面向电力领域自然语言理解的数据增强研究与实现
2023-10-30施俊威
施俊威,宋 晖
(东华大学计算机科学与技术学院,上海 201620)
0 引言
随着人工智能技术的不断发展和应用,电力领域也逐渐迎来了智能化转型的浪潮。在电力行业中,用户往往通过人工客服和电力公司网站等传统方式获取与用电相关的各种信息,然而,这些方式存在着诸多问题,如人工客服效率低、需要等待时间长。因此,在人工智能系统与电力系统的融合中,智能问答成为一种重要的应用方式和技术手段,将自然语言处理技术应用于电力系统中,提高沟通效率和工作效率,节省了人力资源[1],使电力系统向自动化、智能化方向发展[2]。
在电力领域的智能问答中正确地理解用户的问题至关重要,目前通常采用自然语言理解(NLU)模型来实现[2]。在面向电力营销指标问答的应用时,由于业务场景很多,需要识别的槽也很多,直接标注企业提供的少量问题,构建NLU 模型,识别准确率只能达到60%左右,离实际应用要求相去甚远。研究表明,大量的训练数据能够显著提高NLU 模型的准确性[3]。在实际应用中,用户和企业提供的领域问题数据并不能满足模型训练要求,并且人工数据标注的成本大,所以需要使用数据增强技术生成大量的电力领域样本数据,以此满足NLU 模型训练需求。
传统的文本数据增强方法包含词汇替换、文本表面转换以及随机噪声注入[4]。但是在面向电力领域NLU 任务里,通过使用这些方法生成的文本不能保证文本语义的连贯性和文本多样性,这会导致NLU 模型性能下降[5],因此考虑采用生成式模型生成问题样本,生成模型能够基于给出的关键词生成问题句。我们首先通过槽值替换方法获得部分样本,再利用这些样本一起训练生成式模型。
目前生成式模型的解码方法一般是基于集集中搜索[6],其生成的文本会出现重复词或者多个同类型词连续出现,导致生成的文本语义不正确。本文提出了一种基于对比搜索[7]关键词文本生成模型(neural text generaion with contrastive search,CSTG)。在文本生成过程中,生成的输出应该从模型预测的最有可能的候选词集合中选择,生成的输出应该具有充分的区分性,以便于与前文上下文的关系进行区分。通过这种方式,在电力领域样本数据生成任务中,模型所生成的问题文本既能够更好地保持语义连贯性,同时避免模型退化和在生成的文本中出现连续的重复词。实验结果表明,该模型降低了生成电力领域问题文本的重复率,从而使得训练后的NLU模型能够更加准确地理解用户的问题,提升电力指标检索系统的准确率。
1 基于对比搜索关键词文本生成模型
1.1 模型框架
在电力领域的指标问答应用中,NLU模型需要理解用户问句对应的业务领域、指标问法,以及关键槽值。如领域domain为配变异常,指标意图intent为query_total,槽和对应的槽值slots:{“org”:“南因供电所”,“time”:“2022 年 1月”,“detail”:“情况”}。
我们首先使用传统的槽替换、值替换等方法,基于用户提供的典型和应用系统数据,获得的样本数据作为训练数据集,用于训练问题生成模型:模型将问题句的各种槽值(关键字)作为输入,输出一段完整的文本,该段文本应尽可能包含这些给定的领域关键词。输入领域关键词包含售电量、石家庄、3月和排名,经过模型的文本生成,生成完整的文本:“今年3月份在石家庄的售电量排名是多少?”
本文设计了CSTG模型来实现生成过程,该模型是基于注意力机制的LSTM文本生成模型[8],如图1所示。根据输入的电力领域关键词W生成与电力领域关键词相关的问题文本。
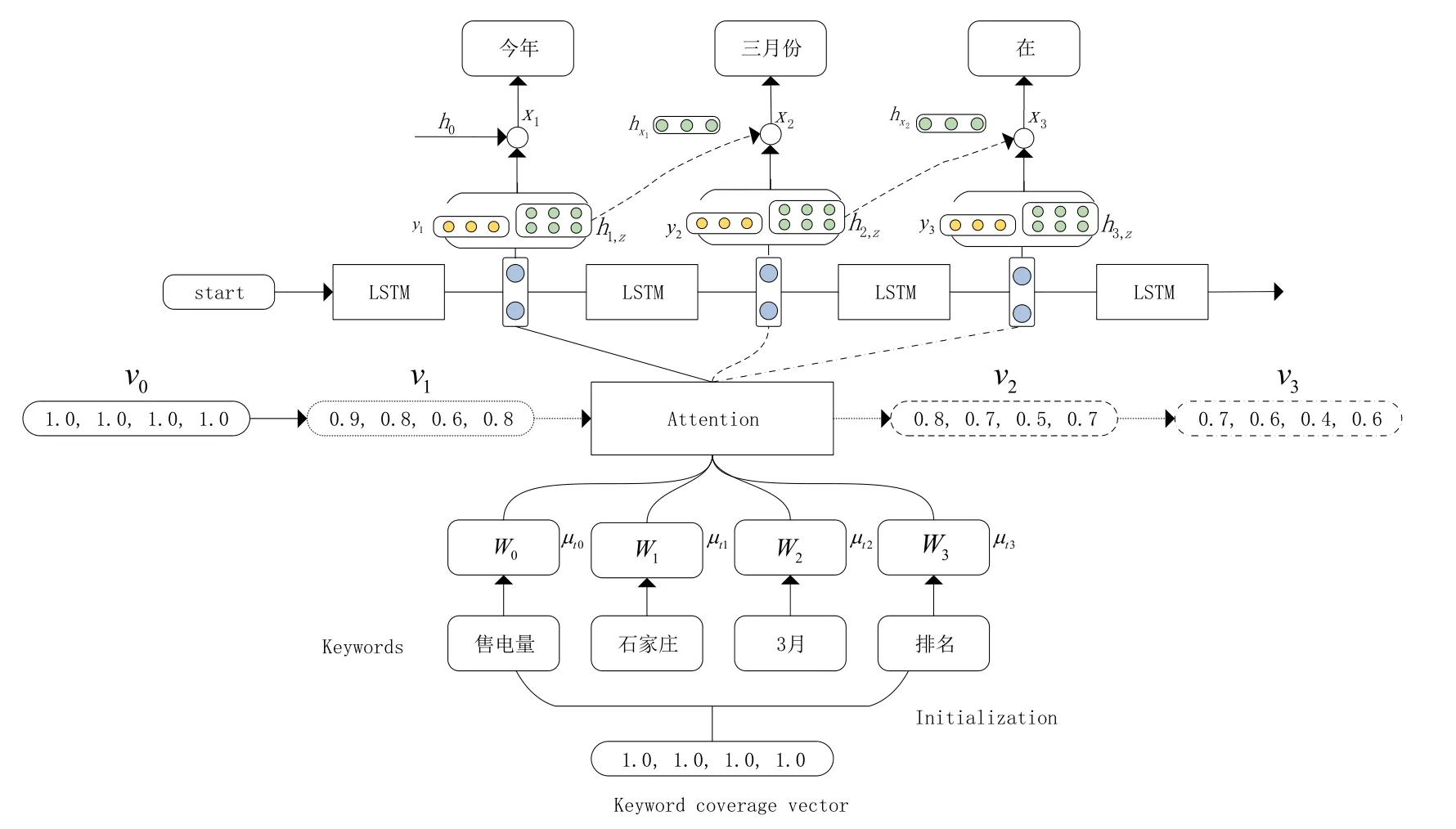
图1 模型结构
CSTG模型由编码和解码两部分组成,在编码部分,主要包含对关键词的编码以及设置关键词表达的覆盖向量,覆盖向量是控制关键词在文本生成中被表达的权重值向量,使得关键词尽可能地在文本中被表达出来。在解码部分,包含注意力模块和解码策略,注意力模块让解码器基于自身历史输出,来计算输出。解码策略则基于所给候选词选择最优项作为输出。
1.1.1 编码
在模型的编码阶段,首先模型将输入的关键词通过一个词嵌入层转换成向量表示W,然后,通过引入注意力参数μ,我们可以将每个关键词表示为Tt,并将每个关键词的语义通过注意力机制传递到生成的单词中,该注意力参数定义为一个向量:μ1、μ2、…、μk,其中μi表示领域关键词词汇i的分数。在时间步t生成文本时,Tt的计算公式如下:
其中,Wj表示第j个关键词的编码张量,μtj的计算方式如下:
并且qtj的计算公式表示为
其中va,Xa和Ya是三个矩阵,在模型训练期间需要进行优化。
1.1.2 关键词覆盖向量
模型设置一个关于所给关键词的覆盖向量v,每一维度代表该关键词在将来的文本生成中被表达的程度,关键词覆盖向量通过一个参数φj进行更新,这个参数可以被视为关键词Wj的话语级重要性权重。该参数用于调整生成过程中领域关键词的表达程度,从而影响模型对关键词Wj的关注程度,使得生成的文本能够更好地符合关键词Wj的内容要求。在模型的生成过程中,模型会根据覆盖向量v和注意力机制调整生成策略,使得模型能够让未被表达的关键词在生成过程中表达,从而提升生成文本的可读性和完整性。在当前时间步t生成新的词时,第j个关键词Vt,j的计算方式如下:
其中μt,j表示第j个关键词在时间步t的注意力权重。φj=N·σ(Uf[T1,T2,…,Tk]),Uf∈。
在模型的训练过程中,可以利用已有的电力领域问题和关键词来训练模型的参数和关键词覆盖向量。在模型训练的过程中,可以采用基于梯度下降的方法对模型的参数和关键词覆盖向量进行更新。综合上述,基于关键词的文本生成模型可以帮助解决电力领域NLU 任务中数据数量不足的问题,提高训练数据的数量和质量,从而提高模型的性能和准确率。同时,利用关键词覆盖向量可以让模型更好地理解关键词,并根据关键词生成符合要求的文本。
1.2 模型解码
1.2.1 文本生成
模型在生成文本阶段,是基于上一个生成的词预测下一个词,下一个预测词的概率根据下式得出。
上式中模型在时间步t的隐层状态ht的公式如下所示:
一般生成式模型,在得到预测词的概率后会选择搜索算法,从候选词中选取较为合适的词作为生成文本。本文选用对比搜索作为模型的解码策略,生成语义正确的文本数据。
1.2.2 对比搜索
基于关键词的文本生成模型普遍的解码方法包括集中搜索、贪心搜索和随机采样,虽然这些方法在一般情况下可以保证生成文本的语义正确性,但是在电力领域中,领域词之间存在相似性,使用这些方法容易导致生成的文本出现重复词或连续生成同类词,从而影响生成文本的质量。究其原因,是因为解码算法没有对语言模型的偏差合理规避[9]。为此,在基于关键词的文本生成模型的基础上,可以采用对比搜索的解码方法来解决这一问题。对比搜索的方法会基于候选词的选中概率,在每个解码步骤中选择模型预测的最可能候选词集合,在选取最优候选词时,生成的输出与前一个上下文有足够的区别性,以避免模型的退化。这种方法可以更好地保持生成文本与前缀的语义连贯性,并避免生成的文本质量下降。
对比搜索是一种用于解码的策略。在每个解码步骤中,该策略会从模型预测的最有可能的候选集合中选择输出,以确保生成的文本与人类编写的前缀之间的语义一致,并保持生成文本的词汇相似度矩阵的稀疏性,从而避免模型退化。一般解码方法会选择概率最高的候选项作为输出,而候选集合通常包含模型预测的前k个最高概率的选项,k的取值通常为3到10。对比搜索引入了一项惩罚机制,用于评估候选项与先前上下文的可区分性,从而保证生成的文本具有足够的多样性。在时间步骤t,给定先前上下文x<t,选择输出xt的过程如下:
在上式中Z(k)是模型概率分布中前k个最高预测的候选集合,通常设置为3 到10。第一项模型置信度是模型预测的候选z的概率。第二项衰变惩罚度量候选z相对于先前上下文x<t的可区分性。s在公式中被定义为z的表示和x<t中所有tokens 的表示之间的相似度。这里ht,z是表示在当前时间步候选词在模型中的隐层状态。表示时间步t-1,选择的最优候选词的隐层状态,其中z的更大的退化惩罚意味着它更类似于上下文,因此更容易导致模型的退化。超参数θ∈[ 0,1] 调节这两个组件的重要性。当θ=0时,对比搜索退化为贪心搜索方法。
2 实验
2.1 数据集与实验设置
在当前的电力领域文本生成研究中,构建面向电力领域指标检索的问题数据集是非常关键的。样本数据集是JSON 的文件格式,每一条数据包含问题文本、领域、意图、槽及槽对应的槽值。为了能够更好地训练和评估电力领域的文本生成模型,选择了基于问题模板生成的电力营销领域样本数据,并从企业真实数据中获取了用电量、售电收入、投诉数量、地市排名等多个问题句类型的数据。
该数据集包含了20920条样本数据,其中训练集包含17500 条文本数据,测试集包含3420条文本数据。为了更好地模拟真实情况,数据集的关键词是选自于NLU 样本问题的槽数据,能够更好地体现电力领域的语境和特点。通过这样的数据集构建,可以为电力领域的文本生成研究提供更加真实、具有代表性的数据,有助于研究者们更加深入地探究电力营销领域文本生成模型的性能和应用场景。
2.2 实验设置
在模型的实现上,该模型是基于LSTM 的文本生成模型,其中使用到注意力机制,模型的超参数设置为:batch_size 为32,候选词的数量k为3,训练轮次为45,最大关键词词数为5,embedding_dim 为100,hidden_dim 为512,最大句子长度为128,学习率为1e-7,ReLU 作为激活函数。
2.3 评估指标
为了评估模型的性能,我们采用以下三个指标:
(1)Bleu 指标通过比较机器翻译结果与参考翻译之间的n-gram重叠率来进行评估。
(2)MAUVE 是一种衡量生成的文本和人类编写的文本之间的标记分布紧密度的指标。更高的MAUVE 分数意味着该模型生成更多类似人类的文本。
(3)rep-n这个指标以生成文本中重复n-gram的比例来衡量序列级别的重复,其中,n表示连续词语或字符的数量。该重复率越低代表所生成的文本出现重复词越少。对于所生成的文本n-gram级别的重复的定义如下:
(4)Diversity指标考虑到不同的n-gram 级别生成的重复,可以视为模型退化的整体评估,较低的多样性意味着模型退化得更加严重。其公式如下:
3 实验结果比较与分析
实验1通过在文本生成模型中使用不同解码方法,根据模型所生成的文本质量判断模型整体的性能。该实验中使用对比搜索和集中搜索两种解码方法,使用两种解码方法的模型在测试集中,实验1的结果见表1,使用对比搜索的模型相较于使用集中搜索提高了9%,说明在电力领域使用对比搜索相较于传统的集中搜索可以提高所生成文本的质量,模型的性能也会更好。
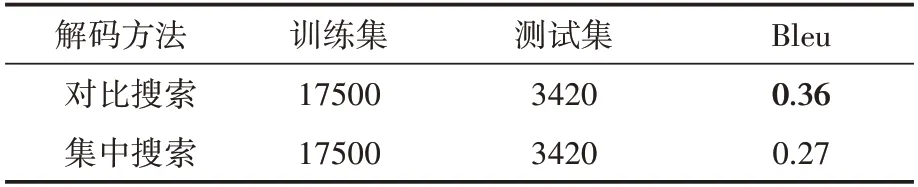
表1 模型性能实验结果
在实验2中,根据训练数据集已有的领域关键词利用已训练的模型生成4000 条文本,分别计算基于不同的解码方法所生成文本的文本重复率,以此评估生成的文本质量。实验结果见表2,不同模型所生成的文本的重复率使用不同的解码方法有了显著的下降,其中对比搜索相较于集中搜索,在Rep-2、Rep-3、Rep-4 三个指标上都有较为明显的下降,分别降低10.88、5.27、2.61,并且Diversity 与Mauve 指标有一定提高,对比搜索相较于贪心搜索和Nucleus Sampling 两种解码方法也有很大提升,表示对比搜索在该模型中能够显著降低生成文本的重复率,更好地保持模型生成文本与人类编写的文本之间的语义一致性以及保留生成文本的词汇相似度矩阵的稀疏性。

表2 不同解码方法对文本重复率的影响
此外,通过对实验2中所生成的文本进行分析,在模型训练数据集中,根据不同文本长度的文本数据对应的领域关键词生成文本,分析不同的文本长度对文本重复率是否产生影响。如表3所示。

表3 文本长度对重复率的影响
在电力领域数据集,平均文本长度分别为21.37和28.11,每种文本长度选取基于不同领域关键词生成的1800 条文本数据进行分析,其对比搜索的重复率指标Rep-2、Rep-3 和Rep-4 相较于集中搜索都有一定幅度的降低,整体重复率指标Diversity 有一定提高。在分析不同长度的文本数据中,使用对比搜索的解码方法相较于集中搜索取得更好的效果,基于对比搜索的模型所生成的文本,其重复率对于集中搜索有明显的下降。
4 结语
本文针对智能问答中电力指标检索系统的NLU 问题,训练NLU 模型,其需要大量的样本问题满足训练模型需要,但企业搜集的数据较少,人工标注成本较大,不能满足需要,因此使用数据增强技术生成大量样本数据。我们构建了一个面向电力领域的样本问题数据集,提出并使用CSTG 生成了与电力领域相关的问题样本。对比搜索的核心思想是在每个解码步骤中,从模型预测的最可能候选集中选择输出,保持生成文本与给定前缀之间的语义一致性和词汇的区分性,并避免模型的退化。实验结果表明,相对于传统的集中搜索,对比搜索能够生成更加准确和合理的电力领域问题,且能够有效地解决电力领域生成文本出现重复词的问题,一定程度上减少高频率文本的重复率[10],使得模型在各项评估指标都得到了提升,NLU 模型在使用模型所生成的文本数据后,模型识别用户意图的准确率有所提高,这也提升智能问答的电力指标检索的准确率。
