煤化工机器学习分类研究
2023-03-25*汪浩
*汪 浩
(西安石油大学 化学化工学院 陕西 710065)
LIBS的原理属于原子发射光谱法,在过去的20年里蓬勃发展。在钢铁、烟草、医学和环境等各个领域,LIBS技术[1-2]已经被广泛应用。目前,在对样本进行更精确的分类、回归、聚类等研究方面,越来越多的采用机器学习算法[3-4]与LIBS技术结合研究。Odhisea Gazeli等人[5-6]提出了将LIBS与机器学习算法相结合来检测光谱信息方法,能够实现对橄榄油高效、快速的分类方法;当使用线性判别分析算法(LDA)[7-8]构建模型时,该方法进行预测的预测结果准确率达到99.1%。DanielDiaz等人把主成分分析(PCA)算法和LIBS技术结合,搭建了应用于金矿石的分类模型。李晓慧等人提出了对脂肪、肌肉、皮肤等软组织的判别方法,该方法采用了LIBS技术结合多元统计原理的方法,利用K最近邻(KNN)算法和SVM算法搭建模型,最后验证模型的鲁棒性和准确性,采用交叉验证法验证的结果表明,在选择KNN算法模型和SVM算法模型作为分类器时,模型的灵敏度达到了0.995,鉴别准确率超过99.84%。王平等人提出了一种用来对铁矿石酸度进行分析的模型,采用LIBS技术与随机森林(VIM-RF)算法结合搭建模型,由实验结果可知,在模型的性能方面,采用的偏最小二乘法(PLS)模型次于VIM-RF模型的性能。赵云等人研发了一种用来检测土壤Pb的污染程度,该模型原理基于LIBS技术和深度信念网络(DBN)算法。验证结果表明,LIBS数据能够使用机器学习算法处理,模型预测的训练集和测试集的准确率分别达到98.47%和90.62%。使用不同算法作为分类器,搭建模型实现不同煤矿标样数据的高效、精确分类。首先利用一阶导数、S-G平滑[9-10]、多元散射校正[11-12]、标准正态变量[13]、向量归一化[14]五种预处理方法[15]对原始煤矿样标光谱数据进行预处理,然后对光谱数据进行不同梯度比例划分训练集和测试集。再使用ELM[16]、SVM[17]和RF[18]算法作为分类器使用煤矿标样数据进行分类。
1.实验部分
(1)LIBS装置。文中使用的Nd:YAG激光器是由法国Quantel公司生产,激光器的最大频率10Hz,其最大脉冲能量为200mJ,激光波长为1064nm,脉冲持续时长为10ns;采用的光谱仪是产自荷兰Avantes公司的七通道宽幅光谱仪,光谱的分辨率为0.1nm,光谱的范围为190~950nm,有两种方式来触发外部设备,一种由采用外部TTL电平,另外一种是输出电平。采用的可自由控制的XYZ轴的样品台,样品台的行程范围为5cm,能够实现微米级(<1μm)的定位高精度控制。
(2)数据集。本研究中使用数据集为28种煤标样均以粉末状购自济南中标科技有限公司。将每个粉末样品在28MPa的压力下压成颗粒5min。为了尽量减少样品异质性的影响,在不同位置获得了30个光谱,每个光谱是10个激光脉冲的平均值。
(3)建模环境。本文实验平台为Intel I5处理器,16GB RAM,Windows 11操作系统,编辑语言为Python3.7,IDE为PyCharm2022,框架为Pytorch10。
(4)数据预处理。为了实现光谱基线校正、消除背景的不同程度干扰、增强不同吸收特征的对比度和光谱特征值,对光谱进行一阶导数处理;为了消除数据噪声在提取光谱数据信息时产生的影响,采用S-G平滑进行预处理;为了消除样品颗粒形状大小对光谱产生的光谱误差,增加光谱与数据间的关联性,选择多元散射校正(MSC)对光谱进行预处理;为了降低表面散射以及光程度变化所产生的光谱误差影响,采用标准正态变量(SNV)对光谱进行预处理;在消除光程变化对光谱产生的影响时,通过光谱数据减去光谱的吸光度和平均值向量归一化(VN)的方式来进行光谱与处理。
(5)建模原理。①极限学习机。在训练单隐藏层前馈神经网络(SLFN)时,采用传统的SLFN训练算法进行训练与采用极限学习机(ELM)算法有区别,在输入层权重和隐藏层偏置设置方面,极限学习机随机选取参数,输出层权重通过最小化根据训练误差项以及输出层权重范数的正则项所组成的损失函数,按照Moore-Penrose(MP)广义逆矩阵原理计算解析得出。我们假设给定训练集(符号表达式,表示数据示例,表示数据示例对应的标记,集合代指所有训练数据),极限学习机的隐藏节点数为L,与隐藏层前馈神经网络的结构一样,极限学习机的网络结构如图1所示。

图1 极限学习机的网络结构
对于一个神经网络而言,我们完全可以把它看成一个“函数”,单从输入输出看就显得简单许多。很明显图1中,输入部分为训练样本集X,隐藏层在中间,而从输入层到隐藏层之间的部分是全连接层,记隐藏层的输出为H(x),那么隐藏层输出H(x)的公式如下:
隐藏层的输入乘以对应权重参数再加上偏差,得到隐藏层的输出,再通过非线性函数,将其全部节点结果求和得到。而隐藏层部分的节点的输出函数并不固定为同一个函数,输出函数的不同能够应用在不同的隐藏层神经元。通常hi(x)在实际应用中如下表示:
②随机森林。随机森林(Random Forest,RF)算法属于机器学习算法,作为分类算法比较高效。它由若干个子树构成,而子树又有子树的子树构成,每个子树都是一个分类器,最终构成随机森林分类器。所有子树分类器统一采用自主抽样法,随机生成唯一的训练集,根据自主抽样技术的特点,能够不间断生成训练集数据和测试集数据。森林由大量的树木组成,随机森林涉及处理许多决策树。每棵树预测目标变量的概率值,然后我们对产生最终输出的概率进行平均,通过选择有替换的数据点来创建数据集的第一个样本。接下来,我们不使用所有输入变量来创建决策树,我们只使用可用的一个子集。每棵树都被允许长到尽可能大的长度,并且不涉及修剪。
③支持向量机。支持向量机(Support Vector Machine,SVM)算法,是根据数学统计学理论而发展来的高效的机器学习算法。SVM算法设计的初衷是为了解决二进制的分类问题,为了提高数据类别的模型分类效果,引进了线性函数的假设平面到多维空间中运算。该算法利用变化的支持向量分类器,使其适用于评估非线性决策边界。通过使用称为kernels的特殊函数扩大特征变量空间。该算法考虑的决策边界允许将特征变量标记为目标变量。它用于评估边界的数学函数由下式给出,其中K代表核函数。
由于化学计量算法的特点,针对高维的LIBS光谱数据,不能有效处理高维特征向量数据。考虑到SVM算法的优秀全局收敛性的优势,能够定位高维特征空间中的边界位置。SVM算法的步骤如下:A.针对不一样的煤矿LIBS标样数据,任意选取两个样本数据构造SVM模型,k类需建立K(K−1)/2个数量的分类器;B.利用分类器决策决定模型分类的结果。把LIBS特征数据集任意分为两个部分,依次划分为占总数据集的70%的训练集以及占总数据集30%的测试集来验证SVM模型的准确率。
2.结果与讨论
为评估各个模型在不同规模训练集中的表现,每个规模的训练集按照训练集和测试集的划分比例随机抽取10次进行实验进行比较,把各模型在不同规模大小的训练集上的每次运行时间、模型分类精确度以及模型预测标准偏差的平均值作为各个模型的最终性能评价参考指标值。
(1)分类准确率。分类的准确率是对RF、ELM、SVM模型分类结果是否可靠的衡量指标,模型的准确率越高,表示模型分类的可靠性越高。各个模型分别在不同大小规模的训练集上的分类准确率情况如表1所示。

表1 各模型在不同规模的数据集上的分类精度(单位:%)
从表1可看出,不同比例的数据集中,各模型的性能随着训练集样本的增加均逐渐增加,当训练集和测试集规模比例达到588/252后,RF模型的分类精度达到99.05%以上。其中在各组数据集中,与ELM、SVM相比,训练集规模大小RF的分类准确率均为最高,支持向量机的准确率稍次。由分析得出结论,集成学习可以把性能弱的分类器集成起来,进一步提高各个弱分类器模型的非线性分析能力;RF模型的分类准确率较高,分析认为RF算法能够把样品光谱数据之中的无效特征波长剔除出去,从而实现筛选最具样品属性特征的波长。ELM的分类准确率比SVM模型的低,代表核函数对ELM模型的鉴别能力几乎没有影响,然而其非线性建模性能比SVM算法差。
(2)运行时间。模型的运行时间是对分类模型工作效率的重要衡量参数,模型运行的时间越短表示煤矿分类模型的效率越高。如下表2展示了RF、ELM、SVM在不同规模大小的数据集上的模型运行时间。

表2 各模型在不同规模的数据集上的模型运行时间(单位:s)
由表2可看出,RF、ELM、SVM随着训练集规模大小的增加,模型运行时间均逐步增加,并且不论训练集规模的大小,三个模型之中支持向量机模型的运行时间都最长,RF模型的运行时间第二,随机森林模型的运行时间最短。研究分析可知,由于集成学习方式需要训练多个弱分类器,从而完成最后网络的训练,导致RF模型只含有一个隐含层的网络,并且不需要多次迭代寻优过程,从而减少了模型的运行时间。
(3)模型稳定性。为了验证模型具有较强的应用稳定性,采用预测标准偏差(Standard deviation,STD)作为评估SVM、RF、ELM模型稳定性的评价指标。各个网络模型在数据集按照不同比例划分的训练集上的STD参数如图2所示。
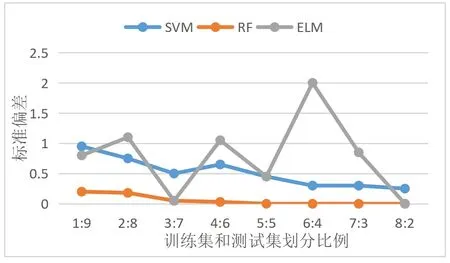
图2 各模型在不同比例训练集上的预测标准偏差
由图2可看出,与极限学习机、支持向量机比较可知,按照不同比例大小划分训练集和测试集,随机森林最低模型表现的STD值较低,支持向量机次之、极限学习机的STD值波动较大。结果显示集成学习方法有助于提升随机森林模型的稳定性。
3.结论
煤矿LIBS标样数据分类模型,在效率和准确率以及稳定性方面能够满足分类需求。煤矿标样LIBS光谱数据蕴含煤矿标样的种类组成,以及元素含量等信息。文中对全光谱数据进行了数据预处理,建立极限学习机、随机森林、支持向量机三种不同分类模型。极限学习机、随机森林、支持向量机三种算法模型分类的准确率分别为83.1%、80.6%、90.4%,支持向量机的准确率最高。
