基于Sentinel-2的川西高原植被叶片含水量反演
2023-10-24谢兵,杨武年,杨鑫,王芳
谢 兵,杨 武 年,杨 鑫,王 芳
(1.四川司法警官职业学院,四川 德阳 618000; 2.成都理工大学 地球科学学院,四川 成都 610059; 3.内江师范学院 地理与资源科学学院,四川 内江 641000)
0 引 言
叶片含水量的多少是植被长势好坏的重要参考因素,也是植被蒸腾和固碳的主要因素,在植被生长过程中起到重要作用,进而对生态环境也有着重要的影响。对植被叶片水含量的广泛监测,可以为植被生长状况提供及时的科学评判,保证植被的良好生长。植被叶片含水量的多少对森林火灾预防和减弱也有着重要的作用,植被叶片水含量越多植被燃烧的速度会越慢,植被着火点的温度也会越高,有助于延缓森林火灾和火势蔓延,为及时扑灭火灾赢得宝贵的时间[1]。
对于植被叶片含水量的测量或估算的传统方法,往往都是将研究区划分为众多小区域,通过实地调查采样和插值的方法得到整个研究区植被叶片含水量。卫星遥感可以大范围、快速和多谱段地进行遥测,获取大量地面上有效信息[2-3],具有高效、无损、低成本、覆盖范围广等特点。通过遥感技术获取植被叶片含水量主要有以下2种方法。
一是采用相应的辐射传输模型通过输入不同的叶片结构参数、生化组分含量信息、入射光线最大入射角等定量反演植被冠层含水量。阿布都瓦斯提·吾拉木等[4]根据叶片和冠层辐射传输模型Prospect模型、Lillesaeter模型、Sail H模型、大气传输6S模型构建了一种新植被指数SPSI(短波红外垂直失水指数)来估算植被冠层含水量,并与野外实际测量的冠层含水量比较,研究发现两者结果较为接近,新植被指数能很好地估算冠层含水量。程晓娟等[5]依据物理PROSAIL模型分析了对小麦冠层水分敏感的波段,利用这些敏感波段构建了一种新的植被水分指数,发现这种新植被指数对冬小麦冠层水分含量估算精度很高。
二是基于统计分析方法监测植被水分。Zhang等[6]利用了10个与水分相关的植被指数来估算冠层含水量(CWC)和冠层平均叶片等效水厚度(EWT),发现绿叶绿素指数、红边叶绿素指数、红边归一化比值对CWC和EWT最为敏感。张海威等[7]通过分析8种植被指数与植被叶片含水量之间的相关关系,发现MSI和GVMI植被指数与植被叶片相对含水量的非线性三次拟合函数精度最高,GVMI指数反演的误差最小。李玉霞等[8]基于光谱指数法建立植被含水量之间的关系模型,发现光谱指数法反演精度较高。
Sentinel-2卫星搭载的多光谱成像仪有13个光谱波段,其特有的植被红边波段在植被参数反演中有着重要作用,且与其他波段相关系数较低,提高了影像的光谱信息量,为影像分类提供了更多的光谱特征。本文基于Sentinel-2,提取6种植被指数,利用野外实测的60个样本数据计算的叶片含水量数据,建立植被叶片含水量与植被指数之间的关系模型,并进行验证,得到川西高原研究区植被叶片含水量分布结果,该结果对于四川地区的生态环境评价有着重要意义。
1 研究区概况与数据
1.1 研究区概况
松潘县位于川西高原东北角,境内有大片森林覆盖,适合作为研究区分析研究植被水含量。研究区主要包含松潘县燕云乡、红扎乡、小姓乡、大姓乡、安宏乡、青云乡、牟尼乡等乡镇,总面积约1 000 km2,研究区内有两条大的河流——热务曲河和岷江,两条河流汇聚于镇江关乡,年平均气温5.7 ℃,年均降水量720 mm,属川西北高原气候[9],研究区地理位置见图1。
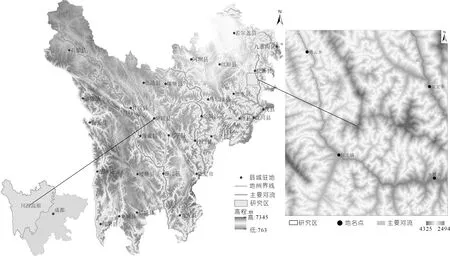
图1 研究区位置
1.2 数 据
1.2.1叶片含水量测定
通过2018年8月进行的野外实地调查,在研究区内大致均匀设置60个样方(见图2)。主要记录每个样方的经纬度信息、高程、采集树叶样本。每个样方内按照植被顶、中、底3层各采集10片树叶现场采用经过校准的幸运JA303P型号电子分析天平称其鲜重,采集的树叶装入纸袋中[10],采用叶面积测量仪测量树叶面积。室内叶片样品在70 ℃烘干24 h以上,直至恒重后再采用华志HZY-A400型号电子分析天平称重叶片干重,按照公式(1)计算叶片含水量(以叶片等效水厚度表示)。

注:底图为2018年8月Sentinel-2卫星影像,R:Band 8,G:Band 3,B:Band 2假彩色合成。
(1)
式中:EWTleaf表示叶片含水量,g/cm2;Wfresh表示新鲜叶片的重量;Wdry表示烘干后叶片的重量;A表示叶片的面积。
1.2.2遥感数据处理
Sentinel-2数据由于传感器平台在运行过程中的复杂情况,以及受到地球大气情况、地表高程起伏状态的影响,传感器记录的值往往与目标辐射亮度或地表反射率存在着偏差,需要通过数据预处理消除这些误差[11]。经遥感数据预处理得到Sentinel-2地表反射率数据产品(见图3)。
2 模型与方法
2.1 植被指数
植被指数常用来估算植被相关信息,常见的植被指数有NDVI、NDWI、TVI、FVC等,由于Sentinel-2数据是唯一一个在红边范围含有3个波段的数据[12-14],增加了红边归一化植被指数NDVI705,选取的植被指数见表1。

表1 Sentinel-2数据的植被指数计算公式
2.2 方 法
根据植被指数与叶片含水量的关系建立相应数学模型,方法包括:多元逐步回归、随机森林、BP神经网络[15]。
2.2.1多元逐步回归
多元逐步线性回归是从所有变量中考虑与植被叶片含水量决定系数最大、均方根误差最小的变量,直至所选取的模型效果最好的变量即为最优的变量。
多元回归方程是假设有多个植被指数作为自变量x1,x2,x3…xn,它们与植被叶片含水量y之间存在如下关系:
y=a0+a1x1+a2x2+…+anxn
(2)
式中:a0为常数项,a1,a2,a3,…,an为待求回归系数。
2.2.2随机森林
随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,通过集成多个决策树来完成预测和分类任务。它结合了决策树的特点和随机性,具有较强的预测能力和稳定性。
设定不同叶子数和树数,通过比较回归得到的各种叶子大小和树的数量的均方误差来寻找最佳叶子大小和树的数量(见图4),从图4中可以看出,叶子数为5、树的数量为450时,误差最小且稳定,利用该参数进行植被指数的重要性分析,重要性由大到小依次为FVC、NDVI705、NDVI、NDWI1,NDWI2、TVI。
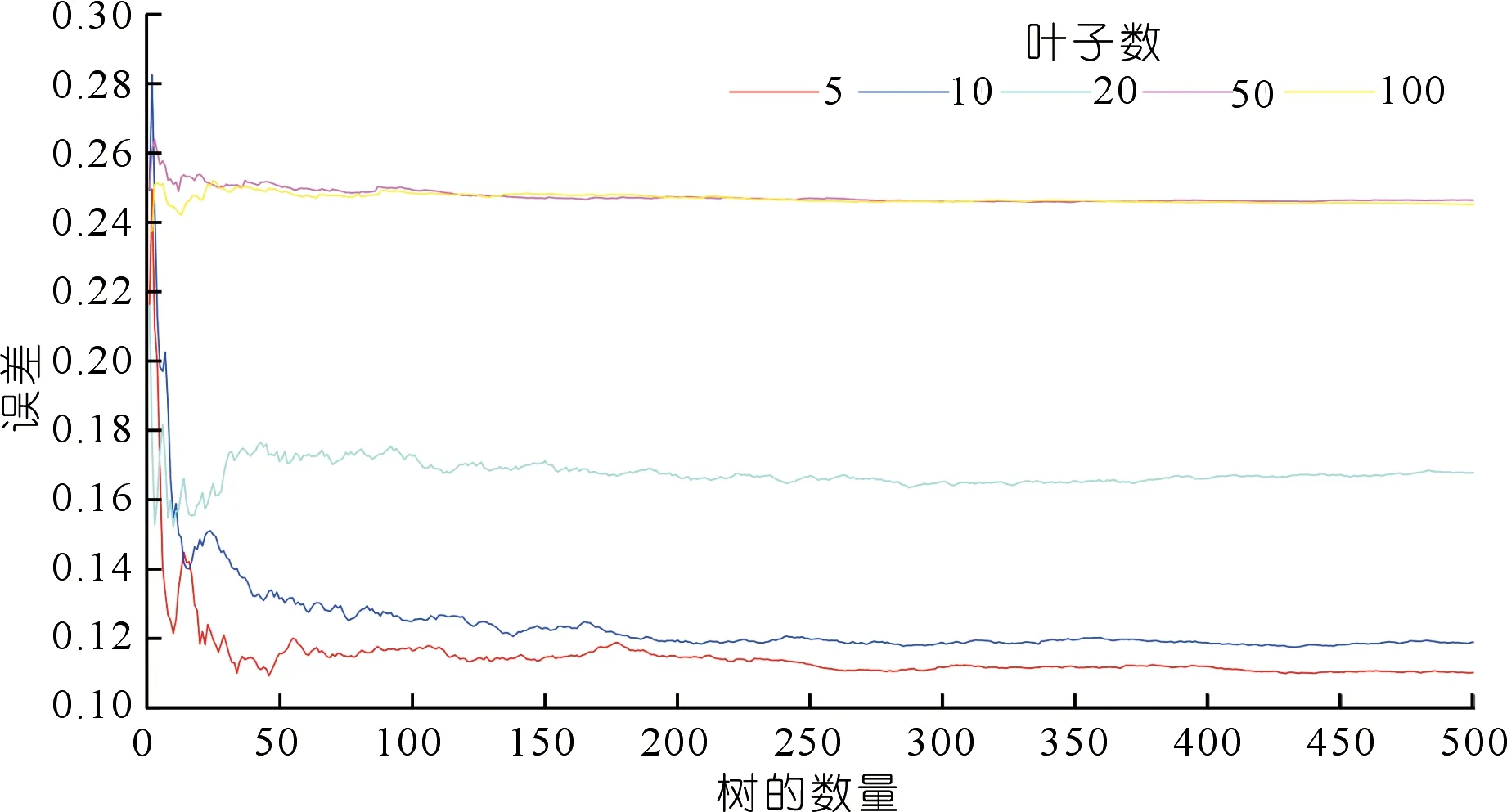
图4 叶子数、树数与误差
2.2.3BP神经网络方法
BP神经网络能够很好的处理输入与输出数据,主要由输入层、隐藏层、输出层3部分组成,输入层与隐藏层和隐藏层与输出层通过权重、函数进行连接,输出层在隐含层的基础上确定输入变量和激活函数输出,当与目标存在误差的情况下,经输出值与期望值比较,当误差大于设定值时,则误差反向传播,通过逐层修改神经元的权值,减少误差,如此循环直到输出的结果符合精度要求为止。
神经网络隐含层的第i个节点的输入变量neti为
(3)
隐含层的第i个节点的输出变量为
yi=f(neti)
(4)
式中:f为激活函数,f(x)=1/(1+e-x),xj为隐含层第j个节点的输入参数,wij为隐含层的第i个节点到输入层的第j个节点之间的神经网络权值函数。bi为阈值参数[16]。
隐含层神经元个数采用如下经验公式确定:
(5)
式中:m为输入层个数,n为输出层个数。计算出本模型的隐藏层神经元个数为5。
2.3 精度评价方法
采用十折交叉验证法的均方根误差RMSE、平均绝对误差百分比MAPE检验模型的精度,公式为
(6)
(7)
3 植被叶片含水量反演
3.1 因子相关性分析
采用的植被指数有6种,需要分析他们之间的自相关性,避免数据冗余,论文采用Pearson相关系数来确定植被指数之间的相关性[18](见表2)。统计学认为系数值的范围在0~0.19之间为极低相关,0.20~0.39之间为低度相关,0.40~0.69为中度相关,0.70~0.89为高度相关,0.90~1.00为极高相关。
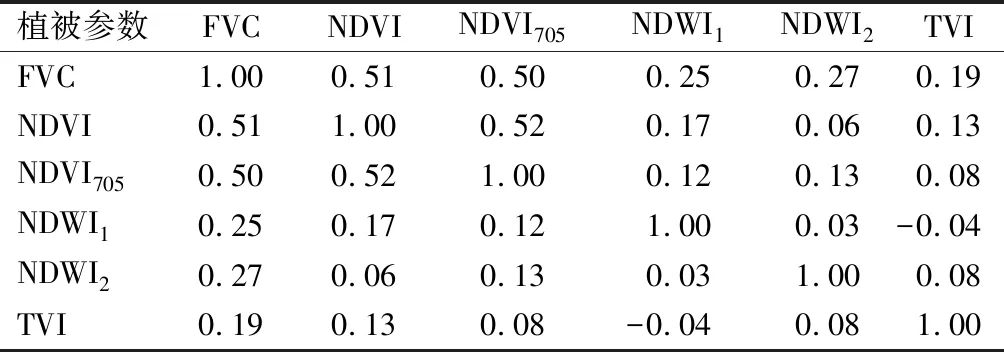
表2 植被参数之间相关系数
从表2可以看出,最大相关性为NDVI与NDVI705,Pearson相关系数为0.52;最小为TVI与NDWI1,Pearson相关系数为-0.04。只有NDVI与FVC、NDVI705与FVC、NDVI705与NDVI的Pearson相关系数处在中度相关,其他全部在极低度相关和低度相关,综合分析,6种植被指数均可作为模型输入数据。
3.2 植被叶片含水量反演模型与验证
论文基于多元逐步回归、随机森林、BP神经网络方法建立植被指数与植被叶片含水量遥感估算模型,并采用精度评价方法对3种模型加以验证。根据十折交叉验证方法,将60个样本数据平均分成10份,其中9份用于训练,1份用于测试。论文采用MATLAB软件处理,运用crossvalind函数进行十折划分,通过循环训练计算10折交叉验证的平均均方根误差RMSE和平均绝对误差百分比MAPE,结果见表3。
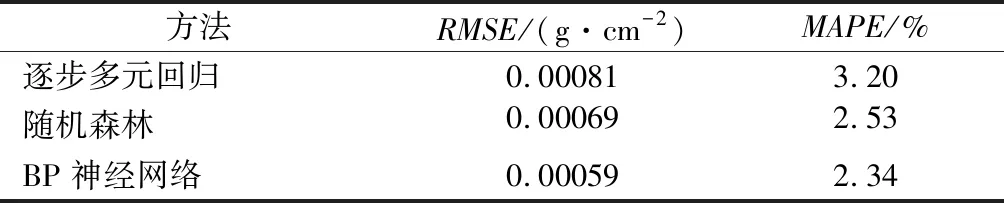
表3 十折交叉验证法结果
从表3中可以看出,BP神经网络在均方根误差和平均绝对误差百分比上均小于随机森林算法和逐步多元回归算法,分别为0.000 59 g/cm2和2.34%,可以认为3种方法中BP神经网络模型反演植被叶片含水量效果最好。
3.3 植被叶片含水量反演结果
由于BP神经网络模型在训练数据和验证数据集上精度最高,论文采用MATLAB软件将Sentinel-2提取的FVC、NDVI、NDVI705、NDWI1、NDWI2、TVI植被指数作为输入数据,运用已训练好的BP神经网络模型反演研究区植被叶片含水量,结果如图5所示。

图5 研究区植被叶片含水量分布
与图1比较,可以看出河流段、城镇村庄处呈现红色,植被区域呈现绿色和黄色,河流、城镇区域植被叶片含水量低,与实际情况一致。
4 结 论
本次研究从Sentinel-2影像和研究区实测叶片含水量为数据源,分析了Sentinel-2影像FVC、NDVI、NDVI705、NDWI1、NDWI2、TVI 6种植被指数,并对6种植被指数的相关性进行分析,通过多元逐步回归方法、随机森林方法与BP神经网络模型,实现对川西高原植被叶片含水量的定量反演。结果表明:
(1) 基于因子相关分析,6种植被参数之间的自相关性低,均可以作为模型输入参数。
(2) 采用随机森林算法通过对叶片含水量与植被指数进行重要性分析,重要性由大到小依次为FVC、NDVI705、NDV1、NDWI1,NDWI2、TVI。
(3) 通过十折交叉验证方法对3个模型进行评价可知,BP神经网络均方根误差和平均绝对误差百分比最小,分别为0.000 59 g/cm2和2.34%,表明BP神经网络模型优于逐步多元回归模型和随机森林模型。
