面向智能立项平台的数据预处理体系研究
2023-10-12黄道友康健徐超
黄道友, 康健, 徐超
(1.国网安徽省电力有限公司,安徽 合肥 230022; 2.上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
近年来,随着各种计算机、通信、自动化技术与电网融合,其在推进电网智能化水平不断提高的同时,给电网带来了海量数据[1-3]。为了处理电网中的海量数据,电力大数据应运而生。但目前电力大数据在采集、传输过程中受到外界干扰导致的数据缺失和数据异常问题普遍存在,降低了后续数据分析的可靠性和科学性。
数据预处理作为解决数据缺失和数据异常问题的手段,目前已有一些对电力大数据预处理的研究。文献[4]提出了基于Apache Spark统一计算引擎的配电网大数据预处理技术,能够有效的清洗数据。文献[5]研究提出 MapReduce技术的电力大数据预处理属性约简方法,能够高效处理数据并具有良好可拓展性。文献[6]提出偏序约简算法进行电力大数据预处理,解决了决策表信息丢失问题。
本文提出面向智能立项平台的数据预处理体系。首先介绍了本文面向的数据平台——智能立项平台。然后介绍了数据预处理的三个环节:缺失值与异常值处理、多时间尺度数据整理、数据归一化。最后将数据预处理体系运用于实际电力运行,通过算例验证了该体系的有效性。
本文的主要创新点如下。
(1) 综合电网各系统数据与业务构建智能立项平台,实现电网设备项目管理的智能化、科学化和效率化。
(2) 提出智能立项平台的数据预处理体系,有效提高数据质量和可靠性,有利于提高电网公司数据挖掘的质量。
1 智能立项平台概述
1.1 智能立项平台简介
智能立项平台由安徽省国网公司建立,其接入了PMS、GIS、调度SCADA、电能量、自然灾害和生产实时管控等自动化系统数据,整合了负荷分析中心、理论线损分析中心、技术降损评价中心和地理信息中心等相关中心数据。智能立项平台不仅可以促进现有业务系统异常数据治理,实现现有业务系统数据的综合应用,而且可以发现电网薄弱环节为电网技改大修项目立项提供科学依据,提升电网设备项目管理科学化、智能化管理水平。系统总体功能架构如图1所示,由基础服务、数据中心和业务应用三个层级构成,每个层级包含了不同的功能模块。基础服务提供了系统运行所需的基础支撑框架及基础组件,内容包括报表组件、绘图组件、控制中心、数据集成中心、服务汇总及输出等。电网数据中心用来管理电网的核心业务数据,包含电网模型管理、数据质量分析以及地理信息中心、负荷分析中心。业务应用包含理论线损分析中心、技术降损评价中心和缺陷隐患分析中心。
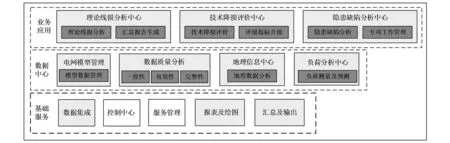
图1 智能立项平台结构图
1.2 智能立项平台数据体系
智能立项平台的数据库系统主要有SCADA系统、PMS系统、营销数据系统,以及安徽省国网公司个性化定制的自然灾害在线监测预警系统。以上数据库系统各司其职,数据无法统一调度参与协同计算。但智能立项平台可以从SCADA系统、PMS系统、营销数据系统和自然灾害在线监测预警系统等数据库采集数据,打通孤立系统的数据屏障。系统数据架构如图2所示。
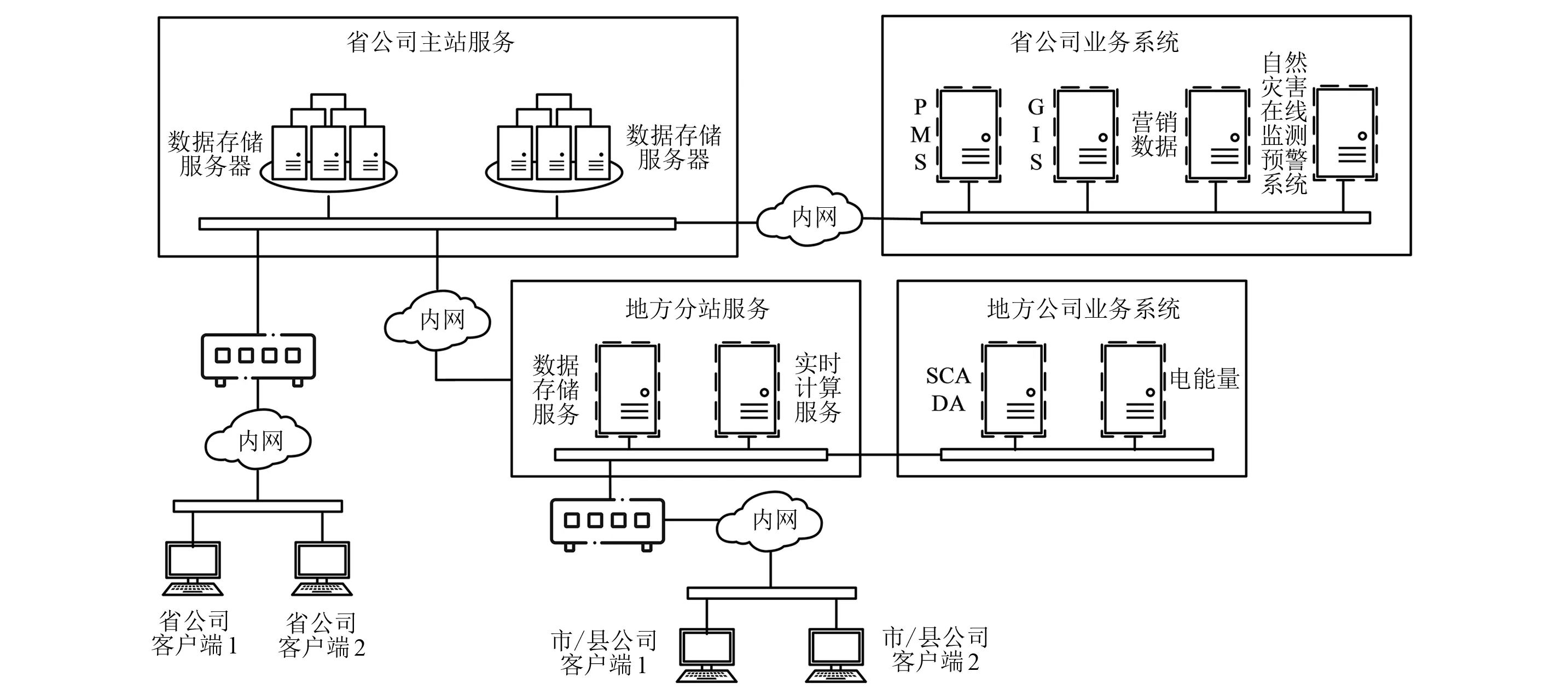
图2 智能立项平台数据架构
2 智能立项平台数据预处理体系
2.1 数据预处理结构
由于智能立项平台中最有代表性也最庞大的数据为负荷数据,本文以负荷数据的预处理为例展示智能立项平台的预处理体系。原始的负荷数据来源于仪器量测数据,经过通信网络传递后部分数据存在缺失和异常问题。因此,预处理过程中首先将数据中的异常值替换,缺失值填充。然后,为了满足多时间尺度的数据挖掘,需要进一步进行多时间尺度数据整理工作。最后,为了便于不同负荷节点的横向比较,需要对负荷数据进行归一化处理。本文研究的智能立项平台数据预处理体系,其结构如图3所示。
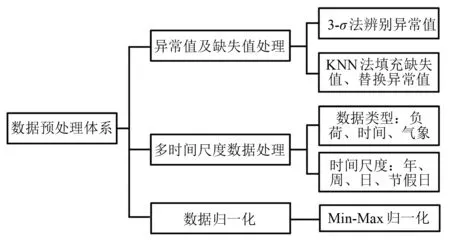
图3 数据处理体系结构
2.2 缺失值与异常值处理
本文采用3倍标准差法(3-σ方法)来甄别异常负荷数据。
对于正态分布的数据,在均值上下3倍标准差内的概率高达99.7%。因此,偏离均值超过3倍标准差的数据有较大概率是异常值。
3-σ方法是统计学方法,需要明确划分样本空间。考虑到电力系统中含有海量的负荷数据,并且海量数据主要来源于:①电力系统有海量的负荷节点;②每一个负荷节点都以15 min为步长统计长期的负荷数据。本文按照负荷节点和日期划分样本空间,异常值判断的定义式如式(1)所示。
(1)
式中:μij为号节点号i在日期j天的负荷均值;σij为节点号i在日期j天的负荷标准差;πi,j,k为布尔型变量,表示i号节点在日期j天的第k个负荷是否异常;f为采用3-σ方法的异常值判别函数。
本文所研究的时间序列中,每一个时序的负荷值与相邻时序的负荷值存在潜在的关联性,因此不能简单地将异常值和缺失值删除。本文采用k最邻近算法(k-nearest neighbors,KNN)的算法原理对异常值进行替换,对缺失值进行填充。KNN算法中用欧式距离来衡量两个向量之间的远近关系,针对向量xi=(xi1,xi2,…,xin)和向量xj=(xj1,xj2,…,xin),用dij来表征两者之间的距离。dij的定义式如式(2)所示。
(2)
针对异常值和缺失值xi,将异常值和缺失值前p个和后q个正常的负荷值xi作为对应的向量Xi=(xi-p,…,xi-1,xi+1,…,xi+q), 正常值xj所对应的向量为Xj=(xj-p,…,xj-1,xj+1,…,xj+q),计算时间序列上所有的正常值对应向量Xi和Xj之间的距离,选择其中距离最近的k个正常值,以其均值作为xi的新值。xi,new,xi,new的定义式如式(3)所示。
(3)
2.3 多时间尺度数据处理
从时间尺度来看,需要整理的数据包括年度数据、周数据、日数据和节假日数据。从数据类型来看,需要整理的数据包括负荷数据、气象数据和时间数据。原始的负荷数据是以15 min为时间间隔采集的功率数据,调整负荷的时间尺度需要考虑电量和功率数据之间的转换。对负荷数据进行整理时用式(4)进行处理。
(4)
式中:Et1,t2为从t1到t2时刻的累积电量;Pt为t时刻的实时功率值,最终用单位时间内的累积电量来表示新时间尺度的负荷。
多时间尺度数据整理实际是做数据集成工作,将不同数据库中的气象数据与处理后的负荷数据集成到新的数据库中形成一条新的记录。
2.4 数据归一化
本文采用Min-Max归一化来实现数据归一化,该方法利用了样本空间的边界值信息,将特征线性化地映射到特定范围内,Min-Max归一化的计算方程如式(5)所示。
(5)
式中:x为样本归一化前的值;xnew为归一化后的值;xmin为样本空间的最小值;xmax为样本空间的最大值。
采用Min-Max归一化后,各个特征对目标函数的影响权重具有一致性,避免部分特征起主导作用从而屏蔽其他特征的问题。Min-Max归一化需要用到样本空间的最大值xmax和最小值xmin,因此非常容易受最大值xmax和最小值xmin异常数据的影响。本文在进行归一化之前先进行了异常数据的替换,因此可以有效避免这一问题。
3 算例分析
3.1 异常数据处理
本文选取某计量点2021年4月23日的用电量作为数据来源,由于当日用电量为-119 952.97 kWh,采用3-σ方法判定当日存在异常数据。经过对数据库原始数据的定位,发现该日4∶00—5∶45,22∶00—22∶45,共计12个实时运行数据存在异常。
使用KNN算法将当日12个时刻的异常值替换后,计算得到新的日负荷为39.830 4 kWh/d。异常值替换前后该计量点日负荷曲线如图4所示。异常数据替换前极端异常值的存在影响了对负荷曲线其余位置的变化趋势的观测,异常数据替换后负荷曲线具有了明显的变化趋势。因此,本文设计的数据预处理体系中采用的3-σ方法可以有效甄别异常值,采用的KNN算法可以有效修正异常值。
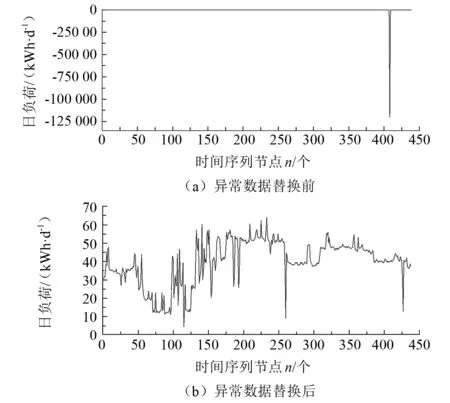
图4 异常数据替换前后负荷曲线
3.2 多时间尺度数据处理及归一化
本文选取安徽省合肥市某计量点在2020-08-01 00∶00至2020-08-07 23∶45的实测负荷数据作为数据集,对其进行数据处理和归一化。图5(a)为原始负荷曲线,图5(b)为数据处理并归一化后的负荷曲线,归一化操作将原始的负荷变为无量纲值。
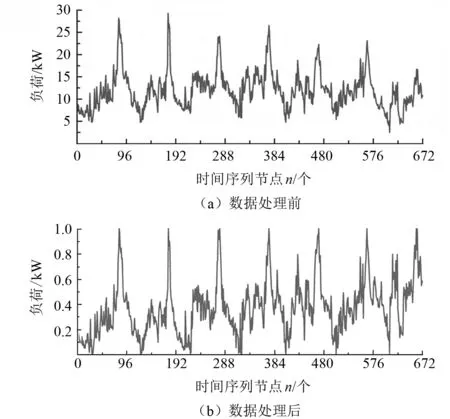
图5 数据处理前后负荷曲线
4 结束语
电力大数据正在逐步显现其重要性,科学化、智能化的电网管理的需要也正在被提出。本文提出的智能立项平台可以有效地提高电网项目管理的效率与智能程度,有效推进智能电网的构建。算例结果表明,数据预处理体系则可以有效解决电网所接受到的数据质量低问题,同时为后续的数据挖掘做好铺垫。
