高维加性Cox 模型的估计
2023-02-07雷馨钰徐嘉璐
雷馨钰,徐嘉璐
(兰州财经大学,甘肃 兰州 730101)
1 绪论
在信息爆炸的时代,高维数据的产生便于研究者从多个维度去分析问题,但同时,传统的回归模型就不能满足高维数据的需要,故近年来,半参数回归模型的产生很好地解决了模型构造问题。Cox 模型是由英国统计学家D.R.Cox 于1972 年提出的一种半参数回归模型[1]。该模型以生存结局和生存时间为因变量,引入基线风险函数,对实际问题中的无规律分布、删失数据等问题可以很好地处理。该模型自问世以来,在医学随访研究中得到广泛的应用,也是迄今生存分析中应用最多的多因素分析方法。
然而,在实践中,通常很少或没有先验信息表明协变量的影响呈线性形式或属于任何其他有限维参数族。因此需要通过使用一类更灵活的非参数模型,例如加性Cox 模型,加性Cox 模型中分量函数的引入显著增加了模型的灵活性,因此,大量学者对加性Cox 模型进行了研究。
Tibshirani(1997)首次提出在Cox 模型中使用Lasso进行变量选择,Fan 和Li(2002a,2002b)提出在Cox模型中使用平滑剪裁绝对偏差(SCAD)惩罚进行变量选择和估计,Huang(1999)利用多项式样条研究了部分线性可加Cox 模型下最大偏似然估计的性质,但是,上述作者仅仅研究了加性模型维数p 固定时的情况。对于稀疏加性Cox 模型,Lemler(2012)考虑了Cox 模型中基线风险函数和回归系数的联合估计,但未考虑由分量函数和基线函数的线性组合引起的近似误。基于高维数据与生存分析模型所具有的特殊性,传统的变量选择方法就不再适用,这是由于传统的变量选择方法不满足变量选择应该具有的准确性、可解释性、稳定性等显著特点。因此需要对加性Cox 模型在高维情况下的变量选择进行系统分析,以便高效处理高维数据下的变量选择问题。
总体上看,在高维数据中,使用变量选择方法来筛选出数据中的重要信息是未来发展的趋势。大量学者基于惩罚思想对有关模型的变量选择进行不断地改进,常见的变量选择的方法有岭回归、Lasso、SCAD、MCP[2]等。但往往有些变量选择方法的“过度压缩”会导致重要信息的损失,从而损失模型估计的精确度。故如何使模型在变量选择后仍保留更多的有用信息也是研究者们大量关注的问题。
传统Lasso 方法对不同系数进行相同程度的加权,造成过度压缩绝对值较大的参数的情况,得到过于稀疏的模型,而且Lasso 方法是在单个变量的基础上对模型进行特征选择,不具备处理具有组特性的数据。Yuan(2006)提出了组Lasso(Group Lasso)方法,组Lasso是Lasso 的扩展,它的不同之处是对一组系数向量添加约束,因此克服了Lasso 方法无法实现从组的水平进行特征选择的这一缺点。组Lasso 在各个领域中都被广泛使用:
在医学方面,Ma(2007)将有监督的组Lasso 方法用于基因选择和模型预测,并通过组Lasso 方法选择集群,从基因簇中找到重要的基因。基于变量选择特征,Kim(2012)将组Lasso 方法用于生存数据的分析中,该方法可以有效地结合临床和基因组协变量,并在实际微阵列中进行了实验。
在机器学习方面,Yeh(2014)将组Lasso 多核学习方法应用于异构特征选择,并证明了在选择紧凑特征子集方面是有效的。在金融风险投资方面,Qi 等(2021)利用非负稀疏组Lasso 方法[3],用于成分股的选择和权重系数的估计。
针对现有文献中存在的问题,本文使用了一类正则化方法,通过对对数偏似然函数施加群组惩罚,并基于一些温和的假设条件可以同时对高维Cox 加性模型进行结构识别,变量选择及其估计。特别地,我们将模型的结构识别和变量选择问题转化为一个对于分量函数的判别问题,通过构建正交B 样条基可以将这些问题参数化,并通过快坐标最优下降法lv(2017)[4]对提出的变量选择方法进行识别。
2 稀疏加性Cox 模型
一般来说,医学中生存分析的研究应用在观察时间与事件发生时间不一致的情况,它将事件发生的结果与观察时间两因素结合起来,研究生存函数与斜变量之间的关系,可以分别对完全、不完全数据进行分析,通常可用生存率、生存曲线等指标来估计生存时间。但当生存时间的分布过于复杂时,简单的计算指标不能满足现实的需要,而Cox 比例风险模型就可以很好地解决上述问题。
Cox 模型不直接考察生存函数与斜变量之间的关系,而是用风险函数作为因变量,将参数与非参数结合,排除混杂因素影响,筛选出影响生存时间的因素。但在Cox 模型中,当引进的斜变量对时间的响应较为敏感时,偏似然函数损失的信息较多。故在本文中对带有时间变量的Cox 模型进行假设。
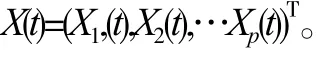
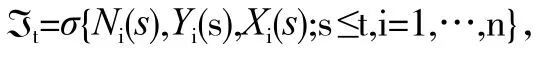
由lv(2017)知稀疏加性Cox 模型如下:
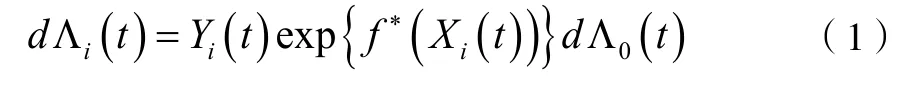
其中,Yi(t)为关于i 的主观时变风险过程,为参数部分,f*(Xi(t))为具有P 维斜变量的真实分量函数,为非参数部分。Λ0(t)为未知的基线累积函数。并且针对稀疏加性cox 模型要满足p≥n。但在实际中关于f(x)的重要协变量相对较少,所以,针对式(1)中的分量函数可以表示为:
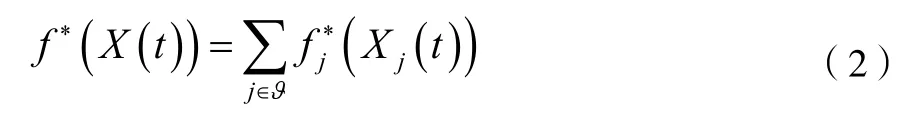
其中,中的元素都为单变量,并且ϑ⊆{1,2,...,p}是基底|ϑ|=d0的子集,满足d0<<p。
3 惩罚对数偏似然函数
本文针对模型,提出主要应用B样条[5]的方法对未知的分量函数进行样条基函数展开,从而进行后续估计。在样条估计中,主要利用样条基函数的线性组合来逼近未知的光滑函数,这种组合可以拟合不同形状或分布的数据,因此,为了使得B 样条估计方法可以对更复杂的模型进行逼近求解,对于合适的基函数的选取也是我们值得关心的问题。
假定Xj(t)在任意t∈[0,T]在区间[a,b]上取值,且j=1,2,…p,假定多项式空间Sn中有K个点,满足a=ξ0<ξ1<…ξK+1=b,则K个点就为多项式空间Sn中的K个节点。用IKq表示为区间[a,b]上的子集,建立IKq=[ξq,ξq+1],q=0,1,…K,其中K满足K=K(n)=nv0<v<1/2 并使得max1≤q≤K+1|ξq-ξq+1|=O(n-v)成立。
此时定义Sn为满足以下条件的多项式样条空间:(1)IKq为Sn的子集,且1≤q≤K;(2)对于ℓ≥2 与0≤ℓ≤ℓ-2,函数s是ℓ 次连续可微的。
由上述可知,在空间Sn上,当1<k<mn,mn=K(n)+l时存在一个B 样条基k使得对于任意fnj∈Sn都存在:
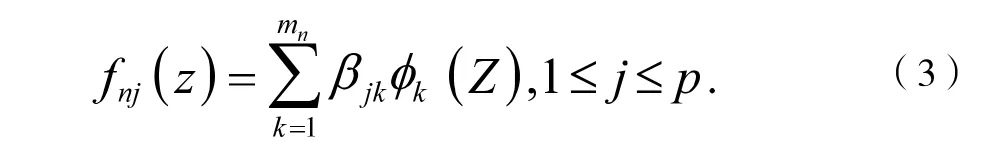
基于光滑性假定,基函数fnj(z)可以逼近Sn,在上述近似下,每个分参数分量都可以表示为样条基函数的线性组合,则通过B 样条可以将模型中未知的分量选择问题变成了线性组合中选择系数组的问题,便于之后的估计。

目标函数:

4 模拟研究
本节对整合后的加性Cox 模型进行蒙特卡洛模拟分析,因高维数据的特殊性,分别考虑当P=10 和P=50时的拟合情况。
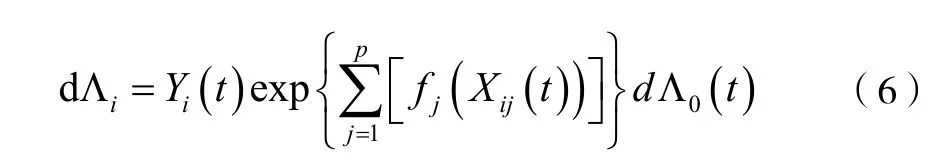
其中,假定在上式中前三个变量当j=1,2,3 时定义为f1(x)=sinx+2,f2(x)=sin(2x)2+12,f3(x)=10(x-2)2,当j=4,…p定义为fj(x)=0,且协变量和残差都满足均匀分布。
情形1:当P=10 时,分别取n=100、200、500。可得表1:
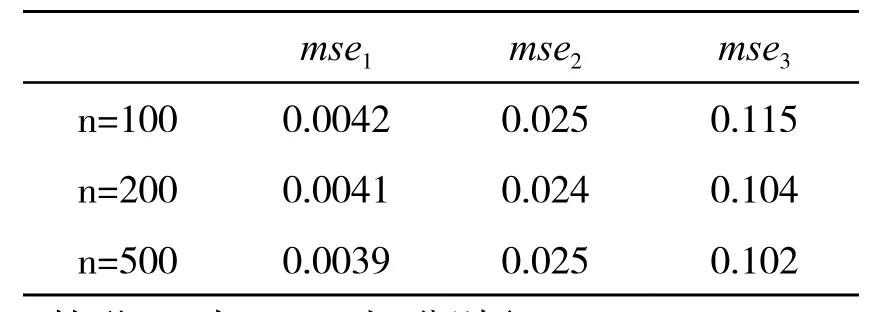
表1
情形2:当P=50 时,分别取n=100、200、500。可得表2:
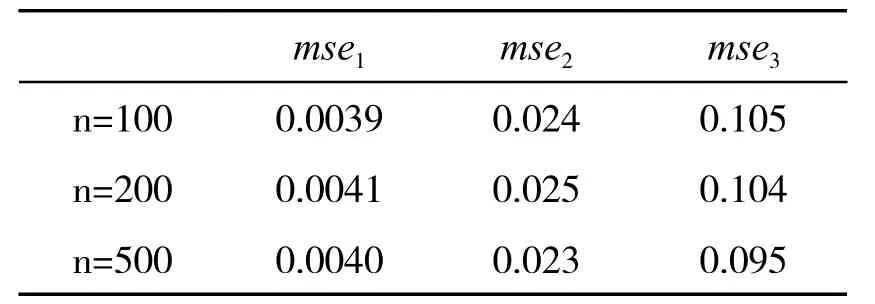
表2
由情形1 和情形2 可知,随着维数增加,误差会增大,但数值普遍较小,可知估计量有良好的性能。
5 总结展望
从大量数据中选择出重要变量对于模拟研究及探寻事物变化的本质有着重要的意义,因此变量选择方法在高维数据中就显得尤为重要。在本文中,考虑加性Cox 模型在高维数据中的情况,通过B 样条曲线拟合模型,将函数中的未知函数用样条基函数展开,结合具有Oracle 性质的组Lasso 惩罚方法,建立了更完善的加性Cox 模型的变量选择过程。后续可考虑在更高维度下的变量选择问题。
