药物-靶标相互作用预测平台设计与实现
2023-05-15任浩然邓博韬李建华孝大宇
任浩然,邓博韬,李建华,孝大宇
(东北大学医学与生物信息工程学院, 沈阳 110169)
0 引言
药物在疾病的预防和治疗中发挥着重要作用,不断开发新的药物是人类战胜疾病的必要手段。新药开发成本高昂,从抽象概念到市场产品,一种新药研究和开发成本估计为1.61~45.4 亿美元[1]。旧药新用,也称为药物重定向,是对现有药物发现新的适应症[2]。药物重定向极大减少了药物开发的时间与成本,目前已经取得一些突破性的成果。例如,研究发现,传统的止痛药阿司匹林具有降低脑卒中复发、预防心肌梗死等功效。
自新冠肺炎疫情暴发以来,药物重定向成为国内外诸多科学家与研究机构的关注焦点。2022 年7 月25 日,中国国家药监局应急附条件批准阿兹夫定用于治疗普通型新冠肺炎成年患者,这是我国首个国产新冠口服药,而该药原本用于治疗艾滋病。
利用计算机发现潜在的药物-靶标相互作用(drug-target interaction,DTI)是药物重定向的一种重要方法。设计和开发一款药物-靶标相互作用预测平台,对相关生物医学知识的科学普及、学生科研训练及药物重定向研发具有重要意义。
1 平台框架
在药物重定向的过程中,可以先利用计算机预测出可能的药物-靶标相互作用,然后在实验室和临床验证这些相互作用的真实性。所设计的药物重定向平台将实现筛选潜在药物-靶标相互作用的功能,为了评估平台的有效性,需要确定实验的数据集、数据处理、预测方法、评估标准及测试流程等。预测方法决定着平台的预测性能,将在第2节专门介绍。
1.1 标准数据集
本平台采用文献报道的标准数据集[3],根据药物-靶标相互作用类型数据集分为Enzyme、IC、GPCR 和NR 四个子集。每个子集中包括药物名称、靶标名称、药物-靶标相互作用的信息。同时,对于每种药物计算了该药物与其他药物的化学结构相似性(DS_CS),对于每种靶标计算了该靶标与其他靶标的蛋白质序列相似性(TS_Seq)。表1列出了标准数据集中各子集包含的药物、靶标及相互作用的数量。
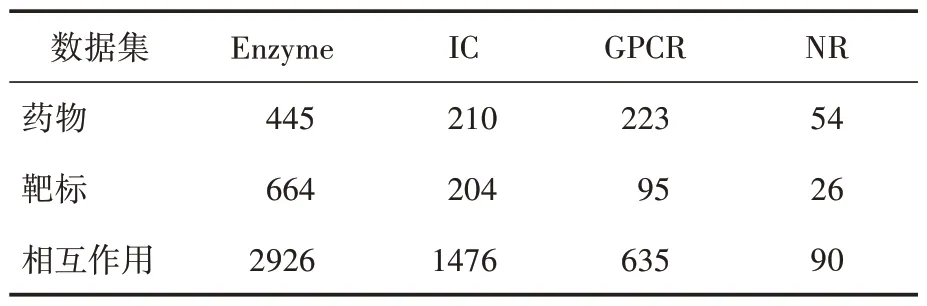
表1 药物-靶标相互作用预测标准数据集
1.2 相似性计算与Logistic变换
目前很多药物是通过靶标蛋白发挥治疗作用的。因此,基于药物-药物相似性、靶标蛋白-靶标蛋白相似性及药物-靶标相互作用可以推测尚未发现的药物-靶标关联。除了前述标准数据集中的DS_CS和TS_Seq,基于药物-靶标相互作用能够计算出新的药物相似性和靶标相似性数据。
药物-靶标相互作用可以视为由0 和1 组成的矩阵。药物和靶标分别构成矩阵的行和列,如果药物与靶标相互作用,那么相应的位置为1,否则为0。药物di与所有靶标的相互作用情况可用一维向量IP(di)表示,靶标ti与所有药物的相互作用情况可用一维向量IP(ti)表示。
根据向量夹角余弦公式,可得到两种药物di和dj的余弦相似性:
同理,可得到两种靶标ti和tj的余弦相似性:
根据文献报道的高斯内核方法[4],可以计算两种药物di和dj的高斯内核相似性:
其中
类似地,也可以获得两种靶标ti和tj的高斯内核相似性:
其中
一般地,设γd′=1,γt′=1,nd表示药物的数量,nt表示靶标的数量。
最终,获得3 种药物相似性数据:DS_CS、DS_Cos和DS_Gauss,以及3种靶标相似性数据:TS_CS、TS_Cos 和TS_Gauss。各种相似性数据值域为[0,1]。表2 列出了从Type1 到Type4 共4种组合类型,不同组合对预测结果的影响将在后文阐述,更复杂的组合可按照相同的思路研究。相似性数据本质上是一个方阵,因此也称之为相似性矩阵。

表2 药物和靶标相似性数据的组合
表2 中的第二、三列是DS和TS,可以选择是否经过Logistic 变换处理,通过对比预测结果,可以确定这种变换的作用。药物和靶标的Logistic变换如下面公式所示:
其中,C为常数,可以通过交叉验证确定,本研究取C=-20。为了处理相似性数据为0的情况,设d=log(9999)。
1.3 验证方法
本平台采用网络一致性投影(network consistency projection,NCP)法预测潜在的药物-靶标关联[5]。为了评估NCP方法的预测性能,采用5折交叉验证。将已知的DTI数据随机分为5份,每次取4 份作为训练集,剩余的1 份作为验证集,循环5次,每份都将作一次验证集。
将预测结果与验证集比较,可以得到真阳性率和假阳性率,进而绘制接受者操作特性曲线(receiver operating characteristic curve,ROC)。ROC 曲线下的面积为AUC 值,该值越大,性能越好。本文以AUC值作为评估标准。
1.4 预测流程图
本平台预测流程如图1 所示。基于药物-靶标相互作用可以获得药物和靶标的余弦相似性数据和高斯内核相似性数据。将相似性数据组合,获得4种组合类型。每种类型在实验时选择是否采用Logistic 变换。然后,药物相似性数据进行网络一致性投影(DNCP),靶标相似性数据进行网络一致性投影(TNCP),将两种投影数据合成(DTNCP),获得预测的药物-靶标关联。在每种组合类型下,分别5 折交叉验证,以AUC值评判预测性能。
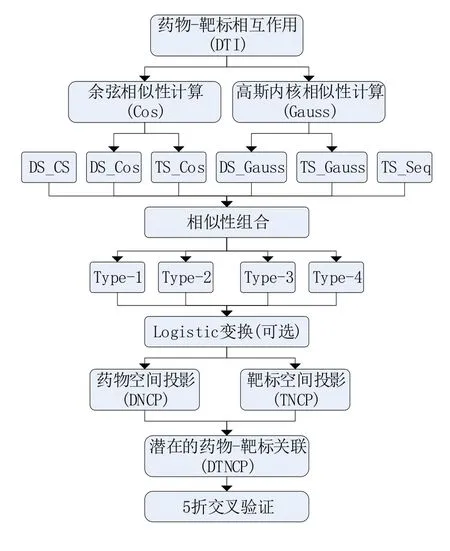
图1 药物-靶标相互作用平台预测流程
2 预测方法
每种组合都包含了药物相似性矩阵DS和靶标相似性矩阵TS。DS中行向量DS(i, :)表示药物i与其他药物的相似性,TS中列向量TS(:,j)表示靶标j与其他靶标的相似性。矩阵A表示药物-靶标相互作用,A中各行表示药物,各列表示靶标,A(i,:)表示药物i与各靶标的相互作用信息,A(:,j)表示靶标j与各药物的相互作用信息。网络一致性投影预测药物-靶标关联分为三步。
第一步,通过药物相似性,计算药物i和靶标j之间的关联值DNCP(i,j):
第二步,通过靶标相似性,计算药物i和靶标j之间的关联值TNCP(i,j):
第三步,通过DNCP(i,j)和TNCP(i,j),计算药物i和靶标j之间的预测关联值DTNCP(i,j):
在上述公式中,对于向量x,‖x‖表示对x取模运算。当采用Logistic变换时,将公式(9)~(11)中的DS和TS分别替换为从公式(7)和(8)得到的DS_L和TS_L。
3 系统测试与分析
本系统以Matlab为开发和运行环境。Matlab具有强大的矩阵运算能力,适于计算药物相似性矩阵DS、靶标相似性矩阵TS,并结合药物-靶标相互作用矩阵A,实现NCP 预测算法。首先,基于原始相似矩阵预测;然后,选择Logistic变换对原始相似矩阵处理后再进行预测。
3.1 基于原始相似数据的预测
首先,从Type1 到Type4 组合,4 种组合中DS和TS不采用Logistic 变换,对Enzyme、IC、GPCR 和NR 中药物-靶标相互作用矩阵A进行5折交叉验证,实验结果如表3所示。
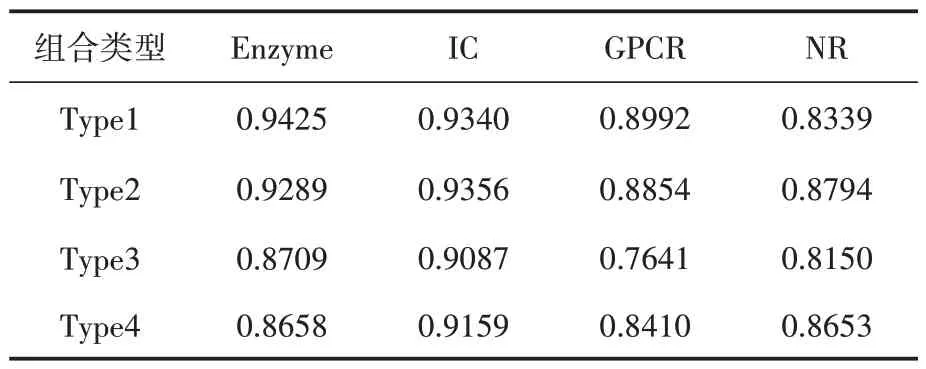
表3 不同相似性组合预测AUC比较
从表3可见,对于每种标准数据子集,采用余弦相似性的Type1 和Type2 总体优于采用高斯内核相似性的Type3和Type4。Enzyme和IC中包含更多的药物和靶标,AUC 值高于0.9,GPCR和NR中包含药物和靶标较少,AUC值低于0.9。
对于每种标准数据子集,Type1对应的AUC值大于Type3的值,意味着仅基于药物-靶标相互作用数据,余弦相似性变换优于高斯内核相似性变换。例如,GPCR 数据子集中,Type1 的AUC值为0.8992,而Type3 对应的为0.7641,前者比后者高出17.68%。对于每种标准数据子集,Type2 对应的AUC 值均大于Type4 的值,意味着结合药物化学结构相似性和靶标序列相似性,余弦相似性变换依然优于高斯内核相似性变换。
进一步分析发现,对应每种数据子集,基于药物-靶标相互作用获得的药物相似性和靶标相似性,在分别结合药物化学结构相似性和靶标序列相似性后,AUC 提高并不明显,有些反而下降。例如,在Type1 下,IC 对应的AUC 为0.9340,而在Type2 下,AUC 为0.9356,增加很小;对于Enzyme 和GPCR,AUC 反而有所降低。比较Type4 和Type3,IC、GPCR 和NR 的AUC 提高,只有Enzyme 的AUC 值略有降低,表明采用高斯内核相似性变换时,结合药物化学结构相似性和靶标序列相似性总体上是有利的。
3.2 基于Logistic变换的预测
为了对比分析,4 种组合中DS和TS采用Logistic 变换,对Enzyme、IC、GPCR 和NR 中药物-靶标相互作用矩阵A进行5 折交叉验证。Logistic 变换中参数C对结果有影响,为了避免过拟合,实验中C=-20,实验结果如表4所示。
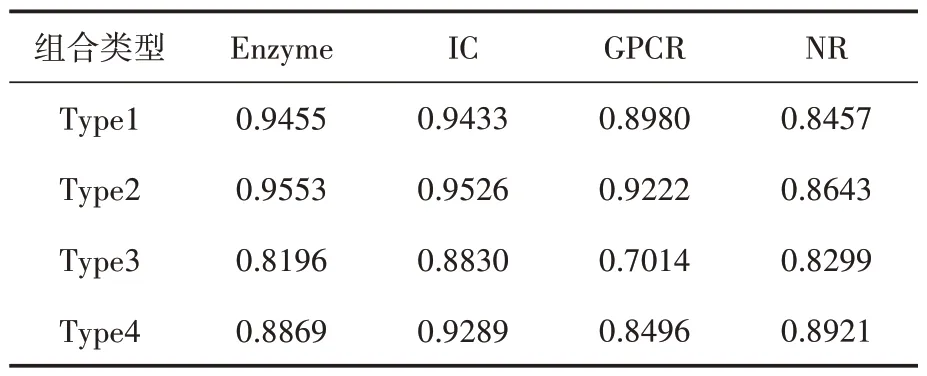
表4 不同组合Logistic变换后预测的AUC比较(C=-20)
比较表4 和表3,采用余弦相似性的Type1和Type2,经过Logistic变换后,8个AUC值中的6 个有所增加,Type2 条件下增加更加明显,2个降低的值出现在GPCR 中Type1、NR 中Type2。NR 中仅包含54 个药物,26 个靶标,90个相互作用,因数据量小结果不稳定。Type2条件下,GPCR 对应的AUC 增加最多,从0.8854增至0.9222,提高了4.16%。就4 个数据子集平均而言,对应Type1,AUC 值提高0.65%;对应Type2,AUC 值提高了1.78%,后者的增量是前者的近3倍。
在表4 中,采用高斯内核相似性的Type3 和Type4 与相应表3 中的数据比较,Type3 条件下除NR 数据子集外,AUC 值反而降低,而Type4条件下AUC值全部提高。总体上,对于Type3,4个数据子集AUC值平均降低3.78%;对于Type4,AUC值平均提高了2.00%。
由表4数据可知,对应任意一种标准数据子集,Type2 条件下的AUC 值高于Type1 条件下的,平均提高1.73%。Type4 条件下的AUC 值高于Type3 条件下的,平均提高10.51%。这表明药物-靶标相互作用矩阵无论采用余弦变换还是高斯内核变换,融合药物化学结构相似数据DS_CS 和靶标序列相似数据TS_Seq 后,预测性能明显提高。
3.3 对比分析
从上述分析可见,在Type2 条件下,经过Logistic 变换后NCP 方法性能最高。将NCP 方法与文献报道的DVM方法比较[6],除NR数据子集外,在其他3 个子集上AUC 值都高于DVM,显示本方法具有一定的优越性。
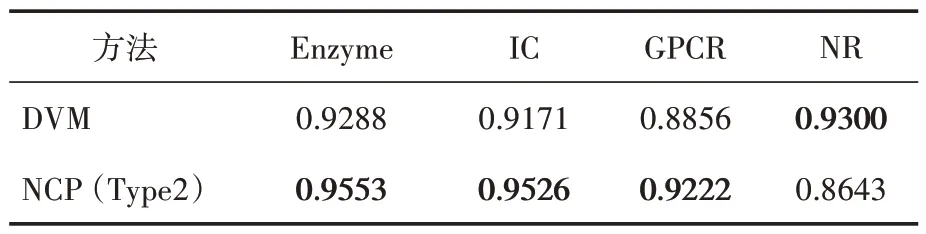
表5 NCP与DVM预测结果的AUC比较
4 结语
通过计算方法筛选潜在的药物-靶标相互作用有利于节约药物重定向的成本。本研究基于Matlab 语言开发一个药物-靶标相互作用预测平台,实验证明该平台是稳定、可行的。平台采用的NCP 预测方法具有一定优越性,对于如何更合理设置各种参数需要深入研究。该平台基于模块化思想设计,可灵活替换不同预测方法,快速获得实验结果。因此,该平台的开发对生物医学知识科普、学生科研训练和药物重定向研究都是有益的。
