基于YOLOv5的人脸口罩检测研究与实现
2023-06-25吴昱昊王会成朱云强
吴昱昊 王会成 朱云强
摘 要:文章基于YOLOv5算法,开发实现了人脸口罩佩戴智能监测系统。系统可以实现对目标图片、目标视频、实时监控画面的人脸进行是否佩戴口罩的检测。通过开源数据收集、网络照片采集、人工拍照采集等方式自制得到了不同环境下人像的数据集。使用了PyTorch深度学习框架,使用了PyQt作为界面的开发框架,系统提供了高精度的实时口罩检测功能,具有较好的应用前景。
关键词:YOLOv5;CNN;口罩检测;深度学习
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)04-0098-03
Research and Implementation of Face Mask-Wearing Detection Based on YOLOv5
WU Yuhao1, WANG Huicheng2, ZHU Yunqiang2
(1.Jiaxing Vocational & Technical College, Jiaxing 314036, China; 2.Xinfengming Group Co., Ltd., Jiaxing 314513, China))
Abstract: Based on YOLOv5 algorithm, this paper develops and achieves an intelligent detection system of face mask-wearing. The system can detect faces of mask-wearing in target pictures, videos and real-time monitoring screen. Through the collection of open-source data, python crawler, manual photo and other methods, the data sets of portraits in different environments are obtained. The deep learning framework of PyTorch is used, and PyQt is used as the development framework of the interface. The system provides high precision real-time mask-wearing detection function, and has a better application prospect.
Keywords: YOLOv5; CNN;mask-wearing detection; deep learning
0 引 言
疫情防控期间,口罩佩戴成为进出公共场所的必要条件。借助目标检测技术检测人员口罩佩戴情况,能够提高场所出入口的管理工作效率,有效地控制病毒传播。
目标检测技术是指对图像中的特定目标进行识别和定位的技术。目前,目标检测技术的特征选取技术从传统的手工设计逐渐发展到了使用深度学习提取的方法。以深度学习技术为核心的目标检测技术,其检测效率随着方法的更新也不断得到了提升。卷积神经网络(Convolution Neural Network, CNN)在深度学习中被广泛应用,一般在目标检测算法中扮演特征提取器的角色,多用于图像特征提取、图像分类。YOLO(You Only Look Once)算法由R. Joseph等于2015年首次提出,采用深层卷积神经网络,在位置检测和对象的识别方面性能表现突出。结合实际应用,考虑数据规模以及口罩检测的实时性要求,本文以YOLOv5为基础开展了口罩佩戴检测的研究。
1 技术分析
1.1 深度学习与卷积神经网络
随着计算机视觉技术的持续发展,深度学习变得越来越重要。以深度学习技术为核心的目标检测技术相比于利用手工特征提取方法获取目标特征的传统识别器有着特征表达能力优、检测准确率高、实时性强的优点。神经网络作为一种常用的深度学习架构,常用于图像识别,提升工作效率。传统的全连接神经网络最初被应用在手写数字集上,用选定的神经网络和损失函数通过监督学习的方法进行训练,以确定网络中不同神经元的权重。一般来说,图像因为像素量的原因数据十分庞大,对应会产生大量的神经网络参数,因此传统的神经网络结构在实际应用中往往需要巨大的参数空间,这对模型的速度及准确率产生了很大程度的影响。
由于传统的神经网络存在的各种缺点,卷积神经网络(CNN)由杨立昆于1989年首次提出。该网络的基本结构包括:卷积层、池化层、全连接层。卷积层,降采样层,全连接层。结构的每一层有多个特征图,每个特征图有多个神经元。在CNN中,卷积层和池层通常交替设置,即池层后接卷积层,池层后紧接卷积层。CNN与全连接神经网络最大的不同点在于,所有上下层神经元在CNN中并不是都能直接相连的。CNN把“卷积核”作为中介,同一个卷积核在所有图像内都是共享的,从而实现参数共享,构建权值共享结构网络。图像经过一次卷积操作后仍然能够保留初始的位置关系。正是由于CNN限制了参数的个数并挖掘了局部结构的这个特点,CNN能使用较少的参数,训练出更好的模型,同时有效地避免过拟合。CNN的泛化能力明显优于其他方法,在良好的容错能力之外还有优秀的并行处理能力和自学能力。CNN是目前最流行的神经网络之一,为目标检测中的分类与回归任务奠定了基础。
1.2 目标检测与YOLO算法
R-CNN(Region-CNN)是最早采用卷积神经网络进行目标检测的算法。作为一種Two-stage目标检测算法。R-CNN首先需要对被输入的图片采用搜索算法,生成一系列候选边界框作为样本。针对每个候选边框,会有一个独立的CNN通道,再通过卷积神经网络结合SVM预测分类候选边界框中的样本。因此,R-CNN也被称为基于区域的方法。R-CNN虽然对于位置检测与对象分类准确率相对较高,但是由于它的运算量大,检测速度非常慢,这使得这种算法在实际生产中难以得到比较好的应用。
YOLO算法是在R-CNN基础上发展起来的,one-stage目标检测算法的典型代表。R-CNN作为Two-stage目标检测算法包含了物体类别(分类问题)、物体位置(回归问题),即需要先产生大量的先验框,然后再去判断先验框里是否有检测目标。而YOLO创造性地把目标检测问题为了回归问题,把产生先验框和判断先验框中的目标这两个阶段合成一个。在YOLO中,图像被缩放到为统一的尺寸。YOLO把整张图作为网络的输入,只需经过一个神经网络就能直接在输出层回归得到bounding box即目标的位置和box所属的类别。在YOLO的网络框架中,图片没有被真正的网格化处理,而是被作为整体看待。YOLO将单个卷积神经网络(CNN)用在整张图片上,再将图片分成网格,以此预测每个网格的类概和边界框。因为YOLO把检测作为一个回归问题,因此不用复杂的框架,是一个非常快速的目标检测算法。YOLOv5是YOLO较新的版本,使用Pytorch框架编写。相比YOLOv4,YOLOv5尽管在性能上稍有逊色,但是速度快、体积小,在保证一定精度的前提下,在快速部署方面极具优势。
2 口罩检测模型
2.1 口罩检测数据集
数据的获取方法主要有:手机拍摄(校园进出口)、网络照片采集、网络开源数据集,自制得到人脸口罩数据集。采用GitHub-huzixuan1所提供的开源代码进行爬虫采集(符合协议要求)。使用GitHub -AIZOOTech所提供的开源数据集作为数据补充。
在数据量的准备方面,由于YOLOv5的输入端采用了Mosaic数据增强的方式,数据集中4张图片可以被随机缩放和拼接,在很大程度上丰富了现有数据集。另一方面,计划使用预训练的模型开展目标模型的训练,因此可以认为目标模型对自制数据集的数量量要求不高。最终得到的数据集含有原始图片共计2 000张。
在数据格式方面,为了方便统一不同来源的图像数据,尽管算法设计中要使用的是YOLOv5模型,为了方便统一数据格式,对自制原始图片使用labeling进行了VOC格式的标注,标注范围为人像整个头部含少量肩膀上部。在程序代码中设置了数据格转化。而VOC格式这也方便了这个数据集未来可以使用在其他模型中。
在数据预处理方面,考虑了图片大小的调整。在大部分的目标检测算法中,需要将原始图片经过缩放、填充部分黑边统一到一个尺寸标准下再输入网络。这一过程会带来一定量的信息冗余并直接增加了模型的训练时间。YOLOv5的代码中在输入端的letterbox函数中做了一定的优化修改,能够对原始图像自适应的添加最少的黑边,理论上来说,输入图像的大小对YOLOv5的限制较小。但是,输入图像大小的不同会导致网络宽度发生变化,对应的模型文件大小也一并发生变化。由于计划使用预训练的模型参数文件,因此在程序中将输入图像的大小设置为640×640,这个大小和YOLOv5的作者的预训练模型在coco数据集上使用的输入图像大小是一样的。
2.2 模型构建与训练
由于硬件条件限制,为了缩短训练时间,提高模型的泛化能力,此模型是在预训练模型的基础上进行二次训练得到的。YOLOv5的官方代码给出了四种网络模型,从小到大分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x四个网络。考虑到实际任务需求和硬件环境条件,使用下载得到的官方代码YOLOv5s(权重文件)作为预训练模型,并在此基础上使用自制数据集对模型进行训练。
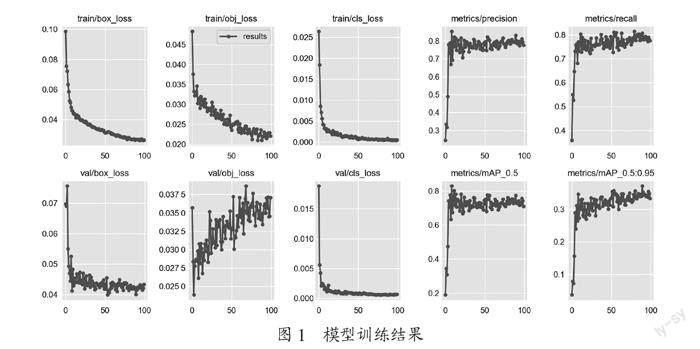
模型训练使用自制数据集,总样本2 000个,分为训练集、测试和验证集。其中,将1 200个样本划分为训练集,400个样本划分为测试集,400个样本划分为验证集。在图像处理工作站上进行100次迭代训练,每一次训练的ACC和Cost都直观地展现出来,最后保存训练模型。模型训练结果如图1所示。
2.3 模型评估
图1给出了模型经过100轮训练的性能变化。随着训练的迭代次数的增加,loss则随着训练轮数的增加在不断的降低,趋于稳定,也同时达到了期望的数值。Precision及recall随着迭代次数增加不断上升分别稳定在0.8及0.79左右。观察不同阈值下两者的数值的波动情况,较为稳定。可以认为模型具有比较好的精准度及稳定性。
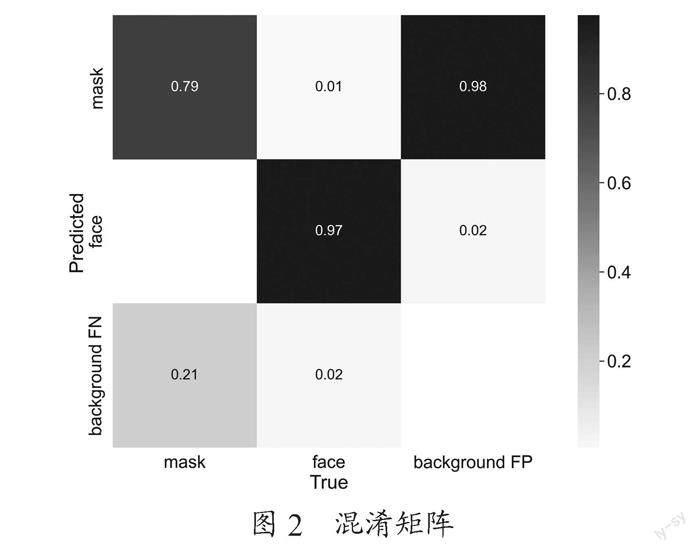
为了进一步分析模型的性能,将模型在400个样本的验证集上进行测试。模型在验证集上表现较好,分析图源及由图2混淆矩阵分析可得,模型对人脸的检测能力较好,但容易将戴口罩的人脸误测为背景因素。这一定程度上是可能是存在图片像素过低、一张图片中戴口罩人脸过小、口罩佩戴不规范等因素造成的。
3 系统实现
3.1 系统设计
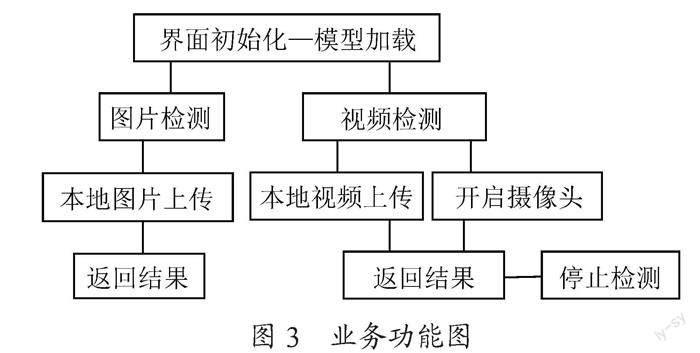
该系统使用训练好的YOLOv5模型对目标进行检测,判断后对原图像人脸加方框显示是否戴口罩。具备以下功能:图像采集、图像处理、口罩检测、图像显示。系统业务功能图如图3所示。
图像采集:图像可以由两种方式采集,分别是本地上传(图像或视频)、摄像头实时采集。
图像处理:对于视频画面,使用cv2自带的VideoCapture读取摄像头信息或本地视频文件,按照默认25毫秒获取视频流图像。
口罩检测:对YOLOv5模型进行接口封装,使其提供模型推理能力。构建函数提供目标检测能力。
图像显示:將口罩识别结果显示在系统的可视化界面上。考虑系统使用效率,在界面初始化时加载好检测模型,并创建临时目录用以保存中间处理结果。
界面设计:通过添加tab页将图片检测和视频检测分为两个页面。图像检测页面同时显示原始图像及检测结果,视频检测页面仅显示检测结果。使用盒子布局,嵌套水平布局和垂直布局。
3.2 实施结果
使用PyQt5构建人脸口罩智能分析监测系统的GUI界面,可以实现模型检测结果的可视化,用户可以通过相关按钮调用模型检测目标图片、目标视频、摄像头视频,实时看到检测结果,极大程度提高了用户体验。系统运行效果如图4、图5所示。
4 结 论
本文基于YOLOv5卷积神经网络结构的物体识别算法对图片、视频信息进行分析,能够对人脸佩戴口罩进行实时检测,并同时具备较高的检测效率。在后续的研究过程中,可以侧重于与相关硬件结合,推广到门禁系统、生产安防等工作中的智能检测中。
参考文献:
[1] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//IEEE Conference on Computer Vision and Pattern Recognition. USA:IEEE,2016:779-778.
[2] 周飛燕,金林鹏,董军.卷积神经网络研究综述 [J].计算机学报,2017,40(6):1229-1251.
[3] 张珂,冯晓晗,郭玉荣,等.图像分类的深度卷积神经网络模型综述 [J].中国图象图形学报,2021,26(10):2305-2325.
[4] 曹城硕,袁杰.基于YOLO-Mask算法的口罩佩戴检测方法 [J].激光与光电子学进展,2021,58(8):211-218.
[5] 曾成,蒋瑜,张尹人.基于改进YOLOv3的口罩佩戴检测方法 [J].计算机工程与设计,2021,42(5):1455-1462.
[6] 王福建,张俊,卢国权,等.基于YOLO的车辆信息检测和跟踪系统 [J].工业控制计算机,2018,31(7):89-91.
[7] 张瑞国.基于卷积神经网络的区域人脸检测研究 [J].网络安全技术与应用,2021(9):55-56.
作者简介:吴昱昊(1996—),女,汉族,浙江上虞人,助教,硕士研究生,研究方向:深度学习、社会网络分析。
收稿日期:2022-10-10
基金项目:嘉兴职业技术学院2022校立科研项目(jzyy202249)
