A structural developmental neural network with information saturation for continual unsupervised learning
2023-12-01ZhiyongDingHaibinXiePengLiXinXu
Zhiyong Ding | Haibin Xie | Peng Li | Xin Xu
College of Intelligence Science and Technology,National University of Defense Technology,Changsha,China
Abstract In this paper, we propose a structural developmental neural network to address the plasticity-stability dilemma, computational inefficiency, and lack of prior knowledge in continual unsupervised learning.This model uses competitive learning rules and dynamic neurons with information saturation to achieve parameter adjustment and adaptive structure development.Dynamic neurons adjust the information saturation after winning the competition and use this parameter to modulate the neuron parameter adjustment and the division timing.By dividing to generate new neurons,the network not only keeps sensitive to novel features but also can subdivide classes learnt repeatedly.The dynamic neurons with information saturation and division mechanism can simulate the long shortterm memory of the human brain, which enables the network to continually learn new samples while maintaining the previous learning results.The parent-child relationship between neurons arising from neuronal division enables the network to simulate the human cognitive process that gradually refines the perception of objects.By setting the clustering layer parameter, users can choose the desired degree of class subdivision.Experimental results on artificial and real-world datasets demonstrate that the proposed model is feasible for unsupervised learning tasks in instance increment and class increment scenarios and outperforms prior structural developmental neural networks.
K E Y W O R D S neural network, pattern classification, unsupervised learning
1 | INTRODUCTION
Human beings can continually learn in an open environment,that is, actively discover new knowledge and not forget the previous knowledge.Similarly, when an intelligent system operates in the real world, it is often exposed to the open environment [1–3] and requires the capability of continual learning[4],that is,to integrate new knowledge while retaining the experience learnt previously.Such ability is generally considered to be one of the attributes necessary for general artificial intelligence in the future [5, 6].However, current mainstream learning models usually rely on a complete training set available at once [7], which often leads to catastrophic forgetting[8,9]when new knowledge has to be learnt,as the new information overwrites previously learnt knowledge, making it difficult to sustain learning in a non-stationary environment.As a result,the issue of continual learning has attracted a great deal of renewed attention in recent years, and many continual learning approaches have been proposed [10–13].However,most of these techniques still focus on the problem of supervised learning, where each data is given a class label, which usually contradicts the nature of open environments where prior and external supervised information is often missing and a large amount of data is usually without class labels.In this study,we will focus on continual unsupervised learning that is more relevant to continual learning application scenarios.
Continual unsupervised learning aims to learn from a nonstationary stream of unlabelled data, where the distribution of data or the number of categories is presented gradually as the learning process continues, rather than being determined in advance.However,neural network models often face a stabilityplasticity dilemma [14, 15] in continual unsupervised learning,that is,it is difficult for a learning network to balance the plasticity of adapting to a rapidly changing environment and maintaining the stability of previously learnt knowledge when trying to adapt to a changing environment.To address this problem,some growing neural networks based on Hebbian competitive learning[16]have been proposed.The topology of such neural networks continues to develop autonomously with the input of data streams to adapt to the currently learnt data,which we call structural developmental neural networks,and they have proven to be an effective mitigation mechanism for stability-plasticity dilemmas[17–20].
Inspired by the way the ART network [14, 21, 22] incrementally adds neurons, some structural developmental neural networks based on the classic competitive neural network selforganising map (SOM) [23] and Neural Gas (NG) [24] have been proposed with the aim of solving the problem that the number of neurons(cluster number)must be predetermined in SOM and NG, which leads to the plastic-stability dilemma.Representative structural developmental neural networks include the Growing Neural Gas(GNG)network proposed by Fritzke [17], the Grow When Required (GWR) network proposed by Marsland et al.[18], and the self-organising incremental learning neural network (SOINN) proposed by Shen et al.[19].
At present, several approaches based on structural developmental networks have been proposed for application in different continual learning scenarios.For instance,GWR-based approaches have been proposed for incremental learning of body movement patterns [25–27]as well as in human subjectbased interactions [27]; the combination of pre-trained CNN and SOINN applied to continual target recognition scenarios[28].In addition,processing heterogeneous information within the homogeneous network component [29, 30] can also take advantage of network structure development such as the SOINN-based general associative memory system(GAM)[31].These extended algorithms introduce the incremental learning nature of structural developmental neural networks into classification algorithms, making the classifier applicable in open environments.
These structural developmental networks allow the network to dynamically develop by adding or deleting neurons and connections between neurons at the right time to adapt to the data flow in an open environment.They consist of a setNof neurons and a setEof connections between neurons.Each neuronni∈Nhas a central weightμi∈Rdand the central weight can be considered as the position of the neuron in the input space.The network structure is a self-organising competitive neural network, where neurons compete with each other when samplesx∈Rdare input,and the neuron with the smallest distance from the input sample wins.The network then enters the learning phase, which includes adjusting the central weights of the corresponding neurons, adjusting the connections between the corresponding neurons, and adding and removing neurons.The purpose of the central weight adjustment is to move the winning neuron and the neurons that have connections to it towards the input sample, and the amount of change in the central weight vector is calculated as
ɛ(i,t) is a constraint on the amount of change andtis the number of times a neuron wins or the number of times the network is updated.The calculation ofɛ(i,t) is different in different network models.ɛ(i,t)is constant in GNG,inversely proportional totin SOINN,and negatively exponential totin GWR.It can be seen that in SONNIS and GWR, the largertis, the smallerɛis, that is, the smaller the magnitude of neuronal update.Furthermore,a connection will be established between the winning neuron and the second-winning neuron,and the connection between neurons will gradually age with the increase in the number of input samples.When the age parameter increases to a preset threshold, the connection will be deleted.In terms of neuron addition and deletion, the network adds neurons according to the accumulated local error in a certain period(GNG,SOINN),or determines whether the winning neuron is representative of the current input according to a fixed (GWR) or adaptive (SOINN) similarity threshold and thus decides whether to add a new neuron.In addition,the network removes isolated neurons in due course.
These structural developmental neural networks effectively improve the plasticity and stability of neural networks through the mechanism of adaptive development of the network topology.However, there are still many gaps in the continual unsupervised learning in the open environment and the simulation of the human learning process.
• As the scale of structural developmental neural networks increases with the increase of input,the global computation in the network operation will become less and less efficient with the increase of the number of neurons.Therefore,it is very important to improve network parallelism and avoid global computing.
• The open environment demands the higher real-time performance of neural network models, and the training and testing phases may not be distinguished, which requires a seamless transition between the learning and use phases of the network model [32].The addition and deletion of neurons based on the connection age threshold and pre-set periodic parameters will lead to the oscillation of the number of neurons and the instability of classification results during the development of the network, which is not conducive to the real-time performance of the model.
• There are still many pre-set hyperparameters in the network,which is undoubtedly difficult in the open environment without prior knowledge.
• Learning in an open environment, neural networks should be able to perceive things with increasing refinement like the human learning process,that is,be able to subdivide known classes as more and more information is input.As shown in Figure 1.
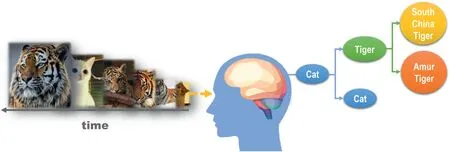
F I G U R E 1 The more samples the human brain learns, the more finely it cognises things.
In this study, we propose a Structural Developmental Neural Network with Information Saturation (SDNNIS),whose topology can develop adaptively to accommodate continual unsupervised learning of non-stationary data streams.Network development is motivated by the need to learn novel features or to subdivide when repeatedly learning samples of the same class.We unify this motivation into one mechanism,namely, information saturation, which reflects the degree of neuronal activation and controls the parameter adjustment and division timing of neurons.The introduction of information saturation enables the network to simulate the long short-term memory of the human brain, effectively overcoming the plasticity-stability dilemma.The neuron division mechanism based on information saturation allows the network to remain sensitive to novel features and to subdivide classes that are learnt repeatedly.The proposed information saturation allows the number of hyperparameters of the network to be streamlined to one,avoiding the reliance on prior information.In addition,we propose an original neuron and a covering domain matching mechanism in enhancing network parallelism,thus limiting the operations to local neurons without considering the global situation of the network and improving the network operation efficiency.Finally, we introduce a clustering layer parameter,allowing the user to select the desired level of category subdivision.In the algorithm validation,we use artificial datasets and real-world datasets to verify the effectiveness of the proposed method and compare the performance with several representative structural developmental neural networks.The results show that SDNNIS can adaptively develop with the input of samples, effectively adapts to continual unsupervised learning tasks,and has excellent plasticity and stability.
2 | PRELIMINARY
2.1 | Biological insights of information saturation
When humans learn continually in a changing environment,they are able to learn new knowledge more effectively based on old knowledge and learn new knowledge without forgetting previous knowledge.Complementary learning systems(CLS)theory[33]defines the complementary roles of the hippocampus and neocortex in learning and memory,suggesting the existence of specialised mechanisms in the human cognitive system that protect the consolidation of knowledge.The hippocampal system is responsible for short-term adaptation, allowing rapid learning of new information that will be transferred and integrated into the neocortical system for long-term storage.Daniel et al.mentioned in Ref.[34]that in the hippocampal region of the mammalian brain, new functional neurons are continually generated by neuronal stem cells and embedded in existing neural networks.When people are constantly exposed to the same type of object,the memory neurons associated with it are continually activated,and the memory about that type of object is continually enhanced.
Additionally,in the human cognitive process,as we receive richer and richer information, our knowledge of things will become more and more accurate.When the number of samples corresponding to the learnt class is rich to a certain degree,it is natural to subdivide this class.For example, at the macro level,domestic cats and tigers have many similar characteristics,both belong to the feline family and can be classified into one class.When we know more and more tigers, the one animal,the tiger can then be subdivided into subspecies classes such as the Northeast tiger, Siberian tiger, and South China tiger, ss shown in Figure 1.
Inspired by the above biological neural mechanisms and human cognitive processes, we added the information saturation property to the neurons in SDNNIS, which reflects the amount of information carried by the neurons and controls the update magnitude of neurons and whether they divide or not.The adjustment of neuron parameters tends to stabilise as the information saturation continues to increase.Once the information saturation reaches the saturation threshold,the neuron divides to generate a new neuron.SDNNIS maintains sensitivity to new features by original neuron division and subdivision of repeated learning classes by generated neuron division,and it is the neuron division caused by the winning neuron information saturation reaching the saturation threshold that unifies these two mechanisms into one mechanism.In the following section,the composition of SDNNIS and the developmental process will be described in detail.
3 | STRUCTURAL DEVELOPMENT NEURAL NETWORK WITH INFORMATION SATURATION
SDNNIS is a network consisting of the input layer and the competitive layer (output layer).The overall structure of SDNNIS is shown in Figure 2.The number of neurons in the input layer is equal to the dimension of the sample features in the input space, and the role of the neurons in this layer is to transfer the sample features.After receiving the sample features incoming from the input layer,the competition layer first performs the neuron covering domain detection, that is, only the local neurons covering the input sample respond.Then it enters the competitive learning phase, that is, the responding neurons compete with each other, and the neuron with the largest response value is activated,and the winning neuron gets the opportunity to update the information saturation.If the information saturation does not reach the saturation threshold,then the neuron performs the adjustment of the central weight vector and the output of the network is the index of the winning neuron; if the saturation threshold is reached, then the neuron divides to generate a new neuron and the output of the network is the index of the new neuron.Finally,the current input sample is labelled according to the output of the network, the layer where the corresponding neuron is located in the clustering tree and the clustering layer parameter set by the user.The complete algorithm flow diagram is shown in Figure 3.
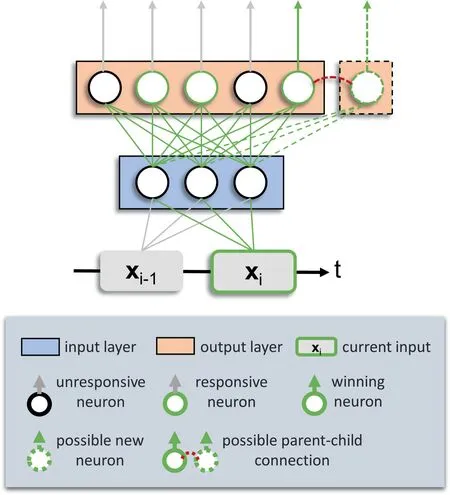
F I G U R E 2 Structure of SDNNIS.
Next, we will further introduce the elements of individual neurons in SDNNIS,the structural developmental competitive learning rule, and how to use the output information for clustering.Before going into more detail about SDNNIS, we define the symbols we need to use in Table 1.
3.1 | Properties of a single neuron
Each neuron in the competitive layer of SDNNIS represents a clustering centre in the input space, and they only respond to input samples within a certain neighbourhood.The neuron with the largest response value is activated, and its output represents the classification of the input samples.In particular,we introduce an information saturation for neurons, which reflects the amount of information they carry.The more the neuron is activated,the greater the information saturation and the more stable the neuron is.When the amount of information carried is saturated, the neuron divides to generate new neurons.In addition, each neuron needs to record its parent index in order to construct a parent-child relationship tree to realise the selection of category subdivision degree in the subsequent clustering process.
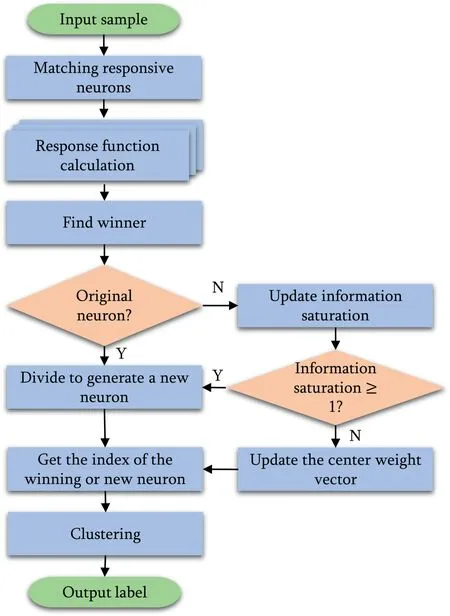
F I G U R E 3 SDNNIS algorithm flow

T A B L E 1 Notation used in SDNNIS algorithm

3.2 | Structural developmental competitive learning rule
The network model of SDNNIS is a self-organising competitive neural network, which learns the input data streams and classifies them in a structured developmental competitive learning manner based on information saturation.
3.2.1 | Matching and competition
It can be seen that the centre and standard deviatio.n of this Gaussian-type response function are the centre weight vector and the covering domain parameter of the neurons respectively.The neuron with the largest response value is activated, and the indexkof the winning neuron is obtained,which is calculated as
It is crucial to note that in open environments, intelligent systems usually encounter unseen samples, that is, the input samples may not fall in the covering domain of any neuron in the current neural network.To ensure the sensitivity to novel features and the parallelism of the network, we set up an original neuron, analogous to the presence of stem cells in a living organism, from which the competitive layer starts to develop.The central weight vector of the original neuron is the origin of the sample space,and the covering domain parameter is positive infinity, which ensures the ability to respond to the input samples in the whole sample space,and the information saturation is one,in a saturated state,which ensures that when only the original neuron responds (novel features appear), it instantly divides to generate a new neuron to represent the new features.Thus, the quaternion form of the original neuron is represented asn0={0,∞,1,-1}, which remains constant throughout the network development.Furthermore, the setting of the original neuron unifies the discovery of new features and the subdivision of categories into the neuron division mechanism, which makes the network model more concise and consolidates the parallelism of the network by avoiding the global operations of the network.
3.2.2 | Updating and division
The winning neuron is activated and then enters the learning phase, that is, adjusts the centre weight vector or divides to generate a new neuron.The adjustment or division depends on whether the information saturation reaches a saturation threshold(value of 1)after the update.The amount of change in information saturation of the winning neuronnkabout the inputxiis denoted as Δsk,i, whose amount depends on the similarity denoted asok,ibetweenxiandnk,which is calculated using a Gaussian radial basis function
The amount of change in information saturation is calculated as
whereais the constraint coefficient taking the value of 1-R,andRis the information saturation reset threshold,that is,the fallback value of information saturation after neuron division,which will be introduced later when describing neuron division.The similarity curve and the corresponding curve of the amount of change in information saturation are shown in Figure 4.
It can be seen that the input sample closer to the neuron's centre weight vector is less “informative”, while the input sample further away from the neuron's centre weight vector introduces more discrepant information, resulting in a greater amount of change in information saturation, prompting the neuron to divide or create new neurons to represent potential new classes.The information saturationskis then updated tos′k=sk+Δsk,i.

F I G U R E 4 The curve of the similarity between the input sample and the neuron and the corresponding curve of the amount of change ininformation saturation.In this example the neuron's weight vector μ = 0,the covering domain parameter σ = 1, and a = 0.2.
If the information saturation does not reach the saturation threshold, the network output is the index of the winning neuron, and the winning neuron will update the centre weight vector so that it moves towards the input sample.The centre weight vector is updated in the following way:
μ′kdenotes the updated centre weight vector.It is easy to see thatμkcorresponds to a weighted average of the input samples that cause the neuronnkto win,which approximates the estimation of the expectation of the local information represented by the neuronnkusing the sample mean,recording the local first-order moment information.The difference is that the ratio of the variation in information saturation to the current information saturation is introduced as a weight instead of the average weight so that inputs with different distances from the neuron's centre weight vector contribute differently to the internal properties of that neuron.As the information saturation grows,the learning rate coefficientin Equation(6)gradually decreases,and the constraint on the adjustment magnitude of neurons gradually becomes larger, prompting the neurons to stabilise, which simulates the transition from short-term to long-term memory in the human brain.In summary, during the competitive learning process,the centre weight vector of each neuron in the competitive layer will gradually adjust to the clustering centre of the input sample space and tend to stabilise.
If the information saturation reaches the saturation threshold, which means that the neuron carries a sufficiently abundant amount of information, the neuron will divide to generate a new neuron and the network output is the index of the new neuron.The generation of new neurons reflects that the network has learnt a new class (generated by the original neuron division)or has subdivided the existing class(generated by the non-original neuron division).The new neuron takes the input sample that triggered the division of the winning neuron as the centre weight vector,and its covering domain parameter is one-third of the distance between the centre weight vector of this neuron and that of its parent, that is, the parent's centre weight vector is located at a boundary of 3σfrom the new neuron, in order to allow the new neuron to better represent the emerging cluster of samples while inheriting the information of the samples already learnt by the parent.The information saturation of the new neuron is initialised as the upper exact boundary of the amount of change in information saturation, and the parent index is the index of the winning neuron so that the new neuron is initialised as
Meanwhile, the centre weight vector of the parent neuron is kept unchanged.To prevent frequent division of the winning neuron,the information saturation of the parent after division information saturation of the parent neuron falls back directly to the reset thresholdR.
The structural developmental competitive learning mechanism with the introduction of information saturation brings four benefits: first, it effectively simulates the long short-term memory of the human brain and improves the stability of the neural network model;second,it endows the network with the ability to discover new classes and to subdivide classes that occur more frequently, increasing the plasticity of the model; third,compared to adding neurons near the neuron with the largest cumulative local error involving global computation, the division mechanism based on information saturation is the behaviour of a single neuron, consolidating the parallelism of SDNNIS operation and improving the computational efficiency;fourth,it makes SDNNIS generate new neurons when needed, instead of relying on the periodic parameter that requires certain prior knowledge, improving the real-time performance of the model.The structural developmental competitive learning algorithm of SDNNIS is shown in Algorithm 1.

Algorithm 1 : Pseudo code of SDNNIS.?
3.3 | Clustering
After SDNNIS executes competitive learning on the input sample, it outputs the index of the neuron corresponding to that input sample, that is, the index of the winning neuron or the newly generated neuron.Subsequently, the incremental clustering of the new sample is completed by attaching the class labels to the input sample based on the output index of the network and the user-given clustering layer parameter.
The clustering method based on SDNNIS incorporates both prototype-based and hierarchical clustering.In detail,the centre weight vector of each neuron can be used as a prototype in clustering, and importantly, the number of prototypes does not need to be specified in advance but is dynamically adjusted according to the input samples.The parent-child relationship formed by the division of neurons establishes a tree hierarchy,where the child neurons subdivide the classes represented by the parent neurons, and the user can set the clustering layer parameter, denoted asCL, according to the desired degree of class subdivision.
Specifically,as shown in Figure 5,the original neuron is the root node of the clustering tree, which is at layer zero.The child neurons of the original neuron form layer one of the clustering tree, and so on for the other neurons.The layer wherenjis located is denoted aslrj.Assuming that the clustering layer parameter set by the user is two, the neurons located in layers less than two are each a clustering centre with a unique class label, such as its index.The class label of the neurons located in layers greater than two is directly inherited from the parent neuron.Therefore, neurons in layers greater than the clustering layer parameter under the same parent have the same class labels and are clustered into the same class.Finally, the input sample is labelled with the same label as the corresponding neuron to complete the incremental clustering.The pseudo-code of the clustering process for the current input sample is shown in Algorithm 2.

Algorithm 2 Clustering?

F I G U R E 5 Example of the class label of neurons in the output layer.The number on the neuron indicates the parent index of the neuron.The classes are distinguished by colour,and neurons with the same colour have the same class label.Neurons form a tree structure based on the parentchild relationships and the original neuron is at layer zero.The clustering layer set in this example is two.
3.4 | Analysis of time complexity and computational efficiency
SDNNIS is optimised in terms of both time complexity and computational efficiency compared to prior structural developmental neural networks.In Algorithm 1,when a new sample is input, the model first enters the matching and competition phase, during which the neurons calculate the distance to the input sample, and the neurons that respond calculate the response function value,so the time complexity of this phase is linearly related to the number of neurons in the competition layer, so the time complexity isO(|Ni-1|).The subsequent updating or division of the winning neuron is the behaviour of a single neuron, independent of the number of neurons, so it does not affect the time complexity of the model.In Algorithm 2, the clustering of new samples only involves the calculation of the layer of the winning neuron or the new neuron in the clustering tree, so it does not affect the time complexity of the model.Therefore, the time complexity of SDNNIS for learning and clustering each sample isO(|Ni-1|).
As for the time complexity of prior structural developmental neural networks,the learning of a new input sample by GNG, GWR, and SOINN includes the competition of neurons in the output layer and the adjustment of the age parameter or removal of the connecting edges between neurons, so that the time complexity is linearly related to the number of neurons and the number of connecting edges, so the time complexity isO(|Ni-1|+|Ei-1|).
In terms of computational efficiency, SDNNIS is much more efficient than other structural developmental neural networks because it avoids a large number of global computations, and its learning and clustering processes are more compact.Specifically,only the matching phase in the operation of SDNNIS requires global operations, and the operations in the remaining steps are limited to single or local neurons.In contrast, the steps that require global operations during the operation of GNG, GWR, and SOINN are the competitive learning phase, neuron connected edge removal, finding the maximum local error to add neurons, and clustering.Besides,SOINN's operation of calculating the similarity threshold of the winning neuron when deciding whether to add a new neuron may also perform a global operation.In addition,compared with other structural developmental neural networks, the learning process of SDNNIS does not involve the increase or decrease of the connection edges,and the addition of new neurons where the local error is the largest, and the clustering process of SDNNIS does not require all neurons to re-cluster, so the overall operation process of SDNNIS is simpler.
For these reasons, the computational efficiency of SDNNIS is greatly improved from the point of view of time complexity and the running process.The following experimental section verifies that SDNNIS uses less time while ensuring a higher accuracy rate on the same amount of input data.
4 | EXPERIMENT
In this section, we test the developmental process and the subdivision capability of the network to verify the effectiveness of the structural developmental competitive learning rule with the introduction of information saturation.The effect of the hyperparameter on the structural development as well as the performance of SDNNIS is discussed to give a reference for the selection of the hyperparameter.The incremental clustering performance of SDNNIS is validated on artificial datasets and compared with typical structural developmental neural networks GNG, GWR, and SOINN.Finally, the effectiveness of SDNNIS on continual unsupervised learning is further validated on a real-world dataset.The results show that SDNNIS can develop adaptively with sample input,effectively adapts to continual unsupervised learning tasks, and has excellent plasticity and stability.
4.1 | Experimental settings
4.1.1 | Datasets and learning scenarios
In this study, we use artificial datasets as well as real-world datasets to validate SDNNIS.Due to the visibility of twodimensional data and the fact that the normal distribution is the most common distribution in nature,we construct artificial datasets that are two-dimensional normally distributed datasets with different distribution characteristics (see Table 2).The real-world dataset is obtained from the coil-100 [35].Learning scenarios are classified into instance incremental and class incremental according to the sample input method.In the instance incremental learning scenario,the order of appearance of samples of different classes is random, while in the class incremental learning scenario,samples are input in the order ofclasses, that is, all samples of one class are input before inputting the next class.The above dataset and learning scenario settings can verify the effectiveness of the algorithm in a more comprehensive way for different feature datasets and different continual learning scenarios.

T A B L E 2 List of artificial datasets
4.1.2 | The evaluation indicators
We choose the commonly used external and internal evaluation indexes of clustering, ACC [36], and DBI [37] to judge the performance of clustering.
• Accuracy (ACC): ACC represents the proportion of the correct number of clustering,and the calculation formula is
wherelpiandltirepresent the predicted label and the real label respectively,nis the total number of data,map() is the Hungarian algorithm function to achieve the best allocation of labels.ACC ranges from zero to one.A larger ACC value indicates a higher proportion of correct clustering results.
• Davies–Bouldin Index (DBI): For the cluster divisionC={C1,C2,…,Ck}, DBI is defined as

4.1.3 | Comparison networks
We used GNG,GWR,and SOINN,which are currently typical and commonly used structural developmental neural networks,for comparative validation.All three networks involve hyperparameters:agemax,which is the age threshold of the connection edge,andλ,which is the periodic parameter for increasing and decreasing neurons in GNG and SOINN.In the next comparison experiments,these two hyperparameters are uniformly set toagemax=5 andλ=30,which are the optimal values chosen through multiple experiments.The other hyperparameters of the comparison network are the same as the original paper.
4.2 | Network development process
SDNNIS incorporates information saturation as well as an original neuron mechanism for generating new neurons to represent novel features that have not been seen,or to subdivide classes that have been learnt over and over again,and therefore can adapt to open environments through structural development.We tested SDNNIS and three other structural developmental neural networks,GNG,GWR,and SONNIS on DS1 for the variation in the number of neurons and the variation in the number of identified clusters under two continual learning scenarios:instance incremental and class incremental.
As shown in Figure 6a,b, the number of neurons of the structural developmental neural networks all vary with the increase of the number of input samples in both instance incremental and class incremental learning scenarios.In the instance incremental scenario, the number of neurons of SDNNIS grows fast and can quickly identify all current classes and subdivide the classes in further sample inputs, but the disadvantage is that the constant division of neurons leads to difficulty in controlling the size of the network.When GWR develops to a certain extent, the number of neurons can stabilise, while the number of neurons in SOINN fluctuates greatly and in GNG increases in a periodic manner.In the class incremental scenario, the change curves of the number of neurons in SDNNIS, GWR, and SOINN show a step-like pattern, indicating that new neurons can be rapidly generated to represent new classes when new classes appear,but SOINN fluctuates greatly,while GNG still increases neurons according to the cycle and cannot discover new classes quickly.
The number of neurons and connections between neurons affect the clustering result.As shown in Figure 6c,d, in the instance incremental scenario, our SDNNIS can quickly identify the clusters existing in the environment and remain stable,while other networks have problems such as the number of clusters recognised fluctuates greatly during development and cannot distinguish clusters quickly and effectively.In the class incremental scenario, SDNNIS can quickly identify new clusters when they appear and keep the number of identified clusters stable, while GNG could not identify new clusters in time, and GWR and SOINN had a large fluctuation in the number of identified clusters.
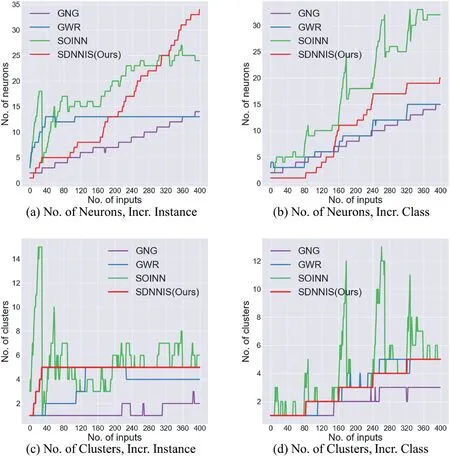
F I G U R E 6 Curves of the number of neurons and the number of recognised clusters of networks during the development under instance incremental and class incremental learning scenarios.
Based on the above analysis, it can be seen that the neuronal division mechanism based on information saturation of SDNNIS can effectively improve plasticity and enable the network to timely discover new classes in the environment.Meanwhile, information saturation and the father-child relationship between neurons maintain the learning results of old samples and improve the stability of the network.
4.3 | Subdivision of classes and selection of subdivision degree
The division property of neurons enables SDNNIS to subdivide classes.In addition, the subdivision level of clustering results can be determined by adjusting the clustering layer parameterCLto meet the different levels of class subdivision required by users in practical applications.We verify the subdivision ability of SDNNIS on DS5.The test dataset is composed of five clusters subject to the normal distribution,and some clusters overlap with each other.The clusters that overlap with each other can be regarded together as one large cluster, so the dataset can be regarded as two large clusters,and the two large clusters are respectively composed of two and three subclusters.The learning mode is instance increment.In the early stage of learning,when the number of input samples is small, the number of generated neurons is small,and the classification is coarse;SDNNIS is able to identify the wide classes present in the environment.As shown in Figure 7a,b,when the number of samples is only 10,SDNNIS considers them as one class, and when the number of learnt samples grows to 30, it is already able to identify two wide classes.As the number of learnt samples increases,neurons in SDNNIS will divide to generate new neurons when their information saturation reaches the saturation threshold, leading to a subdivision of the existing classes, and the newly generated neurons can represent more fine-grained classes, simulating the human cognitive process.As shown in Figure 7c–e,SDNNIS gradually identifies subclasses in two wide classes as the number of learnt samples increases.It is noteworthy that since the clustering layer parameterCLis set to three, the number of classes remains constant even though the neurons continue to grow during the subsequent sample increase (see Figure 7f).

F I G U R E 7 Example of class subdivision by SDNNIS.The dot represents the input sample, the star represents the neuron centre vector, and the circle represents the neuron covering the domain boundary.As the number of learning samples increases, neurons in SDNNIS will divide to generate new neurons when their information saturation reaches the saturation threshold, leading to a subdivision of the original class, simulating the cognitive process of humanbeings.
The selection of the subdivision degree depends on the user-set clustering layer parameterCL.Figure 8 shows the clustering results whenCLis taken as one, two, and three for the dataset DS4.WhenCL= 1, the clustering result is one class;whenCL=2,the clustering result is 3 classes(including the parent class); whenCL= 3, the clustering result become more subdivided.It can be seen intuitively that the larger the number of clustering layers is,the finer clustering results can be obtained.The specific number of clustering layers can be set according to actual needs.In addition,it can be seen from the figure that SDNNIS can well reflect the classes of learning samples at different levels of subdivision, which conforms to the intuitive feeling of the human brain.
4.4 | Analysis of the hyperparameter
SDNNIS has only one hyperparameter, the information saturation reset thresholdR, which is significantly streamlined compared with the previously proposed structural developmental neural networks(six,five,and 10 for GNG,GWR,and SOINN, respectively), reducing the reliance on a priori information and the trial-and-error process and effectively improving the adaptability of the algorithm in open environments.
Rdefines the fallback value of information saturation after neuron division and constrains the magnitude of the change in information saturation.Theoretically,Raffects the speed of information saturation growth, the frequency of neuron division, and the stability of neurons after division.WhenRis relatively large, the information saturation of the divided neurons is still at a high level, which can keep the neurons stable and at the same time make it easier to divide and generate new neurons.On the other hand, the calculation of the amount of change in information saturation (see Equation 5)sets the constraint coefficientaso that the information saturation grows more slowly whenRis large becauseais negatively correlated withRand thus Δsk,iis negatively correlated withR, which inhibits the division of neurons to some extent.The above mechanisms form a mutually constraining relationship in favour of reducing the sensitivity of the model toR.In the following,we will test the effect ofRon the network size and clustering results.
We test on DS1 the number of neurons generated by SDNNIS and the DBI values of the clustering results whenRtakes different values, which can reflect the effect ofRon SDNNIS to some extent.According to the implication of the information saturation reset threshold, neurons with information saturation at the reset threshold should be in a relatively stable state, so we test the effect ofR∈[0.50, 0.95](interval taken as 0.02) on the number of SDNNIS neurons and the DBI values of clustering results under two learning scenarios:instance incremental and class incremental.Since SDNNIS is sensitive to sample input order, each test conducts 30 times according to different sample input orders,and the final result is the average of 30 test results.
As shown in Figure 9a it reflects the effect of the reset threshold on the number of neurons generated by the network.In two different learning scenarios, the number of neurons decreases as the reset threshold increases, reflecting that the constraining effect of the reset threshold on the growth of information saturation dominates, that is, the larger R is, the more slowly the information saturation grows and the harder it is for the neurons to divide.Figure 9b reflects the effect of the reset threshold on the clustering results, where in the instance incremental scenario the DBI tends to decrease with the increase of the reset threshold, while in the class incremental scenario whenR∈[0.65, 0.80] the DBI is at a relatively low level, which means better clustering results.

F I G U R E 9 Effect of the information saturation reset threshold on the number of generated neurons (a) and clustering performance (b) of SDNNIS under instance incremental and class incremental learning scenarios.

F I G U R E 8 The clustering layer determines the degree of subdivision of the clustering results.(a),(b)and(c)show the clustering results when the clustering layer CL is 1, 2, and 3 respectively.The dot represents the input sample, the star represents the neuron centre vector, and the circle represents the neuroncovering the domain boundary(for convenient observation,only the covering radius boundary of mature neurons whose layer is smaller than the cluster layer is shown).Colours are used to represent classes,and the same colour has the same class label.The larger the number of clustering layers is,the greater the degree of subdivision of SDNNIS learning samples is and the finer the cognition of things is.
Therefore,a larger reset threshold can improve the stability of divided neurons and reduce the number of neurons to improve the operating efficiency of the network;however,too large a reset threshold is not conducive to the plasticity of the network and thus affects the clustering results.Considering the operation efficiency, plasticity-stability, and clustering performance of the network, we set the hyperparameterRto 0.8,which can maintain a good DBI level and keep the number of neurons low.It is important to note that the hyperparameter is inherent to SDNNIS and do not require different parameter settings for different datasets and tasks.
4.5 | Continual unsupervised learning on artificial datasets
SDNNIS adopts competitive learning to adaptively adjust the centre weight vectors of neurons in the competitive layer so that the corresponding weight vectors of each neuron are gradually adjusted to the cluster centres of the input sample space to represent the convex clusters.More importantly,SDNNIS is able to adapt to continual unsupervised learning problems in open environments by performing structure development motivated by the discovery of novel features and the subdivision of recurring classes.In the following, we validate the clustering performance of SDNNIS on artificial datasets under instance incremental and class incremental continual learning scenarios and compare it with typical structural developmental neural networks GNG, GWR, and SOINN.
To validate the clustering performance of SDNNIS, we constructed four artificial datasets DS1, DS2, DS3, and DS4 with different distribution characteristics(see Table 2),and the sample input method differs for each dataset.DS1 contains five clusters, each with the same number of samples and variance,and the sample input method is class increment;DS2 contains five clusters with the same distribution as DS1, but the sample size of each cluster is one-quarter of that of DS1,and the sample input method is instance increment; DS3 contains four clusters,each with the same number of samples,but with different variance (0.01,0.02,0.03,0.05), and the sample input method is instance increment; DS4 contains four clusters, each cluster has the same variance but the different number of samples (25, 50, 100,200), and the sample input method is instance increment.The clustering effect on different datasets is shown in Figure 10 with the clustering layer parameterCL= 2.
As shown in Figure 10, SDNNIS achieves clustering results that are compatible with reality on datasets with either even or uneven density among clusters and under different continual learning scenarios.The generated neurons can fit the distribution of samples well, which verifies that the adaptive adjustment of neurons can enable the network to discover the distribution of different clusters effectively.In particular,it can be seen from Figure 10b,c that the number of neurons is higher in regions with a larger number of samples as well as a larger sample variance,which is in line with one of the original purposes of the design of SDNNIS, that is, to match the neurons to the sample size.
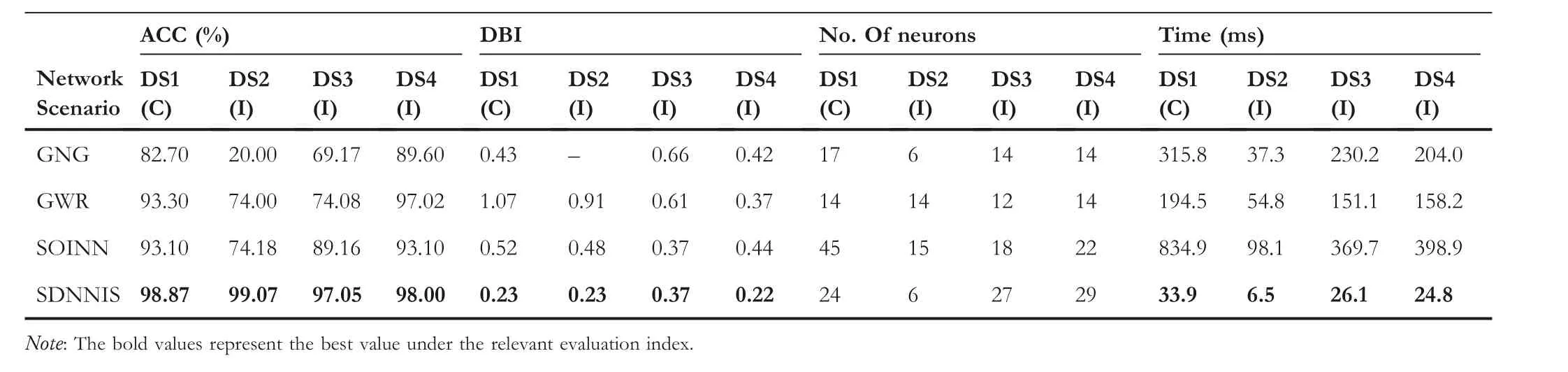
We evaluated the clustering results of different structural developmental neural networks on DS1, DS2, DS3, and DS4 using the external metric ACC and the internal metric DBI,and recorded the final number of neurons and the network running time to evaluate the network computational efficiency.Considering the developmental characteristics of the networks,we intercepted the sample labels that are in the last 20%of the input order for clustering results evaluation.Since the structural developmental neural networks are sensitive to the sample input order, 30 experiments are conducted with different sample input orders for each set, and the final results are averaged.The experimental results are shown in Table 3.From the experimental data, it can be seen that our proposed SDNNIS achieves the best clustering results and the highest computational efficiency in different datasets and different continual learning scenarios.
The DBI value of GNG's clustering result of DS2 in Table 3 is a short horizontal bar, indicating that it cannot be calculated.The reason is that GNG cannot timely delete the connections between neurons representing different categories when the input sample size is small, resulting in only one cluster in the clustering result, but the calculation of DBI requires the number of clusters to be greater than or equal to two.

F I G U R E 1 0 Clustering results of SDNNIS on artificial datasets with different distribution characteristics.The dots indicate the input samples, the stars indicate the neuron centre weight vectors, and the colours are used to indicate the class labels.
Notably, the excellent continual unsupervised learning performance of SDNNIS on these datasets is not due to generating a larger number of neurons.According to the experimental results, the growth curves of the number of neurons in each network in Figure 6a and the clustering results of DS3 and DS4 in Table 3 show that the number of neurons generated by SDNNIS is indeed more than that of other structural developmental neural networks when the number of input samples is large.However,the clustering results on DS2(the sample size is one-quarter of that of DS1, and the distribution is the same as DS1)show that SDNNIS generates the smallest number of neurons (only six neurons) but achieves a high accuracy(99.07%)in this small sample case.If the number of input samples continues to increase,the number of neurons in SDNNIS will increase rapidly (see Figure 6a), but the clustering result will not change greatly (see Figure 6c for the stable clustering cluster number curve of SDNNIS).Therefore,it can be seen that the higher clustering accuracy achieved by SDNNIS is not at the cost of increasing network complexity.In fact, the reason for the rapid growth of the number of neurons in SDNNIS is that the repeated occurrence of samples of the same class easily leads to the frequent division of neurons when the number of samples is large.If there are subdivided classes in the datasets, these generated neurons can effectively represent the subdivided classes and thus improve the clustering accuracy.However, there is no subdivision class in the datasets of this experiment, so these frequently divided neurons have little impact on the accuracy, only causing redundancy in the number of neurons.
In principle,the high accuracy achieved by SDNNIS is the result of better plasticity and stability.The plasticity of SDNNIS benefits from the neuron division mechanism,which enables SDNNIS to generate new neurons and represent new categories in time when encountering novel samples and thus effectively divide samples even when the number of samples is small.As for the prior structural developmental neural networks,since the edges connecting neurons can only be deleted when the “age” of edges reaches a specified threshold, it is often hard to divide the classes in time after the emergence of a new class or when the number of samples is small.The stability of SDNNIS is due to the learning rules modulated by information saturation and the clustering method controlled by the clustering layer parameter,which enables SDNNIS to maintain the stability of precious learning outcomes and cluster number.In contrast, for other networks, the operation of adding or deleting neuronal connection edges during the development process tends to cause adhesion of neurons of different classes or the isolation of neurons of the same class, resulting in instability in the number of clusters, which then reduces the average accuracy.Therefore, it is better plasticity and stability that improves the performance of SDNNIS for continual unsupervised learning tasks.
4.6 | Continual unsupervised learning on real‐world dataset
In this experiment,we test the continual unsupervised learning performance of our proposed SDNNIS on real-world objects and compare it with GNG,GWR,and SOINN.The images of real-world objects are from the coil-100 dataset [35].The dataset contains images of 100 objects.The objects have a wide variety of complex geometric and reflectance characteristics.The objects are placed on a motorised turntable against a black background.The turntable is rotated through 360° to vary object pose with respect to a fixed colour camera.We selected five geometric objects in the coil-100 dataset(see Figure 11),each with 10 images from different angles.

F I G U R E 1 1 Grayscale images of 5 selected geometric objects.
T A B L E 3 Comparison of the clustering result evaluation, final number of neurons, and running time of structural developmental neural networks on artificial datasets with different distributional characteristics and under different continual learning scenarios

T A B L E 4 Comparison of the clustering result evaluation,final network size and running time of structural developmental neural networks on real-world datasets with different sample size and under different continual learning scenarios
The experimental dataset is divided into two sets, and the difference between the two sets is the different number of training set samples for the learning stage.The number of samples corresponding to each object in the training set of Set I is 10, and the number of samples corresponding to each object in the training set of Set II is 60.The purpose of setting up two sets in this way is to test the clustering performance of the networks under different data quantities and the subdivision function of SDNNIS.In the learning stage, different Gaussian noises are added to the images of five objects to obtain the training set.The PCA method is used to extract the features of the images, and the obtained feature vectors are input into networks in both instance incremental and class incremental ways to simulate different continual learning scenarios in the open environment.In the test stage, the feature vectors of the original grayscale images are input into the network.In the comparison experiment, SDNNIS’ clustering layer parameterCL= 1, and GNG's period parameterλ= 5.Other hyperparameters are the same as those in the experiment on artificial datasets.ACC is used to evaluate the clustering results,and the final number of neurons generated by networks and the running times are recorded to test the performance of the network.Because the structural developmental neural networks are sensitive to the sample input order, 30 experiments are performed with different sample input orders for each set of data, and the final results are averaged.The experimental results are shown in Table 4.
The experimental results show that SDNNIS achieves 100%accuracy in clustering results on images of five physical objects at different input sample sizes and in both instances incremental and class incremental continual learning scenarios and uses the smallest network size and the least network running time.The excellent performance achieved by SDNNIS is due to the better plasticity and stability of the network during development, as well as the simpler learning and clustering process.As for the other three structural developmental neural networks,when the number of input samples is small (Set I), the networks fail to match with the actual sample distribution in time, resulting in low accuracy.After the number of input samples increased(Set II), the clustering accuracy of GNG and GWR improve,but it is still not high.However,due to the large fluctuation of the number of clusters in SOINN, the clustering results are unstable,so the average clustering accuracy even decreases.

F I G U R E 1 3 The clustering results of SDNNIS (CL = 2) on Set II under the class increment learning scenario.It shows that SDNNISsubdivides the classes after the number of input samples is increased.The same colour indicates the same label.
In order to illustrate that the more samples feed into SDNNIS the more finely it cognises things, that is, the class subdivision function of SDNNIS as the number of input samples grows, we set different clustering layer parameters of SDNNIS for Set I and Set II datasets to observe the clustering results of SDNNIS on different number of input samples at different subdivision degrees.The datasets used in this experiment can be divided into different physical object classes, and each physical object class can also be divided into subdivision classes of “frontal”, “left-skewed” and “rightskewed”.On Set I, whenCL= 1 andCL= 2, the clustering results are the same, as shown in Figure 12.These results illustrate that SDNNIS can effectively distinguish each physical object when the number of input samples is small, but it has not yet subdivided the physical object class.The sample size of Set II increases by a factor of five compared to Set I.WhenCL= 1, the clustering results are still as shown in Figure 12,indicating that the clustering results at the classification level of the physical object remain stable.WhenCL=2,the clustering result is shown in Figure 13.The results show that at a finer classification level,the samples in Class A,are subdivided into“left-skewed” and “right-skewed” subclasses, and the samples in Class B and C are subdivided into “frontal”, “left-skewed”and “right-skewed” subclasses.Class D has a tendency to be subdivided,while Class E samples fail to be subdivided due to little difference in pictures with different deflection angles.The clustering results of SDNNIS on both Set I and Set II illustrate that SDNNIS is capable of subdividing classes as the number of input samples of the same class grows.In addition, by setting different values ofCL, users can select the desired degree of class subdivision.
Unlike the mainstream supervised learning-based image classification methods that require a large number of samples to train the network to obtain a better classifier, SDNNIS is able to quickly identify new classes with a small number of samples present in the environment and classify the samples efficiently when sufficient training samples are not available and when no prior knowledge about the task is available.The clustering results on real-world object images further demonstrate that SDNNIS can be adapted to clustering tasks in different continual learning scenarios.
5 | CONCLUSION
In this paper,we propose a new structural developmental neural network for continual unsupervised learning.The network employs dynamic neurons with information saturation and competitive learning rules to achieve adaptive structure development and parameter adjustment so that the network can adapt to the continual unsupervised learning tasks of instance increment and class increment.Specifically, the network continually adjusts the information saturation of the winning dynamic neuron according to the real-time dynamic data and uses this parameter to regulate the adjustment of the centre weight vector and the division time of the neuron.By generating new neurons through division,the network is sensitive to novel features and has the ability to subdivide repeatedly learnt classes.Information saturation and division mechanism enable dynamic neurons to simulate the long short-term memory of the human brain, maintaining both the plasticity and stability of the network model, so that the network can keep learning new samples while maintaining the previous learning results.The parent-child relationship among neurons generated by the division enables SDNNIS to simulate the human cognitive process of gradually refined cognition of things.The setting of the clustering layer parameter allows the user to choose the required degree of class subdivision.Experimental results on artificial and real-world datasets demonstrate the effectiveness of SDNNIS on continual unsupervised learning tasks in instance incremental and class incremental scenarios, and the performance of SDNNIS is better than that of prior structural developmental neural networks.Overall,this paper proposes an innovative neural network to address the plasticity-stability dilemma, computational inefficiency, and lack of prior knowledge in continual unsupervised learning.
However, SDNNIS still has some shortcomings in continual unsupervised learning tasks, such as the unrestricted growth of neurons leads to ineffective control of network size especially when the samples of the same class appear frequently,the corresponding neurons tend to split uncontrollably; the radius of the neuron covering the domain is not adaptively adjusted,which easily leads to the confusion of classification.In future work,we will study the inhibition mechanism of neuron division and the adaptive adjustment mechanism of covering the domain radius to improve SDNNIS.
ACKNOWLEDGMENTS
The work is supported by the National Natural Science Foundation of China(Grants Nos.61825305 and U21A20518).
CONFLICT OF INTEREST
We declare that we have no conflict of interest.
DATA AVAILABILITY STATEMENT
Data openly available in a public repository that issues datasets with DOIs.
ORCID
Zhiyong Dinghttps://orcid.org/0000-0002-4345-7030
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Fault diagnosis of rolling bearings with noise signal based on modified kernel principal component analysis and DC-ResNet
- Short‐time wind speed prediction based on Legendre multi‐wavelet neural network
- Iteration dependent interval based open‐closed‐loop iterative learning control for time varying systems with vector relative degree
- Thermoelectric energy harvesting for internet of things devices using machine learning: A review
- An embedded vertical‐federated feature selection algorithm based on particle swarm optimisation
- An activated variable parameter gradient-based neural network for time-variant constrained quadratic programming and its applications