基于联合注意力-可分离卷积的立体匹配算法
2023-12-09张伟黄娟顾寄南黄则栋李兴家刘星
张伟, 黄娟, 顾寄南, 黄则栋, 李兴家, 刘星
(江苏大学机械工程学院, 镇江 212000)
立体匹配是计算立体彩色图像对的对应点偏差以获得密集视差图的过程。它广泛应用于双目测距[1]、自动驾驶[2]、三维重建[3]、机器人导航等领域。作为双目视觉系统的核心技术,立体匹配精度决定着整个系统的性能。传统算法将立体匹配过程分为代价计算、代价聚合、视差计算和视差优化四个步骤。但随着深度学习在计算机视觉领域的广泛应用与快速发展,基于卷积神经网络(convolutional neural network,CNN)的端到端立体匹配算法逐渐代替了传统算法。相比于传统算法,立体匹配算法有着更高的匹配精度且不需要繁杂的手动操作步骤。
Mayer等[4]提出Disp-Net(disparity network),构造了第一个端到端的立体匹配网络,提出用卷积代替WTA(winner take all)直接回归视差。Kendall等[5]提出GC-Net(geometry and context network),第一次利用3D卷积的概念去获得更多的上下文信息,并采用回归的方法去预测视差值。Chang等[6]]提出PSM-Net(pyramid stereo matching network),首次引入了金字塔池化模块[7]将全局环境信息结合到图像特征中并提出了一个堆叠的沙漏3D CNN来扩展匹配代价卷中的上下文信息。Guo等提出Gwc-Net(group-wise correlation stereo network)[8],在构建代价体时采用分组相关和通道拼接两种方法,组成联合代价提并简化3D聚合网络。此时立体匹配网络的匹配精度达到最高。
上述方法均致力于研究聚合更多上下文信息,解决反射、弱纹理等不适定区域的匹配精度问题。但随着3D聚合网络的提出,使得深度学习立体匹配网络参数量剧增,模型运行时间长。因此,Xu等[9]提出的AA-Net(adaptive aggregation network)用同尺度聚合模块(intra-scale cost aggregation,ISA)和跨尺度聚合模块(cross-scale cost aggregation,CSA)代替原网络模型中的3D卷积聚合模块;Xiao等[10]将轻量化shuffle net应用于3D聚合网络,提出了一种高效的轻量级体系结构。最近的研究趋势偏向于轻量级立体匹配网络,但带来的问题是其匹配精度也随之减低。
针对上述问题,现嵌入联合注意力机制和空洞金字塔池化(atrous spatial pyramid pooling,ASPP)[11]模块,用3D深度可分离卷积代替标准3D卷积,提出一种新的轻量级高精度算法CAS-Net。嵌入的卷积块注意力机制先将提取特征在空间和通道维度进行加权,从而提高重要特征的表征能力并抑制不必要的特征,在利用空洞金字塔池化(ASPP)模块选择不同膨胀率的空洞卷积来扩大感受野,提取多尺度的上下文信息。最终将多尺度特征通过组相关和级联的方式形成联合代价体,送入新的轻量级特征聚合网络对联合代价体进行学习。从而生成一个性能更好的特征提取网络和更加轻量的特征聚合网络。
1 CSA-Net网络模型设计
本文所提出的CSA-Net算法以Gwc-Net为基准,此模型在特征提取部分运用二维标准卷积,在3D聚合网络部分运用三维深度可分离卷积。根据参数量计算原理:F×F×F×Cin×Cout(F为卷积核大小,Cin为输入通道,Cout为输出通道),本模型运用三维深度可分离卷积,在模型复杂度上优于基准网络。
算法模型如图1(a)所示。整体网络模型分为4个部分:特征提取,构建代价体,特征聚合,视差回归。具体算法流程为:将两张左右RGB图像输入特征提取网络进行权重共享特征提取,随后在视差维度整合左右特征,利用级联(Concat)和组相关(Group-wise correlation)的方式形成联合4D匹配代价体(cost volume),再将4D匹配代价体送入特征聚合网络,聚合空间和通道维度的信息,学习匹配成本(cost)估计,最后将学习到的cost进行上采样恢复原图大小后通过SoftMax回归预测视差,输出最终视差图。
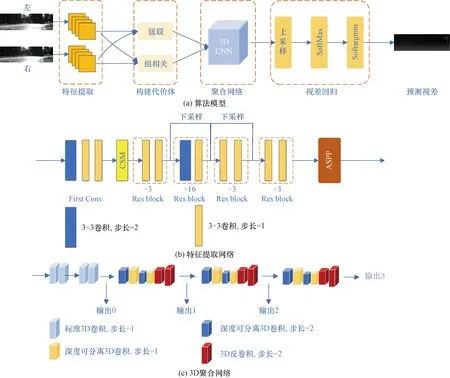
图1 网络模型结构图Fig.1 Network model structure diagram
1.1 特征提取网络
鉴于很多立体匹配算法的特征提取网络并未对输入图像的通道和空间维度进行加权关注与抑制,且对于现实场景中的反射和遮挡等不适定区域,原网络并未能够提供多尺度的上下文信息。因此本文所提出的网络针对上述问题上加入了联合注意力机制[图2(a)]与空洞金字塔池化(ASPP)模块[图2(b)]。
联合注意力机制如图2(a)所示,由通道注意力[12]和空间注意力[13]组成。联合注意力机制根据空间和通道的两个维度分别计算相应的特征图,从而引导模型更加关注图像中最具辨别力的区域,以提高模型任务的准确性。通道注意力模块Mc提取对目标具有高贡献的通道注意力图,空间注意力模块Ms以级联方式提取空间注意力图,以获得最终输出。全局最大池化操作可以获得目标之间最多样的特征,这有助于推断更精确的渠道注意力。因此,同时对于空间和通道注意力均同时使用全局平均池化[14]和全局最大池化[14]。对于大小为C×H×W(C为通道数,H为特征图高,W为特征图宽)的特征图F,经过最大池化层和平均池化层,将特征图在空间维度压缩为C×1×1,然后经过共享全连接模块得到两个结果并进行相加,再通过一个sigmoid激活函数得到通道注意力的输出结果Mc,表达式为
Mc=∂{FC[max(F)]+FC[avg(F)]}
(1)
式(1)中:FC为全连接操作;∂()为sigmoid函数;max()和avg()为最大池化和平均池化操作。最后将输出结果乘以输入特征F得到F′,即
F′=McF
(2)
并作为空间注意力的输入。F′通过全局最大池化和全局平均池化得到两个1×H×W的特征图,然后经过拼接操作对两个特征图进行拼接,通过7×7卷积变为通道数为1的特征图,再经过一个sigmoid得到空间注意力的输出结果Ms,即

图2 联合注意力机制和空间金字塔池化模块Fig.2 Joint attention mechanism and spatial pyramid pooling module
Ms=∂{conv7×7[max(F′);avg(F′)]}
(3)
式(3)中:conv7×7为大小为7×7的卷积操作。最后乘以空间注意力的输入F′得到联合注意力的最终输出特征图F″,即
F″=MsF′
(4)
空洞金字塔池化(ASPP)模块如图2(b)所示,对输入特征图以扩张率分别为1、6、12、18的空洞卷积同时进行稀疏采样,然后将采样得到的特征图在通道维度进行拼接,扩大通道数;最后通过1×1的卷积将通道数调整为理想输出通道数。空洞卷积在不引入额外参数的情况下设置卷积扩张率,增大卷积的感受野可以捕获多尺度上下文信息,进一步利用学到的上下文来提高特征的可辨识度。
特征提取网络如图1(b)所示,先通过一个由3组3×3卷积+BN层+ReLU组成的first conv 进行左右图像特征预提取,随后将得到的特征输入联合注意力机制进行不同维度的加权操作,关注不同维度的有效特征。经过联合注意力机制加权后的特征图将被送入4组类ResNet[15]网络进行深度特征提取,将最后3组特征图在通道维度进行拼接得到320通道的特征图,将320通道的特征图输入空洞金字塔模块进行多尺度上下文信息的提取,最终的输出特征图保持320通道。
1.2 3D聚合网络
许多其他计算机视觉问题需要3D卷积来对4D数据进行操作,最近出现了使用3D卷积进行立体匹配的前景,其中3D卷积用于处理4D成本数据。但是3D卷积的使用会造成网络参数量激增,例如一个2D卷积的参数量为F×F×Cin×Cout,而一个3D卷积的参数量为F×F×F×Cin×Cout(F为卷积核大小,Cin为输入通道,Cout为输出通道)。因此相同情况下一个3D卷积的参数量为2D卷积的F倍,这导致了网络模型复杂化,运行时间长。
在本文中,构建的匹配代价体(cost volume)在C×H×W的基础上增加了深度维度,即为一个C×D×H×W的4D数据,因此也需要用3D卷积聚合网络来处理4D匹配代价体数据。3D聚合网络如图1(c)所示,该网络由一个预沙漏模块(4个标准卷积)和3个堆叠的3D沙漏网络组成。本文主要目的是将立体匹配网络轻量化,运用标准3D卷积构成沙漏模块会增加网络模型参数量,所以本文提出将2D轻量级深度可分离卷积[16]提升到3D,代替原来聚合网络沙漏模块中的标准3D卷积从而降低参数量减少运行时间。
2D深度可分离卷积如图3(a)所示,3D深度可分离卷积如图3(b)所示。由于输入卷积操作的数据由3D变为4D,因此其卷积核大小也由原来的F×F变为F×F×F。3D深度可分离卷积由一个3D深度卷积和一个3D点卷积组成。首先,利用深度卷积在通道维度进行逐一特征卷积,其次利用一个点卷积实现通道维度的特征信息融合,且通过一个1×1×1的卷积降低参数量。3D深度可分离卷积的参数量为F×F×F×Cin+1×1×1×Cin×Cout(F为卷积核大小,Cin为输入通道,Cout为输出通道)。假设F=3,Cin=32,Cout=16,将数据代入上述标准3D卷积与3D深度可分离卷积,可得标准3D卷积参数量为13 824,3D深度可分离卷积参数量为1 376。因此可知在相同输入与输出的情况下,3D深度可分离卷积参数量仅约为3D标准卷积参数量的1/10,基于此实现网络的轻量化。

图3 2D和3D可分离卷积Fig.3 2D and 3D depth separable convolution
1.3 损失函数
4D匹配代价体(cost volume)由特征聚合网络聚合后得到匹配代价cost,将匹配代价送入视差回归模块,通过两个标准3D卷积将通道维度压缩至1通道, 在使用进行上采样操作将视差图恢复到原图大小。由网络结构图可看出本网络共输出4个预测视差图,通过SoftMax函数运算预测匹配代价,计算在最大视差范围内每个视差值的概率。本文采用soft-Argmin 回归方法得到预测视差图,即每个视差图的预测视差Dpre被计算为每个视差d的总和,由其概率加权表示为
(5)
式(5)中:Dpre为预测视差;Dmax为最大视差值;d为范围内视差值;Pd为d的概率。
本文采用平均绝对误差L1[17]来评估视差预测效果。与均方误差L2相比,平均绝对误差L1的鲁棒性更强,对异常点不敏感,所以使用L1的模型的误差会比使用L2的模型对异常点敏感度更低。平均绝对误差L1计算公式为
(6)
式(6)中:smoothL1(·)为损失函数;x为函数变量。每个输出视差图的平滑损失L1可表示为
(7)
式(7)中:N为视差图像素总数;Dt,i为第i个像素的视差真值;Dpre,i为第i个像素预测视差值。为了充分利用输出的4个预测视差图,在计算损失时对每个输出视差图output 0,1,2,3分别分配不同的权重,则加权之后的模型总损失表示为

本文以CNKI为数据来源,在高级检索中选择“期刊检索”,以“网络信息行为”为检索词进行主题检索,共检索到322篇文献,剔除不符合研究主题或者重复的文献,共得到310篇文献。
(8)
式(8)中:Kj为赋予预测视差图的权重,j=0,1,2,3。
2 实验设计及分析
2.1 实验设计
依据本实验室现有硬件环境,本文实验操作系统为Ubantu18.04,GPU型号为个 NVIDIA RTX 2080Ti,显存大小为11 GB。算法在 Python3.8,Pytorch1.8框架下训练,模型在训练时采用Adam优化器(β1=0.9,β2=0.999)进行梯度下降。为了验证本文所提算法的性能,将算法在两个常用数据集SceneFlow和KITTI上进行训练测试验证。
本文模型先使用SceneFlow数据集作为网络的预训练数据集进行预训练,设置训练迭代轮次为10轮。依据GPU显存大小设置批量大小为2,初始学习率为0.001,当网络迭代到第4轮和第6轮时,学习率分别下降一半,防止训练过程中学习率过高导致模型过拟合。SceneFlow预训练完成之后,得到的预训练权重用于训练KITTI数据集。对于KITTI数据集,设置训练轮次为300轮,批量大小为2,初始学习率为0.001。当训练到200轮后,网络学习率下降为原来的10倍。参数设置完成后加载预训练权重对KITTI数据集进行训练。
2.2 数据集
2.2.1 SceneFlow
SceneFlow[18]数据集是一个大型的合成数据集,用来训练立体匹配网络。由Flyingthings3D、Driving和Monkaa三部分组成,共有35 454张训练图像和4 370张测试图像,图像大小为960×540。SceneFlow有Finalpass和Cleanpass两个版本,在本文方法中使用Finalpass进行预训练,因为它包含更多的运动模糊和散焦,比Cleanpass更接近真实世界。在深度学习立体匹配网络中SceneFlow由于其样本数量足够大,通常被当作预训练数据集增强网络泛化性,以用于后期真实数据集的训练。
2.2.2 KITTI12&15
KITTI 2012[19]和KITTI 2015数据集是一个面向自动驾驶场景的室外真实数据集。KITTI 2012提供194个训练和195个测试图像对,KITTI 2015提供200个训练和200个测试图像配对,图像大小均为1 240×376。在训练KITTI数据集钱前,需先将图片在空间维度进行补“0”操作,将图片大小扩充为1 248×384在训练时,将训练集按照80%和20%的比例划分为训练集和验证集。
2.3 评价指标
对于SceneFlow数据集,评估指标通常是端点误差(end-point-error,EPE),即像素中的平均视差误差,EPE可表示为
(9)
对于KITTI 2012,报告了非遮挡(noc)区域像素和所有(all)像素的预测误差值超过设定阈值像素占像素百分比。对于KITTI 2015,针对背景(bg)、前景(fg)和所有(all)像素评估视差异常值D1的百分比(异常值D1即为误差大于初定误差阈值的预测视差。)本文中对于KITTI12误差阈值设置均为2像素、3像素、5像素,KITTI15误差阈值设置为3像素,以利于与其他算法进行实验结果对比。
2.4 消融实验
为了验证CSM模块、ASPP模块和3D深度可分离卷积对于网络匹配精度和运行速度的影响,在KITTI12和KITTI15数据集上测试3像素的误差率,以此进行消融实验。
如表1所示,当分别使用CSM模块和ASPP模块时,模型在两个测试数据集上的匹配精度均比同时使用的精度低,且CSM模块对匹配精度的影响较大。由表中运行时间可看出,CSM模块和ASPP模块对模型运行速度影响较小。
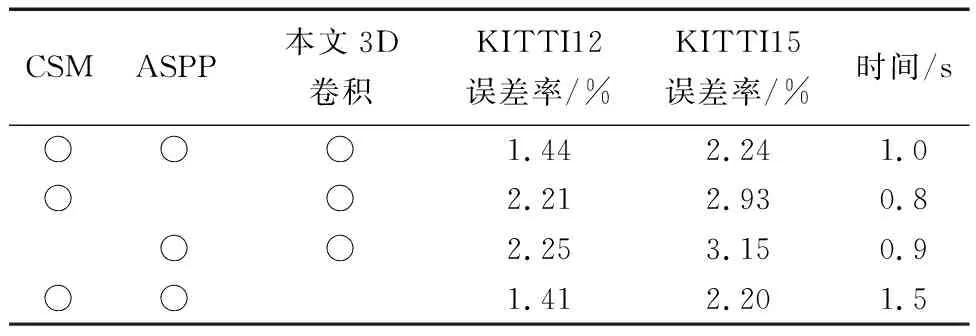
表1 不同模块对网络性能的影响Table 1 The impact of different modules on network performance
当使用本文所提出的3D深度可分离卷积时,模型匹配精度并未明显降低,但是运行时间比使用标准3D卷积快了1/3。
2.5 实验结果对比
本文旨在于在不损失网络模型匹配精度的情况下降低网络的参数量,减少网络的运行时间。为验证本文方法的有效性,分别利用KITTI12和KITTI15测试集在网络训练模型上进行测试得到预测视差图。由于KITTI数据集官方未向使用者提供视差真值,所以将KITTI12的195张预测视差图与KITTI15的200张预测视差图上传至KITTI官方得到匹配误差值。
如表1所示,本文模型在KITTI15测试集上测试时,在全部像素(all)区域,背景异常值(D1,bg)相较于基准网络模型GwcNet降低了0.05%,前景异常值(D1,fg)降低了0.49%。在非遮挡像素(noc)区域,背景异常值(D1,bg)降低了0.02%,前景异常值(D1,fg)降低了0.05%其可视化结果如图4所示,从预测视差图可看出对于如石杆、广告牌等细节部位有较好的匹配精度。如表2所示,本文模型在KITTI12测试集上测试时,在误差阈值为2 px和3 px时,其误差率均优于GwcNet,且在本文对比算法中达到最低。
如表3所示,本文模型的参数量相比于GwcNet大大减少,3D聚合网络的参数量仅约为原算法的5/13,模型总参数量仅约为原算法的3/4。如表4所示,在运行时间上,本文模型训练KITTI15数据集的一个迭代的时间约为1.01 s,原算法运行一个迭代的时间约为1.47 s,降低了约1/3,在训练总时间上也减少了2.8 h,由此可看出本文所提出的算法相较于原算法实现了轻量化的目的。

图4 KITTI15可视化结果Fig.4 Visualization Results of KITTI15

表2 不同方法在KITTI 15测试集上的结果比较Table 2 Comparison of results of different methods on KITTI 15 test set

表3 不同算法在KITTI 12测试集上的结果比较Table 3 Comparison of results of different algorithms on KITTI 12 test set
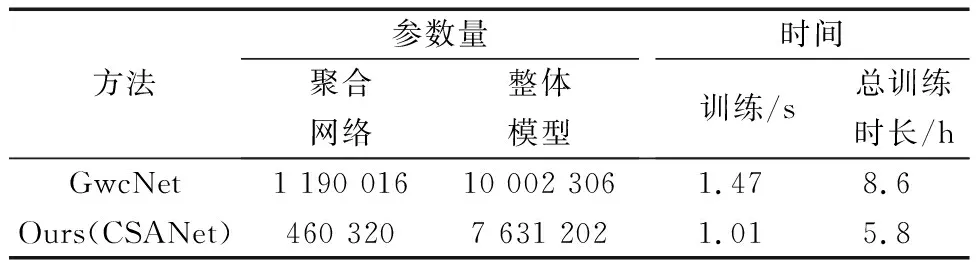
表4 不同算法模型参数量与运行时间的结果比较Table 4 Comparison of parameters and running time of different algorithm models
3 结论
本文提出了基于联合注意力(CSM)、空洞金字塔池化(ASPP)和3D深度可分离卷积的立体匹配算法来估计双目图像对的视差图。通过实验得出以下结论。
(1)由于在特征提取网络引入联合注意力可以在空间和通道两个维度进行加权关注,且空洞金字塔池化(ASPP)利用不同膨胀率的卷积来扩大感受野,提取对尺度上下文信息,这提升了网络对于不适定区域特征提取能力,进而将模型在KITTI 2012和2015数据集上在三像素匹配误差率提高为1.44%和2.24%。
(2)在特征聚合网络利。用3D深度可分离卷积代替标准卷积降低了网络的参数量,减少了运行时间。通过最终利用网络模型在不同数据集上测试的实验结果表明,本文所提出的算法在不减少精度的情况下减少了模型参数量,运行时间降低了近1/3,解决了高精度与轻量化不能共存的问题。
