Novel multi‐domain attention for abstractive summarisation
2023-12-01ChunxiaQuLingLuAijuanWangWuYangYinongChen
Chunxia Qu| Ling Lu | Aijuan Wang | Wu Yang | Yinong Chen
1College of Computer Science and Engineering,Chongqing University of Technology,Chongqing,China
2School of Computing and Augmented Intelligence,Arizona State University, Tempe,Arizona,USA
Abstract The existing abstractive text summarisation models only consider the word sequence correlations between the source document and the reference summary,and the summary generated by models lacks the cover of the subject of source document due to models'small perspective.In order to make up these disadvantages, a multi-domain attention pointer(MDA-Pointer)abstractive summarisation model is proposed in this work.First,the model uses bidirectional long short-term memory to encode,respectively,the word and sentence sequence of source document for obtaining the semantic representations at word and sentence level.Furthermore,the multi-domain attention mechanism between the semantic representations and the summary word is established,and the proposed model can generate summary words under the proposed attention mechanism based on the words and sentences.Then,the words are extracted from the vocabulary or the original word sequences through the pointer network to form the summary, and the coverage mechanism is introduced, respectively, into word and sentence level to reduce the redundancy of summary content.Finally, experiment validation is conducted on CNN/Daily Mail dataset.ROUGE evaluation indexes of the model without and with the coverage mechanism are improved respectively,and the results verify the validation of model proposed by this paper.
K E Y W O R D S abstractive summarisation, attention mechanism, Bi-LSTM, coverage mechanism, pointer network
1 | INTRODUCTION
The massive amount of information in digital era has triggered the realistic demand for quick acquisition of critical information from large-scale data.People usually need to read and obtain key information from a large number of texts,including news, novels, legal documents, blogs etc.in a relatively short period of time.Thus, automatic text summarisation [1, 2]comes into being.It aims to generate concise text outlining the significant information of source document by understanding the semantic information of source document.It is one of the important basic tasks in research and application of natural language processing (NLP), such as information retrieval systems, automatic question answering systems and also has important practical significance for research and application in disciplines including library and information science, applied linguistics [3], cognitive psychology and other disciplines.
Current automatic text summarisation methods are generally divided into two main categories:extractive and abstractive.The former[4,5]produces a summary extracted from a source document,while the latter[6,7]generates novel words to form summary, which is closer to the manner that people write summaries [8–11].High-quality summarisation should cover key information of the source document and also be concise and fluent in syntax with strong readability, which provides multiple directions for studies of automatic text summarisation.In terms of covering more cue information about the source document and improving readability of summaries, existing approaches mainly model word sequence correlations between the source document and the target summary,which ignores an important action in a human-written summary, that is, information synthesis across text regions.In manual summarisation,one first reads words and phrases, then combines sentences,paragraphs, and subheadings of the source text to generate a summary that fully covers the key information of source documents.However, current automatic summarisation techniques do not sufficiently take into account this natural information fusion behaviour in manual summarisation.
Inspired by manual summarisation methods, it is reasonable to argue that reading documents from perspectives of sentences,paragraphs and whole texts,integrating information from all regions of the source document,helps to improve the quality of generated summarisation.Based on this view, we argue that integrating semantic information of sentences and paragraphs into word sequences can enhance the understanding of the source document, thus to improve the quality of automatic summarisation.
In view of these,a multi-domain attention pointer (MDAPointer) abstractive summarisation model is proposed by us,which can improve the cover and readability of summarisation by incorporating an attention mechanism.The attention mechanism between sentences of the source document and target summary words is established via this model.Thus,MDA-Pointer can learn to seize the semantic representation of the source document from multiple viewpoints in the stage of encoding.And during the decoding stage,the model considers contributions of the source document from word and sentence when generating the summary.In this case, the informative semantic representation of a document is obtained from two horizons of words and sentences level.It can be used by MDA-Pointer to supervise the decoder to generate ideal summaries, which can better reflect important and saliency information of this document.
Our contributions can be summarised as follows:
(1) We consider the importance of sentences of the source document for summary and the natural information fusion that manual summarisation.
(2) We propose a multi-domain attention based on words and sentences of text, which can enhance the semantic representation of the text, thus to generate a high-quality summary.
(3) Experiments are conducted on the CNN/Daily Mail datasets.The results show that our MDA-Pointer abstractive summarisation model outperforms the baseline model.Source code is available at: https://github.com/Qudaxia66/MDA-Pointer-master.
The rest of this paper is organised as follows.Related work on automatic summarisation is reviewed in Section 2.The inspiration of our work is described in Section 3.The MDAPointer abstractive summarisation model is presented in Section 4.Experiment and analysis are given in Section 5.Finally,Section 6 concludes the paper.
2 | RELATED WORK
Currently, sequence-to-sequence (Seq2Seq) [12, 13] based on deep neural networks provide an end-to-end text generation framework for NLP, and it is widely used in headline generation [14], speech recognition [15], machine translation (MT)[16] and other fields.Most automatic text summarisation approaches consider abstractive summarisation as a MT task,thus the encoder–decoder framework commonly used in MT is extensively used for abstractive summarisation task.Among them, the encoders and decoders can be feedforward neural network (FNN), convolutional neural network (CNN) and transformer [17].In particular, long short-term memory(LSTM), gated recurrent unit (GRU) etc.are also widely used.Rush et al.[7]propose to encode the source text with a CNN encoder and generate summary with an FNN decoder,which is the first application of the neural translation model in automatic abstractive summarisation tasks.Chopra et al.[18]replace the decoder with recurrent neural network(RNN)and achieve state-of-the-art performance results on Gigaword and DUC-2004 datasets.Nallapati et al.[6] implement both the encoder and the decoder using RNN and the attention mechanism, and they also construct CNN/Daily Mail corpus,which has been one of the benchmark datasets in automatic text summarisation research.
The quality of summaries is always affected by out of vocabulary (OOV) words, because it is impossible to cover all words in the vocabulary.Vinyals et al.[19]propose the PtrNet model that added to the Seq2Seq model,after pointer network is widely adopted [20–22].In 2016, Gu et al.[23] propose a CopyNet model with a copying mechanism, and this mechanism is similar to human mechanical memory methods.Part source document words are copied by the CopyNet model to alleviate problem of poor summary readability caused by OOV words.In 2017, See et al.[8] propose the automatic text summarisation method combining the pointer network[19].It combines the pointer generator network with the Seq2Seq [6]model for generating summary.The method generates new words from fixed vocabulary and extracts words from the document, thus coping better with the OOV words problem and generating more natural and fluent summary.
Another common problem of the summary generated by the abstractive summarisation models is redundant words,that is, certain words appear repeatedly and consecutively in the summary.In this regard, See et al.[8] first apply coverage mechanism [24] to automatic text summarisation, which effectively alleviated the problem of generating redundant words.Lin et al.[25]propose a global encoding framework that enriches the information representation of encoded fragments to avoid generating redundant words at the decoder side.With the development of attention mechanism in various research tasks, particularly image processing [26, 27], more attention mechanisms are proposed in automatic text summarisation.Intra-decoder attention mechanism[28]and temporal attention mechanism [6] have also been demonstrated to alleviate the problem of repetitive generation to some extent.
Overall, the Seq2Seq models based on attention mechanism are commonly used for automatic text summarisation tasks.Strategies based on MT to improve quality of automatic summaries by capturing the attention between words of source text and words of summary are also commonly accepted.Meanwhile, pointer mechanism and coverage mechanism can deal with OOV words and redundant context to some extent.Currently, dominating applications of the Seq2Seq model mainly focus on word level, that is, the encoder encodes the word sequence of the document to obtain the semantic representation, and then the decoder generates the summary.However,from the way that people write summaries,we argue that understanding text should focus on both word sequences and sentence sequences, or even paragraph sequences.Obviously, reading consecutive sentence sequences and understanding the original document from a larger perspective can help to improve the understanding of the original document,thus increasing the cover of the summary to the main idea of source document text.In this regard, the existing horizon,which focusses only on word correlations of the document with summary, may restrain the further improvement of summary quality.
Therefore, this paper incorporates sentence information into abstractive text summarisation model and proposes the MDA-Pointer abstractive summarisation model with sentence attention that can generate a summary that better covers the main idea information of the source document.Meanwhile,pointer networks [19] and coverage mechanisms [24] are used to cope with OOV words and redundant contexts,respectively.Experimental results on the CNN/Daily Mail dataset show that summaries generated by MDA-Pointer are enhanced in terms of ROUGE index and have better fluency and readability.
3 | INSPIRATION
Since abstractive text summarisation is mostly considered as an MT task,which is to translate source text into a summary,the encoder–decoder framework based on Seq2Seq for MT is widely used for automatic summarisation tasks.As shown in Figure 1,the encoder first reads word sequenceT=[t1,t2,…,ti,…,tn] of the source document and then learning and accumulating knowledge to obtain the semantic representationsH= [h1,h2,…,hi,…,hn] of the source document.
Hrepresents the comprehensive information of the source document, which not only contains the document semantics,that is, the main information of the document, but also knowledge of grammatical structure of document word sequence.Therefore, the decoder can generate the summary word sequenceW= [w1,w2, …,wj, …,wk] that reflects the significant implication of the source document and also has grammatical rule.
The abstractive text summarisation needs to translate the source document into a summary,which means converting the long and redundant text into a brief and condensed version of text.Consequently,Hshould fully cover and reflect the important and saliency information of the source document,so as to help the decoder to generate a desirable summary that represents the core information of this document.Existing LSTM-based encoders are mostly focussed on word sequences.Although LSTM can remember the semantics of long range,it is insufficient in learning and grasping the key information of the source document.Hence, the attention mechanism is introduced for further study.Attention between a sequence of source document words and summary words can be regarded as a contribution of the source document words to the summary words.It has been experimentally demonstrated that using attention mechanism to generate summary words can effectively improve the quality of summaries.However, the source document is fed to encoder as word sequence, making the encoder can only read and understand the source document at word level,and then the attention is established only in words of the source document and words of the summary.The small viewing horizon makes it difficult for the encoder to produce a representation that reflects both whole text information and highlights the main idea information.
It is common to read and comprehend the whole document first in manual summarisation.This is due to the fact that reading only part of the words,sentences or paragraphs is not sufficient to understand the whole document.In addition, the model only focusses on the word sequence of the source document and word-level attention may failed to reflect the global key information of this text; thus, this is inconsistent with the requirement that the summary is an overview of source text.For example, in Figure 2, the meaning of ‘家(home)’, ‘生命(life)’, and ‘回家(home)’, ‘路上(way)’ are entirely unimportant to the words of summary ‘食物(food)’and ‘中国式伦理(Chinese ethics)’.While words ‘食物(food)’and‘中国式伦理(Chinese ethics)’are more essential.Based on the word-level attention, the model learns the correlation not only costly but also its efficiency is low.And this causes the problem that did not see the forest for the trees appears.
We argue that it is usually necessary to read the whole document before manual summarisation.It is necessary to understand this document at both word level and sentence level.The former makes us read and understand this document, while the latter is to understand the key information of the document in a wider scope.Thus, by understanding the original document from both word and sentence domains,the quality of the generated summary can be improved.
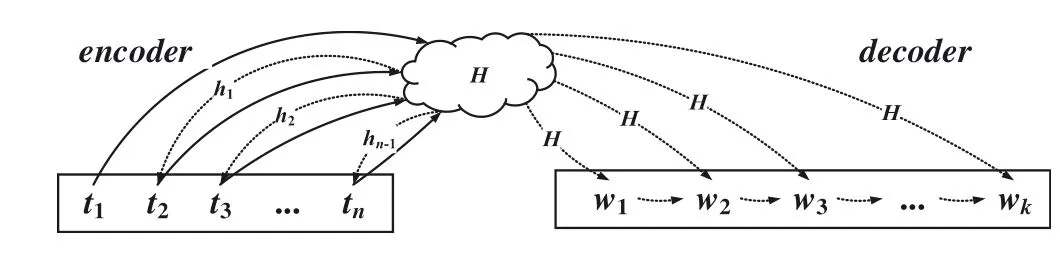
F I G U R E 1 The flow diagram of conventional abstractive summarisation model

F I G U R E 2 Example of article and summary
It is well known that the encoding stage of manual summarisation contains two operations:read and understand.Read,in other words, read through this whole document.And the semantic and syntactic information about the source document can be obtained,while understand,that is,to understand the full document from sentence level;this operation can gasp important and saliency information.The second stage is mainly to observe some areas of this document, which may obtain key information of the original document and is crucial to understanding this article.To sum up,in order to overcome the deficiency of understanding and capturing the important and saliency information of source document text with attention only in document words and summary,this paper adds the understand process into encoder–decoder framework after overall and comprehensive understanding,as shown in Figure 3.
The encoder consists of read and understand steps:
Step1 Read: from the perspective that the document is composed of words, the encoder reads, studies and understands a sequence of a document word in order to acquire word level semantic representation.
Step2 Understand:from the sentence at this higher level,the encoder further reads, studies and understands the sentences of the source document to obtain higher level semantic representation.
During the decoding, the overall semantic representations of this document are obtained by the word encoder and sentence encoder, respectively, and the target summary is used to establish the attention mechanism, and the multir-domain attention is obtained from the perspective of word and sentence level,and the corresponding semantic vector is obtained to guide the model to write a desirable summary that is concise and has high saliency.
4 | MDA‐POINTER MODEL
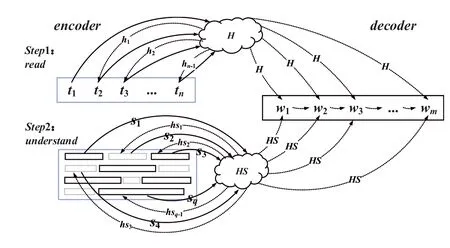
F I G U R E 3 The flow diagram of the multi-domain attention abstractive summarisation model of combining sentences attention
We describe the MDA-Pointer abstractive summarisation model in detail in this section.To generate summaries, See et al.[8] propose a fusion of an attention-based Seq2Seq [6]and pointer network[19],which inspired the method proposed in this paper.In order to apprehend the important information of the source document more comprehensively and accurately during the process of encoder,this paper proposes the MDAPointer abstractive summarisation model integrating wordlevel and sentence-level multi-domain attention under the model of See et al.[8].The proposed model is shown in Figure 4.The model contains four parts: read, understand,pointer generator network and coverage mechanism.First,read, namely, a sequence of document words are fed into the word encoder of the MDA-Pointer abstractive summarisation model, and the model uses bidirectional LSTM to project the word embedding of document words into semantic vector space.We can obtain their semantic representation to generate summary words.Inspired by the manner that people write summary,people can observe the large view of the document,we incorporate the understand process.In this way,the model can receive the global key and important information by the document sentences is input.Similarly, an additional bidirectional LSTM is used to process sentences in the same projecting way.Context vectors are obtained by the read and understand steps, in other words, the multi-domain attention mechanism between the document words and sentences attention scores to the target summary word.And then, the model utilises the pointer generator network to generate a summary,which can copy words from the source document to cope with OOV words problem.Finally, the model in this paper still generates redundant content that affects the quality of summary.Thus,coverage mechanism[24]incorporated into the MDA-Pointer abstractive summarisation model alleviates this problem.
4.1 | Attention‐based Seq2Seq model
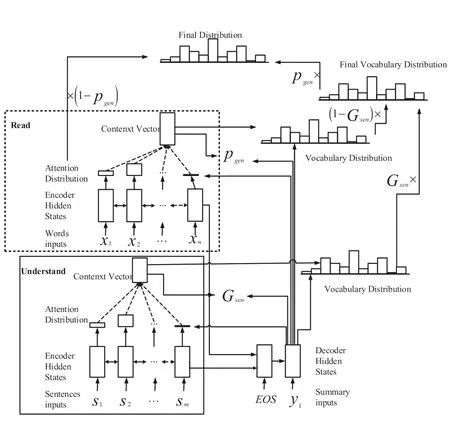
F I G U R E 4 Model structure diagrams of MDA-Pointer abstractive summarisation model
The encoder of the MDA-Pointer abstractive summarisation model has abilities that learning and comprehending knowledge of the source document and projects the source document into semantic vector space from word and sentence domain, respectively, forming the representations of this document in different horizons.Bidirectional LSTM is used to encode the word sequence of the document, to obtain semantic and syntactic representation of this document.

wherexiis the word representation of theithword in word sequence of the source document, andhiw_eis the semantic representation of contents beforeithword in the source document.
The decoder of the MDA-Pointer abstractive summarisation model is unidirectional LSTM, which receives the summary word embedding on each steptto obtain the decoder statehtw_d.During the model training,this word is the target summary word, while it is predicted summary word by the model in the test time.


4.2 | Multi‐domain attention mechanism
The MDA-Pointer abstractive summarisation model simulates the human-written summary, understanding the composition of source document text as different types of semantic units,and considering the key,main information of source document text from both word and sentence levels completely and accurately, and then guiding the generation of high-quality summaries that are readable, coherent, non-redundant and consistent with the main information of this document.
The MDA-Pointer abstractive summarisation model has a understand step, which establishes the multi-domain attention between the source document words and sentences to the target summary word.


4.3 | Pointer generator network
The pointer generator network is a hybrid model combining both an attention-based Seq2Seq model [6] and a pointer network [19].Summary words can be generated from fixed vocabulary or copied from the source document.The generation probabilitypgenis a soft switch and determines the word is generated or copied:

4.4 | Coverage mechanism


5 | EXPERIMENT AND ANALYSIS
5.1 | Experimental setting
The experiments are conducted on the CNN/Daily Mail dataset [6], which is the benchmark dataset of automatic text summarisation research.The dataset is an open-domain text that articles are online news, with a summary written by human.The dataset includes CNN and Daily Mail,and both have 90,266 training pairs,1220 validation pairs,1093 test pairs and 196,961 training pairs,12,148 validation pairs,10,397 test pairs,respectively.From Table 1, we can find that the average word length of articles is 764,the average words length of summaries is 58, and the length ratio is 13:1.To fair the results of experiment,we utilise the pre-processing method proposed by See et al.[8].
The size of sentence embedding, word embedding and LSTM hidden states are set to 768, 128 and 256, respectively.Since the pointer network can solve the OOV problem, we utilise a vocabulary of 50k words.The optimisation algorithm in experiments is Adagrad[30].The initial learning rate is 0.15,initial cumulative value is 0.1, and the gradient norm used for gradient clipping is 2.The input word sequence length is 400;the maximum length of sentence input sequence is restricted to 30.The maximum length of the output sequence of MDAPointer is 100 during training and 120 during testing.The experimental batch size is set to 32, and a beam search of beam size four is used to generate the summaries when decoding.The adjustment factor of the loss function in Equation (28) is set as 1.
5.2 | Evaluation index
The evaluated mechanism of generated summarisation in this paper adopts the ROUGE scoring mechanism [31], which ismainly used to calculate the degree of lexical unit overlap between the reference summarisation and the generated summarisation.ROUGE-N is calculated as follows:
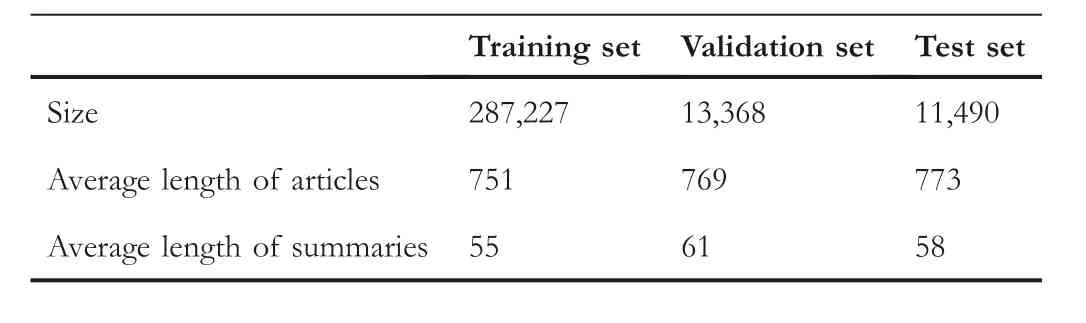
T A B L E 1 CNN/Daily Mail and related attribution
where {ReferenceSummaries} is the reference summaries,gramnis the meta-grammar unit co-occurring between summaries generated by the model and reference summaries given by human, Countmatch(gramn) is the same number of gramnbetween generated summaries and reference summaries, and Count (gramn) is the number of gramnoccurrences in reference summaries.While ROUGE-L evaluates summaries from the dimension of the oldest sequence, and the calculation process is given in the following formulas:
whereXrepresents reference summaries,Yrepresents generated summaries,mandnrepresent the length of reference summary words and generated summary words,respectively, LCS(X,Y) is the longest common subsequence length of reference and generated summaries, and Rlcsand Plcsrepresent recall rate and accuracy rate, respectively.βis equal of Rlcsdivided by Plcs, and Flcsis the final ROUGE-L score.
5.3 | Experimental results and analysis
We compare models proposed by this paper with some comparative models proposed by other researchers,which also verify the validation on CNN/Daily Mail [6].We report the results directly from the related paper, and the comparative models are as follows:
Attention-based Seq2Seq: the model is a basic encoder–decoder structure in which encoder is GRU and so does decoder, where encoder encodes the input text and decoder decodes the contextual representation obtained from the encoder and gives different attention scores to the input text.
Pointer generator model: this model combines an attention-based Seq2Seq model with a pointer network.By this way,the model generates novel words from a fixed vocabulary or copies document words.
Pointer generator + coverage: the coverage mechanism is incorporated to the pointer generator model, aiming to solve redundant.
Pointer generator with pre-trained word embedding: this model adds an extra pre-trained layer of word embedding for the pointer generator model, aiming to improve the quality of abstractive summarisation.
Pointer generator with pre-trained word embedding + coverage: based on the pointer generator with pretrained word embedding, this model incorporates coverage mechanism to solve the repetition problem.
Topic Augmented Generator (TAG): this model uses the latent topics of the document to enhance the decoder to have access to additional words co-occurrence statistics captured at document corpus level.
The models proposed by this paper are as follows:
MDA-Pointer:MDA-Pointer is the model proposed by this paper;this model has a multi-domain attention based on words and sentences.
MDA-Pointer + coverage: this model combines with coverage mechanism to avoid repetitive content.
From the results shown in Table 2, we can find that the model proposed in this paper outperforms the comparative models in ROUGE evaluation index results.The MDA-Pointer abstractive summarisation model is proposed to integrate word and sentence multi-domain attention.By introducing and calculating the attention between the source document sentence sequence and target summary word sequence, the semantic representation of the source document text at a higher level,namely sentence level, can be obtained.Therefore, compared with the baseline model(pointer generator model),the evaluation indexes of ROUGE-1, ROUGE-2 and ROUGE-L are improved by 0.97%, 0.54% and 0.62%, respectively.Humans observe the generated summaries, and we can find that summaries have duplication in content.In order to solve this problem,the generated summary can effectively avoid repetition after incorporating the coverage mechanism into the model,namely,MDA-Pointer+coverage.From the result of evaluation index of MDA-Pointer+coverage,compared with the pointer generator + coverage model, ROUGE-1, ROUGE-2 and ROUGE-L are enhanced by 0.15%, 0.32% and 0.05%,respectively.
To observe the effect of proposed methods in this paper,we show the summaries generated by MDA-Pointer, MDAPointer+coverage and the baseline models(pointer generator and pointer generator + coverage) in Table 3, in which the reference summary extracted from CNN/Daily Mail[6]test set is shown in Table 3.
Examples in Table 3 shows that summary generated by the MDA-Pointer and MDA-Pointer + coverage model better cover the content of a reference summary.This indicates that the MDA-Pointer can extract and capture more key and saliency information that improves the quality of generated summaries.Compared with the baseline model (pointer generator model), the summaries generated by MDA-Pointer can comprehend the semantic information of source document sentences at a higher level.Then,the model can generate the context that ‘will be released on March 25, 2016’, and the film stars ‘affleck’ and ‘henry cavill’, which can appear in the generated summaries.These contents contribute to the semantic meaning of the generated summary is more consistent with the reference summary and source document.And they can cover the lexical units of the reference summary, resulting in improvement of the scores of ROUGE index.However,the redundant contents also appear in the generated summary that make summary unreadable, incoherence and unconcise.To solve this problem, we add coverage mechanism into the model to effectively reduce the occurrence of repeated content.The coverage mechanism incorporated into the MDA-Pointer can solve the problem of repeated content and is compared with the baseline model (pointer generator + coverage), and MDA-Pointer + coverage can generate more key and important information.For example,the content‘will be released on March 25,2016’,‘affleck’and‘henry cavill’only appear once in the generated summary by MDA-Pointer + coverage.At the same time, comparing the generated summaries by pointer generator + coverage and MDA-Pointer + coverage, we can find that the later covers more saliency information of the reference summary.According to the above,incorporating the sentence information of the source document into this modeland establishing the multi-domain attention in both sentences and words to the target summary word,this model can help the decoder to write a high-quality summary that projects completely and accurately the main idea of the long document.

T A B L E 2 ROUGE evaluation result

T A B L E 3 Summarisation examples of different models

T A B L E 4 Ablation studies of our model on the test set

F I G U R E 5 Iterative graph of different model training losses

F I G U R E 6 Iterative graph of different models with coverage mechanism training loss
We conduct ablation experiments to demonstrate the effect of the model proposed by this paper.As shown in Table 4,we can find that all kinds of module more or less performance boost to the model.First, we set the group ‘-sentence’ and remove the attention between the source document and target summary word.Results show that the results of ROUGE-1,ROUGE-2, ROUGE-L decreased by 0.27%, 0.27%, 1.4%,respectively.This indicates that the sentence level attention can extract and capture more key and saliency information of the source document.Second, to verify the effectiveness of coverage mechanism,we set‘-coverage’group and remove the coverage mechanism from our model.We find that the results of ROUGE-1, ROUGE-2, ROUGE-L dropped to 37.32%,16.35%, 34.13%, respectively.This means that the coverage mechanism can avoid the repetitive and redundant content.Finally, we set the group ‘-pointer’ and remove the pointer from our model.We find that the results of ROUGE-1,ROUGE-2, ROUGE-L dropped to 34.63%, 13.62%, 31.99%,respectively.And we observe that the summary generated by the model appear as‘UNK’.From the results of ROUGE and generated content, we can find that the pointer generator network can copy words from the input.
The training loss iterative graph of the MDA-Pointer abstractive summarisation model and the pointer generation model is presented in Figure 5.And then the training loss iterative graph of these models with coverage mechanism is given in Figure 6.In the figures, the horizontal coordinates indicate the number of model training steps and the vertical coordinate is the loss value of the corresponding steps.
From Figure 5, we can find that MDA-Pointer does not increase the number of model training steps due to the addition of the sentence encoding module.From Figure 6,we find that the loss of MDA-Pointer is lower than the loss of pointergenerator.
6 | CONCLUSION
This paper proposes MDA-Pointer abstractive text summarisation model combining word-level and sentence-level attention for automatic text summarisation.Under the conventional attention-based Seq2Seq model based on word sequence, sentence information is introduced and sentencelevel attention is incorporated into the decoding structure of the model.The pointer generation network is adopted to deal with OOV words problem,and coverage mechanism is utilised to optimise the repeated and redundant snippet in summary.Experimental results on CNN/Daily Mail shows that the summary generated by MDA-Pointer outperforms the benchmark models.Inspired by the way that a human writes summaries, this manner learns and understands the source document from the two horizons of words and sentences and observes the significance of information obtained from different perspectives.Experiments verify the validity of this idea.However, in terms of loss function, negative log likelihood is adopted in this paper.Therefore,word coverage is still the main control in the process of generated summary in this work; however, there is no further evaluation about the coverage of the generated summary topic to the source document theme.The following studies will be made on changing the view of observation and improving the loss function, so as to further improve the recall rate of generated summary words and expressive force of the summary to the main idea of the source document.ACKNOWLEDGEMENTS
This work is partially supported by the National Social Science Foundation of China(2017CG29),the Science and Technology Research Project of Chongqing Municipal Education Commission (2019CJ50), and the Natural Science Foundation of Chongqing (2017CC29).
CONFLICT OF INTEREST
None.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available from the corresponding author upon reasonable request.
ORCID
Chunxia Quhttps://orcid.org/0000-0002-3341-810X
Yinong Chenhttps://orcid.org/0000-0002-8780-3994
猜你喜欢
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Fault diagnosis of rolling bearings with noise signal based on modified kernel principal component analysis and DC-ResNet
- Short‐time wind speed prediction based on Legendre multi‐wavelet neural network
- Iteration dependent interval based open‐closed‐loop iterative learning control for time varying systems with vector relative degree
- Thermoelectric energy harvesting for internet of things devices using machine learning: A review
- An embedded vertical‐federated feature selection algorithm based on particle swarm optimisation
- An activated variable parameter gradient-based neural network for time-variant constrained quadratic programming and its applications