基于近邻规则和粒子群优化的半监督自标记方法
2023-10-16黎隽男
周 鹏,刘 河,黎隽男
(1.重庆人文科技学院 工商学院,重庆 401524;2.重庆市教育科学研究院,重庆 400015;3.重庆工商大学 人工智能学院,重庆 400067)
0 引言
数据分类[1]是统计机器学习中的一个重要任务。在数据分类中,通过学习足够的有标记样本,一个分类模型能对无标记样本进行类别预测。半监督分类能利用少量有标记和大量无标记的样本去训练分类模型和完成分类任务。经过数十年的研究,学者们提出了许多半监督分类范式[2],包括半监督支持向量机、半监督优化路径森林[3]、半监督k近邻分类器[4]、半监督自标记方法[5]等。半监督支持向量机、半监督优化路径森林和半监督k近邻分类器是算法水平方法。他们能改进传统的分类器(或分类模型),如支持向量机分类器、优化路径森林分类器[3]和最近邻分类器[4],以使得被改进的分类器能适用于包含有标记和无标记样本的半监督数据集。而半监督自标记方法是数据水平方法,它能用被自己预测的样本来扩充初始的有标记集,然后用被扩充的有标记集来训练给定的分类模型和完成数据分类任务。
Yarowsky(1995)[5]提出了最早的自标记方法,并把它应用于文本分类。Triguero等(2015)[6]于2015年对自标记方法进行了综述,并把自标记方法大致划分为自训练方法、协同训练方法、基于多视图的自标记方法和基于分歧的自标记方法。STSFCM(Self-Training with Semi-Supervised Fuzzy C-Means)[7]和STDP(Self-Training with Density Peaks)[8]是典型的自训练方法。在迭代过程中,STSFCM和STDP分别用半监督模糊C均值聚类[9]和密度峰值聚类[10]来发现容易被预测正确的(即具有高置信度的)无标记样本,并用一个给定的分类器来迭代地预测和学习他们。
Triguero 等(2014)[11]发现,由于初始有标记样本数量不足和分布受限,因此在迭代过程中,自标记方法会不可避免地误预测无标记样本。如果自标记方法把被误预测样本加入有标记集,那么自标记方法的性能将明显降低,且将造成更多的误预测。学者们提出用数据剪辑技术(如ENN(Edited Nearest Neighbor)[11]、CEWS(Cut Edge Weight Statistic)[11]、ENaNE(Extended Natural Neighbor Editing)[12]等)去识别和移除在自标记方法迭代过程中的被误预测样本,从而克服误标记。例如,MLSTE[13]用ENN 去识别和移除在自训练方法迭代过程中的被误预测样本。STDPCEWS[14]用CEWS 去识别和移除在STDP 迭代过程中的被误预测样本。STDPNF[13]用ENaNE 去识别和移除在STDP迭代过程中的被误预测样本。然而,许多数据剪辑技术严重依赖于特定的假设。例如,ENN、CEWS 和ENaNE 假设被误预测的样本与其周围样本有不同的类别。当给定假设不被满足时,数据剪辑技术容易误识别被误预测的样本。
为了克服误标记问题和相关解决方案(即数据剪辑技术[11—14])中的缺陷,本文提出一种基于近邻规则和粒子群优化的自标记方法(a Self-Labeled Method based on Nearest Neighbor rules and Particle Swarm Optimization,SLM-NNPSO),采用一种新的近邻规则去快速地发现具有高置信度的无标记样本,提出用粒子群优化算法去识别和移除被误预测的样本,而无须依赖任何假设,并在来自销售市场、医学检测、图像识别等领域的真实数据集上进行仿真实验,以验证SLM-NNPSO的优越性。
1 理论基础
1.1 基本术语和符号
设XSSL={x1,…,xn}代表一个包含有标记和无标记样本的半监督数据集,XSSL=XL∪XU。XSSL中的样本数为n。XL={(x1,y1),(x2,y2),…,(xl,yl)}代表有标记样本集。yi(i=1,2,…,l)是样本xi的类标记。XU={xl+1,…,xn}代表无标记样本集。xi={xi,1,xi,2,…,xi,d,…,xi,D}代表具有D个属性的第i个样本。本文涉及的主要术语和符号如下:
(1)Particle={P1,P2,…,PN}代表一个拥有N个粒子的粒子群。
(2)Si=(Si,1,Si,2,…,Si,M)代表粒子Pi的位置向量。
(3)Vi=(Vi,1,Vi,2,…,Vi,M)代表粒子Pi的速度向量。
(4)c1和c2代表学习率。
(5)w代表惯性权重。
(6)gbest代表粒子群Particle中最好的粒子的位置。
(7)pbesti代表粒子Pi在迭代过程中的最好位置。
(8)NN(xi,XSSL)代表样本xi在半监督数据集XSSL上的k近邻集合。
(9)XConf代表具有高置信度的无标记样本集。
(10)Xnew代表新预测的样本集。
(11)Xcorrect代表被正确预测的样本集。
(12)代表用粒子Pi在Xnew上形成的样本子集。
(13)fitnessig代表粒子Pi第g次迭代的适应度值。
(14)fitnessgbest代表最好粒子的适应度值。
1.2 粒子群优化算法
Kennedy和Eberhart于1995年提出了粒子群优化算法(Particle Swarm Optimization,PSO)[15]。与传统方法(如数据剪辑技术等)[11—14]相比,PSO 不需要对样本的几何、分布、类关系等作出具体假设[16]。与遗传算法、蚁群算法、模拟退火算法等优化算法相比,PSO易于实现,收敛速度快,且易于找到全局最优解。PSO有两种版本,即CPSO(Continuous PSO)[17]和BPSO(Binary PSO)[16]。学者们已经把BPSO应用于许多组合问题,如特征选择、样本子空间优化等[16,17]。接下来,本文简单地介绍BPSO的原理。
设Particle={P1,P2,…,PN}是一个拥有N个粒子的粒子群。每个粒子Pi(i=1,2,…,N)有一个位置向量Si=(Si,1,Si,2,…,Si,M) 和 速 度 向 量Vi=(Vi,1,Vi,2,…,Vi,M) 。M是针对特定问题的解空间的维数。位置Si,j(i=1,2,…,N;j=1,2,…,M)仅有0或1的值,这暗示是否需要选择粒子Pi(i=1,2,…,N) 的第j(j=1,2,…,M) 个解空间。起初,BPSO用式(1)和式(2)来初始化每个粒子Pi的位置向量Si和速度向量Vi:
在式(1)中,函数rand()返回0至1之间的随机值。在式(2)中,Vmax是一个参数,它用来控制每个粒子Pi的速度Vi,j的最大值。当初始化位置向量Si和速度向量Vi之后,BPSO迭代地更新每个粒子Pi的速度向量Vi和位置向量Si,并计算每个粒子Pi的适应度值(通常用一个与问题相关的适应度函数来计算适应度值),直到BPSO达到最大迭代次数G。在迭代过程中,BPSO用式(3)和式(4)来更新每个粒子Pi的速度向量Vi和位置向量Si。
在式(3)中,r1和r2是0 到1 之间的随机值;c1和c2是学习率参数;w是惯性权重参数;gbest代表在粒子群Particle中的最好粒子的位置,最好粒子具有最大的适应度值,gbestj代表最好粒子的位置在第j(j=1,2,…,M)个解空间上的值;pbesti代表粒子Pi在迭代过程中的最好位置,gbestj和pbesti,j仅有0或1的值。当迭代结束之后,BPSO 输出在粒子群Particle中的最好粒子的位置gbest。受BPSO 的启发,本文所提出的SLM-NNPSO 用BPSO 来识别和移除被误预测的样本,从而克服误标记问题,且无须特定的假设。
2 基于粒子群优化算法的半监督自标记方法(SLM-NNPSO)
SLM-NNPSO的流程图如下页图1所示。SLM-NNPSO包含如下主要步骤:(1)SLM-NNPSO 用有标记集XL去训练一个给定的分类模型C;(2)SLM-NNPSO 用近邻规则从无标记集XU中发现具有高置信度的无标记样本集XConf;(3)SLM-NNPSO 用分类模型C来预测具有高置信度的无标记样本的类别,从而形成新预测的样本集合Xnew;(4)SLM-NNPSO 用BPSO 来识别和移除被误预测的样本,并把被正确预测的样本Xcorrect加入有标记集XL中;(5)重复步骤(1)至步骤(4),当没有发现具有高置信度的无标记样本时,SLM-NNPSO 输出在迭代过程中被训练的分类模型C。

图1 SLM-NNPSO的流程图
2.1 采用近邻规则发现具有高置信度的无标记样本集
在SLM-NNPSO 的迭代过程中,SLM-NNPSO 用近邻规则从无标记样本集XU中发现一些容易被分类模型预测正确的无标记样本,即具有高置信度的无标记样本,如定义1所示。
定义1(具有高置信度的无标记样本):设NNk(xi,XSSL)代表样本xi在半监督数据集XSSL上的k近邻集合。如果一个无标记样本xi是具有高置信度的无标记样本,那么xi在半监督数据集XSSL上的k近邻集合包含有标记样本,且这些有标记样本仅属于某一类,如式(5)所示。
在式(5)中,函数l()返回给定样本的类别。因此,l({xj|xj∈NNk(xi,XSSL)}) 返回集合{xj|xj∈NNk(xi,XSSL)}中的所有样本类别。函数unique()返回给定集合不重复的值。因此,unique(l({xj|xj∈NNk(xi,XSSL)})) 返回l({xj|xj∈NNk(xi,XSSL)})中的不重复的类别。如果|unique(l({xj|xj∈NNk(xi,XSSL)}))|等于l,那么无标记样本xi在半监督数据集XSSL上的k近邻集合包含某一类有标记样本。
2.2 采用粒子群优化发现和移除被误预测的样本
虽然SLM-NNPSO能发现一些具有高置信度的(即容易被预测正确的)无标记样本给被训练的分类模型预测和学习,但是由于初始有标记样本过少且可能包含噪声,SLM-NNPSO 仍可能误预测无标记样本,因此,在SLM-NNPSO 的迭代过程中,SLM-NNPSO 用BPSO 在新预测的样本集Xnew中识别和移除被误预测的样本,从而形成被正确预测的样本集Xcorrect。实际上,上述问题可以被视为一个基于BPSO 的样本子空间优化(Sample Subspace Optimization, SSO)问题[16,17]。BPSOSSO 的伪代码如算法1所示(见表1)。

表1 算法1:BPSOSSO
如前文描述,BPSO 拥有具有N个粒子的粒子群Particle={P1,P2,…,PN}。每个粒子Pi有一个速度向量Vi=(Vi,1,Vi,2,…,Vi,M) 和位置向量Si=(Si,1,Si,2,…,Si,M) 。在SLM-NNPSO中,每个粒子Pi可以视为Xnew中的一个样本子集。同样,Si,j(i=1,2,…,N;j=1,2,…,M)仅有0 值或1 值。如果Si,j等于0,那么用粒子Pi所形成的样本子集包含Xnew中的第j个样本,反之亦然。在SLM-NNPSO 的BPSO 中,M等于Xnew的样本个数(即|Xnew|)。SLM-NNPSO 中的BPSO 需要一个与问题相关的适应度函数去评估每一个粒子的适应度值。本文用式(6)来计算每个粒子Pi的适应度值。
在式(6)中,fitnessig代表粒子Pi在第g次迭代中的适应度值;accuracy(f,XTraining,XValidating)返回一个给定分类器f在验证集XValidating上的分类正确率,且分类器f把XTraining作为训练集。本文把式(6)中的分类器f设置为k近邻分类器(k=3),且让XTraining=XL∪,并让XValidating=XL。算法1 描述了用BPSO 去识别和移除被误预测样本的伪代码。本文把算法1 记为BPSOSSO(BPSO-based SSO)
在算法1的第9行上,fitnessgbest代表在Particle中最好粒子的适应度值。在算法1的第18行上,代表粒子Pi在第g次迭代中的位置向量。在算法1 的第26 行上,算法1用gbest来从Xnew中发现样本 子 集Xcorrect。 具 体 地,如 果gbestj(j=1,…,M) 为0,那么这代表子集Xcorrect包含Xnew中的第j个样本,反之亦然。与数据剪辑技术[11—15]相比,由于BPSO 的特性,因此算法1无须对样本的几何、分布、类关系等作出具体假设。
2.3 SLM-NNPSO的伪代码和特性
SLM-NNPSO的伪代码如算法2所示(见表2)。
SLM-NNPSO 需 要 输 入 参 数c1、c2、Vmax、G、w和k。其中,c1和c2是算法1中的学习率参数;Vmax是算法1中的速度边界参数,G是算法1 中的最大迭代次数参数,w是算法1 中的惯性权重参数,k是用于公式(5)和发现高置信度无标记样本的参数。在算法2 的第5 行上,SLM-NNPSO 用BPSO(即算法1BPSOSSO)重新标记集合Xnew中选出被正确标记的集合Xcorrect,从而过滤掉被误预测的样本,且不需要特定的假设。接下来,本文将用实验来证明SLM-NNPSO的有效性。
3 仿真实验
3.1 仿真实验的设置
本文用一台具有2.10GHz 的Inter(R)Xeon(R)Silver 4100 CPU 和32G 内存的个人电脑去运行所有的仿真实验。从UCI机器学习公开数据库(http://archive.ics.uci.edu/ml/)和Kaggle 机器学习公开数据库(https://www.kaggle.com/)中选取12个真实数据集来作为实验的数据。表3详细地描述了这12 个真实数据集的名称、属性数、样本数、类别数和应用背景。
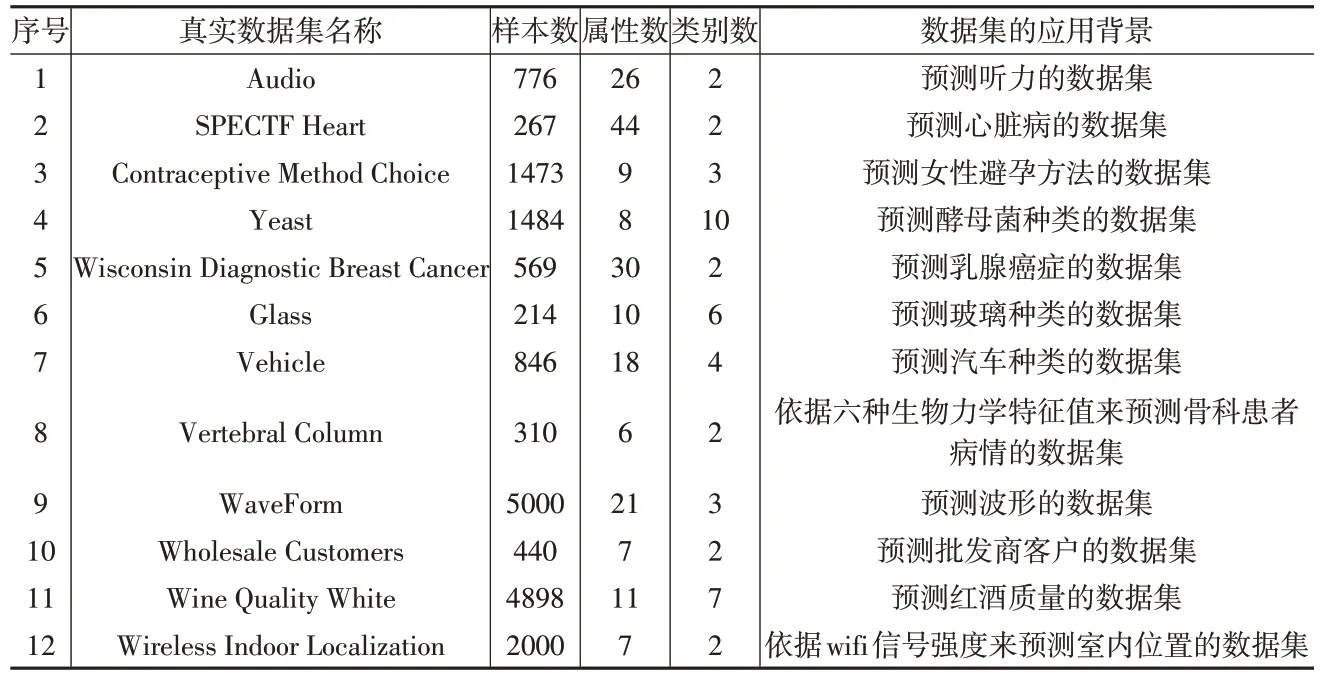
表3 实验的真实数据集
从表3 中可以发现,实验数据集的样本数在214 到5000范围内,实验数据集的属性数在6到44范围内,实验数据集的类别数在2到10范围内。本文用10折交叉验证把每个真实数据集划分为测试集和训练集。在训练集中,本文把10%~50%的样本作为有标记样本,并且把剩余样本作为无标记样本。全部实验重复10 次,把10 次实验的平均分类正确率(Average Classification Accuracy,ACA)作为评估标准,如式(7)所示:
在式(7)中,代表第i次实验的测试集,代表在中被训练的分类模型预测正确的样本。另外,表4描述了实验所采取的对比方法。本文将5个流行的半监督自标记方法作为对比方法。在表4中,MLSTE[13]、STDPCEWS[8]和STDPNF[9]是自训练方法,Op-FSCO[18]是基于多视图的自标记方法,Tri-training[19]是基于分歧的自标记方法。本文把对比方法的参数设置为他们的标准版本。

表4 用于对比的半监督自标记方法
在对比方法中,本文把k近邻分类器(k=3)设置为最终训练的分类器。换句话说,在实验中,表4 中的自标记方法用少量有标记样本和大量无标记样本去训练k 近邻分类器(k=3)。然后,本文用平均分类正确率来评估对比方法的有效性。
3.2 采用真实数据集验证SLM-NNPSO
本文用表3中的真实数据集和表4中的对比方法来验证SLM-NNPSO 的有效性。用10 折交叉验证把每个真实数据集划分为训练集和测试集,在每个真实数据集的训练集上,把10%的样本作为有标记样本,且把剩余样本作为无标记样本。
下页表5展示了对比方法就训练k近邻分类器的平均分类正确率。从表5 中可以看出,在8 个真实数据集(即Audio、SPECTF Heart、Wisconsin Diagnostic Breast Cancer、Glass、Vehicle、Vertebral Column、Wholesale Customers 和Wine Quality White)上,SLM-NNPSO实现了最高的平均分类正确率。在4 个真实数据集(即Contraceptive Method Choice、Yeast、WaveForm 和Wireless Indoor Localization)上,SLM-NNPSO 所实现的平均分类正确率稍微低于对比方法。可能的原因是,由于有标记集包含噪声或离群点,因此SLM-NNPSO 中的BPSO(即算法1BPSOSSO)仅搜索到一个局部最优解。

表5 对比方法训练k近邻分类器的平均分类正确率 (单位:%)
从表5中的“平均值”行也可以发现,在所有数据集的平均分类正确率上,SLM-NNPSO能实现最高的平均值,且比MLSTE、STDPCEWS、STDPNF、Op-FSCO 和Tri-training分别平均高出1.11%、1.25%、0.55%、1.53%和1.19%。
本文用Friedman检验[20]中的平均秩去分析表5中的数据。平均秩是表5中各组数据的秩的平均值。例如,对比方法在表5 中的“Audio”行上的秩(升序)为1,3,4,2,5,6。如果一个对比方法越优越,它将能实现越高的平均秩。从表5 的平均秩行可以看出,SLM-NNPSO 实现了最高的平均秩。
另外,本文也采用Wilcoxon 秩和检验[20]去分析表5 中的数据。本文把Wilcoxon 秩和检验的显著性水平设置为0.05。在表5 的“Wilcoxon 秩和检验”行中,符号“+”代表SLM-NNPSO 显著地优于该栏上的对比方法,符号“=”代表SLM-NNPSO和该栏上的对比方法没有显著差别,符号“-”代表该栏上的对比方法显著优于SLM-NNPSO。从表5 的“Wilcoxon 秩和检验”行可以看出,就训练k 近邻分类器而言,SLM-NNPSO 显著地优于MLSTE、STDPCEWS、Op-FSCO和Tri-training。
总的来说,表5 中的数据能证明,在大多数的数据集上,SLM-NNPSO能优于5个流行的自标记方法。
3.3 有标记样本比例影响的实验验证
为了讨论初始有标记样本比例的影响,本文把初始的有标记样本的比例从10%增加到50%。图2 展示了对比方法在不同有标记样本比例的情况下训练k 近邻分类器的平均分类正确率。

图2 对比方法在6个真实数据集上的平均分类正确率
从图2 可以看出,随着初始有标记样本比例的增加,初始有标记样本将变多,且所有对比方法将实现更高的平均分类正确率。另外,当初始有标记样本比例为10%、20%、40%和50%时,SLM-NNPSO 在Wisconsin Diagnostic Breast Cancer 上实现了最高的平均分类正确率。当初始有标记样本比例为10%、40%和50%时,SLM-NNPSO 在Vehicle 上实现了最高的平均分类正确率。当初始有标记样本比例介于10%~50%时,SLM-NNPSO 在Vertebral Column 上实现了最高的平均分类正确率。当初始有标记样本比例为10%、40%和50%时,SLM-NNPSO在Wholesale Customers上实现了最高的平均分类正确率。当初始有标记样本比 例 为 20% 、30% 、40% 和 50% 时,SLM-NNPSO 在Yeast 上实现了最高的平均分类正确率。当初始有标记样本比例为10%、20%、40%和50%时,SLM-NNPSO 在Wine Quality White 上实现了最高的平均分类正确率。
总的来说,图2 中的数据能证明,在大多数的初始有标记样本的比例下,SLM-NNPSO 能优于5 个流行的自标记方法。
3.4 计算效率的实验验证
下页表6 展示了对比方法在真实数据集上的平均运行时间(10次执行)。从表6中可以看出,就平均运行时间而言,在全部数据集上,SLM-NNPSO 快于STDPCEWS 和Op-FSCO。

表6 对比方法的平均运行时间 (单位:秒)
4 结束语
为了克服自标记方法中的误标记问题和相关解决方案(即数据剪辑技术)中的缺陷,本文提出一种基于近邻规则和粒子群优化的自标记方法SLM-NNPSO,其包含如下主要步骤:(1)用有标记集去训练一个给定的分类模型;(2)用近邻规则从无标记集中发现具有高置信度的无标记样本集;(3)用分类模型来预测具有高置信度的无标记样本;(4)用BPSO来识别和移除被误预测的样本,并把被正确预测的样本加入有标记集中;(5)重复步骤(1)至步骤(4),当没有发现具有高置信度的无标记样本时,SLM-NNPSO输出在迭代过程中被训练的分类模型。相比于已有的半监督自标记方法,SLM-NNPSO 具有如下优势:(1)它能用近邻规则去快速地发现迭代过程中具有高置信度的无标记样本;(2)它能用BPSO来识别和移除被误预测的样本,且不需要对被误预测的样本作出具体的假设。在仿真实验中,本文用12个来自各个领域的真实数据集和5个流行的自标记方法(即MLSTE、STDPCEWS、STDPNF、Op-FSCO和Tri-training)来验证SLM-NNPSO的有效性。结果显示:(1)由于SLM-NNPSO能用粒子群优化去更好地克服误标记问题,因此,在大多数的数据集上,且在大多数的初始有标记样本比例下,SLM-NNPSO 均优于5 个流行的自标记方法;(2)就平均运行时间而言,SLM-NNPSO 快于STDPCEWS和Op-FSCO。
