基于深度学习的车辆目标检测算法综述
2023-08-07邹伙宗邓守城
邹伙宗 邓守城
摘 要:近年来,随着人工智能技术的迅猛发展,许多车企和互联网企业都共同致力于研发智能化的自动驾驶系统。在自动驾驶技术中,车辆目标检测技术是至关重要的核心技术之一。目前,传统的目标检测算法无法满足实时检测的要求,因此在自动驾驶等实际应用场景中很难进行大规模应用。相比之下,基于深度学习的目标检测算法更适合此类场景,已经成为该领域的主流算法。本文首先回顾了传统目标检测算法,然后介绍了当前几种主流的两阶段车辆目标检测算法和单阶段车辆目标检测算法,分析了这几种算法的结构和优缺点,最后对未来车辆目标检测算法的研究方向进行了展望。
关键词:深度学习 车輛目标检测 卷积神经网络 计算机视觉
1 引言
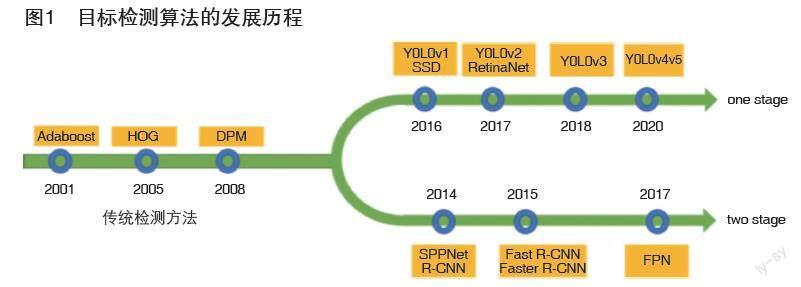
随着人工智能技术的不断发展,深度学习技术在计算机视觉领域中得到了广泛的应用。车辆目标检测一直是计算机视觉领域中一个极具挑战性的问题,具有广泛的应用前景。传统的方法往往需要手工提取特征并构建分类器来实现车辆目标检测,这种方法容易受到环境变化的影响,并需要大量的调整和优化。近年来,随着深度学习技术的不断发展,基于深度学习的车辆目标检测算法在准确率和处理速度方面都取得了很大的提升,逐渐成为研究的热点。图1展示了目标检测算法的发展历程。
本文旨在对基于深度学习的车辆目标检测算法进行综述,回顾了传统目标检测算法,然后介绍了当前几种主流的两阶段车辆目标检测算法和单阶段车辆目标检测算法,并分析了这几种算法的结构和优缺点,以期为相关研究提供参考和启示。同时,本文也将对未来的研究方向进行展望。
2 传统目标检测算法
传统目标检测算法一般包含3个步骤:区域选择,特征提取和特征分类。区域选择是指在输入图像中寻找可能包含待检测物体的区域。一种常见的区域选择方法是使用滑动窗口技术,以不同大小和比例的窗口在图像上滑动,对每个窗口进行分类器评估,得到可能包含物体的区域。特征提取是指从选择的区域中使用人工设计的特征提取方法来提取图像中的特征。常见的人工设计特征包括SIFT[1]、HOG[2]等。这些特征提取方法可以有效地捕捉图像中的局部纹理和形状信息,并对目标分类起到关键作用。然而,这种手动设计特征的方式需要耗费大量的时间和精力,限制了算法的扩展性和泛化能力。特征分类是指对提取的特征进行分类,判断该区域是否包含待检测物体,并对其进行识别。常用的分类算法有支持向量机(SVM)[3]和AdaBoost[4]。然而,近年来深度学习技术的发展已经开始改变这种情况,特别是卷积神经网络(CNN)的广泛应用使得端到端训练成为了可能,可以直接从原始图像中学习特征表示,避免了手动设计特征的过程。
3 基于深度学习的车辆目标检测算法
基于深度学习的车辆目标检测算法是指利用深度神经网络模型对道路场景中的汽车进行自动化识别和定位。该算法通过学习大量的车辆图像数据,能够在完成目标检测任务的同时,还具备一定的鲁棒性,即能够拥有对光照、天气等因素变化的适应能力。
常见的基于深度学习的车辆目标检测算法包括以R-CNN系列网络为代表的两阶段检测算法和以SSD和YOLO系列为代表的单阶段检测算法。这些算法都采用了卷积神经网络作为特征提取器,通过不同的网络结构和技巧来实现目标检测。与传统的基于手工特征的方法相比,基于深度学习的算法具有更高的准确率和更快的运行速度,已经被广泛应用于自动驾驶、交通监控等领域。
3.1 两阶段车辆目标检测算法
两阶段车辆目标检测算法是先生成候选框,再对候选框进行分类和回归,从而实现对图像中目标物体的检测与定位。接下来主要介绍R-CNN、Fast R-CNN和Faster R-CNN。
3.1.1 R-CNN
R-CNN[5]是由Ross Girshick等人于2014 年提出。它是一个基于深度学习的目标检测算法,能够在图片中识别出不同类别的物体,并标注它们的位置。
R-CNN算法主要分为三个步骤:首先,算法通过选择性搜索(Selective Search,SS) 方法来生成一些可能包含物体的候选框。该方法基于图像的颜色、纹理、大小和形状等特征进行分割,从而得到一些可能包含物体的区域。然后,针对每个候选框,算法使用卷积神经网络来提取特征。最后,采用支持向量机分类器来对每个候选框进行分类,确定该区域内是否存在目标物体。同时,还会使用回归器来微调边界框的坐标,从而更精确地定位物体。
总的来说,R-CNN是将物体检测任务分解为候选框生成、特征提取和分类定位三个子任务。但是,它的速度较慢,因为需要对每个候选框都进行CNN计算和SVM分类,这使得其难以应用于实时物体检测场景。后续的改进模型如Fast R-CNN、Faster R-CNN 等在 R-CNN 的基础上做了一些改进, 提高了检测速度和 准确率。
3.1.2 Fast R-CNN
Ross Girshick等人对R-CNN进行改进,提出了Fast R-CNN[6]。该算法首先是在图像上使用选择性搜索算法生成约两千个候选区域,然后将整张图像通过卷积神经网络提取特征,将SS算法生成的候选区域投影到特征图上获得相应的特征矩阵,然后使用RoI Pooling对每个特征矩阵提取固定大小的特征向量,最后使用全连接层进行分类和回归预测。Fast R-CNN仍然需要使用选择性搜索算法来生成候选区域,这个过程比较耗时,限制了算法的速度。
3.1.3 Faster R-CNN
针对 R-CNN和Fast R-CNN的不足,2015年Shaoqing Ren等人再次做出改进,提出了Faster R-CNN 算法[7]。它是R-CNN系列算法中速度最快的一种。与R-CNN、Fast R-CNN相比,Faster R-CNN引入了一种名为Region Proposal Network(RPN)的新型神经网络结构,可以在图像上提取出具有潜在检测目标的候选区域。这种结构可以与分类器共享卷积层特征,从而避免了重复计算。
Faster R-CNN 的網络结构主要由三个部分组成:卷积神经网络(CNN)、RPN网络和 Fast R-CNN检测网络。首先,在卷积神经网络中对输入图像进行特征提取。然后,特征图被送入RPN网络,以生成包含潜在目标的候选区域。这些候选区域会被进一步处理,以去除不相关的区域,并将剩余的区域送入Fast R-CNN检测网络中进行目标分类和边界框回归。
总的来说,两阶段检测算法通常检测精度较高,但检测速度慢。
3.2 单阶段车辆目标检测算法
单阶段车辆目标检测算法是将两阶段检测算法的两个阶段合并成一个阶段,在一个阶段里直接完成目标物体的定位和类别预测。接下来主要介绍SSD和YOLO系列算法。
3.2.1 SSD
单阶段的SSD(Single Shot MultiBox Detector)目标检测网络是一种基于深度学习的目标检测算法[8],它可以在一个前向传递中直接预测出图像中所有物体的位置和类别。
SSD网络由一个卷积神经网络和一个预测层组成,其中CNN负责从输入图像中提取特征,而预测层则负责根据这些特征预测物体的位置和类别。具体来说,SSD网络首先使用一个基础的卷积神经网络(如VGG-16或ResNet)来从原始图像中提取特征。然后, 每个特征图位置都会生成一组默认框(default box),这些默认框具有多种大小和长宽比,可以适应不同大小和形状的目标。最后,网络会对每个默认框进行分类和回归,以确定目标的类别和位置。
通过这种方式,SSD网络可以在一个前向传递中同时完成对图像中多个物体的检测和分类。由于它是单阶段的目标检测算法,因此速度比两阶段的算法(如Faster R-CNN)更快。
3.2.2 YOLOv1
YOLOv1是一种基于卷积神经网络的目标检测算法[9],其主要思想是将目标检测任务转化为一个回归问题,与传统的目标检测算法不同,YOLOv1是一个端到端的模型,可以直接从原始图像中输出检测结果。具体来说,YOLOv1将输入图像分成7×7个网格(grid cell),每个网格预测2个边界框,并且会选择与真实框具有最大IoU值的边界框来负责预测该物体。此外,每个网格只能检测一个物体。因此该算法的缺点也很明显,那就是对小目标检测效果较差。
3.2.3 YOLOv2
YOLOv2算法是在YOLOv1算法的基础上进行改进[10],YOLOv2采用了先进的网络结构DarkNet-19,相对于第一代YOLOv1算法,在精度和速度上都有 所提升。其核心思想是将输入图像分成13×13的网格,每个网格预测5个边界框,与YOLOv1不同的是,YOLOv2引入了锚框(anchor)机制,锚框的尺寸大小是使用K-means对数据标签进行聚类得到的。此外,YOLOv2还使用了多尺度训练策略和Batch Normalization等技术,进一步提高了检测精度。
3.2.4 YOLOv3
YOLOv3是一种端到端的目标检测算法[11],主要由骨干特征提取网络 DarkNet-53和多尺度特征融合的预测网络组成。YOLOv3通过不断堆叠残差块(Residual Block)来组成骨干网络 DarkNet-53,进行特征提取。整体的网络结构是以FPN[12]式的特征金字塔结构来构建,实现对三种尺度特征的融合检测。每种尺度的特征图对应分配三种不同大小的锚框,在三种尺度的特征图上共设置9种不同大小的锚框来进行检测。YOLOv3相比较于它的前身YOLOv2,在准确率和速度方面都有很大的提升。
3.2.5 YOLOv4和YOLOv5
2020年基于YOLOv3的改进版本 YOLOv4[13]和 YOLOv5[14]先后被提出,它 们都是当前非常流行的目标检测算法。
YOLOv4 相较于YOLOv3,在DarkNet-53 中引入了 CSP 模块(来自CSPNet[15])组成其骨干特征提取网络CSPDarkNet-53。在预测网络部分,一方面使用SPP结构提取多尺度特征,增强模型对不同大小目标的检测能力,另一方面利用FPN和PAN(来自PANet[16])的结合,实现不同分辨率特征的融合,提高目标检测精度。
YOLOv5的骨干网络采用的是New CSP-DarkNet53。在预测网络部分,一方面SPP换成了SPPF,两者的作用是一样的,但后者效率更高,另一方面在PAN结构中加入了CSP模块。需要注意的是YOLOv4中的PAN结构没有引入CSP模块,YOLOv5在v6.0版本后把网络第一层的Focus模块换成了一个6×6大小的卷积层。除此之外,YOLOv4和YOLOv5都使用到了Mosaic数据增强来增加训练样本的多样性。
总的来说,YOLOv4和YOLOv5都是对YOLOv3的改进和优化,并且在速度和精度上都有所提高。目前YOLO系列算法仍处在更新改进阶段。
4 结语
本文主要是对车辆目标检测算法进行阐述,先回顾了传统目标检测算法,然后介绍了具有代表性的基于深度学习的两阶段和单阶段车辆目标检测算法。在复杂的道路场景下对车辆目标进行检测,就需要发展更加高效的深度学习算法,进一步提高车辆目标检测的精度和实时性。未来可以探索将智能化算法与硬件结合,进而实现更加智能、更加高效的车辆目标检测系统,也可以将各个领域的技术不断融合,例如将摄像头和激光雷达等多种传感器数据进行融合,进一步提升车辆目标检测的精度和可靠性。
参考文献:
[1]Lowe D G.Object recognition from local scale-invariant features[C]//1999 the Proceedings of the Seventh IEEE International Conference on Computer Vision.IEEE,1999,2:1150-1157.
[2]Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),June 20-25,2005,San Diego,CA,USA.IEEE,2005,1:886-893.
[3]Cortes C,Vapnik V. Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[4]Yoav Freund,Schapire R,Abe N.A short introduction to boosting[J].Joumal-Japaneses Society For Artificial Intelligence,1999,14(5):771-780.
[5]Girshick R,Donahue J,et al.Rich feature hierarchies for accurate object detection and semantic segmentation [C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2014:580-58
[6]Girshick R.Fast R-CNN[C]//2015 Proceedings of the International Conference on Computer Vision (ICCV),December 7-13,2015,Santiago,Chile.IEEE,2015:1440-1448.
[7]Ren S,He K,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[8]Liu W,Anguelov D,Erhan D,et al.SSD:single shot multibox detector[M]//Leibe B,Matas J,Sebe N,et al. Computer Vision-ECCV 2016. Lecture Notes in Computer Science.Cham:Springer,2016,9905:21-37.
[9]Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[10]Redmon J,Farhadi A. YOLO9000:better,faster,stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),July 21-26,2017,Honolulu,HI,USA.IEEE,2017:6517-6525.
[11]Redmon J,Farhadi A.YOLOv3:an incremental improvement[J/OL].(2018-04-08)[ 2020-11-20].https://arxiv.org/abs/1804.02767.
[12]Lin T Y,Dollár P,Girshick R,et al. Feature pyramid networks for object detection[C].Proceedings of the IEEE conference on computer vision and pattern recognition,2017:2117-2125.
[13]Bochkovskiy A,Wang C Y.YOLOv4:optimal speed and accuracy of object detection[J/OL].(2020-04-24)[2020-11-20].https://arxiv.org/abs/2004.10934.[14] https://github.com/ultralytics/yolov5.
[15]Wang C Y,Liao H,Wu Y H,et al.CSPNet:a new backbone that can enhance learning capability of CNN[C]//2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),June 16-18,2020,Virtual Site.IEEE,2020:6576-6584.
[16]Chen Y,Wang Y,Zhang Y,et al.PANet:a context based predicate association network for scene graph generation[C]//2019 IEEE International Conference on Multimedia and Expo (ICME).IEEE,July 8-12,2020,Shanghai.IEEE,2020:1535-1543.
