基于Q-learning的多业务网络选择博弈策略
2023-12-04王军选
王军选,赵 县,王 颖
(1.西安邮电大学 陕西省信息通信网络及安全重点实验室,陕西 西安 710121;2.北京邮电大学 信息安全中心,中国 北京100876)
随着移动互联网的蓬勃发展,智能设备和移动应用的数量飞速增长,全球移动数据流量显著增加,预计到2026年全球移动数据数量相较于2021年将增长6倍以上[1]。学术界和工业界为第五代移动网络(5th Generation Mobile Networks,5G)提出了两种解决方案。第一种解决方案是通过改进物理层和介质访问控制(Medium Access Control,MAC)技术提高许可频谱利用效率,但当前可用频偏基本已被分配殆尽。第二种解决方案是将蜂窝通信的带宽扩展到现有的未许可频带[2]。由于WiFi接入点目前被运营商广泛部署,同时又具有高带宽、高移动性等特点,用WiFi对蜂窝网络中的数据进行分流可以解决授权频段拥挤的问题,因此很多网络选择研究将WiFi作为异构网络提供额外频谱资源的重要候选者[3]。
目前,在异构网络中网络选择解决方案的研究主要集中在为不同的用户提供满足偏好的同时访问高质量网络的机会[4]。解决接入网络选择的方法可以分为以网络为中心和以用户为中心两种。在以网络为中心的方法中[5-7],网络端决策通过集中控制器进行。集中控制器通过用户报告的本地信道条件,为用户分配最匹配的服务网络,这种方法要求系统中各种无线接入网络之间高度耦合。在以用户为中心的方法中[8-10],每个用户根据自己的偏好实现接入网络的垂直切换,而无需任何信令开销或不同接入网络之间的协调,因此以网络为中心算法的整体吞吐量优于以用户为中心的算法。由于以网络为中心的算法需要网络与用户协作,因而造成显著的通信开销。此外,不同的网络运营商很少有合作的动机。在以用户为中心的方法中,用户自主选择适合的网络,可以提供个性化服务。
5G采用以用户为中心的接入网架构,可以满足不同的通信需求[11]。文献[8]提出了一种智能网络接入策略,考虑了信道状态和网络服务质量(Quality of Service,QoS)要求,并根据用户访问请求执行网络选择。文献[9]提出了多用户深度强化学习方案以控制每个集群中用户之间的切换,首先集中控制器根据移动模式对用户进行聚类,再使用强化学习为相同群集的用户获得最佳切换控制器。在随机环境中,智能体需要长时间搜索获得全局最优结果,这会导致收敛缓慢[10]。
针对以用户为中心的方法网络吞吐量低、收敛慢的问题,拟提出一种在5G异构网络场景下,基于Q学习(Q-learning)的多业务网络选择博弈(Multi-Service Network Selection Game based on Q-learning,QSNG)策略。该策略将通过模糊推理和综合属性评估得到的多业务网络效用函数作为Q-learning的奖励,以满足用户选网Qos偏好。同时,通过博弈算法预测Q-learning选网收益,从而避免用户访问负载较重的网络。为了验证QSNG策略的有效性,将其与基于Q-learning的网络辅助反馈(Reinforcement Learning with Network-Assisted Feedback,RLNF)策略与无线网络选择博弈(Radio Network Selection Games,RSG)策略进行比较。
1 系统模型
所提QSNG策略的框架采用两阶段决策过程,包括基于Q-learning的多业务网络选择(Multi-Service Network Selection based on Q-learning,QSNS)过程和网络选择博弈(Network Selection Game,NSG)两个过程。QSNG策略流程如图1所示。

图1 QSNG策略流程
QSNS针对异构网络中不同用户业务需求,利用模糊过程,得到与QoS相关的各属性权重与各属性效用函数。根据属性权重和属性效用函数计算网络QoS效用,将QoS效用与网络价格效用的线性组合作为Q-learning的奖励。同时,用户的状态为用户所连接网络的QoS和价格情况,动作为候选网络选择。用户做切换决策之前,首先判断此时策略是否产生更高选网收益,避免接入状况较差的网络。NSG采用了802 .11协议中分布协调功能的思想,通过二进制指数退避策略降低了多个用户并发性接入某一节点的概率,克服了现有技术中由于未考虑并发性接入导致用户体验差的问题。
在分析网络博弈中,根据MAC协议将吞吐量模型分为吞吐量-公平模型和比例-公平模型[12]两类。
模型1吞吐量-公平模型。用户M连接在网络k上获得的吞吐量取决于连接到相同网络的特定用户的集合,连接到同一网络的所有用户实现相同的吞吐量。用户M连接到网络k的吞吐量[12]可以表示为
(1)

模型2比例-公平模型。用户M连接到网络k上获得的吞吐量仅取决于共享相同网络的所有用户的总数nk,而不是特定的用户组合。用户M连接到网络k的吞吐量[12]可以表示为
(2)
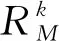
在高斯假设下,吞吐量均值等于实际吞吐量,标准差等于噪声值e和实际吞吐量的乘积。因此,用户M连接到网络k的瞬时吞吐量服从的概率分布为
(3)

将异构网络中的网络选择问题建模为非合作博弈,其中用户以分布式方式选择网络以增加其自身的吞吐量。因此,参与者是用户集合,策略是网络选择结果。
2 相关技术
2.1 模糊推理系统
为了降低模糊规则的复杂性,引入了并行模糊推理系统。对于用户的不同业务请求先得到用户对网络属性的偏好,再利用模糊逻辑量化用户的偏好得到网络属性的权重。在解模糊过程中,使用模糊评分法将模糊推理得到的模糊数转换为对应的明晰数。最后,计算出归一化属性权重,用于为特定用户业务计算不同网络QoS的效用。具体的模糊推理系统过程如图2所示。

图2 模糊推理系统过程
QoS效用函数的限制条件如下。
(4)
(5)
(6)
(7)
式中:U(Q)表示QoS效用函数;U(i)表示第i个QoS属性的效用函数;H表示QoS属性的总个数;xi表示函数U(i)的自变量。式(5)表明,QoS效用函数中每个决策属性的效用的单调性与相应的决策属性效用的单调性一致。
网络选择的决策属性包括QoS和价格,根据决策属性的效用函数,设计网络k的网络选择模型的表达式[13]为
Uk=ωQ·(Uk(b))ωb·(Uk(d))ωd·(Uk(p))ωp·(Uk(j))ωj+ωc·Uk(c)
(8)
式中:Uk(b)、Uk(d)、Uk(p)和Uk(j)分别表示第k个网络的带宽、时延、丢包率和抖动的效用函数;Uk(c)为第k个网络价格的效用函数;ωb、ωd、ωp和ωj分别表示通过模糊推理得到的网络业务对带宽、时延、丢包率和抖动的偏好权重,ωb+ωd+ωp+ωj=1;参数ωQ和ωc分别为QoS和价格的权重,并且ωQ+ωc=1。
2.2 智能网络博弈
在将Q-learning算法应用于网络选择前,需要将系统状态、动作和奖励等因素映射到实际的接入模型中,具体的映射过程如下。
1)t时刻用户i的状态表示为
(9)

2)t时刻用户i的动作是从服务列表中选择合适的服务网络,其由WiFi1、WiFi2、5G和长期演进(Long Term Evolution,LTE)等4个部分组成。
3)t时刻用户i的奖励表示为
(10)
式中,Uk(t)表示t时刻用户i选择网络k的基于业务类型的选网效用。

(11)

将网络选择问题建模成非合作网络选择博弈,利用NSG策略辅助Q-learning进行网络选择,提升Q-learning选网准确性,同时加快收敛速度,文献[12]证明了NSG策略可以收敛到纳什均衡。在任何特定时间内,当通过QSNS选择的网络吞吐量大于当前连接的网络,才进行切换。t+1时刻参与者i从网络v切换到网络w,定义预期的切换收益为
(12)

(13)
式中,λ为切换增益阈值,且λ≥1 。
为了提高策略准确性,期望吞吐量应接近可用吞吐量。但是,如果多个参与者同时选择相同的网络,则预期吞吐量和可用吞吐量实际值可能相差较大,这将导致不好的用户体验。考虑网络上的并发切换的数量,类似于802.11协议中分布式协调功能中的二进制指数退避,当参与者i发现网络发生并发切换,则将其并发性接入概率设置为
ρ=ρmi
(14)
式中:0<ρ<1;mi表示参与者i观察并记录的过去连续并发切换数量。在QSNG策略中,只有当切换后吞吐量提高并且满足并发性切换条件时,用户才会执行切换。
3 仿真分析
3.1 仿真设置
为了验证策略的性能和稳定性,采用仿真软件对所提策略进行仿真。仿真环境基于由3种网络组成的异构网络区域,设置40个用户设备(User Equipment,UE)随机分布在网络覆盖区域,具体的仿真环境如图3所示。
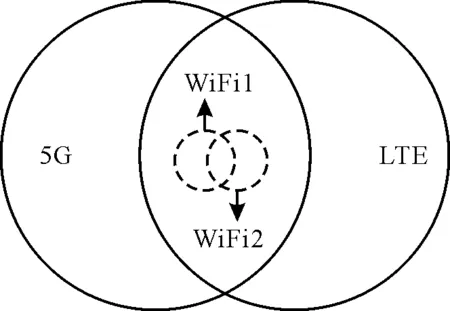
图3 异构网络仿真环境


表1 主要仿真参数
为了比较不同网络选择策略的公平性,采用被广泛应用的Jain公平性指数[15],其表达式为
(15)
式中,xi是用户i的平均吞吐量。根据定义可知,该值越大,说明系统公平性越高。
为了验证所提策略的性能,将所提策略与以下两个策略相比。
1)RLNF策略。使用网络辅助信息改善网络选择的性能,该策略收敛于相关均衡,仿真时使用Q-learning模拟强化学习算法。
2)RSG策略。所有网络都将其业务量信息推送给所有用户。在每次迭代时,用户选择提供最高吞吐量的网络,该策略收敛于纳什均衡。
3.2 NSG策略有效性
通过任选UE3和UE26两个用户验证NSG策略的有效性。两个用户的网络选择结果具体对比情况如图4所示。

图4 两个用户的网络选择结果
由图4(a)和图4(b)可以看出,UE3频繁地在4个网络之间切换,而UE26没有发生显著的频繁切换。由图4(a)和图4(c)可以看出,当使用了NSG策略之后,UE3的频繁切换明显减少,这是由于通过预先评估网络收益,与其他网络相比,5G可以提供更稳健的服务。由图4(b)和图4(d)可以发现,利用NSG策略可以减少正常用户UE26接入非最合适网络的数量并且加速收敛速率。
3.3 业务类型对网络选择的影响
以会话业务为例,当只有40个用户时,近37%的用户选择访问5G。随着网络负载的增加,信道资源可能会被耗尽,策略只能满足最低QoS的要求。因此,访问5G用户比例逐渐降低,4个业务的网络分配比率如图5所示。

图5 4个业务网络分配比率对比结果
由于Q学习的随机探索和网络博弈的影响,当用户数量增加时,图5(c)中连接到WiFi1的用户并不总是减少。由于后台业务的用户对QoS属性的要求较低,因此用户倾向于选择实惠的网络,如图5(d)所示,用户刚开始就倾向于访问WiFi1。
总体来说,当用户数量较少的时候,系统信道资源足够多,大部分用户都可以根据自己的偏好选择适合自己业务的网络。
3.4 与现有策略的性能比较
为了验证QSNG策略吞吐量,将所提QSNG策略与RLNF策略、RSG策略等策略的系统吞吐量进行对比,具体如图6所示。由图6可以看出,在RLNF策略中,用户使用网络辅助反馈更准确地估算其收益函数,由于该策略用户切换次数很多,因而损失了部分吞吐量。RSG策略能够准确建模每个用户的决定对其他用户的影响。QSNG策略和RSG策略类似,不同之处在于,QSNG策略可以根据实际传输情况和用户业务需求动态地调整信道资源,因此可以获得较高的吞吐量。由于引入了Q-leaning算法,通过系统学习,当前信道资源被合理地占用,从而减少了信道冲突,提高了信道利用率。

图6 3种策略的系统吞吐量对比结果
通过Jains指数将3种策略的公平性随着迭代次数增加的变化趋势进行对比,从而验证QSNG策略的公平性。Jains指数对比情况具体如图7所示。
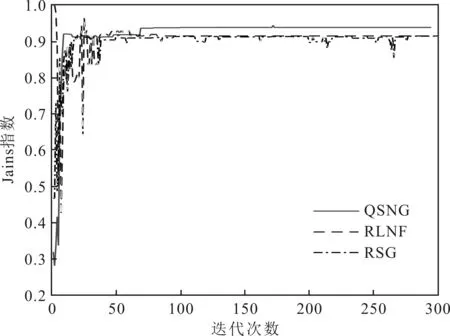
图7 Jains指数对比结果
由图7可以看出,由于上述3种策略都收敛于相应的博弈均衡状态,因此都获得了非常好的公平性指数。不同之处在于RLNF策略刚开始公平性波动很大,而RSG策略收敛较慢。QSNG策略刚开始就获得了很好的公平性,而且公平性相比于其他两种策略来说一直保持在很好的状态。
对于QSNG策略的稳定性,可以将所提QSNG策略和其他两种对比策略的切换次数和迭代次数进行对比,3种策略的切换次数对比情况如图8所示。

图8 3种策略的切换次数对比结果
由图8(a)可以看出,3种策略中的用户都尝试探索周围环境以达到最终的选网均衡状态,每次迭代用户切换次数越来越少。图8(b)显示的切换次数远远低于对比策略,而且策略收敛速度最快。在QSNG策略中,用户可以根据QoS效用和价格函数确定适合其业务的网络。因此,用户可根据预测指标访问更稳定的网络。此外,用户可以在执行策略之前预测网络选择收益,能够避免切换到重负载网络。QSNG策略还利用二进制指数退避策略显著减少了并发切换,避免网络拥塞,从而提高了切换增益和服务质量。
4 结语
针对5G异构网络中多业务网络选择的问题,提出了一种QSNG策略。在QSNG策略中,通过模糊过程获得各种业务对网络QoS的量化值。然后,将网络QoS选择模型与价格决策属性结合起来以评估备选接入网络。QSNG策略中引入了强化学习和博弈算法,不仅考虑了服务质量而且还考虑了负载选择网络,目的是在满足用户QoS偏好的同时最大化平均系统吞吐量。此外,由于博弈算法在选择网络之前已经预估了吞吐量情况,因此可以提升强化学习选网准确性,进而加快强化学习收敛速度。QSNG策略还考虑了切换效果和并发性,可以减少不必要的信令开销并保证切换效果。实验结果表明,通过使用所提的QSNG策略,在大多数情况下可以通过合理数量的迭代过程实现全局优化。
