基于深度学习的多源降水数据融合方法及其应用
2023-12-02覃晓东,朱仟,周东旸,丁洁
覃 晓 东,朱 仟,周 东 旸,丁 洁
(东南大学 土木工程学院,江苏 南京 211189)
0 引 言
降水是水文循环中的重要组成部分,同时也是水文模拟中的主要输入变量,降水估计的准确性直接影响水文模拟的精度[1]。以往的研究表明,水文模拟中70%~80%的不确定性源于降水数据[2-3],因此,亟需获取高精度、高分辨率的实时降水数据为水文模拟和洪涝灾害预报提供支撑。
传统的地面降水观测数据是最为直接准确的数据来源,但是受到成本、地形等因素的限制,地面观测站点的数量以及覆盖范围较为有限,分布不均,难以充分反映降水的空间分布。卫星遥感经过多年的发展,已能够提供全天候、全覆盖的降水数据产品。已有较多研究对遥感降水产品的精度及水文方面的应用进行了评估[4-6],并表明遥感降水产品能够比较准确地反映降水的时空分布特征,但在精度方面仍有较大的改进空间。
自20 世纪80 年代数据融合首次应用于雷达-观测降水数据融合以来[7],已逐渐成为改善降水数据分辨率和质量的主流方法之一。Chao等[8]运用混合地理加权回归的方法,对地面观测降水数据和CMORPH遥感降水数据进行了融合,显著提高了遥感降水数据的空间分辨率,并改善了其对降水空间异质性的捕捉。Chen等[9]使用两个神经网络模型,设计了一个降水数据融合系统,其利用地面雷达降水估计作为桥梁,对地面观测降水和遥感降水进行融合,有效提高了遥感降水产品的精度。Wu等[10]则通过深度学习方法,融合了地面观测降水数据和TRMM遥感降水数据,在中国范围内生成了一套准确度和空间分辨率更高的降雨数据集。以上研究都表明降水数据融合产品能够充分结合地面观测降水数据的精度以及遥感降水数据的高分辨率,而事实上其质量很大程度上取决于融合算法的选择和设计。本次研究采用基于长短期记忆神经网络(Long Short-Term Memory network,LSTM)的空间插值方法和时间动态贝叶斯模型平均(Dynamic Bayesian Model Averaging,DBMA)数据融合方法,对地面观测降水数据和基于综合多卫星反演的全球降水测量(Integrated Multi-satellite Retrievals for Global Precipitation Measurement,IMERG)遥感降水数据进行融合,旨在获得更高精度、高分辨率的降水产品,并提高其在水文模拟中的应用效果。
1 研究区域与数据来源
1.1 研究区域
湘江是长江最大的支流之一,也是湖南省最长的河流,全长约856 km。湘江流域位于长江中下游地区(东经110.50°~114.25°,北纬24.50°~28.25°),湘潭站以上流域面积约为82 375 km2(见图1)。流域属亚热带季风气候,年均气温约为17 ℃,年均降水量约为1400~1700 mm。流域地形以山地丘陵为主,地势上总体呈现南高北低的特点。流域内的土地利用类型以林地为主,西部和南部分布着大量农业用地[11],是中国重要的粮食基地。而流域下游城镇密集人口众多,是湖南省的经济发展中心。
1.2 数据来源
本次研究选用美国国家航空航天局NASA (National Aeronautics and Space Administration,NASA) 发布的IMERG V05B作为遥感降水数据来源[12]。IMERG由多种降雨反演算法组成,并结合了从GPM传感器获得的多个遥感数据源,能够以0.1°的空间分辨率和30 min的时间分辨率提供降水估算。本次研究选用IMERG系统产生的滞后时间为4 h的IMERG Early Run(以下简称IMERG-E)作为降水数据融合的遥感降水数据来源。
从中国国家气象信息中心(https:∥data.cma.cn)获取湘江流域27个气象站的日降水数据(以下简称GAUGE)作为降水数据融合的地面站点观测降水数据来源。同时,应用27个气象站的其他气象数据(最高和最低温度、相对湿度、风速和太阳辐射)获得用于驱动水文模型的气象变量。
为了对融合降水数据进行评估,本次研究选用中国国家气象局发布的中国自动站与CMORPH降水产品融合的逐时降水量网格数据集1.0版(以下简称CMA)作为参考降水数据集[13]。该产品具有较小的偏差,可以捕捉到强降水期间的降水时空变化特征,在中国区域优于国际同类型产品的精度[14]。研究中使用的湘潭水文站2014~2017年间每日观测径流数据来自湖南省水文局,使用的2015年归一化植被指数(Normalized Difference Vegetation Index,NDVI)数据来自中国科学院资源环境科学数据中心(http:∥www.resdc.cn/)。
2 研究方法
本次研究选用湘江流域27个地面站点处的GAUGE降水数据和IMERG-E遥感降水数据,在0.1°的空间分辨率下,对2014年4月1日至2017年12月31日的日降水数据进行数据融合。首先采用基于LSTM的空间插值方法,对27个地面站点处的GAUGE降水数据进行空间插值,获得0.1°空间分辨率下的降水估计(以下简称GAUGE-grid)。然后通过DBMA数据融合方法,对GAUGE-grid和IMERG-E在时间序列上进行数据融合,以获得整个流域上基于遥感降水的高精度降水估计(以下简称CMA-E)。最后对融合降水产品的精度及水文应用方面进行评估。图2展示了上述的时空动态数据融合方法。
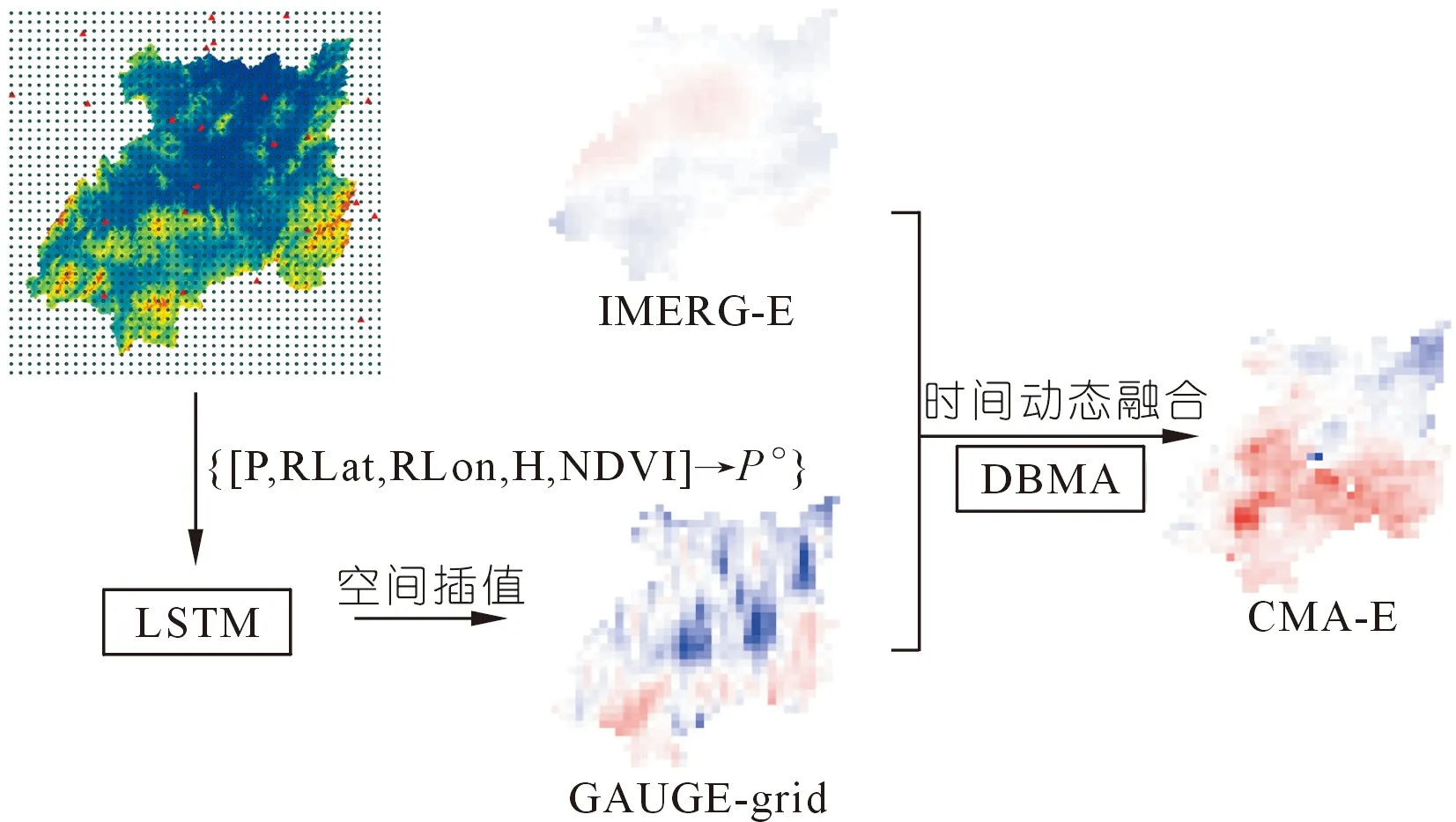
图2 时空动态数据融合方法Fig.2 Spatio-temporal dynamic data fusion framework
2.1 基于长短期记忆(LSTM)神经网络的空间插值方法
本次研究基于LSTM对降水数据进行空间插值,该过程主要包括建立时间序列样本和模型训练两部分。假设在研究流域有N个地面观测站点,这N个站点的时间序列样本则为
P=[P1,P2,…,PN]∈R1×N
(1)
Lat=[lat1,lat2,…,latN]∈R1×N
(2)
Lon=[lon1,lon2,…,lonN]∈R1×N
(3)
H=[H1,H2,…,HN]∈R1×N
(4)
NDVI=[NDVI1,NDVI2,…,NDVIN]∈R1×N
(5)
式中:P为降水数据;lat为纬度;lon为经度;H为高程;NDVI为归一化植被指数。
由于在插值过程中较近的观测站点对目标点的影响较大,而较远的观测站点对目标点的影响较小,本次研究选用距目标点欧氏距离最近的8个地面观测站点在目标点进行插值。此外,直接计算已知点与未知点之间的距离可能会丢失方向信息,为了解决这个问题,本次研究考虑了点与点之间的相对位置,用相对纬度和相对经度作为输入变量,其计算公式如下:
RLat=(lato-Lat)∈R1×N
(6)
RLon=(lono-Lon)∈R1×N
(7)
式中:lato和lono为目标点的经纬度。在添加空间信息后,模型的输入和输出可表示为
{[P,RLat,RLon,H,NDVI]→Po}
(8)
模型训练选择均方误差MSE作为LSTM的目标函数,并采用学习率LR为0.000 1的Adam算法训练模型。神经网络通常将数据集分为训练数据集与验证数据集,前者用于训练拟合模型,后者用于调整模型的超参数并在模型迭代训练时验证模型的泛化能力。在本次研究中,将27个地面观测站点数据的时间序列样本以2∶1的比例分为训练集和验证集,并根据训练期和验证期的模型性能综合选取最佳的模型参数。确定最佳模型参数后将湘江流域748个0.1°格点的高程、归一化植被指数和相对经纬度以及地面观测站点的降水数据的时间序列样本作为输入,将地面观测降水数据在湘江流域插值至0.1°。
2.2 动态贝叶斯模型平均(DBMA)数据融合方法
在本次研究中,使用DBMA数据融合方法[15],其由不同模型的概率密度函数(Probability Density Function,PDF)分配不同的权重来改善降水估计,以获得与参考降水数据之间良好的适配度。与传统的为不同模型分配固定权重的贝叶斯模型平均法相比[16-17],DBMA数据融合方法为不同模型分配动态权重,该方法的动态性体现在权重会随时间变化,以使其适应时间变化引起的天气模式变化。DBMA数据融合结果的PDF为
(9)
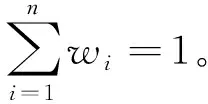
p[y(t)|O(t)]=
(10)
(11)
式中:ai和bi是通过参考降雨数据以及不同模型降雨数据简单线性回归得到,其可以视为简单的偏差矫正过程。从本质上来说,DBMA融合的降水估计是在给定参考降水数据的基础上,基于不同降水产品的似然值进行加权平均获得的。由于直接求解DBMA参数解析解的复杂性,通常会采用迭代的方法,本研究选用期望最大化(expectation-maximization,EM)算法求解DBMA参数[18]。
DBMA融合降水估计y的后验平均值E(y|O)和方差Var(y|O)为
(12)
(13)
该步骤中训练期是一个滑动窗口,对于时间点t来说,在其之前40 d内的各个模型的降雨估计都是其训练数据集,随后利用线性回归对训练期各个降雨估计进行偏差矫正。最后使用EM算法计算拟合该时间点下各个模型降雨产品的权重系数,最终实现权重系数随时间动态变化。
2.3 DHSVM模型
DHSVM模型是由美国太平洋西北国家实验室(Pacific Northwest National Laboratory,PNNL)和华盛顿大学(University of Washington,UW)开发的分布式水文模型[19]。DHSVM利用近地表气象数据(气温、风速、湿度、降水量以及短波和长波辐射)作为水文气象输入来计算能量和水量平衡问题。本次研究使用的模型版本为DHSVM 3.1.2,设置的网格分辨率为3 000 m。在DHSVM模型中将湘江流域被划分为6种土壤类型和8种植被类型,其空间分布如图3所示。
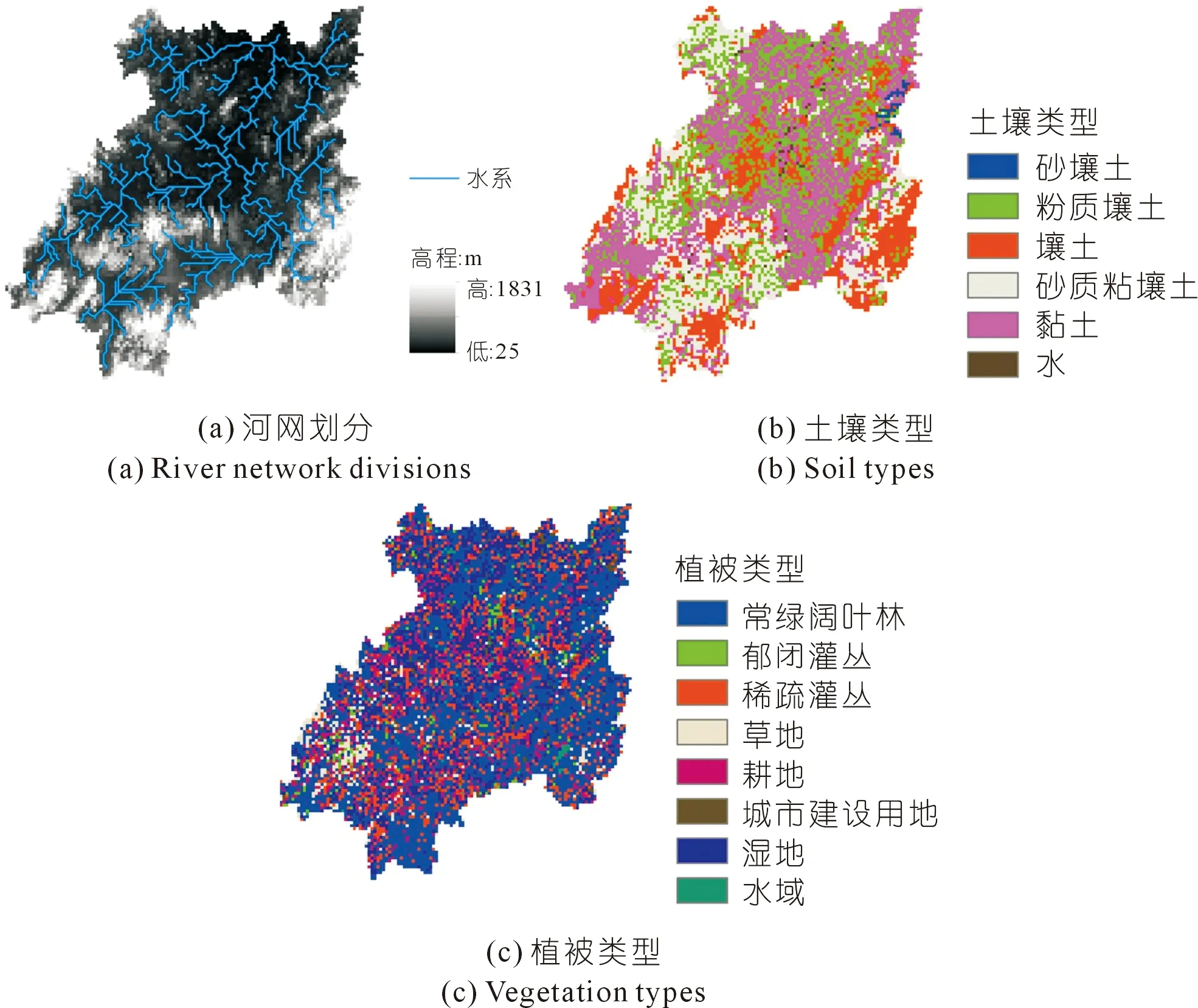
图3 DHSVM模型中湘江流域Fig.3 Division of Xiangjiang River Basin in DHSVM model
本次研究选用DHSVM模型进行水文模拟,将研究时期分为3个阶段:预热期(2014年4~12月)、率定期(2015年1月至2016年12月)和验证期(2017年1~12月)。以径流模拟的纳什效率系数NSE为目标函数,采用基于ε支配的第二代非支配排序遗传算法(ε-dominance Non-dominated Sorted Genetic Algorithm Ⅱ,ε-NSGAII)的自动率定模块进行参数率定[20]。
2.4 评估指标
本次研究选用相关系数(Correlation Coefficient,CC)、均方根误差 (Root Mean Square Error,RMSE)、相对偏差(Relative Bias,BIAS)3个指标定量评估遥感降水在湘江流域的精度,并采用NSE和BIAS-P评估遥感降水在径流和洪水事件模拟中的表现,具体指标计算公式如下:
(14)
(15)
(16)
(17)
(18)
3 结果与讨论
3.1 融合降水评估
图4显示了湘江流域2014年4月1日至2017年12月31日,CMA,IMERG,GAUGE-grid,CMA-E降水产品的平均日降水量的空间分布。根据CMA的降水空间分布,湘江流域的降水具有较大的空间异质性,从东北向西南呈显著下降趋势。IMERG-E在流域中西部降水相对较少,其他地区降水分布相对均匀。GAUGE-grid在流域北部降水较多,可以显示出较多降水空间分布的细节。CMA-E则与CMA的空间分布比较吻合,经过对IMERG-E和GAUGE-grid的融合,其降低了IMERG-E在流域南部对降水的高估,而在流域中部的降水估计则有所提升,呈现出北多南少,从东北向西南递减的降水空间分布。
研究统计了以GAUGE为参考降水数据,CMA,IMERG-E和CMA-E降水产品在地面站点处的CC,RMSE和BIAS,如表1和图5所示。根据评估指标CC,CMA-E降水产品展现出了与地面观测降水数据较强的相关性,在大部分站点处其CC要大于IMERG-E和CMA。在部分地面站点,如编号为57 669,57 679,57 682和57 780的站点,CMA-E降水产品的CC高于0.65,表现出了较高的相关性。在RMSE方面,CMA-E降水产品与IMERG-E,CMA降水产品相比均有所改善,其均值约为11.23 mm,略小于IMERG-E的13.3 mm以及CMA的12.03 mm。通过比较27个地面观测站点处的BIAS,IMERG-E是3种降水产品中表现最好的,其BIAS绝对值的平均值约为10%,而CMA和CMA-E则为20%左右。CMA对其中22个地面观测站点的降水存在明显低估,而CMA-E表现与CMA类似。
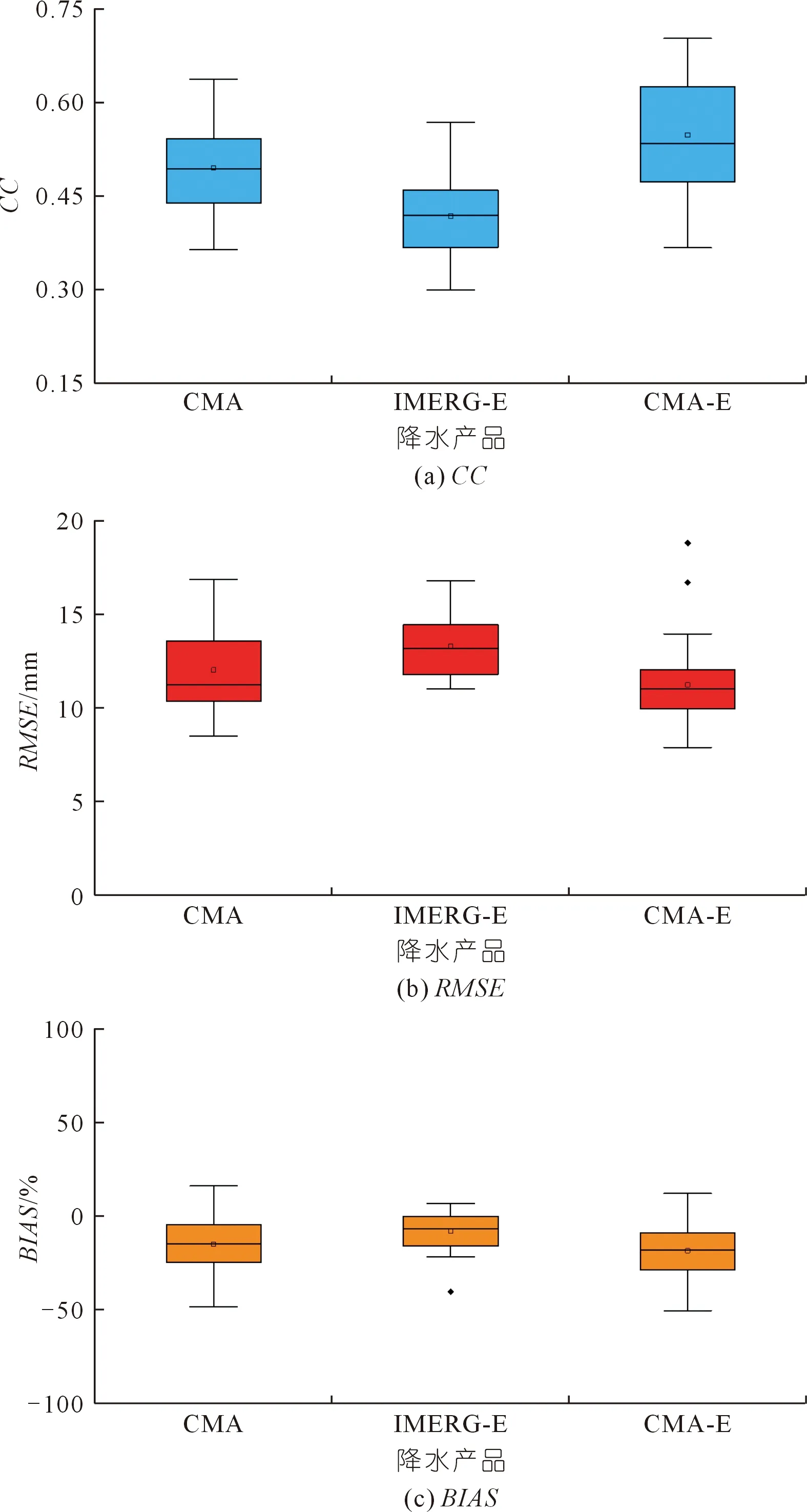
注:箱线图显示25,50和75百分位,其中正方形表示平均值。图5 CMA,IMERG-E和CMA-E降水产品在地面观测站点处的CC,RMSE和BIAS箱线图Fig.5 CC,RMSE and BIAS of CMA,IMERG-E and CMA-E at ground observation stations
基于以上结果,本文提出的方法所得到的降水融合产品空间分布与CMA基本一致,降低了IMERG-E在流域西南区域上的高估值并修正了一些误报。同时根据表1结果,最终所得到的降水与地面观测结果有着更强的相关性,其CC和RMSE相较于IMERG-E有较大的改善。其原因是降水融合过程中采用了LSTM的空间插值方法,该方法融合了研究流域内的高程以及NDVI数据,将27个地面站点处的GAUGE降水数据进行空间插值。但是其BIAS较低,存在对降水的低估现象,这是由于神经网络方法的局限性,其原理机制存在一定的黑箱效应,在使用神经网络方法进行降水融合时也存在类似低估的现象[21]。
总体而言,融合降水产品 CMA-E能够很好地捕捉湘江流域降水的空间分布,在基于地面站点的评估中,其CC和RMSE相较于IMERG-E有较大的改善,与地面观测降水有着更高的相关性。
3.2 基于融合降水的水文模拟
分别以3个降水产品(CMA,IMERG-E,CMA-E)作为DHSVM的降水输入进行水文模拟,并选用NSE和BIAS-P对模拟性能进行评估,其降雨-径流过程如图6所示。由图6可知,CMA-E径流模拟的NSE基本与CMA相当,在率定期分别为0.79和 0.80,在验证期分别为0.87和0.86,二者均远高于IMERG-E的0.55与0.75。将CMA和CMA-E作为降水输入得到的模拟结果良好,证明了DHSVM模型在湘江流域进行径流模拟的适用性。
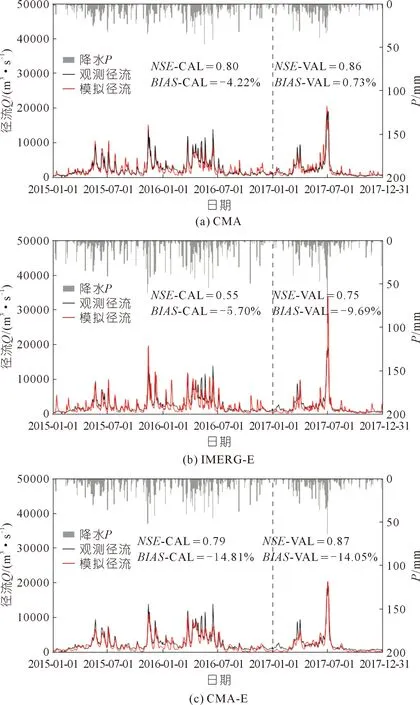
注:CAL表示率定期,VAL表示验证期。图6 湘江流域CMA,IMERG-E,CMA-E驱动下的日尺度DHSVM模型模拟径流Fig.6 Daily streamflow simulated with DHSVM model drivenby CMA,IMERG-E and CMA-E precipitation in the Xiangjiang River Basin
为了评估遥感降水产品在洪水模拟中的表现,本次研究选取了研究时间范围内的11场历史洪水事件进行评估,选择的依据为洪峰流量超过8 600 m3/s(相当于97分位数)。表2显示了将CMA,IMERG-E和CMA-E作为降水输入的洪水事件模拟的性能。相较于IMERG-E,CMA-E有效改进了洪水事件模拟的性能,率定期的平均NSE从0.26提高到了0.61,验证期的平均NSE从0.41提高至0.84,对比CMA的0.80也有一定的改进。且IMERG-E所有洪水事件模拟的NSE均大于零,有效改善了IMERG-E无法准确捕捉到的洪水事件模拟。BIAS-P方面,其结果与NSE相似,CMA-E模拟的洪水事件较IMERG-E在BIAS-P均值上亦有所降低,率定期的均值从21%下降至14%,验证期的均值由40%下降至21%。
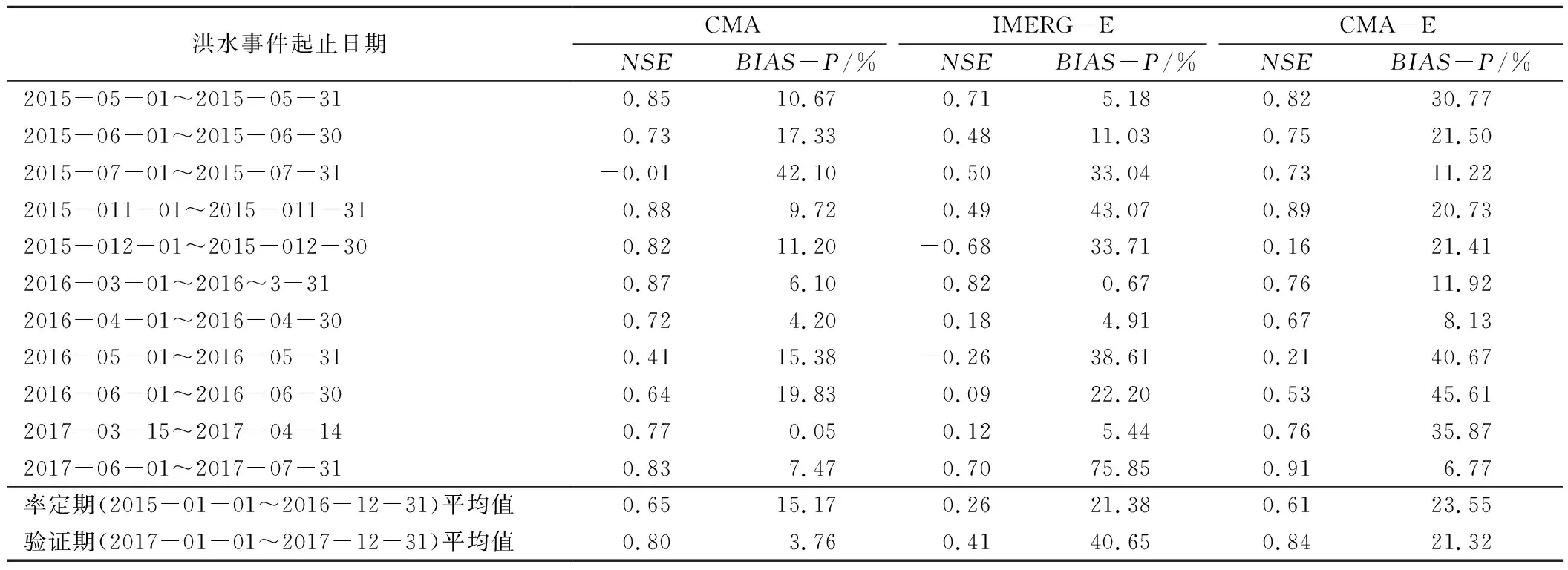
表2 CMA、IMERG-E和CMA-E驱动下的DHSVM模型对洪水事件模拟的NSE和BIAS-PTab.2 NSE,BIAS-P of flood events simulation using DHSVM driven by CMA,IMERG-E and CMA-E
基于以上结果可以看出,IMERG-E作为降水输入时所得到的径流模拟效果较差,在洪水事件的表现上有着最大的不确定性,无法很好地捕捉洪峰,对多个洪峰存在显著的高估,低流量时期也存在类似的高估现象。这是因为作为降水输入的IMERG-E本身存在误差,而降水估计的误差会在水文模拟的过程中传播,导致最后径流模拟效果较差[22- 23]。相对而言,CMA-E作为降水输入时所得到的径流模拟效果有着更好的表现,其结果有着更高的NSE,同时能模拟出更为平滑稳定的径流,更符合实际观测所得的径流过程,这证明了本研究所采用的数据融合方法能够得到更高精度的降雨数据,进而改进其在径流模拟中的性能。
4 结 论
本文提出了一种时空动态数据融合方法,并通过评估融合降水数据的精度及在水文模拟中的应用,有效证明了所提出的时空动态数据融合方法在改善遥感降水的精度及其在水文模拟中应用的适用性。具体结论如下:
(1) 利用本文所提出的基于LSTM和DBMA的时空动态数据融合方法对湘江流域的地面观测降水和IMERG-E遥感降水数据进行融合,能够获得高精度、高分辨率的CMA-E降水产品。其能够很好地捕捉湘江流域的降水空间分布,与地面观测降水具有较高的相关性。
(2) 基于分布式水文模型DHSVM对CMA-E降水产品在水文模拟中的应用进行评估,发现与CMA,IMERG-E相比,CMA-E能够更准确地模拟径流,并且在洪水事件期间,NSE与BISA-P也均有一定程度上的改善。
