基于深度Q学习的无线传感器网络目标覆盖问题算法
2023-11-24高思华贺怀清
高思华,顾 晗,贺怀清,周 钢
(1.中国民航大学 计算机科学与技术学院,天津 300300;2.吉林大学 计算机科学与技术学院,长春 130012;3.中国民航信息网络股份有限公司 科技管理部,北京 101300)
无线传感器网络(wireless sensor networks,WSNs)[1]因具有部署速度快、网络规模大、自组织性强、网络健壮性好等特点,已广泛应用于医疗卫生、环境保护、军事侦查等领域.覆盖质量和网络生命周期是无线传感器网络最基本、最重要的问题.如何在满足覆盖要求下延长网络生命周期被定义为无线传感器网络的覆盖问题[2].按感知目标属性不同,覆盖问题可分为目标覆盖、区域覆盖和栅栏覆盖.其中,目标覆盖问题应用场景丰富,其求解方法主要分为整数规划方法、基于博弈理论的方法和智能算法.文献[3]对多感应半径下无线传感器网络的目标覆盖问题进行研究,通过列生成方法建模求解;文献[4]通过列生成方法对无线传感器网络的覆盖连通问题建模,针对列生成方法辅助问题求解速度慢的问题,设计遗传算法进行替换,有效加快了求解速度;文献[5]提出了关键目标的概念,制定优先覆盖网络中被较少传感器覆盖目标节点的策略,设计混合列生成方法进行求解,延长了网络生命周期;文献[6]针对视频传感器感知范围受限的特征,提出了一种基于列生成方法的有向传感器网络目标覆盖问题的求解方法;Shahrokhzadeh等[7]将传感器节点视为参加博弈的节点,使用非合作博弈模型对目标覆盖问题建模,证明博弈必然存在Nash均衡;文献[8]通过博弈模型对有向传感器网络的目标覆盖问题建模,提出节点感知方向改变策略,设计了一种减少覆盖漏洞的分布式算法进行求解.Cardei等[9]最先利用启发式算法对目标覆盖问题进行研究,提出休眠调度策略,仅激活部分传感器节点保障目标覆盖质量,其他传感器节点通过休眠节约能量,考虑覆盖目标数量和传感器节点剩余能量,通过贪心策略选择被激活的传感器;文献[10]针对有向传感器网络的目标覆盖问题提出主动冗余策略,要求每个目标需要被多个传感器节点覆盖,确保信息不会丢失,分别利用先验进化算法和后验进化算法调整有向传感器节点的感应角度,在保证所有目标均被覆盖的前提下,尽可能提高冗余覆盖的目标数量;文献[11]提出了一种基于分布式算法求解目标覆盖问题的方法,假设每个传感器节点可以获取邻居节点的工作状态,帮助改变传感器节点被选择的概率,减少冗余现象发生,延长网络生命周期;文献[12]提出了兴趣区(ROI)概念,将目标覆盖问题通过二部图转化为匹配问题,提出了一种启发算法和3种不同的近似优化算法,通过选择兴趣值最大的传感器节点完成目标覆盖任务.文献[13]提出了一种改进的麻雀搜索算法优化无线传感器网络的覆盖,通过引入佳点集改善初始化策略,避免算法的早熟现象,在麻雀搜索过程加入动态学习策略,优化算法的寻优模式;文献[14]提出了一种基于学习自动机的节点选择方法,该方法增加满足能量限制条件传感器的激活概率,降低冗余传感器的选择概率,通过构建更多可行解集延长网络生命周期;文献[15]提出了一种用遗传算法求解有向传感器的K-目标覆盖问题,用每个染色体表示网络中能构建的所有解集合,通过交叉、变异等操作逐渐优化种群,构建更多的可行解集.
整数规划方法和基于博弈理论的方法在求解过程中忽略目标覆盖问题的内在特征,通过设计大量限制条件寻找最优解,易出现收敛速度慢的问题.启发式算法与目标覆盖问题的特征紧密联系,算法根据网络当前状态激活最合适的传感器以覆盖目标.该类算法求解速度快,但对影响无线传感器网络生命周期的原因分析较片面,自我学习能力不足,解的质量有待提高.进化算法解的构建较容易,进化过程可隐性揭示覆盖问题的内在特征,但初始解的构建经常依赖贪心算法,易发生求解速度较慢、陷入局部最优等问题.
针对上述问题,本文提出一种基于深度Q学习的传感器调度算法.首先,根据网络中传感器节点的能量、是否激活和目标节点的覆盖情况3个特征描述当前网络状态;其次,智能体通过深度Q学习选择激活的传感器节点;再次,从传感器节点覆盖目标数量与自身能量消耗的关系设计奖励函数,指导环境给予智能体瞬时奖励;最后,智能体进入新的网络状态.该过程迭代进行,直到无法构建新的可行解集为止.智能体以获取最大累计收益为目标,不断学习传感器节点调度策略,构建更多的可行解集,延长网络生命周期.

图1 强化学习原理示意图Fig.1 Schematic diagram of reinforcementlearning principle
1 深度Q学习原理
强化学习是机器学习的一个重要分支.智能体(Agent)在与环境交互中学习动作策略π,获得最大的累计奖励值.在给定某时刻t,智能体在状态空间S中观测当前状态st,在动作空间A中选择动作at与环境互动[16].环境给予智能体奖励rt,并迁移到新的状态st+1.智能体根据rt逐步学习完善策略π.图1为强化学习方法的原理示意图.
Q学习是一种基于价值的无模型强化学习方法.通过动作-价值函数Qπ(st,at)评估在当前状态st下,智能体根据策略π选择动作at后可获得累计奖励Ut的期望值,计算公式为
Qπ(st,at)=ESt+1,At+1,…,Sn,An[Ut|St=st,At=at],
(1)
其中:Ut为折扣回报;γ∈[0,1]为折扣因子,用公式表示为
Ut=rt+γrt+1+γ2rt+2+…+γn-trn.
(2)
由式(1)可知,Qπ(st,at)依赖于策略π.假设π*为最佳策略,则Q*(st,at)为最优动作-价值函数,此时Q*(st,at)只依赖于st和at,与π不再相关,即
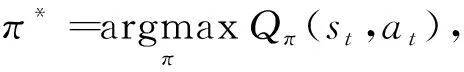
(3)
Q*(st,at)=maxQπ*(st,at).
(4)
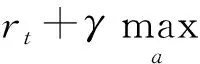
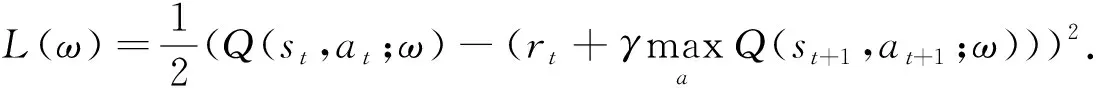
(5)
2 系统模型和问题描述
2.1 网络模型

图2 由5个传感器和3个目标组成的网络Fig.2 Network consisting of five sensors and three targets
在X×Y的二维空间内随机部署n个传感器节点覆盖m个静态目标.设P={p1,p2,…,pn}为传感器节点集合,T={t1,t2,…,tm}为目标节点集合.本文假设网络中传感器具有相同的覆盖能力和初始能量,且节点部署后位置不再发生变化.图2为由5个传感器和3个目标组成的网络.
2.2 传感器模型
本文传感器节点的感知范围是以传感器为圆心、半径为k的圆形区域.传感器节点pi与目标节点tj的覆盖关系采用确定性覆盖模型[19],即pi和tj的覆盖关系仅与双方距离d相关.pi和tj的位置通过二维坐标表示,分别为(xi,yi)和(xj,yj).pi和tj的欧氏距离d计算公式为
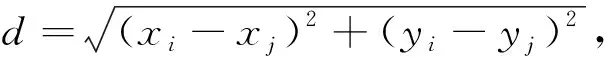
(6)
当d≤k时,本文记作pi覆盖tj.ci记录传感器节点pi可覆盖的目标集合.由图2可见,c1={t1,t2},c2={t1,t3},c3={t2},c4={t3},c5={t3}.
2.3 能量模型
网络中所有传感器节点具有容量为E个单位的初始能量,其中E>1.传感器具有两种状态,分别为休眠状态和激活状态[20].处于休眠状态的传感器节点不消耗能量,也无法覆盖网络中的目标;处于激活状态的传感器节点单位时间内消耗1单位能量,对其覆盖范围内的目标持续感知.本文假设传感器节点在两种状态转换过程中能量消耗忽略不计.传感器节点在能量耗尽后被视为死亡节点,无法被再次激活.
本文各变量含义如下:n为传感器节点数量,P为传感器节点集合,pi为第i号传感器节点,m为目标节点数量,T为目标节点集合,tj为第j号目标节点,ci为传感器节点pi可覆盖的目标集合,CS为可行解集的集合,csi为第i个可行解集,actx为可行解集被激活的时间,L为可行解集的总数,E为传感器节点具有的初始能量,eix为pi节点单位时间消耗的能量.
2.4 目标覆盖问题
定义1可行解集是P的子集,该子集可覆盖网络中的所有目标节点.
可行解集的集合记作CS={cs1,cs2,…,csL},任一可行解集csi应满足以下公式:
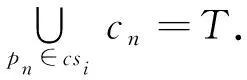
(7)
图2中存在可行解集cs1={p1,p4},cs2={p1,p2,p3}等.
定义2可行解集中单独覆盖目标节点数为零的传感器节点称为冗余传感器节点.
冗余传感器覆盖的全部目标均可由可行解集中其他传感器节点覆盖.如图2所示,存在可行解集{p1,p3,p5},传感器节点p3覆盖的目标t2同时也被传感器p1覆盖.因此,传感器p3为冗余传感器节点.
定义3存在冗余传感器节点的可行解集称为冗余可行解集.
冗余可行解集会额外消耗传感器能量,严重影响网络生命周期.例如,传感器p3所在的冗余可行解集{p1,p3,p5}激活,影响另一个可行解集{p2,p3}的激活时长,导致网络生命周期缩短.
定义4不存在冗余传感器节点的可行解集称为非冗余的可行解集.
定义5无线传感器网络持续覆盖所有目标节点的时间长度称为网络生命周期.
定义6构建并调度无线传感器网络中的可行解集,使得网络生命周期最大称为目标覆盖问题.
目标覆盖问题建模为
其中L表示可行解集的总数,actx表示可行解集被激活的时间,限制条件(9)表示任意传感器节点pi在各可行解集中消耗的能量总和不超过其自身初始能量E,eix表示pi单位时间消耗的能量,限制条件(10)表示任一可行解集的工作时间非负.
定理1目标覆盖问题得到最优解时,被激活的可行解集可全部为非冗余的可行解集.
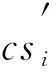
3 算法设计
本文假设每个传感器节点单位时间能耗相同,且每个可行解集的工作时间相同.求解目标覆盖问题的核心变为构建更多数量的可行解集.构建可行解集过程中,当前网络状态只与网络的前一个状态和激活的传感器节点相关,具有Markov性.状态空间无法穷举,且依次激活休眠节点符合离散问题特征.因此,本文采用深度Q学习算法对目标覆盖问题建模并求解.
3.1 算法建模
深度Q学习算法需要对状态空间、智能体的动作空间和环境给予的奖励函数进行定义.
3.1.1 状态
无线传感器网络的状态通过无线传感器节点状态和目标覆盖状态进行描述,t时刻无线传感器网络状态可表示为
St={state1,state2,…,staten,{tc1,tc2,…,tcm}},
(11)
其中: {tc1,tc2,…,tcm}记录每个目标被当前网络激活状态下传感器节点覆盖的次数;statei={ei,isActivei}记录传感器节点pi状态,ei为pi的剩余能量,isActivei表示pi是否被激活,取值为
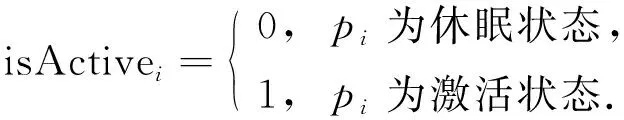
(12)
初始状态下,网络中各传感器节点均处于休眠状态.将无线传感器网络状态St输入到Q网络中,估算出激活每个传感器节点对应的动作价值,并基于此选择被激活的传感器节点pi.状态的转移根据此时pi的情形可分为以下4种.
1)pi处于休眠状态,此时pi从休眠状态转为激活状态,且网络中激活的传感器节点未构成可行解集,即∃tcj=0,j∈{1,2,…,m}.St+1中更新statei和目标覆盖情况,即statei={ei-1,1},目标覆盖更新公式为
tcj=tcj+1, ∀tj∈ci;
(13)
2)pi处于激活状态,此时环境状态St+1=St;
3)pi处于死亡状态,此时环境状态St+1=St;
4)pi处于休眠状态,此时pi从休眠状态转为激活状态,网络中处于激活状态的传感器节点可构成一个可行解集;St+1首先按情形1)进行更新,然后对所有传感器节点状态以及目标覆盖情况更新.
传感器节点状态更新公式为
statei={ei,0}, ∀i∈{1,2,…,n}.
(14)
目标覆盖更新公式为
tcj=0, ∀j∈{1,2,…,m}.
(15)
3.1.2 动作
智能体的动作空间表示为A={p1,p2,…,pn}.根据当前无线传感器网络状态,智能体的动作为选择一个传感器节点并尝试激活.本文根据ε-greedy策略选择出当前动作at,用公式表示为

(16)
3.1.3 奖励
本文从传感器节点覆盖目标数量和自身能量消耗两方面设计奖励函数.由定理1可知,智能体应构建非冗余可行解集.因此,环境应对智能体有助于构建非冗余可行解集的动作给予奖励,对导致冗余的动作进行惩罚.具体到每一个动作,传感器节点单独覆盖目标数量越多,对应的奖励越多;单独覆盖目标数量相同的情况下,剩余能量越多,对应的奖励越多.冗余传感器节点应该得到惩罚,且能量越少获得的惩罚越多.已激活和死亡的传感器节点没有对构成可行解集做出贡献,也没有能量消耗,故设置奖励为0.随着训练的进行,智能体会逐渐学习到构建更多非冗余可行解集的策略,延长网络生命周期.因此,智能体在时刻t选择激活传感器节点si后的奖励函数可表示为
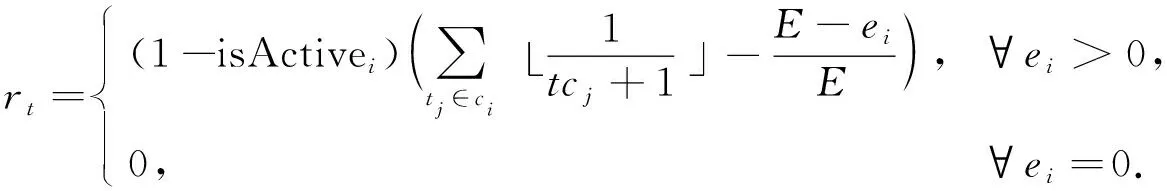
(17)
3.2 网络结构及算法流程
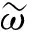

(18)
由于yt部分基于事实,因此Q(st,at;ω)应向yt靠近.本文采用均方差损失函数L(ω)训练网络,计算公式为

(19)
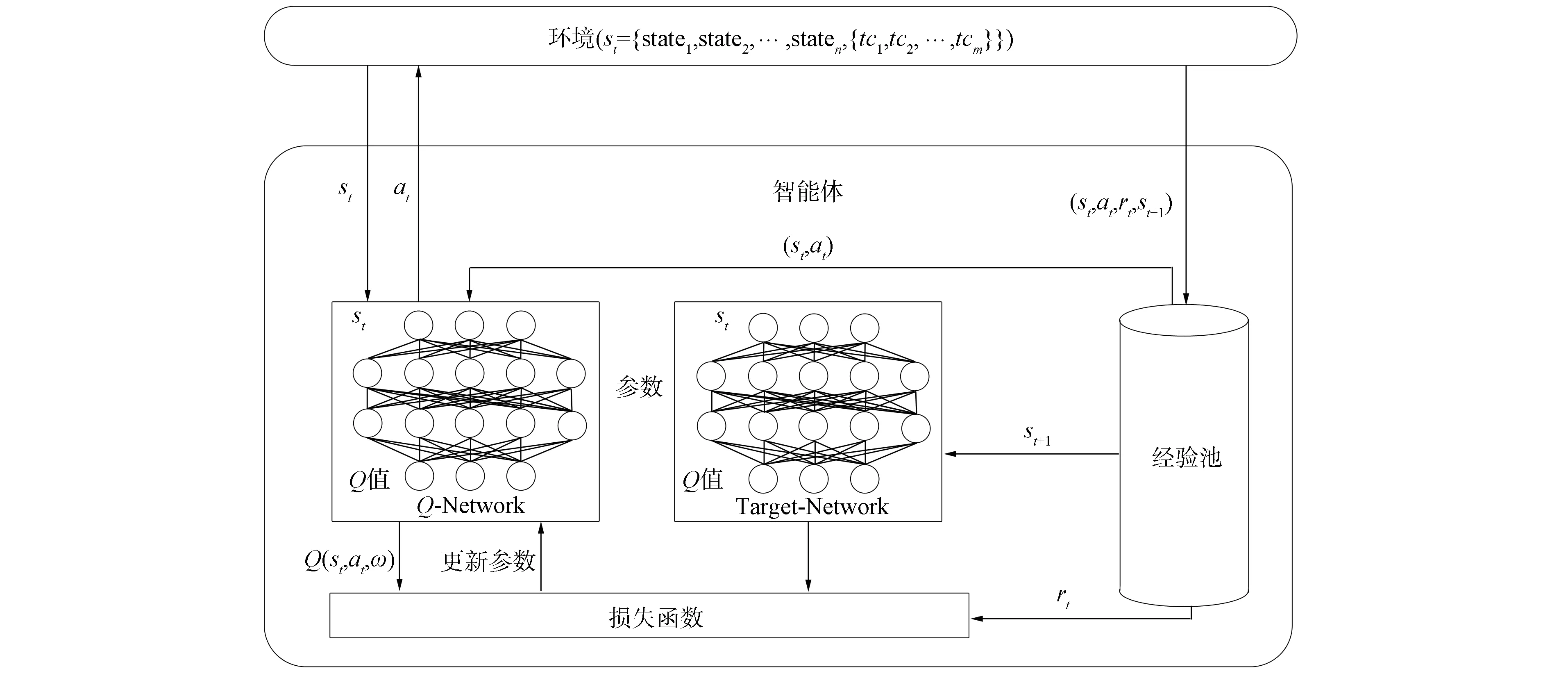
图3 深度Q学习算法网络结构Fig.3 Network structure of deep Q learning algorithm
算法1目标覆盖问题的深度Q学习算法.
输入: 训练轮数e,同步参数间隔值C,记忆池容量M,数据提取批数b;
输出: 累计奖励和网络生命周期;
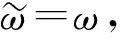
步骤2) 开始训练循环,初始化累计奖励和网络生命周期为0;
步骤3) 智能体感知环境得到状态st;
步骤4) 进入构造可行解集循环;
步骤5) 网络根据ε-greedy策略选择当前动作at;
步骤6) 获得瞬时奖励rt并更新执行动作at后的环境状态st+1;
步骤7) 将(st,at,rt,st+1)存入记忆池;
步骤8) 更新累计奖励;
步骤9) 根据式(18)预测动作价值;
步骤10) 随机选取经验池中b批数据训练,更新Q网络参数ω;
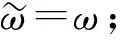
步骤12) 判断是否能继续构成可行解集,若无法构建,则跳出循环;
步骤13) 输出本次得到的累计奖励和网络生命周期;
步骤14) 转至步骤2)开启下一轮训练,直到训练轮次达到预定数量e后停止训练.
4 仿真实验
将无线传感器网络布置在80 m×80 m的矩形区域内.在该区域内随机部署50,100,150个传感器节点,随机部署10,20,30个目标节点.传感器节点的感知半径为10,20,30,40 m,初始能量为3单位能量.深度Q网络共有4层,其中输入层神经元个数与状态维度相关,中间两个全连接层的神经元个数分别为256个和128个,输出层神经元个数与网络中传感器节点个数相同,实验采用ReLU激活函数.经验池中可存储5 000条数据,每次随机提取64批数据参与训练.当经验池中数据存满后,新产生的数据会替换原有旧数据.实验设置学习过程中的折扣因子为γ=0.9.
4.1 算法收敛性验证
在无线传感器网络中随机部署10个目标节点,感知半径为40 m的传感器节点50个.图4记录了3 000轮训练中智能体的累计收益.由图4可见,智能体在训练初期选择动作较盲目,选择较多的冗余传感器、已激活传感器和死亡传感器;随着训练轮数增加,智能体逐渐学习到获取较多单步奖励的策略,累计奖励逐渐增加;训练2 500轮后,智能体在每轮训练中获取的累计收益逐渐平稳,算法趋于收敛.
4.2 与其他目标覆盖算法的对比
在无线传感器网络中随机部署10,20,30个目标节点,感知半径为40 m的传感器节点50,100,150个.用本文提出的深度Q学习算法、3种贪心策略算法(Greedy1采取的策略为每次选择覆盖目标数量最多的传感器节点;Greedy2算法采取的策略为选择剩余能量最高的传感器节点;Greedy3算法采取的策略为选择覆盖最多未被覆盖目标的传感器节点)、最大寿命目标覆盖率算法(MLTC)[21]和自适应学习自动机算法(ALAA)[14]分别计算网络生命周期,实验结果如图5~图7所示.由图5~图7可见: Greedy1算法和Greedy2算法在传感器数量少的情况下,网络生命周期与其他算法相差很小,当传感器数量增加,覆盖情况复杂后,两种算法效果均不佳;Greedy3算法、MLTC算法和ALAA算法结果较好,但在不同网络环境下稳定性有待提高;深度Q学习算法的结果优于其他几种算法,取得了较长的网络生命周期.同时,实验结果表明,网络生命周期与传感器节点数量呈正相关.
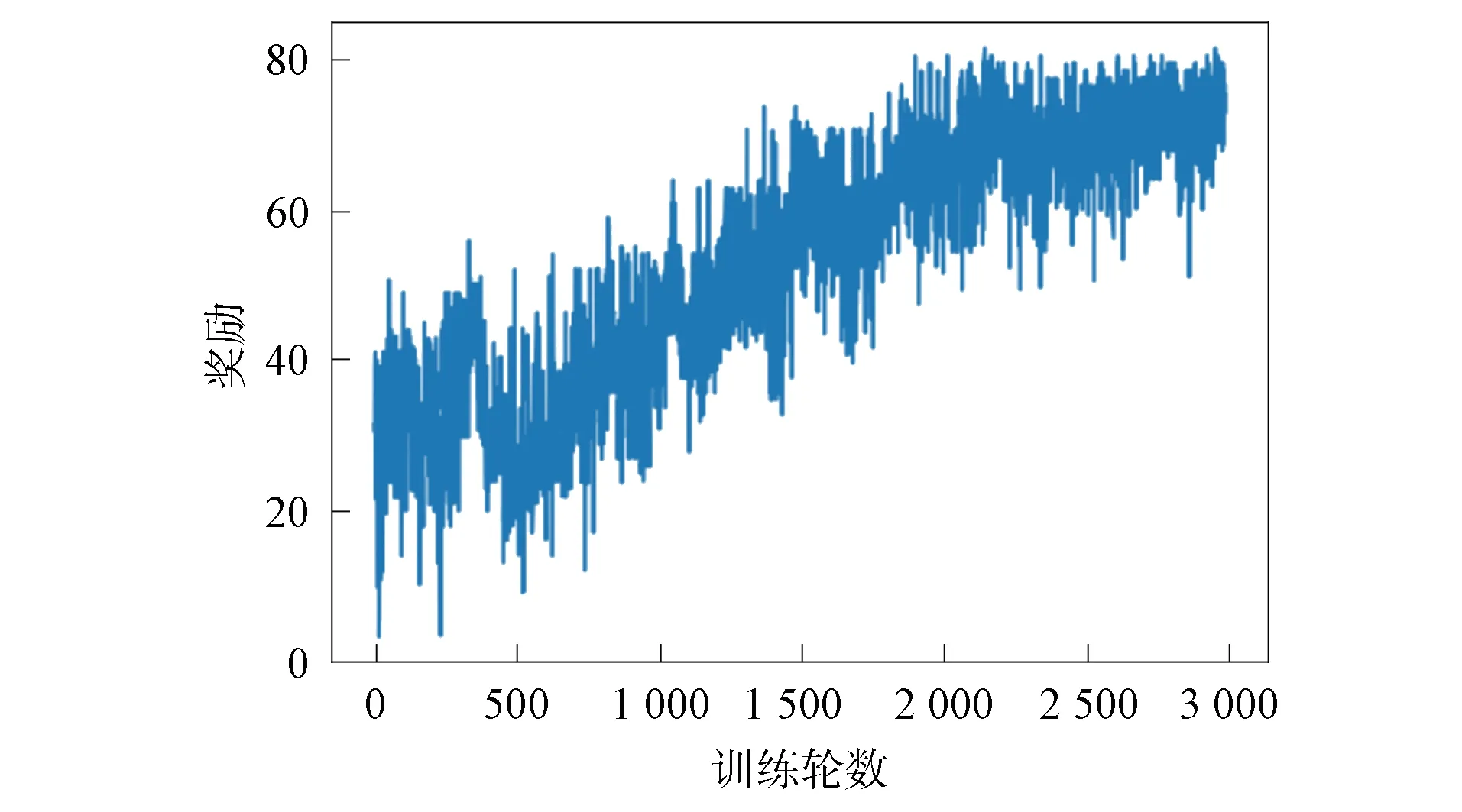
图4 奖励收敛曲线Fig.4 Convergence curves of rewards
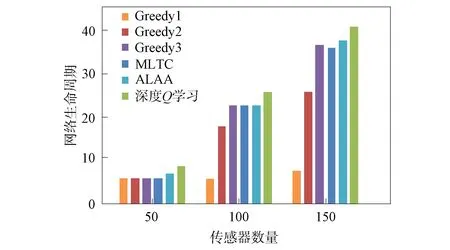
图5 不同算法目标数为10的网络生命周期对比Fig.5 Comparison of network lifecycles with targetnumber of 10 for different algorithms
4.3 传感器节点感应半径对网络生命周期的影响
在无线传感器网络中随机部署100个传感器节点和40个目标节点,传感器节点的感知半径分别为10,20,30,40 m.利用上述各算法分别计算网络生命周期,实验结果如图8所示.由图8可见,当感应半径为10 m时,网络中各传感器节点覆盖的目标数量少,各算法计算的网络生命周期近似.随着感应半径的增加,每个传感器节点覆盖的目标数量增加,每个目标节点可以被更多传感器节点覆盖.因此,虽然各算法计算的网络生命周期存在差异,但均显示网络生命周期与传感器的感知半径呈正相关.
4.4 传感器节点初始能量对网络生命周期的影响
在无线传感器网络中布置100个传感器节点,同时布置20个目标节点,传感器节点感应半径固定为30 m,携带的初始能量从3单位能量开始逐级提高至12单位能量,仿真实验结果如图9所示.由图9可见,当传感器携带能量较少时,各算法网络生命周期均较短.随着携带能量的提高,其网络生命周期对应延长.因此,实验表明网络生命周期与传感器初始能量呈正相关.

图6 不同算法目标数为20的网络生命周期对比Fig.6 Comparison of network lifecycles with targetnumber of 20 for different algorithms
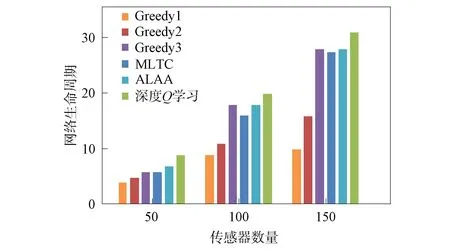
图7 不同算法目标数为30的网络生命周期对比Fig.7 Comparison of network lifecycles with targetnumber of 30 for different algorithms
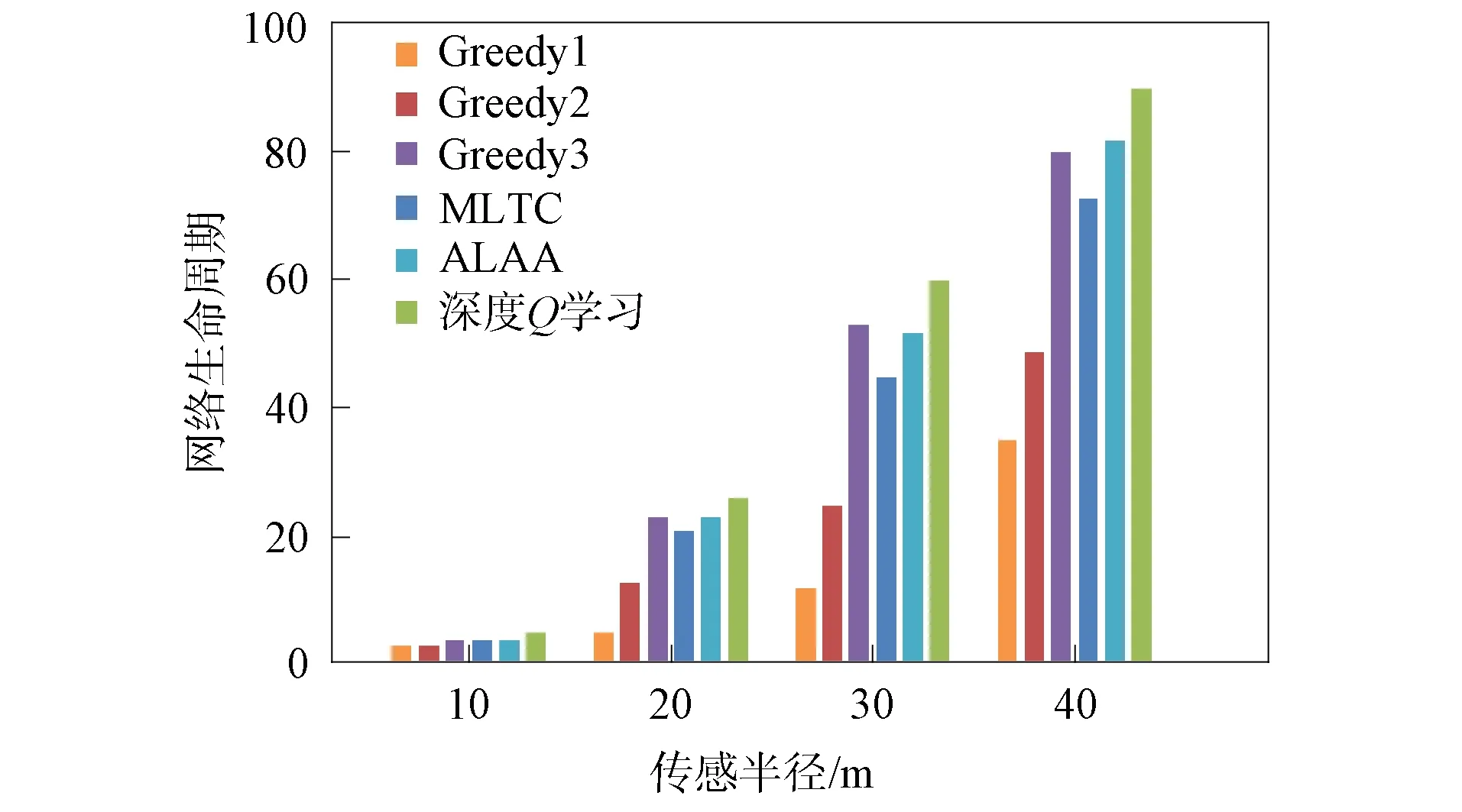
图8 各算法对不同传感半径的网络生命周期的影响Fig.8 Effect of each algorithm on network lifecyclewith different sensing radii

图9 各算法对不同初始能量的网络生命周期的影响Fig.9 Effect of each algorithm on network lifecyclewith different initial energies
综上所述,针对求解无线传感器网络目标覆盖问题过程中存在的节点激活策略机理不明确、可行解集存在冗余等问题,本文提出了一种基于深度Q学习的目标覆盖算法对无线传感器网络目标覆盖问题进行建模并求解.首先,用传感器节点的能量、是否激活和目标覆盖情况描述网络状态;其次,将智能体的动作作为网络中待激活的传感器节点;最后用智能体的奖励综合考虑传感器节点覆盖目标数量与自身能量消耗.通过训练,智能体学习调度网络中传感器节点的策略,可减少冗余现象发生,增加可行解集的数量.仿真实验结果表明,本文算法可合理调度传感器节点,延长网络生命周期.
