基于深度学习的人脸识别研究
2019-10-19罗灿峰
罗灿峰
(武汉传媒学院,湖北 武汉 430205)
一、前言
人脸识别技术通过图像采集设备采集目标人脸图像,并利用相应的算法识别目标身份。与其他生物特征识别技术相比,人脸识别具有识别过程友好方便、操作简便、多人同时识别等优点。人脸识别技术具有广泛的应用场景。除传统的门禁系统外,还可以与视频监控系统、手机解锁、计算机登录身份认证等结合使用。尤其是目前,公安安全技术要求最为迫切。人脸识别技术可用于协助公安机关解决案件。因此,如果人脸识别领域能够突破其技术瓶颈,将充分挖掘其巨大的潜在市场价值。
二、基于深度卷积神经网络的人脸识别
(一)基本算法框架
在整个人脸识别过程中,除了人脸的检测和对齐外,最重要的是人脸特征的提取。不同的方法可以不同地提取特征。卷积神经网络模型主要是基于监督学习,获得具有类间差异的人脸特征向量,将不同的人脸图像分为不同的类别,训练网络利用交叉熵损失函数进行多分类任务学习,最终去除了Softmax层,采用全连接。SoftMax前一层的部分。层的输出用作面部特征表示。
这两种算法都是通过深度卷积网络从原始图像数据中自动提取特征。最后,在人脸识别中,常用余弦相似度和欧氏距离来度量不同人脸之间的相似度。对于人脸检索任务,直接对查询图像与数据库中图像的相似性进行排序输出。人脸验证的任务还可以训练二元分类器确定查询图像是否是同一个人的相似性阈值。
(二)基础的卷积神经网络识别模型
1.基本模型结构
卷积层使用连续的小尺寸卷积核代替单个大尺寸的卷积核,全部使用 3×3 大小,步长设定为1,通过零填充保持输出数据体的尺寸与输入相同。相比单个大尺寸的卷积核,连续小尺寸卷积核可以达到同样的提取效果,且由于层数增加,经激活函数进一步增加了非线性,增强模型表达力。
在训练过程中在前两个全连接层后都增加Dropout层,Dropout 层的作用在于按照一定比例随机暂时舍弃部分该层的神经元,这样使得在使用批梯度下降进行网络训练时,每次训练的网络结构都不相同,在更新权重时被舍弃的神经元的权重就保持不变。
2.相似性度量
通过训练完成的卷积网络模型提取出人脸特征向量,在应用于最终的人脸识别时,主要通过比较两个人脸特征向量之间的相似度判定人物身份。常用的相似性度量方法包括欧氏距离、余弦相似度等,本文所提出的方法最终都选择使用余弦相似度比较人脸之间的相似程度。
余弦相似度计算的是两个向量间夹角的余弦值,公式定义如下式(2-1):
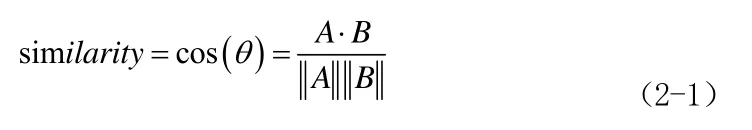
余弦相似度的值范围在-1 到 1 之间,两特征向量方向一致时夹角较小,相似度趋于 1,说明两个特征越相似,更可能是同一人。相反的,夹角越大相似度越小,说明属于不同人。
(三)实验设计与结果分析
1.CACD数据集及图像预处理
CACD数据集由Chen等在2014年公开,是当时数据量最大的跨年龄变化人脸数据集。在收集该数据集时,研究人员首先考虑了两点重要的原则,一是数据集中的人需要包含不同年龄,二是这些人的面部图片能够通过互联网方便、大量地采集。鉴于此研究人员选择了IMDb.com上不同年龄的名人作为待收集的对象,最终从1951年至1990年出生的名人中,每年选取排名前50位,一共包含了2000位名人。然后通过Google搜索这些名人的图片,以名人“名字+年份”作为关键词。每个人采集2009年至2018年的图片,因而年龄跨度为十年。但此方法获取的图片也包含大量噪声影响,如检索到的图片包含多人或某些名人在有的年份公开的图片很少等,研究人员仅对测试集数据进行了人工检验。在对所有收集的图片进行人脸检测、去重后,最终CACD数据集得到了年龄在16到62岁的共163446张人脸图片,其中20-60岁的图片居多,平均每人有80张左右的图片数据。
CACD 数据集包含足够的数据量,且每个人包含的图片数较为均匀,可用于深度卷积神经网络模型的训练,为提高模型的识别效果,在训练前还需要对图像数据进行一些预处理操作。
为进一步增强模型的泛化能力,在训练过程中使用图像增强技术构建更多的训练样本,更有效抑制过拟合。对于训练集数据主要采取两种图像增强技术:水平翻转和随机裁剪。由于人脸具有一定的对称性,通过水平翻转图像可以使训练得到的模型对同一人不同角度具有一定鲁棒性。
经检测对齐处理后人脸区域的图像大小为 256×256,进一步通过随机裁剪至224×224 大小的图片作为最终训练的输入,可以成倍增加训练样本数量,促使网络模型对部分位置的平移变换甚至是面部遮挡不敏感,有效提升模型的泛化能力。
2.实验结果与分析
本节实验选择40年中每年排名3至5的名人共120名作为测试集,以这120人在2013年的图片作为查询图片,另外将剩余图片分为2004至2006年、2007至2009年、2010至2012年三组,作为待检索的数据库图片,分别测试在不同年龄区间上的检索效果。
(1)批规范化的影响
本小节主要通过实验比较批规范层对深度网络训练的影响,一个模型ModelA 保持原状,一个模型 ModelB 在卷积层和全连接层后增加批规范化层,使用相同的 SGD 优化算法及0.1的学习率,在CACD数据集上训练多分类模型。
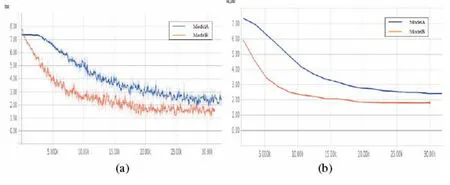
图2-1 两种网络模型分类loss曲线
(a)训练集 loss 曲线;(b)验证集 loss 曲线
图2-1所示为两个模型的loss曲线,可以明显发现批规范化操作加速了模型的收敛,在前期 loss 值能够更加快速下降,最终也更倾向收敛于较低值。深层的网络结构给梯度的更新带来了困难,实验证明批规范化操作确实能有效解决这一问题。从在CACD测试集上的检索效果看,选取 ModelA 训练集迭代 20 轮得到的模型与 ModelB 迭代 6 轮得到的模型比较第一识别率。ModelA 在不同年份数据库上的第一识别率分别为 82.4%、76.5%、74.46%,ModelB 则分别为 88.3%、86%、82.6%,直观地体现了两种模型提取的特征间的差距。
(2)特征维数影响
基于深度卷积神经网络的模型以倒数第二层全连接层的输出作为人脸特征向量,然后通过余弦相似度计算两个人脸图像间的相似性,因而训练得到的特征维数会对相似性计算产生一定的影响。高维特征向量在进行有监督分类训练时,能够更快达到收敛,但向量相对稀疏且可能包含更多噪声;低维的特征向量相对更紧密,但训练中准确率提升更缓慢。
在同样采取 SGD优化算法进行模型训练的条件下,特征维数选择128、256、512、1024 进行实验。图2-2给出了不同特征维数下在各年份区间数据库检索的MAP曲线,由图中可以看出更高维的特征在检索准确率上反而效果更差,最高维的1024维特征在各年份区间上的MAP值都是最低的。随着特征向量维数的逐步降低,检索的MAP值均有一定的提升,特征维数为256时提升较为明显,在相隔最久的2004至2006的数据库上检索准确率均值达到了63.42%。
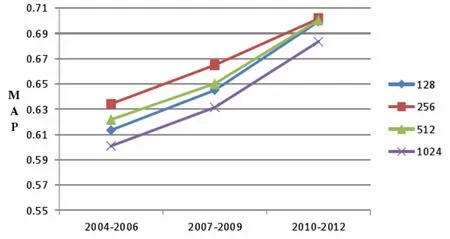
图2-2 不同特征维数下检索 MAP 曲线
在进一步降低特征维数至 128 维时,MAP 值没有继续提升且比 512 维的模型效果还稍有降低,可能是由于维数过低,在进行 1584 类的多分类任务模型训练时,未能很有效将特征压缩至 128 维,观察训练过程中验证集loss 曲线也可见趋于收敛时的 loss 值相对较大。
结语
人脸识别因其广泛的实际应用场景而引起了众多研究者的关注。同时,人脸识别的准确性往往受到诸多因素的影响。本文针对年龄变化引起的认知问题,研究了基于深度学习的认知方法在这一问题上的有效性。利用Web技术设计并实现了一个人脸识别应用程序。介绍了该应用程序的设计目标和开发环境。详细介绍了应用程序各模块的实现方法,并对其基本功能进行了测试。该应用具有轻便、跨平台的特点,能够满足人脸识别的日常需要。
