基于改进的YOLOv8脆柿缺陷检测
2024-02-20王靖东张东升
王靖东张东升
(1.山东交通学院,山东 济南 250357;2.山东省交通建设装备与智能控制工程实验室,山东 济南 250357)
引言
脆柿的品质是影响其市场价值和消费者满意度的关键因素。具有裂纹的脆柿品质较差易坏;具有霉点的脆柿可能会致癌;因此在分级中需要淘汰有此缺陷的果子。在脆柿的分级过程中,主要依靠的还是人工分拣,不仅耗时耗力,还受到人为主观因素的干扰[1]。为解决此问题,本文以缺陷脆柿为研究对象,提出一种YOLOv8n-C2f_Faster-DLKA模型,在YOLOv8n模型的基础上,将引入FasterNet中的FasterBlock模块替换C2f模块中的Bottleneck模块,有效降低了模型参数计算量和模型深度,提高了检测精度和运行速度;在主干网络中加入了DLKA注意力机制[2],基于特征学习变形形成了自适应卷积核,这种自适应卷积可以提高模型的特征提取能力。在C2f_Faster模块的基础上,通过加入其他的注意力机制进行对比,通过与其他检测模型对比验证,证明了YOLOv8n-C2f_Faster-DLKA模型的优越性。
1 图像数据采集和标注
本实验中,为了得到较为强大的脆柿数据集,由于现有公开的数据集网站上并没有缺陷脆柿的相关图像且受到实际条件的影响,除自己采集到的图像外,还通过其他方式收集了一些图像通过数据增强,进一步扩充数据样本。扩充后的数据按照7∶2∶1比例划分训练集、验证集、测试集,分别为945幅、270幅、135幅[3]。用LabelMe进行数据注释,以数据为基础的模型效果的优劣很大程度上取决于所使用数据的质量,由于收集到的图像过于复杂,导致改进的模型不能够达到很高的指标。
2 模型改进
2.1 FasterNet
FasterNet[4]是2023年CVPR提出的新神经网络,结合了PConv设计,形成了FasterNet系列。该网络在各类设备上运行速度快,在分类、检测和分割任务中表现出卓越性能,同时具备低延迟和高吞吐量。FasterNet的架构包括4个层级,每个层级前面有一个嵌入层或合并层,用于空间下采样和通道扩展。每个阶段都包括FasterBlock块,其中PConv层和2个1×1卷积层组成倒置残差块,中间层扩展通道数,并包含Shorcut以重用输入特征。FasterNet模块中的PConv层只在部分输入通道上应用常规卷积来进行空间特征提取,同时保持其他通道不变,这种方法既能更好地利用设备计算能力,又能在空间特征提取中发挥关键作用。
2.2 DLKA Attention
可变形大内核注意力[5](Deformable Large Kernel Attention)是2023年CVPR提出的一种新的注意力机制,用于处理医学图像分割。该模块采用可变形卷积,调整采样网格整数偏移,创建一个偏移场,并基于特征学习自适应卷积核,以增强检测脆柿表面缺陷的效果。与传统的注意力方法不同,其无需额外的归一化函数,避免忽略高配信息降低注意力机制性能的可能性。

图1 FasterNet网络结构

x1=D﹣LKA﹣Attn(LN(xin))+xin
xout=MLP(LN(x1))+x1
MLP=Conv1(GeLU(Convd(Conv1(x))))

图2 2D DLKA注意力机制网络结构
2.3 YOLOv8n-C2f_Faster-DLKA检测模型构建
原有的YOLOv8算法对脆柿缺陷数据集进行检测时,存在精度不高,检测速度过慢等问题,不便于在具体的分拣过程中应用。在YOLOv8n的原始模型中,C2f的Bottleneck模块是一种残差块的变种,融合Bottleneck之前的和之后的feature map,由n个Bottleneck串行,每个Bottleneck都和最后一个Bottlenec再融合起来,这就达到了特征融合的目的。其设计旨在提高网络的效率和表达能力,同时减少计算量。但原始模型中C2f模块就比较多,且每个C2f拥有一个或者多个bottleneck模块,每个bottleneck模块都包含一个卷积,尽管这种设计使得C2f模块能够学习到丰富的特征表示,但同时也增加了模型的计算负载和复杂度。因此,本文通过引入FasterNet中的FasterBlock模块替换C2f中的Bottleneck模块,PConv卷积更加简单,可以有效减少计算冗余和内存访问[6]。通过与C2f模块拼接形成一种新的特征提取模块C2f_Faster[7],经实验证明,C2f_Faster模块提升了对脆柿缺陷的检测速度和精度。
为了避免轻量化改进后的检测精度再有所上升,引入DLKA注意力模块,该模块利用大型卷积核充分理解体积上下文。该机制在类似于自注意力的感受野范围内操作,同时避免了计算开销。此外,该注意力机制还利用可变形卷积灵活地扭曲采样网格,使模型能够适应多样化的数据模式,经过后续验证,确实对脆柿数据集的适用性比较好,性能比较优越。
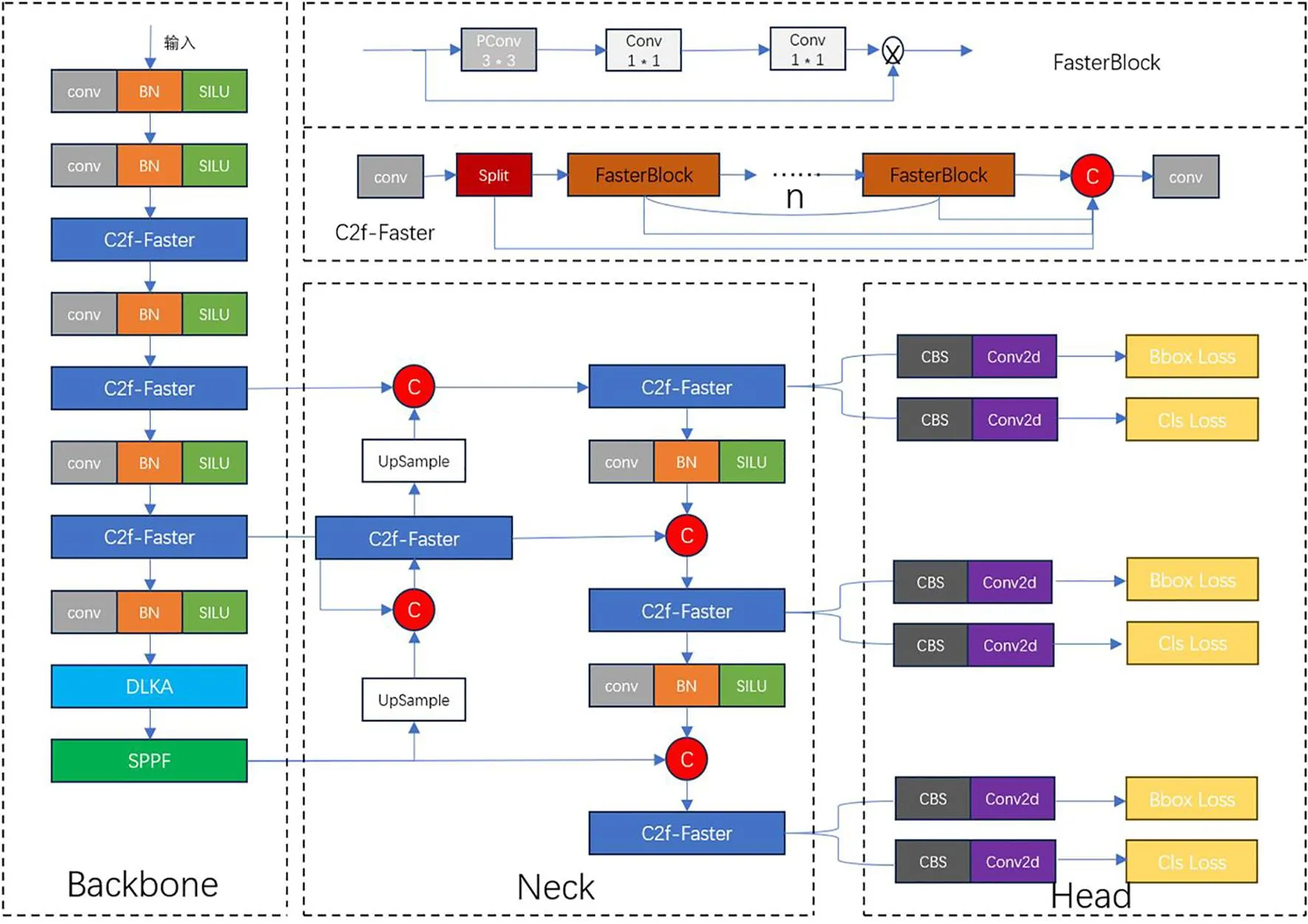
图3 YOLOv8n-C2f_Faster-DLKA网状结构
3 实验与分析
3.1 训练环境和方法
本研究在相同配置的环境下进行了实验,训练配置及参数设置:处理器为英特尔酷睿i7-13620h,GPU为NVIDIA GeForce RTX 4060 Laptop GPU,显存为16G,操作系统为Windows11,使用Python版本为3.11.5,CUDA版本为12.0,使用Pytorch框架进行训练,torch版本为2.0.1,迭代次数Epoch设为150,批次大小设为16,图像输入尺寸为640像素×640像素。
3.2 消融实验
为了展现改进的C2f-Faster、加入DLKA注意力机制对YOLOv8n模型算法的不同影响,在保证实验条件和配置相同的情况下,需要进行消融实验。实验结果如表1所示。

表1 消融实验结果
从表1可以看出,与YOLOv8n模型相比,加入了模块C2f_Faster模型的mAP@.5和mAP@.5-.95分别提高了约5.3%和2.3%,准确率提升了约5.4%,但召回率下降了约2.7%,GFLOPs下降了1.8,这表示出C2f_Faster模块不仅可以提升模型的检测精度,还可在较大程度上减少模型的参数量,提高了运行效率,但降低了召回率。与YOLOv8n模型相比,加入了DLKA注意力机制模型的mAP@.5和mAP@.5-.95分别提高了约5.5%和0.8%,准确率提升了约0.3%,但召回率提升了约5.4%,GFLOPs上升了0.5,这表示DLKA注意力机制虽然可以提升模型的检测精度,但不可避免的是会提高模型的参数量,从而降低运行效率。YOLOv8n-C2f_Faster-DLKA模型的mAP@.5和mAP@.5-.95分别提高了约7.8%和0.8%,准确率提升了约11.3%,但召回率上升了约0.6%,GFLOPs下降了0.2,这表明此模型不仅可以提高模型检测精度和运行效率,还可以解决C2f_Faster模块召回率低和DLKA注意力机制运行效率低的问题。

图4 总损失和mAP@.5曲线
3.3 C2f_Faster加入不同注意力机制对比实验
为了验证D-LKA注意力机制的优越性,将EMA、MLCA、SimAM、CPCA、MPCA、SegNext、Triplet、LSKA等注意力加入到改进的YOLOv8n-C2f_Faster模型中,进行实验对比,得到的实验数据如表2所示。

表2 多种注意力机制对比结果
通过表2对比可知,这些注意力机制的mAP@.5和精度都没有DLKA的高,在召回率上也只有EMA和SegNext比DLKA高。由此看出,DLKA注意力机制对该脆柿数据集的影响远超其他注意力机制,虽然DLKA的GFLOPs会比这些注意力机制高,但其检测效果是明显高于其他的注意力机制,对检测精度的提升有明显效果。
3.4 不同检测模型性能对比
为了证明YOLOv8n-C2f_Faster-DLKA算法较其他算法在脆柿缺陷检测的优越性,与其他检测模型对比,得到的实验结果如表3所示。
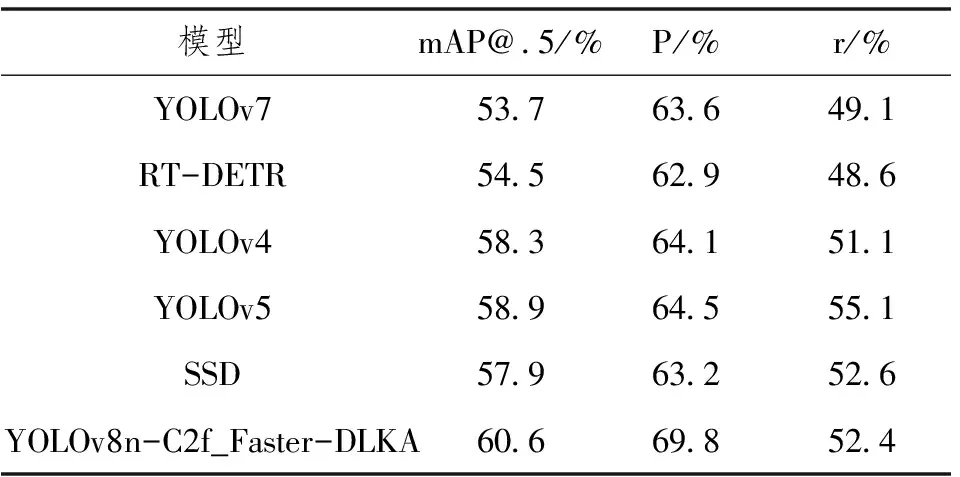
表3 多种检测模型对比结果
4 总结
针对脆柿缺陷检测所需的轻量化网络结构和实时检测要求,提出了一种YOLOv8n-C2f_Faster-DLKA的检测模型,通过在基础模型YOLOv8n中通过引入FasterNet中的FasterBlock模块替换C2F中的Bottleneck模块和DLKA注意力机制降低了模型的参数量和计算量。针对YOLOv8n-C2f_Faster-DLKA模型的有效性验证,在测试集上的mAP@.5和mAP@.5-.95分别为60.6%和26.6%,对比原始YOLOv8n模型分别提升7.8%和0.8%,有效提升了对脆柿缺陷的检测速度和精度。
