一种基于YOLOv5的小样本目标检测模型
2023-04-29侯玥王开宇金顺福
侯玥 王开宇 金顺福

摘 要:深度学习技术在目标检测领域取得了显著的成果,但是相关模型在样本量不足的条件下难以发挥作用,借助小样本学习技术可以解决这一问题。本文提出一种新的小样本目标检测模型。首先,设计了一种特征学习器,由Swin Transformer模块和PANET模块组成,从查询集中提取包含全局信息的多尺度元特征,以检测新的类对象。其次,设计了一种权重调整模块,将支持集转换为一个具有类属性的权重系数,为检测新的类对象调整元特征分布。最后在ImageNet-LOC 、PASCAL VOC和COCO三种数据集上进行实验分析,结果表明本文提出的模型在平均精度、平均召回率指标上相对于现有的先进模型都有了显著的提高。
关键词:小樣本;目标检测;Swin Transformer;通道注意力机制;YOLOv5
中图分类号: TP391.4 文献标识码: A DOI:10.3969/j.issn.1007-791X.2023.01.007
0 引言
近年来,在图像分类领域研究成果的基础上,以深度学习为核心的目标检测技术得到飞速发展。其在智能实时监测[1]、船舶检测[2]、自动驾驶[3]、人脸识别[4]等领域得到广泛的应用。
目前,基于深度学习的目标检测模型想要训练出好的效果,须要以大量的标注样本为基础,但是在实际应用中,很难获得大规模样本数据。而小样本学习只需要少量样本就可以实现对新类目标的分类识别,减少对大规模标签数据的依赖。受到小样本学习的启发,小样本条件下的目标检测技术也在不断崛起。基于包含足够标记样本的数据集,小样本目标检测只需检测新类别中的少量标记样本,然后构建正确的训练方法,设计合适的模型结构以及与训练相对应的损失函数,就可以得到具有泛化性能的检测模型。这大大提高了模型开发的效率。
目前,小样本目标检测方法有基于单阶段或两阶段的目标检测算法。文献[5]以Faster R-CNN为骨干网络,也有一些研究基于单阶段目标检测算法。文献[6-7]使用YOLO作为骨干网络,文献[8]使用SSD作为小样本目标检测的骨干网络。近年来,研究者在不断地将注意力机制与卷积神经网络相结合。例如,自注意力机制Transformer[9]在自然语言处理领域取得突破,例如iGPT[10]和ViT[11]。2020年,Detection Transformer(DETR)[12]的提出将Transformer成功引入到计算机视觉领域。文献[13]在Deformable DETR[14]的基础上,将Transformer与元学习相结合,提出了一种图像级元学习小样本目标检测模型。2021年文献[15]提出了Transformer的改进模型Swin Transformer,其在分类、检测和分割任务中取得了优异的成绩,并且成为一个新的热点模型。例如,文献[16]利用Swin Transformer实现腰部图像的精准分割。
小样本目标检测过程不仅需要提取高层次的语义信息来完成分类任务,还需要低层次的像素信息来实现目标定位。因此,针对上述因素,本文以YOLOv5模型为主干网络,设计出一种新的小样本目标检测模型STFS(Swin Transformer based Few-Shot Learning),它充分利用图像的上下文信息来寻找不同类别之间的可区分特征,以此可以实现图像分类,但图像中包含的无关信息可能会误导目标的定位和识别。因此,增加了注意力机制来提取重要目标周围的有用信息,抑制无关信息的干扰,有助于小样本目标检测的定位和分类。具体工作如下:
1)设计了一个元特征提取网络(Swin Transformer based YOLOv5,ST-YOLO)。它由两部分组成:Swin Transformer模块,通过自注意力的方式扩大全局感受野,并获取全局上下文信息;PANET模块,实现深、浅层之间多尺度的特征融合。
2)设计了一个权重调整模块(Reweighting based ECA,REW-ECA),通过少量的支持集生成具有类属性的权重系数,并自动调整元特征分布以检测新类对象。
1 小样本目标检测模型
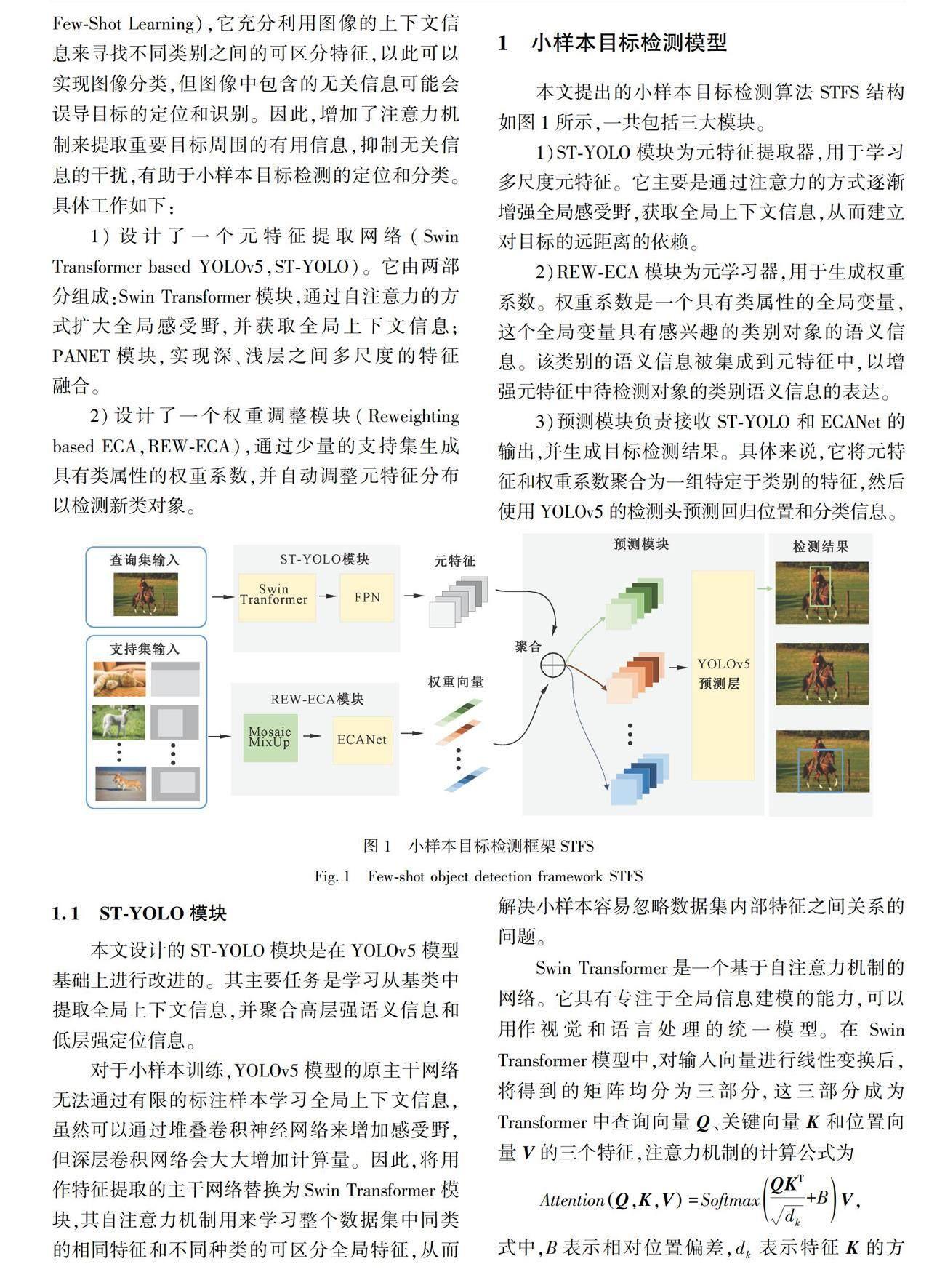
本文提出的小样本目标检测算法STFS结构如图1所示,一共包括三大模块。
1)ST-YOLO模块为元特征提取器,用于学习多尺度元特征。它主要是通过注意力的方式逐渐增强全局感受野,获取全局上下文信息,从而建立对目标的远距离的依赖。
2)REW-ECA模块为元学习器,用于生成权重系数。权重系数是一个具有类属性的全局变量,这个全局变量具有感兴趣的类别对象的语义信息。该类别的语义信息被集成到元特征中,以增强元特征中待检测对象的类别语义信息的表达。
3)预测模块负责接收ST-YOLO和ECANet的输出,并生成目标检测结果。具体来说,它将元特征和权重系数聚合为一组特定于类别的特征,然后使用YOLOv5的检测头预测回归位置和分类信息。
1.1 ST-YOLO模块
本文设计的ST-YOLO模块是在YOLOv5模型基础上进行改进的。其主要任务是学习从基类中提取全局上下文信息,并聚合高层强语义信息和低层强定位信息。
对于小样本训练,YOLOv5模型的原主干网络无法通过有限的标注样本学习全局上下文信息,虽然可以通过堆叠卷积神经网络来增加感受野,但深层卷积网络会大大增加计算量。因此,将用作特征提取的主干网络替换为Swin Transformer模块,其自注意力机制用来学习整个数据集中同类的相同特征和不同种类的可区分全局特征,从而解决小样本容易忽略数据集内部特征之间关系的问题。
Swin Transformer是一个基于自注意力机制的网络。它具有专注于全局信息建模的能力,可以用作视觉和语言处理的统一模型。在Swin Transformer模型中,对输入向量进行线性变换后,将得到的矩阵均分为三部分,这三部分成为Transformer中查询向量Q、关键向量K和位置向量V的三个特征,注意力机制的计算公式为
AttentionQ,K,V=SoftmaxQKTdk+BV,
式中,B表示相对位置偏差,dk表示特征K的方差,Softmax为归一化指数函数。可以看出,该机制是为了在图像中找到关键信息而设计的,这是一种寻找全局特征的方法。
在Swin Transformer用于特征提取的过程中,会失去大量位置信息,不利于目标的定位。因此,将提取的全局特征输入PANET模块,特征金字塔网络(Feature Pyramid Network,FPN)将高层的强语义特征传递下来,像素聚合网络(Pixel Aggregation Network,PAN) 将低层的强定位信息传递上去,实现对目标的精确定位。
总体而言,ST-YOLO模块主要是利用自注意力机制和特征金字塔结构,增强了骨干网络在小样本图像中捕获全局语义信息的能力,并将高层语义信息和低层细粒度信息完美融合,以此提高小样本检测模型学习特征的能力。
1.2 REW-ECA模块
如前所述,REW-ECA模块的功能是生成感兴趣区域的全局变量,该变量具有感兴趣区域中对象的类特征。为此设计的系数生成网络有两个主要功能:一是提取有类别信息的语义特征;二是突出感兴趣的区域。第一点直接使用层数合适的卷积神经网络。第二点通过引入注意力机制来实现。
注意力机制借鉴人类的视觉系统获得关键信息的内部处理过程。例如人类要在嘈杂的市场寻找结伴的伙伴,视线内所有事物的形状、颜色等信息量过于巨大,于是可以选择忽略一部分无关紧要的信息(水果颜色、货物形状),重点观察人的衣服颜色、体型、发色等特征,从而找到相应的目标对象。注意力机制的信息处理过程具体可以表示为
Attention=fgx,x,
式中,g(·)为处理输入特征和产生注意力的过程,f(·)表示结合注意力对输入特征进行处理。对于自注意力机制self-attention,上述过程可以具体表示为
Q,K,V=Linearx
gx=SoftmaxQK
fgx,x=g(x)V。
注意力机制主要分为空间注意和通道注意。在本文中,为了弥补卷积层不考虑每个通道之间依赖关系的缺陷,选择通道注意力ECA在每个卷积通道之间分配资源,并设计了ECANet网络来生成任务所需的权重系数。
总的来说,REW-ECA模块将支持集作为其输入,学习将支持集的信息转换为全局向量,该向量具有感兴趣区域中对象的类特性。在该模块的作用下,将增强查询集中新类对象的特征,有助于检测头的预测。
1.2.1 通道关注模块
通道关注模块(Efficient Channel Attention,ECA)的设计主要考虑到捕获所有通道之间的依赖关系不是必要的,且效率会很低。因此,通过局部跨通道之间的信息交流产生通道之间的注意力,相比与所有通道之间交互有效地降低了模型的复杂度,并保持较高的模型效率。每个通道只与其相邻的才k个通道进行相互交流,通道yi的权重计算为
wi=σ∑kj=1αjiyji,
其中,yji∈Ωki,Ωik表示yij的k个相邻通道的集合。使用卷积的共享权重的方法,以此来进一步提高模型的性能。
跨通道信息交互的覆盖率由卷积核k的大小决定,其计算公式为
k=ψC=log2Cγ+bγodd,
式中,|X|odd为与X距离最近的奇数,C为通道维数。
原始ECA模块通过全局平均池化操作(Global Average Pooling,GAP)获取全局信息,并提取全局完整信息。针对小样本条件下的目标检测任务,将ECA模块进行了修改。本文修改后的ECA模块结构如图2所示,利用全局最大池化操作(Global Max Pooling,GXP) 替换原先GAP,以便它可以关注图像中最感兴趣的区域。
3.4 实验过程和结果分析
本研究采用元学习训练策略,分为两个阶段。第一阶段为基础训练阶段,以具有足够标记样本的基类作为输入,并以指定的学习率对模型进行特定轮次的预训练;第二阶段为微调阶段,使用新类或类似数量的新类和基类来微调模型。
1)ImageNet-LOC数据集
先在COCO数据集上进行基础训练,再使用少量样本数据集进行训练。分别为50个ImageNet-LOC数据集的类别进行1-shot、5-shot、10-shot训练。每类测试集的样本为500个,总共进行了500次的episode训练。
观察表1结果可以看到,在样本量相对较多的 10-shot和5-shot任务上,检测结果均高于另外两种算法。并且在样本量极少的1-shot任务上,检测结果同样优于经典的小样本目标检测算法LSTD和RepMet。在10-shot任务中,STFS模型的性能达到50.8%,比其他先进算法的最佳结果49.2%高出1.6%。主要原因有两方面:一方面是使用Swin Transformer和PANET进行全局上下文信息提取和多尺度特征融合,提升了小样本的学习能力;另一方面,通道注意力机制ECA的使用突出了感兴趣区域,抑制了无关任务信息对小样本检测的干扰。
2) PASCAL VOC数据集
使用trainval 07+12进行正常训练,并对test 07进行测试,按照文献[17]中的小样本目标识别设置方法。比较结果如表2所示。可以看到,在大多数情况下,STFS的性能比现有的方法要好,除了在样本量极少的1-shot任务上,特征提取模块在多尺度的放大下可能导致模型过度拟合,因此平均精度平均值(mean of Average Precision,mAP) 低于RepMet模型和FsDet View模型。然而,隨着新类别样本量的逐渐增加,STFS在2-shot、3-shot、5-shot和10-shot任务中的检测结果均高于其他模型。
3)COCO数据集
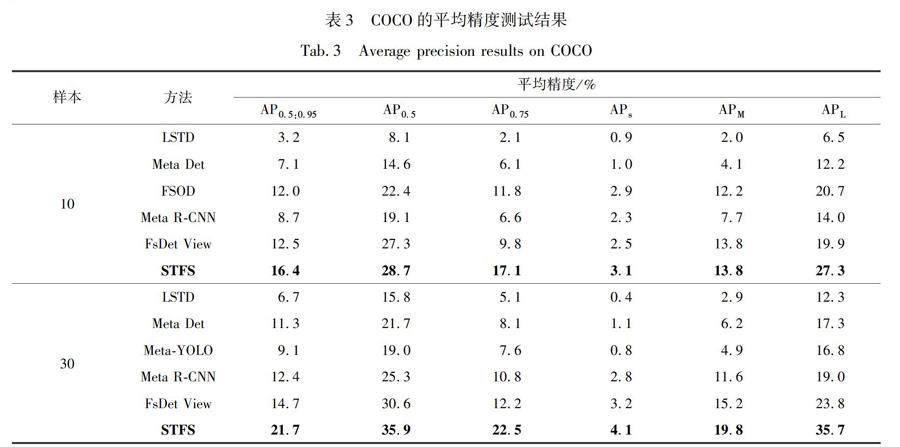
选取与PACAL VOC重叠的20个类别,将其作为新类别,剩下的60个类别作为基类,对10-shot和30-shot任务进行评估,结果显示如表3与表4。可以看到,尽管COCO数据集在更高的复杂性方面(如大规模变化)更具挑战性,但STFS在所有任务下的表现仍优于其他模型。具体来说,在主要指标AP0.5:0.95中,STFS模型在10-shot上比最先进的方法高3.9%,在30-shot上高出7.0%。在严格指标AP0.75中,10-shot的9.8%增加到17.1%,30-shot的12.2%增加到22.5%。此外,STFS在所有规模的图像,尤其是大规模图像上的性能最好,主要是因为STFS通过图像级预测有效地利用了全局上下文信息和各个通道之间的信息,多尺度的特征融合机制有效地提高了复杂场景中的小目标检测。除了直接测量检测器性能的平均精度(Average Precision,AP )外,平均召回率(Average Recall,AR)同样重要,AR越高,检测遗漏越少。如表3所示,STFS在AR100方面也大大超过了最先进的方法,其中10-shot增加了6.8%,30-shot增加了7.5%。
最后,对STFS模型下的三种数据集部分检测结果进行可视化,如图5~7所示,更直观地说明了本文模型的性能。图中只显示新类别的检测结果,因为主要重点是检测新类别的对象。可以观察到,本文提出的STFS模型即使在训练样本稀少的情况下也能检测出新类别对象。此外,STFS在大型对象上的性能非常好,在小型对象上的性能也不差。
经过上述3个数据集的对比实验,本文提出的STFS模型的可行性得到验证。无论是在PASCAL VOC数据集、ImageNet-LOC数据集还是更复杂的COCO数据集中,面对少量样本条件下的目標识别都能取得较好的效果。
4 结论
为了进一步提高小样本的检测效果,本文提出了一种新的目标检测框架STFS。在特征提取过程中,利用Swin Transformer对图像的全局信息进行建模,尽量保留小样本信息,提高小目标的检测效果。采用MixUp数据扩充的方法,减少小样本模型的过度拟合。不同数据集上的实验结果表明,该模型有效地利用了全局上下文信息和各个通道之间的信息,借助多尺度特征融合机制有效地提高了复杂场景中的小目标检测。在平均精度与平均召回率性能指标上比其他先进的网络模型具有更好的性能,在小样本的目标检测中可以取得良好的效果。
参考文献
[1] 胡正平, 张乐, 李淑芳, 等. 端对端SSD实时视频监控异常目标检测与定位算法[J].燕山大学学报, 2020, 44(5): 493-501.
HU Z P, ZHANG L, LI S F, et al. End-to-end SSD real-time video surveillance abnormal target detection and localization algorithm[J]. Journal of Yanshan University, 2020, 44(5): 493-501.
[2] 董众,林宝军,申利民.一种基于图像显著性的离岸船舶目标检测效率优化方法[J].燕山大学学报, 2020, 44(4): 418-424.
DONG Z, LIN B J, SHEN L M. An efficiency optimization method of offshore ship target detection based on saliency[J]. Journal of Yanshan University, 2020, 44(4): 418-424.
[3] 段续庭, 周宇康, 田大新, 等. 深度学习在自动驾驶领域应用综述[J].无人系统技术, 2021, 4(6): 1-27.
DUAN X T, ZHOU Y K, TIAN D X, et al. A review of the application of deep learning in the field of autonomous driving[J]. Unmanned Systems Technology, 2021, 4(6): 1-27.
[4] 邓熠, 毕磊, 薛甜, 等. 基于深度学习的人脸识别技术发展现状分析[J].无线互联科技, 2021, 18(19): 71-72.
DENG Y, BI L, XUE T, et al. Analysis of the development status of face recognition technology based on deep learning[J]. Wireless Internet Technology, 2021, 18(19): 71-72.
[5] FAN Q, ZHUO W, TANG C K, et al. Few-shot object detection with attention-RPN and multi-relation detector[C] //2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle, USA, 2020: 4012-4021.
[6] LI X, DENG J, FANG Y. Few-shot object detection on remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing,2022,60:5601614.
[7] 陈诚, 代江华, 吕秒, 等. 基于Yolov3的小样本智能电极帽端面检测和识别系统[J].电脑编程技巧与维护, 2021 (8): 130-131.
CHEN C, DAI J H, LU M, et al. Few-shot intelligent electrode cap end face detection and recognition system based on Yolov3[J]. Computer Programming Skills and Maintenance, 2021 (8): 130-131.
[8] 李钧正, 殷子玉, 乐心怡. 基于小样本学习的钢板表面缺陷检测技术[J].航空科学技术,2021,32(6):65-70.
LI J Z, YIN Z Y, LE X Y. Surface defect detection technology of steel plate based on Few-Shot learning[J]. Aviation Science and Technology, 2021, 32(6): 65-70.
[9] CHEN C, ZHA Y, ZHU D, et al. Hydrogen bonds meet self-attention: all you need for protein structure embedding[C] //2021 IEEE International Conference on Bioinformatics and Biomedicine, Houston, USA, 2021:12-17.
[10] CHEN M, RADFORD A, CHILD R, et al. Generative pretraining from pixels[C] //International Conference on Machine Learning, New York, USA, 2020: 1691-1703.
[11] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale[C] //International Conference on Learning Representations,Addis Ababa, Ethiopia,2020:1-22.
[12] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C] //European Conference on Computer Vision, Berlin, German, 2020: 213-229.
[13] ZHANG G, LUO Z, CUI K, et al.Meta-DETR: few-shot object detection via unified image-level meta-learning[C] //International Conference on Learning Representations,Virtual Event, Austria,2021:1-21.
[14] ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection[C] //International Conference on Learning Representations,Addis Ababa, Ethiopia,2020:1-12.
[15] LIU Z,LIN Y T,CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows[C] //2021 IEEE/CVF International Conference on Computer Vision,Montreal, Canada,2021:9992-10002.
[16] 田應仲, 卜雪虎. 基于注意力机制与Swin Transformer模型的腰椎图像分割方法[J].计量与测试技术,2021, 48(12): 57-61.
TIAN Y Z, BU X H. Lumbar spine image segmentation method based on attention mechanism and Swin Transformer model[J]. Metrology and Testing Technology, 2021, 48(12): 57-61.
[17] ANG Y, WEI F, SHI M, et al. Restoring negative information in few-shot object detection[J]. Advances in Neural Information Processing Systems, 2020,33:3521-3532.
A few-shot object detection model based on YOLOv5
HOU Yue,WANG Kaiyu,JIN Shunfu
(School of Information and Engineering, Yanshan University, Qinhuangdao, Hebei 066004, China)
Abstract:
Deep learning technology has achieved remarkable results in the field of target detection, but related models are difficult to function under the condition of insufficient sample size.With the help of few-shot learning technology,a new few-shot object detection model is proposed.First, a feature learner is designed, consisting of a Swin Transformer module and a PANET module, to extract multi-scale meta-features containing global information from the query set to detect new class objects. Second, a weight adjustment module is designed to convert the support set into a weight coefficient with class attributes to adjust the meta-feature distribution for detecting new class objects. Finally, experimental analysis is carried out on ImageNet-LOC, PASCAL VOC and COCO datasets. The results show that the model proposed in this paper has a significant improvement in mAP and AR indicators compared to the existing advanced models.
Keywords: few-shot; object detection; Swin Transformer; channel attention mechanism; YOLOv5
