基于未来可预知特征的高速列车变流器超温故障KFF-LSTM预测方法
2023-10-13刘典秦勇杨伟君周伟扈海军杨宁刘冰赵鹏飞董光磊
刘典,秦勇,杨伟君,周伟,扈海军,杨宁,刘冰,赵鹏飞,董光磊
(1. 北京交通大学 轨道交通控制与安全国家重点实验室,北京,100044;2. 中国铁道科学研究院 机车车辆研究所,北京,100081;3. 北京纵横机电科技有限公司,北京,100094;4. 中南大学 交通运输工程学院,湖南 长沙,410075;5. 中南大学 轨道交通安全教育部重点实验室,湖南 长沙,410075)
随着数据、算力、算法、模型的发展,面向高速列车谱系的故障预测与健康管理(PHM)技术[1]涵盖了铁路移动装备结构化、半结构化、非结构化及流式的海量健康状态数据。然而,目前高速列车设备状态异常诊断大部分仍基于传感器测量阈值组合以事后报警的形式呈现,少部分设备的健康态势评估也仅在短期预测具有较高置信度。对于高速运营列车来说,提前几分钟甚至几秒收到预警信息,承运单位难以消除设备故障造成的影响。
长时间序列预测(long sequence time-series forecasting,LSTF)是一种以较高预测容量来捕捉输出与输入之间长距离依赖关系的预测方法[2-4],已在疾病传播[5]、经济金融[6]、能源电力[7-8]、自动驾驶[9]、运量预测[10-11]、状态识别[12]、故障诊断[13-16]等诸多领域成功应用。JORDAN[17]提出了包含单个自连接节点的循环神经网络模型(recurrent neural networks,RNN),该方法在短序列任务上的表现效果优异,但关联长序列反向传播时过长序列导致梯度消失或爆炸,预测效果较差;CHUNG等[18]在传统RNN 基础上提出了门控循环单元结构(gated recurrent unit,GRU),可有效缓解梯度消失或爆炸现象,但仍不能完全解决梯度消失的问题。金晓航等[19]基于转速、温度、功率与风速等风力发电特征数据,采用稀疏自编码神经网络算法对风电机组异常状态预警,但如能结合未来可预知气象数据来强化模型,可取得更好的预测效果;谷歌团队开发的BERT[20]和OpenAI 团队开发的GPT-3[21],以复杂网络结构、海量参数以及强大算力在时序数据预测中取得了成果,在GPT-3 中有1 750亿个参数、96层网络与上百个GPU强大算力支持,但由于铁路场景的算力成本和时效性约束,没有足够的经济性优势。
由于预知推演和工程可实践性的难度,基于未来可预知变量的模型并未广泛应用。但近年来在交通领域基于未来可预知变量的模型已经有了工程应用的实例。2022 年,北京亦庄开设了自动驾驶示范区,基于交通信号灯信息联网,某路口某时刻的红绿灯状态成为未来可预知的变量信息。导航软件通过该未来可预知的信息,并结合路况向司机推荐行驶速度,最终可以通过模型计算实现“全程绿灯”。通过大数据、先验知识及物理定律来预知推演未来某时刻的某变量,可以为既有模型提供更多的可研究方向和应用场景。
高速列车的运营故障诊断面临预测更准、响应更快等挑战,本文作者以牵引变流器电机定子的超温故障为对象,引入静态、缓变、动态物理量与恒定状态量等未来可预知特征KFF(known future feature)数据进行训练。通过调整长短期记忆神经网络(long short-term memory,LSTM)的输出门、状态更新单元及隐变量,降低预测状态与真实状态的物理状态偏差和时间相位偏滞,以优化模型的预测准确度与及时性,并基于高速列车真实运营数据对KFF-LSTM 模型与传统模型进行了对比和分析。
1 KFF-LSTM故障预测模型
1.1 LSTM神经网络基本原理
神经网络预测的准确度与及时性指标定义如图1所示。

图1 神经网络预测的准确度与及时性指标定义Fig. 1 Accuracy and timeliness definition of neural network prediction
LSTM是一种反馈型时间循环神经网络[22],具有长短期信息记忆能力,作为一种特殊递归神经网络,LSTM 隐藏层增加了记忆单元C与遗忘门F,在时间序列轴时间步t时,记忆单元Ct可以从状态向量中进行读取、写入或删除的操作;输入门使记忆单元决定是否更新单元状态;遗忘门使记忆单元可以丢弃其记忆;输出门使单元细胞可以决定输出信息是否可用。LSTM神经元通过输入门、遗忘门和输出门的状态组合和记忆单元操作,实现对长序列数据的预测,其原理如图2所示。

图2 LSTM模型原理图Fig. 2 Schematic diagram of LSTM model
LSTM 模型的输入参数为Xt、记忆层Ct-1、隐藏层St-1,设有遗忘门Ft、输入门It、候选记忆单元为C′t、输出门Ot,输出参数为当前记忆层Ct、隐藏层St和输出Yt,其中Yt为St的一个维度,模型可表征为:
式中,σ为Sigmoid 激活函数;⊙为Hadamard 乘积;tanh 为双曲正切激活函数;wF与bF分别为遗忘门权重矩阵和偏置项;wI与bI分别为输入门权重矩阵和偏置项;wC与bC为候选记忆门权重矩阵和偏置项;wX和wH分别为输出门输入矩阵X和隐状态矩阵H的权重矩阵;bO为输出门的偏置项。
1.2 KFF-LSTM故障预测模型构建
通过在LSTM 神经网络加入未来可预知特征KFF(known future feature)进行训练与优化,形成KFF-LSTM 故障预测模型。模型中引入的未来特征包括不可预知特征数据X(u)和可预知特征数据X(p),对于高速列车时序数据集,其特征状态包括动态物理量、缓变/静态物理量和恒定状态量。
1) 动态物理量是随列车运营工况而实时动态变化的状态特征量。对于部分不可预知的动态物理量,基于固定线路、固定操作指令、里程、时速等信息,以时序平移、前后状态继承、大数据预测等方式可转换为未来可预知的特征值。例如根据列车运行图、运行速度与里程点位置,列车经过给定线路某位置的时刻是可预知的,结合天气预报可预知该时刻、该位置通过列车的室外温度;结合购票检票信息通过旅客及其行李的平均质量可以推算出某区段的列车载运总质量;由于给定线路固定里程位置时接触网压比较稳定,结合线路运行图以及前车通过某里程点的接触网压有效值预知列车到达该里程点的接触网压。
2) 缓变/静态物理量是某行驶区间仅发生缓慢变化或保持不变的列车运行物理特征量。对于固定线路同一车型的某车次列车,其缓变/静态物理量是恒定的,如转向架空气弹簧压力。
3) 恒定状态量是某行驶区间保持恒定的列车运行状态特征量,如软件版本等。
对高速列车牵引变流器的电机定子温度故障相关特征数据集,其物理量特征类型、特征描述、数据来源与是否可预知列表如表1所示。

表1 高速列车牵引变流器电机定子温度物理特征数据集Table 1 Physical features of high-speed train traction converter motor stator temperature
KFF-LSTM 模型算法步骤分为特征选取、预知推演、数据归一化、特征权重分配、模型训练与特征预测。引入历史已知特征与未来可知特征数据的KFF-LSTM模型原理图如图3所示。在特征选取阶段,产品专家按照数据性质将数据分为定类数据、定序数据、定距数据、定比数据,通过行业经验及先验知识进行特征值选取;在预知推演阶段,基于全路列车大数据、物理定律、产品特性,推演动态物理量、缓变/静态物理量在未来时刻的特征值;在数据归一化阶段,通过0均值归一化方法避免数值大的特征对模型训练产生负面效果;在特征权重分配阶段,依据模型预训练结果调整特征权重参数以获得更优的预测效果;在KFF-LSTM 模型训练与特征预测阶段,通过引入未来可预知特征数据,提高模型预测准确性、降低时序偏置(滞后)步数。

图3 KFF-LSTM模型原理图Fig. 3 Schematic diagram of KFF-LSTM model
在KFF-LSTM 预测模型中,为生成预测值Yt和下一个时间片的完整输入,需计算隐藏节点的输出St。当计算未来不可预知特征X(u)(Xt∈X(u))时,沿用原模型表达式;当计算未来可预知特征X(p)(Xt∈X(p))时,由于下一时刻的特征值是已知的,故不需要记忆单元Ct和隐藏状态单元St参与运算,输出Yt的计算公式如下:
在历史区间可预知特征Xt(p)和不可预知特征Xt(u)皆为模型输入,在预测区间可预知特征Xt(p)仍作为模型输入并参与权重矩阵和偏置项计算。
2 牵引变流器电机定子温度预测
2.1 数据集描述与预处理
牵引变流器作为高速列车电能转换的关键部件,在列车运行过程中会产生大幅热量,而服役过程中冷却系统滤网堵塞会导致变流器过热,超温严重时引发烧损等故障,影响列车正常运营。针对高速列车牵引变流器电机定子的超温故障,对某型21 列车的239 个特征采样点收集了10.4 万个数据样本,数据集样本包括线路号、车次号、所在车厢与功能位置等静态物理量,阈值超限标签、操作状态等缓变物理量,日期时刻、里程信息、运行车速、定子温度、冷却液温度、室外环境温度、电机转速/功率/电流/电压等动态物理量。
由于不同车型的设备与技术条件差异,其物理特征的关联影响有所差别;不同线路的列车运行图与里程地理信息完全不同,无法从不同线路中获取有效未来可预知信息,因此,对于不同车型、不同线路的列车运行数据集采用独立的模型参数进行训练及预测。对于多源异构数据集的预处理如下。
1) 统频处理。由于各类传感器采样频率不统一,将所有特征状态数据统频为1/60 Hz(采样间隔1 min),针对超统频的状态数据采用极值重抽样降频,针对低统频的状态数据采用线性插值升频。
2) 数据清洗。对于整备状态列车无运行速度的数据样本,由于数据价值密度低,不是温度故障预测模型关注的状态数据,进行直接删除。
3) 数据填充。由于运营现场工况较为复杂,在数据采集、传输和转储过程中有部分数据缺失,缺失数据用时域最近的上一个样本数据填充。
4) 归一化。牵引变流器电机定子温度相关特征包括温度、电压、电流、压强、质量、长度等物理量,为避免不同物理量单位换算对模型训练的影响,采用0均值归一化对训练验证数据集进行预处理使各特征均值为0、方差为1。
式中:Z为归一化后的特征值;x和xˉ分别为当前样本特征值与数据集样本平均值;N为数据集样本数量。
5) 特征值选取。根据行业专家经验和先验知识,并结合基于数据驱动的特征相关性及贡献度进行特征值选取,区分该特征是否可预知。其中,特征贡献度及特征权重分配采用SHAP模型[23]分析结果为依据进行决策,通过将输出值归因到每一个特征的Shapely 值来评价模型每个特征对结果的贡献度。经各特征对预测结果的正向、负向贡献度分析,特征值贡献度排序由高至低依次为功率类、温度类、状态类、压强类。
2.2 模型训练及预测
基于牵引变流器电机定子温度状态特征数据,将数据划分为训练集和测试集,通过训练集和测试集分别拟合KFF-LSTM、LSTM、GRU、RNN模型,分别以1 步、4 步、8 步、16 步为跨度进行预测。选择平均绝对误差(MAE)、均方根误差(RMSE)和R2分数综合评价各模型预测准确度:
式中:E为平均绝对误差;ERMS为均方根误差;R2为R2 分数;y、与分别为真实值、预测值与真实值的平均值。其中,MAE 用于衡量预测值与真实值之间的平均绝对误差,越小表示模型越准确;RMSE用于评价回归模型预测结果与真实值的偏离程度,其单位与数据集一致,RMSE越低表明模型越稳定;R2 分数是综合评价回归模型的指标,越接近1表示模型综合评价越高。
在滞后性评价方面,基于TLCC算法和数据集的波峰-波谷特性,通过逐步移动模型预测时间序列,计算预测与真实时序数据间的相关性,确定最强相关性所在的移动步数为滞后步数。详细步骤为:将各模型的预测结果向时间轴的负或正方向移动i个时间步,再将平移后的各模型预测数据与真实值进行比较,计算Pearson相关系数ρ,
式中,Cov(·)为两序列协方差,σy与分别为真实值与预测值的自标准差乘积。
根据式(9)计算定位移动i步的相关系数,当系数达到最大时定位移动步数i为滞后步,若i<0,则预测值超前真实值i步,反之滞后i步。
2.3 数据实验结果
通过KFF-LSTM、LSTM、GRU(深度学习神经网络时间序列)与RNN模型分别对某高速列车牵引变流器电机定子温度数据集的前70%数据进行训练集数据预测,对后30%数据集进行测试集数据预测,模型训练不会接触到测试集中的数据,实验结果如图4所示,由于训练集中温度的实际值参与模型训练,故可以通过多次迭代使预测值与训练值趋于一致,难以考量模型泛化性和在新数据集中的效果;测试集中温度实际值不参与模型训练,结果可以验证模型的泛化性,更具备工程可实践性。由图4可见,在训练集部分和测试集部分,本文方法KFF-LSTM 的预测结果曲线更贴合实际结果,即预测结果的准确度和滞后性都比其他模型的更优。
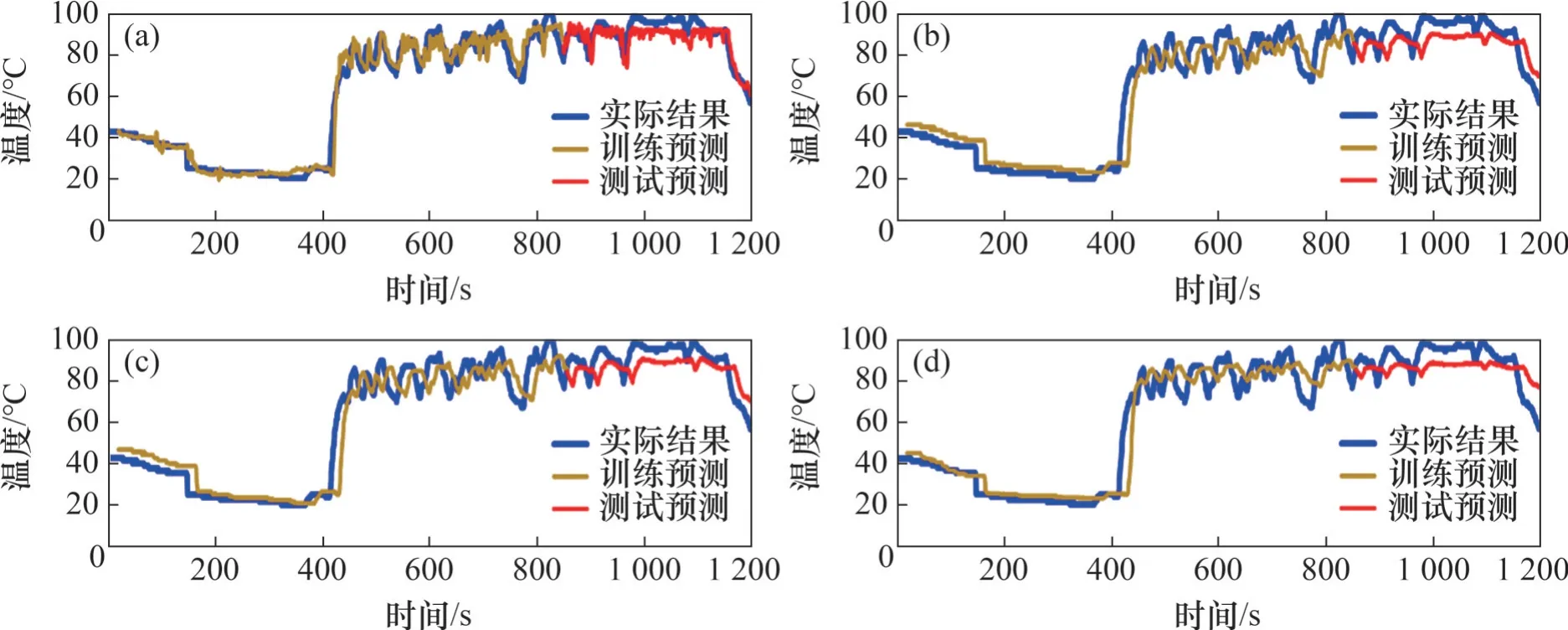
图4 不同模型超前16步预测结果对比Fig. 4 Comparison chart of 16-step prediction results among different models
通过消融实验,分别采用RNN、GRU、LSTM 及KFF-LSTM 模型进行超前1 步、4 步、8步、16 步时序数据预测,在训练集与测试集中计算并对比MAE、RMSE、R2 评价指标,同时对比不同预测区间超前步数下不同方法的偏滞步数以评价不同模型的预测及时性,结果如表2所示。从表2可见:超前1步预测预测时,本文方法预测结果在预测准确性和及时性上要优于次优模型预测结果,但差别不大。随着预测区间的延展,各模型预测准确性和及时性的差距开始增大,本文方法的预测结果始终优于其他模型。
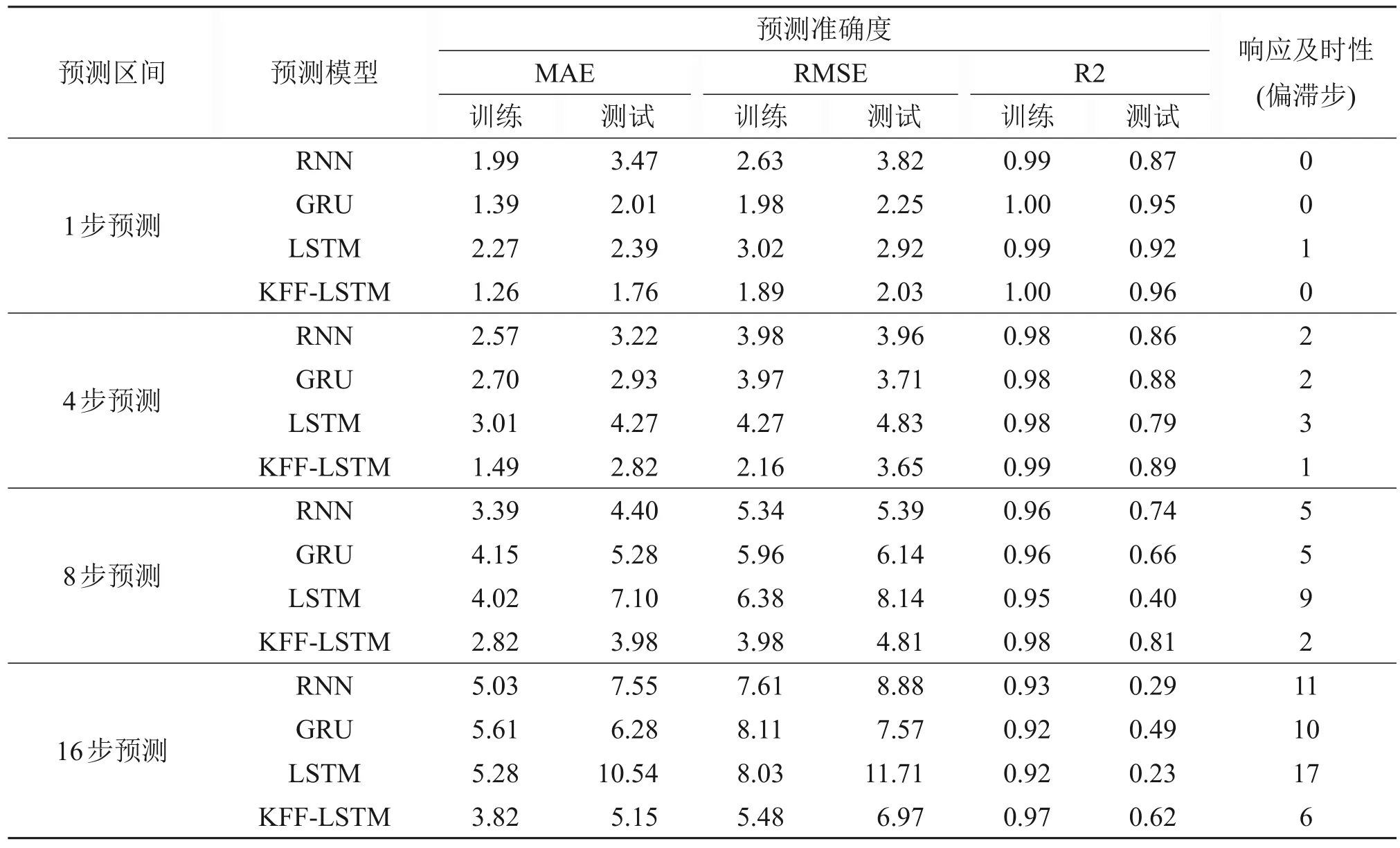
表2 各模型预测效果对比Table 2 Comparison of prediction results among different models
实验结果表明:
1) 预测准确度评价方面,KFF-LSTM 模型在超前1~16步预测的MAE、RMSE均比RNN、GRU和LSTM 方法的低。相对于其他3 种方法,KFFLSTM 模型训练集的MAE 与RMSE 的最小误差分别降低了9.4%~42.0%与4.6%~45.6%,KFF-LSTM模型测试集的MAE 与RMSE 的最小误差分别降低了3.8%~18.0%与1.7%~10.8%;KFF-LSTM 模型预测结果的R2 分数亦优于其他3 种方法的R2 分数,在超前16步的训练集与测试集预测结果的R2分数分别提升了4.3%与26.5%,预测的准确度有较大改善。
2) 预测及时性评价方面,随着预测区间的超前步数增加,KFF-LSTM 模型的响应偏滞要显著低于其他3种方法的响应偏滞。相对于其他3种方法,KFF-LSTM模型超前4步、8步和16步预测的偏滞步数的最少偏滞步数分别降低了50%、60%与40%。
综上可知,相比于其他预测模型,KFF-LSTM模型具有更好的数据拟合能力,无论是在训练集还是测试集的预测结果上均表现出更好的真值逼近与时间响应性能。
3 结论与展望
1) 面向长序列时间预测的准确性及滞后性问题,提出了一种KFF-LSTM 模型。该模型将未来可预知的特征数据引入模型的训练及预测,对经典LSTM模型架构的输出门、状态更新单元及隐变量进行调整以优化预测准确度与响应的及时性。
2) 基于高速列车牵引变流器的实际运营数据进行了KFF-LSTM、LSTM、RNN 和GRU 模型的变流器电机定子温度预测,通过消融实验对比,KFF-LSTM 模型在MAE、RMSE 与R2 指标表征的准确度和偏滞步数表征的响应及时性均优于其他3种方法的最优结果。
3) 基于未来可预知特征的KFF-LSTM 长时序数据预测模型丰富了高速列车关键装备的故障诊断与预警方法,其预测结果可以作为设备健康度诊断和视情维修计划的重要参考,下一步研究工作的重难点是如何将算法延伸应用至高速列车装备健康度定量分析及模型可解释性拓展。
