高维纵向数据的亚组识别方法及应用
2022-10-11吉洋莹
段 谦,吉洋莹,黄 磊
(西南交通大学 数学学院, 成都 611756)
0 引言
亚组识别常用于精准医疗[1]或精准营销[2],根据个体之间的异质性,针对不同亚组的个体采取特异性的方案,从而提高总体的治疗效果或营销收益。因此,在进行统计推断和决策之前,先正确识别亚组是十分有必要的。常用的亚组识别参数划分的方法有贝叶斯方法[3]、分类与回归树[4]等。然而,在大数据的背景下,递归分割方法具有通用性和更强的计算效率,使得一系列非参数方法流行起来,这类方法包括针对患者分层的预后特征所提出的PRIM方法[5]、适用于临床药物开发所提出的sequential-batting方法[6]、基于最大似然估计原理所提出的MOB方法[7]等。亚组识别方法的原理是如果某些个体属于同一亚组,则协变量对同一亚组的预期效应是相同的。为了更好地对群体进行亚组识别,目前已有二值分割[8]、同时分组划分和特征选择[9]、分层聚类[10]等方法。有关亚组识别方法的详细文献综述,可以参阅Lipkovich等[11]的文章。由于每个个体中有大量的测量数据,因此可以将每个个体中的数据视为一个独特的亚组,并拟合一个适合这个亚组的模型。与传统的总体模型相比,该建模方法允许不同亚组间模型的协变量系数发生变化。将在高维纵向数据的背景下构建一种亚组识别的方法。在详细介绍此亚组识别方法前,先介绍一下纵向数据和高维变量筛选。
纵向数据[12]是按照时间的推移对一系列的个体进行重复多次测量获得的兼备横截面数据特性和时间序列特性的一类数据。纵向数据可分析个体的响应变量随时间变化的趋势,也可横向对比个体之间的差异。根据研究课题内重复测量的次数,纵向数据可以分为不定期测量的且测量次数有限的稀疏纵向数据[13]和定期测量且测量次数趋于无穷的密集纵向数据[14]。现有文献详细地探究了纵向数据的统计方法,常见的有参数方法、非参数方法以及半参数方法。Liang等[15]基于拟似然的思想提出了广义估计方程的方法,且验证了该方法运用到实际纵向数据分析的问题中是有效的;赵明涛等[16]研究了纵向数据的单指标模型的参数估计方法;李劭珉等[17]利用指数平方损失函数对纵向数据模型构建了一种稳健的估计法;Li等[18]提出了基于B样条基的同质划分方法对纵向数据进行了研究。随着大数据技术的发展,纵向数据也越来越容易收集到高维的协变量,因此对纵向数据进行回归建模时,也有必要考虑高维协变量的筛选。
模型的协变量过多,或者说数据的维度过高就会产生多重共线性或者伪相关问题,并导致参数估计量的方差过大以及响应变量预测值的方差过大,且在拟合高维模型时需要强大的计算量,费时费力。统计学者们通过引入惩罚估计方法对此类问题进行系数收缩建模,如景甜甜等[19]利用主成分对肌电信号特征参数进行降维,摒弃冗余信息;林倩瑜[20]结合特征压缩方法对分类输出的云服务组合大数据进行降维处理;还有lasso[21]以及elastic-net[22]等广为人知的统计学习方法,但是这些方法都不具有oracle性质,即不具备模型选择的相合性和参数估计的渐近正态性;在此基础上,Fan等[23]提出了SCAD(smoothly clipped absolute deviation)方法,Zhang[24]提出了极大极小凹惩罚(minimax concave penalty)方法,简称MCP方法。这些惩罚估计方法不仅可以剔除不重要的协变量,还可以提高计算效率,最终获得更稳健的预测模型。其中MCP已经成为对高维数据进行变量选择的一种流行工具。该方法能有效地筛选出不重要的协变量,从而获得一个更简约的模型。除此之外,它还能减少过度拟合的可能性,并使建模过程不那么耗费算力。与lasso等方法相比,MCP方法更能产生稀疏的模型,并获得参数的无偏估计。因此将采用MCP对高维纵向数据的亚组识别问题进行变量选择。到目前为止,高维纵向数据的亚组识别并没有得到彻底的研究,也没有完整的解决方案。
综上所述,将针对高维纵向数据进行建模分析,将变量选择方法与亚组识别方法相结合,即将MCP方法引入到同质划分中,再通过二值分割的方法对回归系数之间的变点进行自动识别,系统地构建了一套关于高维纵向数据的亚组识别方法。该方法的步骤大致如下:首先对每个个体进行建模,通过MCP来获得回归参数的初始估计;然后利用二值分割的同质划分法来识别回归系数的变点,获取被识别的亚组结构;最后,在每个已识别的亚组上重新构建模型,并再次利用MCP来剔除不重要的协变量,最终得到更可靠的回归系数的估计值。
剩余部分安排如下:在第1节建立亚组模型,并基于MCP法构建了一种详细的亚组识别方法;第2节将通过统计模拟试验来评估所构建的亚组识别方法的性能;第3节通过所构建的亚组识别方法对国内各地区生产总值和产业结构进行建模,以验证所构建方法的适用性和可行性;第4节对全文进行了简单的总结。
1 亚组模型和方法
下面将对亚组模型及其参数估计和亚组识别进行讨论。
1.1 亚组模型

(1)
其中εi=(εi1,…,εiTi)′,i=1,…,n是均值为零的多元正态误差项。假设对于不同的个体的误差项是不相关的,但是εi的元素之间是互相相关的。
此外,假设亚组模型的结构为:

(2)

然而,当个体数量和观测次数相对较少时,但考虑的协变量的数量非常大时,对回归系数的估计提出了严重的挑战。因此,不使用传统的模型(如最小二乘法)来估计亚组的回归系数,而是使用MCP方法进行估计。采用MCP的损失函数作为亚组识别的损失函数,有以下优势:该方法不仅降低了协变量的维数,同时具有oracle性质;在某种情况下,可使模型能够正确的识别亚组的数目,且所估计的回归系数具有无偏性。
1.2 亚组识别和参数估计

步骤1(MCP初估) 对于每一个个体,首先通过最小化模型的带MCP惩罚项的平方损失函数来估计回归系数:
(3)
其中正则化参数λ≥0,γ>1,φλ,γ为MCP惩罚函数:
阈值算子:

定义Yi=(Yi,1,…,Yi,Ti)′,Xit,0=1,Xi, j=(Xi1, j,…,XiTi, j)′,Xi=(Xi,0,…,Xi,p)。
则目标函数(3)可用矩阵格式表示为:
(4)


对于任意1≤l1≤l2≤n,定义第一部分τ-l1+1观测的均值与最后一部分l2-τ观测均值之间的比例差函数为:
定义δ为阈值,该阈值可以由AIC或BIC选择,则识别变点的二值分割算法的步骤如下:
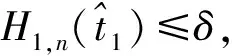


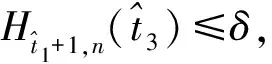

步骤3(分组建模) 使用步骤2中识别的亚组结构,通过MCP对每个亚组构建的模型表示为:
(5)
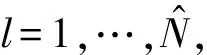

(6)
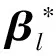
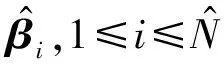
1.3 MPLS-ADMM算法
MCP是一种估计量稀疏、连续、无偏的估计方法,它通过构造一个惩罚函数对回归系数进行压缩,并使得一些回归系数为0,来构建一个简单且易于解释的模型,进而达到变量选择的目的。其主要思想是在回归系数的约束条件下,最小化模型的残差平方和,从而得到回归系数的一个稀疏估计。针对非凸函数优化问题,将采用交替方向乘子法[26](the alternating direction method of multipliers,以下简称ADMM算法),作为惩罚函数来估计每次迭代中的更新准则和停止准则。ADMM算法结合了对偶算法和最小二乘法的优点,可以在合理的计算代价下解决涉及高维数据的非光滑和分布式非凸优化问题,此外,它非常适合处理并行和稀疏优化问题,特别是统计学习的问题。ADMM 算法是一个分解协调求解的过程,将大的全局问题分解成多个较小、易求解的局部问题,并通过协调子问题的解来得到全局问题的解。其特点是:多次迭代可收敛到一个很高的精度,也可以和其他算法组合使用。用ADMM算法求解MCP简称为MPLS-ADMM算法,过程如下。
针对目标函数(4),引入一个辅助变量αi∈Rp,i=1,…,n,目标函数(4)可以写成以下形式:
(7)
其相应的增广拉格朗日函数是

(8)


(9)
经过一些代数的计算,式(9)中βi的估计值可以由式(10)获得:
(10)
其中Ip是一个p×p的单位矩阵,在实际解决问题中,当p>n的时候,直接计算线性函数(10)比较困难,因此将其分解成以下形式:
(11)
同样的,式(9)中的αi的估计值可以由式(12)获得:
(12)
其中:
给定调节参数λ和γ,关于MPLS-ADMM算法的实现步骤如算法1所示。
算法1MPLS-ADMM算法

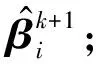


4.检查停止标准;
5.结束while;


2 模拟研究
本节通过设定多个模拟模型,运用Mento Carlo模拟方法来验证第1节中所探究的MPLS-ADMM算法的有效性。在模拟和实际数据分析中,使用BIC[27]准则来选择调节参数δ,ω表示需要估计的参数的总个数,其中BIC定义为
本节中评估了不同数量的个体和不同数量的重复测量的协变量选择、分组、估计和预测的准确性。考虑以下真实模型:
(13)
这里i=1,…,n;t=1,…,Ti,个体水平协变量
Xit=(Xit,1,…,Xit,p)=(0.1t+Xit,1,…,0.1t+Xit,p)
其中Xit,1,…,Xit,p是相互独立同分布的,即服从多元正态分布,均值为零,协方差Cov(Xit,d,…,Xit,l)=0.2|d-l|。(εi,1,…,εi,T)′是由标准多元正态分布产生的。考虑以下模拟的亚组结构:
当j=0,2,4时,

当j=1,3时,

故将所有个体分为N=4组。本节考虑以下4种情形,模拟试验参数如表1所示。

表1 模拟试验参数
在模拟试验中,假定个体的数量为n=40或80。 在不失一般性的情况下,考虑平衡设计,其中重复测量的数量对所有个体都是相等的,Ti=30或60。
为了体现所构建的亚组识别方法的优点,比较了以下7种方法,如表2所示。

表2 构建的亚组识别方法
在估计回归系数时,方法1是不考虑聚类效应的同质性拟合方法,是参数最少的方法,缺点是它完全忽略了亚组。方法2是一种异质性拟合方法,它使用个体的初始估计对βi进行估计,但不进行变点识别,这是一种参数最多的方法。方法3考虑了亚组的识别,但它对不同的协变量进行了不恰当的混合,从而产生的亚组可能不合理。
通过下列参数来评估这7种方法的协变量选择、亚组识别、估计和预测的性能。对每个案例和数据模拟200次。Lasso和elastic-net用R包glmnet实现,SCAD和MCP用R包ncvreg实现。这里的评估准则有:
TP:对模型有贡献的协变量个数;
FP:对模型没有贡献的协变量个数;
N:确定的亚组的组数;
NMI[29]:标准互信息,它是测量估计所识别的亚组结构接近真实结构的程度,范围在0~1之间,值越大表明2组之间的相似性越高;假设P={P1,P2,…}和Q={Q1,Q2,…}是关于个体{1,2,…,n}的2个不相交的组,i和j分别为该2组的亚组总数,则:
其中互信息:
熵:

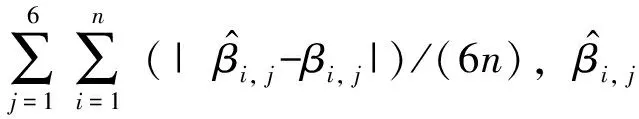
表3为200次数值模拟不同个体数量和不同测量次数中的TP和FP的中位数,从表中可知7种方法选择出的重要协变量大多为4个,与拟合方法的重要变量的真实数量相等;比较了这7种方法,可以发现方法4产生的FP(无效变量)值最少。当重复测量次数Ti增加时,无效协变量的数量降低。

表3 200次模拟中TP和FP的中位数
表4为200次数值模拟运行中N和NMI的中位数。从表4可得,同质性拟合方法(1个单组)和异质性拟合方法(n组)都不能识别个体的真实结构。方法3识别的亚组数目多于实际亚组,而方法4和方法5、6、7识别的亚组数与实际亚组数相当接近。同时NMI接近1,也支持了这个观点,这表明方法4在识别亚组方面比方法3具有更好的性能,方法5和方法6也取得了与方法4相似的结果。随着重复测量次数Ti的增加,识别真实亚组的机会也增加。

表4 200次数值模拟中N和NMI的中位数
表5为200次模拟中的MSE和BIAS的平均值,方法1相较于其他的亚组识别方法,估计和预测结果较差。除方法1外,所有其他方法都能很好地估计回归系数,偏差在0.1左右。方法4的偏差值最小,比其他的方法更准确。随着重复测量次数Ti的增加,偏差在逐渐变小。

表5 200次数值模拟中MSE和BIAS的平均值
综上所述,所提出的方法在变量选择、亚组识别、参数估计以及各种情况下的预测方面效果较好。
3 实证分析
将亚组识别的方法应用于分析全国31个省份的国内生产总值和其产业结构的关系。该数据集包括31个省份2005年到2017年的每年国内生产总值(用y表示),共包含了13年的数据,样本量共有n=31×13=403个,来源于国务院发展研究中心信息院。协变量包括第一产业(农林牧渔业x1)、第二产业(工业x2、建筑业x3)、第三产业(交通运输和仓储邮政业x4、批发和零售业x5、住宿和餐饮业x6、金融业x7、房地产业x8)及其两两之间的相互作用(单位为亿元)。因此,本数据总共有36个协变量。协变量分别用x1,…,x36来表示。
为了避免数据出现异方差的现象,采取将数据取对数的方法,并考虑随机因素对模型的影响,添加随机因子ε,则对每个省份建模可以得到:
lnyi=βi0+βi1lnxi1+…+βijlnxij+εi
其中i=1,…,31,j=1,…,36。
为了综合地了解31省份的产业结构的分布对国内地区生产总值的影响,研究了地区的哪些产业对国内生产总值的影响较大,以及每个产业对每个地区的国内生产总值的影响是否相等,即地区之间是否存在亚组。除了采用提出的亚组识别方法(方法4),也考虑了在模拟试验中提到的识别地区之间亚组的各种方法。
MCP迭代的最大次数设置为100。通过十折交叉验证来选择惩罚模型的调优参数。表6给出了确定的亚组数、亚组模型中选择的非零协变量数以及均方误差;除此之外,构造了一种类似AIC的信息准则来验证方法的有效性,将该信息准则称作AIC extension for subgroup,以下简称AIC_ES,其值为:
AIC_ES=lnMSE+2w/n
其中w为总的回归参数的数量。
由表6可知,通过计算所有方法的AIC_ES,方法4的AIC_ES最小,即本文采用的亚组识别方法的综合性能最好。
表7是方法4所确定的6个亚组的结果。表8是每个亚组最终选择的协变量和回归系数的估计值。

表6 7种方法的非零协变量、均方误差和AIC_ES值

表7 方法4的亚组结果
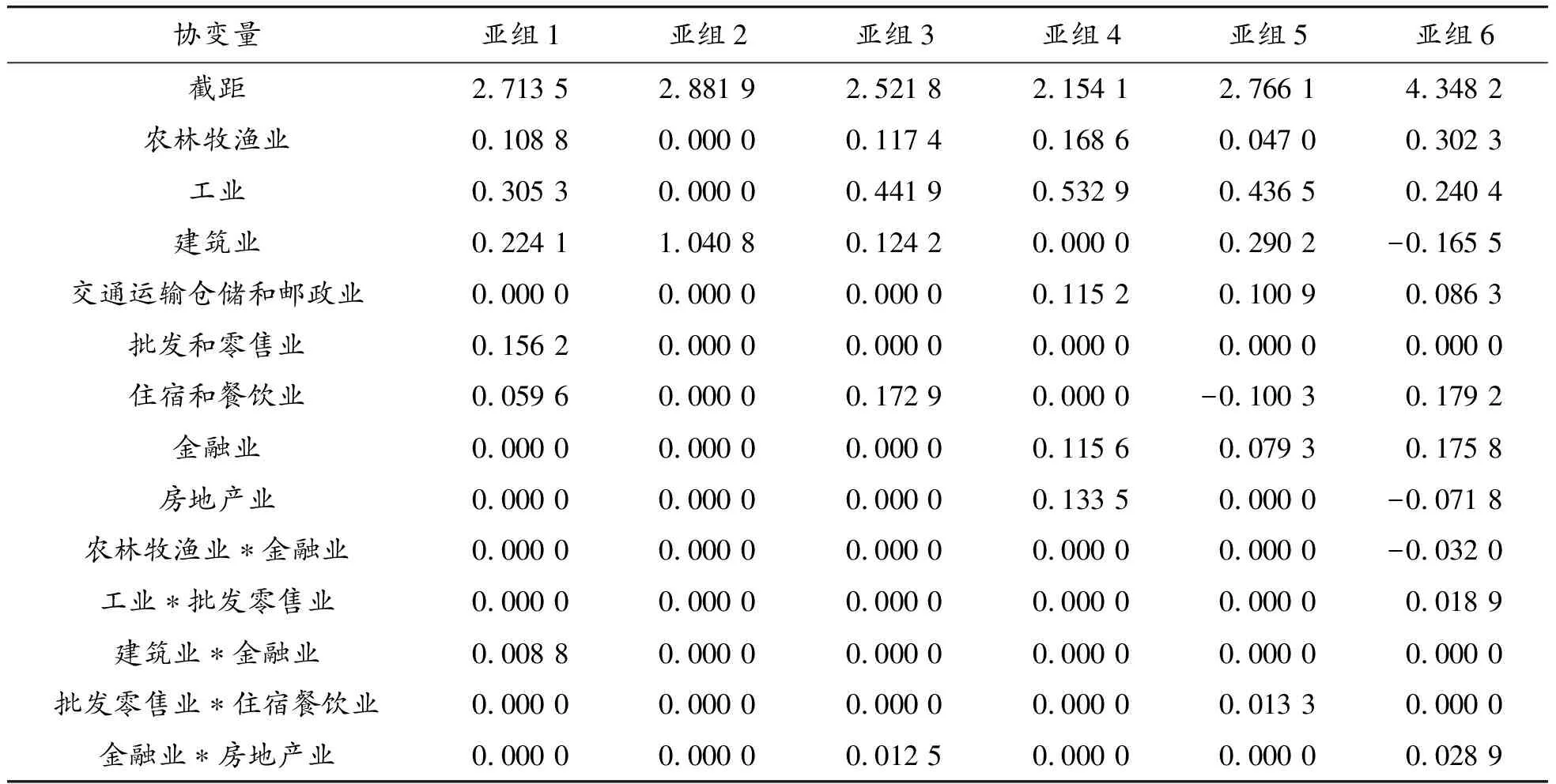
表8 选择的协变量和回归系数估计值
从表7和表8可知:① 对于亚组1,农林牧渔业、工业、建筑业、批发零售业对地区生产总值的影响比较显著,房地产业和金融业的影响最不显著;比如四川省,由于地形的限制及区域经济发展不均衡,其发展主要靠农业和工业支撑,金融业和房地产业发展相对较弱。② 对于亚组2,北京和天津的地区生产总值和建筑业的关系比较显著,其他产业相对来说并不显著;从实际情况来看,北京作为我国首都,在2003年到2017年间发展迅猛,在经历持续的旧城改造及新城建设过程中,离不开建筑业的大力支持,因此北京的建筑业对城市的发展作出了巨大的贡献,也提供了大量就业机会。③ 对于亚组3,它的工业和住宿餐饮业对于地区生产总值的影响比较显著;比如广东是一个工业大省,第二产业发达,各类轻重工业对地区生产总值的影响较大;除此之外,广东第三产业,即服务、旅游及餐饮产业完备,因此广东的住宿餐饮业比较发达。④ 对于亚组4,建筑业、批发零售业以及住宿餐饮业对地区生产总值的影响不显著,其他产业和地区生产总值的关系都比较显著;如贵州省多山,它的优势在于土地资源丰富,电力便宜,但是缺乏基础支柱产业,人才流失严重,地区相对贫穷落后,因此贵州的农林牧渔业和工业对地区生产总值的影响较大,但是由于地区落后,游客较少,住宿餐饮业相对不发达。⑤ 而亚组5的产业发展比较平衡,影响较显著的产业当属工业;如山东作为装备制造业强省,它最重要的动力引擎是从济南到青岛之间的胶济铁路沿线形成的一条工业经济带,石油、化工、金属冶炼、机械等产业聚集在这里。⑥对于亚组6,从表中可以观察到农林牧渔业、工业、住宿餐饮业、金融业对地区生产总值的影响是积极的,而交通运输业、建筑业和房地产业的影响不积极;比如河南,身处内陆,有大量的农业人口和强大的工业能力,但是没有沿海优越的地理位置,从而造成运输成本的增加,因此河南的生产总值主要受农业和工业的影响,而交通运输业对河南的地区生产总值影响较小。通过以上分析,可以得出所提出的亚组识别方法是合理有效的,且有较好的估计性能。
4 结论
构建了一种新的高维纵向数据的亚组识别方法。为了克服对高维纵向数据实现聚类效果的困难,考察了7种不同的方法对不同的个体使用不同的系数来考虑异质性,将MCP方法和二值分割的同质划分方法结合起来识别回归系数中的变点,获得被识别的亚组结构。通过模拟试验,可以直观观测到该方法的协变量选择和回归系数估计值较准确,未知参数的个数较少,并且模型的误差和偏差比其他的模型更小。这些都表明构建的方法在识别亚组和估计回归系数方面是有效的。此外,通过综合分析全国31省的产业结构数据集,实证了方法的有效性和适用性,但得到的亚组结构是基于数据驱动的结果,其经济学内涵还有待进一步研究。希望该方法今后可以有效地运用于其他纵向或面板经济数据的分析中。
构建的方法的性能在一定程度上受δ的选择所影响。δ的选择相当于变点数的选择,采用BIC准则选择最优δ。通过模拟研究表明它是一个可行可信的选择方法。考虑的是常数系数模型。当回归系数是时变的,可采用B样条估计系数函数,并使用一些特定的函数来度量系数函数之间的偏差,证明所提方法可以适用于时变系数模型的亚组识别。
