融合XLM词语表示的神经机器译文自动评价方法
2023-12-06李茂西裘白莲王明文
胡 纬,李茂西,裘白莲 ,王明文
(1. 江西师范大学 计算机信息工程学院,江西 南昌 330022;2. 江西开放大学 现代教育技术中心,江西 南昌 330046;3. 江西师范大学 管理科学与工程研究中心,江西 南昌 330022)
0 引言
机器译文自动评价方法是机器翻译研究的直接推动力,其极大地促进了机器翻译的研究和系统开发。一方面,译文自动评价结果方便用户选择更好的翻译系统;另一方面,译文自动评价结果能够使系统开发者及时地了解翻译性能,以便开发更好的翻译系统[1-2]。
机器译文自动评价方法大都是通过对比机器翻译系统的输出译文和人工参考译文来定量计算译文的质量。BLEU[3]、模糊匹配的BLEU[4]、NIST[5]、METEOR[6]、METEOR-SD-Makov[7]和 TERp[8]等基于词语匹配统计信息的方法使用词形、词根和同义词等信息对机器译文和人工参考译文进行对比计算译文质量;基于句法[9-10]、语义结构匹配[11-12]的方法使用词语的词性知识、句子的短语结构树、依存结构树和语义角色标注信息等对机器译文和人工参考译文进行对比计算译文质量。近年来,随着深度神经网络在自然语言中的成功应用,许多学者将词语的分布式表示应用在译文自动评价中,包括基于静态词向量的方法[13]和基于动态上下文词向量的方法[14]。
然而,当前神经译文自动评价方法均只在目标语言的深度语义空间对比机器译文和人工参考译文,评价时不仅缺乏源语言句子的对照参考,而且没有在同一语义空间对比源语言句子和机器译文的语义差异。针对这个问题,本文尝试使用跨语种预训练语言模型XLM[15]将源语言句子、机器译文和人工参考译文映射到同一语义空间以计算差异特征: 人工参考译文和机器译文构成的深度语义信息反映了同语种下机器译文语义与真实语义之间的差异;源语言句子和机器译文构成的深度语义信息反映了不同语种下机器译文语义与真实语义之间的差异;源语言句子和人工参考译文构成的深度语义信息作为评价的黄金参考。为使提取的句子表征充分考虑不同网络层和不同词语位置所包含的深度语义信息,本文分别在XLM模型表示的纵向和横向上使用分层注意力[16]和内部注意力,将得到的表征向量与黄金参考进行逐元素相减、相乘等操作以增强表示,获取差异特征,并将差异特征融入机器译文自动评价模型中以指导译文自动评价。在WMT’19译文自动评价数据集上与现有模型进行对比实验,结果表明融合XLM词语表示的神经机器译文自动评价方法在句子级和系统级任务上均显著提高了机器翻译自动评价与人工评价之间的相关性。
1 相关工作
在基于静态词向量的神经机器译文自动评价中,Boxing和Hongyu[13]使用Word2Vec[17]静态词向量表征机器译文和人工参考译文中的词语,并通过启发式的方法计算两者在词级别目标语言语义空间中的相似度;Gupta等人[18]提出利用树结构长短时记忆网络(Tree-LSTM)将机器译文和人工参考译文的词级别Glove静态词向量表征编码为句子级别表征,并以两者句子表征的积与差逐元素操作的结果作为前馈神经网络的输入计算译文的质量。
近年来,BERT[19]、GPT[20]等使用大规模数据进行训练的预训练语言模型被相继提出,使得直接利用句子向量进行机器译文自动评价的方法成为可能。RUSE[21]使用预训练的InferSent[22]、Quick-Thought[23]以及Universal Sentence Encoder[24]作为编码器获取句子向量,再通过多层感知机回归器预测机器译文质量。BERT regressor[25]则使用更先进的预训练语言模型BERT[19]代替RUSE中的三种句子向量编码器,并与多层感知机回归器一起进行微调。Mathur等人[14]首先使用BERT提取的动态词向量,并将其输入Bi-LSTM模型中进一步学习机器译文和人工参考译文的句子向量,最后将两者间的交互程度用于机器译文质量评价。然而机器翻译是一项开放式任务,对于同一个源语言句子可能存在多个不同的正确翻译。这些方法使用的单一人工参考译文仅能代表一种可能的翻译,不能准确评价所有正确的候选译文。Qin[26]和Fomicheva等人[27]通过引入多个参考译文来缓解这个问题,然而获取多个参考译文需要大量的人力。由于源语言句子与参考译文在语义上是等价的,Takahashi等人[28]提出通过引入源语言句子作为伪参考的方法,Luo等人[29]使用译文质量估计向量将源端信息引入模型。
与上述方法不同,本文使用跨语种预训练语言模型XLM[15]获取源语言句子、机器译文和人工参考译文两两之间的深度语义信息,结合注意力机制提取它们的差异特征,并将得到的差异特征融入机器译文自动评价中,进一步提高了机器翻译自动评价方法与人工评价方法之间的相关性。
2 背景知识
2.1 跨语种预训练语言模型
近年来,使用大型语料库进行自监督学习的预训练语言模型,如GPT[20]和BERT[19]等,在一些自然语言理解和生成任务上取得了显著性突破。然而,这些模型仅在单语语料上进行自监督训练,使得在不同语言任务上不仅需要进行多次训练,而且无法获得跨语言的信息。XLM[15]在BERT上进行改进: 使用字节对编码[30]将子词编码独立于语言;加入语言嵌入层;在多语言平行语料库上使用翻译语言模型(Translation Language Modeling, TLM)进行预训练。在XNLI跨语言分类任务[31]上,XLM取得了比多语言BERT(multilingual BERT, mBERT)[19]更好的性能。
2.2 引入源端信息的机器译文自动评价方法
语境词向量方法将词语映射到一个语义空间中,具有相近含义的词语在这个空间中会获得较高的相似度。Mathur[14]等人从“译文评价是计算机器译文和人工参考译文之间的相似度”的观点出发,将语境词向量空间中机器译文和人工参考译文之间的交互程度用于反映机器译文的质量。Luo等人[29]通过引入译文质量估计向量的方法将源端信息融入Mathur等人[14]的模型中。


将长度为lr的人工参考译文r和长度为lt的机器译文t作为模型的输入,使用Mathur[14]等人的(Bi-LSTM+attention)BERT和(ESIM)BERT分别得到matt和mesim,作为人工参考译文和机器译文的相互表示。Luo等人[29]提出的(Bi-LSTM+attention)BERT+QE和(ESIM)BERT+QE方法分别将matt、mesim与vqe拼接后得到的向量输入到前馈神经网络中,以计算译文质量的得分。相比没有引入源端信息的(Bi-LSTM+attention)BERT和(ESIM)BERT[14]方法,(Bi-LSTM+attention)BERT+QE和(ESIM)BERT+QE[29]方法在WMT’19译文自动评价任务数据集上与人工评分的相关性更高,证明了源端信息在译文自动评价任务中的有效性。
3 融合XLM词语表示的神经机器译文自动评价
3.1 注意力层
预训练语言模型最后一层中首个位置的输出向量通常作为下游任务的输入。然而,之前的研究[33]表明,预训练语言模型编码器的每一层涵盖不同的语言学特征: 底层关注词法信息,中间层关注句法信息,顶层关注语义信息。对于机器译文自动评价任务,各种语言学特征都是评价机器译文质量的重要信息,Zhang等人[34]研究表明仅使用最后一层通常会导致机器译文自动评价模型性能下降。此外,如果仅使用跨语种预训练语言模型首个位置的输出向量,在一定程度上容易丢失其他位置输出向量所包含的跨语言信息。
为了解决这两个问题,本文在跨语种预训练语言模型XLM纵向上使用分层注意力机制[16]以融合各层次语言学特征,并在横向上使用内部注意力机制将首位置的输出向量与所有位置的平均向量进行加权求和,以获取包含各层次语言学特征的深度语义信息。
本文将源语言句子src、机器译文mt和人工参考译文ref两两拼接组成三组句子对分别输入到XLM模型中: “src+ref”和“src+mt”表示由源语言到目标语言的句子对,“ref+mt”表示由同一个源语言句子产生的两个目标语言句子的组合。以长度为lsrc+mt的句子对“src+mt”为例,注意力层结构如图1所示。
将XLM每一层的隐藏层向量作为XLM的输出,通过分层注意力机制对这些隐藏层向量含有的各种语言学特征进行融合,得到exj,如式(4)所示。
(4)

其中,βsrc+mt和γsrc+mt为可学习的权重参数。“src+ref”和“ref+mt”所对应的句子对向量计算过程与“src+mt”类似,分别得到ssrc+ref和sref+mt。
将通过注意力层得到的三个句子对表征向量ssrc+mt、ssrc+ref和sref+mt进行拼接,以获取跨语言特征空间中同语种和不同语种下的表征信息,并考虑同语义时不同语种间的差异。最后,对ssrc+mt和ssrc+ref之间逐元素相减、相乘以突出ssrc+mt与黄金参考ssrc+ref之间线性与非线性的差异,如式(7)所示。
(7)
本文将edv称为差异向量,符号“;”表示向量的拼接操作。
3.2 模型总体架构
为了提高自动评价方法的效果,本文把提取的差异向量融入前人提出的(Bi-LSTM+attention)BERT+QE和(ESIM)BERT+QE模型中,模型整体结构如图2所示。图左边由UNQE模型[32]和Bi-LSTM网络提取出源语言句子和机器译文的词语级别质量向量,再通过池化层将其处理为句子级别质量向量。图右边通过(Bi-LSTM+attention)BERT或(ESIM)BERT模型[14]提取交互表示的增强向量。图中间部分使用跨语种预训练语言模型XLM[15]作为特征提取器,将“src+ref”、“src+mt”和“ref+mt”分别映射到跨语言特征空间中,通过分层注意力和内部注意力获取跨语言信息并进行增强表示。最后将三个部分得到的向量进行融合,并通过前馈神经网络得到机器译文的质量分数。

图2 融合XLM词语表示的神经机器译文自动评价方法模型总体结构
由式(1)~式(3)可知模型的左边部分输出为句子级别的译文质量向量vqe[29,32]。模型右边的输出为matt或mesim,具体细节见文献[14]。最后将vqe、edv和matt或mesim拼接得到的向量输入到前馈神经网络中,以预测译文质量分数,如式(8)、式(9)所示。
(8)
或
其中,参数w,W,b,b′均为前馈神经网络中可学习的权重。
(11)
其中,M表示训练集包含的样本数量。
4 实验
4.1 实验设置
为了验证融合XLM词语表示的神经机器译文自动评价方法的有效性,本文在WMT’19 Metrics Task[35]的德英、中英和英中语言对的语料库上进行实验。表1展示了每种语言对的统计数据。

表1 WMT’19 Metrics task德英、中英和英中任务的测试集数据统计
对于德英语言对,本文使用WMT’15-17 Metrics task[36-38]德英语言对的句子级别任务数据集进行训练,其中训练集和开发集比例为9:1。由于WMT Metrics task 在中英和英中语言对的训练集样本数量过少,本文采用Luo等人[29]的方法: 使用CWMT’18翻译质量评估在中英和英中语言对的语料用于模型训练,并将该语料库中的人工后编辑率(HTER)处理为译文人工评分(1-HTER)。中英和英中任务完全按照CWMT’18翻译质量评估数据集给定的训练集和开发集进行训练,表2展示了每种语言对的训练集和开发集统计数据。

表2 德英、中英和英中训练集、开发集数据统计
本文将BLEU[3]、chrF[10]、BEER[39]、仅使用跨语言模型的hyp+src/hyp+ref和hyp+src+ref方法[28]等作为基线方法,并将本文提出的方法与Mathur等人[14]的方法以及Luo等人[29]的方法进行比较。遵循WMT’19 Metrics Task[35]中官方做法: 使用肯德尔相关系数评价模型在句子级别上与人工评分的相关性,使用皮尔森相关系数评价模型在系统级别上与人工评分的相关性。
本文使用XLM-15[15]作为跨语言特征提取器,隐藏层向量维度大小为1 024。UNQE输出的译文质量向量维度在德英任务中为500,在中英和英中任务上为700。模型中包含的Bi-LSTM隐藏层向量维度大小均为300。(Bi-LSTM+attention)BERT和(ESIM)BERT[14]均使用“bert-base-uncased”提取英文预训练词向量、“bert-base-chinese” 提取中文预训练词向量。本文模型使用Adam优化器优化模型参数,初始学习率为0.000 4。
4.2 实验结果
表3展示了在WMT’19 Metrics Task的德英、中英和英中任务上各种自动评价方法与人工评价的句子级别相关性。本文提出的融合XLM词语表示的神经机器译文自动评价方法“(Bi-LSTM+attention)BERT+QE+DV”和“(ESIM)BERT+QE+DV”在三个语言对上与人工评分的句子级别相关性均远超过UNQE、sentBLEU等基线模型。仅使用跨语言模型的hyp+src/hyp+ref和hyp+src+ref方法[28]也具有一定的竞争性。“(ESIM)BERT+QE+DV”相比Luo等人[29]未融合XLM词语表示的方法“(ESIM)BERT+QE” 在德英、中英以及英中任务上分别提升了38.9%、3.2%和0.6%;“(Bi-LSTM+attention)BERT+QE+DV”相比“(Bi-LSTM+attention)BERT+QE”在德英、中英以及英中任务上分别提升了26.3%、3.4% 和1.7%。这表明通过融合XLM词语表示的方法可以有效提升机器译文自动评价与人工评价之间的句子级别相关性。

表3 在WMT’19 Metrics Task的德英、中英和英中任务上自动评价与人工评价的句子级别相关性对比实验
表4展示了在WMT’19 Metrics Task的德英、中英和英中任务上各种自动评价方法与人工评价的系统级别相关性。本文提出的融合XLM词语表示的神经机器译文自动评价方法“(Bi-LSTM+Attention)BERT+QE+DV”和“(ESIM)BERT+QE+DV”在三个语言对上与人工评分的系统级别相关性超过了所有基线模型。同时,“(ESIM)BERT+QE+DV”在所有语言对上均高于对应的Luo等人[29]未融合XLM词语表示的方法“(ESIM)BERT+QE”,在德英、中英以及英中任务上与人工评价之间的系统级别相关性分别提升了1.7%、0.8%和0.3%;“(Bi-LSTM+Attention)BERT+QE+DV” 相比(Bi-LSTM+Attention)BERT+QE”,在中英任务上保持一致,在英中任务上提升了0.8%。这表明通过融合XLM词语表示的神经机器译文自动评价方法有助于提升机器译文自动评价与人工评价之间的系统级别相关性。
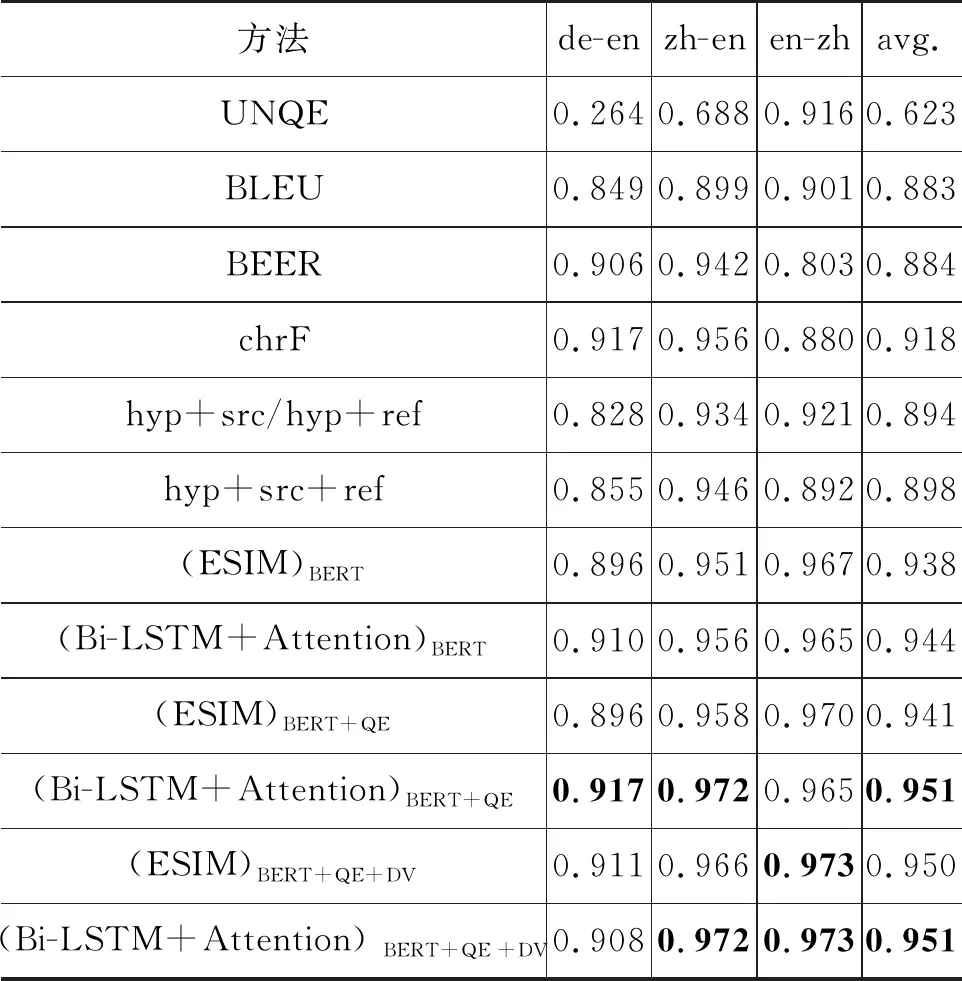
表4 在WMT’19 Metrics Task的德英、英中和中英任务上自动评价与人工评价的系统级别相关性对比实验
4.3 消融实验
本节设计了一系列消融实验以进一步分析本文方法中所引入的两种注意力机制的有效性。消融实验结果在表5和表6中展示。表中“w/o L”、“w/o I”以及“w/o L&I”分别表示去除分层注意力、内部注意力以及同时去除这两种注意力后的模型。由表5和表6中所展示的实验结果可以发现,分层注意力机制的引入对模型性能的影响最大,而内部注意力机制对模型性能影响较弱,并且同时引入两种注意力机制后模型性能达到最优,证明了本文所引入的注意力机制的有效性。另外,通过对表中结果的观察发现,在不使用分层注意力机制的情况下单独引入内部注意力机制反而会导致性能降低,这表明模型仅通过XLM最后一层的输出可能无法充分获取各个位置的跨语言信息。

表5 在WMT’19 Metrics Task的德英、中英和英中任务上自动评价与人工评价的句子级别相关性消融实验

表6 在WMT’19 Metrics Task的德英、英中和中英任务上自动评价与人工评价的系统级别相关性消融实验
4.4 实验分析
为了定性说明本文所提出方法的效果,在中英语言对开发集中抽取了一个实例以分析融合XLM词语表示的神经机器译文自动评价方法的特点。
在如表7所示的实例中,机器译文将源语言句子中“让权力在阳光下运行”翻译成“let power run in the sunshine”。但通过对比源语言句子和人工参考译文“power is exercised in a transparent manner”,可以发现对于相同语义,不同语种间的表达存在一定的差异,而机器译文并没有表达出源语言句子的内在含义。相比未融合XLM词语表示的(Bi-LSTM+Attention)BERT+QE和(ESIM)BERT+QE方法,本文所提方法的打分均更接近于人工评分。通过这个实例表明,融合XLM词语表示的神经机器译文自动评价方法能够充分考虑源语言句子、人工参考译文以及机器译文之间的差异信息,更好地评价机器译文质量。

表7 不同自动评价方法对机器译文打分实例
5 结论
本文提出融合XLM词语表示的神经机器译文自动评价方法。与现有方法相比,融合XLM词语表示的神经机器译文自动评价方法能够充分考虑源语言句子、人工参考译文以及机器译文之间的差异,与人工评价具有更高的相关性。未来工作中,我们将尝试在更深层次上挖掘源语言句子、人工参考译文以及机器译文之间的语义差异,进一步提高译文自动评价的性能。
