Altmetric TOP100榜单对论文被引量的影响研究
——基于倾向得分匹配
2023-02-24许林玉
许林玉
(徐州医科大学管理学院,江苏 徐州 221004)
随着互联网技术的发展,网络学术社交平台得到了广泛的发展和应用,形成了开放自由的学术交流体系。在此背景下,学术成果交流、传播与利用的时空发生了变化,需要反应更为及时的评价指标来丰富传统引文评价指标。Priem J等[1]认为网络环境的学术行为也可以测度,并首次提出Altmetric指标来表征基于社交网络的影响力。研究者们普遍认为,Altmetric指标以反应及时、数据更新快、传播范围广、公共深度参与等特点丰富了传统评价指标,延展了学术影响力,在一定程度上完善了学术评价体系[2-3]。
自2018年以来,中共中央办公厅、国务院办公厅等机构先后印发了关于深化项目评审、人才评价、机构评估等措施及指导意见,其中反复提到科研领域要关注“标志性、代表性成果”。在这样的背景下,探索学科领域高社会影响和高学术影响力论文成为国内学术界持续关注的热点问题。Altmetric TOP100论文榜单和高被引论文等标签作为领域内高关注度论文,有效解决了研究者搜寻领域内的高活跃度、高影响力论文过程中的信息不对称和信息不完全等问题。
现有研究主要侧重于探索Altmetric各指标与被引量的关系,且不同的研究结果存在差异。但Altmetric TOP100榜单是否对论文被引量有影响,这个问题较少被提及,虽然Altmetric值及学术论文被引量这两个指标是不同受众群体对学术论文的关注、认可所引发的结果,但是二者之间存在因果关系,正如电影豆瓣评分会影响电影的播放量、下载量等,学术论文的Altmetric值亦会影响学术论文的被引量,特别是学术论文在社交媒体平台形成口碑效应后对被引量具有较大的影响,而进入Altmetric TOP100论文榜单在一定程度上体现了学术论文在社交媒体平台的高口碑效应。故而本文在前人研究基础上通过倾向得分匹配的因果分析方法探究Altmetric TOP100论文榜单与论文被引量之间的因果关系,进一步细化学术论文的社会影响力与学术影响力关系研究,拓宽Altmetric的理论和实证研究;进一步推进因果分析法在图情领域的应用。
1 研究综述
1.1 Altmetric TOP100榜单相关研究
高Altmetric主要通过Altmetric TOP100榜单来表征。Altmetric TOP100是Altmetric.com官网根据Altmetric指标数据,评选出的每年最受公众关注的前100项研究成果[4]。现有研究者对于高Altmetric的研究主要围绕Altmetric TOP100榜单论文的特征及论文Altmetric分数与其被引量关系等。
1.1.1 Altmetric TOP100榜单论文的特征分析
李根等较早对Altmetric TOP100的来源期刊、学科领域、作者地域分布和论文传播途径等方面展开分析[5];邱均平等学者将时间跨度扩大到2016—2018年,并对Altmetric TOP100论文的来源机构、来源期刊、所属学科及传播途径进行更细致的探究[6];赵蓉英等团队在上述研究的基础上探究Altmetric TOP100榜单论文的合作模式[7]及Altmetric TOP100论文的来源期刊、学科分布等特征的动态演化[8];欧桂燕等研究2013—2018年Altmetric TOP100论文的特征演化趋势[9]等。
1.1.2 论文Altmetric分数与其被引量关系研究
现有研究对学术论文的Altmetric分数与其被引量相关性的结果莫衷一是,主要有弱相关及不相关两种结论。
有研究者指出Altmetric分数与被引量存在弱相关性,如Poplašen L等利用2014年Altmetric TOP100论文,证实了被引量与Altmetric分数的弱相关关系[10];Tornberg H N等从COVID-19领域Altmetric分数前100篇论文得出Altmetric分数与被引量弱相关关系[11]。
而Kim J E等以中枢神经系统炎性脱髓鞘病(CIDD)的Altmetric TOP100的论文为研究数据,没有发现Altmetric分数与被引量的显著相关性[12];谭贝加以2014—2017年Altmetric TOP100论文为研究对象,认为Altmetric得分与被引量不相关[13]。
有学者对上述结论展开了进一步的思考,提出高Altmetric分数与论文被引量的相关性与累计时间效应有关,如王睿等“采用公平性测试方法”消除时间窗口影响后得出高Altmetric分数与被引量的关系较强[14]等;亦有学者认为,高Altmetric分数与论文被引量的相关性可能与研究领域相关,如郭飞等运用Altmetric TOP100数据得出学科差异性显著影响Altmetric分数与被引量的相关性[15]。
1.2 倾向得分匹配方法在图情领域的应用
目前,国内外有少量学者运用PSM方法解决图情领域问题。国外学者如Mirnezami S R等采用倾向得分匹配法探讨是否具有“研究主席”职位的科学家论文产出量的差异性[16];Mutz R等运用PSM方法论证具有“VIP论文”称号对论文被引量的影响[17];Shimada Y A等使用PSM-DID探讨科研项目类型对项目参与者论文的数量及内容的影响[18];Liu M J等通过PSM发现多语种期刊和线上期刊的存续时间更长[19]等。
国内情报学主流期刊也逐渐出现了基于倾向得分匹配法的因果关系研究,如赵宇翔等探索“优秀回答者称号”及“进行个人认证”等用户标识对回答者在问答平台转移行为的影响[20];宋士杰等探讨了互联网环境对公民健康素养的影响[21]以及使用互联网对老年人孤独感的影响[22];陈玲等运用PSM-DID方法探究政务大数据政策与技术创新之间的因果关系[23];李广威等运用PSM探究解密和脱密的政策实施效果[24];张克群等运用PSM对专利价值的影响因素进行分析[25]等。
1.3 研究述评
已有Altmetric TOP100榜单的研究多集中于Altmetric TOP100论文特征演化研究及Altmetric分数与被引量的相关性等视角的研究,且相关性结果有弱相关及不相关等相悖的结论。
目前,对于Altmetric分数与论文被引量的研究多用传统的回归方法进行验证,如多元线性回归及负二项回归等,主要研究二者的相关性关系。受论文内生性、选择性偏差等问题的影响,直接进行相关及回归分析难以剥离其他因素对被引量的影响,无法获得Altmetric TOP100论文榜单对论文被引量影响的“净”效应。本文采用基于匹配思想的倾向得分匹配法,通过控制其他协变量,比较“同质”论文在Altmetric TOP100榜单及非Altmetric TOP100榜单状况下被引量的差异,并将学术论文细分为高被引论文和普通论文组,深入考察Altmetric TOP100论文榜单对高被引论文和普通论文的影响的差异性,结果的解释性及稳健性更强。
2 研究数据、方法及研究设计
2.1 数据的采集及预处理
2.1.1 数据采集
本文的数据集主要包括3部分:Altmetric TOP100论文数据、WOS核心合集内所有高被引论文的题录数据以及部分普通论文的题录数据。本文选取该数据集的理由主要有两点:①WOS数据库是世界范围内较为核心且权威的数据库,其认定的高被引论文在一定程度上具有权威性;Altmetric网站日益受到大家的关注与认可,是目前成熟的Altmetric分析工具[4],其认证的Altmetric TOP100受到研究者的广泛认可;②本文的年份选取为2013—2015年,在确保论文超过5年的累积被引量的基础上,保证足够的样本量。
1)2013—2015年Altmetric TOP100论文数据:本文通过Altmetric.com官网下载该数据集,主要题录信息包括Altmetric分数、论文标题、发表期刊、发表日期、作者、摘要及DOI等。数据集下载时间为2020年11月,共得300条论文数据。
2)2013—2015年WOS核心合集内所有高被引论文的题录数据:本文参照科睿唯安官网,将高被引论文定义为“在10年内发表且其引用频次处于该研究领域同一出版年前1%的研究成果”[26]。下载流程如下:首先选择WOS核心合集数据库,在高级检索框中输入“PY=2013”(出版年为2013年)的检索条件进行搜索,选中“领域中的高被引论文”,并以纯文本格式导出文献题录的全记录;题录主要包括作者、标题、期刊名称、关键词、摘要、资助机构及DOI等字段。检索时间为2020年11月27日,一共得到14 413篇高被引论文的数据。2014—2015年数据亦如此下载,最后共得2013—2015年高被引论文44 620篇。
3)2013—2015年WOS核心合集内部分普通论文的题录数据,下载流程如下:首先选择WOS核心合集数据库,检索出2013年去除掉高被引论文的其他论文,并以纯文本格式导出前20 000篇论文题录的全记录,题录信息与上文高被引论文相同,共下载2013—2015年60 000条数据。本文的普通论文定义为不包括高被引论文和零被引论文的其他论文,故而本文将60 000条论文数据去除零被引论文数据,剩余的数据为不包含高被引论文和零被引论文的普通论文数据集。
2.1.2 数据预处理
1)数据删除
本文将高被引论文及普通论文数据集都剔除少量缺失“标题”“作者”“摘要”“关键词”或“期刊”等关键信息的不完整数据,最终高被引论文数据集获得42 776条研究数据,普通论文数据集30 164条。
2)数据匹配
本文主要从两个数据平台下载数据集,需要对2013—2015年Altmetric TOP100及WOS论文这两个数据集进行识别匹配。DOI作为论文的标识,具有唯一性,故而本文根据“DOI”字段进行匹配。2013—2015年Altmetric TOP100共300条数据,有17篇无DOI标识,另有10篇预发布在arXiv等平台上未能在WOS平台检索,最后共有273篇论文通过匹配,其中高被引论文组有139篇论文通过匹配,故将这139篇论文作为高被引论文组的实验组,其余高被引论文作为待匹配的控制组;而在普通论文组,有134篇论文通过匹配,故将这134篇论文作为普通论文组的实验组,其他普通论文作为待匹配的控制组。
2.2 研究方法
倾向值(Propensity Score)最早由Rosenbaum P R等学者于1983年提出[27],是指被研究的个体在控制混淆变量的情况下受到某种自变量影响的条件概率。倾向得分匹配是指(Propensity Score Matching,PSM)使用倾向值作为距离函数进行匹配的方法,目的是通过建立“控制组”及“实验组”构造一个近似随机化实验的场景。
本文运用该方法的基本思路是:比较同一篇论文在“AT100榜单”与“非AT100榜单”两种情形下论文被引量的差异。若同一篇论文在“AT100榜单”与“非AT100榜单”下论文被引量存在差异,则认为AT100榜单导致了论文被引量的差异。本文以i代表论文,y代表年份,AT代表论文是否属于AT100榜单,若属于AT100榜单为1,否则为0。TC为论文被引量,TC1和TC0分别表示论文是否进入AT100榜单状况下论文的被引量,则AT100对论文被引量影响的“净”效应为:
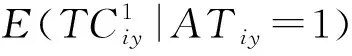
“匹配”就是在非AT100榜单组将与AT100榜单组“相仿”的论文找出来,具体操作是令AT100榜单组和非AT100榜单组论文所有协变量相同或相似。但协变量指标较多,其指标权重难以衡量,故而本文通过倾向得分匹配方法将众多协变量合成一个得分,对AT100榜单组和非AT100榜单组相近得分的论文进行匹配。由于本文的处理变量是二分类变量,因而可以采用形式更灵活的Logit模型[30]。
倾向得分匹配的匹配方法主要为K近邻匹配、半径匹配、核匹配以及局部线性回归匹配等。其中K近邻匹配指寻找倾向得分最近的K个不同组个体;半径匹配是将倾向得分的绝对距离限制在某个范围内,上述两种方法都是匹配最近的个体,本质上属于近邻匹配;而核匹配及局部线性回归匹配是基于不同权重计算方法的整体匹配法,核匹配使用核函数计算权重;使用局部线性回归来估计权重则称为局部线性回归匹配。本文使用Stata15实现倾向得分匹配法。
2.3 变量设计
2.3.1 结果变量
本文考察的是Altmetric TOP100榜单对论文被引量的影响,并将论文细分为高被引论文和普通论文两个组。故而本文的结果变量为高被引论文被引量和普通论文被引量,其中被引量用总被引量表征。
2.3.2 处理变量
本文将Altmetric TOP100榜单作为处理变量,若该篇论文属于Altmetric TOP100榜单,赋值为1,若不属于Altmetric TOP100榜单,则赋值为0。
2.3.3 协变量
1)协变量的选取及定义
协变量又称控制变量,本文基于论文内外部特征选取协变量,主要包括标题长度、作者合作规模、国家合作规模、关键词数量、摘要长度、基金资助、学科数量、参考文献数量、文章篇幅、文献类型、研究领域、期刊所属分区、开放获取及出版年份等。本文根据协变量的数据结构又将其分为离散变量和分类变量,其中离散变量主要为标题长度、作者合作规模、国家合作规模、关键词数量、摘要长度、学科数量、参考文献数量、文章篇幅等,分类变量主要为基金资助、开放获取、文献类型、研究领域、期刊所属分区以及出版年份等。各变量的选取及定义如表1所示。

表1 变量选取及定义
2)协变量的处理
①协变量的清洗处理
直接获得的研究数据使用之前需要进行一定的清洗处理。如国家合作规模,本文基于“Addresses”字段获取地址中国家信息,清洗、去重后最终获得国家数量,作为国家合作规模指标值;WOS数据库期刊分区的更新会滞后1年,本文在填充期刊分区字段时,根据期刊名称匹配论文出版年前一年所对应的WOS平台公布的期刊分区列表,并填充到相应字段,没有被匹配到的期刊说明当年没有被JCR收录,故而没有匹配到的期刊为其他。对于研究领域字段,本文将所有研究领域分别填充到WOS平台公布的五大研究领域中,分别为艺术与人文、生命科学与生物医学、自然科学、社会科学以及应用科学,其中标注多个学科的为跨学科研究。其他变量的处理在表1中有明确的定义说明。
②分类变量的处理
对于分类变量,本文引入虚拟变量,即取值设为0或者1,当有多分类变量时,如研究领域、期刊分区及出版年份等,设置多个虚拟变量,而不能只设置1、2、3等数值来区分,因为分类变量之间的区分度比较大,引入虚拟变量表明处于不同的分类水平使用不同的截距项,如果只设置数值标注在回归过程中无法起到区分效果。
3 数据分析及实证结果
3.1 描述性统计分析
3.1.1 高被引论文与普通论文的描述性统计
表2显示了高被引论文与普通论文各变量的描述性统计分析结果。由表2可得,高被引论文与普通论文部分变量的差异性较大:高被引论文与普通论文被引量的平均值相差16倍多;基金资助高被引论文占比较多,为81.32%,而普通论文只占比51.58%;高被引论文开放获取的比例比普通论文高近16%;普通论文的文献类型主要为研究型论文(Paper),占比高达95.16%;而高被引论文中综述也占有一定的比重;在研究领域方面,除了跨学科领域外,高被引论文与普通论文占比最高的都是生命科学与生物医学,最低的是艺术与人文,且艺术与人文领域论文只有4篇论文入选高被引论文,在普通论文组也只占0.32%,样本量较少,无法得出可靠的研究结论,故而在下文的分析中将艺术与人文领域的数据去除;在期刊分区方面,大部分高被引论文都发表于一区期刊中,占比80.23%,可见高被引论文多发表于优质的期刊,而普通论文的期刊分布在4个区较为均衡。
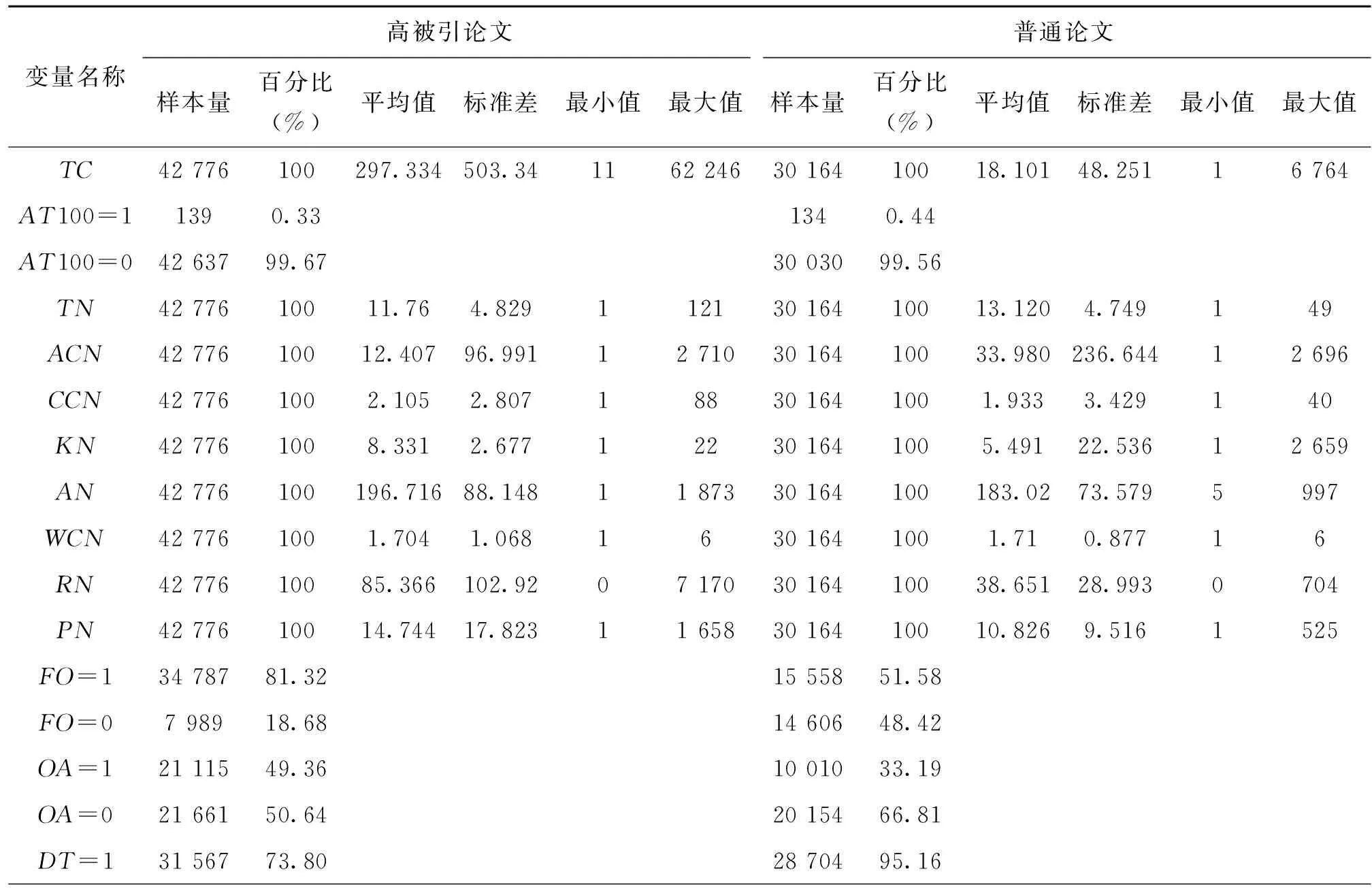
表2 高被引论文与普通论文的描述性统计
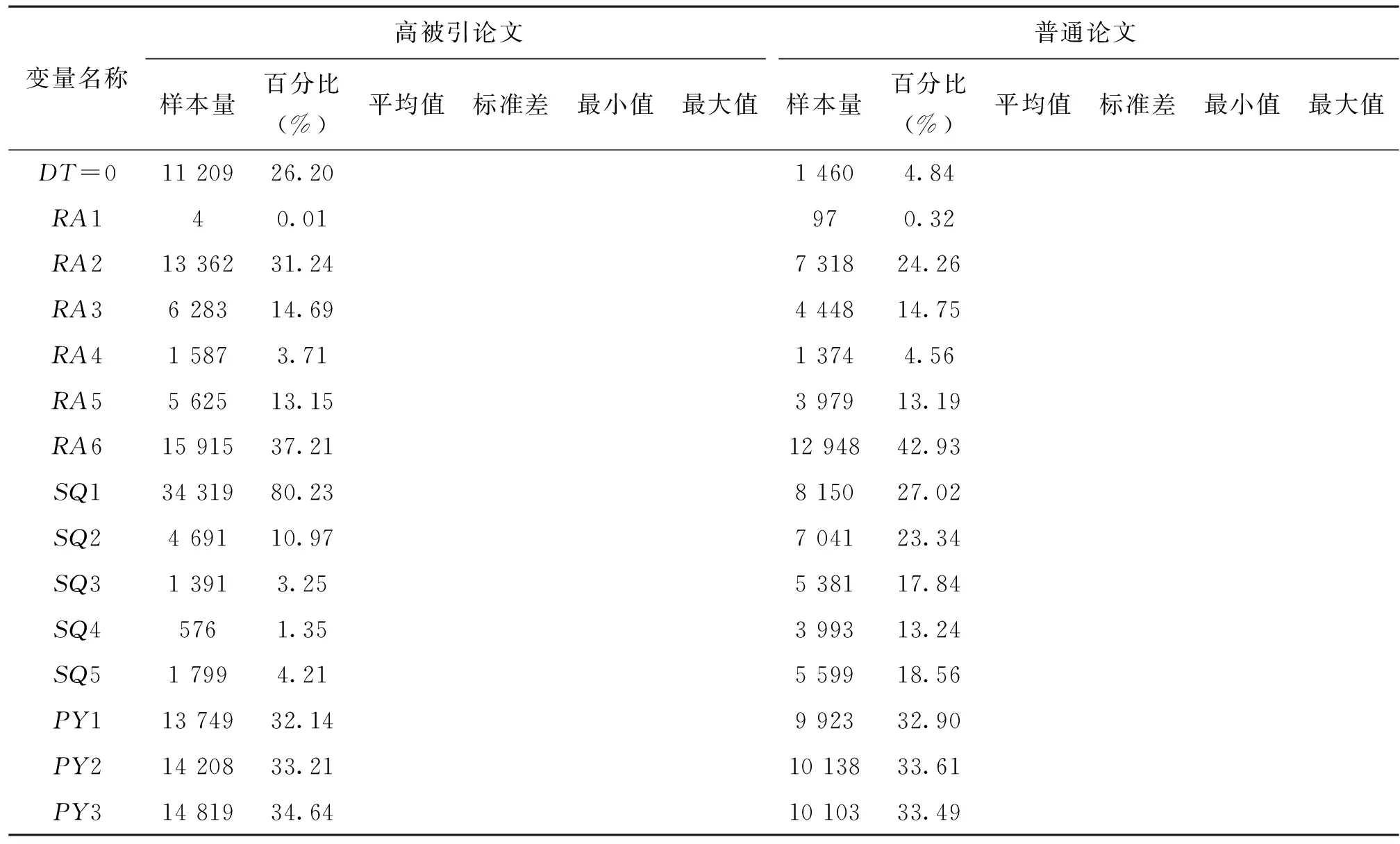
表2(续)
3.1.2 高被引论文AT100榜单与非AT100榜单的描述性统计
表3展示了高被引论文AT100榜单与非AT100榜单各变量的描述性统计结果。由表3可得,高被引论文AT100榜单组与非AT100榜单组的差异性主要集中于被引量、开放获取、文献类型及研究领域等变量,其中,AT100榜单论文被引量的平均值比非AT100榜单论文高370篇左右;AT100榜单组开放获取占比较多,为71.22%,而非AT100榜单组只占比49.29%;AT100榜单组的文献类型主要为研究型论文(Paper),高达95.68%,而非AT100榜单组中综述也占有一定的比重;在研究领域方面,AT100榜单组占比最高的是应用科学,其次是生命科学与生物医学,非AT100榜单组占比最高的是跨学科研究。
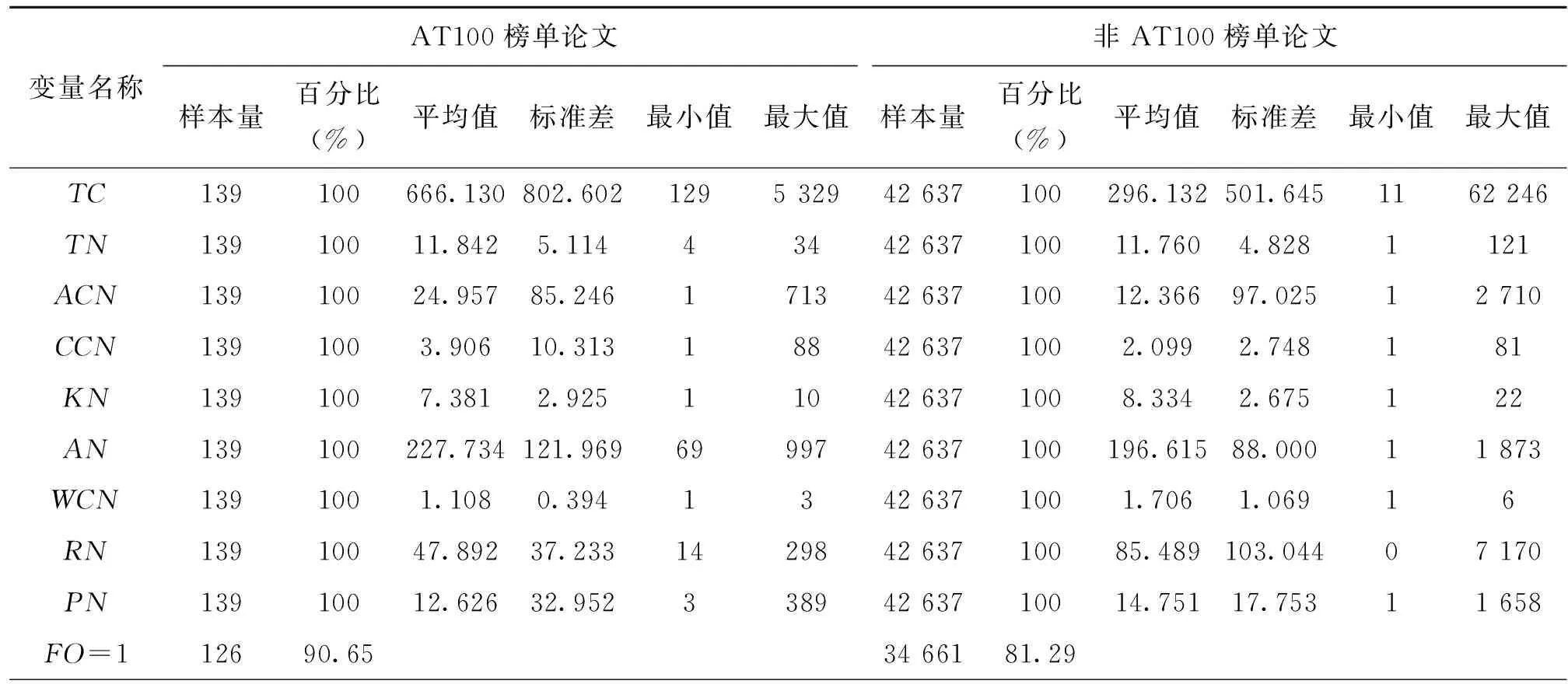
表3 高被引论文AT100榜单与非AT100榜单各变量的描述性统计
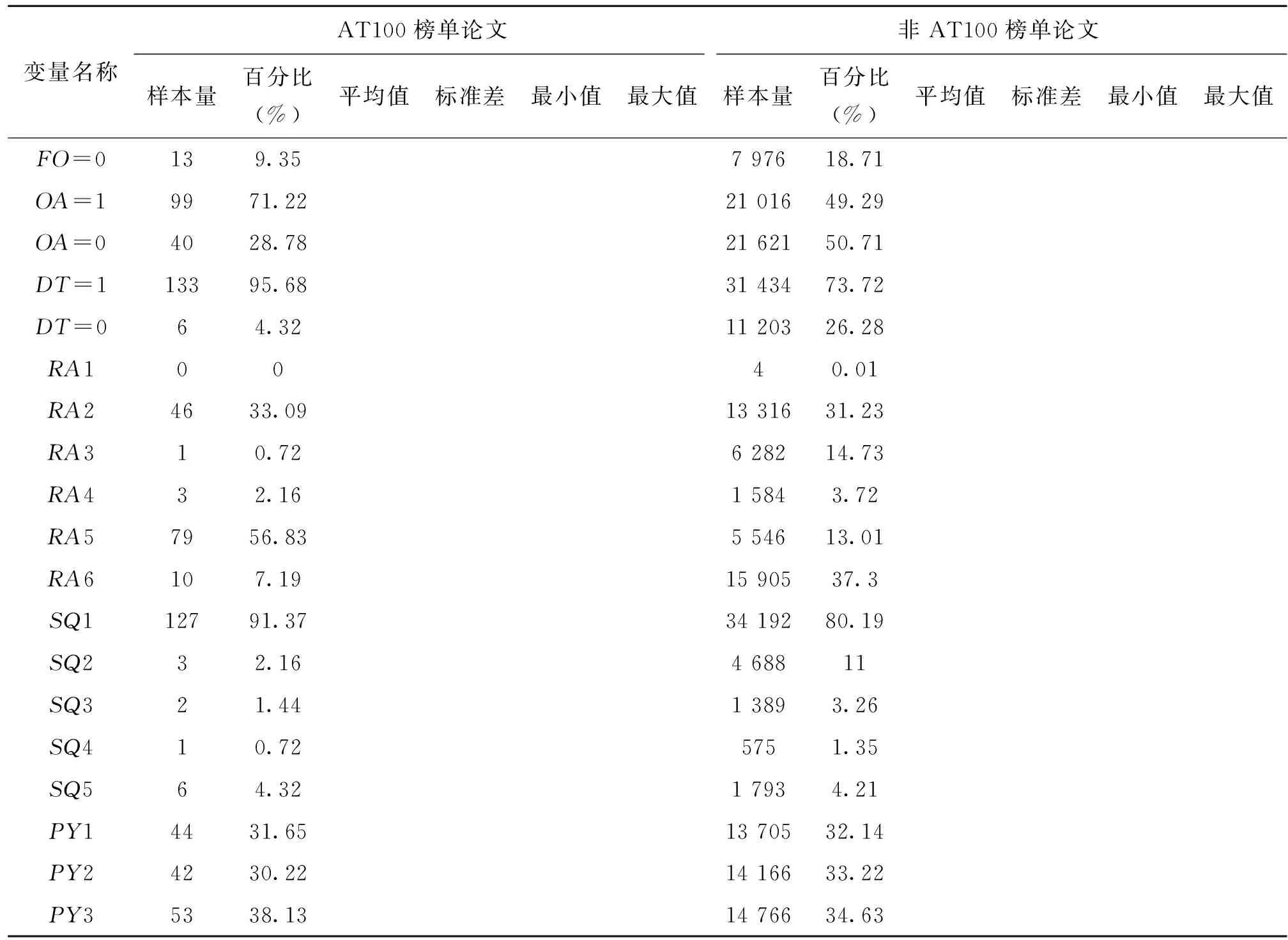
表3(续)
3.1.3 普通论文的AT100榜单与非AT100榜单的描述性统计
表4展示了普通论文AT100榜单与非AT100榜单各变量的描述性统计结果。由表4可得,普通论文AT100榜单组与非AT100榜单组差异性主要集中于被引量、基金资助、开放获取、研究领域及期刊分区等变量。其中,AT100榜单组被引量的平均值是非AT100榜单组的10倍;AT100榜单组84.33%的论文被基金资助,而非AT100榜单组基金资助只占51.43%;开放获取AT100榜单组占比较多,为75.37%,而非AT100榜单论文组只占33%;在研究领域变量中,AT100榜单组占比最高的是应用科学,非AT100榜单组占比最高的是跨学科研究;AT100榜单组91.79%的论文都发表于一区期刊中,而非AT100榜单组论文的期刊分布在4个区,较为均衡。其他变量的差异性较小,不一一赘述。
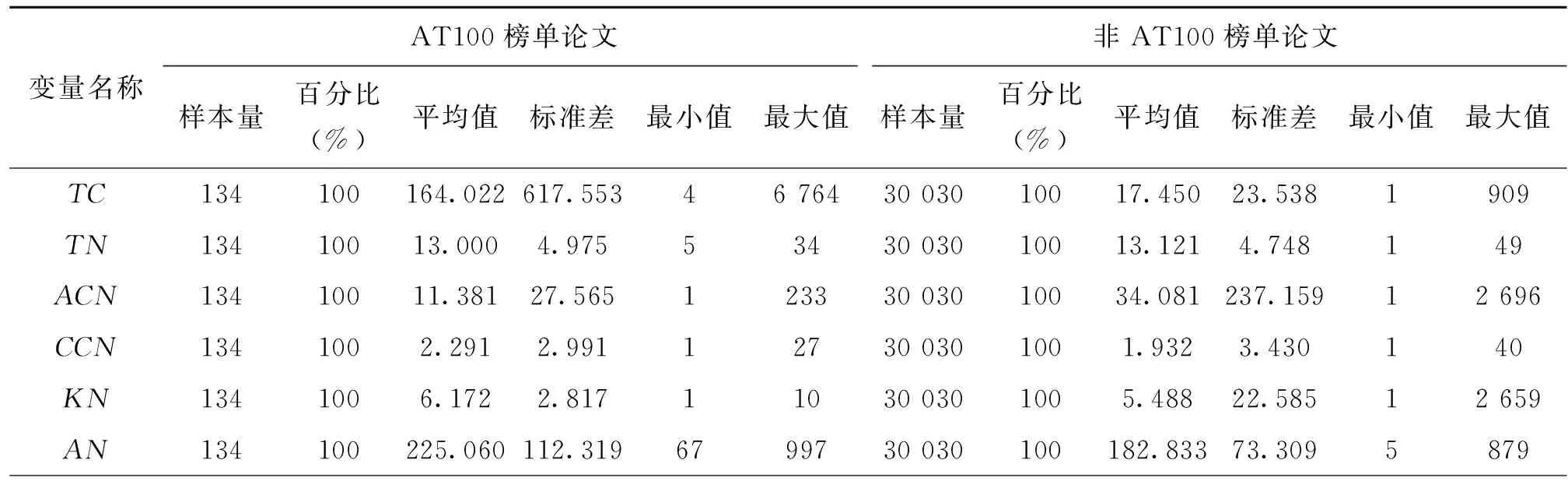
表4 普通论文AT100榜单与非AT100榜单各变量的描述性统计
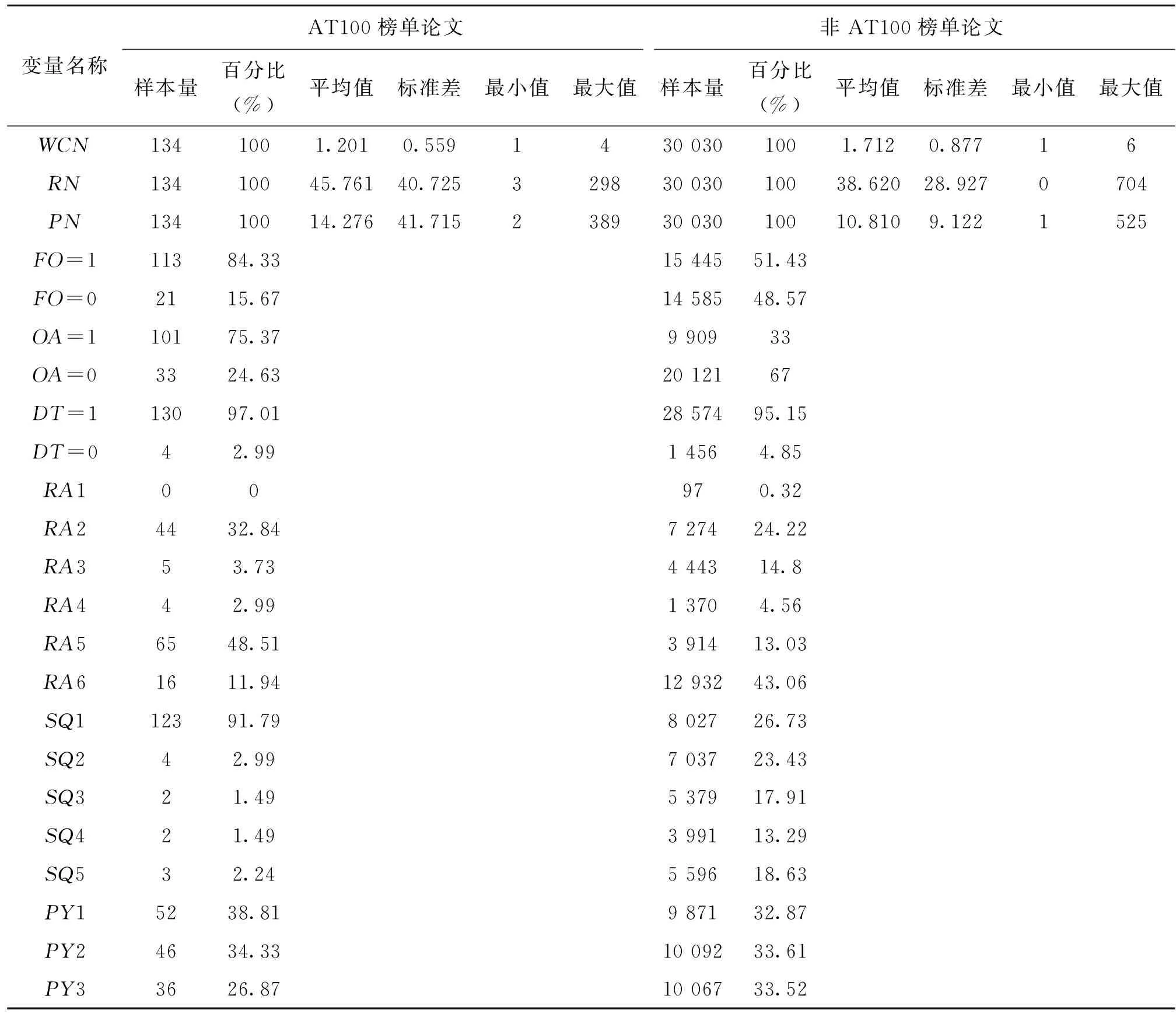
表4(续)
3.2 实证分析结果——基于倾向得分匹配
本文采用倾向得分匹配方法(PSM)尝试探究AT100榜单与论文被引量的因果关系,其中,处理组为AT100榜单论文,控制组则为非AT100榜单的论文。如果实验组中的论文可以在控制组中匹配到一个或多个协变量相同或类似的论文,则论文被引量的差异即认为是AT100榜单带来的平均处理效应(ATT)。为了检验研究数据是否适用于倾向得分匹配及保证论文匹配结果的可靠性,本文需要对匹配后变量的平衡性及共同支撑等进行检验。
3.2.1 平衡性检验
本文构建了高被引论文及普通论文各变量的平衡性检验结果,以检验匹配后结果是否较好地平衡了数据,以K值匹配中的1∶1匹配为例,如表5所示。平衡性检验的标准一般为两点:其一是匹配后的标准化偏差小于10%视为平衡效果较好;其二是匹配后的两组论文的变量无显著性差异,主要通过T检验的P值来表征,若P>0.1,未通过显著性检验,即表明AT100榜单组与非AT100榜单组变量在匹配后无显著性差异。
由表5可看出,大部分高被引论文和普通论文变量的标准化偏差都小于10%(高被引论文组关键词长度、普通论文组标题长度及研究领域为自然科学组除外),可见匹配后数据得到了较好的平衡,匹配效果较好。本文在表5的基础上绘制了高被引论文和普通论文各变量的标准化偏差图,如图1、图2所示,其中横坐标为各变量标准化偏差值,纵坐标为各变量名称。由图1、图2可直观看出,匹配前,变量分布较为零散,大部分变量距离原点较远;而匹配后,大部分变量都围绕在原点附近,可见大部分变量的标准化偏差在匹配后都明显减小,匹配效果较好。而且由表5可得,高被引论文和普通论文所有变量匹配后的P值都较高,即AT100榜单组与非AT100榜单组在匹配后无显著性差异。综上可得,本文高被引论文组和普通论文组平衡性检验效果较好。
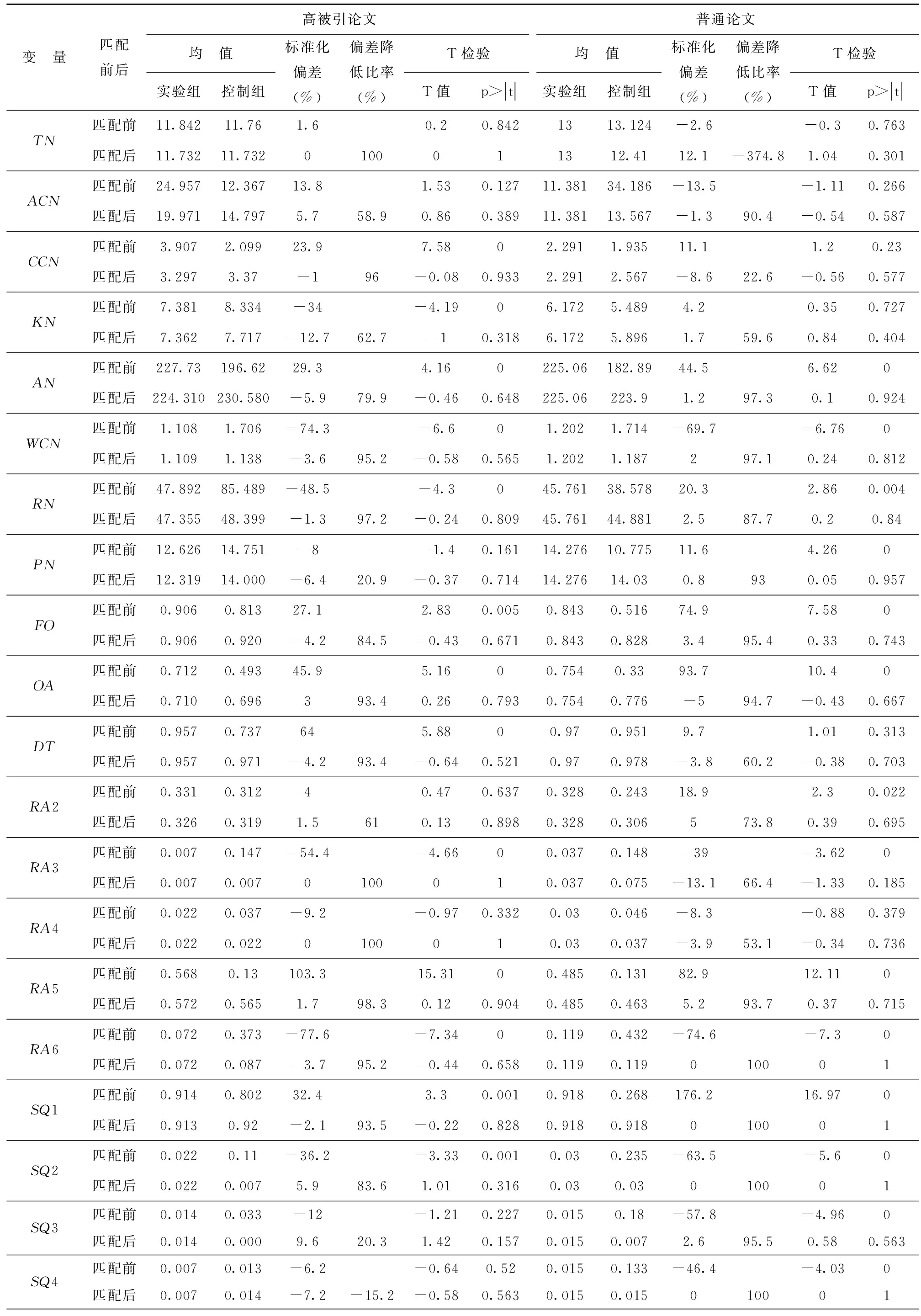
表5 高被引论文及普通论文各变量的平衡性检验结果
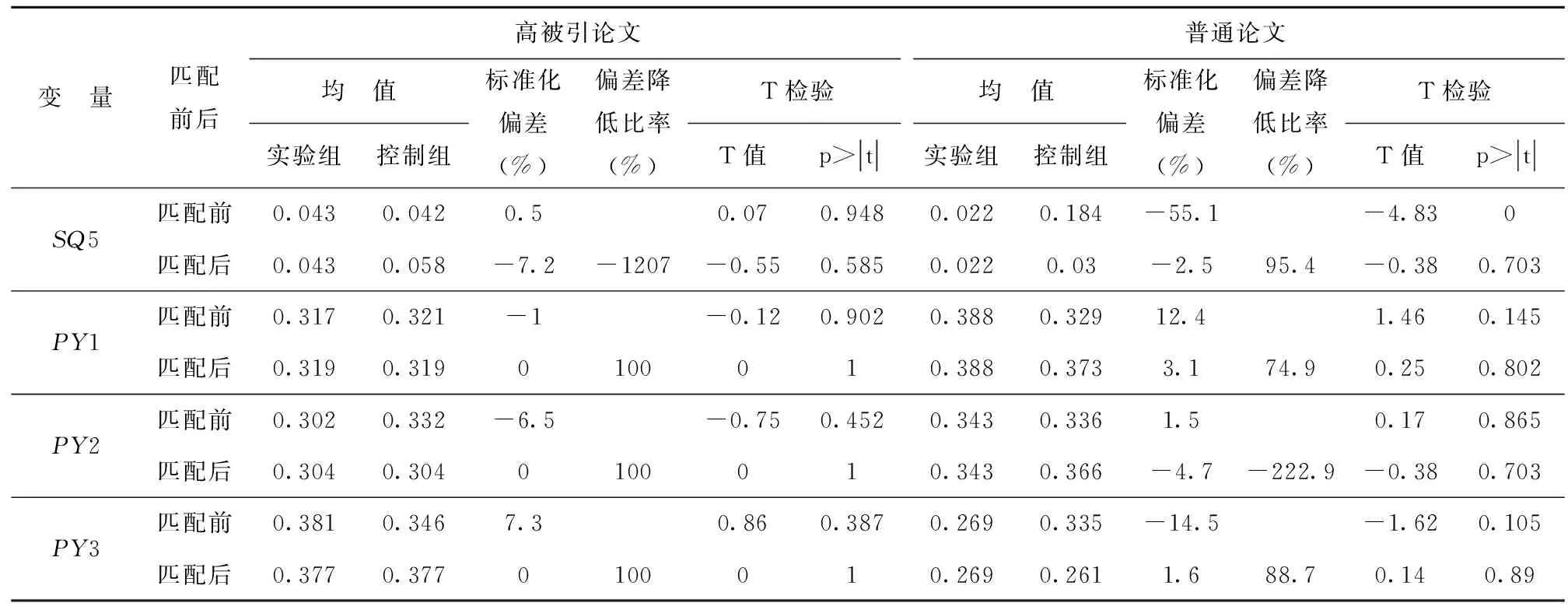
表5(续)
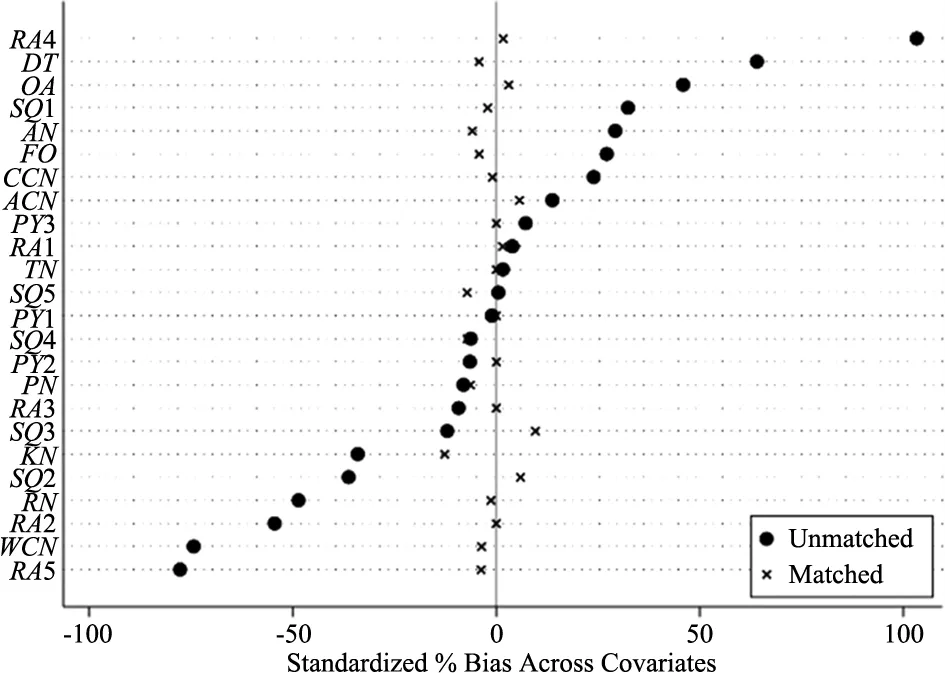
图1 高被引论文各变量的标准化偏差图

图2 普通论文各变量的标准化偏差图
3.2.2 共同支撑性假定
为了显示倾向得分的共同取值范围,本文绘制了匹配得分箱图及匹配后的核密度图,如图3~4及图5~6分别为高被引论文及普通论文倾向得分的共同取值范围箱图和匹配后的核密度图。其中,箱图中横坐标的0值代表控制组,1值代表处理组,纵坐标表示倾向得分;核密度曲线中,虚线表征实验组,实线表征控制组。由匹配得分箱图可看出,高被引论文及普通论文的AT100榜单组与非AT100榜单组的倾向得分有较大的共同取值部分。且由匹配后倾向得分核密度曲线图可看出,高被引论文组和普通论文组匹配后AT100榜单组与非AT100榜单组的核密度曲线几乎重合,曲线重合的下方有较大的共同支撑区域,故而综上可得,高被引论文与普通论文数据满足共同支撑假定。
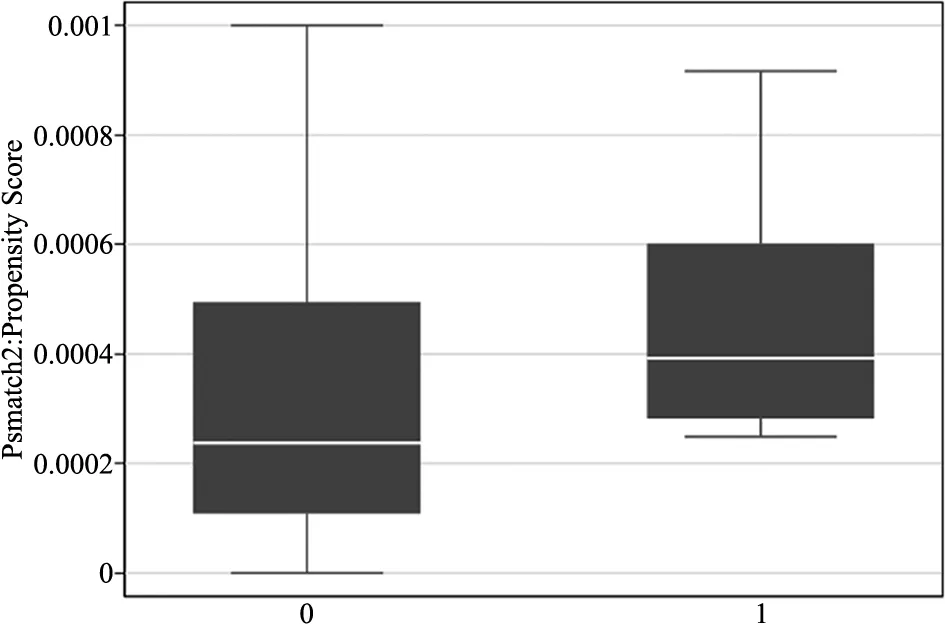
图3 高被引论文倾向得分的共同取值范围箱图
3.2.3 匹配结果估计及稳健性检验
为了保证结果的稳健性,本文采用多种匹配方
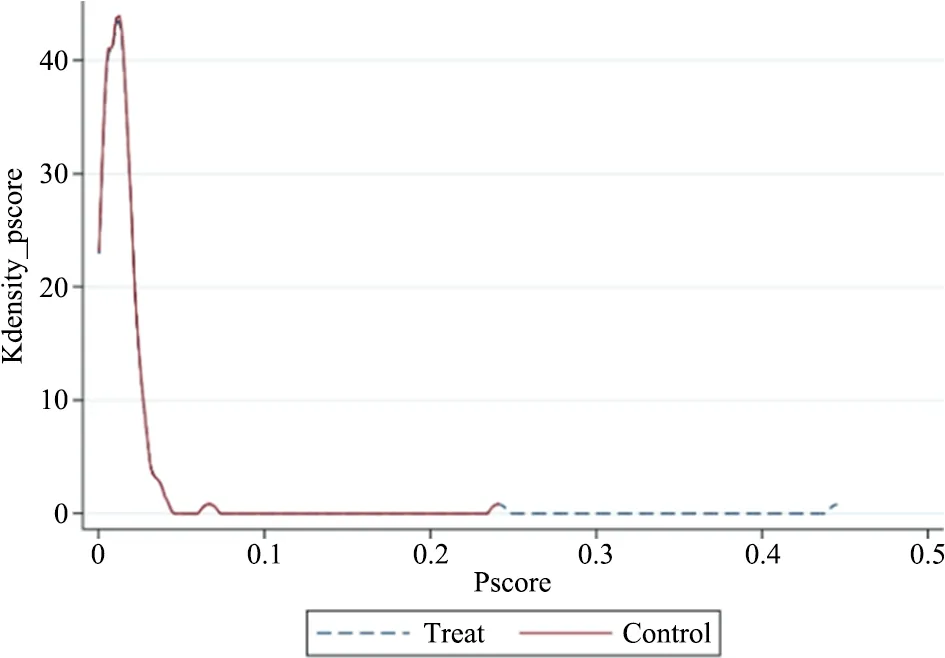
图4 高被引论文倾向得分的核密度曲线(匹配后)
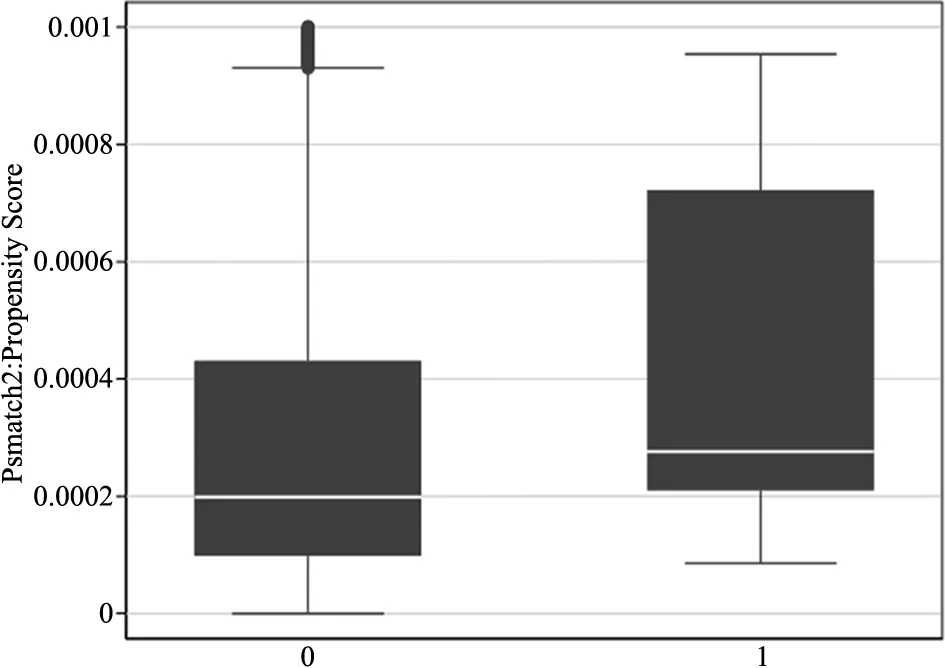
图5 普通论文倾向得分的共同取值范围箱图
法来计算AT100榜单对论文被引量的平均处理效应(ATT值)及其显著性,包括K近邻匹配法(1∶1、1∶2、1∶3以及1∶4)、半径匹配、核匹配以及局部线
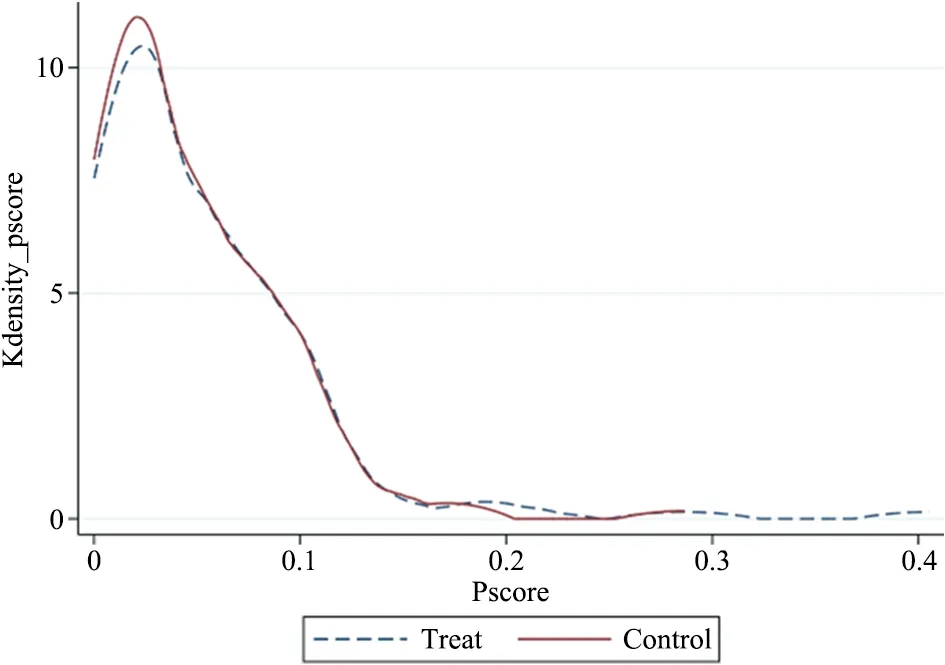
图6 普通论文倾向得分的核密度曲线(匹配后)
性回归匹配,其中,半径匹配与核匹配没有通过平衡性检验,故在结果中去除,最终通过检验的倾向得分匹配结果呈现,如表6所示,模型1和模型2不同匹配方法下的ATT值有细微差别,但总体差别不大,且都通过了显著性检验,可见结果具有较强的稳健性。由模型1可得,AT100榜单对高被引论文的平均处理效应(ATT值)为312.156,可见AT100榜单平均能使高被引论文提高312篇被引量;由模型2可得,AT100榜单对普通论文的平均处理效应为134.069,可见AT100榜单能使普通论文提高134篇被引量。故而可得AT100榜单对高被引论文和普通论文被引量都具有显著的正向促进作用,AT100榜单对高被引论文比普通论文被引量具有更大的正向影响。
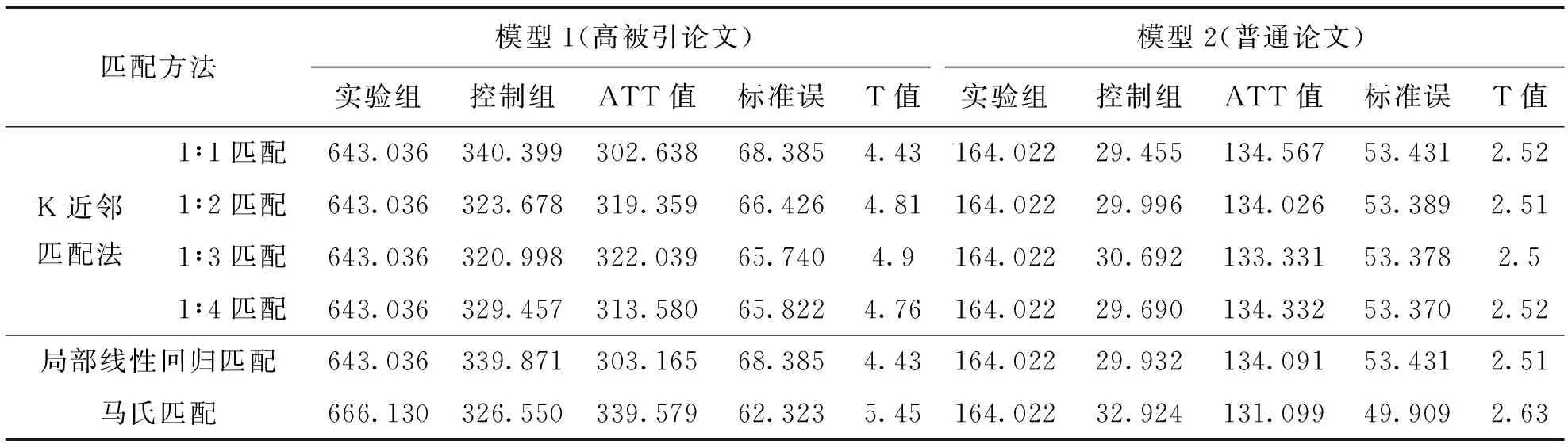
表6 高被引论文与普通论文的倾向得分匹配结果
本文最后使用马氏匹配对上文倾向得分匹配结果进行验证,如表6所示。马氏匹配先于倾向值匹配被提出来,也是一种基于变量之间相似度或距离进行匹配的方法,只是对于相似度或距离的计算方法与倾向得分匹配不同,是一种被广泛应用的匹配方法。由表6可看出,无论是平均处理效应,亦或是显著性,马氏匹配的结果都与倾向得分匹配结果类似,可见倾向得分匹配的结果具有较强的稳健性。
4 研究结论
随着Altmetric指标的兴起,越来越多的研究者关注于Altmetric TOP100论文与其学术影响力的关系研究,本文梳理前人的研究成果,从Altmetric TOP100榜单的视角考察其对论文被引量的因果影响。本文运用2013—2015年Altmetric TOP100论文及WOS数据库的高被引论文、普通论文题录数据,在平衡性检验及共同支撑检验的基础上,综合采用近邻匹配、半径匹配、核匹配以及局部线性回归匹配等匹配方法,在非AT100榜单组寻找与AT100榜单论文相似的匹配对象,进而通过比较AT100榜单组与非AT100榜单组论文被引量的差异来评估AT100榜单对论文被引量影响的净效应,并最终通过马氏匹配来检验结果的稳健性。研究结果表明:
1)高被引论文与普通论文变量值存在较大差异,主要为被引量、基金资助、开放获取、文献类型、研究领域及期刊分区等方面;高被引论文AT100榜单论文与非AT100榜单论文的差异性主要集中于被引量、开放获取、文献类型及研究领域等变量;普通论文组AT100榜单论文与非AT100榜单论文变量的差异性主要集中于被引量、基金资助、开放获取、研究领域及期刊等。
2)AT100榜单论文作为科研领域的“强信号”,极大地增加了论文的可见性,对论文被引量具有显著的正向影响。由上文可得,AT100榜单对高被引论文的平均处理效应为312.156,而AT100榜单对普通论文的平均处理效应为134.069,可见AT100榜单平均能使高被引论文提高312篇被引量,而AT100榜单能使普通论文提高134篇被引量,AT100榜单对高被引论文被引量的影响比普通论文更大。可能是AT100榜单极大地提高了论文的“曝光量”,但是在引用过程中,施引者仍会优先考虑领域的优质论文,故而AT100对高被引论文被引量比普通论文有更大的影响作用,是施引者施引行为的择优过程。
本研究存在一些不足,首先对于普通论文组数据的选择,因为WOS核心合集每年的普通论文数据量较多,无法下载所有普通论文,只能选取部分数据,可能无法涵盖所有普通论文数据信息,故而普通论文得到的平均处理效应可能有些许偏差。其次,本文基于前人研究选取了学术论文被引量的核心影响因素作为本文的协变量,无法穷尽并控制所有可能引起被引量的影响因素,以考察AT100对学术论文被引量的因果关系,所以本文得出的平均处理效应可能会有些许偏差,在以后的研究中,将探寻更多可能影响学术论文被引量的因素,以得出更为严谨的研究结果。
