基于大样本的电动汽车行驶工况构建方法研究
2022-10-11谢光毅付江华黄泽好
陈 宝,黄 春,谢光毅,付江华,黄泽好
(重庆理工大学 车辆工程学院,重庆 400054)
0 引言

国外行驶工况较成熟,美国、欧洲、日本分别使用FTP75、NEDC、JAPAN10-15作为本国标准行驶工况[3-4]。2019年10月,中国国家市场监督管理总局,针对燃油汽车与非插电式混合动力汽车的中国自主汽车行驶工况正式发布,这将为我国车辆能耗、排放测试及产品研发提供重要依据[4-5]。
我国不同地区的交通状况、驾驶模式不尽相同,使得不同地区的汽车行驶工况存在差异,汽车能耗测试的结果与当地实际行驶工况存在较大偏差[6-7]。因此,这对于不同地区制定符合实际交通状况的车辆行驶工况十分重要。
当前针对行驶工况的构建,大部分研究学者在车型的选择上,多采用燃油车、商用车等车辆。由于电动汽车通过电机驱动,其速度、扭矩响应等方面与燃油车存在差异,针对电动车的电池能耗、续航里程等性能评估上,燃油车行驶工况不适用,所以构建电动汽车行驶工况非常重要。
综上所述,为充分反映电动汽车的实际运行特征。以成都市为例,收集了该市30辆电动汽车3个月的行驶数据,对原始行驶数据进行预处理分析、运动学片段的划分、特征参数提取,采用主成分分析法以及粒子群算法和K均值聚类算法结合,构建了成都市电动化汽车行驶工况。
1 行驶数据采集与预处理
1.1 行驶数据采集
针对车辆行驶工况构建方法的研究,尽管在试验规划、数据采集与处理、工况合成与验证等方面有所不同,但行驶工况构建的流程基本一致[18]。采用图1的流程构建成都市电动汽车行驶工况。

图1 行驶工况构建的流程框图
为兼顾不同驾驶员的驾驶习惯以及确保所构建的典型工况能真实反映道路特征,采用自主行驶法进行数据采集,即对行驶路线不做具体的规定,驾驶员可根据自身的常行程安排随机选择行驶路线[19]。选择了30辆成都市某型电动汽车,整车主要参数如表1所示。连续采集3个月的行驶数据,采样频率为1 Hz,最终获取了覆盖442.7 km、3 640 800条有效行驶数据,如图2。收集的数据主要包括行驶时间、经纬度、车速、加速度、电池SOC、电机转速、电机转矩、百公里电耗等参数。由图3行驶路线经纬度分布可知,行驶路线主要分布在经度为103.9°~104.2°,纬度为30.6°~30.7°附近,试验车辆主要成都市武侯区、成华区地段活动。
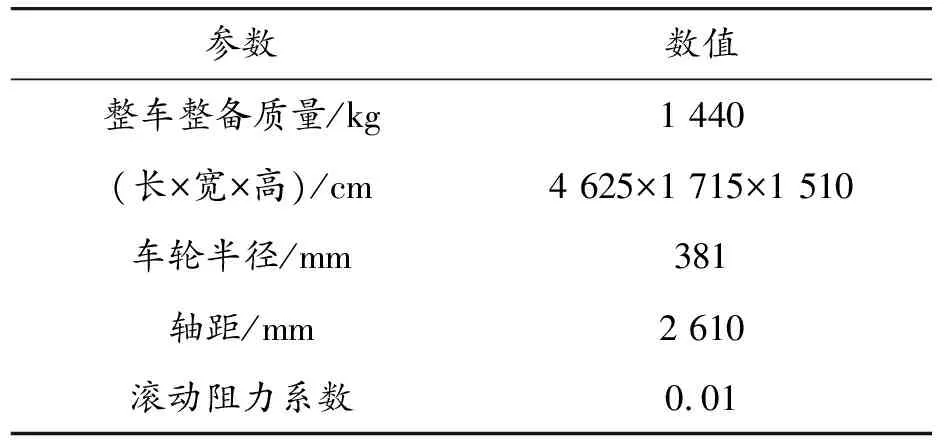
表1 某型电动汽车整车主要参数

图2 总体样本车速数据
1.2 行驶数据预处理
在数据采集过程中,采集设备精度、交通环境等因素的影响下,使得数据存在缺失、异常等现象,数据质量有所下降。为保证数据可靠性,需对数据进行预处理分析。
1.2.1GPS信号缺失数据
当车辆经过高层建筑物、隧道等路段时,GPS信号由于受遮挡导致定位不准或者不连续,车速数据有所缺失。采用插值的方法或剔除的方式进行处理后,GPS为0的数据有125个,缺失的数据有1 036个。
1.2.2怠速数据处理
由于长时间堵车或停车,采集的数据并不满足要求。将汽车断断续续行驶,最高车速小于10 km/h,视为怠速;以车速为0且持续时间小于180 s为筛选原则,超过180 s之后的数据直接剔除[20]。经处理,不正常数据达1 777 064个。
1.2.3最高速度、加速度限制
通过图4可知,汽车主要在城区或郊区行驶,车速限制在120 km/h以内,加速度限制在-6~6 m/s2以内[21]。
1.2.4速度滤波处理
由于外界因素影响下,行驶数据存在异常噪声干扰现象,使得数据存在误差。采用滑动平均滤波算法对原始数据进行滤波处理,对原始数据用一个固定长度的滑动窗口,其邻域内几个数据的均值来代替相应位置的原始数据,形成一个均值新序列[22]。
(1)
式中:y(t)为平均值,t=1,2,…,n。n为总数据长度,T为时间步长,x(t)为原始速度数据。从图5中可以看出,在滤波之前,原始速度数据存在尖点峰值,而在滤波之后,速度曲线变得平滑,滤波前后的车速曲线较吻合。

图4 滤波前后的速度数据
通过上述处理,得到有效数据数据为1 863 736个,原始速度的平均速度为11.87 km/h,平均行驶速度21.94 km/h,处理后的数据的平均速度为16.92 km/h,平均行驶速度23.30 km/h。分析其原因,在数据采集阶段,由于测试人员持续对车辆进行汽车NVH、电机等相关测试,收集的数据出现大量的停车段,在怠速数据处理时,进行删除处理。
1.3 运动学片段划分及特征参数提取
汽车行驶过程可看作由大量的运动学片段拼接而成,运动学片段是指汽车从怠速开始至下一个怠速开始之间的车速区间,由加速、减速、匀速、怠速工况构成[23],如图5。根据国标[5],由式(2)对原始数据的速度v和加速度a进行运动学片段的划分:
(2)

图5 汽车运动学片段示意图
为准确描述各个运动学片段状态和特征,选取14个特征参数用于表征汽车行驶工况特征评价体系指标(如表2);选取3个特征参数用于表征电动汽车的性能特征(如表3)。

表2 行驶工况特征参数

表3 电动汽车性能特征参数
将预处理分析后的1 863 736条行驶数据划分为8 599条运动学片段,得到特征参数矩阵M8 599×17元素,如表4。
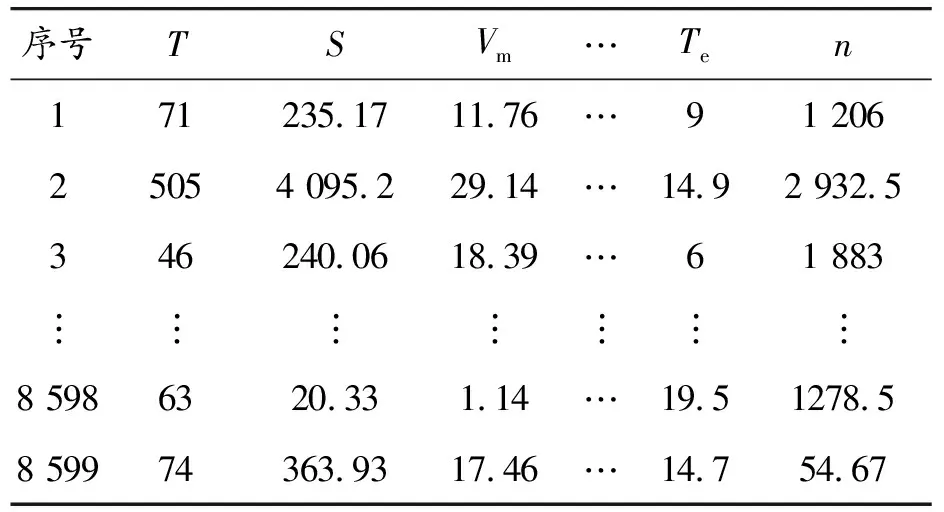
表4 运动学片段特征参数矩阵M8 599×17元素
1.4 主成分分析
在车辆行驶工况的构建过程中,有些特征参数之间并不是相互独立的,而是存在一定的相关性,应用主成分分析对特征参数进行降维,通过几个互不相关的主成分去表达原始数据的特征参数所蕴含的信息,可减少在对特征参数矩阵进行聚类分析运算的时间[24]。具体步骤如下:
1) 特征参数标准化处理。为避免特征参数单位不统一而使特征参数取值分散程度较大,影响聚类分析的结果,需对特征参数矩阵M8 599×17标准化处理,如式(3)。

(3)

(4)
2) 计算标准化处理后的矩阵Xij的协方差矩阵C。
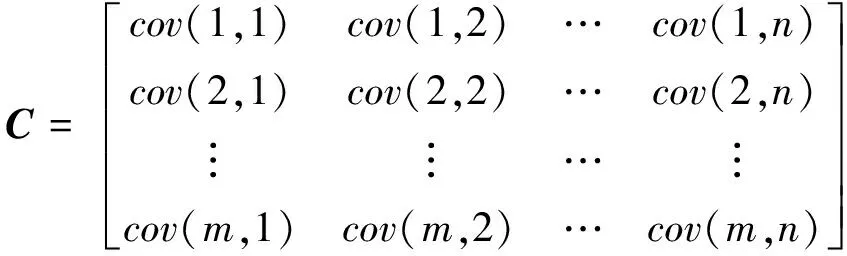
(5)
(6)
式中,cov(x,y)表示为协方差矩阵C的第x行与第y列的协方差。
3) 求解协方差矩阵C的特征值λ和特征向量φ。将特征值λ从大到小排序。计算所有特征值贡献率ω和累计贡献率β。贡献率用来衡量主成分所表达的信息,若贡献率越大,则主成分所表达的信息越多。
(7)
(8)
式中:ωi为第i个特征值的贡献率,βk为前k个特征值累计贡献率,选取累计贡献率大于80%或特征值大于1的主成分[12],并确认主成分的个数c。
4) 计算主成分F。
(9)
式中,φi为第i个特征值所对应的特征向量。
综上,对所提取的运动学片段的特征参数矩阵M8599×17进行主成分分析,得到各个主成分的特征值、贡献率以及累计贡献率,如表5所示。

表5 各主成分贡献率及累计贡献率
根据主成分个数筛选原则,前5个主成分的累计贡献率已达到80.68%。各个主成分特征值分布如图6,当主成分为4时,特征值曲线出现拐点,当主成分个数小于4时,特征值下降的幅度骤减,当主成分个数大于4时,随着主成分个数的继续增大而特征值趋于平缓,由于第五主成分的特征值大于1,综上,选取5个主成分。主成分载荷矩阵元素如表6所示。
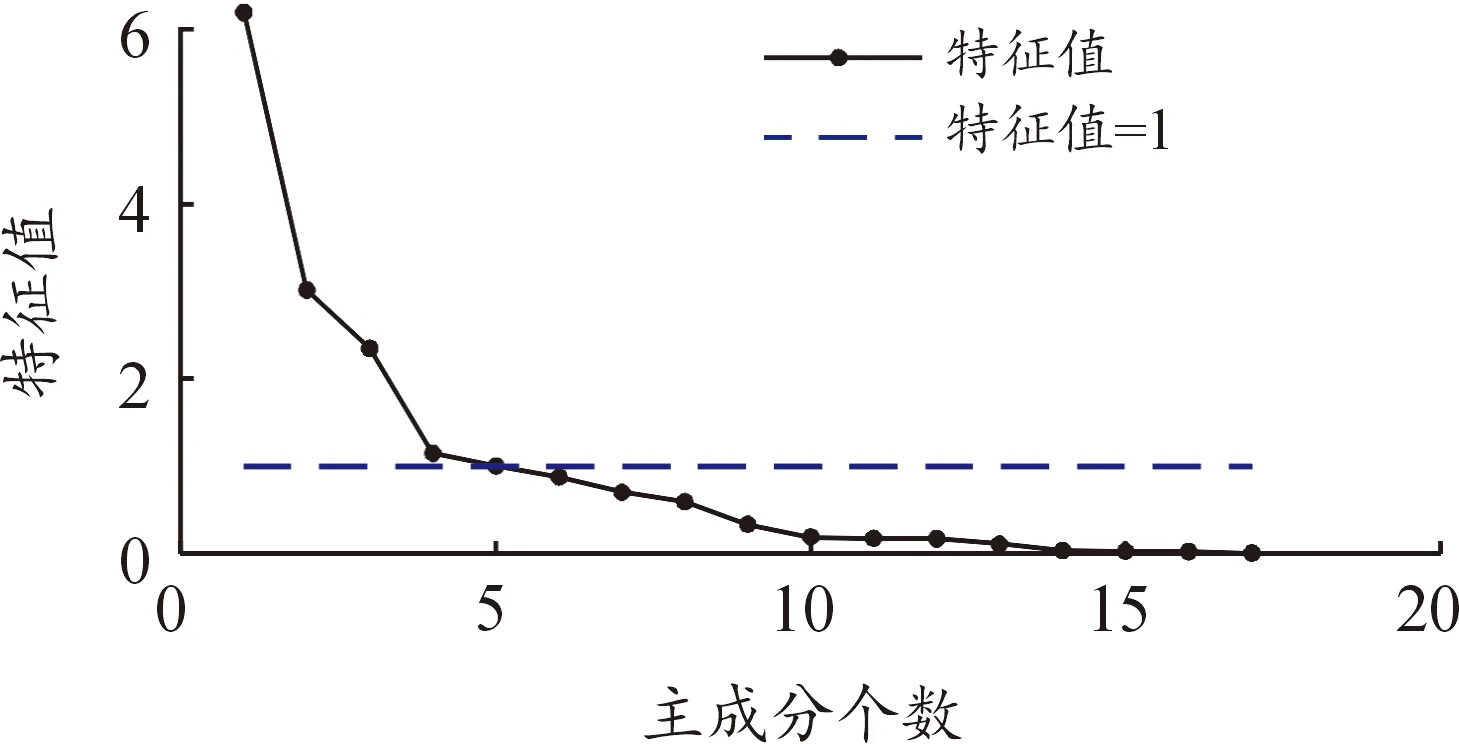
图6 主成分特征值分布
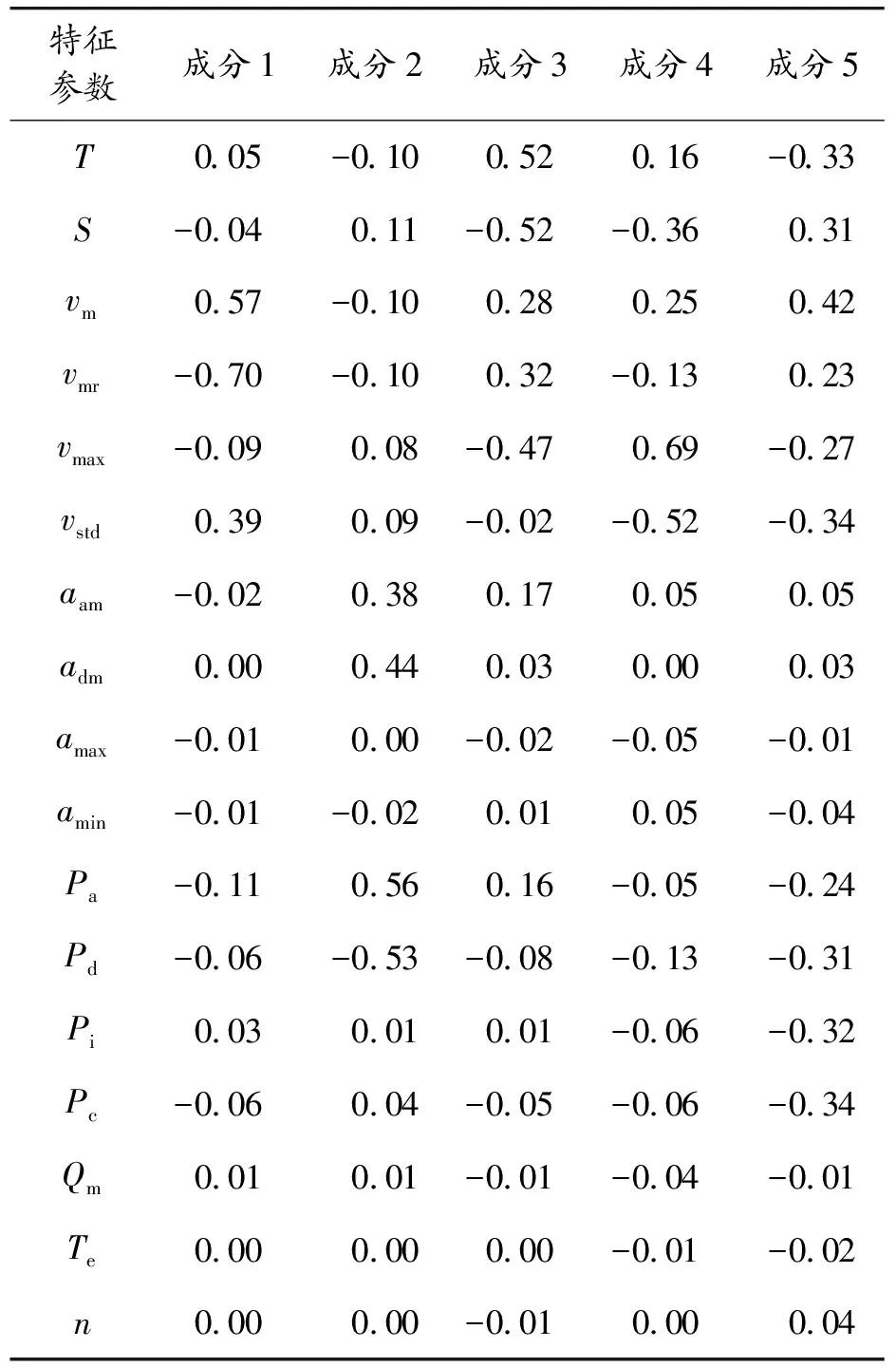
表6 主成分载荷矩阵元素
第一主成分主要反映的是平均速度、速度标准差;第二主成分主要反映的是平均加速度、平均减速度、加速时间比;第三主成分主要反映的是运行时间;第四主成分主要反映的是最大速度,第五主成分主要反映的是运行距离、平均速度、平均行驶速度。基于主成分得分矩阵N8599×5元素,如表7。采用粒子群算法与K均值聚类算法结合的方式,对主成分得分矩阵进行聚类分析。

表7 主成分得分矩阵N8 599×5元素
1.5 改进的K均值聚类分析
K均值聚类(k-means clustering,kmc)通过选定聚类数目k与初始聚类中心,计算各样本数据与聚类中心之间的最小距离,根据距离远近,分配样本数据到最近的聚类中心,不断迭代选取新的聚类中心并调整各数据类别[13]。
由于K均值聚类算法受初始聚类中心影响,其较弱的全局搜索能力易陷入局部最优,聚类个数凭经验选取。采用肘部法和Silhouette轮廓系数[12]结合选取聚类数目,结合粒子群算法(particle swarm algorithm,PSO)全局搜索能力,优化初始聚类中心[25]。由于系数和最大速度等参数选取不当,会影响粒子群算法收敛速度和精度。采用调整惯性权重来平衡全局搜索和局部搜索,再使用K均值聚类算法,使初始的聚类中心之间尽可能的远,进行分类。
基于粒子群K均值聚类算法(PSO_kmc)基本步骤如下:
1.5.1聚类数目的确定
1) Silhouette轮廓系数函数
(10)
式中:α(i)为同一簇中,样本i与其它样本的平均距离,即簇内不相似度,b(i)为样本i的与相邻最近的一簇内所有点平均距离的最小值,即簇间不相似度。s(i)为轮廓系数,将所有点的轮廓系数求平均,就是该聚类结果总的轮廓系数,s(i)接近1,则说明样本i聚类合理;当s(i)为0时,则代表两个簇中的样本相似度一致,两个簇为同一个簇;
2) 肘部法(误差平方和SSE)
随聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐升高,误差平方和SSE会逐渐变小。当k小于真实聚类数时,由于k的增大会增加每个簇的聚合程度,故SSE的下降幅度会很大。当k接近真实聚类数时,再增加k,SSE的下降幅度会骤减,随着k值的继续增大而趋于平缓。
(11)
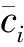
通过处理分析,肘部误差平方和SSE如图7,当聚类数目小于3时,误差平方和急剧下降,聚类数目大于3时,误差平方和趋向于平和。平均轮廓系数值如图8,聚类数目为3时,平均轮廓系数最高。轮廓系数曲线如图9,不同类别下轮廓系数值均有少量负值出现,聚类数目为3时,各类数量分布较为均匀。综上,选取聚类数目为3。
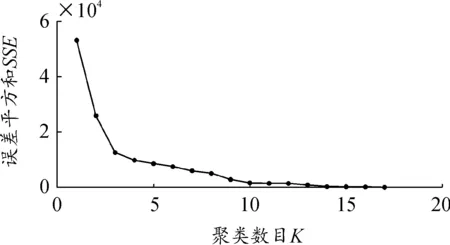
图7 肘部误差平方和SSE
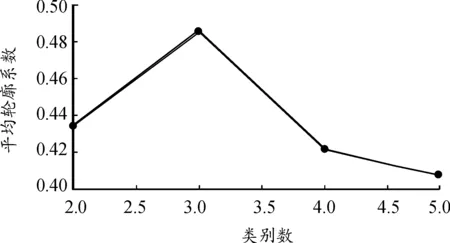
图8 平均轮廓系数值
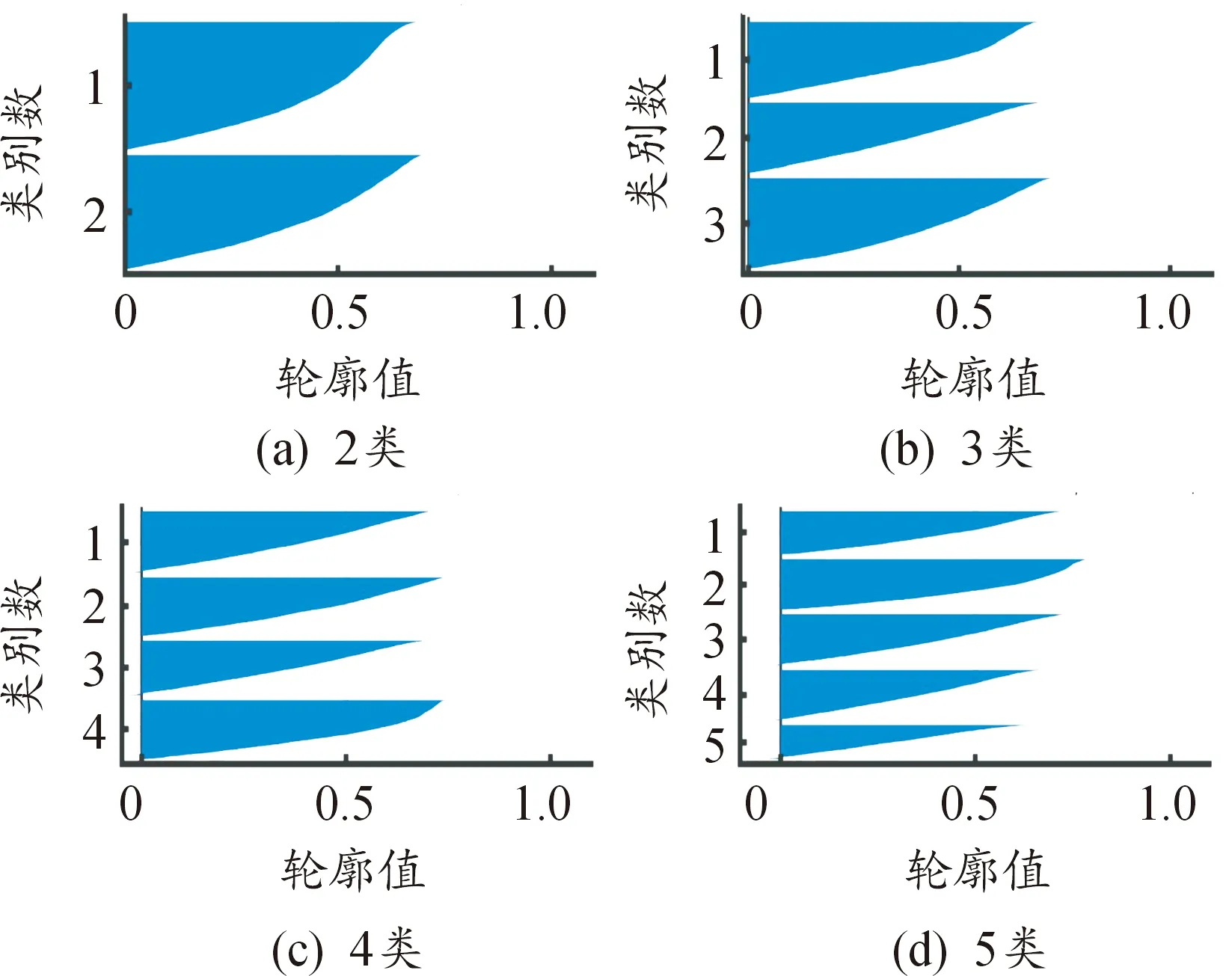
图9 轮廓系数曲线
1.5.2粒子群算法优化K均值聚类中心
1) 初始化种群。随机产生粒子初始聚类中心,初始位置xi和速度vi,学习因子bi。
2) 适应度值fi计算。由式(12)计算各类内数据到聚类中心欧式距离fi,作为粒子的个体极值,最小的适应度值作为全局极值。
(12)
式中:i为数据cij所在的类,m为第i个类数据个数,ci为第i类数据聚类中心。
3) 通过式(13)惯性权重实现粒子从粗略的全局搜索到局部的精细搜索,式(14)(15)更新整个粒子群的粒子位置与速度,计算更新后粒子的适应度值。
(13)
(14)
xi(t)=xi(t-1)+vi(t)
(15)
式中:wmax、wmin分别为权重最大和最小值,fbest、fbad分别为粒子最好与最差的适应度值。rand1、rand2为0~1中的随机数,Pbesti为粒子最佳位置,Gbestd为全局极值。
4) 由式(16)粒子群的适应度方差δ2判断当前粒子是否达到收敛状态。fa为粒子群的平均适应度。当δ2小于设定阈值0.1时,则群体趋于收敛。选择10个最优粒子,进行k均值聚类。
(16)
5) 计算每个样本与当前聚类中心的欧氏距离,根据距离的大小,进行粒子聚类划分。在轮盘法基础上选取下一个聚类中心,更新粒子的适应度值。
6) 判断适应度值是否最优或达到最大迭代次数,则结束。
由表8,图10、11、12可得出,第1类中平均行驶距离最短,约77 m,怠速比例最高,速度分布在0~10 km/h,可反映出在城市拥堵路段上运行时的交通特征。第2类中速度分布在10~20 km/h、加速、减速、匀速、怠速时间比较为均和,运行距离适中,可反映出在城市主干道上运行时的交通特征。第3类速度分布在20~40 km/h,运行时间、行驶距离、最高车速、平均行驶车速、最大加速度、最大减速度高于其余两类,可反映在城市郊区道路上行驶的交通特征。

表8 各类特征值参数
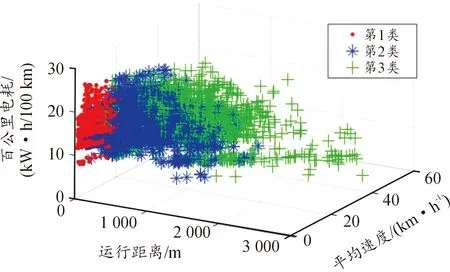
图10 各类运行距离-平均速度-百公里电耗分布
2 行驶工况构建
根据k均值聚类算法定义,每一类别中的样本与其聚类中心的距离越小,则表明该样本越能反映本类别的特点[12]。所构建的成都市城市电动汽车行驶工况时长为1 500 s,根据每类总的行驶时间在总体数据中所占的时间比,可以计算出各类在最终拟合工况中所占的时间,再根据每一类与其聚类中心的聚类从小到大排序,筛选出候选片段[14]。根据聚类结果,第一、二、三类的运动学片段数分别为1 462、4 188、2 949。
(17)
式中:Ti为第i类在最终合成的汽车行驶工况中的时间长度,i=1,2,3,k为类别数,k=3,tij为第i类的第j个片段所持续的时间。
通过计算,第一类、第二类、第三类在最终合成后的行驶工况中的时间长度分别为215、668、619。选取的片段分别为3条低速片段、10条中速片段、7条高速片段。最终构建了持续时间为1 502 s、最高车速为58.4 km/h、总行程为6.723 km的成都市电动汽车行驶工况,如图13。

图13 成都市电动汽车行驶工况
3 工况验证与分析
3.1 运动学片段特征参数误差分析
通过粒子群算法与K均值聚类结合(pso_kmc)与传统K均值聚类(kmc)进行工况构建对比,通过式(18)计算了成都市与样本数据特征参数的相对误差。
(18)
式中:Ck、Uk分别构建工况和原始样本数据的第k个特征参数,n为特征参数个数。
由于最高车速、最大加速度、最大减速度偶然性较大,将其进行对比的意义不大。由表9可知,基于粒子群和K均值聚类 (pso_kmc)行驶工况曲线与样本数据特征参数相对误差均在5%以下,各特征参数值的平均相对误差为2.28%。而通过同样的方式采取传统的K均值聚类算法(kmc)所构建的工况误差相对较大,各特征参数值的平均相对误差为5.82%,由于K均值聚类受初始聚类中心的影响,较弱的全局搜索能力陷入局部最优,致使误差较大。因此,结合粒子群算法的K聚类提高了工况构建精度。

表9 部分特征参数相对误差
3.2 速度—加速度联合分布
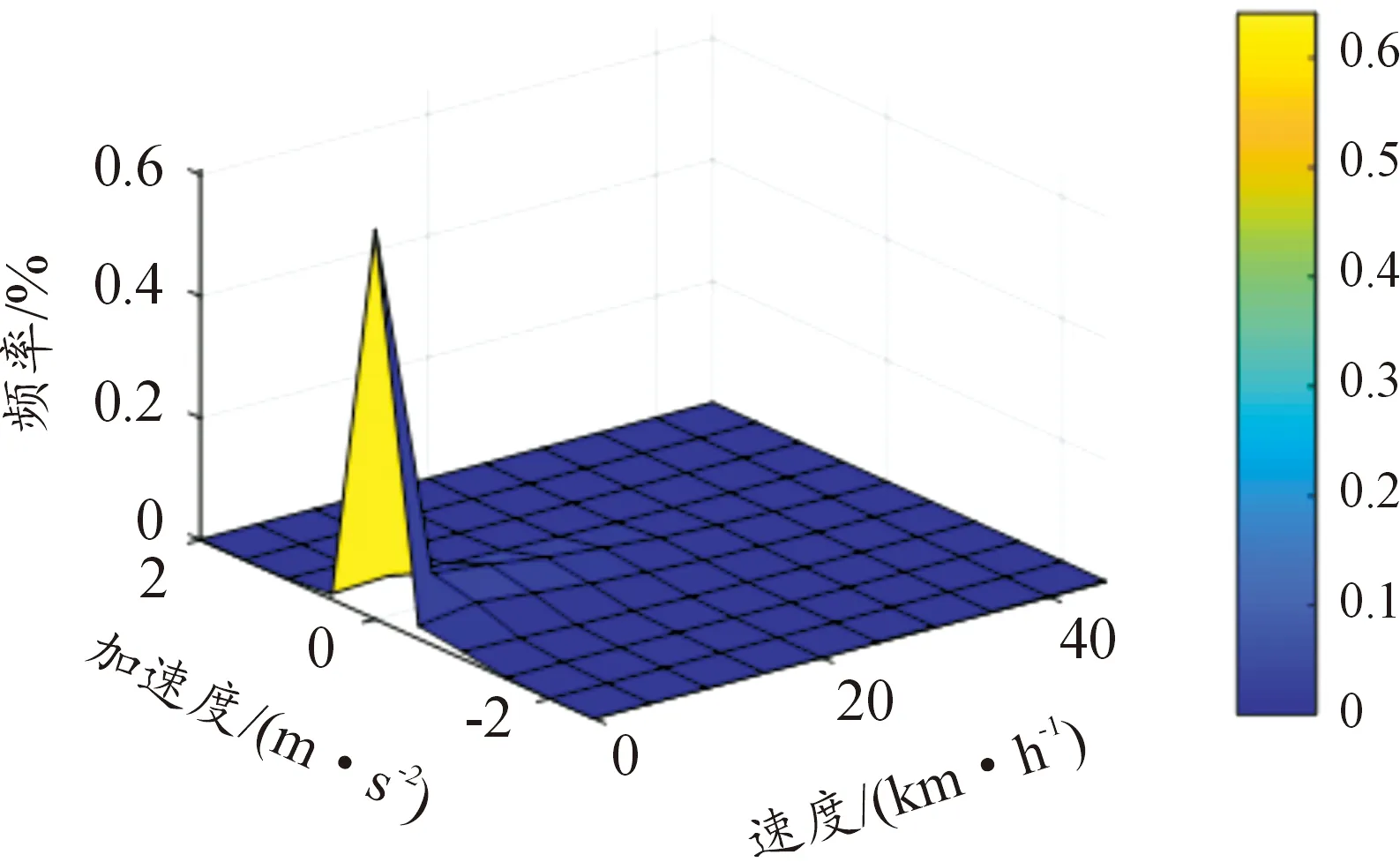
图14 原始样本数据速度加速度联合分布
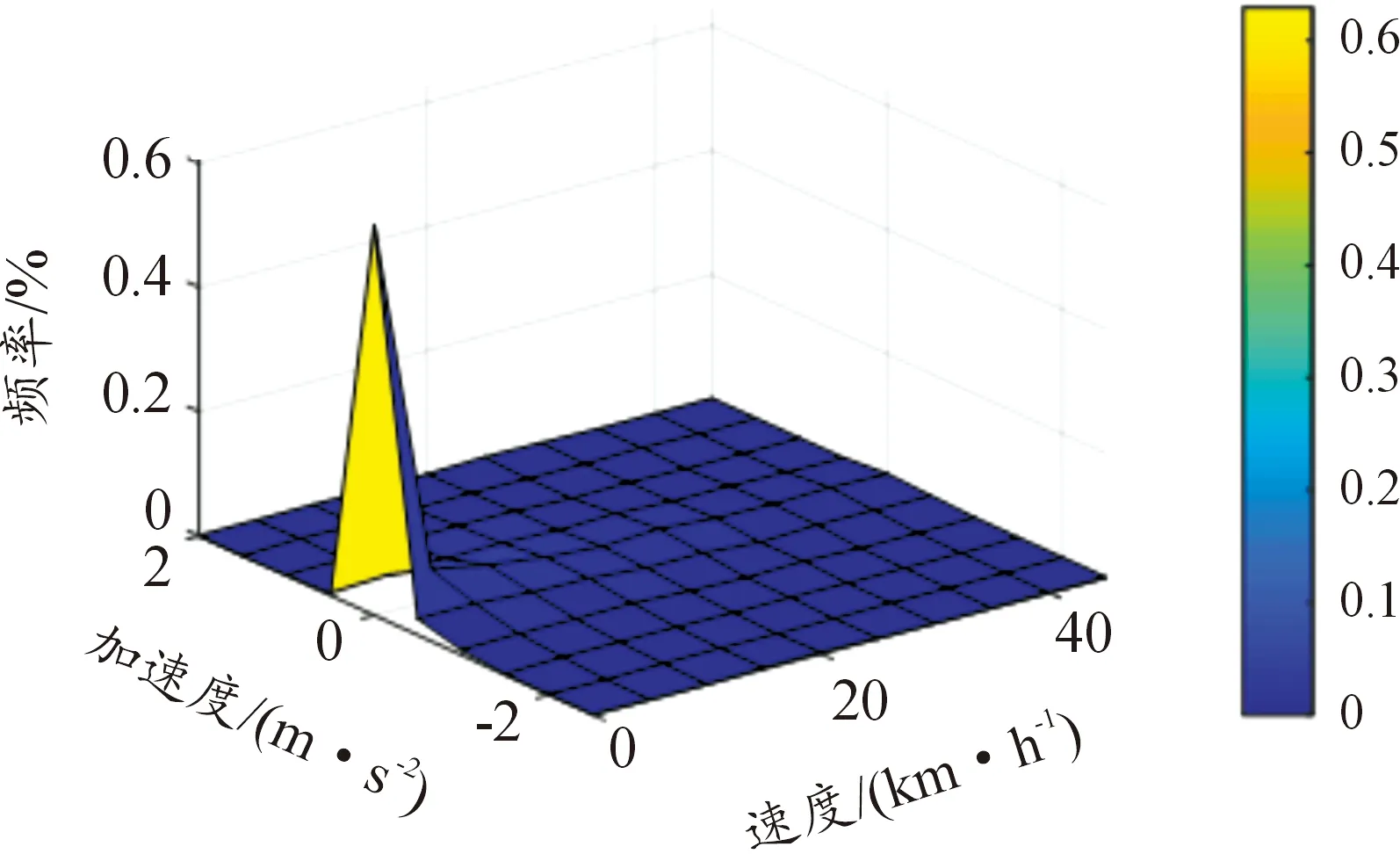
图15 行驶工况速度加速度联合分布
3.3 典型工况对比
由表10,通过比较成都市电动汽车行驶工况与欧洲行驶工况NEDC[10]、中国的乘用车CLTC-P工况[4]以及合肥[26]、西安[27]的电动汽车行驶工况的特征参数,成都市电动汽车行驶工况的平均速度,加速、减速、匀速、怠速时间比等存在显著差异,成都市电动汽车行驶工况具体特征表现为:平均速度较低,怠速比例高、匀速比例低。

表10 国内外几种循环工况特征参数
分析其原因:① 我国不同地区的交通状况不尽相同,使得不同地区的汽车行驶工况存在差异; ② 电动汽车与燃油车在动力系统的差异导致了车辆行驶特征的不同,电动汽车由于电机的低速恒扭矩且电动响应迅速等特性,相比于燃油车,电动汽车的起步较快且起步时间更短。若直接采用中国乘用车CLTC-P或欧洲行驶工况NEDC进行电动汽车能耗测试,则不能准确的反映成都市电动汽车实际行驶特征。
4 结论
针对研究过程中的3 640 800条原始车速数据,剔除了GPS缺失、怠速异常等数据,引入滑动平均滤波滤除干扰信息,得到1 863 736条有效车速数据,提取8 599个运动学片段并选取了17个特征参数进行研究,得出结论如下:
1) 通过主成分分析对特征参数矩阵进行降维处理,采用轮廓系数和肘部法结合的方式确定聚类数目,结合粒子群算法优化K均值聚类中心,最终构建了时长为1 502 s、最高车速为58.4 km/h、总行程为6.723 km。
采用此方法所构建的行驶工况精度更高,与样本数据库特征参数相对误差均在5%以下,平均相对误差为2.28%。
2) 所构建的成都市电动汽车行驶工况与国内外城市循环工况比较发现差异较大,说明汽车行驶工况受特定地域的道路交通影响,采用燃油车行驶工况不适用于电动汽车的性能评估,后续有必要对电动汽车行驶工况构建展开研究。
