基于混合自注意力机制的神经机器翻译
2023-12-06宋恺涛陆建峰
宋恺涛,陆建峰
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
0 引言
得益于序列化模型的快速发展,神经机器翻译(Neural Machine Translation, NMT)[1-3]在近年来见证了飞速的发展。循环神经网络(Recurrent Neural Network, RNN)[4]最早被应用于构建神经机器翻译模型并取得显著效果。然而循环神经网络必须依赖先前的隐状态,这样的时序结构导致循环神经网络不能够支持序列并行计算。为了解决这类问题,科学家们开始研究神经机器翻译中的并行化结构。这其中,一些工作尝试应用卷积神经网络[5](Convolutional Neural Network, CNN)到神经机器翻译中,并取得了不错的效果。
注意力机制是神经机器翻译中一个重要的组件。早期的注意力机制被用来构建源语言端和目标语言端的对齐模块,用于指导目标端的单词应当被对齐到源语言端的哪个单词。得益于注意力机制的成功,深度自注意力网络(Transformer)[6]被提出用于解决机器翻译问题。深度自注意力网络是由自注意力网络(Self-Attention Network)完全构成的编码器-解码器结构,其在编码器端或者解码器端采用一种多头注意力机制来提取语义特征。除此之外,自注意力也能够支持并行化计算,而且相比于循环神经网络和卷积神经网络,由于自注意力网络能够捕获到任意两个单词的关系,因此也具备了对长依赖语义的建模能力。
然而,这种自注意力机制依然存在一些瓶颈。通常而言,注意力机制以加权的方式来计算每个位置之间的关系。这就导致了自注意力机制网络缺少对时序信息的建模,而这个信息在序列建模中则非常重要。如图1所示,单词 “值” 在句子 “两支笔值五元” 和 “五支笔值两元” 中能够收集到相同的信息,但是其收集的上下文语义却并不相同。而卷积神经网络和循环神经网络通过线性变化建模则可以避免这个问题,因此这也是深度自注意力网络必须依赖位置编码的原因。由此可见,自注意力机制对位置编码相当敏感,而如何让模型本身能够直接具备感知位置的能力也成为大家关注的一个重点。在过去的工作中,Peter等人针对注意力机制中的绝对编码表达位置能力不足的问题[7],提出了相对位置编码的方案,但依然不能增强注意力模块自身对位置的编码。Shen等人针对语言理解的任务设计了双向注意力[8],但其每个分支都采用独立参数,使得模型过大,而且也不能获取局部语义。

图1 注意力机制在不同顺序下的依赖捕获
基于目前的研究现状,本文希望自注意力机制能够像卷积神经网络那样捕获局部语义信息或者像循环神经网络那样捕获前后向语义信息。例如,在图1中,“两”和“五”分别是“笔”和“元”的修饰符,但标准的自注意力网络却不能够捕获这种相对关系。因此,本文认为,如果自注意力网络能够在提取出全局语义之外,还能够提取和融合局部语义或者前后向语义,那么模型的性能也能够得到提升。而且这种多层次的语义信息也能够提供给模型一种多维度的理解。
为了解决上述问题,本文提出了一种新型的自注意力结构。该结构能够同时提取全局语义、局部语义以及前后向语义。每个语义信息,仅仅需要在自注意力机制的点积操作之后添加额外分支,并通过设计不同的注意力掩码即可实现,而我们也设计了一种压缩门机制来融合不同的语义信息,并且不需要添加太多额外参数。该方法被命名为基于混合自注意力机制网络(Hybrid Self-Attention Network)。上述方法在三个最常用的机器翻译数据集上进行了验证。实验结果表明,我们的方法相对于经典的Transformer模型能够获得显著的性能提升。综上所述,本文贡献总结如下:
(1) 提出了一种新型的自注意力网络,能够同时提取全局语义、局部语义和前后向语义信息;
(2) 通过详细的消融实验分析各个模块对位置信息建模的重要度;
(3) 实验结果表明,本文提出的模型能够取得比多个基准模型更好的翻译性能,并且具有更好的感知位置的能力。
1 相关工作
本节介绍本文所需要的相关知识。主要包括: ①基于编码器-解码器的神经机器翻译; ②深度自注意力网络。
1.1 基于编码器-解码器的神经机器翻译
给定源语言端的输入序列x={x1,…,xn},以及目标语言端的输入序列y={y1,…,ym},其中,xi和yj分别表示源语言端的第i个单词和目标语言端的第j个单词,n和m分别表示序列x和y的长度。神经机器翻译模型的主要目标是最大化最大似然估计函数P(y|x)。其中,P(y|x)计算如式(1)所示。
(1)
其中,θ表示模型参数,而生成下一个单词yt的概率如式(2)所示。
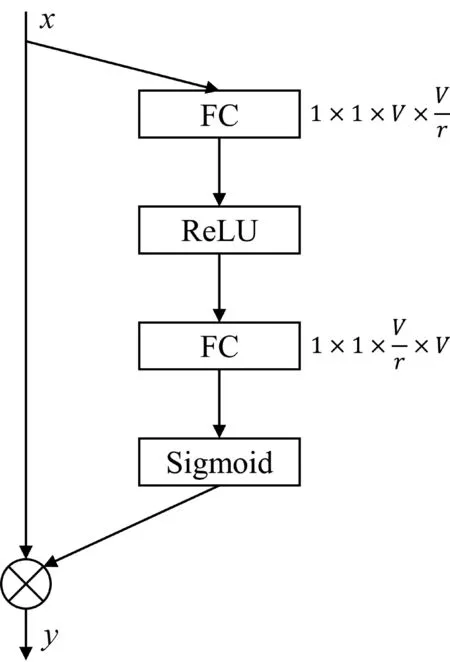
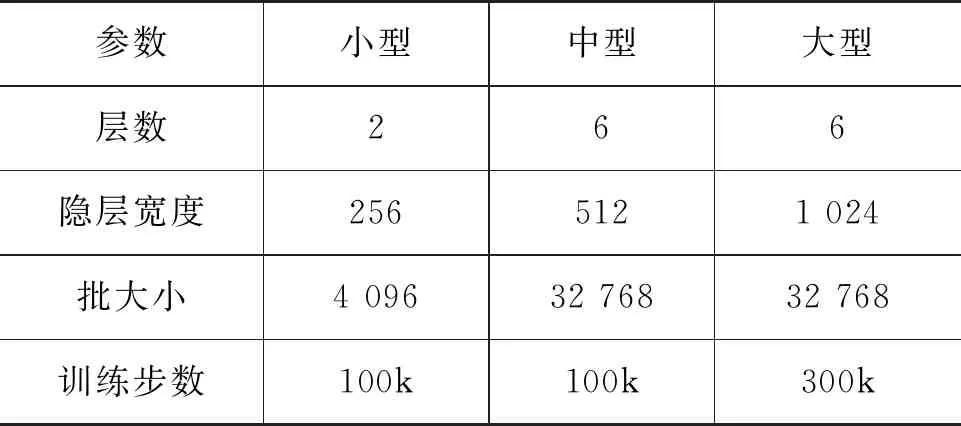
P(yt|yt,x;θ)=exp{f(y (2) 其中,ct表示用于生成第t个单词的特征向量,f(·)是解码器的模型函数。在本文的方法中,f(·)指自注意力网络。 注意力机制通常被用于计算源语言单词和目标端单词的相似度。通常情况下,计算注意力机制的对齐系数有多个选择,如点积、拼接等方式[9]。基于深度自注意力网络的经验,本文也采用了点积的方式,其形式采用了查询-键值(Query-Key-Value)的方式: Attention(q,k,v)=softmax(qkT)v (3) 其中,Attention(·,·,·)对应注意力机制的函数,q、k、v分别表示输入的查询、键、值。 深度自注意力网络(Transformer)由自注意力网络层搭建而成。其中,每一层由一个多头注意力子网络和一个前向反馈子网络组成。同时,为了能够支持深层网络,深度自注意力网络同时还在每个子网络后增加了层归一化(Layer Normalization)[10]和残差连接[11]。而为了能够让网络具备识别位置信息的能力,深度自注意力网络又在词嵌入上添加了位置嵌入P={p1,…,pn} 。多头注意力子网络则构建在尺度点积注意力机制上。每个多头注意力由h个注意力头构成,且每个注意力头都会接收一个对应的查询-键值输入,并用式(3)来计算特征。最终,每个注意力头输出的特征会拼接起来作为下一层网络的输入,并用一个全连接层来融合特征。这样的结构能够允许模型从不同的注意力头中捕获单独的关系。除此之外,在解码器端,还会添加前向掩码来确保前面的单词不会捕获到后面单词的语义信息。 而与多头注意力子网络相连的是前向反馈子网络。每个位置的特征都会经过该子网络来进一步增强语义。该网络由两个全连接层构成,中间用一个ReLU激活层[4]连接。其形式如式(4)所示。 FFN(x)=max(0,xW1+b1)W2+b2 (4) 其中,W1和W2是权重参数,b1和b2是偏置参数。 自注意力网络是一种可以从全局内容中学习语义的模型结构。在本文中,我们针对注意力网络设计了两种特别的注意力掩码。每个注意力掩码,都通过一个额外的分支来分别计算不同级别的语义特征,我们将这些分支网络分别称为“双向自注意力”和“局部自注意力”,并采用了一种压缩门机制来混合不同的分支网络以构成混合自注意力。图2显示了模型的结构,我们将每个分支的特征送入融合函数中做线性变化。多头查询、多头键、多头值分别表示多头注意力机制的查询、键、值。 图2 多头混合注意力机制网络的结构 双向自注意力是一种用于捕获方向信息和时序信息的掩码注意力模块。标准的自注意力网络以点积的形式能够学习到一个单词到所有单词的依赖。其中,点积计算出来的对齐系数是注意力机制中最为关键的部分,因为这个系数包含了任意两个位置的关系。而我们注意到自注意力机制中的对齐矩阵是一个标准方阵,即行数和列数相等。因此,本文设计了一个掩码矩阵来捕获方向性依赖,如式(5)所示。 DiSAN(q,k,v)=Softmax(qkT+M)v (5) 其中,M在这里指前向掩码Mfw或者后向掩码Mbw,并采用DiSAN(·,·,·)来表示双向自注意力的模型函数。其中前向掩码Mfw定义如式(6)所示。 (6) 其中,-∞表示负无穷大。当两个位置之间的对齐系数等于负无穷大时,就等价于没有关联。对于前向掩码,我们允许位置i只能看到在其之前的位置j。而后向掩码Mbw定义如式(7)所示。 (7) 后向掩码用于控制单词只能看到后面的位置,也就是位置i只能看到其后面的位置j。得益于这样的设计,双向自注意力就能够在不依赖位置编码的情况下捕获到时序的语义和更加深层的内容特征。我们的双向自注意力仅仅适用于编码器端,因为解码器本身已被限制为前向信息。 标准的自注意力通常着重于捕获全局语义,而忽略了局部语义。在上节提到过,注意力机制的对齐矩阵是一个标准的n×n关系矩阵。相比较于自注意力机制,卷积神经网络通常在一个局部窗口内提取语义。受启发于卷积神经网络的特性,我们为自注意力机制设计了一个对称矩阵来捕获局部语义,其中k定义为局部自注意力的窗口半径。与卷积神经网络相似,我们的局部自注意力机制也能通过一个窗口看到2k+1个元素。局部自注意力的具体定义如式(8)所示。 LSAN(q,k,v)=Softmax(qkT+M)v (8) 其中,掩码M也分为针对编码器的掩码Me和解码器的掩码Md。其中用于编码器的掩码Me是: (9) 而解码器端的掩码Md是 (10) 其中,对于位置i的单词,局部自注意力允许其在编码器端可以看到两边距离不超过k的单词。而在解码器端只允许看到在位置i之前且距离不超过k的单词。通过这样的设计,注意力机制也能捕获到局部语义。在实验中,我们能够从{1,2,5}中选出k的值进行对比。 基于本文所设计的混合自注意力机制网络,我们可以得到全局语义、前向语义、后向语义以及局部语义等分支。为了能够将提取的特征用于最后的预测,还需要将各个分支的语义特征进行融合。本文采用的融合方式如式(11)所示。 (11) 我们用Mi来表示不同分支网络的掩码矩阵,l表示分支数量,f(·)表示融合函数。为了能够探索融合信息的方式,我们选择了三种方式进行研究,分别是相加、拼接以及门控相加。其数学表达如式(12)所示。 (12) 其中,H(·)是一个全连接层用于降维,SG(·)是一个压缩门函数。压缩门包括一个压缩模块和一个门控模块,从而确保其输出值的范围在0到1之间。压缩模块由两个全连接层组成,中间是一个ReLU函数。第一个全连接层用来降低维度,而第二个全连接层用来确保维度一致。而门控模块则是一个sigmoid激活函数。因此,压缩门可以表示如式(13)所示。 SG(x)=σ(f2(ReLU(f1(x))) (13) 图3阐述了压缩门的设计思路,而这样的设计与直接的相加或者拼接相比,拥有以下两个优点: ①节省参数; ②增强非线性。 图3 用于融合各个注意力分支的压缩门 本节详细介绍实验使用的数据集、实验设置、实验结果和分析实验。 我们选用了一个小规模数据集以及两个大规模数据集来验证模型性能,分别是IWSLT14德英、WMT14 英德和WMT17 中英。表1中给出每个数据集的统计量,其中各个数据集的处理细节如下。 表1 数据集规模统计 (1) IWSLT14 德英数据集是从TED以及TEDx中筛选出来的。经过清洗后,我们保留160k的句子作为训练集以及7k的句子作为验证集。我们合并了dev2010、tst2010、tst2011、tst2012作为测试集。为了能够避免语料处理后的词典过大,我们将整个语料以子词的形式进行处理,最终的词典大小为32 000。 (2) WMT14 英德数据集由三个公开数据集组成。语料的训练集包含4. 5M的句子对,其中newtest2013和newtest2014分别选为验证集和测试集。我们同样将语料处理成子词的形式,处理之后的词典大小为32 000。 (3) WMT17中英数据集由三个公开数据集组成。处理之后的语料包含18M个句子对,newsdev2017和newstest2017分别被选为验证集和测试集。由于中文和英文相差较大,因此每个语料分别采用子词进行处理,处理之后每个语种的词典大小为40 000。 对于IWSLT14 德英数据集,我们使用一个小型(Small)模型来验证性能;对于WMT14 英德数据集,我们选用一个中等模型(Base)和一个大型模型(Large)来验证;对于WMT17 中英数据集,则选用大型模型来验证。表2详细介绍每种模型的参数设置。 表2 模型参数设置 所有的实验结果都采用BLEU[12]作为评估指标。我们首先分析了本文方法与其他基准模型的对比。表3和表4分别列举本文方法在WMT14英德和WMT17中英数据集上的实验结果。我们还列举了多个其他类型的系统用于对比,包括基于循环神经网络以及卷积神经网络的基准模型。出于公平比较,本文还与标准的Transformer网络进行了对比。从表3和表4可以看出,Transformer已经取得比其他架构网络更好的性能。而在此基础上,我们的中等模型和大型模型在WMT14英德上依然能够分别取得0.6和0.4个百分点的提升。在WMT17中英数据集上,也可以看到明显的性能提升。这一系列的提升也表明,本文方法能够在多个不同尺度的模型上都能够取得更好的性能,而模型参数仅增加不超过1%。另外,我们还对比了利用显式的相对位置编码[7]来增强位置语义的方法,然而依然能够取得可比的实验结果。需要注意的是,本文方法是在模型层面来隐式增强位置语义,因而可以与相对位置编码完美兼容。 表3 WMT14 英德数据集 表4 WMT17 中英数据集 为了进一步分析不同注意力分支对模型的影响,我们在IWSLT14德英数据集上进行了一系列的消融实验。除此之外,为了能够验证本文方法具备更优越的提取时序信息的能力,我们还做了一组不包含位置编码输入的实验。表5包含了所有的实验结果分析,其中,Lk表示窗口为k的局部注意力,“base”表示基准模型,“Δ”表示相对于基准模型的提升,“NoP”表示禁用位置编码。出于公平对比,每组实验都采用了门控和的特征融合方式。从表5可以发现: (1) 相比较于基准模型,实验组1~3和4~7可以取得最多0.65的BLEU提升。其中实验组1~3主要研究双向自注意力,实验组4~7主要研究局部自注意力。这些提升说明双向自注意力和局部自注意力能够帮助编码器获得收益。当对比基准模型以及实验组13~15,我们发现局部自注意力机制在解码器端只能够取得最多0.16的分数提升。因此,叠加过多的局部自注意力并不能给解码器端带来太多收益。 (2) 相比于基准模型,我们发现实验17和实验18几乎没有差异。两组实验都能够获得接近1个百分点左右的提升,这也说明在编码器端和解码器端叠加多个局部自注意力分支并不能带来更多的收益。 (3) 为了进一步说明本文方法能够有效建模位置信息,我们还做了不包含位置信息的对比实验组。可以发现,在不包含位置信息的实验中,通过添加额外的双向注意力或者局部注意力分支,我们的模型能够获得超过15个百分点以上的提升。这种现象也说明了位置信息对于Transformer的重要性。而通过将对比实验组1~3、4~7以及8~12和实验组13~16,我们发现编码器对位置信息更加敏感。这些现象也说明了位置信息对编码器学习更加重要。而解码器端受位置信息影响较弱,我们认为这是因为其等价于前向自注意力而具备一定的时序建模能力。而不包含位置信息的实验结果,也表明了本文的方法可以为模型隐式地对位置信息进行建模,并且位置信息也能够为模型带来收益,尤其在编码器端。 为了能够理解各种分支融合方式对模型性能的影响,我们还进行了多组实验来验证各种融合方式的影响,实验结果汇总在表6中,其中“Transformer”是基准模型,“+ (number)”表示相对于基准模型增加的参数量。为了能够体现每个分支在不同模型尺度下的鲁棒性,我们在各种模型设置上都做了实验。依据表6可以得出以下结论: 表6 多分支特征融合方法的实验结果 (1) 直接相加的方法不增加任何参数。但是由于缺少线性变化,使得模型对于相加之后的特征具有不适应性。因此,我们看到相加的方式在小型模型上提升0.8个百分点,在中型模型和大型模型上几乎不提升。 (2) 拼接等价于密集连接。因此,它通常需要一个全连接层来确保输出维度一致。更重要的是,拼接方式能够比相加的方式提供更好的适应性和可塑性,但拼接的方式却需要提供接近10%的额外参数。 (3) 门控和是本文推荐的一种连接方法。相比于其他方法,门控和具有更好的适应性,且取得了更好的成绩。而且,相比拼接的连接方式,门控和还拥有参数上的优势,只需要增加不到1%的参数。因此,本文选用了这种机制来做特征融合。 在这篇文章中,我们针对神经机器翻译提出了一个自注意力机制网络的变体——基于混合自注意力机制的网络。为了解决自注意力机制不能有效提取时序语义以及局部语义的问题,我们设计了多个不同注意力分支以提取不同层次的语义信息。本文的方法在仅仅增加少量参数的情况下,能够取得更加优异的性能。除此之外,设计了一个压缩门网络来融合各个分支的相关性。在多个数据集上的实验结果表明,本文方法能够取得更好的结果。在下个阶段,我们将继续研究自注意力的结构和可解释性,并将该模型扩展到更多应用上。1.2 深度自注意力网络
2 方法
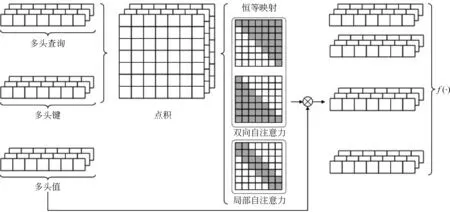
2.1 双向自注意力

2.2 局部自注意力
2.3 融合
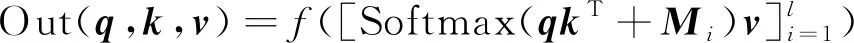
3 实验
3.1 数据集

3.2 模型设置
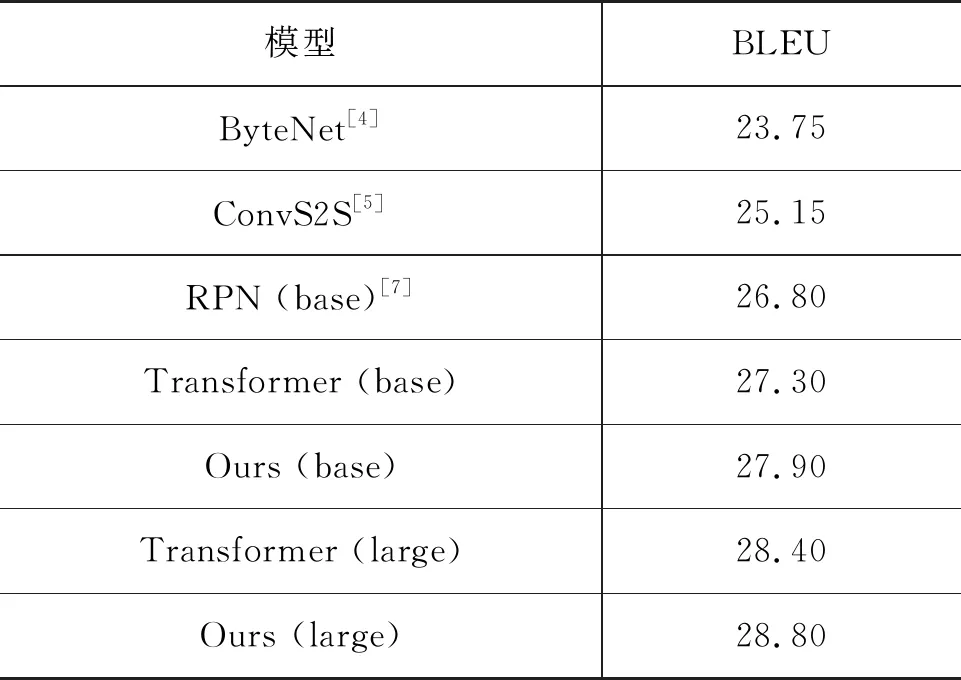
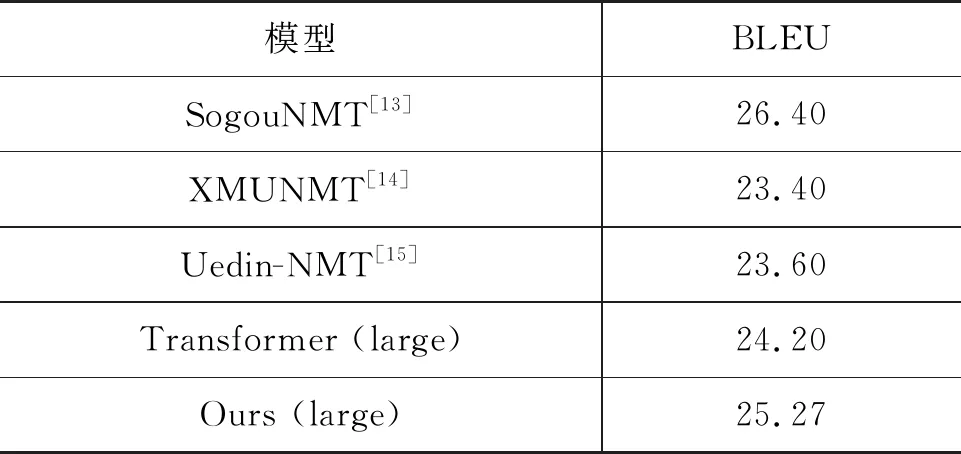
3.3 实验结果
3.4 消融实验
3.5 特征融合分析

4 总结
