基于组学、机器学习和生物转化技术的农药及其转化物筛查方法研究
2023-10-25卢大胜汪国权邱歆磊金玉娥陈宇航
冯 超,卢大胜,汪国权,徐 骞,邱歆磊,金玉娥,陈宇航
(上海市疾病预防控制中心,国家环境保护新型污染物环境健康影响评价重点实验室,上海 200336)
我国是全世界最大的农药生产和消费国,由于农业产业化水平低、农民用药的安全意识淡薄,我国的农药污染情况相比国外更为严重[1-2],呈现种类多、地域差异大的趋势[3]。然而,受限于人员与设备,传统的检测方法仅适用于日常的靶向监测,不能实现农药及其转化物的拟靶向广谱筛查与鉴定。目前,食品安全领域的拟靶向筛查技术主要基于色谱与高分辨质谱的联用[4-5],化合物的鉴定主要参考其色谱行为(保留时间RT)和质谱特征,包括一级质谱特征(精确质荷比、同位素轮廓、中性丢失和加合形态)与二级质谱特征(MS2)[6]。然而,广谱和高通量的化合物筛查与鉴定需考虑以下3 方面:1)化合物的质谱数据库。虽然实验室自建的数据库可信度更高,但建库不仅需储备大量的标物,其过程也极为耗时耗力,所以商业数据库(或方法包)仍为多数实验室首选;2)低歧视性的样品提取与广谱的仪器分析方法。目前高稳定性和低歧视性的QuEChERs 方法是该领域的主流提取方法[7],色谱-高分辨质谱联用则是污染物广谱筛查中最理想的仪器,特别是多色谱系统(如气相色谱-质谱与液相色谱-质谱)的互补可以更完整地了解样品中的化合物全貌[3];3)高效的数据分析方法。分析方法主要包括靶向、拟靶向与非靶向3种;靶向方法主要基于数据库中化合物色谱与质谱特征的匹配[8]进行数据筛查;拟靶向方法则主要针对已知分子结构,但缺乏RT与MS2信息的化合物。拟靶向方法通常仅通过一级质谱特征(MS1)匹配筛查数据,结果的可靠性低,假阳性多,需进一步借助其他技术来排除假阳性,这些技术包括通过组学差异挖掘数据中的质谱特征[9],以及近年来在代谢组学和环境科学中逐渐流行的机器学习技术[10-11];非靶向方法则主要针对未知结构的化合物,如果未知物与已知化合物的结构以及质谱特征存在相似性,则可通过匹配质谱数据库中的特征二级碎片或者特征中性丢失发现潜在的同系物或环境转化物[12],继而通过质量亏损、化合物转化规律和质谱裂解规律推导疑似化合物的结构,或在了解化合物变化规律的前提下,通过预测或推导化合物的结构,继而在拟靶向的基础上进一步筛查与鉴定[13]。然而,由于化合物在质谱离子化时普遍存在源内裂解的现象,以及同分异构化合物在质谱中难以被区分,拟靶向方法和非靶向方法的鉴定结果仍缺乏可信度,需要标准品帮助确证结果,因此标准品的匮乏始终是化合物鉴定的瓶颈[14],尤其对于农药转化物。近年生物转化技术也在分析化学领域得到了应用,主要通过肝微粒[15]或微生物(细菌和藻类等)[16]等媒介模拟农药在环境媒介下的转化得到农药转化物,从而有效获取转化物的色谱与质谱特征,实现化合物的一级鉴定[14]。
本研究基于广谱低歧视的QuEChERS 提取方法和液相色谱-静电场轨道阱联用(LC-Q-Orbitrap)检测,在组学、机器学习和生物转化等多学科技术的帮助下,搭建了基于数据库匹配的靶向筛查方法,并借助组学和人工智能(AI)预测技术建立了农药转化物的拟靶向筛查方法。同时,运用肝微粒体外孵育技术建立了疑似转化物的高置信度确证方法。该方法具有高效、广谱和高特异性等特点,可满足不同食品类型中多农药残留及其转化物的快速筛查与确证需求(图1)。鉴于多农药及其转化物在食品中的残留分析重点在于广谱的样品提取方法、低歧视的数据采集方法和高通量与高置信度的数据挖掘方法,本研究将通过以下4 方面讨论如何在真实样本中系统地筛查并确证农药及其转化物的阳性结果:1)广谱的农药提取方法;2)高分辨质谱中的二级质谱特征采集方式;3)基于数据库多元参数匹配的靶向数据筛查;4)基于AI预测与生物转化技术的拟靶向筛查。
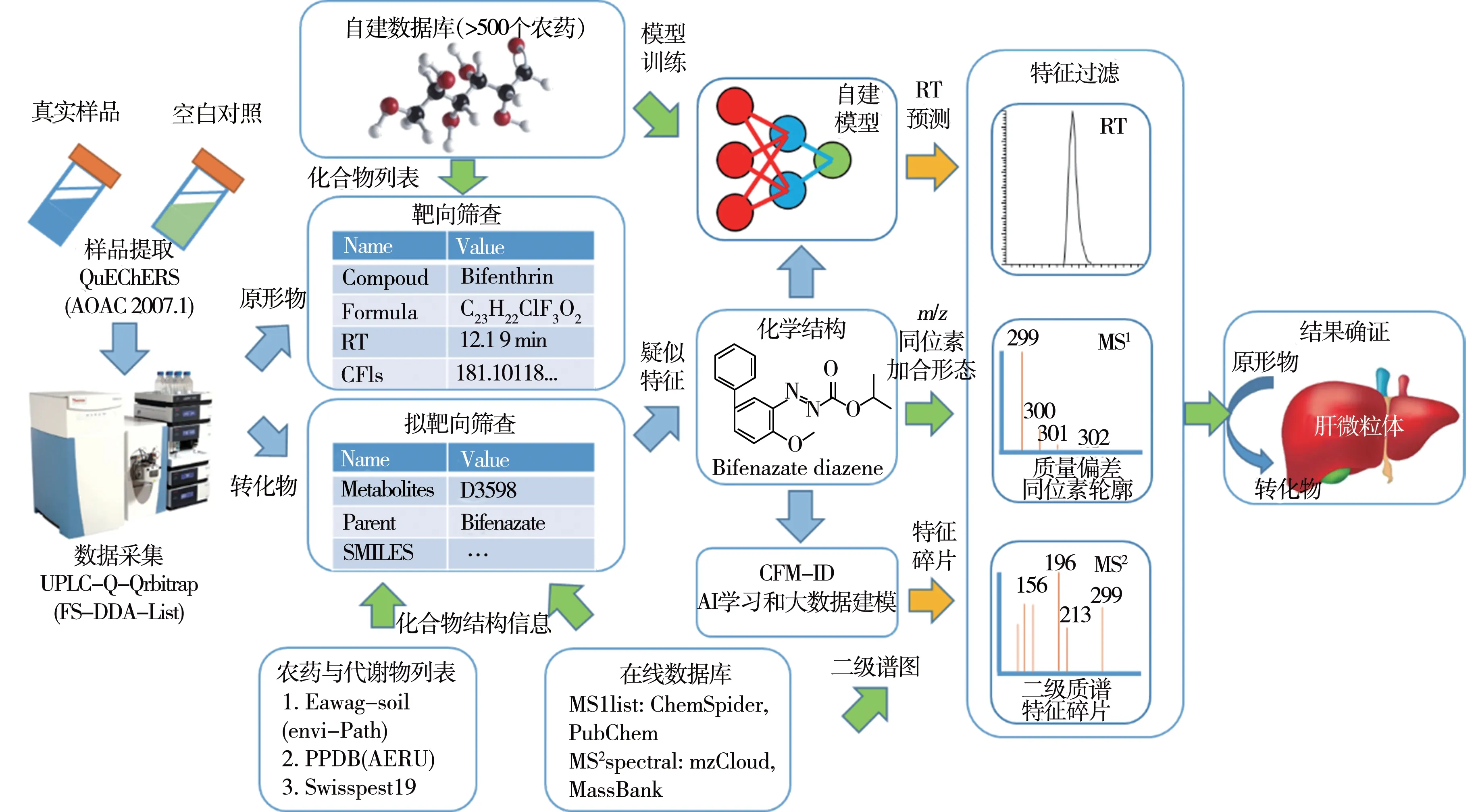
图1 拟靶向筛查方法的技术框架Fig.1 Framework of suspect screening method
1 实验部分
1.1 标准品与试剂
所有农药标准物质均购自Dr.Ehrenstorfer(Augsburg,Germany)或者 LGC Standards(Teddington,UK),纯度均大于95%;甲酸、乙酸、甲酸铵、乙酸钠、无水硫酸镁(HPLC 级试剂)均购自Sigma-Aldrich(Steinheim,Germany),其他试剂均为HPLC级;去离子水采用Milli-Q-Plus超纯水设备制备。
磷酸缓冲液(0.1 mol/L)、NADPH 再生系统(0.1 mol/L)和混合人肝微粒(20 mg/mL,0.5 mL/管)均购自武汉普莱特生物医药技术有限公司;固相萃取小柱(Oasis HLB,6 cc,500 mg)购自Waters(Milford,USA);食品基质如玉米(Rye,EUPT-CF10)、柠檬(Lemon,EUPT-FV19)、绿豆(Green bean,EUPT-FV20)、红甘蓝(Red cabbage,EUPT-FV21,EUPT-FV-SM11)、洋葱(Onion,EUPT-FVSM12)、茄子(Aubergine,EUPT-FV-SM13)、西红柿(Tomato,EUPT-FV-SM14)和小麦(Wheat kernel,EUPT-FV-SM15)均来自欧盟农药参比实验室(EURL,www.eurl-pesticides.eu);75件菊花茶采自北京、浙江和上海三地的商超和菜场;实验用水均为去离子水。
1.2 软件与数据库
液相色谱控制、质谱调谐采集与进样序列控制软件分别为Chromeleon、Tune 和Xcalibur v4.0;靶向和拟靶向数据分析软件为TraceFinder v4.1 和Compound Discoverer v3.3;机器学习的RT 模型构建平台为R(Retip Package,www.retip.app),特征二级碎片预测软件为CFM-ID v4.5;靶向数据库为实验室自建,约含1 000 多种农药原形物与200 多种转化物;拟靶向数据库为文献与在线数据库收集(来自PPDB和Swisspest19),约含1 200多种农药转化物。
1.3 提取方法
取1 g 干样/5 g 半干样/10 g 湿样于50 mL 离心管,加入10 mL(干样)/5 mL(半干样)/不加(湿样)水,干样/半干样在加水后分别浸泡20 /10 min。然后,加入10 mL含1%乙酸的乙腈,涡旋振荡1 min后,先后加入1 g乙酸钠和4 g无水硫酸镁,剧烈振摇后离心2 min(5 000 r/min,约2 000 G),将约1 mL的上清液过0.22 µm 的PVDF 滤膜(Millex FG,Millipore,USA),待上机。对于色素、硫化物和油脂等含量较高的食品如中草药、韭菜和牛油果,将提取的上清液作2~5倍稀释后上机分析。
1.4 色谱条件
液相色谱为Dionex UltiMate 3000 高效液相色谱系统(Thermo Fisher ScientificTM,USA),Thermo Accucore aQ(150 mm×2.1 mm:2.6 µm)色谱柱,柱温20 °C,流速0.4 mL/min。流动相A 为2 %甲醇(含0.1 %甲酸和5 mmol/L 甲酸铵),流动相B 为98%甲醇(含0.1%甲酸和5 mmol/L 甲酸铵)。梯度洗脱程序为:-5~0 min,100% A;0~4 min,100%~80% A,4~5.5 min,80%~60% A,5.5~10.5 min,60%~0% A;10.5~12.9 min,0% A;12.9~15 min,0%~100% A。
1.5 质谱条件
四极杆-静电场轨道肼质谱(Q-Orbitrap MS,Q Exactive)分别采用ESI+与ESI-电离模式,配备加热电喷雾离子源(HESI),源参数为:喷雾电压分别为3.8 kV(ESI+)与3.2 kV(ESI-),离子传输管温度为320 ℃,鞘气(雾化气)流速为 40 arb.unit,辅助气流速为10 arb.unit,辅助气温度为350 ℃。质谱采集中同时进行MS1和MS2扫描,一次MS1扫描搭配5次MS2扫描。
MS1扫描模式为全扫描(FS),扫描范围为m/z80~1 200;分辨率为70 000 FWHM;自动增益控制(AGC)为1×106;最大注入时间(MAX IT)为100 ms。
MS2扫描模式分为数据依赖(DDA,DDA-List)和非数据依赖(DIA或AIF)两类,其中DDA 参数:分辨率为17 500 FWHM;AGC 为1×105;MAX IT 为50 ms;事件循环次数(Loop count)为5;质量隔离窗(Isolation window)为2 Da;归一化碰撞能量(NCE)为20、40、60;二级触发响应阈值为2×104;同位素排除(Exclude isotope)为 ON;峰顶触发时间(Apex trigger)为2~6 s;动态排除时间(Dynamic exclusion)为5 s。DDA-List 将关注化合物加合形态的m/z导入特定列表(Inclusion list),其他参数与DDA 一致。DIA 将m/z100~900 分为16 个间隔50 Da 的质量区间段,对每个质量段内的母离子进行混合MS2扫描。AIF 同时将质量段内的所有母离子进行MS2扫描。DIA 和AIF 中的分辨率、AGC 和碰撞能量等参数与DDA模式一致。
1.6 保留时间预测模型的构建
基于实验室已有约400 种农药的小规模数据,基于R 平台的Retip 包中的4 种机器学习算法(决策树:随机森林、XGBoost、lightGBM;神经网络:Keras),化合物的分子描述符组(Molecular descriptor set,每个化合物约含3 800 个变量信息)和化合物在本方法下的RT 信息,将数据以训练集和测试集(8∶2)的分配形式用4 种不同算法进行训练,构建混合预测模型(Ensemble model),测试集在RT 偏差<1.0 min的阈值内阳性物质的筛查率达到97%[17]。
1.7 肝微粒孵育方法
在3 mL 的EP 管中加入约420 µL 磷酸缓冲液(0.1 mol/L),再加入60 µL 的NADPH 再生系统(0.1 mol/L)和5 µL农药混合标准(2 mg/mL),然后加入20 µL混合人肝微粒(20 mg/mL),于37 ℃水浴中孵育2 h,加入200 µL 的冰乙腈(-18 ℃)终止反应,离心1 min(4 000 r/min,约2 000 G),取上清液过0.22µm的PVDF滤膜后,待上机。
1.8 数据筛查策略
样本中数据筛查的策略如图1所示:待测物经提取和仪器数据采集(FS-DDA-List)后,数据中农药原形物采用基于自建数据库的靶向方法进行分析,化合物鉴定的维度围绕RT、MS1和MS2三个维度的信息,质谱特征(Mass feature)依次通过1)m/z(Δm/z<5 ppm,响应>2×105,S/N>5);2)溶剂空白(Blank,10 倍背景扣除);3)同位素轮廓(IP,Δm/z<5 ppm,响应偏差<30%,总体打分>70%);4)RT(< 0.3 min);5)MS2(至少匹配2个的二级特征,Δm/z<10 ppm,响应>1×104)共5个参数进行过滤,均能满足的质谱特征可认为是阳性结果(鉴定级别=1)。数据中农药转化物用基于结构列表的拟靶向方法分析,由于列表中的化合物缺失RT 和MS2信息,因此方法基于自建的RT 预测模型[17],以及美国环保署(EPA)推荐的MS2预测软件(CFM-ID)[11],对列表中已知结构的化合物进行RT 与MS2预测,除了RT 过滤参数(<1.0 min)设定较为宽泛外,其他过滤参数与靶向方法一致。如满足以上筛查特征,则被认为是疑似结果(鉴定级别=3),如果农药转化物的筛查结果可通过肝微粒体外合成辅助确证,则结果的置信度达2级。
2 结果与讨论
2.1 广谱的农药提取方法
为确保方法对食品基质的普适性以及对绝大多数亲水性较弱的农药有较好的回收率,本研究对提取进行标准化,提取时不同含水量样品的取样与加水量不同,但提取过程尽可能一致。通过乙腈和盐析辅助的液液萃取方法将样本中亲水的杂质与亲有机相的农药进行两相分离,去除绝大多数高极性物质。方法适用于不同含水量的食品(如谷物、中草药和奶粉等干样,禽蛋、水产品和菌菇等半干样,以及多数的果蔬等湿样)。由于前期实验或报道证明,石墨化炭黑(GCB)或者N-丙基乙二胺(PSA)均易造成个别物质的吸附,如乙酰甲胺磷和灭菌丹等农药易被PSA 吸附[18],六氯苯等平面结构农药易被GCB 吸附[19]。此外,复杂基质(如绿茶和中草药)中大量杂质也难以通过分散性填料有效净化。因此,本方法不使用任何选择性的净化试剂,主要采用多倍稀释方法对复杂基质的提取液进行净化,以降低所有基质的上样量和防止个别物质的损失(图2A)。

图2 基于QuEChERS的不同类型食品基质的标准化提取方法(A)和PPDB数据库上1 364种农药的油水分配系数(LogP)预测(B)Fig.2 Unified QuEChERS-based extraction method for different food types(A) and LogP prediction of 1 364 pesticides from PPDB database(B)
研究通过对PPDB 数据库(sitem.herts.ac.uk)中1 364 个农药活性物质的LogP[20]进行汇总与预测(图2B),调研了不同亲水性/极性农药提取和仪器分析的可行性。结果表明,只有极少数(小于5%)农药(如百草枯、敌草快、草铵膦等)的LogP值小于0,即属于较高极性化合物,这类物质不仅难以通过液液萃取直接从水相中萃取,还需使用离子对色谱、HILIC体系[21]或者超临界流体色谱(SFC)[22]才能实现良好的色谱保留。而对于绝大多数中低极性农药的分析,均可通过与本方法[6]一致的液相色谱-质谱联用(反相体系,ESI 源)进行分析,少部分的低极性农药(如有机氯或拟除虫菊酯类农药)则需采用气相色谱-质谱(EI源)进行分析[23]。
基于以上提取方法和理论依据,研究来自欧盟农药残留参比实验室(EURL)的果蔬和饲料等食品基质,如玉米(谷物,干样)、柠檬(水果,湿样)、绿豆(蔬菜,半干样)和红甘蓝(蔬菜,湿样)中不同类型(如拟除虫菊酯、有机磷、新烟碱、三唑等)农药的加标回收率(表1)。结果显示,不同基质中不同类型化合物的回收率为66.3%~126%,方法对不同基质和农药的适用性良好,验证了该提取体系的可靠性。

表1 4类食品基质中多农药残留的回收率Table 1 Recoveries of pesticide multi-residues in four types of food matrices
2.2 高分辨数据采集模式的比较
为使低歧视的仪器分析方法尽可能采集到各类农药的MS1和MS2特征,研究评价了目前最常见的3种不同高分辨质谱二级采集模式在红甘蓝(Red cabbage,EUPT-FV-SM11)中阳性农药筛查中(图3A)的应用,二级采集模式分别为FS-DDA(数据依赖性扫描模式)、FS-DIA(数据非依赖性性扫描模式)、FS-AIF(全碎片扫描模式)和FS-DDA-List(带列表的数据依赖性扫描模式)。结果显示,在无RT辅助确证的情况下,使用DDA、DIA、AIF、DDA-List共筛选出12、16、16、16个阳性结果和1、8、18、1个假阳性结果(图3B)。由于数据依赖性的扫描方法会依据质谱特征的响应强度排序进行二级扫描,所以DDA 的4 个假阴性(黄色标注)结果是由其相对的低丰度(响应普遍低于5×107)引起(图3A);而DIA 和AIF 等非数据依赖性的扫描方式则可以检出所有(16种)阳性特征,但其假阳性数量却显著高于DDA 方式,原因是这些模式下二级碎片的共流混杂度太高导致MS2数据的特异性较差,除非有RT 协助确证,否则将极大增加后续排除假阳性结果的工作量。为了解决DDA模式下的响应歧视问题,DDA-List通过设置拟靶向化合物列表的方式,优先筛查列表中目标物,同时实现高阳性检出率和低假阳性率。以上研究表明,非数据依赖性的扫描方式可获取更全面的化合物二级质谱信息,但数据的特异性不如依赖性的扫描方式,需要其他维度(如RT)补充以进一步排除假阳性数据,而带列表的数据依赖性扫描方式则可以兼顾数据的检出率和特异性。
图3 红甘蓝中阳性农药列表(A)和不同扫描模式下红甘蓝中阳性/假阳性农药的筛查结果(B)Fig.3 List of positive pesticides in red cabbage(A) and screening result of positive/false positive pesticides in red cabbage under different scanning modes(B)
2.3 基于数据库匹配的靶向筛查
2.3.1 多元参数的特征过滤在液相色谱-高分辨质谱采集的数据中,靶向数据的特征挖掘主要基于数据库的多元参数匹配,涉及RT 偏差、MS1(m/z偏差、同位素轮廓打分)和MS2(特征碎片离子)等参数。研究基于一个小麦样本(EUPT-FV-SM15)在ESI+模式下采集的FS-DDA数据,依次通过m/z、溶剂空白、同位素轮廓、RT 和MS25 个维度的参数进行特征过滤。结果显示,满足质荷比偏差的疑似特征共1 779 种,溶剂背景的扣除将可将特征数降至1 666 个,而同位素轮廓和RT 对特征数的过滤贡献较大,依次将特征数削减至267 个和72个。经MS2确证后(仅全扫描的数据需要二次进样确证),能达标的物质仅剩13种(图4)。将该过滤后的结果与官方公布的阳性结果相比,阳性结果除一个ESI-出峰的化合物(Fluroxypyr)外都在其中,且无假阳性的特征。因此,在多元参数的限定下,可以最大程度地减少候选特征数和筛查工作量,增加结果的置信度。
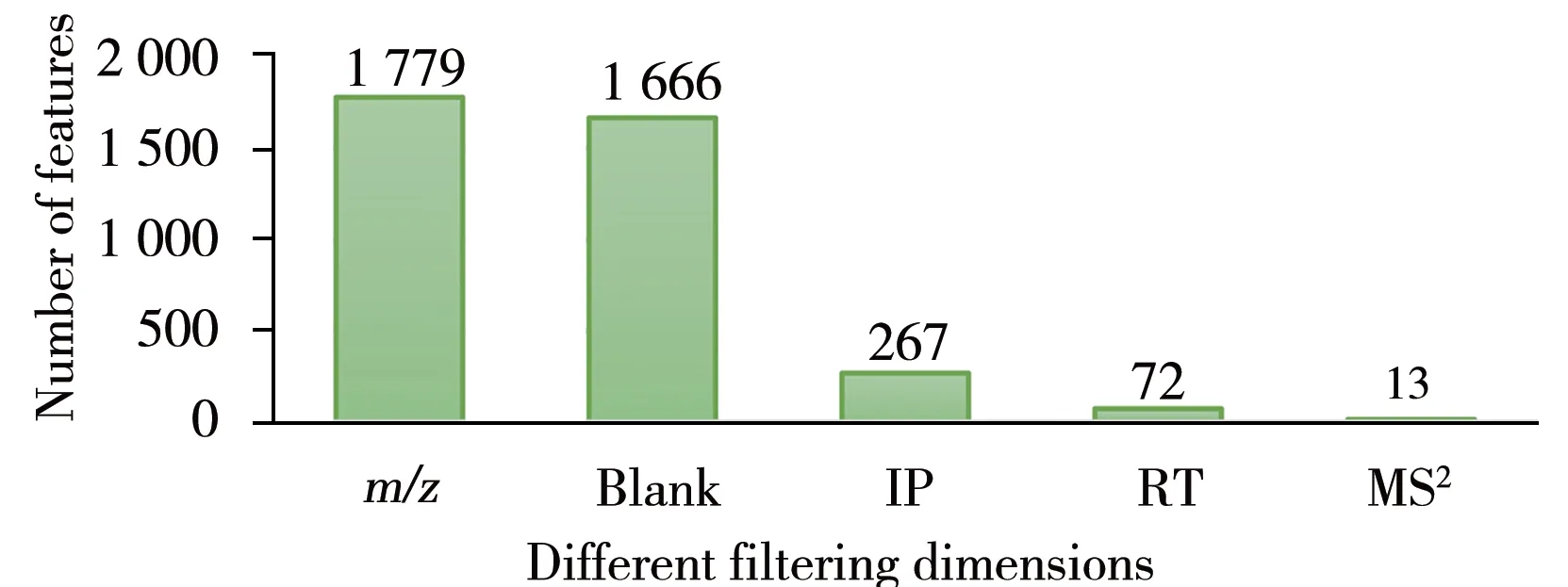
图4 不同维度参数过滤下的质谱特征数Fig.4 Number of mass feature under different dimension parameter filtering
2.3.2 靶向数据筛查的应用研究在红甘蓝样品中发现了疑似苯菌酮(Metrafenone)化合物(图5A),其+H 特征峰的质荷比偏差(Δm/z)小于5 ppm,响应(>2×105)和信噪比(S/N>5)均满足要求,而其+Na 的加合形态也能满足Δm/z< 5 ppm,RT偏差也小于0.5 min。由于化合物含卤素(溴),其同位素轮廓的特异性较好,且每个同位素特征(M+1、M+2、M+3等)与理论的响应偏差(<30%)和Δm/z(< 5 ppm)均满足要求,同位素轮廓打分为100%(>70%)(图5B)。除MS1特征,该化合物MS2的特征也与mzCloud 数据库匹配良好(94.1 分,图5B)。此外,化合物还存在明显的源内裂解(in-source CID)现象,在MS1特征中存在的m/z209.080 70 和m/z229.970 00 两个离子与苯菌酮的特征离子(m/z409.064 12)具有相同的RT和相似的峰形(图5D),且这两个特征属于苯菌酮的主要特征MS2(图5C),其MS2中个别离子(如m/z181.049 3和m/z168.964 6等)也存在于苯菌酮的MS2轮廓中。

图5 基于多元参数综合鉴定疑似苯菌酮农药Fig.5 Comprehensive identification of suspected metrafenone pesticides based on multivariate parameters
2.4 基于AI预测与生物转化技术的拟靶向筛查方法
传统的拟靶向筛查基于疑似列表做MS1特征匹配来发现疑似特征,筛查结果的置信度较低。本方法受益于组学和AI 预测技术,在扣除空白特征、MS1特征匹配的基础上,基于疑似特征可能的化合物结构(SMILES)来预测保留时间(RT)和MS2后进行特征过滤。在实际应用中,基于MS1特征筛查,本方法在75件菊花茶中发现了数十种农药转化物的残留,且其预测RT偏差均满足要求(<1.0 min)。为进一步确证转化物的筛查结果,研究通过肝微粒体外孵育技术,获得部分农药转化物的色谱与质谱特征,其中8 种转化物的MS2得到解析,且其RT 偏差(< 0.3 min)与样本特征较一致(表3)。如咪鲜胺的疑似转化物BTS44596(图6),其孵育RT 与样本RT 的偏差为 0.11 min,通过AI辅助的质谱结构解析后,注释了其主要特征碎片(m/z335.293 64、308.000 43、216.921 83)的结构,确证了该化合物的分子结构。最后,通过孵育后的特征与样品中的特征进行色谱与质谱特征的匹配,确证该转化物的阳性结果,鉴定的置信度为2a级,有关化合物的鉴定置信度级别见表4[14]。

表3 菊花茶中8种农药转化物的筛查与鉴定结果Table 3 Summary of eight pesticide transformation products in chrysanthemum tea

表4 高分辨质谱中化合物的鉴定置信度级别Table 4 Proposed identification confidence levels in high resolution mass spectrometry
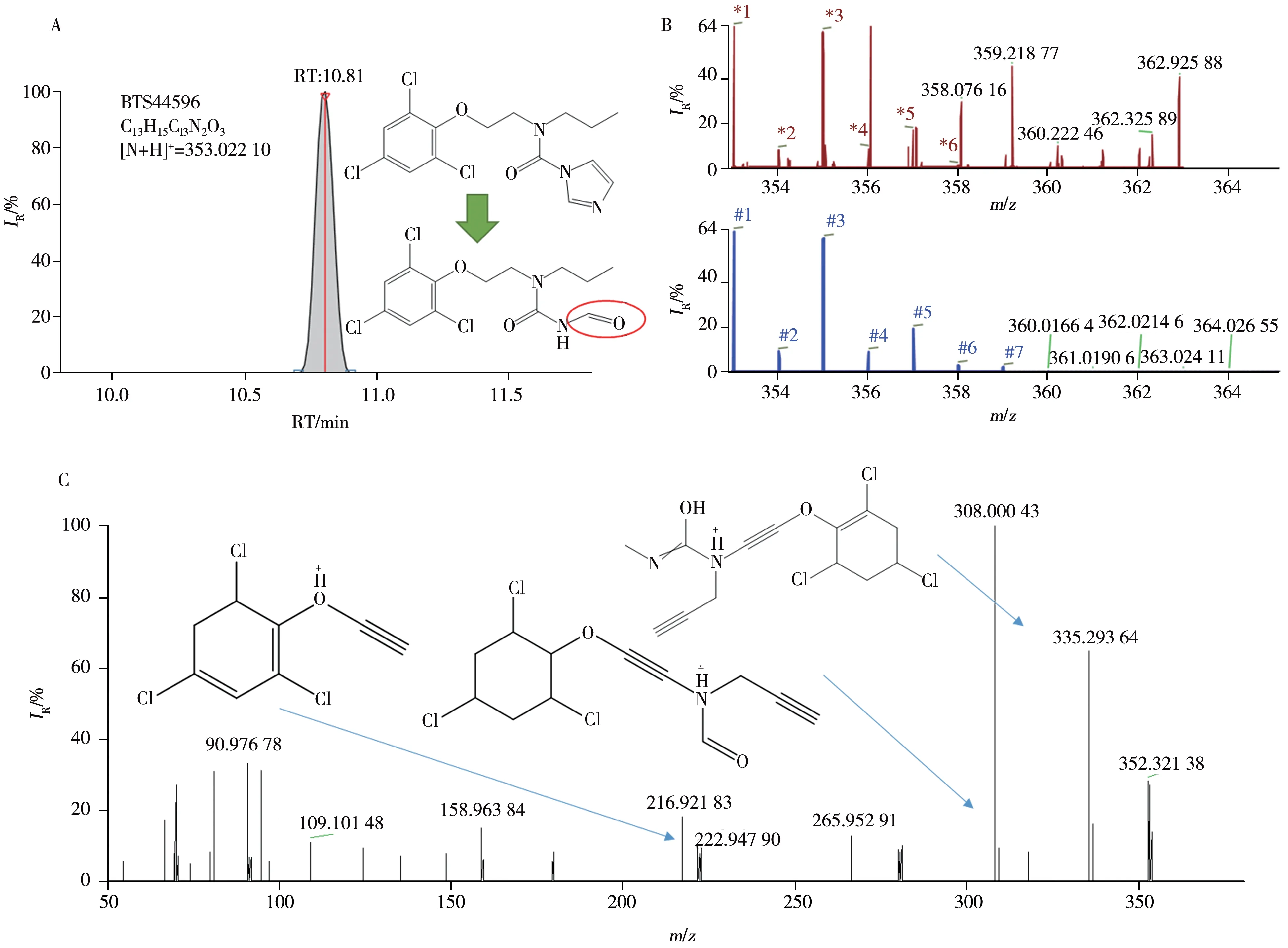
图6 经肝微粒孵育后获得的咪鲜胺转化物(BTS44596)的鉴定与碎片注释Fig.6 Identification and fragment ions annotation of transformation products of prochloraz(BTS44596) after liver microsome incubation
2.5 方法的可靠性验证
本实验室自2014 年以来,历年参与EURL 举办的盲样筛查考核(EUPT-FV-SM)。在无参考标物的情况下,实验室在2019~2021 连续3 年的考核中,基于该方法体系,在72 h 内,分别在卷心菜(EUPTFV-SM11,Lab002)、洋葱(EUPT-FV-SM12,Lab023)、茄子(EUPT-FV-SM13,Lab021)3 类盲样中实现10 多种不同类型农药100%的阳性检出,也在西红柿(EUPT-FV-SM14,Lab010)中鉴定出多个农药转化物(如Propamocarb-N-oxide、Spirotetramat-enol、Bifenazate-diazene 等),证明了该方法对农药及其转化物筛查的广谱、高效和高可信度等特征。
3 结 论
本研究基于高分辨质谱技术,建立了农药及其转化物的筛查与鉴定体系,对各类食品基质和不同农药进行广谱提取,低歧视仪器采集以及高通量和高置信度的数据挖掘与确证,特别是在缺乏标准品的情况下,可通过生物转化方法提升疑似农药转化物鉴定的置信度。研究通过来自欧盟参比实验室的真实样本验证了该方法体系的可靠性,并在历年全国代表性食品监测中使用该方法体系发现并确证了不少农药转化物。通过组学、机器学习和生物转化等多种技术的融合,该研究突破了目前食品安全领域农药转化物筛查与鉴定的瓶颈。在未来研究中,期望通过不断扩充实验数据库并提高数据分析的智能化,实现农药及其转化物快速与广谱的检测。
