基于YOLOv5 的眼前节参数实时测量算法研究
2023-08-14贺永强李泽萌
贺永强,齐 珊,李泽萌,周 盛,杨 军,林 松
(1.中国医学科学院北京协和医学院生物医学工程研究所,天津 300192;2.天津迈达医学科技股份有限公司,天津 300384;3.天津医科大学眼科医院,天津 300384)
0 引言
高精度眼参数测量和成像技术对眼内组织结构生理和病理性变化的研究十分重要,譬如,眼前节参数和眼轴长的变化是老视和近视发生的重要影响因素[1]。青光眼是全球不可逆性失明的主要原因,预计2040 年将有1.118 亿人患有青光眼[2-3]。目前可用的治疗方法无法逆转青光眼对视觉系统的损害,但是早期诊断和治疗可以预防疾病的进展[4]。美国眼科学会指南和加拿大共识建议,所有青光眼疑似病例和原发性开角型青光眼患者的初始评估应包括中央角膜厚度(central cornea thickness,CCT)测量,因为CCT测量的结果有助于解释眼压测量值、风险分层和设定目标眼压[5]。CCT 是预测角膜屈光手术长期并发症的重要参数,在角膜疾病的诊断和管理中是必不可少的[6]。前房深度(anterior chamber depth,ACD)已被确定为开角型青光眼进展的重要危险因素[7]。在超声乳化人工晶体(intraocular corrective lens,ICL)植入术中,ACD 的测量关系到人工晶状体度数以及术后拱高的计算,晶状体厚度(lens thickness,LT)会影响到所需超声剂量[8-9],睫状沟是ICL 的固定场所,睫状沟间距(sulcus to sulcus,STS)可作为ICL 的长度值[10],前房角间距(angle to angle,ATA)亦影响到ICL的选择[11]。
超声生物显微镜(ultrasonic biological microscopy,UBM)穿透性强,不受屈光介质混浊的影响,能够获得相关组织结构的精细成像,是实时观察和精确测量眼前节及其生理参数的重要工具,但是其操作复杂、耗时长,且刺激性较大,容易产生不适感[12],需要有经验的眼科医生人工评估。临床中需要准确、实时地标记解剖结构和测量眼前节参数,然而,由于眼部超声仪器难以完全对准眼球中线,时常会产生质量不高的图像,例如房角不清晰、晶状体后囊与角膜伪影重合、关键点缺失、前房和晶状体伪影、晶状体后囊偏离瞳孔中线、未检测到晶状体后囊、两侧房角倾斜过大。这使得传统的图像处理技术难以适用于不同的UBM 图像,因此基于UBM 图像的眼前节自动测量仍然是一项具有挑战性的任务。
近年来,深度学习方法发展迅速,被广泛应用于医学领域[13-14]。大部分眼科深度学习的研究主要集中在对房角开闭的分类[15-16]。在眼前节参数估计领域,组织厚度和面积是量化眼科医学图像的常用指标,在测量指标之前需要对组织进行分割,角膜在光学相干断层扫描(optical coherence tomography,OCT)图像中的自动分割有助于对角膜的几何形状进行生物力学建模。在目前市售的OCT 设备中,CASIA 能够成像并自动分割眼前段[17]。Williams 等[18]使用传统的图像处理技术分割OCT 图像中的角膜,其骰子相似系数为0.943±0.020,优于之前发表的其他算法。OCT图像包括角膜与虹膜区域,上述方法只提供单个区域的分割,且只能应用于单一类型的OCT 图像,因此Fu 等[19]用图像特征代替临床参数,分割角膜边界和虹膜区域以获得前房角测量值,其研究可应用于临床评估和青光眼筛查。Leung 等[20]使用传统的边缘检测算法测量前房角的尺寸及轮廓,测量的成功率为90%,部分图片因信噪比较低不能被正确识别。Yoo 等[21]使用ResNet50 估计前房深度,以分类浅前房和深前房的图像。Yu 等[22]使用传统图像处理算法定位房角隐窝,准确率达到了95%,该算法可应用于后续房角开闭的分类。Huang 等[23]使用Resnet-34 分级评估青光眼的视野,该算法在处理2 种视野分析仪器(Humphrey Field Analyzer 和Octopus)的数据时具有较高的准确性,可应用于远程医疗中的患者自我评估。Thompson 等[24]使用ResNet34 算法评估青光眼的结构性损伤,该算法在检测轻度视野缺陷的图像方面具有较高的准确性。Xu 等[25]使用ResNet-18定位眼前节光学相干断层扫描(anterior segment optical coherence tomography,AS-OCT)图像中的巩膜突,其定位精度能达到人类专家级别。Wang 等[26]使用EfficientNet-B3 定位UBM 图像中的巩膜突,其定位性能接近专家人工定位水准。
文献[25]和[26]中的算法用于预测眼前节中单个关键点或单个生理参数,本文在此基础上,提出一个YOLOv5 算法结合先验知识的算法,该算法使用YOLOv5 算法定位UBM 图像的中央角膜上皮层、中央角膜内皮、两侧前房角、两侧睫状沟、瞳孔两端、瞳孔中央及晶状体后囊,在自动甄别出符合要求的图像之后,根据这些点的像素坐标计算CCT、ACD、STS、ATA 及瞳孔直径(pupil diameter,PD)等眼前节生理参数的数值。本研究通过YOLOv5 算法结合先验知识的方法,以期快速而精准地定位UBM 图像眼前节各关键点,同时精确测量UBM 图像中的各眼前节生理参数。
1 YOLOv5v6.0 目标检测算法
目前,目标检测算法通常分为基于区域与基于回归两大类。基于区域的算法利用2 个网络分别实现分类与回归,其精度较高,但是速度较低;基于回归的算法在一个网络中完成对目标的分类与定位。这2 类方法检测速度快,能够满足实时要求。本文采用的神经网络为Ultralytics LLC 公司于2020 年5 月提出的YOLOv5,属于基于回归的目标检测算法。
YOLOv5 改变了前一代YOLO 算法检测速度快但精度不高的缺点,提高了检测精度和实时性能,满足了实时图像检测的需要,对于多个小目标有着较好的检测效果。因此,本文使用YOLOv5 作为检测算法。YOLOv5 网络结构分为输入、主干、颈部和输出4个部分,其网络结构如图1 所示。

图1 YOLOv5 网络结构
输入包括3 个部分:马赛克数据增强、自适应锚定框和自适应图像缩放。YOLOv5 的输入端使用了马赛克数据增强方法,采用随机剪裁、随机缩放和随机排布拼接4 张图像,丰富了检测数据集,提高了网络的鲁棒性,减少了图形处理器(graphics processing unit,GPU)的计算量,增加了网络的泛化性,适用于小目标检测,符合本文检测眼前节关键点的需求。
以往的YOLO 算法中需要将输入图像处理成固定大小,增加了许多冗余信息。YOLOv5v6.0 中使用了矩形推理,其先通过仿射变换将较长边缩放到640,由于YOLOv5 会输出32 倍下采样后的特征图,因此将较短边填充至32 的倍数,再输入算法中训练,过程如图2 所示。

图2 矩形推理以及方形推理
YOLOv5 在训练前会对数据集进行回归预测,当先验框对数据集的最佳召回率小于0.98 时,使用K-means 聚类重新计算先验框。UBM 图像上关键点的特征主要分布在水平方向上,锚框形状应为宽大于高的矩形。由于本文只需要定位锚点,为减少锚框对训练的影响,人为设定了锚框长度。经多次实验,在生成数据集时将所有锚框的宽取[0.05,0.051]上的随机数,高取[0.02,0.021]上的随机数。
在主干中,通过CSP-Darknet53 进行特征提取,其基本模块是CBS,与之前版本相比,将激活函数Leaky ReLU 改成了SiLU。为方便部署,YOLOv5 中将之前版本的Focus 模块换成了6×6 的卷积层,两者作用相同,但是后者效率更高。
在颈部中采用了特征金字塔网络(feature pyramid networks,FPN)与路径聚合网络(path aggregation network,PAN)的结构,FPN 自上而下,传递了高层的语义特征,PAN 采用自下向上的特征金字塔,传递低层的定位信息,其结构如图3 所示。
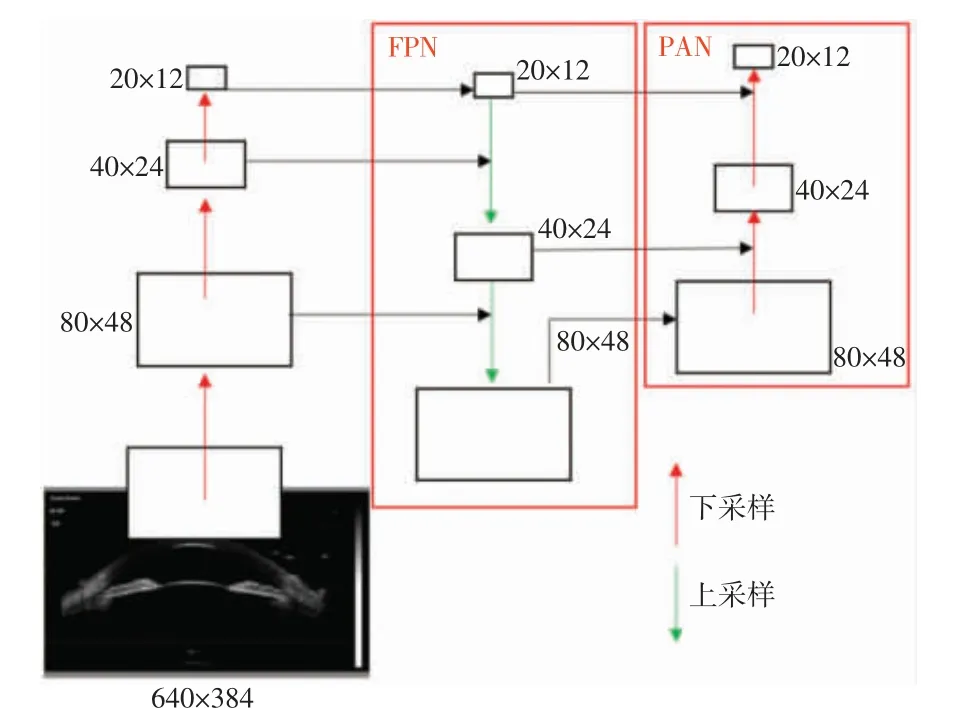
图3 FPN+PAN 结构
输出使用了非极大值抑制(non maximum suppression,NMS),在目标检测和预测阶段,使用加权NMS 增强对多个目标的识别能力,并获得最佳的目标检测帧。
2 眼前节关键点排序算法
在使用YOLOv5 算法检测出UBM 图像上的眼前节各关键点后,需要对各关键点排序,以便后续眼前节参数的测量。本文根据各关键点的空间位置进行排序,以图片的左上角为原点。除前房角和睫状沟外,其他关键点均能直接用x 坐标或y 坐标区分。图4 为不同人眼的UBM 图像,其中前房角和睫状沟不存在x 轴或y 轴上的确切关系,故分别使用斜率k=-1 和k=1 的直线区分左侧的睫状沟和前房角以及右侧的睫状沟和前房角。当直线过前房角时,睫状沟应在直线下方,若设左右前房角点和左右睫状沟的预测坐标分别为(a1,b1)、(a2,b2)、(a1',b1')以及(a2',b2'),则这4 个点的坐标值应满足a2+b2>a1+b1以及a1'+b2'>a2'+b1'。经验证,这种方法能对数据集中所有UBM 图像的标注信息正确排序。
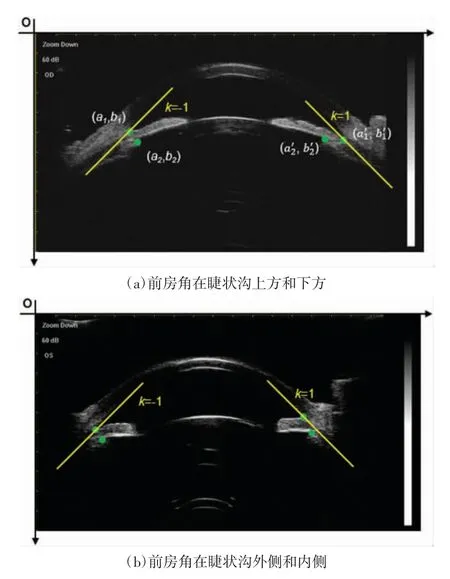
图4 睫状沟与前房角的二分类示意图
由于UBM 图像只有在对准眼球中线时才能准确反映眼前节的结构参数,本文采取神经网络和先验知识相结合的方法,以超声的传播特性及眼前节参数的参考值范围作为判据,筛除偏差较大的图像。
角膜内外表面、晶状体前后表面光滑,超声以镜面反射为主,超声垂直入射时反射最强,因此在扫查切面比较正时,角膜前后表面、晶状体前后表面会形成“明亮的光带”,并且各光带中央大致在一条竖线上(如图5 所示);而扫查面偏差较大时,各光带不在一条垂线上,并且晶状体后界面通常不能显现。因此,有无晶状体后界面回声可以作为切面是否有偏差的判断依据之一。
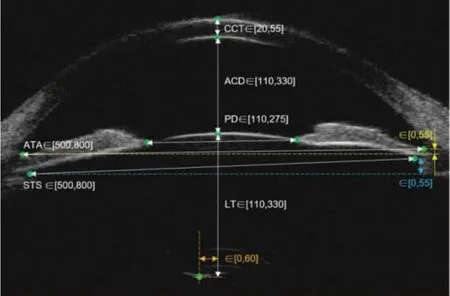
图5 UBM 图像判断条件示意图
本文使用的UBM 图像像素大小为18.18 μm×18.18 μm。为筛除切面有偏差的图片,除UBM 图像中应显示晶状体后囊外,本文还依据眼前节参数参考值范围设定了一些判断条件,如图5 所示。如儿童的PD 为4~5 mm,老年人的PD 为2~3 mm,故取2~5 mm 作为PD 的参考值范围,将单位换算成像素后则PD∈[110,275]。由于UBM 未对准眼球中心时,测量出的PD 会偏小,设定此范围可以排除部分未对准眼球中心的UBM 图像。此外,为了保证在使用UBM时超声是垂直入射角膜的,使角膜中心、瞳孔中心以及晶状体后囊3 个点在同一条直线附近,左右前房角在竖直方向上的坐标差和左右睫状沟在竖直方向上的坐标差须小于1 mm,晶状体后囊与瞳孔中心的水平坐标之差须小于1.1 mm。
3 实验及结果
3.1 算法运行环境
本文使用PyTorch 1.9.0 框架,硬件环境为NVIDIA RTX3090,内存为24 GiB,计算架构为CUDA 11.1,编译语言为Python 3.8。
3.2 数据集生成
本文使用的数据集为天津医科大学眼科医院从2019 年4 月11 日至2020 年9 月18 日采集的眼科疾病患者的前房角UBM 图像。本研究由天津医科大学眼科医院伦理委员会批准(2019KY-24)。UBM 设备为天津迈达医学科技股份有限公司生产的MD-300L,所用超声探头频率为50 MHz,图像分辨力为1024 px×576 px。本次实验共选用前房角UBM 图像样本717 幅,按照592∶125 的比例分为训练集和测试集,其中包含检测到晶状体后囊的图像以及未检测到晶状体后囊的图像。
由经验丰富的临床医生使用labelme 图像标注工具手动标记中央角膜上皮层、中央角膜内皮、两侧前房角、两侧睫状沟、瞳孔两端、瞳孔中央及晶状体后囊,如图6 所示,对于未检测到晶状体后囊的图像则不标注晶状体后囊,以这些标注作为金标准。为满足YOLOv5 数据集的要求,将标注所得的各点的横、纵坐标分别除以分辨力的宽和高后,得到归一化后的锚点坐标。

图6 UBM 图像眼前节关键点标注示意图(金标准)
3.3 评价指标
本文使用二维空间的欧氏距离的平均值评估算法对每个点的定位性能,计算公式如下:
式中,ρ^为欧氏距离的平均值;(x,y)、(x',y')分别为某点的真实坐标和预测坐标;S 为点的个数。同样的,本文使用欧氏距离之差的绝对值评估算法对生理参数的测量误差,计算公式如下:
在筛除切面有偏差的图像时,需要筛除没有晶状体后囊的UBM 图像,此时算法可能在本不包含晶状体后囊的UBM 图像中将角膜的伪影视为晶状体后囊,导致后续测量的晶状体厚度不准确。本文使用假阳性率表示这种情况发生的概率,计算公式如下:
式中,FPR 为假阳性率,TP 为真正例,FP 为假正例。
3.4 训练过程、结果
参数训练采用Adam 优化算法,参数设置如下:输入图像尺寸为640 px×384 px,批量大小为16,最大迭代次数为500,动量因子为0.93334,权重衰减系数为0.00043,初始学习率为0.00693,余弦退火超参数为0.1,采用距离交并比(distance intersection over union,DIoU)作为损失函数。
训练初期模型的权重是随机初始化的,较大的学习率可能带来模型的不稳定,如图7(a)所示。本文采用预热加余弦退火的方式动态调整学习率,如图7(b)所示。预热使模型先使用较小的学习率训练,当模型趋于稳定后,再使用较大的学习率进行训练,使模型跳出局部极小值。当参数接近全局最小值时,通过余弦退火降低学习率,使得损失函数逼近全局最优解[27]。
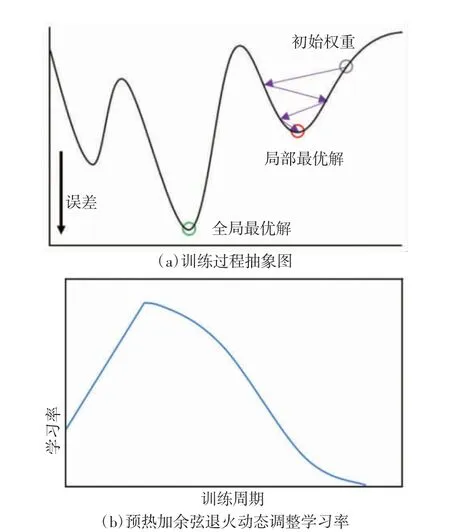
图7 训练过程图及学习率变化图
在预训练中进行了对照实验,结果见表1。YOLOv5s 的训练结果优于模型尺寸更大的YOLOv5m。其原因可能是大模型在训练时产生了过拟合,且前者的速度是后者的2.7 倍,更符合本文实时检测的要求。故以下实验均在YOLOv5s 的基础上开展。

表1 YOLOv5m 与YOLOv5s 的性能比较
超参数初始值将影响到模型的最终性能,而YOLOv5 的超参数初始值是从常见目标检测(common objects in context,COCO)数据集上使用遗传算法得到的。因为预训练时模型在第200 个迭代周期处收敛,故在默认超参数的基础上运行150 次200 个迭代周期,得到适合UBM 图像的超参数。实验结果表明,通过遗传算法优化超参数初始值能够提高模型的定位性能。
卷积神经网络需要大量带标签的数据,但在医学领域获取大量带标注的图像较困难,标注成本较高,因此本文采用迁移学习[28],使用COCO 和视觉目标分类(visual object classes,VOC)数据集上的训练结果初始化YOLOv5 的网络参数。对比从头训练与冻结网络前10 层的训练结果,虽然冻结部分网络能够加速模型训练,但同时也降低了模型精度,这可能是因为COCO 数据集的模型权重不适用于UBM 图像。
表2 中展示了主要的实验结果。第1 行作为对照组。在第2 行中,使用遗传算法寻找较优超参数,模型的精度稍有提高。在第3 行中,训练时冻结部分网络,该方法加快了训练速度,但会降低精度,适合算力不足的场合。为验证本模型能够适应任意尺寸的UBM 图像,在第4 行,将测试集中的UBM 图像尺寸放大2 倍,此时模型的推理速度不变,精度得到了微小的提升。在第5 行中,采用了推理增强和NMS增强,使用后模型精度稍有提高,但是速度较慢,不符合本文实时性的要求。
权衡速度与性能,最优的方案是使用YOLOv5s模型,并使用遗传算法在本文使用的数据集上寻找合适的超参数初始值,此时YOLOv5 模型点定位的平均误差为(66.27±66.25)μm,平均像素误差为(3.65±3.64)px,文献[25]中ResNet-18 模型点定位的平均像素误差为(9.14±5.21)px,文献[26]中EfficientNet-B3模型点定位的平均像素误差为(6.31±5.12)px。由于2 个文献所用的UBM 图像分辨力不同,故使用平均像素误差比较其定位性能,在定位眼前节关键点的任务上,YOLOv5 算法精度较高。本算法预测ATA 的相对误差约为2.05%,预测PD 的相对误差为2.65%,预测STS 的相对误差为1.76%,预测CCT 的相对误差为9.61%,预测ACD 的相对误差为1.98%,预测LT的相对误差为1.32%。
4 结语
针对已有算法无法在UBM 图像中同时测量多个眼前节生理参数的问题,本文提出了一种YOLOv5算法结合先验知识的检测方法,通过迁移学习提高了模型的泛化性能,并使用遗传算法优化模型初始超参数,相比于其他眼前节图像关键点定位的深度学习方法,本文算法对点定位的像素误差更小,并能够精确且快速地测量多个眼前节生理参数。
实验结果中对CCT 的测量误差较大,这是由于CCT 本身值较小,相对误差偏大,另外其他生理参数测量的相对误差均在3%以下,算法的总体精度能够达到要求。算法在配备Ryzen 54600U 处理器的便携式计算机上检测一张UBM 图片的时间为140 ms,说明该算法对硬件要求不高,能够满足实时性的要求。此外,本文的算法能够直接检测不同尺寸及分辨力的UBM 图像,故能应用于不同型号的UBM 仪器。
但本研究仍然有很多不足,首先是缺少绝对正确的标注,由于金标准是由临床医生人工标注的,在此过程中可能会人为地引入误差,当训练集的标注存在错误时,模型会从这些错误中学习规律。有一些研究表明,参与标注的专家越多时,标注的客观性越强,此时误差将趋近于零[29]。其次,由于数据集均来自于同一个医院,在缺乏其他数据集验证的情况下,该算法可能无法在其他地区取得很好的效果。最后,结果中FPR 为4.55%,算法不能完全筛除不包含晶状体后囊的图片,这会使扫查切面不正的UBM 图像亦显示出测量结果,后续研究可以通过增加筛除条件降低FPR。
综上所述,本文提出了一种基于YOLOv5 的UBM图像眼前节参数实时检测算法,该方法经实验测试,准确率高且能达到视频图像实时性要求。在未来,需要更多的研究来评估该算法的临床性能,并通过扩大数据集等方式提高其泛化能力。
