基于LSTM 神经网络的干燥含水量预测研究
2024-01-16汪洁张婷暄张君健孙怀宇
汪洁,张婷暄,张君健,孙怀宇
(沈阳化工大学 化学工程学院,辽宁 沈阳 110142)
化工生产的流程精细复杂[1],具有复杂性以及非线性[2]等特点,在化工生产的过程中会产生大量的数据,这些数据体现了化工过程中各种不同参数的变化以及化工过程的特性。由于化学反应本身具有较大的不稳定性,容易受到外界环境如原料成分、环境温度、压力、催化剂等因素的影响[3],所以如果是完全基于机理来对化工生产过程进行模拟是比较困难的。而利用深度学习算法来对化工数据进行分析和预测,可以优化有意义的参数,从而提高化工生产的产品质量。
随着大数据、人工智能等信息技术的发展,国内外的制造行业正以飞快的速度实现与人工智能的融合[4],然而对于化工领域来说,人工智能与之结合的程度还比较低,尚存在较大发展空间。
干燥通常是指将热量加于湿物料并使其湿组分蒸发,从而得到一定湿含量固体产品的过程[5]。PVC流化床干燥器是化工生产中重要的一个干燥设备,国内外常用的PVC 干燥装置有回转筒式干燥器、气流干燥器以及流化床干燥器[6]。由于流化床干燥器具有流程简单、热效率高、连续操作动力消耗低等一系列性能优势,使得流化床干燥生产工艺在PVC行业中得以普遍应用。
流化床干燥过程是一个复杂的过程,流化床内部物料在气流中呈悬浮状态,如液体沸腾一样发生着强烈的热质交换[7]。在干燥过程中读取的是各个测量点的实时数据,而由于物料是流动的,每个测量点的数据变化和最后的产品之间又存在着时间间隔,导致当前流股干燥结束后的含水量难以被实时监测。而在实际生产中,为了避免产品的含水量过高,使用过度干燥导致工厂生产的成本增加。这时如果可以提前预测到产品的含水量,就可以在产品干燥结束前发现是否有不合格的产品,从而对干燥过程的参数进行及时调节,这样可以节省许多时间和成本。深度学习是近年来发展十分迅速的研究领域,并且在人工智能的很多子领域都取得了巨大的成功[8]。本文以实际生产过程中获得的DCS 运行数据为样本,基于pytorch 深度学习框架构造长短期记忆网络LSTM 模型,对化工干燥产品的含水量进行预测。
1 pytorch 深度学习框架
1.1 简介
Pytorch 是Facebook 在2017 年开源的一款深度学习框架[9],它是基于torch 更新后的一种产品,不仅能够实现强大的GPU 加速,同时还支持动态神经网络。尽管Pytorch 的发布晚于TensorFlow, 但它的使用率在近几年飞速提升 ,特别是在科研领域得到了大量的应用[10]。
1.2 实验环境描述
本文是在系统Win11、512G(SSD)的硬盘、INTEL 酷睿I5-11320H 的CPU 和内存16 GB 的PC机上通过python3.8.5 版本和anaconda4.9.2 版本来使用Pytorch 构造LSTM 深度学习模型。Anaconda 指的是一个开源的Python 发行版本,其包含了Conda、Python 等180 多个科学包及其依赖项[11]。
2 lstm 方法
2.1 lstm 原理
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种变体,是一种具备时序记忆能力的循环神经网络[12],能够很好地发现时间序列中所隐含的规律。LSTM模型将隐藏层的RNN细胞替换为LSTM细胞,能够有效地克服传统RNN 在处理大型时间序列数据时可能会出现的梯度爆炸和梯度消失等问题[13]。
LSTM 模型的核心概念在于细胞状态以及“门”结构[14]。LSTM 的网络结构由3 个门控和1 个记忆细胞构成,记忆细胞用于保存历史信息。3 种门结构分别为遗忘门ft、输入门it和输出门ot,这些门结构以特殊的方式进行交互,不断控制着信息进行更新[15]。LSTM 模型基本结构如图1 所示。

图1 LSTM 模型基本结构
图1 中每一个箭头都表示着一个向量,意味着从一个节点的输出到另一个节点的输入,圆圈则表示向量的相加或相乘计算,箭头分叉表示两个节点复制。
2.2 lstm 的网络结构
2.2.1 输入门
输入门主要决定输入xt能在记忆单元Ct中保留多少成分。首先将前一层隐藏状态的信息ht-1和当前输入的信息xt传递到Sigmoid 函数中去,其次将前一层隐藏状态的信息ht-1和当前输入的信息xt传递到tanh 函数中去,创造一个新的侯选值向量。输入门结构如图2 所示。
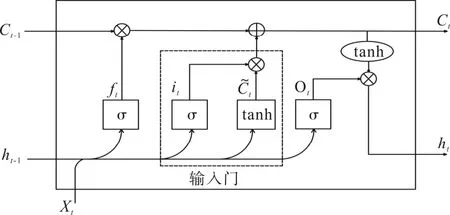
图2 LSTM 输入门结构
输入门的公式可以表示为:
式中:σ—Sigmoid 函数;
Wi、Wc—输入门it和候选向量的权重矩阵,相应的偏置分别为bi和bc;
xt—在t时刻的输入;
ht-1表示t-1 时刻的隐藏状态。
2.2.2 遗忘门
来自前一个隐藏状态的信息ht-1和当前输入的信息xt同时传递到 Sigmoid 函数中去,得到的输出值介于0 和1 之间,0 意味着不保留,1 意味着都保留。遗忘门结构如图3 所示。
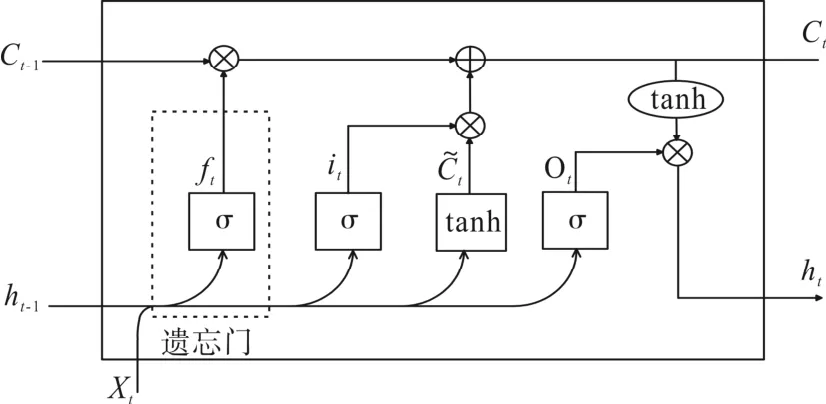
图3 LSTM 遗忘门结构
遗忘门的公式为:
式中:bf—遗忘门ft的偏置项;
Wf—遗忘门的权重矩阵。
2.2.3 细胞状态
主要是用来确定上一层细胞状态Ct-1有多少信息保留在细胞状态Ct中,以及确定输入xt中有多少信息保留在Ct中。前一层的细胞状态Ct-1与遗忘向量ft逐点相乘。如果Ct-1乘以接近0 的值,就表示在新的细胞状态中这些信息将会被丢弃。然后再将得到的值与输入门的输出值相加,将神经网络在t时刻传入的有效信息更新到细胞状态中去。至此,细胞状态便完成了更新。
经过输入门和遗忘门之后,t时刻的细胞状态为:
2.2.4 输出门
输出门决定控制单元Ct输出到ot的信息有多少能输出到隐藏层ht中,用来确定下一个隐藏状态的值。先将前一个隐藏状态信息ht-1和当前输入信息xt传递到Sigmoid 函数中得到ot,然后将新的细胞状态Ct传递给tanh 函数。再将tanh 的输出与Sigmoid 的输出相乘,便得到了隐藏状态最终的输出值ht。最后将ht作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。输出门结构如图4 所示。

图4 LSTM 输出门结构
输出门的公式为:
式中:Wo—输出门ot的权重矩阵;
bo—输出门的偏置项。
3 实验研究
3.1 获取实验数据
3.1.1 原始数据
本次实验的数据为某工厂干燥工艺中干燥器部分DCS 系统所产生的数据,其工艺流程图如图5 所示。低压蒸汽与空气进入干燥器对物料进行干燥,低压蒸汽管线设置远传温度表进行温度监测,同时设置压力指示控制仪表与压力调节阀相连,控制进入干燥器的低压蒸汽流量。空气管线设置流量指示控制仪表与流量调节阀相连,控制进入干燥器的空气流速。同时在干燥器上方设置八旋旋风分离器,干燥器进八旋旋风分离器管线设置温度远传仪表,干燥器上方设置压力指示控制仪表,控制八旋旋风分离器的进风流速。同时在干燥器内设置温度远传仪表,监控2UT-2201 一床上部温度一室、 2UT-2201一床中部温度一室、 2UT-2201 一床下部温度一室、2UT-2201 一床二室上部温度、 2UT-2201 一床二室下部温度、2UT-2201 二床上部温度、2UT-2201 二床下部温度。表1 为各个参数意义表。
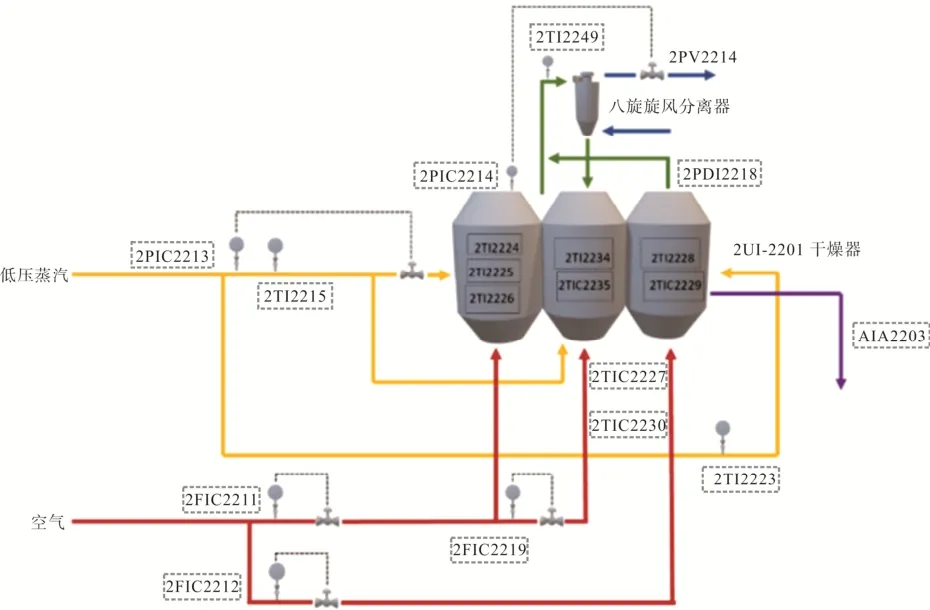
图5 流化床干燥工艺流程简图

表1 各个参数意义表
通过对该工艺实验流程的初步分析,由于在干燥过程中,主要影响干燥效果的参数是温度,所以选取了2TI2249、2TI2224、2TI2225、2TI2226、2TI2234、2TIC2235、2TI2228、2TIC2229、2TIC2227、2TIC2230这10 个重要测温点与含水量数据AIA2203 作为原始数据,时序数据样例见表2。该数据集记录了11 520 条数据。

表2 干燥数据集
本次实验,将干燥数据集前70%数据作为训练集训练模型,并将干燥数据集剩下的30%数据作为测试集,以此来验证该模型的预测能力。
3.1.2 数据处理
为了保证LSTM 模型能够快速收敛并且保持数据一致性,以此来提高模型的预测精度,在输入时对数据进行了归一化处理,在输出时进行去归一化处理。
式中:x—输入数据;
xmin—输入数据的最小值;
xmax—输入数据的最大值;
x'—归一化后的输入数据。
3.2 构建LSTM 模型
本文基于前i(i=720)行的特征向量对第i+ 1行的含水量数据进行预测。i为时间序列长度, 化工干燥数据的预测流程图如图6 所示。
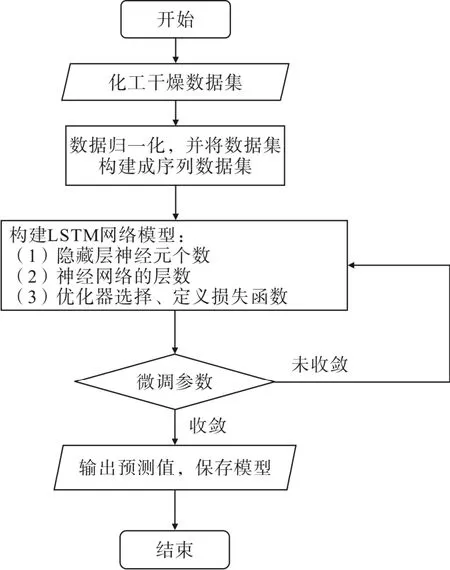
图6 基于LSTM 的干燥数据预测流程
在LSTM 神经网络中,隐藏层神经元的个数的选择至关重要,若神经元数量过少,则会导致欠拟合,若神经元数量过多,则会导致过拟合。
本文通过大量的实验,最终发现隐藏层神经元个数为32 比较好。本次实验采用Adam 优化器,它比SGD 优化器更加稳定,LSTM 层的层数为1 层,学习率为0.001,训练的轮数为50 轮,损失函数为MSELoss 均方损失函数,模型的搭建在Pytorch 深度学习框架下实现。
3.3 模型评价标准
为了更好地展现LSTM 模型对含化工干燥数据含水量的预测结果,本文选取均方误差(MSE)、平均绝对误差(MAE)和均方根误差(RMSE)3 项评价指标来衡量预测结果与实际值之间的差距。具体计算方法如表3 所示。

表3 评价指标及计算公式
其中,yi为实际的含水量值,yˆi为预测的含水量值,N为测试集的样本数量。经过表3 中的公式计算可得:MSE=0.000 058 7,MAE=0.005 968 9,RMSE=0.007 663 9。
4 实验结果
在本次实验中,所选择的测温点10 s 测量一次数据,实验采用的数据集共有11 520 条数据。从工厂操作人员处得知,整个工段流程时间不超过2 h,故本次实验的时间序列长度为720。利用训练好的LSTM 模型,对测试集数据进行预测,其损失函数图形如图7 所示,图8 为真实值与预测值的对比。

图7 损失函数图

图8 模型的预测值与真实值
由图8 可以看出,随着训练次数的增加,损失函数减小到了较小的范围内,模型的预测值和干燥数据的真实值走向非常接近,说明了LSTM 模型的训练效果非常好。
5 结 论
由于化工产品的干燥含水量数据具有非线性、非平稳性以及序列间的相关性等特点,导致一些传统的预测方法所预测的精度都不高,如传统的人工神经网络对化工干燥含水量数据预测后的准确率非常低。近年来,LSTM 神经网络模型已经被许多学者用来预测具有时间序列的数据,如金融领域的股票收盘价,并且得到的预测结果相比其他的方法具有更高的准确率,这说明了LSTM 在处理时序数据方面具有独特的优势。
本文基于Pytorch 深度学习框架构造LSTM 神经网络模型,并将其运用于预测化工干燥含水量的问题上,实验发现,用该模型来进行预测,得到的预测值和真实值的走向非常逼近,并且MSE、MAE、RMSE 这3 项衡量预测结果与实际值之间差距的评价指标均较小,说明模型的预测精度高,误差较小,代表模型具有较强的泛化能力,同时也证明了LSTM 神经网络用于处理化工干燥含水量这类顺序数据同样具有一定的优越性。
由此可见,LSTM 神经网络模型用于对工厂实际生产的产品含水量进行实时预测的效果非常好,在实际生产中,这对工厂加快生产效率、降低人力成本、提高化工产品质量起到了极其重要的作用。未来可以考虑对数据进行降噪处理或对LSTM 模型的结构做出改进,以进一步提高精度。
