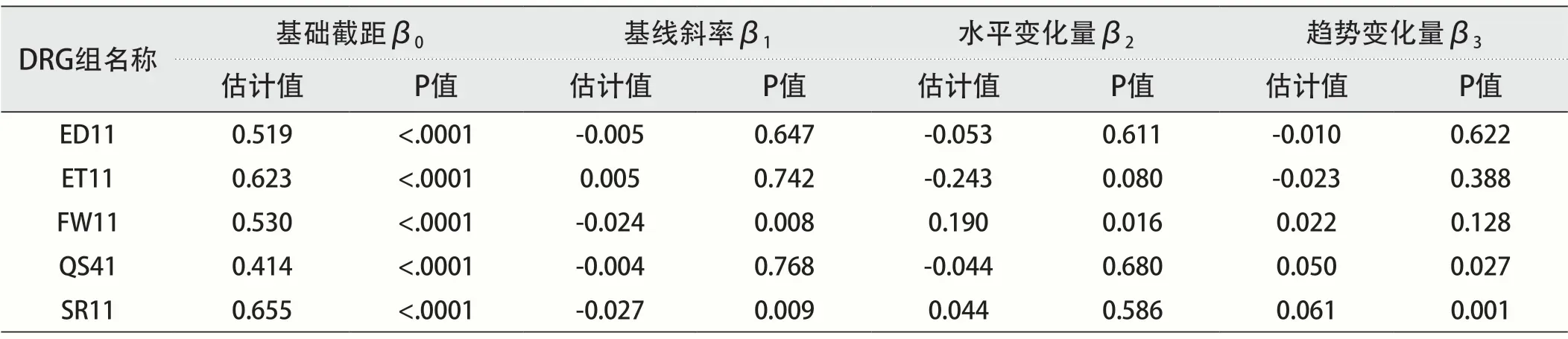
表2 DRG支付制度实施前后伴有严重合并症或并发症的DRG组中病例数构成比间断时间序列分析结果
QS41组的病例数构成比基础斜率值β1为-0.004(P=0.768>0.05),表 示 在 实 施DRG支付制度前,QS41组病例数构成比呈下降趋势,但无统计学意义。QS41组病例数构成比的水平变化量β2的估计值为-0.044(P=0.680>0.05),表示QS41组构成比在实施DRG支付制度的瞬时降低了4.4%,但无统计学意义。QS41组病例数构成比的趋势变化量β3的估计值为0.050(P=0.027<0.05),表示QS41组构成比在实施DRG支付制度后呈增长趋势,每半个月构成比增长4.6%(见图1),有统计学意义。
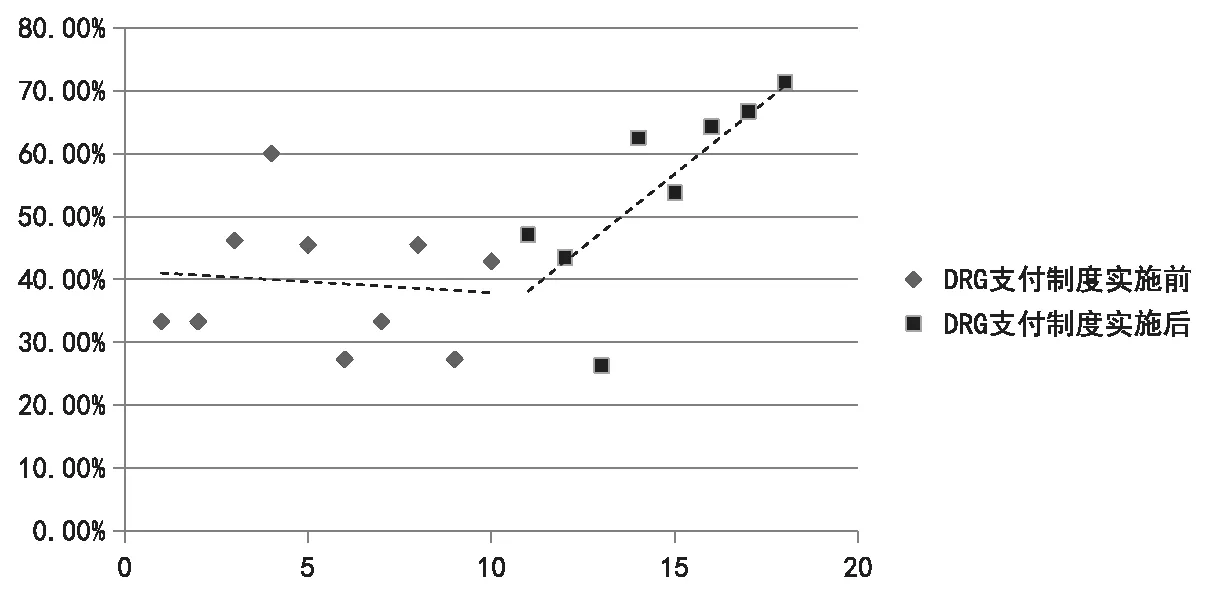
图1 DRG支付制度实施前后QS41组病例数构成比变化折线图
SR11组的病例数构成比基础斜率值β1为-0.027(P=0.009<0.05),表示在实施DRG支付制度前,SR11组病例数构成比呈下降趋势,且有统计学意义。SR11组病例数构成比的水平变化量β2的估计值为0.044(P=0.586>0.05),表示SR11组构成比在实施DRG支付制度的瞬时增长了4.4%,但无统计学意义。SR11组病例数构成比的趋势变化量β3的估计值为0.061(P=0.001<0.05),表 示SR11组构成比在实施DRG支付制度后呈增长趋势,每半个月构成比增长3.4%(见图2),有统计学意义。
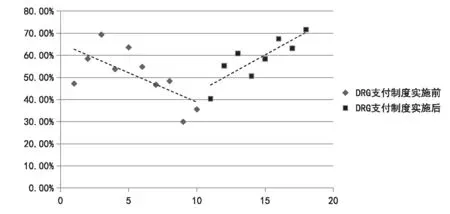
图2 DRG付费前后SR11组病例数构成比变化折线图
3 讨论
本研究选择的试点城市DRG分组方案中,QS41组(其他贫血且伴严重并发症或合并症)的权重为1.01,QS43组(其他贫血且伴一般并发症或合并症)和QS45(其他贫血且不伴一般并发症或合并症)权重分别为0.78和0.52,较QS41组的权重低。SR11组(败血症伴严重并发症或合并症)的权重为1.45,SR13组(败血症且伴一般并发症或合并症)和SR15(败血症且不伴一般并发症或合并症)权重分别为0.98和0.40,较SR11组的权重低。间断时间序列分析结果显示,实施DRG支付制度后QS41的病例数量构成比呈现了每半个月增长4.6%的趋势,而SR11组病例数构成比在实施DRG支付制度后也呈现每半个月增长3.4%的趋势。在该DRG国家试点城市居民的各类患病率未受到其他明显内部因素和外部因素影响的前提下,QS41和SR11的病例数构成比应当保持在一个较小的波动范围内。然而分析发现,在DRG支付制度实施后,QS41和SR11组的病例数量构成比有明显的上升趋势,这主要是由于医院为获得更高医保基金补偿而主动地对疾病编码进行高编码操作,通过改变编码使得病例都分入权重更高的DRG组[10]。本研究在对试点城市医院实地访谈中了解到,在DRG支付制度实施后,医生为了控制超支风险或者获得更多的费用结余,会通过调整疾病诊断编码来使得病例分入权重更高的DRG组。例如,有医生谈到高编码“有些DRG组的权重是根据历史费用确定的,但随着新技术的开展,相应的疾病治疗成本也逐渐上升,但DRG组的权重还是对应技术进步之前的治疗成本,因此为了补偿开展新技术所导致亏损,会选择多填写其他诊断,这样使得病例分入权重更高的DRG组,以此获得更多的医保基金补偿”。这也进一步证实了试点城市医院存在低码高编现象,同时也提示医保部门应对此重点监管。
低码高编行为容易发生在DRG分组不够细致、并发症和合并症考虑不充分的DRG组中[11],这主要是由于DRG分组中疾病编码的设置本身存在一定的局限性,为医生高编码提供了可操作空间。另外,考虑到医生对疾病诊断、治疗有信息优势,其他相关人员难以对编码是否合适进行有效评估,再加上目前DRG支付制度的开展还处于初始阶段,缺乏对医生低码高编行为的应对经验与监管方式,使得高编码的现象较为隐秘地存在于某些疾病编码过程中[12]。根据本研究结果,以及结合低码高编行为研究文献[6,13],提示可以通过加强病案首页和诊断编码的培训学习、提高医务人员对于低码高编行为危害性的认识、完善分组规则、开发研究更高效的大数据监管平台等方式降低DRG支付产生的低码高编道德风险,保障DRG支付制度良性运转。
