基于超网络的社会化标签相似性研究
2023-11-06潘旭伟曾雪梅
潘旭伟, 曾雪梅, 李 涛
(浙江理工大学 经济管理学院,浙江 杭州 310018)
0 引言
社会化标签是用户为自己感兴趣的资源定义的一个或多个标签,且在系统中其他用户可见。社会化标签发挥了用户的集体智慧,改变了原有基于少数专家的分类体系,是一种开放、灵活、有趣的信息分类组织方式[1]。用户自定义的社会化标签刻画了用户的行为和偏好,作为一种有价值的资源已用于解决大数据时代信息过载的链路预测与个性推荐中[2]。在利用社会化标签进行链路预测和个性化推荐过程中,首先要进行标签的相似性评估,构建能够准确刻画社会化标签相似性的度量指标就显得尤为重要。
到目前为止,对标签相似性度量方法的研究主要是利用向量空间矩阵和基于图或网络的标签共现关系来度量标签之间的相似度。这些标签相似性度量方法将用户-资源-标签三元标注关系转化为向量空间或图/网络,在这个转化过程中存在语义丢失、标签内含信息减弱等问题。如何准确刻画社会化标注过程中形成的用户-资源-标签三元关系并保持它们内在关联信息而不割裂这种联系,成为标签相似性指标构建过程中迫切需要解决的问题。
超图和超网络理论[3]的出现,为更好地认识和理解大量现实复杂系统提供了新思路。在超图和超网络中,一条超边可以连接若干相同或不同的节点。在社会化标注中,可以利用超边联系用户一次标注活动中的用户、资源和标签,从而保持用户-资源-标签的三元结构之间的内在联系信息。为此提出基于超网络的标签相似性度量方法,在构建社会化标签超网络基础上,建立刻画标签相似性的度量指标,并利用链路预测的AUC和Precision评价方法对构建的相似性指标的有效性展开实验验证研究。
1 相关工作
自社会化标签出现以来,因其为信息资源的组织、共享和推荐提供了新思路和新维度,基于标签的链路预测和推荐的研究和应用也随即展开,主要形成了基于向量或张量[4]、基于图或网络[5]和基于主题[6]等方法。标签相似性度量是对标签之间共同语义特征的量化表示,一种常见的方法是将用户-资源-标签的三元关系映射转化为向量空间,通过采用如余弦相似度等指标计算标签向量间的相似性[7]。结合频率和用户评分[8]、考虑标签时序特征[2]等其他要素的方法也得到了探讨。基于向量空间模型的标签相似性度量需要将用户-资源-标签三元关系映射转化为向量空间,容易造成用户-资源-标签三元关系的语义丢失和向量空间高维、稀疏问题。为解决这些问题,可将张量应用于社会化标注中,利用基于多元关系的张量分解方法进行标签相似性评估与预测[9]。
社会化标注形成的用户-资源-标签三元关系可抽象表示为二部图或三部图模型,所以基于二部图/三部图的物质扩散模型成为了另一种标签相似度度量及链路预测和推荐的重要方法,如ZHANG等[5]将物质扩散原理分别运用于用户-资源和资源-标签两个二部图中获得了比单一的二部图更好的推荐效果。社会化标签的三部图模型中存在用户、资源、标签三种不同类节点,其边仅存在于不同类节点之间,割裂了同类节点之间的共现关系。针对这一问题,张昌利等[10]、吴小兰和章成志[11]在社会化标签三部图基础上构建了标签共现网络G(T,E),其中T为点集,代表了系统中所有的标签,E∈T×T为边集,连接了具有共现关系的标签。该网络是一种典型的复杂网络,其拓扑结构刻画了标签的语义关联关系。研究表明,标签共现网络对标签语义相似度的影响主要体现于局部拓扑结构[10],因此根据网络拓扑结构和复杂网络节点相似性理论[12],可定义如表1所示的基于标签共现网络局部信息的标签相似性度量指标。

表1 基于标签共现网络局部信息的标签相似性度量指标
表1中,Γ(x)为连接节点x所有边集合,即节点x的邻居节点集合,k(x)=|Γ(x)| 表示节点x连接边的数量或邻居节点数量,称为节点x的度。其中CN指标为基础指标,表示节点x和y之间共有边(邻居)的数量,表达了共同邻居特征。依据社会网络分析中的三元闭包原理,认为节点间共有邻居越多则这两个节点越相似。Sa,Ja,So,HPI和HDI这五个指标在CN基础上,采用不同方式考虑了节点x或/和y节点度的反向作用,即节点x或/和y的邻居数越多,那么在节点x和y之间共有邻居数量相同的情况下,它们之间越不相似。RA和AA指标根据节点x和y共有邻居节点的度构建相似性指标,表示它们共有邻居节点的度越大,那么节点x和y之间的相似性越低,RA直接采用x和y共有邻居节点的度为分母,AA通过对数弱化直接取节点度的影响。表1中的指标分别从标签共现网络结构的不同侧面刻画了标签相似性指标,这些指标在不同的情景下有不同表现,复杂网络的实验表明CN,AA,RA等指标通常具有更好的表现[12]。
2 基于超网络的标签相似性指标构建
2.1 社会化标签超网络的构建
在社会化标签系统中,用户U通过标签T标注资源I,这种联系可抽象表示为三部图模型F(U,I,T,Y),其中U、I、T分别表示用户、资源和标签的有限集,Y为三者之间标注关系的集合[7]。对于任意的(u,i,t) 三元组,如果三者之间满足标注关系则Y(u,i,t)=1,否则Y(u,i,t)=0。基于上述概念构建社会化标签超网络模型。
设对于一个以标签为节点的超网络H=(E,V),其中V表示标签节点集合,E表示超边,代表一次标注活动,若:(1)E={E(u,i)|(u,i)∈U×I∩au,i=1},(2)E(u,i)={vt|t∈T∩Y(u,i,t)=1},则超网络H=(E,V)定义为社会化标签超网络。由上述定义可知,该超网络的节点为用户标注的标签,超边为用户的每次标注活动,其中E={E(u,i)|(u,i)∈U×I∩au,i=1}代表了标注活动中由用户-资源二元组(u,i)所组成的边集,而在边集E中的每一条超边E(u,i)={vt|t∈T∩Y(u,i,t)=1}都连接了在一次标注活动中用户标注资源所使用的标签。
2.2 社会化标签相似性指标构建
在社会化标签超网络中,用户和资源被组合起来形成了超边,一条超边对应于一个用户对一个资源的标注,标签是具体标注的结果。在标注过程中,对同一资源而言,其内容范畴通常是一定的,代表对资源描述的不同标签在语义和内容上很可能具有一定的相似性;同样,对同一用户而言,在标注中使用词汇的习惯以及对资源的理解也是相对稳定的,那么被频繁用于标注一个资源的标签之间也很可能是相似的。在社会化标签超网络中就对应为:同一个超边连接两个标签节点的次数越多,这两个标签就越可能相似。此外,在社会化标签系统中用户可以使用多个标签对资源进行标注,如果资源难以描述或者资源涵盖内容范围比较大,那么用户为求更准确的描述就会倾向于使用多个标签进行标注,此时标签描述的跨度就会更大,标签之间的联系不那么紧密。社交网络中存在类似现象,如果一个人交际十分广泛,那么他可能与大多数朋友都只是泛泛之交。因此可认为,在每次标注过程中,用户使用更多的标签标注资源,那么这些标签之间的相似性可能就会变弱。
基于上述对用户标注过程中使用的标签相似性的分析,结合基于对象关系刻画对象联系与相近程度的邻近联系法则与三元闭包原理,根据社会化标签超网络的拓扑结构,提出了基于超网络的构建社会化标签相似性度量指标的两个基本原则。(1)共超边原则:两个标签节点存在的共有超边数越多,那么这两个标签节点就越相似,即两个标签被用户共同使用来标注资源的频率越高,这两个标签越相似。(2)超边包含节点数原则:一条超边所连接(包含)的标签节点数越少,那么这些标签节点就越相似,即用户在标注一个资源时,使用的标签数量越少,这些标签间的相似性就越高。借鉴复杂网络中的节点间相似性指标构建的基本逻辑,建立了基于超网络的社会化标签相似性度量指标,如表2所示。
表2中,B(x)表示给定社会化标签超网络中的标签节点x的超边集合,B(x)={E(u,i)|(u,i)∈U×I×Y(u,I,t)=1},|B(x)|为包括标签节点x的超边数量,称为节点的超度;z∈B(x)∩B(y),表示同时连接两个标签节点x,y的一条超边,k(z)=|z|表示被超边z连接的标签节点个数。
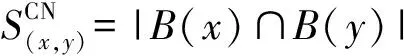
3 实验研究与结果分析
3.1 数据集与实验设计
为验证构建的基于超网络的社会化标签相似性度量指标的有效性,实验选取来自Delicious和Last.fm这两个具有代表性社会化标签应用平台的数据。数据集中每条记录由用户、资源、标签和标注时间4个字段构成,若多个标签用于用户的一次标注,则由多条记录进行表示。表3和表4为数据示例和数据集统计信息。
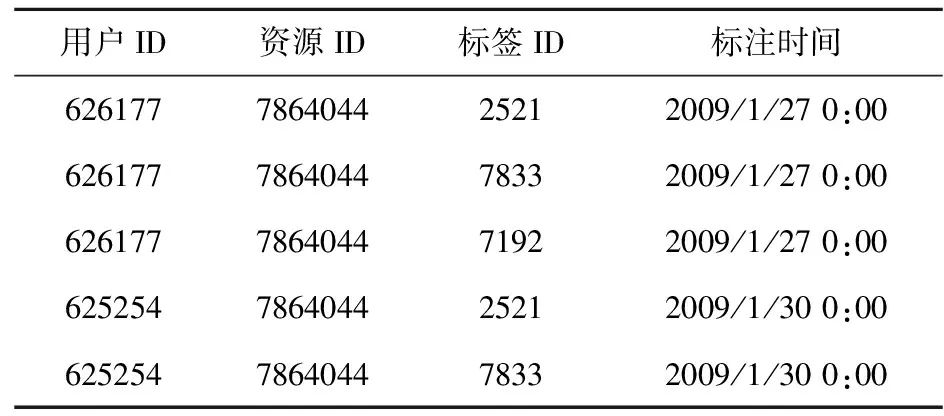
表3 原始数据集数据样例
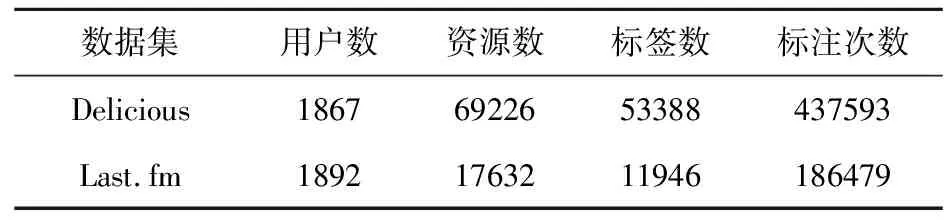
表4 实验研究的数据集基本信息
本文采用网络的链路预测实验方法开展实验设计,通过客观的链路预测指标AUC和Precision对实验结果进行评估。AUC指标从整体上衡量相似性指标的准确性,表示测试集中的边的分数值比随机选择的一个不存在的边分数值高的概率,即每次随机从测试集中选一条边与随机选取的不存在的边进行比较,如果测试集中边的分数值大,则加1分,如果两分数值相等加0.5分,若实验独立比较n次,其中n′次得1分,n″次得0.5分,则AUC=(n′+0.5n″)/n。AUC的大小代表了整体预测结果的准确性,AUC越大表示相似度指标越准确。Precision则只考虑排在前L位的边预测是否准确,如果排在前L位的边中有m个在测试集中则Precision=m/L。Precision代表相似性较高的节点对的预测准确性,其值越大预测越准确(本实验研究中L=100)。为更客观地进行实验评估,利用K折交叉验证将基于超网络构建的社会化标签相似性度量指标与基于标签共现网络构建的指标进行对比评估。
3.2 结果分析
基于标签超网络和基于标签共现网络的标签相似性指标在Delicious和Last.fm两个数据集上链路预测实验得到的AUC和Precision结果如图1-图4所示。
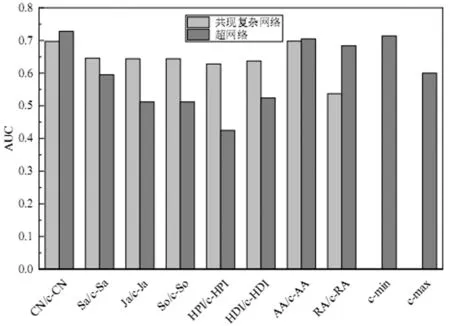
图1 Delicious数据集超网络与共现复杂网络各指标的AUC结果
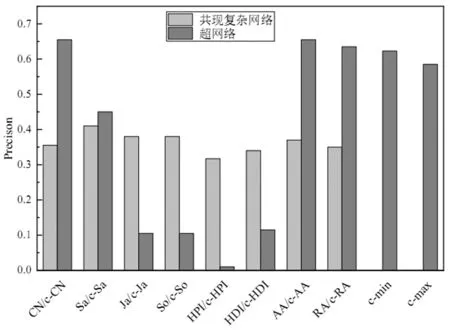
图2 Delicious数据集超网络与共现复杂网络各指标的Precision结果

图3 Last.fm数据集超网络与共现复杂网络各指标的AUC结果
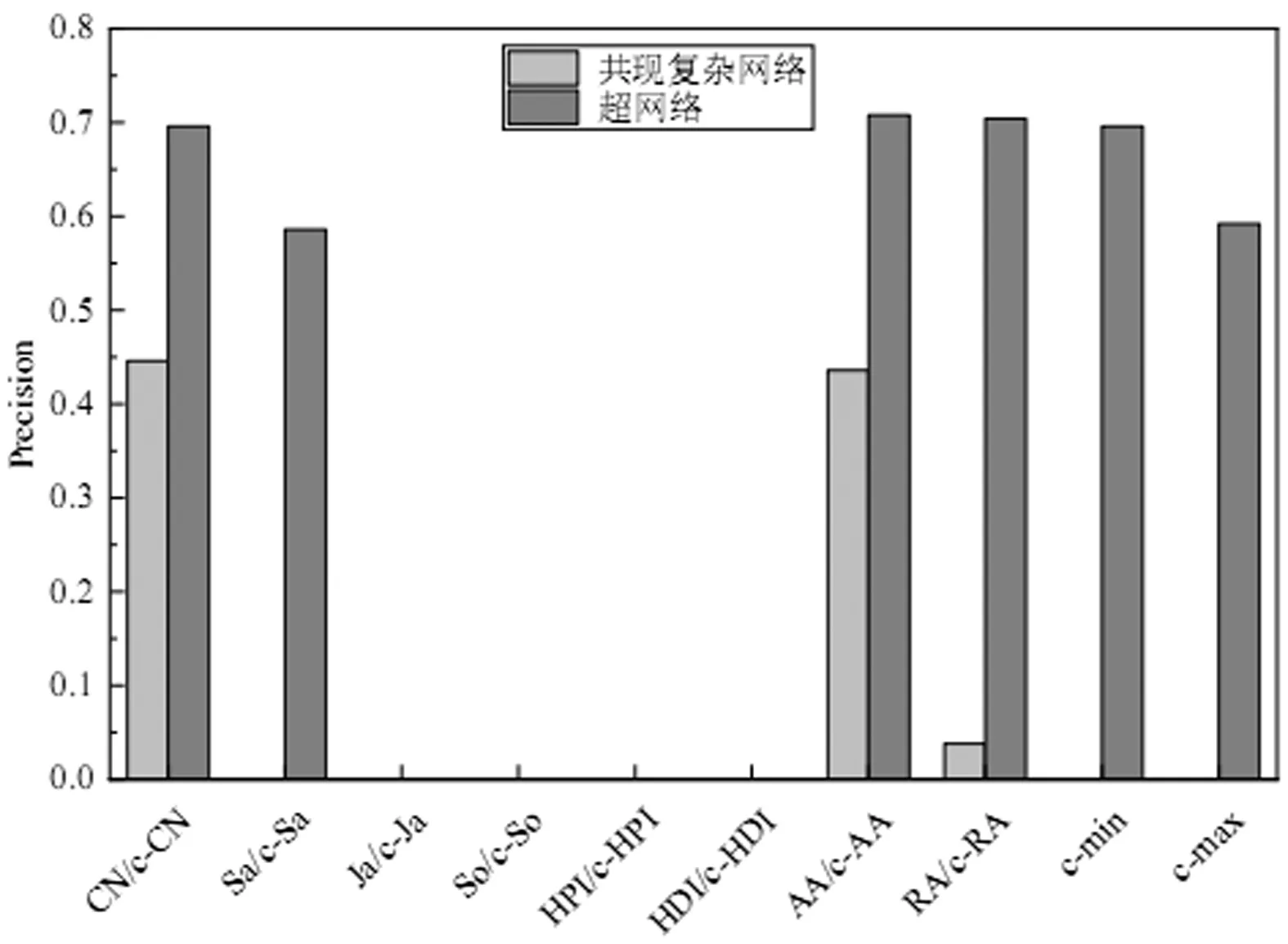
图4 Last.fm数据集超网络与共现复杂网络各指标的Precision结果
对于基于标签超网络的系列标签相似性指标,直接计算共有超边数量的c-CN指标在两个数据集中的AUC和Precision评估均具有较好表现,明显优于考虑其不同规范化的c-Sa,c-Ja,c-So,c-HPI和c-HDI等指标,特别是对于Precision的评估表现。同时在共有超边基础上加入对超边中元素个数的考虑后得到的c-AA,c-RA,c-min和c-max指标表现与c-CN各有优劣,预测准确度均较高。因此由实验结果可表明:在基于超网络模型构建的标签相似度指标,共有超边越多的标签越相似,同时连接标签节点的超边中所包含的节点数越多则标签的相似度减弱。需要特别指出的是,在共有超边的基础上加入节点超度不同规范化形式所派生的指标表现较差,表明加入节点超度要素对标签相似性评估带来一定的负向影响。
通过图1-图4对比不难发现,在基于标签超网络的系列相似性指标中表现较为一致且比较好的c-CN,c-AA,c-RA,c-min和c-max这五个度量指标相较于基于标签共现网络的度量指标在链路预测的准确性上总体都有提升,相对而言,AUC评价的提升幅度要小于Precision评价的提升幅度。从评价指标的内在逻辑来看,AUC侧重于相似性指标整体预测准确性的评价,而Precision则侧重于对相似性较高的标签对的预测准确性评价。标签相似性的度量主要是为个性化推荐提供服务的,在基于标签的个性化推荐过程中,其推荐列表的项数是有限的,主要考虑的就是Top-N项,因而以Precision评价的预测准确性就显得更为重要。因此,从标签相似性度量的实践适用性角度看,这五个标签相似性度量指标在链路预测Precision评价方面的明显改进提升,对于个性化推荐的具体应用实践更具积极价值。
同时从图1-图4可以发现,基于标签超网络共超边原则构建的相似性指标中,加入节点超度要素进行规范化后的c-Sa,c-Ja,c-So,c-HPI和c-HDI这五个指标表现不佳,并且总体表现还不如与之相对应的基于标签共现网络的指标。可以从这些指标加入节点超度的负向影响和网络结构特征差异两方面进行初步解析。一般认为标签节点度或超度越大,表示其邻居数越多或被用来标注次数越多,那么它对标签之间的相似性带来负向影响,会弱化直接邻居或共超边的作用。这从标签共现网络的AA和RA指标比较中可以进一步证实,AA指标对节点度取对数作为权重进行规范化,削弱了节点度对指标的影响,所以在同一网络中比不取对数的RA指标获得更佳的结果。对于标签超网络和标签共现网络,由于节点超度和节点度在物理含义上的差异,其作用机制也不一样,造成了它们间的不同结果。此外,网络结构特征差异也是一个重要因素。在对Delicious和Last.fm的网络结构深入分析中发现,Last.fm中资源主要是音乐,内容相对比较集聚,因而标注的标签覆盖的范围也较小,对应的标签网络的紧密度就较高;而Delicious中资源是各类网站链接,涉及范围广,对应的标签网络的紧密度就不高。相关研究表明基于共有关系构建的节点相似性指标对稀疏网络具有更好的效果[17]。相对于Delicious而言,Last.fm标签网络密度较大,这也可能是在Last.fm数据集中,不管是基于标签超网络还是标签共现网络的相似性指标,其Precision评价都有多个指标的评价结果为0的一个重要原因。
4 结语
社会化标签作为Web 2.0的重要应用之一,构建起了用户与资源之间连接纽带。针对现有基于向量空间矩阵、二部图、三部图和标签共现网络等方法在标签相似性评估和标签链路预测与推荐中将用户-资源-标签三元内在关系进行转化映射造成不同程度标签语义联系丢失的问题,本文创新性地引入超网络模型以系统性地刻画用户-资源-标签三元内在关系,提出基于超网络的社会化标签相似性评估方法。该方法聚焦于用户的标注行为,以标签为节点,以用户标注活动为超边,通过超边连接标注活动中的用户、资源和标签,构建社会化标签超网络,从而准确真实地刻画出用户的标注行为,并保持了用户-资源-标签三元关系的内在语义联系信息。建立基于超网络的社会化标签相似性度量的两个基本原则:共有超边原则和超边包含节点数原则,并据此构建系列的基于超网络的社会化标签相似性度量指标。选取来自Delicious和Last.fm两个代表性社会化标签应用的数据集,利用链路预测的AUC和Precision评价准则开展实验验证,结果表明,基于单纯共超边原则以及综合共超边与超边包含节点数原则构建的基于超网络的标签相似性指标表现良好,与基于标签共现网络构建的标签相似性度量指标相比提升明显,对于基于标签的链路预测和个性化推荐具有较高的实践应用价值。
从现有实验结果来看,与标签共现网络相比,本文提出的基于标签超网络的标签相似性度量方法,在反映Top N预测的Precision评价结果有较大改进,而反映整体预测效果的AUC评价结果改进相对不显著。提出的基于超网络的社会化标签相似性度量指标,主要是基于标签节点共有超边和共有超边包含的节点数这两个基本的网络结构特征构建的,但标签语义相似度的影响情况是比较复杂的,比如在网络中有“弱连接效应”[18]的现象,这可能会影响以共超边这种反映强连接关系的预测效果,从而影响了反映整体预测效果的AUC评价结果,而目前在这方面还没有成熟的研究结论可供借鉴[3],后期在这方面值得探究。此外社会化标签超网络的其他一些拓扑结构特征,如节点间的路径及其距离,下一步也可进一步挖掘这些拓扑结构特征与标签节点相似性之间的关系,进而优化改进社会化标签相似性度量指标。
