微博数据爬虫的检测方法研究
2023-10-30黄志高
黄志高
(泉州师范学院物理与信息工程学院,泉州 362000)
0 引言
网络爬虫在各个领域用于收集数据,即使目标站点禁止机器人爬虫,某些网络爬虫也会收集数据,某些Web 服务尝试通过反爬虫程序方法检测爬虫活动并阻止爬虫程序访问网页,但某些恶意Web 爬虫通过修改其标头值或分发源IP 地址来伪装自己[1],从而绕过检测方法,就好像它们是普通用户一样。
一些公司禁止网络爬虫访问他们的网页,原因如下:首先,网络爬虫可能会降低网络服务器的可用性;其次,网络服务器中的内容被视为公司的知识产权。竞争公司可以复制网络服务器中提供的全部数据,竞争公司可能会向客户提供类似的服务。本文研究了传统的反爬虫方法和各种回避技术,表明传统的反爬虫方法不能阻止分布式爬虫。然后,提出了一种新的反爬虫方法,即长尾阈值模型(LTM)方法,该方法逐渐将分布式爬虫的节点IP 地址添加到阻止列表中。实验结果表明,该方法能够有效识别误报率为0.02%的分布式爬虫。在传统的基于频率的方法中[2],当增加阈值以检测更多的爬虫节点时,误报也会相应增加。
1 传统反爬虫方法及其缺陷
1.1 使用HTTP标头信息进行过滤
基本爬虫程序发送请求而不修改其标头信息,Web 服务器可以通过检查请求标头来区分合法用户和爬虫程序,此标头检查方法是一种基本的反爬虫方法。但是,如果爬虫试图将自己伪装成合法用户,它将使用来自Web 浏览器的标头信息或类似于浏览器的HTTP 标头信息重置[3]。这使得Web 服务器很难通过简单地检查请求标头来确定客户端是爬虫程序还是合法用户。
1.2 基于访问模式的反爬虫
基于访问模式的反爬虫方法根据客户端生成的请求模式将合法用户与爬虫程序进行分类。如果客户端仅连续请求特定网页,而不调用通常应请求的网页,则该客户端将被视为爬虫程序。执行主动爬虫的爬虫程序预定义了爬虫程序想要收集的核心网页,爬虫程序请求特定的网页而不请求不必要的网页。在这种情况下,Web 服务器可以识别客户端不是合法用户。通过分析客户端访问模式的Web 服务,该服务可以根据预定义的普通用户的访问模式将爬虫程序与普通用户区分开来。虽然这种方法可以根据访问模式识别爬虫,但一些爬虫甚至通过分析网络日志来伪装他们的访问模式。
1.3 基于访问频率的反爬虫
基于访问频率的反爬虫方法通过访问频率阈值作为特定时间范围内的最大访问次数来确定客户端是爬虫还是合法用户。如果来自客户端的请求数在预定义的持续时间内超过某个阈值,则Web 服务器会将客户端分类为爬虫程序。这种方法有两个众所周知的问题。首先,它对分布式爬虫有漏洞。如果攻击者使用分布式爬虫(如Crawlera),则可以管理每个爬虫节点的访问速率保持在阈值以下[4]。其次,普通用户和爬虫程序共享单个公共IP 地址,容易被误识别为爬虫程序。
2 阻止分布式爬虫
如上所述,分布式爬虫程序可以绕过传统的反爬虫方法。我们提出了一种新技术来检测和阻止传统反爬虫技术无法防御的分布式爬虫。
2.1 所需的爬虫节点数
为了使分布式爬虫收集网站的全部数据,必须满足以下条件:
其中:Um是一个月内更新的项目数,Td是每个IP 地址的最大请求数,Cn是爬虫程序节点数(IP 地址),30 是一个月的天数。Td乘以 30 得到每月的请求数。
爬虫程序节点需要收集每月所有更新的数据。每月更新数据数除以每月最大请求数。例如,如果一个月内有Web 服务更新30000 个项目,并且该服务具有限制规则,即具有多个(例如100)请求的IP 地址将被阻止,并且尝试从Web 服务收集每个项目的攻击者将需要例如10个爬虫程序节点来避免限制。因此,随着Um增加或Td减少,应该增加Cn并以数字表示网站难以抓取的级别。
2.2 生成长尾区域
一个月内更新的项目数量不能随意增加。因此,防止分布式爬虫的一种简单方法是Td减少,但这也会显着增加误报。在本文中,我们通过反转Web 流量的一般特征并利用分布式爬虫尝试复制Web 服务器的整个数据的事实来解决这个问题。如果项目按访问率排序,我们可以在图表中看到指数递减曲线,如图1 所示。大多数网络流量集中在最常请求的项目上,并且有一个长尾区域具有较低的访问率。我们计算了此长尾区域的最大请求计数,并将此值设置为Td3。
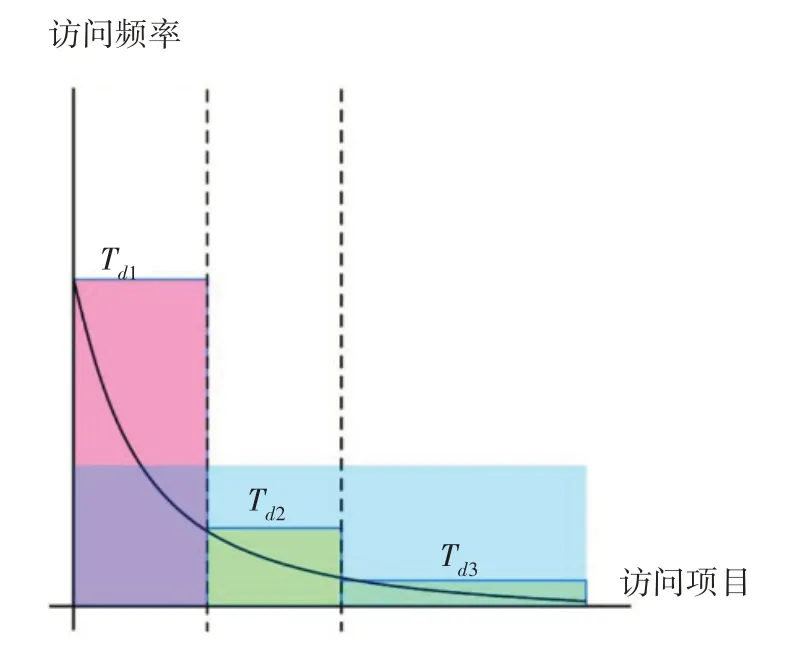
图1 每个链接的访问频率
在信息论中,不太可能的事件比可能的事件更具信息量,而长尾地区的事件比其他事件更不可能。这意味着Web 服务可以从长尾区域的请求中查找更多信息。因此,当客户端不断请求长尾区域中的项目时,Web 服务可以增加计数,直到达到Td3,而不是达到Td平均值。这意味着Web 服务可以设置更敏感的阈值,而不会增加误报率。
2.3 长尾区域节点缩减
为了使攻击者从Web 服务收集整个数据,攻击者还必须访问长尾区域中的项目。但是,攻击者并不确切知道哪些项目属于长尾区域。利用这种信息不对称性,服务提供商可以轻松识别比其他IP 地址更频繁地访问项目的IP 地址。这些已识别的爬虫程序的IP 地址将包含在阻止列表中,并且阻止列表中的IP 地址数将为Cm。如果我们开始通过长尾间隔增加该Cm值,攻击者将使用较少数量的IP 地址进行爬行,并且会在Td间隔内增加Cm[5]。
2.4 虚拟项目
服务提供商可能会添加虚拟项目来检测爬虫程序,并且合法用户无法访问虚拟项目,因为虚拟项目没有用户界面或隐藏。生成虚拟项目的方法很少,它可能以HTML 标签的形式存在,但属性设置不会显示在屏幕上,或者可能包含普通用户不感兴趣的垃圾信息。但是,对服务执行顺序访问的爬虫程序可能会访问虚拟项目。通过这一特性,虚拟项目可以作为长尾区域的延伸。在本文中,我们不会在实验中包含虚拟项目,以便与不包含任何虚拟项目的真实流量日志进行公平比较[6]。
3 实验测试
实验旨在评估爬虫检测模块对网络流量的分类性能。将LTM 方法与基于正常访问频率的反爬虫方法在爬虫节点的最大数量和误报率上进行了比较[7]。在实验中使用这个数据集有两个因素,一个是用户数,另一个是网站中的项目数。用户数量很重要,因为如果用户数量较少,某些用户可能会偏向流量模式。为了实现这一目标,我们开发了一个基于Python 的数据工具和一个模拟器。在数据预处理工具中,如图2所示对原始流量数据进行预处理,以计算单个URL 的访问频率,并对属于长尾区域的集进行分类。每当发生新的访问时,模拟器根据预处理的数据确定访问节点是否为爬虫程序。
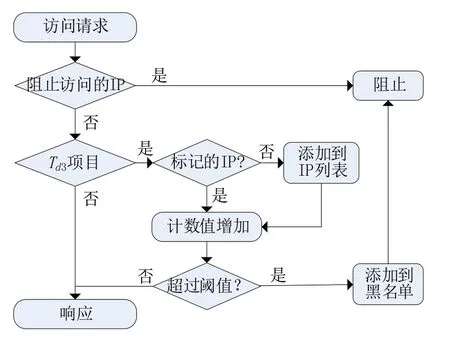
图2 爬虫检测流程
3.1 数据源
NASA 在2005 年7月共公布了2493425份访问日志。我们将这些日志解析为csv 格式,该格式由四列组成,包括IP 地址、日期、访问目标和访问结果。连接的IP 地址总数为41958,项目数为21534。
3.2 数据预处理和流量分配
我们在实验的预处理阶段执行了三个步骤。第一步将日志拆分为两个数据集:训练集和测试集。在NASA 访问日志中,前24 天日志设置为训练集,最后一个日志设置为测试集。第二步筛选出一些访问日志,以计算更准确的访问计数。某些请求合并为单个请求,以防止重复计数。例如,当用户访问html 文件时,他们还可以访问链接的图像文件。这可能会强制访问计数成倍增加。因此,我们删除了一些对图像文件的请求。此外,我们还从实验中排除了访问结果不成功的请求日志。
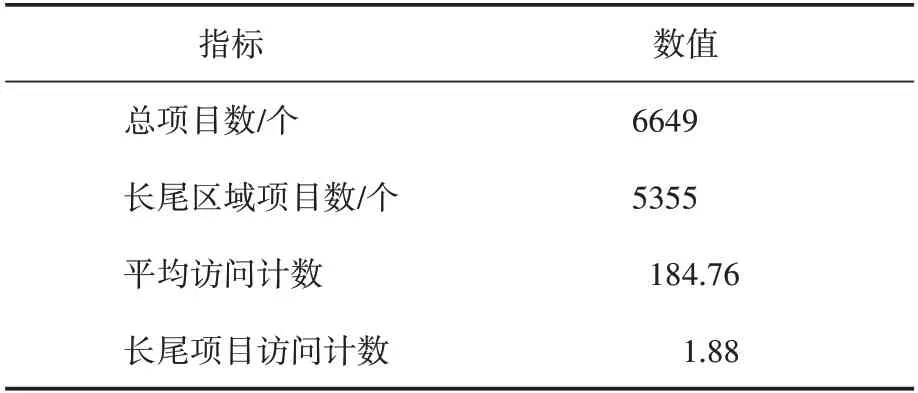
表1 预处理的网络流量数据
实验中构建了一个预处理的流量数据集,该数据集由来自21649 个原始数据的6649 个项目组成,并且它有一个由5355 个项目组成的长尾区域。总访问数平均值为184.76,长尾区的平均访问数为1.88。两个平均值之间的差异只是表明可以在爬虫检测算法中设置一个更灵敏的阈值。
实验还统计了按访问频率排序时最常访问的链接,到最不常访问的链接的特征[8]。比率是指按访问计数对所有项目进行排序时每个组所在的间隔。访问平均值是指属于每个组的每个项目的平均访问次数,最大访问量是指每个组中项目之间的最大访问计数。
3.3 虚拟仿真
在仿真实验中,检查LTM 是否能够检测和禁用分布式爬虫程序IP 地址组,将实际Web 流量输入到LTM 时检查误报率。整个爬虫程序检测流程如图2所示。
3.4 分布式爬虫检测模拟
从表2的实验数据,我们可以观察到爬虫IP地址集合逐渐减少,直到所有IP 地址都被完全阻止。当第一个爬虫节点IP 地址超过Td3阈值IP被封禁,节点减少计数呈指数级增长。这是因为其他爬虫节点得到了更多的访问负荷,并且当爬虫节点被访问时,更多的项目必须访问被阻止。
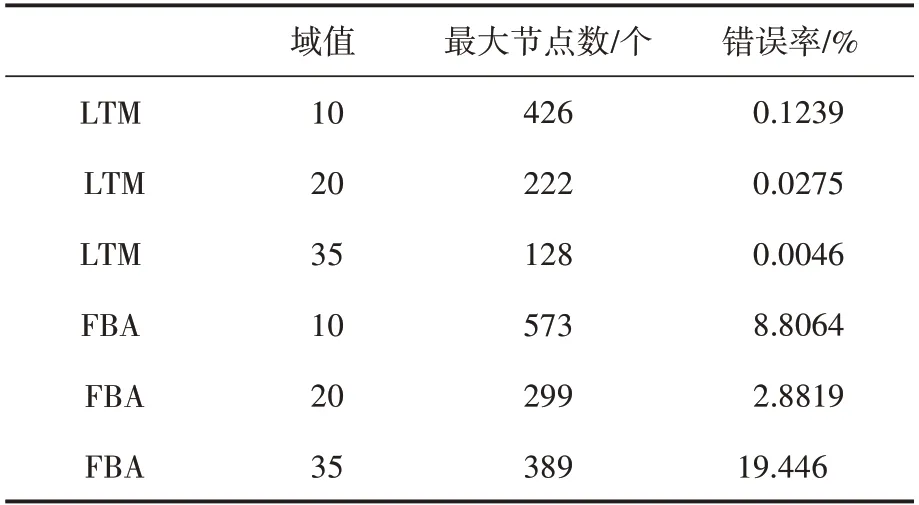
表2 实验数据
实验阈值设置为20,爬虫项目包含222 节点。LTM 检测到了整个爬虫项目所有节点,错误率约为0.0275%,远低于传统的基于频率的爬虫检测方法。在表2 中,我们将LTM 的结果与通用的基于频率的反爬虫(FBA)方法的结果进行了比较。LTM 对分布式的爬虫检测性能非常依赖于项目的数量和长尾比率。考虑到这个限制,仿真实验是使用旧的NASA 交通数据进行[9],项目的总数比通常的现代网络项目要小得多。如果有10 倍数据和类似访问的频率分布的项目,我们提出的方法可以从由2000 个节点组成的网络项目中检测出分布式爬虫。
在实验中,LTM 达到了最小的错误率为0.0046%,而FBA 仅达到0.0367%,这意味着LTM 的检测可靠性比经典FBA 方法提高了500%。当我们将阈值设置为35,这时LTM 达到最小误报率的值,FBA 方法比LTM 方法多了19.400%的误报率。
4 结语
本文介绍了长尾阈值模型(LTM),并展示了LTM 如何有效地检测分布式爬虫,相比之下先前的方法是脆弱的。通过模拟真实的网络流量数据,LTM 有效地识别了分布式爬虫,并显示出极低的误报率。针对网络服务的非法网络爬取成为严重的安全威胁[10]。考虑到一些爬虫开发者将分布式爬虫代理服务用于非法目的,LTM 可以提高网络服务的数据安全性。
