高光谱图像类别独立的域适应分类
2024-04-17余龙李军贺霖李云飞
余龙,李军,贺霖,李云飞
1.中山大学 地理科学与规划学院,广州 510006;
2.中国地质大学(武汉) 计算机学院,智能地质信息处理湖北省重点实验室,武汉 430078;
3.华南理工大学 自动化科学与工程学院,广州 510640
1 引言
高光谱图像监督分类的性能在很大程度上依赖于标记样本的数量和质量(Persello 和Bruzzone,2014)。然而,数据标记的过程通常是昂贵和耗时的(Deng等,2021)。当标记样本数量较少时,训练样本与数据之间的边缘分布差异较大(Belkin等,2006),导致高光谱监督分类方法出现过拟合等问题。
为了解决标记样本少的问题,主动学习(Yadav等,2022)和半监督学习(Wang等,2021)近年来被广泛研究。然而,在高光谱图像跨场景实时分类任务中,目标图像没有任何可用的标记样本,主动学习和半监督学习不再适用(Deng等,2020)。在这种情况下,只能利用已有影像的标记信息来辅助目标图像分类。
对于同一传感器获得的地物分布接近的两幅高光谱图像,其数据特性较为相似(童庆禧等,2016)。因此,利用相似场景的标记信息对新的高光谱图像进行分类,是解决少量标记样本甚至无标记样本下的高光谱图像分类问题的一种策略。该策略面临的问题是,由于光谱偏移,标记样本和新图像数据来自不同的分布,导致直接使用旧图像中的标记样本学习出的分类模型性能较差(Tuia等,2016)。为了学习对光谱偏移具有鲁棒性的分类器,域适应成为新的研究趋势(Du等,2013;Weiss等,2016)。
在域适应领域中,将先前具有标记信息的图像称为源域,将待分类的目标图像作为目标域。域适应算法试图将源域图像的标记信息或分类器迁移到目标域图像中。然而,源域图像和目标域图像可能展示的是两个不同的地理区域,也可能展示的是同一区域不同时间的地物分布。这导致源域和目标域的样本在空间分布和光谱特征上均可能具有巨大差异,给域适应的迁移造成极大的困难(彭江涛等,2020)。
按迁移知识的不同,域适应技术可分为基于模型迁移和基于数据迁移的方法(黎英和宋佩华,2022)。其中,基于模型迁移方法通常只能得到特定任务的结果,且性能受模型的限制,而模型结构的修改和超参数的设置缺乏理论指导(黎英和宋佩华,2022)。在基于数据迁移的方法中,特征表示方法是近年来的研究热点(Tuia等,2016)。由于这些方法试图直接学习域不变特征,因此可以将其输入任何分类器。域不变特征极大地减小了源域和目标域之间的分布差异,使得在源域上训练的分类器能够适应目标域。
根据算法优化目标的不同,特征表示方法可分为两类。第一类方法旨在对齐域之间的整体数据分布。这一类方法只考虑域之间的总体分布差异。迁移成分分析TCA(Transfer Component Analysis)(Pan等,2011)通过最小化最大均值差异(Gretton等,2007),使两个域整体数据的均值在一个共同的低维空间中对齐。而其半监督版本SSTCA(Semi-Supervised Transfer Component Analysis)算法已经被应用于林火烈度评估(郑忠等,2022)。除了均值之外,其他方法旨在对齐两个域的高阶统计量,如相关对齐算法CORAL(CORrelation ALignment)(Sun等,2016)仅将源域样本投影到新的空间中,以对齐源域样本和目标域样本的协方差矩阵。而基于典型相关分析的方法(Hotelling,1936;Hardoon等,2004;Li等,2019)求特征变换的目标是最大化源域样本和目标域样本之间的相关矩阵的迹。另外,Fernando等(2013)通过子空间对齐SA(Subspace Alignment)方法使整个源域的特征映射子空间与目标域的特征映射子空间趋于一致。Yang和Crawford(2016)利用两个域的相似几何特性学习在公共流形空间的特征表示。以上方法旨在减小域之间的总体分布差异,在各类的光谱偏移具有共性规律时表现较好。然而,实际场景中,源域和目标域在不同类别中的分布差异不同,各类的光谱偏移情况变得复杂,这些方法无法使域间各类的类内样本趋于一致。
第二类算法分别减小域间同类样本的光谱偏移,旨在同时对齐每个类的分布。为此,一些代表性算法使域间同类数据分布统计特征趋于一致,如联合域适应算法JDA(Joint Domain Adaptation)(Long等,2013)、类质心对齐算法(Zhu 和Ma,2016)、类质心和协方差对齐算法CCCA(Class Centroid and Covariance Alignment)(Ma等,2019)。另外,Zhang 等(2017)使用两个不同且耦合的特征变换对齐两个域的同类样本。对抗域适应算法通过域判别网络和特征提取网络的对抗关系来提取域不变特征,其中李梅玉等(2022)设计独立的分类器用于对抗一致性约束并提取跨域共有的鲁棒特征,应翔等(2023)利用元优化来协调域对齐和分类两个不一致的任务。然而,这些方法对所有类的类内一致性要求过于严格,可能导致模型振荡难以达到要求,或者在达到目标时加剧类间样本混合。例如,对抗域适应在训练过程中可能会过分关注难以区分的样本,导致模型过拟合和负迁移,降低模型泛化能力(谭琨等,2019;Shu等,2019;Huang 和Yin,2022)。上述问题主要归结于两个原因:一方面,这些方法会被错误的标签信息所误导;另一方面,在不同类样本混合条件下,同时提高每个类内的数据一致性会导致不同类样本的特征也变得更加相似,从而降低数据可分性。针对数据可分性降低的问题,Luo 和Ma(2018)在对齐类均值时增加流形约束;Tuia等(2014)在流形对齐时使同类样本趋于一致,同时增大不同类样本差异。但是这类算法的性能对图结构敏感,图结构又由伪标签决定,因而算法性能容易不稳定。考虑到这些因素,我们提出了一种类别独立的域适应CIDA(Class-Independent Domain Adaptation)算 法。提出的CIDA 算法在多个类别独立的降维子空间中对齐特征,以减轻对数据可分性的影响。然后在多子空间中学习后验概率,而最终的分类结果由多个子空间的后验概率共同决定,从而提升分类结果置信度。
2 研究方法
假定源域ns个标记样本和目标域待分类的nt个样本分别表示为源域标签表示为总共包含C个类别。在介绍提出的域适应算法前,先介绍本文采用的代表性样本选择策略。
2.1 代表性样本选择
同一类中聚集越密的样本越具有代表性,而离群样本因远离聚类中心而不能代表该类别(Ning等,2022)。选择每个类别的若干代表性样本能减小类内的噪声,有利于更具共性的特征表达子空间的学习。类似于密度峰值选择方法(Zhao等,2022),本文对于源域和目标域分别采用了两种简单有效的选择策略。
(1)对于源域,本文假设每个类数据服从高斯分布,且光谱变异导致的异常值数量较少,因而可以将每个类的均值特征作为聚类中心,然后选择与类均值最相似的个样本作为代表性样本集。用于选择的测度为
(2)对于目标域,利用伪标签将所有样本Dt划分为不同类别的样本集,其中第c类样本集表示为。选择每类前r%个ρt(x)最小的样本作为目标域的代表性样本集,其中
式中,dmin(x,c)=表示第j类任一样本x∈与第c类样本的最小欧氏距离。ρt(x)表示样本x到所有类的最小距离的模。
2.2 类别独立子空间
经过代表性样本选择,得到源域代表性样本集Xs和目标域代表性样本集Xt,和分别为源域和目标域的第c类代表样本集。利用和,我们针对每个类构造一个独立的优化目标:
式中,Tr(·)表示求矩阵的迹,矩阵Mc的每个元素表示为
遵循JDA 方法(Long等,2013),将最优化式(3)修改为
为求解式(5),构造拉格朗日函数为
式中,Φ=diag(φ1,…,φk) ∈Rk×k是拉格朗日乘子。求解∂L/∂Ac=0可得到如下特征分解式:
最终,类别独立子空间映射矩阵Ac可以通过求解式(7)的前k个最小特征向量得到。
2.3 基于子空间的后验概率分类器融合
在不同类别独立子空间中,域适应算法映射特征不同。对于总共C个类别独立子空间,目标域样本分类结果至少有C种。因而本文提出的类别独立子空间域适应算法可以产生更加丰富的信息。为了利用多个子空间的信息来优化分类结果,我们提出生成并融合每个子空间后验概率的分类方法。
首先,我们基于类别独立子空间生成两种后验概率:
2.4 基于空间先验的伪标签学习
在进行代表性样本选择和类别独立子空间学习时,都需要目标域的伪标签。伪标签的学习至关重要。为了避免分类结果产生较大噪声,我们采用基于空间先验的分割方法(Li等,2012)对式(10)生成的所有样本的后验概率进行后处理,得到更平滑的伪标签。采用该分割方法的好处是其使用的空间先验和图割算法(Boykov等,2001)考虑了样本间的数据自适应关系,防止分割结果过平滑。
结合上述几个部分,我们提出的类别独立的域适应算法(CIDA)的具体步骤见算法1。
算法1 CIDA算法:
输入:源域数据Ds,目标域数据Dt,源域标签Ys,参数r,k,α,迭代次数T。
(1)分别选择源域和目标域代表性样本集:Xs,Xt。
(2)用源域标签训练的基分类器分类目标域数据,得到目标域伪标签
(3)循环:1)求解式(7)中的投影矩阵Ac,c∈{1,2,…,C}。2)将数据映射到每个类别独立子空间中:
3)根据式(10)计算目标域数据的后验概率。
直到迭代次数达到T,退出循环
3 实验结果
3.1 实验数据
(1)洪湖ZY1-02D数据集:利用ZY1-02D卫星分别于2020年5月18 日和2021年5月24 日在洪湖地区获取的两幅高光谱图像。高光谱传感器空间分辨率为30 m。VNIR(可见光与近红外)部分和SWIR(短波红外)共包含166个波段。实验删除了其中39个信息损失严重的波段。为了验证域适应算法的有效性,将2020年5月18日的高光谱图像作为源域数据,尺寸为500×1300×127,其假彩色图像见图1(a);将2021年5月24日数据进行剪裁作为目标域,大小为119×374×127,如图1(c)。

图1 洪湖ZY1-02D数据集的假彩色图像以及4类地物标记图Fig.1 False color and ground truth images of Honghu ZY1-02D dataset
通过调研,两幅高光谱图像标注了植被、水体、建筑区、农田4 类地物,其中源域标注个65989 样本,目标域标注6807 个样本。各类分布信息见表1。
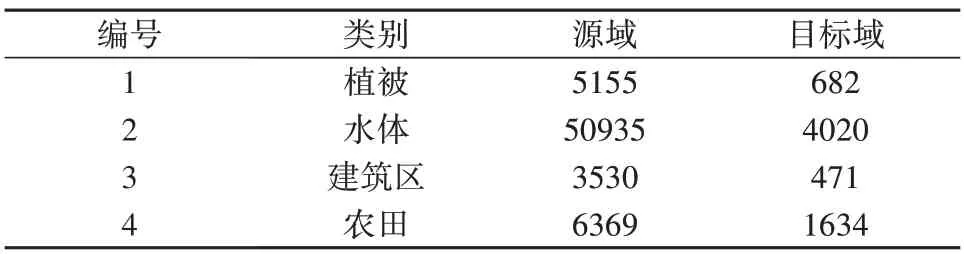
表1 洪湖数据源域和目标域各类样本数量Table 1 The number of samples in the source and target domains of Honghu data
(2)温县GF-5 数据集:利用高分五号AHSI(可见短波红外高光谱相机)分别于2019年11月10日和2019年12月31日在河南省焦作温县附近的黄河区域获取的两幅高光谱图像。数据集空间分辨率为30 m,每幅图像均包含330个波段。实验删除了其中69个低信噪比的波段。源域数据(2019-11-10)和目标域数据(2019-12-31)的尺寸均为960×960×261,其假彩色图像见图2。两幅高光谱图像均标注了大量样本,包含植被、水体、建筑区、农田4类地物,其中源域标注个139886样本,目标域标注101026个样本。各类分布信息见表2。

表2 温县数据源域和目标域各类样本数量Table 2 The number of samples in the source and target domains of Wen-County data

图2 温县GF-5数据集的假彩色图像及地物标记图Fig.2 False color images and ground-truths of Wen-County GF-5 dataset
本文采用了t-SNE(Anowar等,2021)降维方法对洪湖ZY1-02D 数据和温县GF-5 数据的原始光谱特征分别进行二维可视化,如图3所示,实心圆点表示源域样本,空心三角形代表目标域样本,4 种颜色的点分别指向表1 和表2 中的4 种地物类别。图3表明了本文选取的两个数据集的源域图像和目标域图像在各类分布上有明显差异,其中农田和植被特征伴随着独特的物候变化,水体包含泥沙沉积和漂浮物等方面的差异,建筑区具有多种地物混合特性。因此,我们将在这两个数据集上实现跨域分类任务,以验证本文提出的域适应算法的有效性。
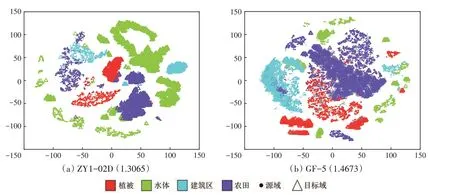
图3 高光谱跨域数据集中的各类别地物分布Fig.3 Distribution of ground objects in each class in hyperspectral cross-domain datasets
此外,为了在跨域分类任务中衡量特征可分性,本文利用了源域和目标域的全部有标记样本,采用Fisher 判别分析方法(Zandifar等,2022)的目标公式计算可分性指标J3:
式中,Sb为类间散度矩阵,Sw为类内散度矩阵。J3越大表明不同类样本特征差异越大,同类样本特征差异越小,即特征可分性越高。图3(a)和(b)的括号内分别记录了两个数据的J3指标数值,用于后续与域适应算法迁移后的特征对比。
3.2 对比算法
本文提出的类别独立的域适应算法(CIDA)在实验中对比了如下几种算法:
(1)NA(No Adaptation):用源域标记样本学习的分类器直接分类目标域数据。
(2)PCA(Principal Component Analysis):将源域和目标域样本投影到去除噪声的低维子空间中。
(3)SA(Subspace Alignment)(Fernando等,2013):将源域的PCA 变换子空间与目标域的PCA变换子空间对齐。
(4)CORAL(CORrelation Alignment)(Sun等,2016):通过线性映射,对齐源域和目标域的协方差矩阵。
(5)CCCA(Class Centroid and Covariance Alignment)(Ma等,2019):迭代对齐类质心和同类样本的协方差矩阵。
(6)TCA(Transfer Component Analysis)(Pan等,2011):在核希尔伯特空间中最小化源域样本均值和目标域样本均值之间的距离。
(7)JDA(Joint Domain Adaptation)(Long等,2013):同时最小化源域和目标域总体均值距离以及两个域的各类均值距离。
(8)MRDA(Manifold Regularized Distribution Adaptation)(Luo 和Ma,2018):在JDA 基础上同时考虑流形正则化约束。
(9)JGSA(Joint Geometrical and Statistical Alignment)(Zhang等,2017):学习两个分别用于源域和目标域的耦合映射,在减小几何和分布差异的同时增大特征可分性。
上述域适应算法将两个域的样本对齐后,将使用最近邻分类器NN(Nearest Neighbor)和基于线性核的支持向量机SVM(Support Vector Machine)对目标域高光谱图像分类。目标域样本的分类结果将作为伪标签用于域适应算法的迭代过程。除了上述传统算法外,考虑到深度学习可以获得跨域分类任务中可迁移能力更强的特征(Tang等,2022),本文还对比了近年来最先进的两种基于深度学习的高光谱图像域适应算法:
(10)CLDA(Confident Learning-based Domain Adaptation)(Fang等,2022):将域适应和置信学习相结合,根据分配的标签和预测的概率来评估每个伪标记目标样本的置信度。选择高置信度的目标样本作为训练数据,提高神经网络的识别能力。
(11)TSTnet(Topological structure and Semantic information Transfer network)(Zhang等,2023):基于CNN 特征动态构建源域和目标域的子图,使用图最优传输来对齐源域和目标域的拓扑关系。
本文提出算法与上述11 种方法进行了对比。目标域样本的总体分类精度OA(Overall Accuracy)将作为算法性能评价指标。
3.3 参数设置
(1)设置域适应算法(仅需要用到伪标签信息的算法)的迭代次数:T=20。
(2)用于计算投影矩阵的代表性样本数量设置:洪湖数据在源域每类选取个,温县数据在源域每类选取0.1个。=Nc是最小的单类样本数量,Nc是第c类的样本数量。在目标域的每类选择符合准则的前50%个代表性样本(且不大于10000个样本)用于计算投影矩阵。
(3)设置训练样本:考虑到源域标记样本数量大,为了降低分类器的计算复杂度,对源域标记样本随机采样后再输入分类器。对于洪湖数据,随机采样30%,对于温县数据,随机采样10%。
(4)设置后验概率融合权重:α=0.5。
(5)投影子空间维度k等参数与其他域适应方法设置一致。
3.4 实验结果
3.4.1 洪湖数据实验
所有算法的分类精度见表3,在传统域适应方法里,提出的CIDA 算法在两种分类器上均取得了最高的分类精度。由于CIDA 是基于JDA 提出的算法,与JDA 相比,CIDA 的分类精度在NN 上提高了9.56%,在SVM 上提高了1%。与深度学习方法相比,CIDA 在NN 上的分类精度比CLDA 提高了9.87%,比TSTnet提高了4.14%。除此之外:
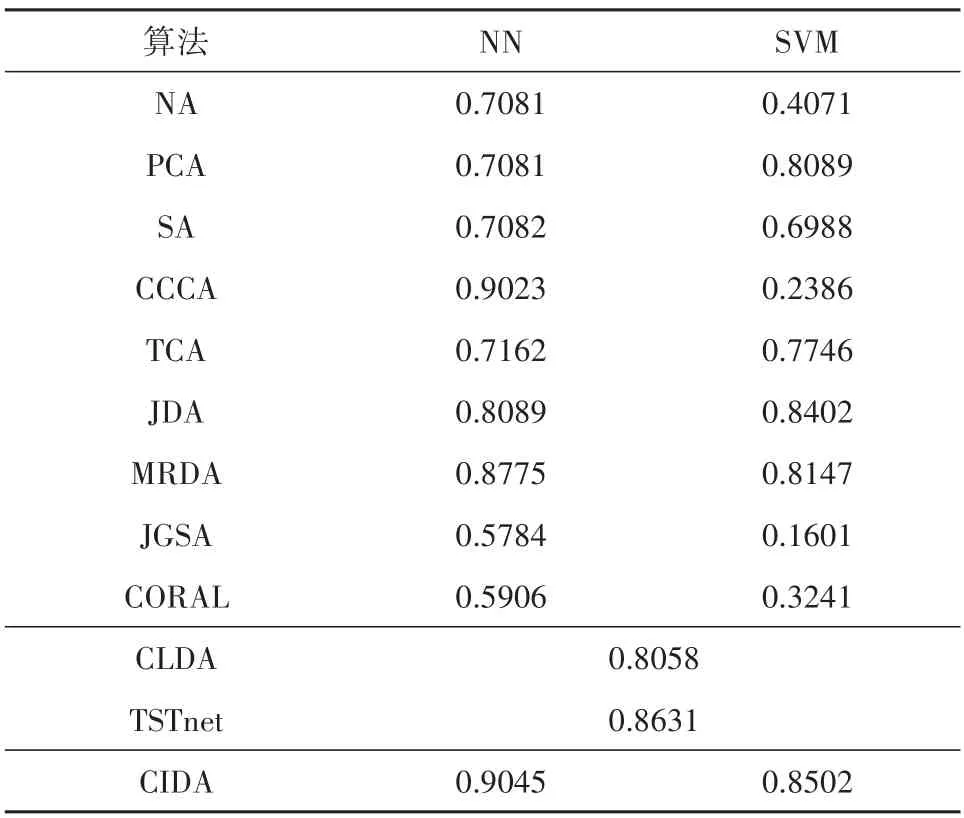
表3 洪湖数据分类结果Table 3 Classification results on Honghu data
(1)CORAL 和JGSA 算法在处理洪湖数据之后,分类精度相比NA 更低。说明CORAL 的协方差对齐和JGSA 的耦合映射不适用于洪湖数据。由于洪湖数据存在严重的类间混叠,且代表性样本集和全部数据的特性(协方差矩阵、类内类间散度)差异,这些算法并不能缩小源域和目标域的偏差。
(2)PCA 降维算法和SA 子空间对齐算法在使用NN 分类器时性能相比NA(使用原始特征)没有提升,而使用SVM 分类器时相比NA 有较大提升,说明的PCA 和SA 得到的对齐特征对分类器有限制,在区分地物类别上没有优势。
(3)TCA 和JDA 算法均有所提升。然而TCA旨在对齐两个域的总体均值,忽略了各类的特征偏移,分类效果没有JDA提升大。JDA同时考虑所有类别的特征对齐,在偏移较大、类间混合严重时,分类性能的提升受到限制。
(4)CCCA 利用了类中心偏移方法直接对齐两个域的同类地物,在初始精度较高的NN 分类器上可以达到不错的对齐效果。但初始精度较低的SVM 分类器提供的伪标签严重恶化了算法的对齐性能,导致分类精度降低。
(5)从表3 中可以看出MRDA 算法和提出的CIDA 算法均能达到较好的效果。其中MRDA 算法增加流形约束,目的是在特征对齐的同时保持局部几何结构,在NN 分类器上相比JDA 提升较大,但是在SVM 分类器上表现稍弱。而提出的CIDA 方法在NN和SVM两个分类器上均表现最优,能有效改善其他算法难以同时对齐每个类的问题。
除分类精度外,本文针对其他方面分析如下:
(1)分类图:图4展示了几种精度较高的域适应算法对洪湖ZY1-02D 目标域图像的分类图。提出的CIDA 算法的分类结果不仅局部更加平滑,且水体、建筑区等地物边界更加清晰准确。而CCCA将左上部分的水体错分成了植被,同时将大量其他地物错分为了建筑区,且右边的水体预测结果破碎不完整。JDA 和MRDA 的预测结果包含大量噪点,且在水体中间错误预测出很多建筑区。基于深度学习的CLDA和TSTnet方法虽然能得到平滑的分类结果,但也模糊了地物边界和小面积的地物类别,产生了过平滑的效果。

图4 洪湖ZY1-02D目标域图像的分类图Fig.4 Classification maps of the target image in ZY1-02D
(2)特征可分性分析:基于t-SNE方法将几种典型算法生成的特征进行二维可视化展示,如图5和图6 所示(括号中记录了特征的可分性指标),这些算法结果的生成过程由KNN提供伪标签。

图5 对比算法的特征二维可视化Fig.5 Two dimensional visualization of features in contrast algorithms
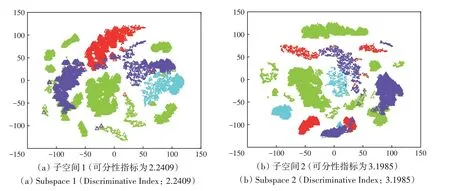
图6 CIDA算法在4个类别独立子空间中特征可视化Fig.6 Feature visualization of CIDA algorithm in four class-independent subspaces
图6 展示了CIDA 算法将样本分别投影到4 个类别独立子空间中的分布,最后CIDA 的分类结果联合了这4个子空间分布来学习。
图5 和图6 中源域和目标域同类样本聚合越紧密,不同类样本分布越远离,样本特征可分性越好。对比图5和图6可知,CIDA、CCCA、MRDA这3种特征分布比PCA 和JDA 的特征分布少了很多类间混叠。另外,对比图3(a)和图6可知,提出的CIDA 算法在每个子空间对齐后的特征相比原始光谱特征的可分性指标提升较大,且在类别独立子空间2 和子空间3 中的可分性指标比PCA、CCCA、JDA、MRDA 的指标都高,因而具有学习出更好分类特征的潜力。
(3)收敛性分析:利用了伪标签的域适应迁移算法均迭代计算了20次,得到精度变化曲线如图7 所示。从图7(a)中可以看出,提出的CIDA 算法相比CCCA 能更快收敛,相比MRDA收敛到更高的精度;而JDA 和JGSA 算法始终振荡难以收敛。图7(b)同样反映出提出的CIDA 算法能快速达到较好的收敛结果,而JDA 还处在一定幅度的振荡过程中。另外,JGSA 仍难以收敛,CCCA 处于精度下降过程。
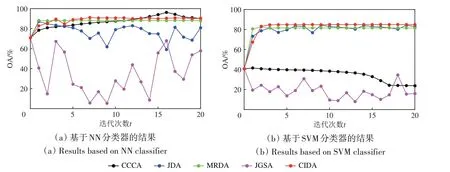
图7 域适应算法迭代中的精度变化Fig.7 OAs in iterations of domain adaptation algorithms
(4)参数分析:首先分析投影子空间维度k对算法性能的影响。图8显示的几种算法会将源域和目标域样本映射到k维子空间中,可以看出MRDA以及提出的CIDA 算法在不同维度的子空间上都有较好的性能。PCA、SA、TCA 方法虽然对参数k稳定,但优势不大。JDA方法对参数k十分敏感。

图8 参数k的影响Fig.8 The influence of parameter k
其次分析后验概率融合权重α对提出的CIDA算法分类精度的影响。如图9 所示,CIDA 算法精度始终在JDA 之上,且在大部分参数范围内远超于性能稳定的MRDA算法。

图9 参数α的影响Fig.9 The influence of parameter α
3.4.2 温县数据实验
从表4 可以看出,提出的CIDA 算法同样适用于温县数据,在应用NN和SVM 分类器时的分类精度均为最高。相较于JDA,提出的CIDA 算法的分类精度在NN 上提高了18.45%,在SVM 上提高了13.5%。相比于基于深度学习的CLDA 和TSTnet 方法,提出的CIDA 方法也高出20%以上。从表4 还可以看出如下几点:

表4 温县数据分类结果Table 4 Classification results on Wen-County data
(1)使用SVM 对原始数据分类(NA 算法)就已经能达到较高的分类精度。
(2)提出的CIDA 之外,其他算法均不适用于温县数据。这些算法在SVM 上的精度相比NA 更低,说明经这些算法处理后的特征的域适应能力不如原始特征。
(3)CIDA 的SVM 分类精度有所提升,表明提出的方法在域适应过程中没有降低特征可分性。
一方面,从图3(b)可以看出,温县GF-5 数据中地物混合严重,不同类别样本很难从特征上区分开,仅利用光谱特征很难达到平滑的分类效果。另一方面,图2的假彩色图像反映出温县GF-5影像中存在大量不连续的区域,例如很多小面积的建筑区分散分布在各处,采用空间方法容易导致过平滑。因而,在该数据上得到既平滑又边界保持良好的分类结果是难度较大的。在图10中,基于深度学习的CLDA和TSTnet算法虽然局部平滑性相当好,但过平滑问题严重影响了分类精度。JDA、MRDA、CORAL算法对齐特征时忽略了类间混叠的问题,局部区域的预测结果存在大量噪声。而提出的CIDA 算法每次只对齐明显属于同类的样本特征,实现了平滑性和细节最好的分类效果,如图10(f)所示。

图10 温县GF-5目标域图像的分类图Fig.10 Classification maps of the target image in Wen-County GF-5
图11 反映出提出的CIDA 算法的收敛性最好,在NN分类器上收敛到最高的分类精度,在SVM分类器上的性能也不会衰减。

图11 域适应算法迭代中的精度变化Fig.11 OAs in iterations of domain adaptation algorithms
图12展示了CIDA 算法的参数稳定性,在多个α值上都能保持最优的性能。

图12 参数α的影响Fig.12 The influence of parameter α
4 结论
本文提出了一种类别独立子空间的域适应算法。该方法首先利用代表性样本集计算每个类的独立子空间,然后将源域和目标域样本分别投影到多个独立子空间中,学习出多个后验概率并融合。在洪湖ZY1-02D 和温县GF-5数据上的实验结果表明,提出的算法将数据投影到子空间后,两个域全体数据的可分性有明显提高。投影到部分子空间后的数据可分性相比JDA 和MRDA 的结果更优,体现了提出算法在对齐域间特征和提升数据可分性方面的能力,因而具有实现目标域高精度分类的潜力。NN 和SVM 的分类精度也表明,提出的算法不仅得到了最好的分类结果,且性能稳定(在迭代计算过程中稳定增长,且能在伪标签精度较低的情况下实现性能提升)。然而,本文提出的算法和实验仍有一定的局限性,我们将其总结如下,以便在未来进一步研究:
(1)当数据量较大时,在多个独立子空间计算后验概率相比于特征变换的时间复杂度更高。未来将探索如何利用多个类别独立子空间构造出域适应能力更强的特征。
(2)对于不同子空间得到的后验概率,CIDA采取了非线性融合的方法得到最终的分类结果。然而不同子空间对特定问题下的特征迁移贡献率有待更深入研究,我们将在未来工作中考虑对不同子空间的输出进行更具有物理意义地融合。
(3)提出的CIDA 算法基于原始特征进行域适应对齐,忽略了深度特征在分类领域的优势。未来将考虑结合深度学习优化域适应的对齐特征。
(4)域间的迁移在减少同类差异的同时也会降低地物的类间判别性,即不同地物变得更难区分。当地物类别增多时,域适应在平衡域间差异和可分性时变得更加困难,因而在精细分类任务上实现域适应是一种极大的挑战。目前的域适应研究主要集中在少量类别分类问题上。然而考虑到高光谱数据在精细分类上的优势,我们会在未来研究中设计适合精细分类任务的域适应方法。
