一种面向中文拼写纠错的自监督预训练方法
2023-11-24苏锦钿余珊珊洪晓斌
苏锦钿 余珊珊 洪晓斌
(1.华南理工大学 计算机科学与工程学院,广东 广州 510006;2.广东药科大学 医药信息工程学院,广东 广州 510006;3.华南理工大学 机械与汽车工程学院,广东 广州 510640)
中文拼写纠错(CSC)也称中文拼写检测,是自然语言处理(NLP)及中文文本分析中的一个重要子任务和研究方向,其主要目的是利用计算机技术识别中文文本中包含的拼写错误并进行纠正[1-3]。早期的研究主要以基于规则、N-元语法、统计机器翻译和神经网络的方法为主,如NMT[4]和CPN[2]等。近几年,随着Transformer 结构[5]及以BERT[6]为代表的预训练语言模型在多个NLP任务中取得了突出的效果,一些学者陆续将预训练语言模型引入到CSC任务中,并提出一系列新的拼写纠错模型,如FASPell[1]、SM-BERT[3]、SpellGCN[7]、DCN[8]、DCSpell[9]、PLOME[10]、PHMOSpell[11]、ReaLiSe[12]等。
相对于早期其他的CSC 工作,BERT 和RoBERTa[13]等预训练语言模型可以通过海量文本预训练和下游任务微调的方式更好地学习字词及句子的语义和上下文信息,从而进一步提升模型在CSC任务中的效果。但BERT 等在预训练过程中主要利用掩码语言模型(MLM)随机屏蔽句子中的字,然后结合上下文预测其正确值。这一方面假定文本序列中各个字相互独立,即忽略词组中各个字之间的依赖关系;另一方面影响了模型对拼写错误的识别和纠正能力,且没有考虑错误字词在发音和字形上的相似性,从而导致预训练和微调目标不一致。针对BERT 的字独立性假设及预训练与微调阶段不一致问题,文献[14]在英文BERT 的全词掩码(WWM)模型基础上,结合中文的特点提出一个基于全词和连续词组掩蔽策略的MacBERT 模型。但MacBERT在CSC任务中同样面临预训练与微调目标不一致问题,特别是CSC中的大部分错误主要是因为发音或字形相近引起的,而不是同义词误用,并且很少出现连续多个词拼写错误的情况。
本文针对BERT 的中文拼写错误识别及纠正能力不足问题,提出一种面向中文拼写纠错的自监督预训练方法MASC,将BERT中的MLM和MacBERT中的Mac任务转换成基于混淆集的拼写错误识别及纠正任务;在全词掩码的基础上利用混淆集从音调相同、音调相近和字形相近等多个方面构造拼写错误候选字,给出相应的掩码策略、替换策略和预训练任务,从而进一步增强BERT 的拼写错误识别及纠正能力;还通过sighan13、sighan14 和sighan15等公开CSC 语料集上的实验证明MASC 能够在不改变BERT/RoBERTa/MacBERT 等模型现有结构的前提下,进一步提升它们在下游CSC任务中的效果。
1 相关工作
与英文拼写纠错相比,中文拼写纠错面临更多的困难和挑战,特别是中文字词之间没有定界符、缺乏形态上的变化和严重依赖于上下文语义等特点,使得对中文拼写错误字符的识别及纠正高度依赖上下文语境。近几年,随着各种预训练语言模型在许多NLP任务上取得一系列突出的成果,部分学者开始将它们引入到CSC中。文献[1]提出一种基于去噪自动编码器(DAE)和解码器的中文拼写检查器——FASPell,其中DAE 采用BERT 中的掩码语言模型,而解码器采用把握度-字符相似度解码器;文献[2]提出一个双向GRU 和BERT 的SM-BERT 模型,其主要思路是通过一个基于双向GRU 的错误检测网络识别句子中可能出错的字的位置,并利用这些位置信息对纠错网络中的输入句子进行软掩码,从而让模型学习只针对可能出错的字进行纠正,而非句子中所有的字;文献[8]提出一种基于动态连接网络的DCN 模型,其主要思路是在RoBERTa[13]的基础上利用拼音增强候选生成器生成候选的中文字,并通过注意力网络对相邻中文字间的依赖关系进行建模;文献[7]提出一种拼写检查卷积图网络Spell-GCN,通过结合BERT 和卷积图网络刻画字符的发音/形状相似性知识以及字之间的先验依赖关系,并生成正确的拼写校正;文献[15]在Transformer注意力机制的基础上添加高斯分布的偏置矩阵,用于提高模型对局部文本的关注程度,同时使用ON_STM 模型对错误文本表现出的特殊语法结构特征进行语法信息提取;文献[16]则提出一种融合汉字多特征嵌入的端到端中文拼写检查算法模型BFMBERT,主要利用结合混淆集的预训练任务让BERT 学习中文拼写错误知识。总的来说,这些工作均证明了BERT和RoBERTa等预训练语言模型能够进一步改善字词及句子的语义表征,从而提升模型在下游CSC 任务中的效果。但由于BERT 和RoBERTa等模型在预训练过程中是通过上下文信息学习字词的语义,而CSC任务中拼写错误的字词通常是离散出现的,因此导致预训练语言模型一方面在拼写错误识别方面存在一定的不足,另一方面在纠正时往往需通过额外的神经网络层引入错误字词和正确字词在音调或字形等方面的相似性知识。
文献[14]在英文BERT 的全词掩码WWM 基础上,结合中文的特点提出一个基于全词和词组掩蔽策略的模型MacBERT。MacBERT 将BERT 中的MLM 任务转换为面向同义词替换的文本校正任务,即让模型学习如何将替换后的同义词识别为原来的字词,目的是缩小预训练和微调阶段之间的差距。但MacBERT 在CSC 中同样面临预训练与微调不一致的问题。一方面,CSC中的大部分拼写错误并不是由同义词误用引起的,而是由音调相同、音调相近或字形相似等因素导致的;另一方面,CSC中一般以单个的字或单词拼写错误为主,很少出现连续多个词组的拼写错误。
文献[17]指出约83%的中文拼写错误与音调相似性相关,48%与字形相似性相关。表1 给出了CSC中一些常见的拼写错误及原因,其中粗斜体部分表示错误的字词,括号中的粗体为正确字词,方括号中为错误字词与正确字词的拼音。

表1 常见中文拼写错误例子Table 1 Examples of common CSC errors
CSC中大部分的拼写错误主要是因为音调相同、音调相近或字形相近等引起的,但BERT/RoBERTa/MacBERT等预训练语言模型在预训练过程中均没有考虑这些相似性知识。文献[18]尝试在预训练阶段引入拼音相似性知识,并提出了混淆汉字和噪声拼音的替换策略;文献[19]也在BERT的基础上提出一个预训练模型SpellBERT,并利用图神经网络将字的偏旁部首和拼音信息引入到预训练任务中。但这些工作均没有进一步探讨如何利用现有的混淆集更好地融合发音和字形等相似性知识。文献[10]提出的PLOME在训练预训练语言模型时引入基于语义混淆集的MASK 策略,并将拼音和笔画作为预训练语言模型以及模型微调的输入,但需依赖于额外的笔画知识;文献[11]则结合光学字形识别(OCR)及自动语音识别(ASR),从多模态的角度对拼音特征、字形特征、语音特征进行信息融合和错误字预测;文献[12]同样也利用了中文字符上的语义、声音和字形等多模态信息。但这些工作均需要在下游任务中对不同模态信息进行融合。因此本文的主要目的是在上述工作的基础上,通过预训练任务和混淆集将中文拼写纠错中错误字词与正确字词间的音调及字形相似性知识引入到预训练语言模型中,从而提升模型在下游CSC任务中的拼写错误识别及纠正能力。
2 面向中文拼写纠错的自监督预训练MASC
下面提出一种中文拼写纠错掩码语言模型的自监督预训练方法MASC。
2.1 MASC预训练
BERT中的MLM在预训练过程中对每一个句子随机选择其中15%的字,然后用[MASK]标记进行掩码后,通过预训练让模型学习如何根据上下文信息预测被掩码字的真实值。每一个字被选中并进行掩码的概率为15%,被选中的字当中有80%的概率被[MASK]标记替换、10%的概率保持不变、10%的概率随机用词汇表中的字进行替换。
MASC采用类似于MLM的选择策略,但是对每一个被选中进行掩码的字,利用混淆集得到相应的候选字后进行替换,最后通过训练让模型学习根据上下文信息预测被替换字的真实值以及是否存在拼写出错。具体来说,MASC的流程如图1所示。
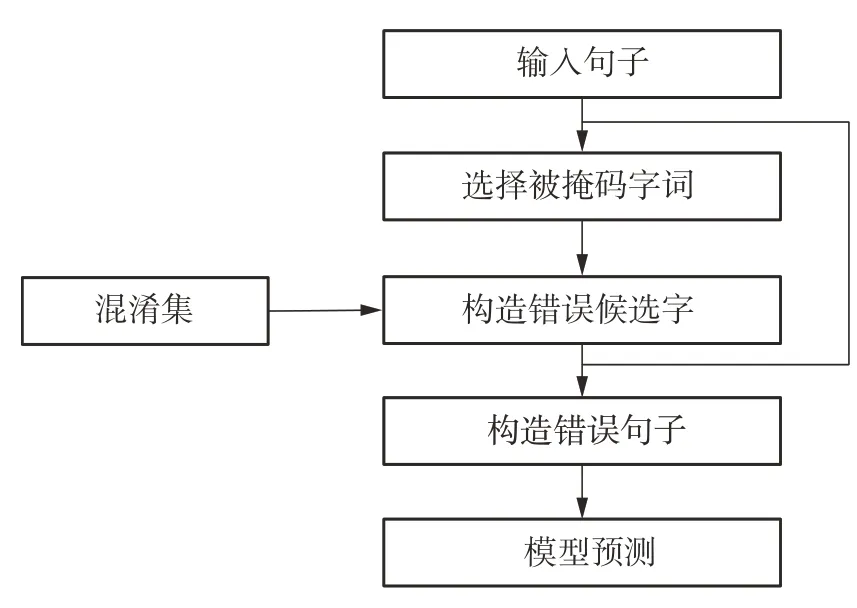
图1 MASC的流程Fig.1 Process of MASC
具体来说,MASC主要采用以下策略。
(1)基于全词掩码和N-grams语法的掩码策略
MASC 在BERT 的全词掩码WWM 基础上,结合MacBERT的N-grams掩码策略,采用一元和二元词的字掩码方式。由于一般文本中的大部分错误为单字或某个单词,很少连续多个单词出现错误,因此MASC 中只考虑一元词(字)和二元词(连续两个字或完整的单词)的掩码策略。具体来说,选择输入句子中15%的字进行替换,被选中的字有90%的概率为一元词组、10%的概率为二元词。若被选中的字为某个词组的字,则有15%的概率同时选择该词组中的其他字。掩码选择算法selectMasked-Char的核心伪代码表示如下:

(2)基于混淆集的替换策略
MASC在文献[2]中的混淆集基础上结合PinYin工具进行扩充,并划分为同音同调、同音异调、近音同调、近音异调和字形相近5种不同类型。
对于每一个待掩码的字或词,采用以下替换策略:40%的概率采用同音同调字典,15%的概率采用同音异调字典,15%的概率采用近音同调字典,10%的概率采用近音异调字典,10%的概率采用字形相近字典,10%的概率保持不变。表2给出了不同掩码方法的示例,其中每一个“+”表示在前一个“+”基础上继续增加新的掩码方法,例如“++WWM”表示在上一行“+MLM”的基础上增加WWM。

替换策略算法charMaskWithConfuseSet 的部分核心伪代码表示如下:
2.2 基于MASC的预训练模型
为了最大程度地利用BERT/RoBERTa/MacBERT 等预训练模型中已学习到的大量知识,MASC 采用原有的预训练模型结构,如图2 所示。其中,ai(1≤i≤n)和bj(1≤j≤m)分别表示输入长度为n和m的句子A和B中的各个字符。
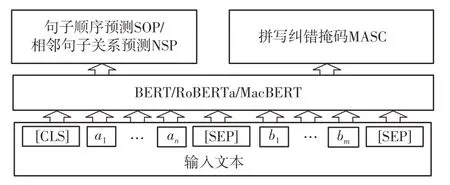
图2 基于MASC的预训练模型结构Fig.2 Pre-training model structure of MASC
为了区别一般的BERT/RoBERTa/MacBERT,将基于MASC 的BERT/RoBERTa/MacBERT 的模型分别记为MascBERT/MascRoBERTa/MascMacBERT。
以MascBERT 为例,预训练任务可形式化地定义为:给定任意一对中文文本序列A={a1,a2,…,an}和B={b1,b2,…,bm},根据BERT 的输入要求将A和B进行串联并构造成输入序列X={x0,x1,…,xt},其中t=n+m+2:
MascBERT 通过词向量嵌入层Embedding 和多层连续Transformer隐层将输入X转换为上下文表示H(L)∈RN×d,其中L为隐层数量,N为输入的字符最大长度(通常最大为512),d为隐层的词向量维度(通常为768或1 024):
在H(L)的基础上,MascBERT 的主要目标是预测替换后的文本序列中拼写错误字的正确值以及是否存在拼写错误。对于替换后的错误字的隐层向量用子集Hm∈Rk×d表示,其中k为被替换字的总数。默认情况下与BERT 一样采用输入序列长度的15%作为k的值,即k=int(t×15%)。
对于训练集中的第i个句子,利用待训练参数矩阵W1∈R|V|×d和偏置向量b1∈ RM将Hm投影到词汇表V上并预测相应的概率分布pi:
利用标准交叉熵函数Losscor计算相应的纠正损失值:
式中,M为每一批数据的数量,yij为M中第i个句子的第j个字的正确值;pij为M中第i个句子的第j个被替换字在词汇表V中的概率分布。
为了进一步提高模型对拼写错误的识别能力,MascBERT 同时还对句子中各个位置上是否存在拼写错误进行判断。利用待训练参数矩阵W2∈R1×d和偏置向量b2∈RM对H(L)进行转换,并利用sigmoid 函数计算相应的错误概率值qi:
qi中每一个位置的值越接近1,则表示该位置出现拼写错误的概率越大。利用二元交叉熵函数Lossdet计算相应的错误识别损失值,其中lij(1≤j≤t)为第i个句子中第j个位置是否出现拼写错误的正确值,“1”表示存在拼写错误,“0”表示不存在拼写错误:
BERT的预训练任务除MLM外,还包括句子相邻关系预测任务NSP。ALBERT[20]和MacBERT[14]针对NSP的效果不佳问题,进一步提出句子顺序关系预测SOP。对于MASC,可根据需要结合NSP 或SOP等其他预训练任务,相应的损失函数分别为
式中,LossNSP、LossSOP分别为针对NSP和SOP任务的损失函数。
3 实验与分析
3.1 实验准备
为了利用MASC 进行预训练,实验从文献[21]的生成语料集ACG中随机选择3万个目标正确句子作为预训练语料集,记为ACG3W;同时,还采用汉语水平考试(HSK)语料集中的部分句子作为预训练数据。HSK 语料集共包含156 820 个句子,最大长度为417 个字,平均长度为27.35 个字。考虑到训练效率和句子表达完整性等因素,只从HSK语料集中选择3万个句子作为预训练数据,每条数据的长度在12到120个字之间,并以句号、问号和感叹号等结尾,记为HSK3W。
因实验条件和篇幅限制,实验中只选择3个最常用的BERT 中文预训练语言模型作为基础模型进行新的MASC 预训练,包括:bert-base-chinese、chinese-bert-wwm和chinese-macbert-base,分别简单记为base、wwm 和macbert。3 个模型均包含12 个隐层、12个多头自注意力,输出张量为768维,参数量约为1.1 亿,词汇量约为2.1 万。第1 个模型的原始预训练采用MLM和NSP,第2个模型采用全词掩码的MLM和NSP,第3个模型采用N-grams(包括一元、二元和三元词组),并利用近义词代替[MASK]进行预测。
预训练过程采用批量训练的方式,每一批数据的数量为32,学习率为5×10-5,共训练5 轮,并采用Adam优化器。由于原始HSK和ACG中的数据大部分为单个句子,因此预训练过程中只考虑MASC及相应的Lossdet和Losscor,而忽略NSP或SOP任务。
为验证MASC 的有效性,实验用3 个经典的公开CSC语料集sighan13[22]、sighan14[23]和sighan15[24],并参照文献[2]的做法,利用OpenCC工具将各语料集中的繁体中文句子转换成简体中文,同时利用PinYin工具获取混淆集中各个单词的拼音信息。3个语料集的相关统计信息如表3所示。

表3 3个CSC语料集的统计信息1)Table 3 Statistical information about three corpora
由于各语料集中句子的最大长度均明显小于512 个字,因此在微调和测试过程中均取其最大长度值作为阈值。
与文献[1,3,7]等其他工作类似,实验中均采用CSC任务中常用的句子级别精确率P(Precision)、召回率R(Recall)和F1 值等作为评价指标,并区分错误识别网络D(Detection Network)和纠正网络C(Correction Network)。例如,PD和PC分别表示识别网络和纠正网络的精确率,RD和RC分别表示识别网络和纠正网络的召回率,F1D和F1C分别表示识别网络和纠正网络的F1 值。同时,为了减少参数初始化及训练过程中产生的偏差,在下游任务中取3次独立微调和测试的结果平均值作为最终实验结果。
3.2 预训练语言模型对比
为了分别对比原始base、wwm 和macbert 与采用MASC进行再次预训练后的效果,本实验采用文献[7]中BERT 的类似结构,在最后Transformer 隐层输出序列的基础上,分别利用sigmoid 和softmax层用于错误识别和纠正判断。表4给出了采用不同预训练语言模型后MASC 在3 个语料集上的效果,后缀agc、hsk和all分别表示采用ACG3W、HSK3W和同时采用ACG3W及HSK3W进行MASC预训练的结果。基于base 的MASC 即相当于文献[21]中的BERT 模型,实验结果来自于相应文献;其他实验结果均为本文的实验结果。粗体部分表示在该语料集上不同模型的最好效果。
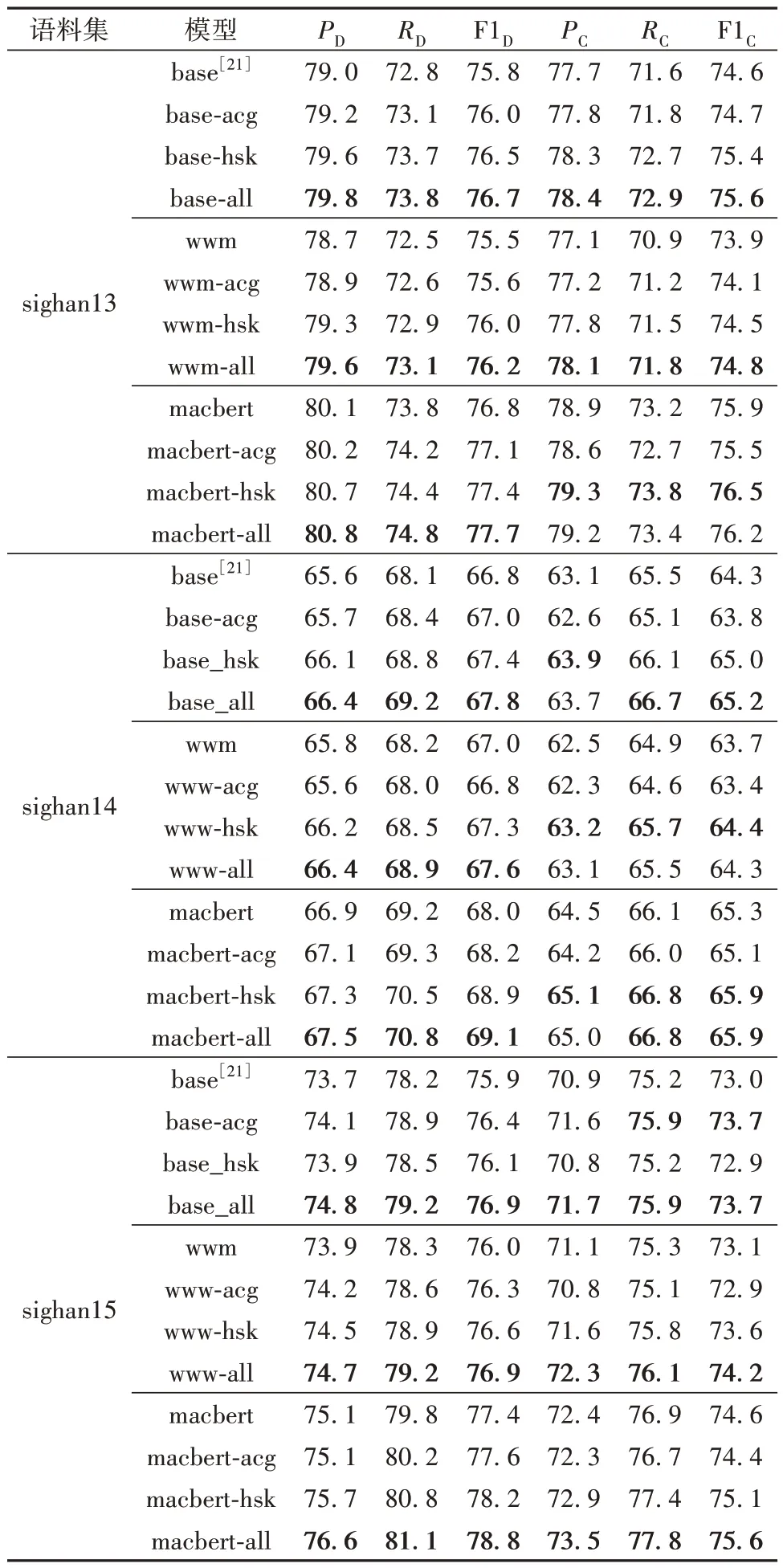
表4 不同预训练语言模型的MASC在3个语料集上的效果Table 4 Performance on three corpora of MASC with different pre-trained language models %
由表4可知:
(1)当采用3 种不同的预训练语言模型时,MASC 在3 个语料集上的表现不同。总体上来说,MASC在macbert上的效果最好,而在bert和wwm上则表现各不同。本文认为主要的原因是macbert 在base基础上结合文本校正预训练任务,进一步增强了模型识别词组和同义词的能力,而且通过大规模的再次预训练能更好地学习句子的上下文语义并提升模型在CSC中的效果。而wwm在3个语料集上的效果并没有明显优于base,甚至部分效果更差,主要是因为:3 个语料集中的大部分错误以单字为主(具体统计信息可见表5),而很少整个词出错,这与wwm 在预训练时的全词掩码策略存在较大的差异;还与3个语料集本身存在一定的差异有关。
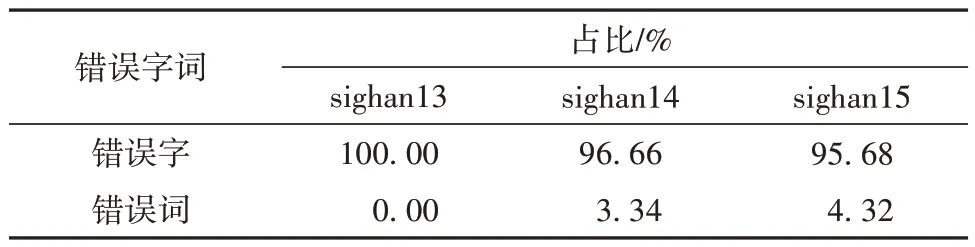
表5 3个语料集中字和词错误的统计信息Table 5 Statistic information about character and word errors in three corpora
wwm与base均没有考虑错误字词与正确字词间的发音或字形相似性知识,且面临预训练和与微调不一致的问题。
(2)对于hsk、acg 和all 3 种不同的预训练语料集,MASC 采用all 数据后在3 个CSC 语料集上总体表现最好,采用hsk 的次之,而采用acg 的最差。这说明预训练数据的内容对于模型在下游任务中的效果有着较大的影响。3 个CSC 语料中的句子主要来自国外的中文初学者所写的散文。HSK中的句子来自于汉语水平考试(HSK)语料集,而ACG的句子则主要来自于人民日报的报道。因此,总体上各个CSC 语料集与ACG 句子内容和语法结构上相差较大,而与HSK 非常接近。实验结果也证明了hsk在CSC 语料集上的表现确实优于acg。采用all 训练数据后,模型效果大部分情况下表现较好,特别是在错误识别效果方面均有一定的提升,但在纠正方面因与acg 训练数据的内容存在一定差异及总体训练不充分等因素,导致纠正的效果有时候略下降。
(3)采用不同训练数据后,MASC在3个语料集上的错误识别效果均得到了一定的提升,这说明MASC确实能有效地提升模型的中文拼写错误识别能力。但在文本纠正方面,采用wwm后模型的效果并没有提升,反而下降了。本文认为主要是因为wwm中对词组的掩码与CSC中以单字拼写错误为主的情况存在很大差异,因此预训练后反而容易引入一些噪声数据,从而导致模型的纠正效果受到一定的影响。
3.3 消融实验
本实验以sighan15 语料集为例对MASC 中的各组成部分进行消融分析。结合表4所示的结果,以MascBERT+base+all 作为基线模型进行分析,实验结果如表6所示。其中“-”表示在原来模型基础上去除相应的组成部分,例如,-N-grams表示不考虑词掩码,即只采用字掩码,-tone表示不考虑拼音的音调,-visual 表示不考虑字形相近信息,-lossdet表示不考虑错误识别层和相应的损失函数。
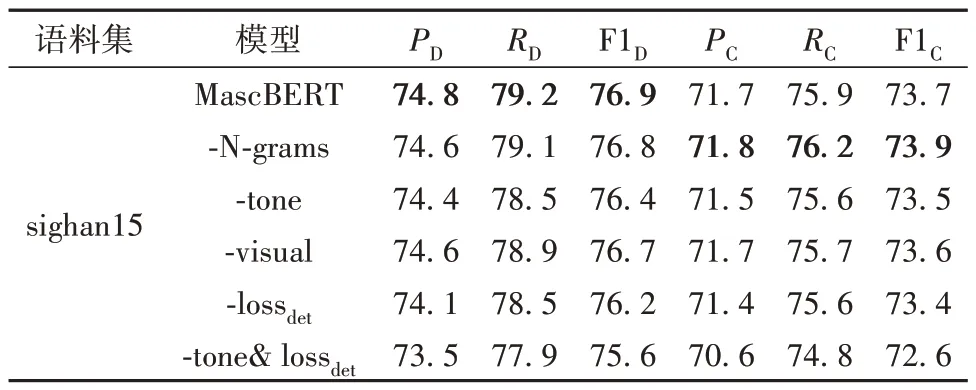
表6 MascBERT的消融实验结果Table 6 Ablation experiment result for MascBERT %
从表6中的实验结果可知:去除N-grams之后,MascBERT 在错误识别效果方面稍有下降,而在纠正方面不仅没有下降,反而有一定的提升。本文认为这主要是因为sighan的训练集和测试集都是以单个字的错误为主,因此去除N-grams虽然降低了错误识别效果,但在纠正时减少了词组所带来的一些干扰信息,因此更符合下游任务的特点,从而使纠正效果有一定的提升。这也与表5的结果相符,同时也说明虽然MascBERT 中采用全词及多元词组掩码能够提升模型在许多下游任务中的表现,但对于CSC任务却不一定有效。对于声调和字形相近信息来说,总体上声调对模型的效果影响更大,这主要是因为大部分拼写错误的正确字与错误字之间存在发音相同的情况,而字形相近的错误相对较少。去除错误识别层及相应的损失函数后,模型的效果明显有一定的下降,这主要是因为原MLM中只考虑对被掩码字正确值的判断,而忽略了对该字是否存在拼写错误进行识别。因此增加错误识别和损失函数后,能够引导模型进一步根据上下文判断相应的字是否存在拼写错误,而不只是单独考虑是否语义正确。当同时去除声调和错误识别判断后,模型的效果下降明显,甚至比不采用MASC的效果更差。这主要是因为sighan15语料集中的拼写错误大多是因为同音或近音而引起的,因此单纯只考虑N-grams和字形相近信息反而容易在预训练时引入噪声数据,特别是在预训练数据量比较有限以及训练不充分的情况下。
3.4 实例分析
下面继续以sighan15 语料集中的部分句子为例,分别对BERT 和MascBERT 的判断结果进行对比分析。测试集中的3个句子如下。
句子1:这两问题真的严重,我么(们)受不了。
句子2:可是你现在不在宿舍,所以我留了一枝(纸)条。
句子3:我以前想要高(告)诉你,可是我忘了。我真户秃(糊涂)。
分别采用预训练及微调后的BERT和MascBERT进行判断,结果如表7所示,其中粗体字表示对应错误的预测结果。

表7 常见中文拼写错误例子Table 7 Examples of common CSC errors
从表7 可以看出,BERT 的输出结果句子在语义上是合理通顺的,但不是正确的目标句子,特别是预测的字词与错误字词之间没有发音或字形上的相似性信息;而MascBERT 的输出结果不仅在句子语义上是合理的,而且能够更好地学习到字之间在发音上的相似性知识。
4 结语
针对现有BERT/RoBERTa/MacBERT 等预训练语言模型的MLM在CSC任务中面临预训练与微调任务不一致的问题,提出一种面向中文拼写纠错的自监督预训练方法MASC,将MLM 中对被掩码字的正确值预测转换成对拼写错误字的识别和纠正,同时结合混淆集引入音调相同、音调相近和字形相近等相似性知识。实验结果表明,所提出的MASC可在不改变BERT/RoBERTa/MacBERT 等模型结构的前提下,有效地提升预训练语言模型在下游CSC任务中的效果。下一步将继续研究如何改进预训练任务中的掩码策略和候选字生成策略,以提升模型的错误识别及纠正能力;还将探讨如何在下游任务中进一步引入其他相似性知识,以避免依赖于特定的混淆集。
