面向地域流动的在线热点话题演化检测方法*
2023-10-20翟菊叶叶泽坤
翟菊叶 叶泽坤
(1.蚌埠医学院卫生管理学院 蚌埠 233030;2.复旦大学计算机科学与技术学院 上海 201114)
1 问题的提出
随着我国移动互联网技术的快速发展,越来越多的民众把网络作为信息交流的主要方式[1]。由于网络打破了时空限制,民众能够在更大范围内交流自己关注的社会热点问题,因此网络中蕴含着大量的热点话题。而随着位置服务[2]的广泛应用,网民发布的文本内容会被打上位置标签,让网络话题具有了地域特征。话题在随时间演化的过程中,其地域特征也会随之演化。所以,对话题的地域特征进行演化挖掘有助于感知话题流行的位置动向,对舆情研判、网络推荐、社会管理等具有十分重要的意义。
20世纪90年代中后期,为了应对网络信息“爆炸”给信息检索带来的困扰,话题检测与跟踪(Topic Detection and Tracking, TDT)技术开始兴起[3],并吸引了大量学者跟进研究。在话题检测技术中,基于聚类的话题检测方法和基于概率模型的话题生成方法是最常用的方法。如Wu等[4]提出了一种基于多策源的群聊话题检测技术,该技术通过构建话题序列解决了话题纠缠问题,并利用群聊消息的用户、时间、类型等属性强化了同话题消息之间的联系,弥补了单纯依靠稀疏短文本特征进行聚类的不足。Jiang[5]等提出了一种基于高斯混合模型的文本表示学习框架,该方法把文本语义映射成主题,再利用统计流形有效地度量文本距离,从而达到文本分类的目的。Zhang等[6]提出了一种基于词向量的话题焦点生成方法,该方法首先运用特征词提取公式构造话题特征词集合;再用Skip-gram模型训练文本词向量;然后通过BTM(Biterm Topic Model)对文本词向量进行主题建模,实现话题焦点的识别。由于话题会随着时间不断演化,为了解决动态数据中的话题检测问题,话题跟踪技术应运而生,其核心思想是在话题检测的基础上引入时间维度,分析时间序列上话题的变化情况。如Liu等[7]提出了一种基于多维特征的网络话题演化分析方法,该方法运用网络评论构建话题图谱,然后利用LDA(Latent Dirichlet Allocation)模型对图谱中话题属性进行划分,并以时间属性为主轴,全方位追踪舆情话题的演化情况。
上述话题检测与跟踪技术都是面向线上数据的,没有考虑话题的位置属性,无法发现话题在地域上的分布。而随着位置服务技术的广泛应用,地域性话题检测技术研究也逐渐兴起。如曹玖新等[8]提出了一种基于在线社交网络的地域性话题识别方法,该方法根据地域性话题的空间关联特征,综合考虑用户发布的文本内容和地理位置信息,按照主题模型思想构建地域性话题发现模型(Geographical Textual Topic Discovering model, GTTD)。该模型将用户、话题和地理位置间存在的紧密关系同时引入话题发现框架中,实现了网络话题的地域特征识别。He等[9]提出了一种基于多层隐狄利克雷过程的地理话题识别方法,该方法把文本、用户兴趣和空间进行联合建模,按照空间-用户兴趣-话题三个层次建立话题树,构造了地理位置上的话题生成规则。地域性话题识别方法把线上话题引入到线下,为更深层的线上线下研究奠定了理论基础,但当前的地域性话题识别方法仍然缺乏对话题地域演化的识别能力,无法感知话题在流行地域上的发展趋势。
为了解决这个问题,本文在OLDA模型的基础上引入位置参数,提出了一种面向地域流动的在线话题演化识别方法。该方法把网络文本数据按时间顺序进行分组,在t-1与t时刻之间建立话题地域遗传矩阵,动态更新t时刻[<话题,地域>-位置]t分布的超参;然后利用t-1时刻主题地域的后验信息,联合建模t时刻文本、话题、地域、位置及词汇五个变量,生成[文本-话题]t、[话题-词汇]t、[<话题,地域>-位置]t三个分布矩阵;最后运用相似度计算公式对t-1与t时刻的话题进行链接,得到t时刻话题流行区域分布[<话题-地域>-位置]t,以此实现话题流行地域的演化识别。
2 相关技术
2.1 话题模型
话题模型(Topic Model, TM)是一种以非监督学习方式对隐含在数据集中的语义结构进行聚类的统计模型[10],它把高维文本数据降维成话题词混合分布向量。目前,常用的话题模型是由Blei等[11]于2003年提出的潜在隐狄利克雷分配模型LDA。该模型依据文本、话题、词汇三者之间的条件依赖关系,把文本建模成K维话题的多项式概率混合,把每个话题建模成N维词汇的多项式概率混合,最终得到文档-话题分布θ和话题-词汇分布φ两个分布矩阵。
LDA模型是一个静态模型,为了让其具备连续数据流环境下的话题语义识别能力,Alsumait等[12]在LDA模型中增加了时间维度,提出了一种在线LDA模型(Online Latent Dirichlet Allocation, OLDA)。该模型的核心是基于时间平滑假设,即在没有受到外部干扰的情况下,t时刻的话题分布只受t-1时刻话题状态的影响。OLDA模型把t-1时刻语料中的话题词频信息作为当前t时刻话题遗传物质,以此动态更新t时刻话题先验,更新方式如公式(1)所示。
Multi(φt)~Dir(βt)~Dir(wt-1Mt-1)
(1)
其中,wt-1是t-1时刻话题分布的遗传度,表示t-1时刻前话题-词汇分布中各词汇出现的频次,Mt-1是根据t-1时刻话题遗传信息构造的话题演化矩阵,大小为K×N,并能自动与t时刻话题分布进行对齐。
2.2 地域性话题模型
地域性话题模型的核心任务是把线上话题映射到位置维度上,建立话题与线下位置的对应关系。根据话题和位置的依赖顺序不同,地域性话题挖掘模型的构造原理也存在着差异。GTTD模型[8]假设距离相近的用户具有相似的兴趣爱好,更容易形成同一话题,所以,此模型把地理位置参数作为生成框架的最高层,把话题作为(地域,用户)上的条件概率,生成顺序是:地域→用户→话题→(位置,词汇)。该模型的缺陷是地域设置不合理容易影响话题识别精度。RO-LDA模型[13]把地域的生成顺排在了话题后面,把文本位置作为模型框架的最底层,认为词汇和位置都是话题生成的,生成顺序是:文本→(话题,地域)→(词汇,位置)。该模型在话题层上建立了地域平行层,通过词汇与位置的映射关系建立话题在地域上的概率分布,从而识别出话题的流行地域。
3 面向地域流动的在线话题演化检测方法
在线话题作为一种网络信息实体会随着时间动态演化,表现为话题的分裂、膨胀、合并、消失等。由于话题具有位置属性,所以线上话题在演化的过程中,其线下流行地域也会随之演化,表现为地域的分裂、膨胀、合并、消失等。文献[12]提出了话题遗传思想,运用马尔科夫链建立了话题演化模型OLDA。该模型假设在无外力干扰的情况下,t时刻话题的生成只受到t-1时刻话题状态的影响,通过建立相邻时刻的话题地域遗传矩阵,有效提高了t时刻话题识别精度。受OLDA模型话题遗传思想启发,经分析发现:由于话题容易受到用户兴趣和社会环境影响,在特定社会环境下用户发布的文档会含有相似的话题。而在没有外力干扰的情况下,社会环境和用户兴趣也是平滑的,所以,话题的地域特征也有和话题一样的遗传特性。因此,本文在OLDA模型中增加(话题,地域)层,搭设话题地域的遗传接口,建立地域性话题演化模型EIAGT。该模型综合运用t-1时刻的话题地域遗传信息,建模t时刻文本-话题分布和(话题,地域)-位置分布,具备了话题地域演化识别能力。
3.1 EIAGT模型描述
设Dt={d1,d2, …,dM}为t时刻网络数据集,K为Dt中隐含的话题数量。V={w1,w2,…,wN}表示Dt中的词汇集合;R={r1,r2,…,rG}表示Dt中位置标签集合;U={
分布1[文本-话题]t:对于Dt中任意文本dm,生成K维话题分布向量Ad=
(2)
分布2[话题-词汇]t:对任意话题zi,生成N维词汇分布向量Bz=
(3)
分布3[话题-地域]t:对任意话题zi,生成G维地域分布向量Hz=
(4)
分布4[(话题,地域)-位置]t:对任意(话题,地域)li,生成S维位置分布向量E(z, l)=
(5)
根据变量之间的依赖关系,模型的建模步骤如下:
第1步,利用t-1时刻话题和地域的遗传信息建立t时刻话题遗传矩阵wt-1和地域遗传矩阵vt-1;
第2步,从文本-话题分布At中随机生成一个话题zi;
第3步,以Interface-β(wt-1)为先验从对应的话题-词汇分布Bt中随机抽取一个词汇wi;
第4步,以Interface-δ(vt-1)为先验从话题-地域分布Ht中随机抽取一个地域li;
第5步,从地域-位置分布Et中随机抽取一个位置ri;
第6步,返回至第2步,直到生成所有的词汇和位置。
从生成过程来看,EIAGT模型在主题层上映射出了一个地域层,地域层又映射出了一个位置层,所以EIAGT模型是一个4层贝叶斯网络,其生成结构如图1所示。

图1 EIAGT模型生成示意图
图1中,方框表示抽样次数,箭头表示依赖关系。话题z和地域l是隐含变量,实心圆圈词汇w和位置r是可观测值,各符号代表的含义如表1所示。

表1 EIAGT模型参数说明
3.2 话题地域遗传矩阵的建立
3.2.1话题地域遗传度计算
话题z在地域l上的特征包括:话题z在地域l上的文本数量;话题z在地域l上的用户数量;话题z在地域l上的用户影响力以及话题z在地域l上的用户交融度。我们用特征增量作为遗传度量标准,则t-1时刻话题z在地域li上遗传度计算公式如(6)所示:
(6)
(7)

(8)
式(8)中,UStr表示话题用户之间产生信息交流的用户数量,|U|表示用户总数。
EIAGT模型将t时刻(主题,地域)-位置分布矩阵νt的生成过程看成马尔可夫链,把t-1时刻的主题位置后验作为t时刻νt的条件先验,先验的传递是通过调节超参δt的来值实现的。超参δt的计算公式如(9)所示。
(9)
其中,Lt表示t时刻话题地域向量中的位置个数,Rank是个符合正态分布的随机变量用来调节遗传偏离。
3.2.2相邻时刻的话题对齐
在EIAGT模型中,t时刻的话题数量K是动态获取的。如果t-1时刻和t时刻的话题数量不相同,在先验遗传时t-1时刻的话题地域遗传矩阵和t时刻的生成矩阵就无法对齐,容易造成话题地域信息的遗传错位。为了避免矩阵相乘带来的误差,需要对两个时刻的位置演化矩阵ν进行对齐操作。对其操作如下:
假设t时间片内的话题数为K,话题演化矩阵C遵循如下原则:①若t-1时间片中的话题数大于K,则Bt-1和Ht-1按分布强度topK原则缩减至K行;②若t-1时间片中的话题数小于K,则Bt-1和Ht-1增加到K行,增加的行向量按分布均值均匀填充。
3.3模型生成过程的公式推导
由于模型中存在隐含变量z和l,直接对参数进行精确推导比较困难。通常情况下,需要通过变量之间的依赖关系建立变量之间的联合概率,然后求解可观测变量w和r的边缘分布,消去隐含变量,得出w和r的生成概率,最后再运用吉布斯采样算法对可观测变量进行迭代,得出At、Bt、Et稳定的近似分布。
3.3.1t时刻词汇w、位置r的生成概率推导
t-1与t两个时刻之间产生的文本形成t时刻文本集,用Dt表示。根据EIAGT的生成过程,文档di∈Dt生成一个服从Dirichlet分布的话题多项式混合,记为Ad。话题zi∈di生成一个服从Dirichlet分布的词汇多项式混合,记为Bz。同时,话题zi又生成一个服从高斯分布的位置多项式混合,记为Ez,每一维高斯分布表示话题的一个地域。高斯分布的最大值对应的位置为话题的地域中心。由于话题存在于多个地域上,所以模型在生成话题位置时,首先选取话题zi生成概率top 100的文档位置作为话题中心,然后按照最小距离dist阈值对这些位置进行聚类,得出话题的多个种子地域,最后依次搜索文本位置并与所有种子的地域中心进行比较,把符合阈值的文本位置分配给话题相应的种子地域,如果地域之间的距离小于阈值时,进行地域合并。
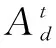
P(At,Bt,Et,w,r,z|αt,βt,δt,wt-1,vt-1)=
(10)
对公式(10)右边部分继续分解如下:
(11)
公式(11)中,Γ(·)表示标准伽玛函数,xd,r表示在r位置内的文本d分配给主题z的词汇数量,x表示在r位置内文本d的词汇总数。
(12)
公式(12)中,yr,z表示话题z在位置r上出现的频数,y表示话题z在所有位置上出现的总频数。

(13)
公式(13)中,cl,w表示地域l上分配给话题z的位置数量,c表示地域l上位置总数。由公式(10)得出w和r的采样公式。

(14)
公式(14)表示采样词汇w在话题zi中且不再z-i中,采样位置r在地域li中且不在l-i中的联合概率。
3.3.2w和r的采样过程
在EIAGT模型中,为了保持话题演化的连续性,通过t-1时刻的遗传矩阵来动态调节t时刻超参αt、βt、δt的分布。然后,使用先验信息依次遍历Dt中的所有文本,动态更新At、Bt、Et三个分布,At、Bt、Et的更新公式如(15)~(17)所示,每遍历一次Dt算作一次采样。
(15)
(16)
(17)
对公式(14)进行反复采样迭代,达到设定的迭代次数或者At、Bt、Et三个分布达到稳定的转移状态后停止采样。
3.4 算法描述
EIAGT模型建立了文本、话题、地域、词汇、位置五者之间的依赖关系,在At、Bt、Et三个分布内形成了一个隐马尔科夫链。根据马尔科夫链的收敛性质,需要对语料库中的可观测量w和r进行采样,采样算法描述如下:
Input:(1)超参α,β,δ; (2)初始时刻t, 位置距离阈值dist。
Output:At,Bt,Et。
IFt= 1 Then
初始化话题遗传矩阵,设定值为αt=β/K;
Else IFt>1 Then
K= Get-K(Dt);//获取t时刻数据集中的话题数
αt=βt/K;
βt= Interface-β(wt-1);//获取话题遗传先验
γt= Interface-δ(vt-1);//获取话题地域的遗传先验
Forl=1 toL
Fork=1 toK
Choosealk~Multi(γtk) fromHt;
For eachr∈lk
Chooseari~Multi(lk) fromEt;
Createzn→lk//建立话题与地域的映射关系
Fori=1 toM
Forj=1 toN
Choose azdn~Multi(θdi) fromAt;
For eachw∈di
Choose awi~Multi(zdn) fromBt;
For eachr∈liandPr> dist
Chooseari~Multi(lzn) fromEt;
Merge(lj,ri);//把位置ri合并到lj中
End For
End For
End For
t=t+ 1;
Createwt-1with Interface-β( );
Createvt-1with Interface-δ( );
End IF
模型在迭代的时候,依次扫描文档、词汇及词汇位置。由于文档并不是由所有词汇构成的,地域也不包含所有位置,所以文本长度设为文本长度的均值lw。每个地域中的位置数量设为所有地域位置数量的均值lr。地域和话题是平行层,文本数量为M,迭代次数为Niter,主题数为K,地域数为G,所以,算法的时间复杂度为O(Niter×M×(Klw+Glr))。
4 实 验
4.1 数据来源及预处理
我们使用“八爪鱼”网络数据采集器爬取了2020年1月10日~2月6日微博热门板块中用户发帖文本数据,共计56 982条。每条数据包括文本内容、发布时间、位置等三个字段。实验数据纳入标注:①所有字段无缺失值;②文本字段需包含汉字。根据纳入标准对不符合要求的数据进行清洗后,得到有效数据52 976条。然后,使用ICTCLAS分词软件对文本进行分词,去除停用词、介词、语气词、转折词等无用词后,建立大小为M×(2+N)的文本矩阵D,每一行表示一条文本信息,其中,第1列存放文本的发布时间,第2列存放文本发表的位置,后N列存放文本分词结果。按照4天的时间间隔划分D,建立数据流Dt=1~Dt=7。需要说明的是:用户发帖时系统会根据用户的位置以“省”为位置单位标识出用户的位置信息,为了便于建模,我们按照字母升序对省份名称进行编号,如:安徽省的编号为r01。
4.2 实验结果分析
当t=1时,EIAGT模型以初始状态开始运行,参数设置为:αt= 0.5/K,βt= 0.01,δt= 0.01;当t>1时,αt= 0.5/K,βt= Interface-β(Et-1),δt= Interface-δ(Et-1)。话题数K为Dt中的最优话题数,由话题最优化函数返回得到[14]。话题位置的生成概率阈值设定为0.010。按照位置生成概率排序,选择Top 10作为地域中的位置数量。以上参数均为经验最优[15]。
4.2.1话题位置的动态识别
EIAGT模型依次对t=1到t=7连续数据段进行运算,共识别出话题169个。按照生成概率从大到小的顺序,从Bt中选取出10个词作为话题特征词,从Et中选取8个位置作为话题流行的地域。EIAGT模型识别出的话题和位置信息如表2所示。另外,由于篇幅限制,每个时间段内仅列举出了热度排名前3的话题。最后,我们把相邻时刻话题链接[11]之后,得出7个热点话题,话题序号按照话题出现的先后进行编排,话题流行地域用位置编号表示。

表2 连续时刻话题特征词及位置识别结果
根据表2中的话题特征词,使用人工方法对7个话题进行内容概括。概括过程如下:首先,在各数据流Dt=i内以话题特征词作为检索词抽取包含该话题特征词的所有文本;然后,由两人共同探讨概括出文本所表达的话题,如果出现意见不一致,则引入“第三人”进行判断。按照这种方式,7个话题的内容概括如下:
话题1:关于春节相关的话题;
话题2:关于旅游的话题;
话题3:关于新冠疫情的话题;
话题4:关于赵忠祥去世的话题;
话题5:关于武汉封城的话题;
话题6:关于科比去世的话题;
话题7:关于复工复产的话题。
4.2.2话题的线上特征分析
从图2中可以看出,持续时间最长的是话题1和话题3,分析原因是因为话题1讨论的是春节相关话题,因为春节是中国人最重要的节日之一,这个话题是人们都爱讨论的;另外,这段时间正是我国疫情发展的初始阶段,大家都在关心疫情发展,所以话题3的持续时间也非常长。话题2在t1时刻后热度就降低了,可能是因为受疫情的影响,很多旅游计划都不能成行,促使了旅游话题的消失。赵忠祥去世和科比去世都是爆炸性新闻,但是热度都只持续两个时间段,且强度不强,主要原因还是因为我国疫情的发展,人们关注的焦点又迅速地转移到了疫情之上。

图2 话题持续的时间分布
4.2.3话题的线下特征分析
话题的线下特征识别包括话题的地域演化识别和流行地域上的话题强度演化识别。本文以话题3为例来说明话题线下特征的识别过程。表3给出了话题3在t1~t4连续时间段上的流行地域热度。
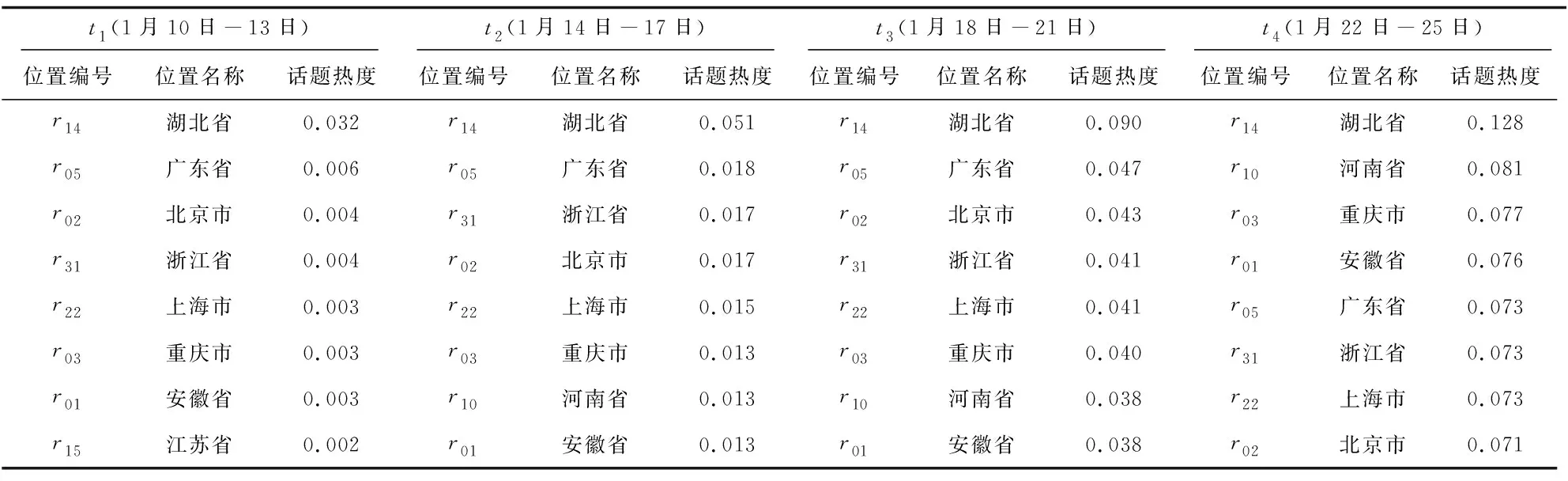
表3 连续时间段上话题3在流行地域上的热度变化
在表3中,在t1时间段,话题3的主要流行地域在湖北省,因为这个时期疫情刚处于发展阶段,外围省份的网民对此关注的还相对较少。在t2时间段,话题3已经向周边省份扩散,一些发达省份话题热度开始逐步增强,原因可能是因为这些地区人口多,网民基数大,发帖量多等原因造成的。在t3时间段,随着疫情的迅猛发展,话题3在湖北省的热度持续走高,且在其他省份的热度也在不断增强。在t4时间段,随着疫情的发展以及大量在外务工人员返乡过年等原因,话题3逐步向中西部流动,表现在河南、安徽、重庆等省市的话题强度明显增长。
4.3 模型性能评价
4.3.1困惑度对比
困惑度(Perplexity)是检测话题聚类质量的评价标准[16],困惑度越小,算法性能越好。为了验证EIAGT模型话题识别的有效性,我们选取OLDA、LDA、TF-IDF[17]、PLSA[18]四个经典话题模型作为对比对象,从每个时间段数据集中随机抽取70%的文本数据作为训练集,剩下的30%作为测试集,各算法在7个连续数据集上话题困惑度对比如图3所示。

图3 困惑度对比
从图3中可以得出,本文模型的困惑度与OLDA相近,均低于其他3个模型,说明EIAGT模型的话题识别精度达到了OLDA的水平,话题识别效果较好。分析原因是因为本文模型与OLDA模型都利用了历史语料信息,使得话题生成先验更加贴近t时刻文本环境,提高了话题先验的准确性。而其它三个模型仅凭人工经验来设定模型的超参,对语料环境一无所知,这就容易造成话题后验的计算偏差。
4.3.2话题地域识别性能对比
为了验证本文模型的有效性,我们采用准确率、召回率和F值作为评价指标,以RO-LDA[13]、GTTD[8]、LGT[19]、GT[20]作为对比对象,在本文提供的7个连续数据集上依次运行这些算法。然后,把各模型识别出的话题地域与人工标注结果进行对比,准确率、召回率、F值分别如表4~表6所示。

表4 准确率对比(%)

表5 召回率对比(%)

表6 F值对比(%)
在表6中,EIAGT模型的综合F值高于其它模型,说明EIAGT模型的话题地域识别性能最好。从对比结果来看,文本方法与当前流行的GTTD和RO-LDA模型相比,有两个方面的优势:一是模型假设优势,二是话题地域遗传优势。GTTD模型基于兴趣聚类假设,认为相同区域内相近的人更容易具有相似的兴趣话题,挖掘生成顺序是地域→话题。这种生成顺序把话题约束在了事先设定的区域内,在区域内热点话题的地域分布挖掘方面具有较强的优势,但在广泛范围内的话题地域识别精度不是很理想。RO-LDA模型的生成顺序恰好与GTTG相反,它在采样话题词的时候一并采样词汇位置,通过对话题词的聚类,建立话题地域层,该模型的生成顺序是话题→地域。这种方式打破了话题的地域限制,更容易识别话题在多地域上的分布,所以在广泛性话题挖掘上RO-LDA要好于GTTD。但是GTTD和RO-LDA都是静态模型,模型超参是根据人为经验设定的,很难判定当前语料环境下的话题和话题地域的最优先验。而本文方法是个动态模型,不仅借鉴了RO-LDA模型的地域生成假设,还利用话题遗传和地域遗传思想,提高了话题和话题地域的识别精度,使得EIAGT模型性能有了进一步的提高。
5 结 语
本文利用OLDA模型的在线话题演化识别能力,在其三层生成框架的基础上增加了(话题,地域)层,建立了地域性话题演化识别模型EIAGT。该模型利用t-1时刻话题和话题地域的遗传信息训练出话题-词汇分布Bt和(话题,地域)-位置分布Et,具备了线下话题流行地域的演化识别能力。经过实验并与其它流行模型进行对比,本文方法不仅在话题识别性能上达到了OLDA模型的水平,而且在话题流行地域的识别性能上也达到了良好效果。
由于EIAGT模型的话题及话题地域遗传信息都是基于时间平滑假设计算得到的,影响了模型在t时刻的话题感应灵敏度,对话题的突变挖掘效果较差。所以如何提高EIAGT模型在时间平滑假设下的突发话题识别速率, 以及基于时序与空间数据学习模型[21,22]下的话题地域挖掘将是我们下一步的研究工作。
