面向多模态医疗健康数据的知识组织模式研究
2023-10-07叶东宇陈文祺
韩 普 叶东宇 陈文祺 顾 亮
(1.南京邮电大学管理学院,江苏 南京 210003;2.江苏省数据工程与知识服务重点实验室,江苏 南京 210023)
以习近平同志为核心的党中央始终“把保障人民健康放在优先发展的战略位置”,党的二十大报告也提出“推进健康中国建设,把保障人民健康放在优先发展的战略位置”。医疗健康事关人民生命健康安全,对经验和知识依赖性强,需要精准、全面、高质量的知识服务[1-2]。知识组织是知识服务的前提和基础[3-5],医疗健康数据的知识组织水平很大程度上决定了医疗健康知识服务的效率和质量[1]。
随着互联网和信息技术的快速发展,各类医疗健康活动产生了海量的文本、图片、视频和音频等多模态数据。多模态数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是一致的,表达相同或相似的语义信息。传统知识组织体系主要针对单模态数据进行知识组织,难以支撑医疗健康领域多模态数据的语义表示、知识关联和融合,当前迫切需要一种更为完善的知识组织方法对类型繁多、专业性强、分布稀疏的多模态医疗健康数据进行序化和组织。有效的知识组织模式不仅有助于缩小多模态数据间的异构鸿沟,获得更强的语义理解、知识补全和知识推理能力,而且有助于提升多模态数据资源的利用效率和知识服务水平,从而更好地服务于“健康中国”国家战略。
1 相关研究工作
知识组织概念最早由分类法专家Bliss在1929年首次提出,1964年袁翰青教授在国内最早使用了知识组织的表述[6],随后刘洪波[7]和王知津[8]等国内学者针对知识组织概念、模型、方法和应用进行了早期的理论和实践探索。作为图情理论和实践研究的核心与热点研究问题,随着信息技术不断发展,知识组织相关理论和实践都取得了显著进步。尤其是得益于大数据和深度学习的进步,知识组织的理论、方法和技术研究成为近些年图书情报学领域的前沿课题[9-10]。本小节主要从模态视角和领域视角对知识组织的最新研究进展进行梳理。
1.1 面向多模态数据的知识组织
大数据时代信息传播丰富多彩,用户获取的信息不仅局限于传统文本模态,还包含了图像、音频和视频等多模态数据。在此背景下,如何将多模态数据进行知识序化形成科学有效的知识组织体系成为当前学界的关注热点[11]。已有研究主要从多模态知识融合、知识表示和实践应用方面进行了重点关注。在方法和技术方面,Wang M等[12]借助维基百科图像描述中的超链接信息关联文本和图像,以生成多模态语义关系。在实践应用方面,Su J等[13]构建了可捕捉文本和图像语义信息交互的多模态神经机器翻译模型;蒋雨肖等[14]利用深度学习模型融合文本和图像的语义特征,进而实现多模态信息分类。随着深度学习和多模态学习的发展,多模态知识图谱成为知识组织的重要方法和工具[15]。Xia F等[16]在已有医学知识图谱基础上,借助图像检索构建医学多模态知识图谱;张莹莹等[17]在中文症状知识图谱基础上,融入图片以丰富实体的视觉信息。在数字人文领域,视觉资源对象语义内容丰富[18-19];曾子明等[18]提出一种基于关联数据的视觉资源组织方法来揭示知识间内在语义关联;夏立新等[20]和庄文杰等[21]分别以资源社会化标签和视频知识元进行非遗视觉资源的知识组织;周知等[22]提出了一种4层架构的数字人文图像资源知识组织模型。
已有研究主要对多模态知识组织中的相关方法和技术进行了研究,这些研究大大拓展了多模态知识组织实践的范围,为多模态知识组织深入研究奠定了基础。总体上,相关研究主要停留在传统的描述阶段,尽管有部分文献根据资源特征构建了基于关联数据的知识组织模型,但主要依赖不同模态数据的元数据,难以充分利用多模态数据的深层语义信息,多模态数据资源的深度序化和模态间语义关联迫切需要充分利用多模态数据的固有特征信息进行知识组织。
1.2 医疗健康领域知识组织
随着知识组织研究的深入以及用户精准知识服务的需求的推动,知识组织正走向领域知识组织时代[5-6]。医疗健康领域知识专业性强,实体数量巨大、更新速度快且实体间语义关系非常复杂[23-24]。已有文献主要对医疗健康领域知识组织中的实体识别、实体对齐和关系抽取等关键问题进行了研究。在实体识别方面,Li L等[25]基于注意力机制与双向长短期记忆网络,提出一种改进的中文电子病历实体识别模型,解决了长文本中远距离带来的信息缺失问题;Ji B等[26]基于多神经网络协同合作方法,构建了中文医学命名实体识别模型,并通过迁移学习引入非目标场景数据集提高模型泛化能力。在实体对齐方面,Hao J等[27]基于本体论、语义网和图神经网络提出了一种端到端实体对齐框架Medeto,有效提高了医学知识库中本体匹配的准确率;Su F等[28]采用关系聚合网络提取文本特征,通过辅助信息不参与网络反向传播有效地提高了实体对抽取的效率。在关系抽取方面,Alicante A等[29]提出一种无监督方法来抽取临床记录中的实体和实体间关系;Bai T等[30]设计了一种基于卷积神经网络的分段关注机制,进而抽取中医草药文献中实体间的语义关系。
作为实现医疗健康领域知识组织目标的最佳途径之一,知识图谱能够以一种便于机器存储、识别和理解的方式对数据进行有效的组织与管理[31],相关研究近些年受到了学界的极大关注[32]。为解决多源健康知识的异构问题,马费成等[9]采用五元组形式进行健康知识表示。王文韬等[33]基于粒度原理将健康领域知识解构成不同知识单元。Warnat H S等[2]利用医疗健康数据和机器学习模型构建了疾病分类系统。以医学学术文献为数据源,Zhu C等[34]构建了疾病知识图谱,蔡妙芝等[23]采用SPO语义三元组进行疾病知识组织。基于寻医问药网结构化信息,武家伟等[35]构建了“疾病—症状”知识图谱。陆泉等[36]提出了一个基于扩展疾病本体的医学数据组织模型,实现电子病历大数据的知识描述与组织。
综上所述,现有的医疗健康知识组织倾向于在单模态视角下探讨不同应用场景下的具体问题,部分研究关注了不同模态数据技术层面的知识融合,但缺少系统的多模态知识组织理论架构。多模态医疗健康数据的涌现使跨模态语义理解与知识组织变得更加迫切,有效的知识组织不仅能够更全面地揭示不同模态医疗健康数据之间的语义关联,同时也能够利用多模态数据补全做出更准确的疾病预测[37]。本研究将从多模态和多粒度视角下探究医疗健康数据的知识单元抽取、多模态知识单元构建和多模态知识图谱补全等问题,进而构建医疗健康领域多模态知识组织模式,并在医疗健康知识问答等应用场景进行分析。
2 面向多模态医疗健康数据的知识组织模式设计与技术分析
多模态医疗健康知识组织模式最终是实现多模态医疗健康数据的有效组织和应用。多模态医疗健康知识组织模式的关键步骤是通过医疗健康数据内涵特征分析,在已有的医疗知识图谱基础上融入其他模态信息以补全语义知识,并通过语义关联为用户提供医疗健康知识服务。其中,相较于传统的知识组织模式,本文的多模态知识组织模式创新之处在于从医疗健康数据知识单元抽取和多模态知识单元构建方面强化多模态知识的深度处理与利用。具体如图1所示。
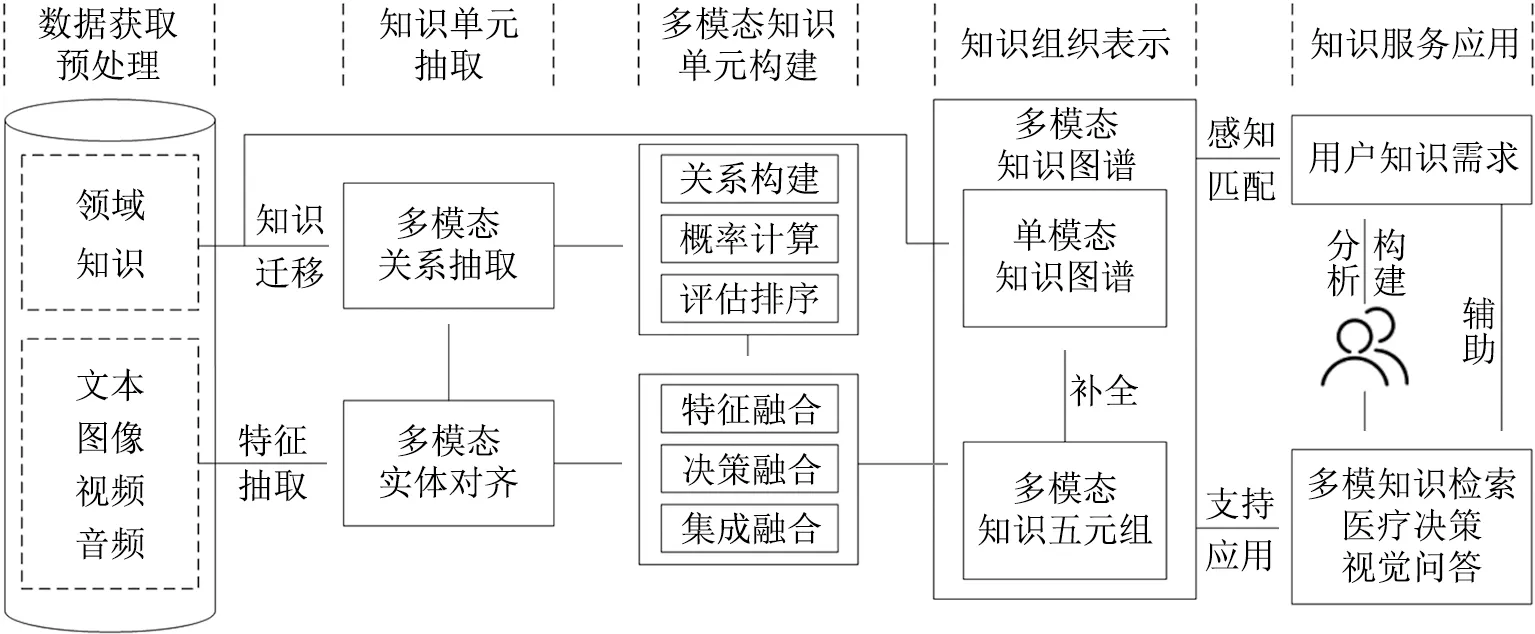
图1 多模态医疗健康数据的知识组织模式设计及应用方案
本文以医疗健康领域电子病历文本和图像数据为知识组织案例,按照图1进行数据获取及预处理、知识单元抽取、多模态知识单元构建、多模态知识组织表示以及知识服务应用的技术流程论证分析。
2.1 多模态医疗健康数据的获取和预处理
高质量的多模态数据集是实现医疗健康知识组织的基础,本文的多模态医疗健康数据来源于医疗机构、在线健康平台和医学知识库,主要包含文本、图像、音频和视频4种模态数据。本研究一方面从合作医疗机构的临床电子病历获取文本及CT、X光和超声等医学图像数据,并对用户隐私信息进行脱敏处理;另一方面利用爬虫获取疾病百科、医学文献和在线健康平台的文本及图像数据;另外,还通过在线短视频平台获取音视频模态数据。
尽管可利用的多模态医疗健康数据较多,但是不同来源的数据质量参差不齐,尤其是包含大量用户生成内容的在线健康平台数据需要清洗和加工。具体而言,首先通过去重、填补缺失值、处理异常值等方法对多模态数据进行预处理;然后利用YEDDA、CVAT、Praat和VoTT等标注工具对文本、图像、音频和视频数据进行多轮标注;接着基于人工随机检查标注结果对多模态知识实体及语义关系标注规范进行适时修正;最终通过标注一致性检验,获得高质量的多模态医疗健康标注数据集。
2.2 医疗健康数据的知识单元抽取
知识单元是知识的基本组分,对知识序化和知识组织有着极其重要的作用。虽然知识单元的分类标准与表达形式目前尚未统一,但已有研究多倾向于使用N元组描述知识单元[38]。一方面采用N元组形式可以将知识单元更好地表示为机器可处理的形式;另一方面可以更方便地实现知识图谱的知识补全[39]。基于以上考虑,本文将使用三元组形式表示各模态医疗健康数据中的知识单元,进而为后续的多模态知识单元构建和知识图谱补全奠定基础。本研究中,每个模态数据知识单元定义为实体与实体间关系所构成的三元组,因此各模态数据中实体和实体间关系抽取是后续研究的关键环节。
尽管已有研究验证了深度学习在实体识别任务上的优势,但医疗健康领域多模态数据具有高度的专业性,存在不同模态数据均指向同一实体的现象。如图2所示,多模态医疗健康数据中文本描述“肿块”、音频数据“占位”、医学影像中A区域和视频中B部分,虽然描述方式不同,但均表征“肿瘤”疾病这一实体。此外,医疗健康领域各实体间还存在大量的一对多关系。这些因素给多模态医疗健康数据的知识单元抽取带来了很大挑战。因此,如何解决多模态数据中实体对齐和关系抽取是本部分的研究重点。
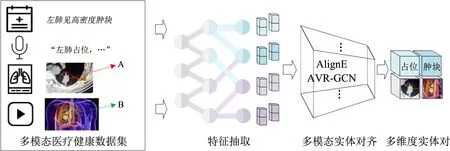
图2 多模态医疗健康数据实体对齐
实体对齐是判断不同数据源和不同模态实体是否为指向同一对象的过程。在已有研究基础上,本小节首先利用深度神经网络对文本、图像、音频和视频数据进行特征抽取;然后借助AlignE、AVR-GCN和Cross-KG等方法实现多模态知识实体对齐和消融;最终构建<肿块/占位/图像A/视频B>的实体对。
本研究中关系抽取任务主要是针对文本模态数据。由于医疗健康领域专业性强、实体表述多样,实体间语义关系复杂,尤其关系重叠现象比较常见,如图3中文本模态数据“左肺见高密度肿块”中的实体“肿块”与“左肺”和“高密度”均存在语义关系。考虑到传统联合抽取和Pipeline抽取方法难以解决此类问题,本研究采用端到端多模态生成模型抽取实体间语义关系。

图3 多模态医疗健康数据中医学实体关系抽取模型
在实体关系抽取任务中,首先将文本模态和图像模态数据输入编码器(Encoder),然后将编码后的信息输入到解码器(Decoder)中进行解码,接着由解码器生成包含实体和关系的序列“肿块
图3中,“肿块
2.3 医疗健康数据的多模态知识单元构建
现有的多模态知识融合和知识组织研究大多直接将图片与文本实体构成的知识单元嵌入知识图谱[17,40]。但知识单元不是独立存在的,只有将其置于原始语境下,才能够最大化地理解知识单元的价值和作用[39]。本研究提出的知识组织模式创新之处在于整合多模态医疗健康数据以构建多模态知识单元,并在此基础上实现医疗健康知识图谱的模态补全,其中多模态知识单元是在特定语境下对特定知识实体及其关系的整合,相较于单模态的知识单元在内容上更加丰富。具体而言,多模态知识单元构建分为知识评估与知识融合两个步骤。首先,对三元组形式的知识单元进行评估以剔除噪声和无关信息进而得到知识真值;其次,融合知识真值与医学知识库中的专业知识得到包含上下文语义信息的多模态知识单元。本部分以图4为例,通过知识评估与知识融合生成多模态知识单元。

图4 医疗健康多模态知识单元构建过程
知识评估是通过关系构建、概率计算和评估排序得到多模态医疗健康数据中知识真值的过程。具体而言,首先基于YOLO和BiLSTM-CRF等算法对图4中脑膜瘤多模态数据进行实体识别,分别抽取其图像实体T1和T2,以及文本实体“右侧鞍旁”和“形状规则占位”;接着通过关系构建枚举多模态知识实体间所有的关系路径;然后将每条路径作为训练专家,通过随机游走关系路径图来计算每条关系路径终点的概率值[41];最后利用医学知识库中语义关系对预测结果进行排序评估并得到知识真值“<右侧鞍旁,T2,形状规则占位>”。
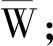
2.4 医疗健康多模态知识组织表示
鉴于已有单模态文本的医学知识图谱研究已较为成熟[34-35],本研究在文本知识图谱基础上进行多模态医疗健康知识组织表示和补全,该部分工作主要包含多模态知识五元组构建和知识图谱补全两部分。五元组构建是在各模态知识单元基础上,采用五元组形式对多模态医疗健康知识进行组织,具体以<多模知识单元U,实体E,关系R,领域D,参考源S>五元组形式TM进行存储。其中,U包括文本单元UL、图像单元UP、视频单元UV和音频单元UA,E表示实体集合,R表示实体间关系集合,D表示领域集合,S是描述参考源集合,TM=(UL∪UP∪UV∪UA)×E×R×D×S。如图5所示,首先将包含图像单元UP和文本单元UL的多模知识单元“神经源性肿瘤”存储在U中;接着将通过实体识别和关系抽取的各部分实体以及实体间语义关系集分别存储在E和R中;最后基于本体知识表示方法,将其他模态信息存储在领域D中,将数据来源信息存储在参考源S。

图5 多模态医疗健康知识五元组构建(以文本—图像为例)
知识图谱补全是指将多模态知识五元组融入现有单模态医学知识图谱。本部分采用语义相似度计算和语义映射的方法将多模态知识五元组融入现有的知识图谱,具体包含实体映射和关系映射两部分。如图6所示,多模态知识五元组中,实体E存在文本实体T1“右下纵膈”和T6“神经源性肿瘤”,关系R中具有T6-T1“发病部位”和T6-P1“图片对应”;单模态医学知识图谱包含实体“纵膈”和“神经源性肿瘤”与表示关系的三元组“<神经源性肿瘤,发病部位,后纵膈、椎管内、腹膜后等>”。实体映射是将多模态知识五元组中的文本实体T1和T6分别同单模态医学知识图谱中的实体1和实体2建立映射;关系映射是将关系“T6-T1”和单模态医学知识图谱中关系1建立映射。由于单模态医学知识图谱不存在图片数据,因此将“T6-P1”作为关系2“图片对应”补全到单模态知识图谱中,最终以

图6 多模态医疗健康知识补全过程
3 基于多模态医疗健康知识图谱的健康知识服务
本研究构建的多模态医疗健康知识组织模式可应用于跨模态知识检索、视觉问答和辅助决策支持等应用场景。本节以医疗健康问答系统为实践应用,验证多模态知识组织模式在语义消歧和知识补全方面的优势,增强知识服务的有效性和全面性。
本研究构建的医疗健康知识问答系统主要分为用户知识需求分析和动态知识匹配两部分。知识需求分析通过获取用户的基本信息和主题意图生成用户知识需求模型。具体而言,首先通过基于规则和统计的方法获取用户基本信息,接着采用主题挖掘抽取用户请求的主题意图进而构建用户知识需求模型;知识匹配是在多模态知识图谱基础上,利用语义相关度计算得到与用户知识需求相关度高的知识标引结果集,并通过语义关联实现用户知识需求与多模态医疗健康知识的精准匹配。
本文以网上问诊为例,构建基于多模态知识图谱的医疗健康知识问答系统,具体如图7所示。在知识需求分析阶段,首先利用多模态实体识别、目标检测和关系抽取等方法获取用户提交数据的关键信息,然后采用主题挖掘方法对用户查询请求的主题意图进行识别,进而构建用户知识需求模型。具体地,首先分析和处理用户提交的数据,抽取如“疼痛”“不均”“阴影”和医学影像图中病变部位等关键信息,然后基于主题挖掘算法识别用户查询请求的主题意图并构建用户知识需求模型。在知识匹配阶段,首先计算用户知识需求模型与多模态医疗健康知识单元的语义相关度,得到相关度较高的知识标引结果集,并利用多模态实体的语义关联实现语义消歧,最终向用户提供匹配度高的多模态医疗健康知识。具体地,通过语义相似度计算得到与用户知识需求匹配度较高的知识标引结果集“肝脓肿”和“脂肪肝”。实际情况下,知识标引结果集中相关概念与用户知识需求可能存在歧义,这将造成系统推送错误信息,如“脂肪肝”的病症“密度降低”是指全肝密度降低,而用户知识需求模型中“低密度阴影”则表明病变部位密度较低。因此系统将知识标引结果集与用户知识需求进行多模态实体的语义关联,计算出用户知识需求中“低密度”“不均”等实体与“肝脓肿”中文本和图像实体具有最高关联度,进而实现语义消歧,最终系统将可能性最高的结果“肝脓肿”及相关信息推送给用户。

图7 基于多模态知识图谱的医疗健康问答系统
4 结 语
随着信息技术的发展和大数据时代的到来,医疗健康领域文本、图像、视频数据增长迅速,传统知识组织体系主要针对文本模态数据进行知识组织,目前迫切需要一种有效的组织方法对多模态数据进行序化整理组织以提升数据资源的利用效率,进而为用户提供多维度多样化知识服务。本文从多模态视角,通过分析文本、图像、音频和视频多模态数据的内在特性和多模态数据间深层语义关系,基于多模态知识图谱和语义知识组织框架,提出一种面向多模态医疗健康数据的知识组织模式,重点从多模态医疗健康数据的获取和预处理、医疗健康数据的知识单元抽取、多模态知识单元构建、多模态知识组织表示和基于多模态医疗健康知识图谱的知识服务等关键层面分析了具体实现路径。本研究一方面推进了多模态知识组织的理论深度;另一方面有助于提升多模态数据资源的利用效率和知识服务水平,对提升国民健康信息素养和创新知识服务具有重要的现实意义。
