基于投票机制的神经架构搜索
2022-09-17杨军张景发
杨军,张景发
(1.兰州交通大学 电子与信息工程学院,甘肃 兰州 730070;2.兰州交通大学 测绘与地理信息学院,甘肃 兰州 730070)
1 引言
卷积神经网络(Convolutional Neural Network,CNN)显著提高了各种视觉分析任务的性能,包括图像分类、人脸识别和目标检测等领域[1],这得益于其良好的模块设计和复杂的网络架构。VGGNet[2]提出使用小的卷积滤波器并堆叠一系列卷积层来实现更好的性能,RESNet[3]引入残差块以利于更深层次神经网络的训练,PointNet[4]使 用 多 层 感 知 机(Multilayer Perceptron,MLP)来学习单个点的特征,并利用T-net对全局信息进行编码,实现了数据及特征的有效对齐,在点云模型识别任务上做出了开创性的工作。尽管这些人工设计的网络可以有效地完成给定数据集的模型识别和分类任务,但在网络架构的设计过程中依赖专家经验和大量的超参数调整,且计算复杂度比较高,设计出的网络架构很难达到最优。因此,研究人员提出了神经架构搜索(Neural Architecture Search,NAS),其目标是通过选择和组合预定义搜索空间中的各种候选操作,自动找到最优的网络架构。
NAS方法主要包含3个基本模块:搜索空间、搜索策略和性能评估策略。预定义一个搜索空间,并使用特定的搜索策略在搜索空间中寻找网络架构,然后通过性能评估策略对搜索到的网络进行测试,根据测试结果再次迭代,直到找出最优的网络架构。其中,搜索空间定义了NAS算法可以搜索到神经网络的类型,同时也定义了如何描述神经网络结构。搜索通常包括两种类型,直接搜索整个网络体系架构(宏搜索)或搜索Cell结构并以预定义的方式堆叠此Cell结构(微搜索)。搜索策略定义了如何找到最优的网络架构,主要包括强化学习、遗传算法和基于梯度的优化算法。性能评估策略用于度量搜索到网络体系架构的性能优劣,包括低保真度、早停、代理模型和权值共享等方法。
目前,NAS在计算机视觉和模式识别领域得到了广泛应用,有效减少了人工干预。文献[5]利用强化学习方法训练一个循环神经网络(Recurrent Neural Network,RNN)控制器,自动搜索一个可以应用于大规模图像分类和目标检测的神经网络架构,但该方法依赖大量的硬件资源,存在计算量较大、时间成本较高的问题。文献[6]利用Softmax函数放缩搜索空间使目标函数可微,通过高效的梯度反向传播算法进行架构搜索,大大提高了NAS的效率,然而由于GPU内存消耗随着候选搜索集的大小呈线性增长,该方法仍存在GPU内存消耗过高的问题。文献[7]在跳跃连接之后使用dropout策略,并在优化过程中限制跳跃连接的数量,但此方法搜索到的架构深度在训练过程中逐渐增长,搜索和评估场景中的架构深度之间存在巨大差异。文献[8]提出了一个基于Gumbel-Max策略的可微采样器,一次只对一个架构进行采样,减少了内存的使用,但搜索到体系结构的性能低于基于遗传算法的方法。
为了解决现有NAS算法自动搜索到的网络架构与评估的网络架构之间存在较大差异的问题,本文提出基于投票机制的神经架构搜索(Neural Architecture Search Based on Voting Scheme,NAS-VS)算法,以多策略融合的方法自动搜索出最优的Cell结构;利用小批量训练数据上测试的训练损失作为性能估计器,只在性能表现良好的候选网络架构中进行采样,以解决均匀采样会导致网络训练效率低的问题;利用组稀疏正则化策略的路径选择方法,解决Cell结构中各节点之间候选操作权重相近时路径难以选择的问题。
2 研究现状
为了自动高效地搜索最优的神经网络架构,大量架构搜索算法被提出,主要分为三类:基于强化学习的方法、基于遗传算法的方法和基于梯度的算法。其中,基于强化学习的方法从搜索空间采样网络架构,并相应地训练控制器。基于遗传算法的方法首先随机初始化若干个子网络作为初始解,计算其适应度,并使用变异和交叉的遗传操作来生成新的网络架构。基于梯度的算法对共享权重和结构参数进行优化,大大降低了对计算资源的需求,提高了搜索效率。
2.1 基于强化学习的方法
文献[9]首次将强化学习应用于NAS,利用一个循环神经网络作为控制器,通过强化学习的方法来搜索子网络,不断更新RNN控制器的参数,直到搜索到符合要求的网络架构;但由于该方法设计的搜索空间较大,因此需要训练数以万计的网络架构,计算资源消耗巨大。为解决该问题,文献[10]提出了搜索Cell结构或者block结构,并将其堆叠以得到最终的网络架构,大大降低了搜索空间的复杂性。文献[11]将基于强化学习方法搜索到的小模型按比例放大,沿着深度、宽度和输入分辨率3个方向构建大模型,从而提高了搜索较大数据集网络架构的准确率。文献[12]提出了一种参数共享的高效NAS算法,通过策略梯度训练控制器,使所有网络架构共享参数,进一步减少了获得奖励的训练步骤。然而,基于强化学习的方法需要枚举大量的网络架构,并从头开始训练其相应的模型参数以获得准确的性能估计,因此计算资源需求大。
2.2 基于遗传算法的方法
遗传算法为NAS提供了另一个方向,文献[13]将遗传算法应用于ImageNet,在相同的硬件条件下,其搜索速度快于强化学习的方法,特别是在搜索的早期阶段。搜索算法迭代评估从群体中性能最佳的体系结构演化而来的少量子网络架构以加速搜索,但仍需要训练数千个单独的体系结构。因此,虽然遗传算法适用于NAS,但它面临着与强化学习方法相同的问题,即训练过程需要大量计算资源。为了解决此问题,文献[14]提出单路径聚合网络架构搜索算法,利用自顶向下、自底向上、融合-分裂、尺度均衡、跳跃-连接和无操作6个异构信息路径来构建搜索空间,并通过进化算法来寻找最优候选路径。然而,进化算法只允许变异和交叉操作,没有考虑层间关系,导致搜索到的网络架构不是最优的。
2.3 基于梯度的方法
基于梯度的方法利用Softmax函数将搜索空间从离散松弛化为连续,并通过梯度下降算法来优化网络架构,大大降低了计算资源使用,但其训练过程需要遍历搜索空间中的所有候选操作,难以直接在搜索空间中搜索大型网络架构,因此,基于梯度的方法大多在搜索时使用浅层模型作为代理任务,并在评估时多次堆叠搜索到的Cell结构以构建更大的模型。为了改进基于梯度的方法,文献[15]提出了一种基于采样的方法来学习体系结构上的概率分布,不断在搜索空间中采样候选网络,以获得性能优秀的网络架构,然而由于不停地采样,计算资源消耗也比较大。文献[16]通过路径二进制化探索没有特定代理的搜索空间,利用one-shot方法和参数共享来加速NAS搜索过程。文献[17]以最小化权重共享子网络和独立网络之间的评估差异性为目标,引入渐进式搜索空间缩减策略,利用贪心算法的路径过滤技术,使超网更加关注那些性能优异的路径。文献[18]以贪婪的方式修剪搜索空间中的候选操作,随着排名较低的候选操作被移除,搜索空间逐渐缩小,搜索专注于剩余的候选操作以进行充分地训练和评估。
综上所述,NAS研究目前主要存在的问题有:(1)在搜索空间中选择候选网络架构时一般使用均匀采样,而每个候选网络架构的性能存在差异,如果对性能较弱的网络架构进行采样和训练,由于所有网络权值共享,会干扰其他网络架构,最终搜索到的最优网络架构性能不佳;(2)在路径选择过程中,由于一些候选操作的权值相近,无法准确地对其进行排名,搜索与评估时期选择的最优模型之间容易存在较大的差异。本文提出NAS-VS算法,使用小批量训练数据上测试的训练损失作为性能估计器,对训练损失较小的候选网络进行采样,并以集成学习的思想融合多种路径选择算法,进一步提高网络架构的性能。
3 基于投票机制的神经架构搜索
3.1 网络整体架构
本文采用了基于梯度的架构搜索策略,搜索一个Cell结构作为基本的模块,并通过堆叠该Cell结构来构建最优的网络架构。为了验证搜索到的最优网络架构在评估阶段中是否也是最优,引入肯德尔系数[19]来评估这一过程。肯德尔系数是衡量两个排名相关性的常用指标,计算公式如下:
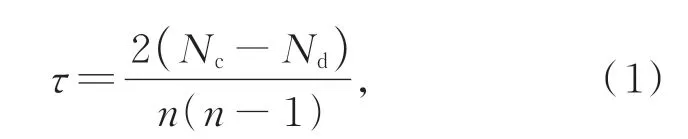
式中:n表示排名中的样本数量,Nc表示在两个排名中顺序一致的数量,Nd表示在两个排名中顺序不一致的数量。肯德尔系数τ是介于-1到1之间的数字,其中-1表示两个排名完全负相关,1表示两个排名完全正相关,0表示两个排名完全独立。
使用DARTS算法在modent40数据集上进行了10组实验,得到了10个不同分类精度的网络架构,根据分类精度对这10组实验搜索出的最优网络进行了排名。同理,将这10个最优网络在验证集上的精度也进行了排名,对比搜索阶段的性能排名和评估阶段的性能排名,理想情况下,利用NAS方法搜索到的网络架构应具有较高的肯德尔系数。从图1可以看到,肯德尔系数只有0.16,即搜索阶段得到的最优网络架构在测试时并不是精度最高的网络,这是由于权重共享过程中随着网络的逐渐收敛,搜索到的网络会更加地契合源数据集,而不是迁移之后的目标数据集,且在搜索过程中Cell结构的路径选择并不是最优的,导致自动搜索的网络架构性能没有达到最优。为了缓解这一问题,需要改进的核心问题有:(1)搜索和评估阶段的差异;(2)权重共享的负面影响。因此,本文提出了NAS-VS算法。首先,以小批量训练数据上测试的训练损失作为性能估计器,对训练损失较小的候选网络进行采样,以提高训练效率;其次,利用可微架构搜索策略、组稀疏正则化策略和噪声策略分别对Cell结构中各节点之间的路径选择进行初步判定;最后,通过加权投票方法对初步判定的路径进行再次选择,进一步提高网络架构的性能,搜索出最优的Cell结构。整体网络框架如图2所示。
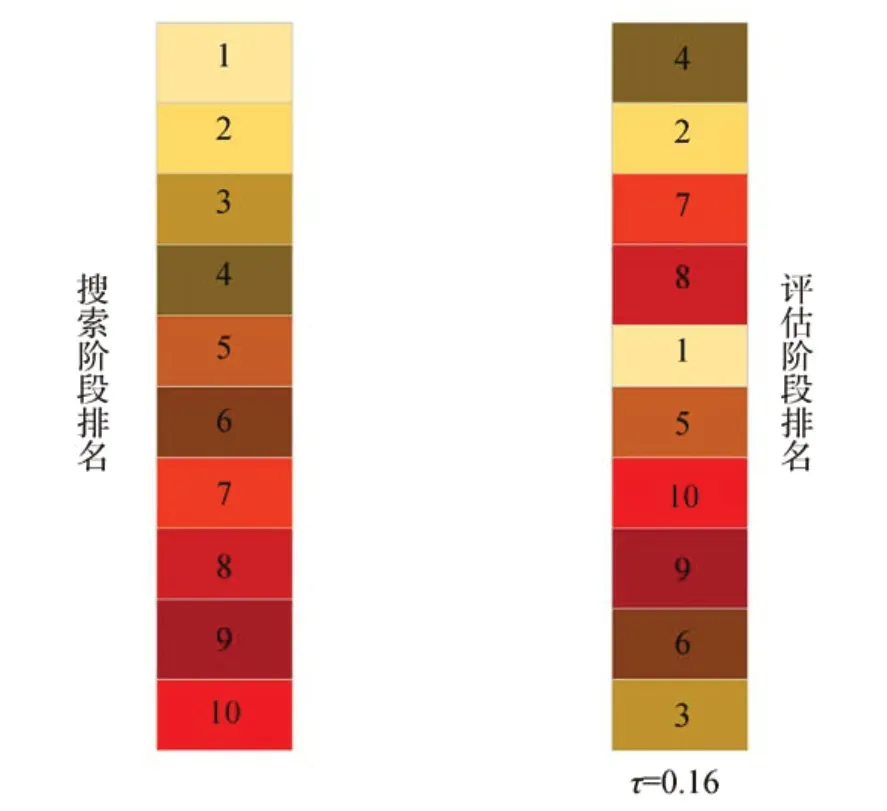
图1 搜索与评估阶段的肯德尔系数Fig.1 Maurice Kendall coefficient in search and evaluation phases
3.2 性能估计器
首先在搜索空间中对候选网络进行采样,然后通过随机梯度下降算法对每个样本进行优化,以便候选网络获得更好的性能。通常来说,整个NAS过程可以分解为两个相对独立的阶段:无约束预训练阶段和资源受限阶段。在无约束预训练阶段,通过权值共享联合优化搜索空间中所有可能的候选网络,其目标是学习权重共享网络的超参数,如式(2)所示:
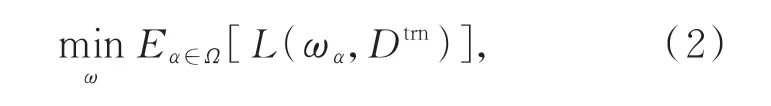
式中:ω为网络中的共享权重,ωα是由体系结构α规定的一个子网络的权重,Ω为搜索空间,L(·)为损失函数,Dtrn为训练数据。期望项E通常由n个均匀采样的网络架构来近似,并用随机梯度下降算法来求解。采样到的较大的网络架构和较小的网络架构都会通过式(2)联合优化,从而提高网络的整体性能。
在资源受限阶段,在给定的资源约束下搜索出性能最好的网络架构,经过式(2)的预训练,所有的候选网络架构都得到了充分的优化,这一步就是通过搜索算法找出最优性能的网络架构,如式(3)所示:
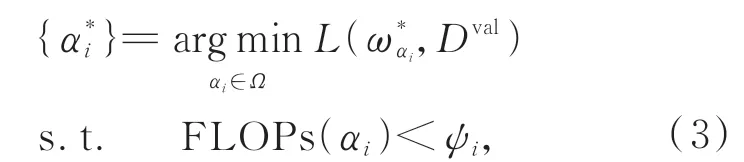
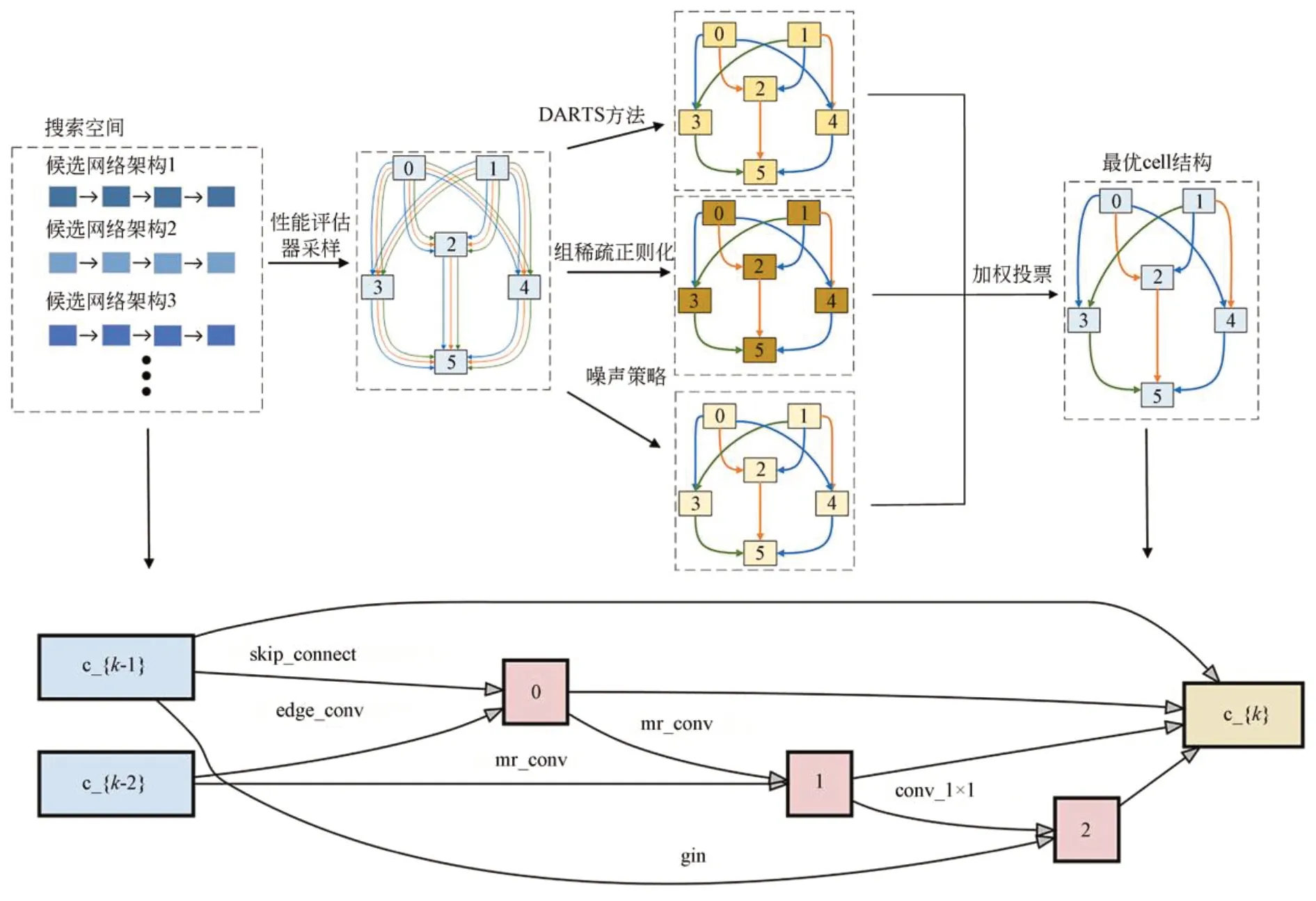
图2 整体网络框架Fig.2 Overall network frame
式中:是在上一阶段学习到的最优权重共享参数,ψi是给定的资源约束阈值,是最优权重参数对应的体系结构,Dval表示验证数据,FLOPs(αi)表示架构αi消耗的计算资源。由于不需要重新训练或微调,该阶段的总体搜索成本通常较低。
尽管已经在这两个相对独立的阶段取得了良好的效果,但在搜索过程中采样时将每个候选网络视为同等重要,这在一定程度上会偏向于性能较差的网络。为了解决此问题,本文利用小批量训练数据上测试的训练损失作为性能估计器,来学习搜索空间中各候选网络架构的概率分布,找出符合要求的一组模型,并将采样的重心集中在这组模型上。首先,引入操作选择的先验分布P(α|A),其中A表示选择不同网络架构的概率。单个网络架构α可以表示为{αi}的离散选择,并从P(α|A)中采样。因此,网络架构搜索转化为在一定监督下的学习分布P(α|A)。由于不同层的选择是彼此独立的,对网络架构α进行采样的概率如下:
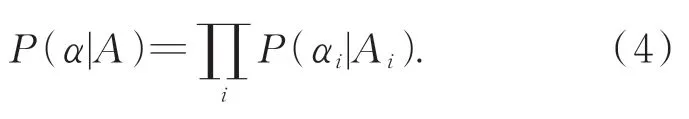
在训练过程中,使用贝叶斯蒙特卡罗法优化连续网络架构参数α,即有:
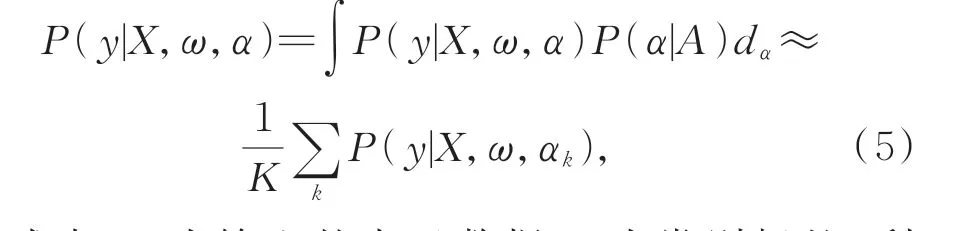
式中:X为输入的点云数据,y为类别标签,利用采样的K个架构和其平均最大似然估计来近似P(y|X,ω,α)的最大似然估计。对于采样的体系结构,通过估计梯度∇αlogP(y|X,ω,α)和∇ωlogP(y|X,ω,α)共同优化体系结构参数α和模型权重参数ω。
然后,按照小批量训练数据上测量的训练损失来决定要采样的网络架构,即在每次迭代中,从P(α|A)中采样K个架构{α1,···,αK},用R(α)表示模型α的性能估计器,权重为ωα。性能估计器R(α)的验证损失为:
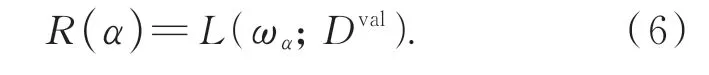
本文将原始训练数据集分成90%的训练集和10%的测试集,然后对子样本训练集进行无约束预训练,将训练迭代次数设置为50,训练完成后,随机采样1 024个子网络,并在子样本的测试数据集上测试它们的性能。最后,利用性能估计器R(α)对这1 024个子网络进行筛选,根据测试结果选择训练损失较小的前256个子网络作为最终需要采样的网络架构。图3为本文利用性能估计器采样与均匀采样的对比图,从图中可以看出,本文算法可以有效地从搜索空间中采样到性能良好的候选网络,从而提高超网的整体性能。
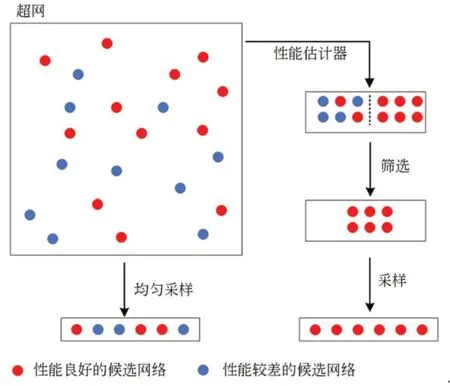
图3 采样方式对比Fig.3 Comparison of sampling method
3.3 加权投票融合
在搜索Cell结构时,由于一些候选操作的权值相近,无法准确地对其进行选择,搜索到的网络架构达不到最优性能。因此,本文利用组稀疏正则化策略扩大候选操作之间的差异,对所有候选操作进行筛选,进一步增加Cell结构中路径选择的准确性,以选择出合适的路径,如式(7)所示:
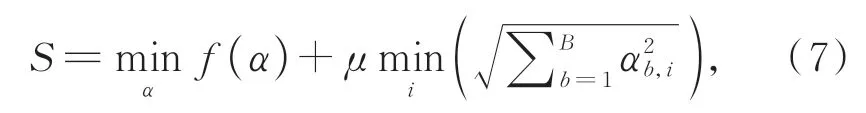
式中:S是候选操作得分,μ是一个可学习的超参数,f(α)是验证损失,B是Cell结构中的总层数。在搜索阶段,αb,i表示第b层中第i次操作的得分,所有得分组成体系结构α。对候选操作进行排序,筛选出各节点之间候选操作得分最高的操作。
利用组稀疏正则化策略对候选操作得分进行排名,并按照该排名选择Cell结构中各节点之间的路径,然而在权重选择过程中可能会出现:(1)有些候选操作的得分排名不是最高的,但此候选操作在网络架构中所起的作用无法被取代,对后续操作的影响可能强于其他操作,按照得分排名而舍弃此操作,网络的整体性能会下降;(2)在搜索空间中存在跳跃连接操作,如文献[20]中所述,由于跳跃连接与卷积结合比较好,网络架构搜索过程中会出现不公平竞争的现象,随着迭代次数的增加,跳跃连接所占的权重会逐步增大,在多次迭代搜索之后,搜索到的网络架构中包含过多的跳跃连接,导致网络性能下降。本文提出的NAS-VS算法,首先,通过Softmax函数放缩搜索空间使搜索空间连续化;其次,使用组稀疏正则化策略,结合DARTS算法中的路径选择策略和文献[21]中的噪声策略,对Cell结构中各节点之间的路径选择进行初步判定;最后,通过加权投票将各节点之间路径的选择加以融合,确定最终的Cell结构。这样可避免由于路径选择不准确引起的搜索与评估阶段的不一致,进而搜索出最优的网络架构,提高三维模型识别与分类的能力。
NAS-VS算法的具体操作如下:给出上述3种路径选择方法下Cell结构中各节点间的路径预测结果,将每个预测结果看作是一个独立的得分,以加权投票方式聚合全部的预测结果来进行路径选择,达到寻找最优路径的目的。由于搜索空间中有9种候选操作,故给出的得分为[S1,S2,…,S9],通过投票机制判断任意节点对中第i条路径的投票结果为Hvote(Si|Gj),路径u的最终选择为,其中,Si为第i条路径的得分,Gj表示任意节点对,k为路径选择的数目。
将路径i的得分Si作为该路径选择的投票值,令Zk(Si)表示节点对Gj中属于各候选操作得分Si的第k条路径,则当各节点对Gj中某条路径Si的得分最大时,对该路径投票,有Hvote(Si|Gj)=1;若节点之间的路径以相近的权重属于多个候选操作,则给这几个候选操作都投出一票。即Hvote(Si|Gj)=1,否则Hvote(Si|Gj)=0,即:
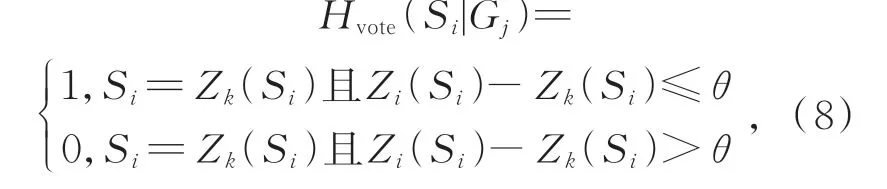
式中:θ为阈值,取值为[0,1)。当θ=0时,各个节点之间仅可以对概率最大的候选操作投一票;当θ>0时,允许对各节点对之间更多接近最大权重值的候选操作投票。也就是说,θ取值较小时,只有一个或多个最为相似的候选操作获得投票,这样限定严格,更多相近的候选操作可能被忽略;θ取值较大时,更多的候选操作获得投票,虽然考虑全面,但是投票结果的可信度也有所降低。
在式(8)中,θ选值不同,有些候选操作可能投了多票,有些候选操作可能只投了一票,不具有公平性。为此,加入了权重系数λ,如式(9)所示:
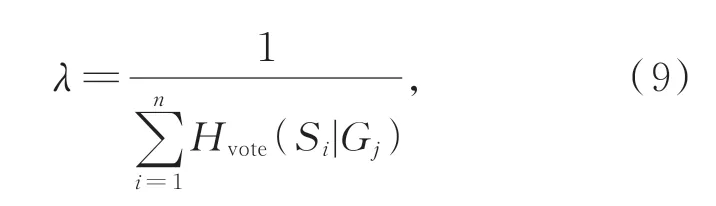
式中:节点对Gj之间的权重λ为其投票数量的倒数,以确保各候选操作在投票中的相对平等地位。所以,最终的投票结果为Hvote(Si|Gj)=
4 实验结果与分析
在ModelNet10和ModelNet40两个公开的标准数据集上进行了实验。ModelNet10包含4 899个三维模型,分为10个不同的类别。Model-Net40数据集有40个类别,包含12 311个三维模型,其中9 843个为训练模型,2 468个为测试模型。考虑到在大规模数据集上的巨大计算成本,首先在较小的数据集ModelNet10上搜索架构,然后将网络架构迁移到大数据集ModelNet40上,并在大的数据集上训练派生架构的网络权重。
4.1 搜索空间及参数设置
本文对搜索空间的设计,遵循SGAS[18]同样的设置。Cell结构如图4所示,它由具有6个节点的有向无环图表示(两个输入节点,三个中间节点以及一个输出节点)。节点是构成Cell结构的基本元素,每个节点Xi是特定张量,如卷积神经网络中的特征映射,每个有向边(i,j)表示搜索空间中节点Xi到另一个节点Xj的候选操作选择O(i,j)。输入节点是前两个Cell结构的输出表示,中间节点聚集来自它所有前置节点的信息流,输出节点被定义为固定数量的前置节点的串联。
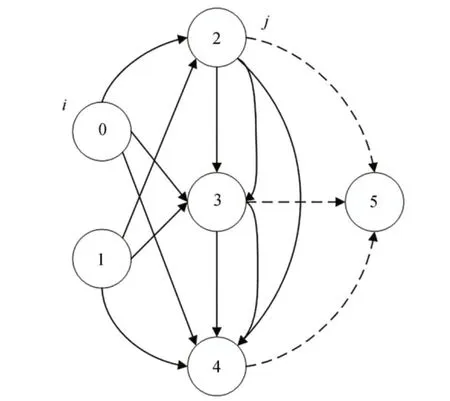
图4 Cell结构Fig.4 Cell structure
实验中,从ModelNet10中的每个三维模型中采样1 024个点,输入特征维度为3,分别为x,y和z坐标。对于体系结构参数α和模型权重ω,使用初始学习率为3×10-4、动量为0.5和权重衰减为10-3的Adam优化器进行优化。为防止架构搜索过程中出现梯度爆炸,在每个节点处都采用批归一化(Batch Normalization,BN)处理,网络迭代次数设置为50。所采用的硬件环境为Intel Core i9-10900k+NVIDIA RTX3090(24GB显存),深度学习环境为Linux Ubuntu 18.04+Pytorch1.4.0。
4.2 实验结果分析
在ModelNet10上搜索到最优Cell结构之后,将其堆叠3次,并在网络顶部使用全局平均池化,然后使用Softmax层进行输出,以构建最终的网络架构。将此网络架构迁移到ModelNet40数据集中,在此过程中,会随机初始化网络的权重(丢弃在搜索过程中学习到的权重),重新训练网络架构,并在测试集上测试此网络的性能。设置迭代次数为250,使网络趋于收敛。
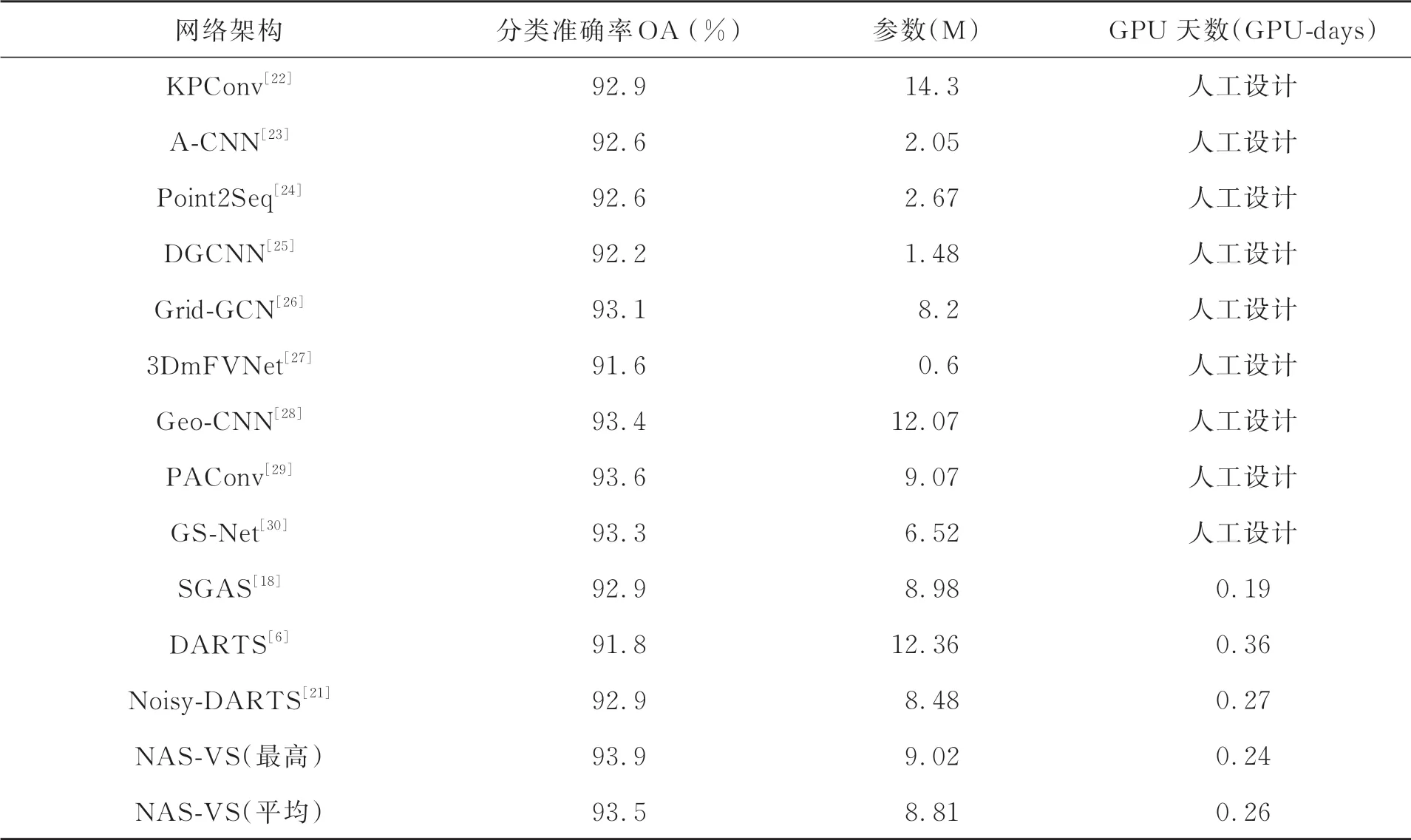
表1 不同算法在ModelNet40的分类准确率对比Tab.1 Comparison of recognition accuracy of different algorithms on ModelNet40

表2 NAS-VS在ModelNet40的分类效果Tab.2 Classification effect of NAS-VS on ModelNet40
实验中进行了5次独立搜索,得到了5个不同的体系结构。在ModelNet40数据集上对这5个体系结构进行了性能评估,并给出了5次评估的最高和平均分类准确率。NAS-VS算法搜索到的体系结构与主流的人工设计网络结果对比如表1所示。可以看出,使用NAS算法自动搜索出的网络架构其三维模型分类准确率明显高于人工设计的网络,在ModelNet40数据集上达到了93.9%的分类准确率,同时优于SGAS[18]、Noisy-DARTS[21]等自动搜 索 算法,充分验 证 了本文算法的优势。原因在于:一是利用性能估计器采样性能优秀的网络架构,避免了权重共享对超网造成的负面影响;二是加权投票方法融合了多种路径选择策略,不仅使cell结构中路径的选择更准确,同时还抑制了跳跃连接的不公平竞争,使搜索到的网络架构更深,有利于深层次特征的提取。由于5次独立搜索到网络架构中候选操作的不同,其参数值也有所差异,其中跳跃连接操作的参数计算最少,因此包含跳跃连接越多的网络架构,其参数量少于其他网络。此外,本文利用小批量训练数据上测试的训练损失作为性能估计器,只在性能表现良好的候选网络架构中进行采样,相比于Noisy-DARTS[21]、DARTS[6]算法,在计算效率上也有所提高。
实验统计了5次独立搜索得到的最优Cell结构和分类准确率,如表2所示。图5则是在搜索阶段迭代50次之后,搜索出的网络架构可视化结果。从表2和图5中可以看出,NAS-VS的分类准确率最高。这是由于NAS算法的特点是在搜索过程中倾向于选择在搜索早期就表现出易收敛性质的网络,相比于其他Cell结构,它的拓扑结构明显是浅且宽的。此外,跳跃连接的数量越多,可学习的网络参数就更少,从而导致网络性能不佳。图5中,mr_conv代表搜索空间中的图卷积神经网络(Graph Convolutional Network,GCN),gin代表图同构网络(Graph Isomorphic Network,Gin),conv_1×1代 表1×1的 卷 积 操作,skip_connect代表跳跃连接操作,edge_conv代表边缘卷积操作,gat代表图注意力网络(Graph Attention Network,Gat),none代表空操作,sage代表图样本和聚合(Graph Sample and Aggregate,GraphSAGE),semi_gcn代表基于图卷积的半监督分类操作。
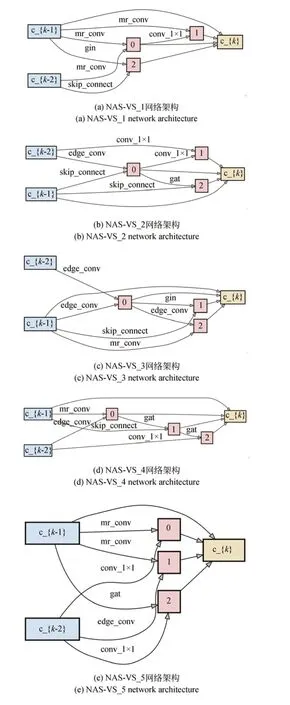
图5 NAS-VS方法搜索得到的最优Cell结构Fig.5 Optimal Cell structure obtained by proposed NASVS method
图5(e)中cell结构的加权投票选择过程如表3所示。由表可知,利用可微架构搜索策略、组稀疏正则化策略和噪声策略初步判定出的cell结构是各不相同的,利用加权投票机制对这3个不同的cell结构进行再次的路径选择,可进一步提高网络架构的性能,搜索出最优的Cell结构。在ModelNet40数据集上达到了93.9%的分类准 确度。
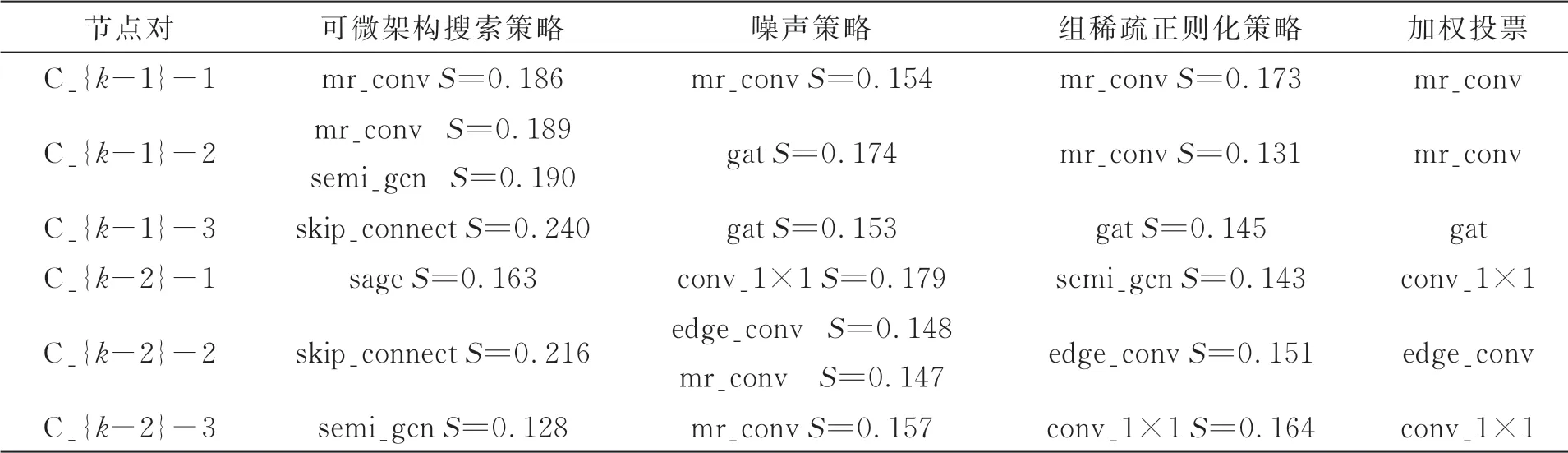
表3 最优Cell结构的加权投票选择过程Tab.3 Weighted voting selection process for optimal Cell structure
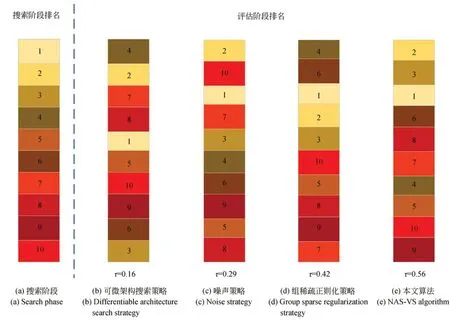
图6 肯德尔系数相关性Fig.6 Correlation of Maurice Kendall coefficient
4.3 消融实验
4.3.1肯德尔系数对比
通过实验来验证本文算法能否有效地缩小搜索和评估体系结构之间的差异,使用前文提到的肯德尔系数,利用3种路径选择策略和投票机制各进行10次实验,得到了10个不同精度的网络架构,并在验证集上进行评估。通过搜索阶段和评估阶段的排名计算出肯德尔系数,如图6所示。本算法的肯德尔系数τ为0.56,相比于单独的噪声策略、组稀疏正则化策略和可微架构搜索策略,总体上更接近最终排名,证明本文算法可以自动搜索出更优的网络架构,降低了搜索和评估体系结构之间的差异。
4.3.2性能估计器的优势
为了更好地分析本文采样方式的有效性,设置了两种不同的采样方式进行了实验对比。第一组实验使用本文基于性能估计器的采样方式,第二组实验使用均匀采样,其他设置则全部相同。实验结果如表4和图7所示,可以看出,基于性能估计器的采样方式可以取得更高的分类精度。这是由于在搜索空间中采样时,所有路径共享权值,如果对一条弱路径进行采样和训练,会干扰那些优良路径的权重,这种干扰会破坏它们最终的性能估计,并影响搜索到的最优体系结构。而基于性能估计器的采样方式不用覆盖所有路径,性能估计器会鼓励超网更多地关注那些潜在的强力候选网络架构,忽略表现较差的网络架构,以此来减轻超网的负担,提高训练效率。
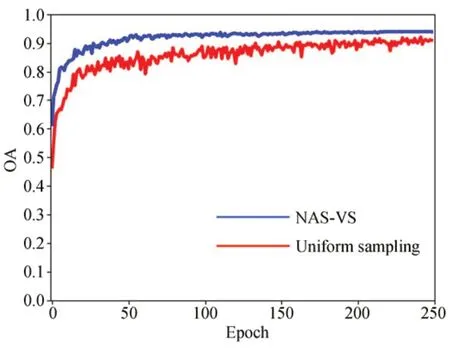
图7 不同采样方式的分类准确率Fig.7 Classification accuracy of different sampling methods

表4 不同采样方式的影响Tab.4 Influence of different sampling methods
4.3.3权重变化过程
为了更好地分析投票机制对各节点之间路径选择的影响,本文将路径选择过程中各节点之间的权重变化可视化,如图8所示。图8(a)是架构搜索时跳跃连接操作的权重变化过程,图8(b)~8(i)是架构搜索时其他候选操作的权重变化过程。可以看出,在DARTS方法中,随着迭代次数的增多,跳跃连接操作的权重增长迅速,在路径选择中逐渐占据主导地位,削弱了其他候选操作的权重,各候选操作之间出现了不公平竞争现象。这种现象会导致搜索到的Cell结构中存在太多的跳跃连接,使网络性能下降。而本文算法使用投票机制融合3种路径选择策略消除了跳跃连接的不公平竞争,使跳跃连接的竞争能力同其他候选操作处于同一水准,各候选操作之间表现出较强的独立性,从而搜索出一个性能稳定的网络架构。
4.3.4跳跃连接操作的影响
为了分析跳跃连接操作对网络架构性能的影响,本文设置了两个搜索空间:Ω1(包含跳跃连接操作)和Ω2(不包含跳跃连接操作),其他设置则完全一致,实验结果如表5所示。Ω1搜索空间搜索到的网络架构分类准确率高于Ω2搜索空间,这是由于虽然跳跃连接操作在神经架构搜索过程中具有不公平竞争性,但适当数量的跳跃连接可以解决较深网络中梯度爆炸和梯度消失的问题,有利于网络的性能提升。因此,只能对跳跃连接的不公平竞争进行限制,不能直接舍弃跳跃连接操作。
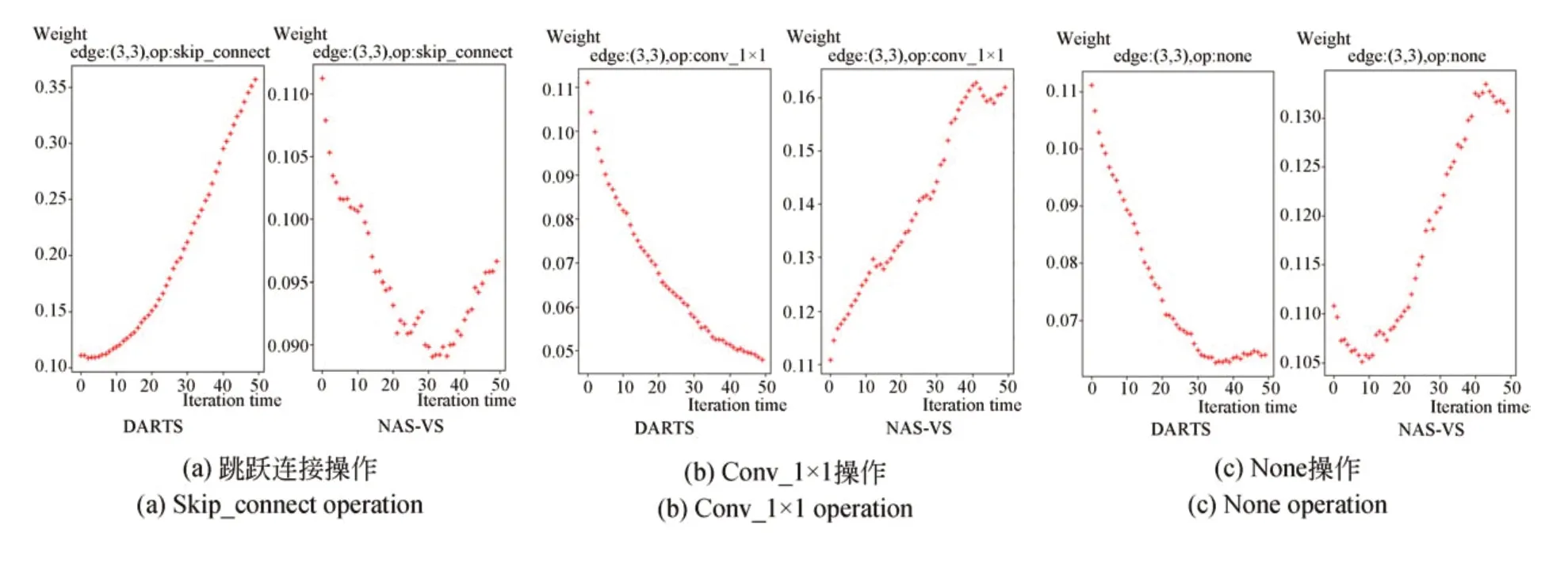

图8 各候选操作的权重变化Fig.8 Weight change of each candidate operation

表5 跳跃连接对搜索空间的影响Tab.5 Impact of skip connections on search space
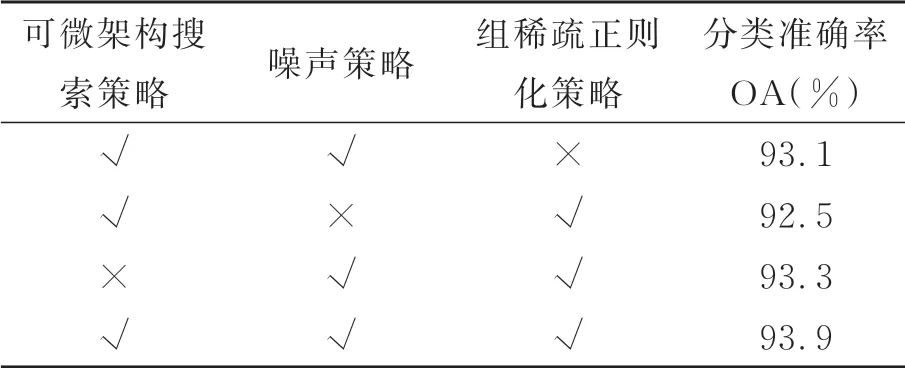
表6 加权投票实验对比Tab.6 Comparison of weighted voting experiments
4.3.5加权投票机制的优势
为了验证本文加权投票融合方法的有效性,在ModelNet40数据集上做了4组实验进行对比。第一组实验对可微架构搜索策略和噪声策略进行加权融合,第二组实验对可微架构搜索策略和组稀疏正则化策略进行加权融合,第三组实验对噪声策略和组稀疏正则化策略进行加权融合,第四组实验对这3种用于Cell结构路径选择的方法进行加权融合。实验结果见表6,可以看出,第二组实验的分类准确率明显低于其他3组。这是由于只对可微架构搜索策略和组稀疏正则化策略进行融合,虽然在一定程度上提高了搜索和评估体系结构之间的相关性,搜索到更优的网络架构,但并没有完全消除掉跳跃连接的不公平竞争。而相比于只对两种路径选择方法进行融合,本文算法搜索到的网络架构分类准确率最高,由此表明利用投票机制对3种路径选择方法进行融合,可以有效地提高Cell结构中路径选择的准确性。
5 结论
NAS已经在模式识别领域取得了巨大突破,本文在DARTS算法的基础上,提出了一种NAS-VS算法。相比人工设计的网络以及其他NAS算法,本算法在ModelNet40数据集上取得了较高的分类准确率,达到了93.9%。该方法有效地缩小了搜索和评估阶段网络架构之间的差异,并解决了以往NAS方法中均匀采样所导致的网络训练效率低的问题。本文方法的局限性在于搜索到的最优网络架构同实际最优网络架构只是部分相关的,不是完全相关,因此,还需要更进一步的研究。
