基于频域Transformer的对抗生成网络去运动模糊算法
2023-10-30顾军华牛炳鑫李春杰
顾军华,李 岩,陈 晨,牛炳鑫*,李春杰
(1.河北工业大学人工智能与数据科学学院,天津 300401;2.河北省大数据计算重点实验室(河北工业大学),天津 300401;3.河北高速公路集团有限公司,石家庄 050000)
0 引言
图像去模糊方法一般是尝试通过去除模糊伪影来将模糊图片恢复成清晰图像。图像中的模糊现象受到许多因素的影响,如快速运动的物体、失焦、抖动等。由于图像去模糊是一种不适定问题,从模糊图像恢复到清晰图像是一个比较具有挑战性的任务。基于模糊核估计的模型[1,2]一般是同时估计模糊图像的模糊核及其清晰图像。但模糊核估计方法对噪声比较敏感且目前的模糊核估计方法适应情况少。现实世界中大多数运动模糊情况都属于不均匀运动模糊,如十字路口一类的动态场景,会有多个物体以不同幅度向不同方向运动。在图像去模糊任务上,还有一类是端到端的方法,这一类方法无需估计模糊核。目前端到端的方法主要分有对抗和无对抗两大类,其中大部分模型均使用卷积神经网络(convolutional neural networks,CNN)进行设计。
目前基于CNN 的去模糊模型研究也都是尽量增大感受野以提高模型的恢复效果。虽然可以通过堆叠卷积层来提升感受野范围,但是堆叠过多的卷积层会增加参数量和计算量,并且更容易出现噪声。为了解决以上问题,本文提出了频域Transformer 图像去运动模糊模型。Transformer[3]的自注意力机制可以对自身及其他所有位置的像素来建立依赖关系,相当于拥有全局感受野。对于去模糊任务而言,越大的感受野越容易处理剧烈的运动模糊情况。Dosovitskiy等[4]提出的视觉 Transformer(vision transformer,ViT)模型证明了Transformer 在图像领域的可行性,并且相对于CNN 网络而言,Transformer 没有归纳偏差问题。Transformer虽然具有强大的表示能力,但是仅从空域层面处理图像还是不够的,因此提出了空频处理模块(spatial frequency processing module,SFPM)。通过傅里叶变换将数据从空域转换到频域,利用频率成分和空域图像间的对应关系,一些在空域难以表述的问题在频域就能迎刃而解。采用傅里叶变换转换到频域后通过其中的平行条纹很容易观察到运动模糊的方向和大小,因此对频域图进行分解操作可以充分利用运动模糊在频域图中所体现的方向性特征,从而更有效地恢复运动模糊。由于频域是有限的频率表示图像,仅从频域处理可能会损失某些信息,因此空域和频域一同处理可以达到互补的目的。
1 频域Transformer图像去运动模糊模型
端到端模型的目的是仅将模糊图像Ib作为输入来恢复清晰图像,不需要模糊核。在训练阶段,有两个网络需要训练,一个是鉴别器,用于区分生成的结果和真实的清晰图像;另一个是生成器,对其输入模糊图片,并输出一个足以骗过鉴别器的结果。
1.1 模型架构
如图1 所示,本文提出的网络基于生成对抗网络,由生成器和鉴别器两部分组成,以对抗方式进行训练。

图1 模型整体架构
训练过程中向生成器输入模糊图像,而不是像原生的生成对抗网络(generative adversarial network,GAN)[5]一样输入一个随机噪声向量。然后通过判别器比较生成器的输出与清晰图像之间的差异。其中生成器使用频域Transformer,判别器使用PatchGAN来进行对抗训练。
1.2 频域Transfoorrmmeerr生成器
生成器架构如图2所示,生成器整体采用U形结构并在编码器与解码器间加入了残差连接。给定一个模糊图片Ib=RH×W×3,其中H表示图像的高度,W表示图像的宽度,3 表示图像的RGB 通道,模型首先使用卷积层将输入映射到高维空间来得到特征图。然后将特征图传递到后面的SFPM 模块,每个SFPM 模块包括多个Transformer模块和一个频域处理模块,它们以并行的方式处理输入图像。映射后的特征图通过空频处理模块(spatial frequency processing module,SFPM)向下传递多层,每个空频处理模块包含多个Transformer块以及一个频域处理模块,两者以并行的方式进行工作。每经过一个空频处理模块进行一次下采样,下采样通过卷积实现。带有下采样部分的左半部分是生成器的编码器,右半部分则是解码器。解码器中首先通过PixelShuffle操作在不丢失信息的前提下进行上采样,然后输入到空频处理模块进行学习。最后通过一个精炼模块来对输出作最后的调整。

图2 生成器架构
Transformer 的自注意力机制能够学习全局之间的关系,但是直接用它来处理高分辨率图像,会使得训练速度变得很慢,并且对于硬件要求也更高。为了满足处理大分辨率图片的需求,引入了局部自注意力机制,通过设置一个窗口大小来控制自注意力的计算范围,有效减少了计算量。同时结合U 形网络,在浅层进行局部注意力计算,提取细节特征;在深层进行全局注意力计算,得到全局信息。编码器部分的每个SFPM 模块都包含卷积下采样操作,输入每通过编码器其中的一个SFPM,尺寸就会进行缩减,相应地,特征就会增加。当输入变得足够小时,就可以将自注意力应用于整个特征图,从而学习到全局信息。通过这种方法,既可以获得局部细节,又可以获得全局信息。在解码器部分使用的则是亚像素卷积上采样层,可以表示为如下公式:
1.3 空频处理模块
图像的退化过程可以理解为是将算子H作用在一个输入图片f(x,y)上来生成退化图像g(x,y)。如果算子H已知,那么可以很容易地将退化图像恢复成原始图像。但在很多情况下并不能得到这样一种准确的理想的算子,只能尽量近似它。根据卷积定理,空域中的卷积操作可以转换为频域乘法,因此一些直接在空间域表述非常困难,甚至不可能的任务在频域中变得非常普通。
空域中的卷积操作转化到频域可以简化为乘积操作,图3 中清晰图像的频域图(a)与频域模糊核(b)进行乘积可得模糊图像的频域图。同样地,模糊图像的频域图除以频域模糊核即可得到清晰图像的频域图。因此模型只需要拟合出图3(b)的倒数再乘上输入的模糊图像的频域图即可得到清晰图像。

图3 频域乘积示例
在现实世界中模糊图像与清晰图像在其频域图上仍然有明显的区别。场景中各种物体的边缘在频域图中相互叠加,频域中可见的条纹由整幅图像的抖动而来,图像的空域信息和频域信息可以相互补充,充分利用这两部分信息可以更好地抑制图像中的模糊伪影。空频处理模块设计如图4(a)所示,左侧为Transformer 分支,用于处理空域信息;右侧分支为频域处理分支,用于对频域图像进行处理。空域信息和频域信息并行处理,最后进行融合得到SFPM 模块的输出。随着U 形网络的加深,SFPM 模块所处理的特征维度就越高,且越注重全局信息,结合U 形网络的特点,频域处理模块更是可以关注不同层次大小的频域图信息。
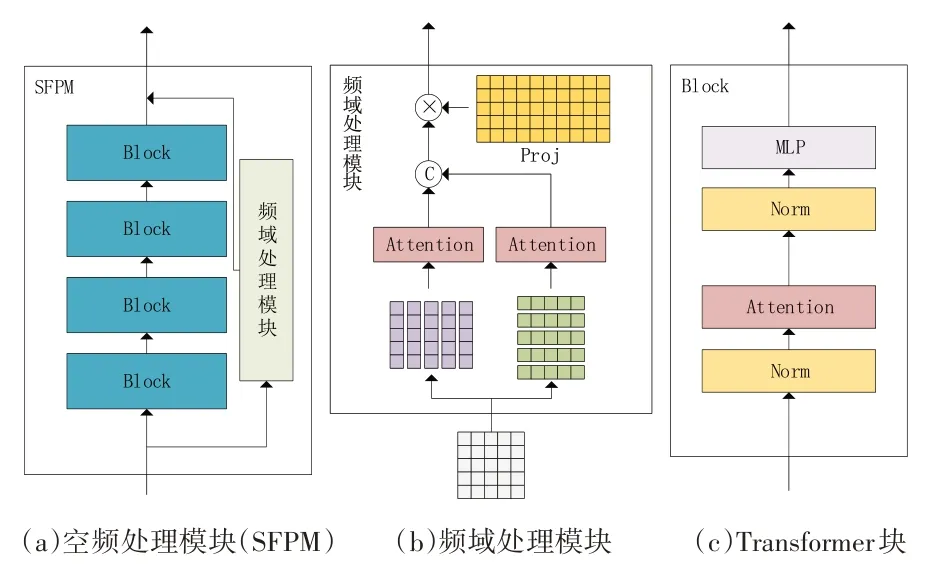
图4 空频处理模块内部结构
为了在频域对图像进行处理需要先将图像转换到频域,通过离散傅里叶变换(discrete fourier transform,DFT)转换而来的频域图可以清晰地反映运动模糊的方向与大小。再将频域图沿水平垂直方向进行分解,然后计算各自的注意力,可以充分利用运动模糊在频域中体现的特征,有效地恢复频域图。DFT 是采样后的傅里叶变换,它不包含组成图像的所有频率,可能会丢失一些细节信息,因此仅在频域处理是不够的,还要结合空域一起处理才能起到互补的作用。
由于模糊图像的频域图包含模糊图像中的运动方向及幅度,因此频域处理模块将频域图沿横纵轴进行分解,将不同方向的模糊频率分解为水平和垂直方向,然后对分解后的向量分别进行注意力计算。垂直分解的向量表示为i∈{1,…,W},其中W表示图像宽度;水平分解的向量表示为,j∈ {1,…,H},其中H表示图像高度。在分解后的向量进行注意力计算之前,首先对其特征维度使用1 × 1 的卷积层扩充至其自身的两倍,由于频域图中包含丰富的不同方向和幅度的频率,通过扩充分解向量的特征数有助于提高模块的表达能力,不会丢失关键信息。该步骤如下所示:
合并所有垂直分解向量的注意力输出即可得到垂直注意力输出Ov。以同样的方式对水平分解向量进行计算可得Oh。然后将垂直和水平的注意力输出合并起来并通过矩阵K∈ R2W×W×2C将输出映射为输入尺寸,并再次使用1 × 1 的卷积层对特征维度进行聚合,表示如下:
其中:O∈ RH×W×C表示模块的输出,iDFT表示离散傅里叶变换的逆运算。傅里叶变换中,低频主要决定图像在平滑区域中总体灰度级的显示,而高频决定图像细节部分,如边缘和噪声。模糊问题也可以理解为原本高频锐利的边缘经过模糊之后变得更平滑,因此去模糊任务就是从比较平滑的低频区域将原本应是高频边缘的部分恢复出来。
1.4 损失函数
原生GAN 的损失函数在两个数据分布完全不重合的时候,JS 散度恒为log 2,所以模型也无法更新。因此损失函数选用WGAN-GP[6]进行训练,公式如下:
其中:惩罚项对分布Ppenalty进行采样,分布Ppenalty介于Pdata与PG之间,只需要保证在该分布的采样的梯度范数小于等于1 即可。此外还增加了一个感知损失函数,感知损失认为生成图像是从内容图变换而来,通过计算内容损失不断迭代生成图片,使其越来越接近内容图。在去模糊任务中,生成图像指的是模糊图像,而内容图则是清晰图像。感知损失函数如下所示:
其中:j表示VGG 网络的第j层,CjHjWj表示第j层特征图的尺寸。将对抗损失函数和感知损失函数组合起来就是模型最终的损失函数,其中λ1和λ2是两个超参数:
2 实验部分
2.1 数据集
实验使用GoPro[7]数据集作为训练集和测试集。它由3214 幅模糊图像和对应的清晰图像组成,分辨率为1280 × 720,其中2103 对用于训练,1111 对用于测试。它使用GoPro 相机以视频的方式捕捉帧,然后对前后连续短曝光的帧进行平均,生成模糊图像。
另一个用于测试的RealBlur[8]数据集使用两个相同型号的相机来捕捉图像,其中一个是以高快门速度进行拍照,另一个是以低快门速度拍照。由研究人员手持两台相机构成的拍摄系统在街道中进行随机拍摄,该数据集采集到的模糊图像更为真实。它们都包含4738 对图像,其中980对用于测试,其余用于训练。
2.2 实验设置
实验使用PyTorch 来实现本文的模型,该模型无需预训练。训练是在带有AMD 5950X CPU以及单块Nvidia GeForce RTX 3090Ti GPU 的服务器上进行的。实验将图像裁剪为几个大小为256 × 256 的图像块,批量训练大小设置为1。在训练阶段,使用ADAM[9]优化器对模型进行训练。学习率设置为10-6,使用余弦退火策略逐步降低学习率。实验使用上述配置在GoPro数据集上训练了300 轮,然后在模糊图像数据集GoPro和RealBlur 上对所提出的去模糊模型分别进行了测试。
2.3 实验结果
实验在GoPro 和RealBlur 数据集上进行了测试。图5展示了各模型的效果对比。

图5 去模糊方法对比
表1 显示了模型在峰值信噪比(peak signal to noise ratio,PSNR)和结构相似度(structural similarity,SSIM)指标上优于其他方法。

表1 模型测试结果
该模型在GoPro和RealBlur两个数据集上与几个经典的去模糊模型进行了比较,其中DeblurGAN和DeblurGANv2 是同一个团队提出的,使用的是CNN 构成的GAN 网络。结果表明本文提出的模型在两个数据集上分别比其他方法至少提高了0.72 dB 和0.83 dB,表现出较强的泛化能力。此外,图6 展示了一些去模糊的结果图与频域图。
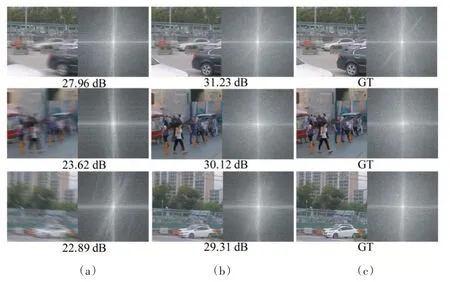
图6 GoPro数据集的训练结果
由图中频域图像也可看出,模型对图像的恢复体现在频域中的效果很明显,成功滤除了造成模糊的频率条纹。
2.4 消融实验
本节详细分析了模型中组件的作用,并在GoPro 和RealBlur 两个数据集上进行对比实验,实验结果见表2。U 形网络结构的性能优于简单的对生成器的输入和输出应用残差连接,如表2中的(A)和(B)所示。它将每个下采样阶段的特征图与对应的上采样阶段使用残差连接结合起来。在U形网络结构中,网络越深感受野越大,网络将更加关注更抽象的全局相关性。相比之下,当网络深度较浅时,它会更加关注纹理细节。
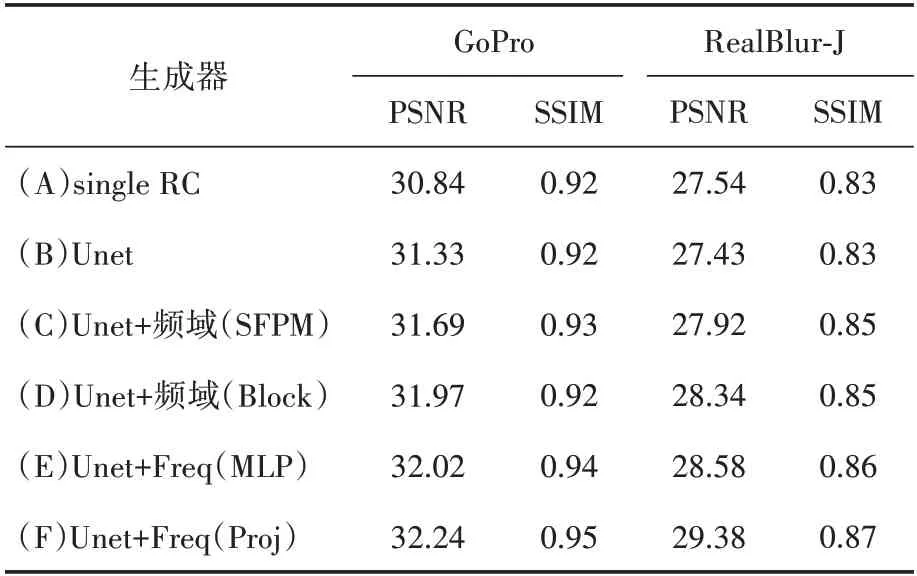
表2 消融实验结果
本节尝试将频域处理模块置于不同位置,结果显示频域处理模块的位置对于去模糊效果是有影响的。(C)尝试将频域处理模块置于与U形网络并行的位置,使其与Transformer 的U 形网络共享输入再合并输出。与之相比,(D)中将频域处理模块放入Transformer块或(E)中将频域处理模块放入MLP 中的性能要更好。当频域处理模块与U 形网络并行时,直接对图像进行处理,将输入转换到频域后对输入进行卷积运算。它只能用有限的频率在频域表示图像,这意味着它会丢失一些信息。但将其放入与Transformer块并行的位置,它就可以处理多个不同大小的特征映射,并可以获得全局和局部的相关性。关于表2 中的(E),是将频域处理模块部署在MLP 模块旁边。虽然最后的分数有一定的提升,但计算量比(D)提高了3 倍左右。在(F)中,再把它放回Transformer 块的旁边,同时改变其内部结构。在(C)和(D)中,只在频域对图像进行横纵向分解后的注意力计算,而(F)中,增加了一个投影矩阵,横纵向分解向量进行注意力计算后通过该投影矩阵可以自动学习关键信息,结果也表明该方法对于去模糊的效果有一定的改善。
3 结语
本文提出一种端到端的基于GAN 的频域Transformer 的去模糊模型,无须估计模糊核,主要面向不均匀运动模糊问题。文中对Transformer的内部结构进行了重新设计,加入了频域处理模块,使得模型能够同时在空域和频域上对图像进行恢复,充分利用了运动模糊在频域图中的特征,与Transformer 处理空域互补,取得了更好的恢复效果。同时生成器U 形网络的架构,使得模型能够处理高分辨率图片,并且可以学习到模糊图片的局部细节以及全局信息。得益于Transformer 的特性,模型对于数据增广的收益要大于基于CNN 的模型,数据量越大对模型效果越有利。模型受益于Transformer 的自注意力机制,但同样受制于自注意力机制,因为对于高分辨率图片构成的输入序列已经属于超长序列,自注意力计算的代价很大,造成了模型参数量大、计算速度慢的问题,后续工作需在此基础上压缩模型参数量,提高模型运行效率,便于部署在计算资源有限的嵌入式终端,如交通监控摄像头等设备。
