基于不平衡数据的特征选择算法研究
2023-09-27田建学
张 珏,田建学
(榆林学院 信息工程学院,陕西 榆林 719000)
当将全部特征直接用于构建分类器,不但耗时,而且会降低分类性能。因此,需要引入特征选择方法,对原始属性进行裁剪,进而依据分类的要求筛选出最有效特征子集用于构建分类器。具体的说,引入特征选择对算法性能提升主要表现在以下四个方面:(1)经过特征选择获得的数据表达,能够增强学习模型在绝大多数实际场景中泛化能力;(2)可以有效克服由维数增加所引发的“维数灾难”和“过拟合”等问题;(3)采用降低维度后的特征构建学习模型,可以在有效提高算法的分类性能的同时降低算法的计算复杂度;(4)通过特征选择后获得的知识表达式,可以降低研究人员对问题理解和解释的难度。特征选择方法可以改进分类器预测性能,提高计算速度并减少内存开销。
不平衡数据是指某一种分类的数量多余另一种分类的数量。不平衡分类问题在多个领域存在,在这些领域中,人们对少数类更感兴趣,少数类的样本也往往更具有价值。面向不平衡数据进行特征选择时,少数类的存在增大了寻找最优特征子集的难度,传统的以最大分类正确率为准则的特征选择算法往往不能选择出有效的特征子集。Ogura等[1]指出传统的特征选择算法对不平衡数据进行特征选择时的不适应性,提出应该设计是适应于不平衡数据的特征选择算法。因此,对于不平数据集分类,特征选择有时比分类算法更重要[2, 3]。
拉普拉斯Laplacian是由He和Cai于2006年提出的,算法基于拉普拉斯特征图[4]和局部保留投影算法[5],算法的基本思想是计算每个特征的Laplacian分数,通过拉普拉斯分数来反映它的局部保持能力。因为在很多实际的分类问题中,数据的局部空间比全局结构更为重要。然而,在不平衡分类这个问题背景下,以最大化分类精度为主要目标的拉普拉斯特征选择算法往往效果较差,因为算法偏向于多数类而忽略少数类,传统的评估指标不能准确地评估分类器的性能。
因此,本文在分析传统特征选择算法不足的基础上,针对二类不平衡分类问题对拉普拉斯特征选择算法进行改进,提出基于改进的Laplacian特征选择算法LP(Laplacian)。算法主要包括四个步骤:(1)根据拉普拉斯分数对特征进行排序。(2)构建若干个特征子集,由最高拉普拉斯分数的特征组成。(3)通过聚类后的标签和真实的标签值来计算每个特征子集的归一化值,有着最高归一化值的特征子集为最优特征子集。实验结果表明,算法具有一定的竞争力。
1 Laplacian特征选择算法
算法描述:Lr代表第r个特征的拉普拉斯分数。Fri代表了第i个样本的r个特征,i=1,…,m。
(1)构造一个有m个结点的图G。xi代表第i个结点,如果xi是xj的K近邻样本,或者xj是xi的K近邻样本,那么就认为xi,xj是近邻。当标签样本是可得到的,那么就在xi,xj之间放置一条边,并且共享标签。

2 改进的拉普拉斯特征选择算法
常用的特征选择算法以分类准确度为度量标准,也取得了不错的效果。在不平衡数据的情况下,传统的特征选择方法所选择的特征更加偏向于多数类,然而实际生活中,人们往往更关注少数类。由于数据的不平衡性,传统的分类评估指标并不能准确评估分类器的性能。为此研究者引入新的分类评价指标马修斯相关系数(Matthews correlation coefficient, MCC)。
马修斯相关系数考虑到真和假阳性和假阴性,通常被视为一种平衡的措施,即时数据的规模大小不同也可以使用。MCC本质上是观察到的和预测的二元分类之间的相关系统,值介于-1和+1之间,+1表示完美预测,-1表示预测和观察之间的完全不一致。马修斯相关系数的定义为:
公式中,TP代表真阳性,TN代表真阴性,FP代表假阳,FN代表假阴。当FP=FN=0也就是预测完全正确时MCC=1,当完全预测错误时MCC=-1,当MCC=0时表明模型和随机预测性能类似。
传统的以最大化分类准确度为目标的特征选择研究中,以拉普拉斯为代表的算法表明能明显的改善算法的性能。受此启发,本文提出一种改进的以最大化MCC为目标的拉普拉斯特征选择算法。改进的拉普拉斯特征选择算法,选择使用MCC评价指标来衡量算法性能,从而提高不平衡数据的分类性能。具体的说,算法在构建最近邻图的时候,使用MCC评价指标来寻找近邻参数k值,在原始的应用中,k值取常数,但是常数不能提供令人满意的性能,而且k的值对于图构建也非常敏感。以MCC为评价指标计算每个特征的Laplacian分数,接下来构建特征子集,第一个特征子集由有着最高Laplacian分数的一个特征构成,第二个特征子集由有着最高Laplacian分数的前两个特征构成,第n个特征子集由有着最高Laplacian分数的前n个特征构成。最后计算每个特征子集的归一化值,有着最优归一化值的特征子集为最优特征子集。
3 实验结果与分析
为了验证本文所提出算法的性能,在公开的不平衡数据集WDBC上进行测试,这个数据集来自于UCI数据库乳腺癌标准数据集,威斯康星大学医院麦迪逊分校,由Mangasarian等人收集。表1列出了这个数据集的详细信息。对于数据集,采用保持方法使用80%的样本进行训练,20%的样本进行测试。算法使用Matlab 2016a 和R3.5.1平台上进行对比验证。仿真实验在Intel(R) Core (TM) I5-8400 CPU, 8GB内存,2.80GHz CPU和windows 64位操作系统的个人电脑上运行。实验中采用有着线性核函数的SVM作为分类器,来验证特征选择的效果。SVM算法使用R中的“kernlab”包来实现,其它参数采用默认设计。
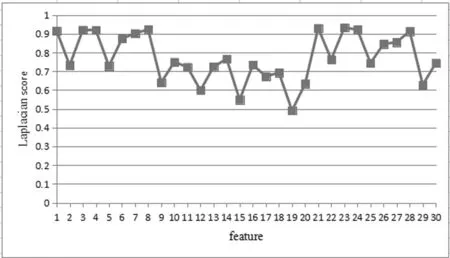
图1 WDBC数据集上每个特征对应的LS分数

表1 实验数据集
为了评估本文提出的LP-SVM算法的有效性,将LP-SVM的结果与局部投影算法(Locality Preserving Projection, LPP)和SVM分类组成LPP-SVM进行比较。LP-SVM与LPP-SVM算法对比,为了说明拉普拉斯特征选择算法的有效性。为了进一步评估算法的有效性,表2显示了本文提出的LP-SVM算法在WDBC上的结果以及各种不同文献方法的对比。Accuracy分类准确度、Sensitivity灵敏度和MCC用作性能指标进行比较。表中的符号“~”代表对应的文献中没有相关数据。
根据表2所示,本文提出的LP-SVM取得了97.48%的精度、100%的敏感度、96.17%的特异性、94.8%的MCC值。通过分类精度可以看到,LP-SVM算法优于大部分的算法,同时本文的算法优于LPP-SVM。本文算法优于LPP-SVM,说明改进的LP特征选择算法优于经典的局部投影算法LPP。虽然部分文献的方法略微优于本文算法,但是本文提出的LP-SVM算法有着和文献类似的性能,和文献方法没有显著差异。综合分析,本文算法有着和经典算法LPP-SVM以及其它流行算法类似甚至更好的预测能力。
4 结论
在不平衡分类这个问题背景下,传统的以最大化分类精度为主要目标的特征选择算法往往效果较差。基于此本文提出一种基于改进LP拉普拉斯特征选择算法,用MCC取代精度来衡量特征子集的分类性能。实验结果表明,LP-SVM算法具有一定的竞争力。该算法也存在一些不足,比如算法效率低、参数设定困难等。因此,如何改进算法效率以及对特征选择算法中某些参数设置问题,摒弃经验值,引入算法实现对参数的自动寻优,是将来重要的研究方向。
