基于深度强化学习的云制造产品配置
2023-12-22童晓薇刘艳斌
童晓薇,刘艳斌
(1.福建船政交通职业学院 机械与智能制造学院,福建 福州 350007;2.福州大学 福建省高校测试中心,福建 福州 350116)
云制造是一种基于云计算技术提供网络化、低成本的大规模、个性化网络协同制造的服务模式[1]。自2010年云制造技术提出以来[2],受益于云制造基础设施逐步完善,大规模定制成为重要的生产模式[3-4]。在大规模定制环境下,随着可配置产品单元增强,基于多目标优化的产品配置方法逐步被引入。袁际军等[5]通过对多目标混合整数规划模型求解,快速获得了最优产品配置推荐方案。朱佳栋等[6]通过改进设计交互式遗传算法,实现了多功能液压千斤顶的配置设计优化。雷成名等[7]以产品配置成本、碳排放量和产品可靠度为优化目标,建立了多目标优化模型。
在云制造环境下,各类软硬件故障、材料缺失、订单调整、优先级变更、需求变化等动态因素更为突出,产品配置面临更加复杂的环境[8-9]。因此,本文针对云制造环境的动态变化性,提出一种基于深度强化学习的产品优化配置方法,系统地分析产品配置建模及优化关键技术点,旨在为云制造环境下的大规模产品定制实施提供一种新思路。
1 云制造环境下产品配置建模
1.1 问题描述
基于云制造服务的产品配置,需要将产品定制需求层次化地分解为部件、零件、加工工序,形成一系列粒度适合、便于协同的制造任务,构成以有向图、无环图描述的制造任务流程。根据制造任务流程,对照云制造平台的服务标准选择对应的候选服务集合,从中优选制造服务实例,将产品制造需求配置为云制造服务实例集,完成云制造环境下的产品配置。基于云制造服务的产品配置过程如图1所示。
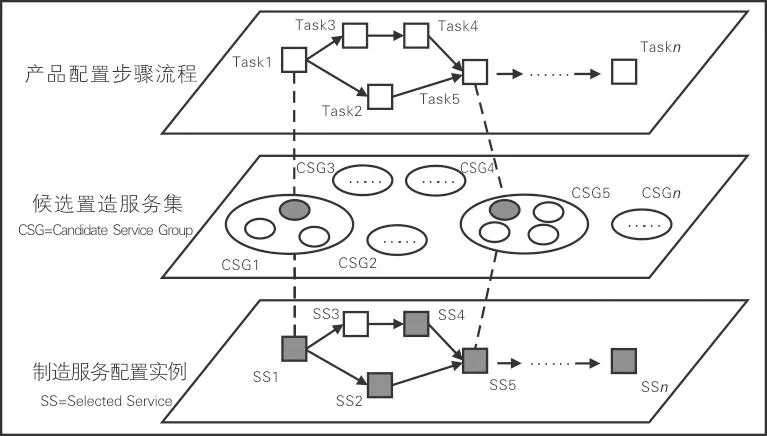
图1 基于云制造服务的产品配置过程
云制造服务的生产价格、物流成本、交付时间、服务评价等与产品配置息息相关的指标经常发生变化,服务提供商的加入和退出、制造服务的注册与注销、制造服务承载力变动、制造成本变动等因素都加剧了的制造过程的不确定性。为实现动态复杂云制造环境下制造服务的优选及有效调度,引入产品配置全过程服务质量(Global Quality of Service,GQoS)指标,以GQoS的最大化为目标从云制造平台匹配的候选服务集中筛选出最优的云制造服务实例,并对云制造产品配置活动进行合理的限定与假设。从需求提出到完成产品配置需要经历任务求解、候选制造服务匹配、最优制造服务选择3个阶段。本文假定任务已经求解完毕并,容易获得对应的候选服务,集中讨论最优制造服务选择问题。产品配置步骤通常包括串行、并行及其组合。为简化问题,本文以串行步骤为典型过程进行建模与优化求解,但主要结论仍适用于组合流程。
1.2 模型建立
由于不同的配置步骤候选制造服务的加工时间、成本、质量属性分值不同,因此需要先进行归一化处理。根据产品配置目标“时间短”“成本低”“服务评价高”,归一化处理时对加工时间、物流配送时间、加工成本、物流配送成本取负值。归一化处理过程为:
(1)
(2)
(3)
(4)
(5)
式(1)~(5)中,j为配置步骤,j=1,2,…,n;tj和cj分别为配置步骤j所选择的制造服务的加工时间和加工成本;rtj,j+1和rcj,j+1分别为步骤j到下一步骤j+1的物流配送时间和物流配送成本,实际中,步骤j到下一步骤j+1的物流不总是发生,如2个步骤采用同一供应商、在同一地理位置或者不存在资源依赖关系,则对应的rtj,j+1与rcj,j+1值为0;qj为服务质量评价;utj为归一化加工时间;urtj,j+1为归一化物流配送时间;ucj为归一化加工成本;urcj,j+1为归一化物流配送成本;uqj为归一化服务质量评价。
构建云制造环境下产品配置模型的目标函数为maxGQoS,即最大化产品配置全过程服务质量。其中,GQoS由总配置步骤n的时间、成本、服务质量评价的加权和组成,表达式为:
(6)
式(6)中,Wt、Wc、Wq分别为时间属性、成本属性、服务质量评价属性在产品配置优化目标中的权重,且满足Wt+Wc+Wq=1。
约束条件为:
(7)
sj=rsj,∀rsj∈CR
(8)
式(7)表示产品的制造时间(包括所有步骤的加工时间和物流时间)不能超过客户对产品交付时间的最长期限DT;式(8)表示用户可要求特定配置步骤sj采用指定云制造服务;CR为用户指定选择的云制造服务的集合。
2 基于深度强化学习的云制造产品配置
2.1 云制造产品配置的强化学习建模
云制造产品配置强化学习模型的整体框架如图2所示。

图2 云制造产品配置强化学习模型的整体框架
云制造产品配置问题主要涉及产品配置各步骤的服务选择决策,每一个步骤需要形成确定的服务选择策略,是典型的离散动作空间问题。本文采用基于价值方法的深度强化学习路线,使用主流的深度Q网络算法作为产品配置多目标优化决策算法。在任意的一个时间步,智能体首先观测到当前环境的状态St,以及当前对应的奖励值Rt。基于这些状态和奖励信息,智能体决定如何行动,而后执行动作At,环境状态转移到St+1。
1)智能体:强化学习通过智能体与环境的不断互动来迭代学习,不需要预先给出监督数据或对环境完全建模,智能体是云制造产品配置策略动作的执行程序。
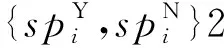
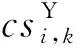
4)奖励:强化学习的目的就是教会智能体如何很好地与环境交互,从而在预先定义好的评价指标下获得好的成绩。为了让智能体从环境中获得反馈,需要在智能体执行动作后在每一个时间步上给予一个立即奖励Rt。在一些情况下,深度强化学习的奖励函数只取决于当前的状态,即Rt=R(St)。云制造配置场景中,在判断更关注成本还是时间、需要尽量选择同一个服务提供商还是局部分散时,难以根据单个配置环节的环境状态得到长期最优决策。因此,本文将奖励设计为基于前序整体配置过程得到的累积奖励,单个环节的奖励采用1.2节所述公式(6)计算。
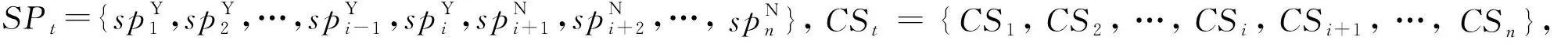
2.2 基于深度Q网络的产品配置求解
结合云制造环境下产品配置建模,建立DQN网络结构如图3所示。
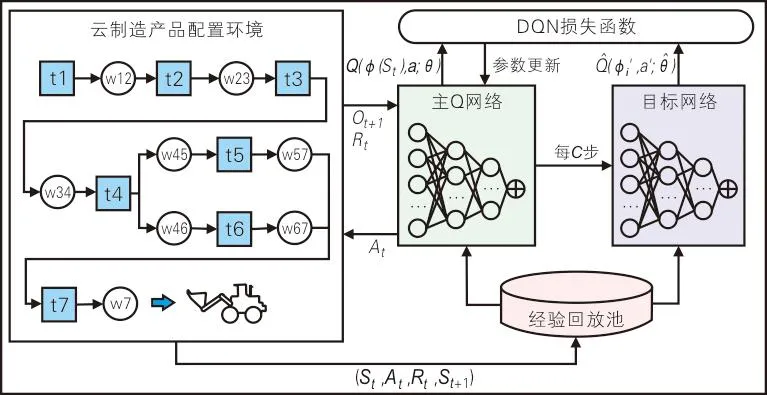
图3 DQN网络结构
深度Q网络(Deep Q-network,DQN)结合了Q-Learning和深度学习解决近似学习状态-动作值函数方法的收敛不稳定性问题,主要思想是用深度神经网络实现对状态-动作值函数的非线性拟合,即用Q值函数Q(S,Ai;θ)替代Q值表。DQN用一个经验回放池D来解决连续样本间的相关性问题,对智能体与环境交互取得的经验数据进行离线更新。智能体采用ε-greedy策略进行动作选择,产生经验数据e=(St,At,Rt,St+1)存到D中,然后从D中随机采集小批量样本用于网络训练,即Q-Learning更新。相较于拟合Q值迭代,经验回放机制可以使用新旧经验来学习Q函数,提高数据的使用效率。如果没有经验回放机制,一个批次中的样本将会连续采集,样本之间高度相关,增加更新的方差,降低DQN的学习效率。
引入目标网络的机制同样很关键。DQN的神经网络部分是由2个结构相同、参数不同的网络组成,即主Q网络与目标网络。主Q网络作为主网络拥有最新参数,负责输出当前的状态-动作下Q的估计值Q(St,At)。目标网络是独立生成Q-Learning目标的网络,不会即时更新参数,每C步将通过硬更新(直接复制)或软更新(指数衰减平均)的方式与主Q网络同步。由于通过使用旧参数生成Q-Learning目标,目标值的产生不受最新参数的影响,避免了过估计的问题,从而大大减少震荡和发散的情况。基于DQN的云制造产品配置优化算法如下。
1:超参数:经验回放池容量N,奖励折扣因子γ,目标值网络更新频率C,ε-greedy中的。
2:输入:空经验回放池D,初始化状态-动作值函数Q的参数θ。
4:for片段= 0,1,2,…,do。
5:初始化环境并获取观测数据O0。
6:初始化序列S0={O0}并对序列进行预处理φ0=φ(S0)。
7:fort=0,1,2,…,do。
8:通过概率选择一个随机动作At,否则选择动作At=arg maxaQ(φ(St),a;θ)。
9:执行动作At并获得观测数据Ot+1和奖励数据Rt。
10:如果本局结束,则设置Dt=1,否则Dt=0。
11:设置St+1={St,At,Ot+1}并进行预处理φt+1=φ(St+1)。
12:存储状态转移数据(φt,At,Rt,Dt,φt+1)到D中。
13:从D中随机采样小批量状态转移数据(φt,At,Rt,Dt,φ't)。
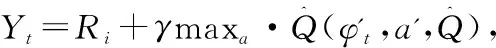
15:在Yi-Q(φi,Ai,θ)上对θ执行梯度下降步骤。
17:如果片段结束,则跳出循环。
18:end for
19:end for
3 实验结果与分析
3.1 实验数据及仿真设置
采用文献[10]和[11]构建的云制造平台在工程机械行业试点运行期间的数据集进行模型训练、验证。数据集涉及某型号轮式装载机的产品配置步骤及其对应的云制造服务,具体包括4家制造服务供应商、1 087个云制造服务,预定义了轮式装载机铲斗、驾驶室等18个产品配置流程环节。某型号轮式装载机云制造服务部分数据样例见表1,云制造物流服务部分数据样例见表2。
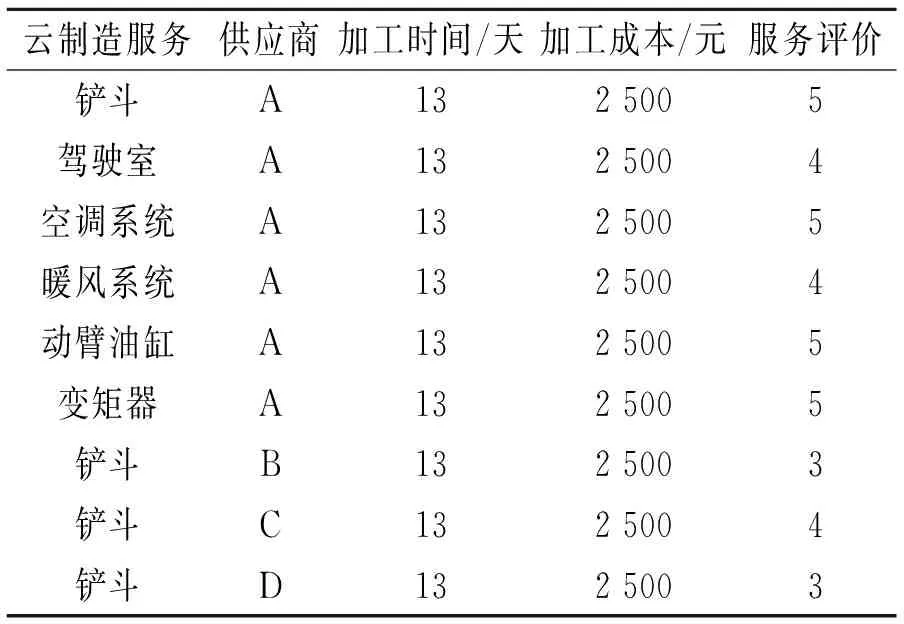
表1 某型号轮式装载机云制造服务部分数据样例
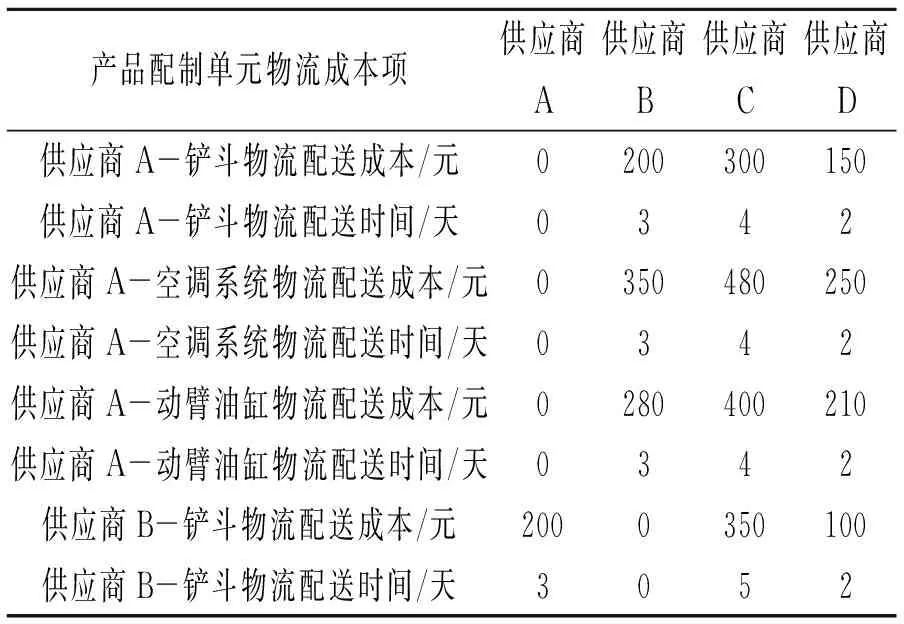
表2 云制造物流服务部分数据样例
强化学习算法通过不断观测环境并与之交互获得知识。实验构建了基于某轮式装载机云制造数据的仿真模拟器,作为强化学习交互的环境,针对强化学习算法给出的产品配置动作(选择特定的云制造服务),基于2.2节阐述的奖励函数进行反馈,同时更新“配置步骤空间”与“制造服务空间”环境信息。为实现对云制造环境动态性的仿真,模拟器实现了随机的制造服务提供商退出、云制造服务不可用、物流时间超过估计时长等动态变化,以模拟真实云制造过程中可能出现的供应商撤单、机器故障、物流异常等情况,以提高算法的鲁棒性。随机错误的比例设置为约3%,客户指定的配件(云制造服务)比例设置为约3%,限定制造时间为不超过60天。
服务器设备搭载Intel Xeon E5-2698 V4处理器,64 GB内存,NVidia V100 GPU卡;软件环境为CentOS 7.5操作系统,Python 3.8编程环境,PyTorch 1.8深度学习框架。模型迭代学习次数为20 000次,初始学习率为0.000 25,采用自适应矩估计(Adaptive Moment Estimation,ADAM)算法更新网络参数,采用整流线性单元(Rectified Linear Units,RELU)函数作为隐藏层激活函数。模型训练时,每次从容量为100 000的经验回放池中选择批次大小为64的数据样本用于智能体学习,每次迭代更新Q值网络参数,每迭代500次将Q值网络的参数复制到目标值网络,实现目标值网络参数更新。奖励折扣因子设置为0.99,ε-greedy中的设置为1。
3.2 实验结果分析
根据文献[10]和[11]云制造平台的试运营经验,工程机械行业客户对云制造服务的关注点依次为“成本低”“时间短”“服务评价高”,故合理设定对应的优化目标Wt、Wc、Wq分别为0.3、0.6和0.1。由于优化目标是强化学习过程收敛的主要导向,也可以根据实验设定或产业实际需求做相应调整、获得关注点构成不同的模型;实验采用的奖励值函数与1.2节公式(5)的优化目标一致,均为截至目前的产品配置的全局奖励归一化值。将Wt、Wc、Wq都归一化到[0,1]区间,理论上最优全局奖励为0.1。模型训练得到损失值变化曲线和奖励值变化曲线分别如图4和图5所示。
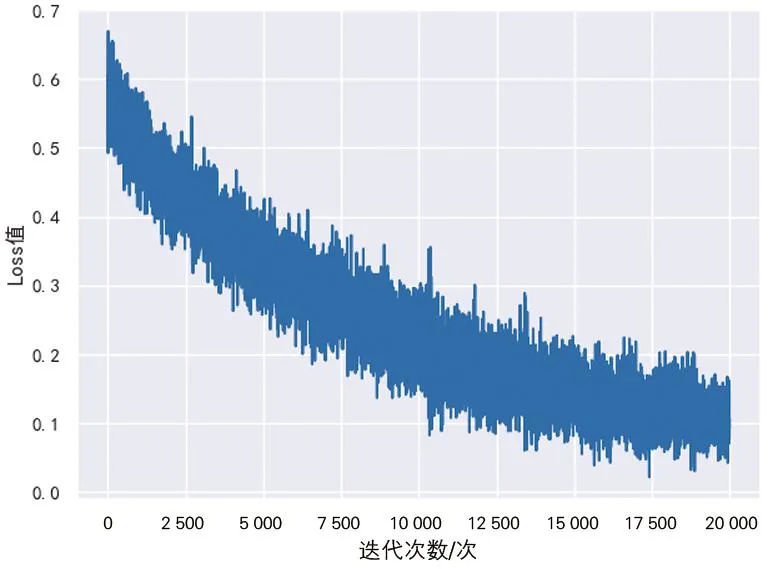
图4 模型训练损失值变化曲线
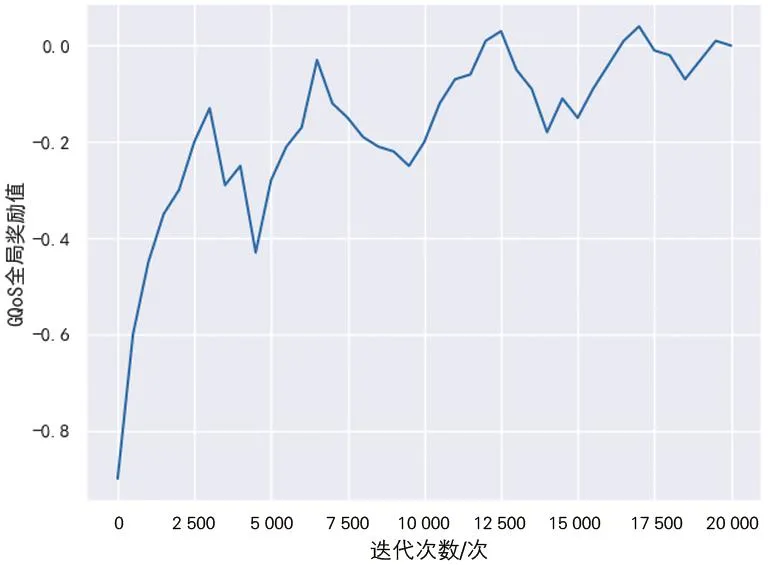
图5 模型训练奖励值变化曲线
由图4可知,DQN算法学习的损失值逐渐下降,当训练的迭代次数达到13 000次左右时,损失值基本收敛,意味着深度强化学习的超参数配置基本合理,算法运行基本正确,能够获得所需要的模型。
由图5可以看出,随着训练迭代次数增加,奖励值也在不断增加且逐步稳定。这意味着基于深度强化学习DQN算法的云制造产品配置模型的效果在不断提高。迭代次数达到10 000次以上时,GQoS全局奖励值在较小范围内波动,与损失曲线基本一致。模型全局奖励值最终接近且收敛于理论奖励值上限0.1,这表明基于DQN的产品配置求解方法可以获得接近最优化的配置目标,也说明了将强化学习方法应用于云制造环境下的产品配置在总体来看是可行的,达到实验目的。
4 结论
以全过程服务质量最大化为目标建立了云制造环境下产品配置模型,将云制造环境下的产品配置问题建模为强化学习问题,对强化学习的关键组件进行了完整表达,设计了基于深度Q学习的求解算法。轮式装载机产品配置的仿真实验表明,模型可以获得接近最优化的配置目标,验证了深度强化学习对云制造环境下的产品配置优化问题的有效性。
