基于Monte-Carlo迭代求解策略的局部社区发现算法
2023-02-03李占利罗香玉罗颖骁
李占利,李 颖,罗香玉,罗颖骁
(西安科技大学 计算机科学与技术学院,西安 710600)
0 引言
人类社会和自然界里许多复杂系统都可以通过网络加以描述,例如社会网络、交通网络、生物网络等[1-2]。一个典型的网络由许多节点与节点之间的连边构成,其中节点代表复杂系统中不同的个体,边代表个体间按照某种规则形成的关系。网络的一个重要属性是社区结构[3-4],Newman 等[5]把社区定义为网络中的若干个内部连接紧密的节点群组,节点与所在群组内的节点连接紧密,与其他群组的节点连接稀疏。这些社区通常表示网络内个体间有意义的拓扑关系[6],实际应用中的社区发现在个性化推荐、信息传播等方面具有重要的意义。
在一些应用场景中,人们只关心特定节点所属的社区[7],因此局部社区发现受到众多研究者的关注。与全局社区发现相比,它更关注局部的网络结构,能够返回更加个性化的社区[8-9]。局部社区发现问题通常定义为:给定某一查询节点,找到其所在的社区,该社区称为目标社区[10]。针对局部社区发现问题,目前已有大量算法,这类算法一般采用基于贪心策略[11]的逐步扩张方式来发现目标社区。初始化时社区仅包含查询节点自身,然后每一步选择一个新的节点加入社区中。在每一步中,都从社区邻接节点集中选择满足某种约束条件且使目标函数最大化的节点。其中约束条件一般要求社区质量单调递增,目标函数一般用来表征候选节点加入后的社区质量或社区邻接节点(称为候选节点集)与社区的紧密程度。在不同的算法中,无论社区质量还是节点与社区间的紧密程度均有不同的定义方式。由于这类算法每一步都是基于贪心策略来选择节点以扩张社区,无法获得整体最优解。当所有候选节点均不能满足社区质量单调递增这一约束条件时,扩张过程结束,未考虑到随着节点后续的多次迭代加入而产生更好的解,算法过早停止迭代而致使查全率较低。
本文摒弃了依据目标函数的最优值来选取节点求得目标局部社区的传统思路,而采取Monte-Carlo 随机策略[12]。赋予候选节点选择概率并基于概率值随机选择节点来扩张社区,从而能够有效避免算法陷入局部最优的不利情况;另外,由于随机选择节点的方式可能引入异质节点,它们的存在会影响局部社区扩张的方向,因此赋予已加入节点淘汰概率并基于概率值随机淘汰节点,从而将局部社区发现的方向导向最佳。
本文的主要工作如下:
1)摒弃了现有局部社区发现算法所采用的基于贪心策略的逐步扩张方式,提出基于Monte-Carlo 迭代求解的新策略。该策略在每轮迭代中随机选择节点加入,并随机淘汰已加入节点,解决了因过早收敛无法获得社区全部节点的问题。
2)提出并实现了一种基于Monte-Carlo 迭代求解策略的局部社区发现算法,该算法在社区扩张阶段根据对目标函数的贡献比例为所有候选节点赋予选择概率;在节点淘汰阶段根据节点间的相似度为已加入节点赋予淘汰概率。
3)在真实网络数据集Karate[13]、Dolphin[14]和Citation[15]上,与局部紧密度扩展(Local Tightness Expansion,LTE)算法[16]、Clauset 算法[17]、加权共同邻居节点(Common Neighbors with Weighted Neighbor Nodes,CNWNN)算法[18]、模糊相似关系(FSR)算法[19]进行对比,实验的结果表明,本文算法性能相较于传统算法有大幅提升。
1 相关工作
目前局部社区发现算法大都采用基于贪心策略的逐步扩张方式来发现目标局部社区,每一步都从候选节点集中选择满足某种约束条件且使目标函数最大化的节点。根据目标函数和约束条件的不同,现有算法可分为四类:基于局部模块度的算法、基于聚类结构的算法、基于PPR(Personalized PageRank)的算法以及基于节点/边的算法。
基于局部模块度的算法利用局部模块度衡量社区质量并设计与之相关的目标函数[17,20-21]。文献[17,20]中均以局部模块度增量为目标函数,每一步都从候选节点集中选取模块度增量值最大的节点加入局部社区,直至局部社区达到预定义的规模;不同的是,文献[20]的约束条件有所不同:要求邻接节点的模块度增量ΔM非负,否则扩张阶段结束,进入剪枝阶段,从当前局部社区中删除使得模块度增加的节点,直至没有节点可被删除为止。
基于聚类结构的算法采用符合特定拓扑结构局部社区作为衡量社区内聚度的衡量指标。常见的局部社区聚类结构包括k-core[6,22-23]、k-truss[24-25]、k-clique[26]。k-core要求社区中的每个节点都至少与该社区的其他k个节点相连,Cui 等[6]提出一种基于k-core 的带阈值约束的社区搜索(Community Search with Threshold constraint,CST)算法,在每一步的扩张中,在搜索空间不大于预设阈值的约束条件下,以候选节点与当前社区内节点的最大关联数为目标函数,选择节点并更新社区内节点的最小度数k直至所有的候选节点均不能使k增大为止。
基于PPR 的算法采用最大化概率的思想来发现局部社区[27-30]。Wu 等[28]首先使用重启随机游走(Random Work with Restart,RWR)算法计算每个节点相较于查询节点的接近度值并以此赋予边权重,然后以最大化社区查询偏置密度为优化目标,得到最终的局部社区。Bain 等[29]首先使用基于多人约束的局部社区发现(Local Community Detection by the Multi-Walker Chain,MWC)求得网络中所有节点的访问概率向量,并据此计算各个节点的分数,然后找到平均得分最大的Top-L个节点,在不超过L的阈值下,以最小化局部社区的阻断率(conductance)为目标,它被用于评估局部社区的紧密程度,值越小表明该局部社区越紧密,因此将具有最小阻断率的子图作为最终的局部社区。
基于节点/边的算法采用候选节点与社区的紧密程度作为目标函数[16,18-19,31-32]。Luo 等[31]提出了最近较大中心性节点(Nearest node with Greater Centrality,NGC)和基于最近较大中心性节点的局部社区发现(Local Community Detection based on NGC Nodes,LCDNN)算法的概念:对于每个节点,其NGC 节点是指中心性最强的最近节点。在该算法中,Nin为当前局部社区C的邻接节点集中那些NGC 节点在C中的节点集合,Nout为邻接节点集中那些NGC 节点不在C中的节点集合,Nin、Nout以及C构成已知的局部网络。在大于当前局部网络平均模糊关系的前提下,以最大化节点与其NGC 节点的模糊关系为目标,从Nin中选取节点加入当前局部社区C。刘井莲等[19]提出一种基于模糊相似关系(Fuzzy Similarity Relation,FSR)的局部社区发现算法,首先利用隶属度函数来衡量节点与社区的紧密程度,然后在保证隶属度大于阈值的前提下,以最大化候选节点与当前局部社区内节点的隶属度为目标,从候选节点集中选择节点加入局部社区中。HqsMLCD(Multiple Local Community Detection via Highquality seed identification)[11]是一种基于高质量种子的局部社区检测算法,首先基于网络嵌入方法找到高质量的种子节点,然后以最大化候选节点的质量分数为目标,从候选集中选取节点直至该局部社区的conductance(conductance指阻断率,用来评估局部社区的紧密程度,值越小表明该局部社区越紧密)不能再变小为止。
2 问题描述
局部社区发现问题描述如下:对于网络G=(V,E),V和E分别为网络中的节点集和边集,给定某一查询节点q(q∈V),找到其所在的社区C。
基于Monte-Carlo 迭代策略求解上述问题时,将网络G中的节点分为三部分:已加入社区的节点集C、C的邻接节点集N和未知节点集U。第i轮迭代开始时,已加入社区的节点集合为Ci-1,Ci-1的邻接节点集为Ni,未知节点集为Ui。图1为网络的局部社区模型示意图:黑色部分代表已加入社区节点,白色部分代表邻接节点,灰色部分代表未知节点。第1轮迭代开始时,C0={q},N1=。在每轮迭代中,按照一定的随机策略从Ni中选择一个节点加入社区,并在必要时按照一定的随机策略从已加入社区中淘汰一个节点。

图1 局部社区模型示意图Fig.1 Shematic diagram of local community model
在按照上述思想求解局部社区时,需要解决以下四个关键问题:1)第i轮迭代中如何确定Ni中每个节点v(v∈Ni)的选择概率PS(v);2)如何判断第i轮迭代是否需要进行节点淘汰;3)若第i轮迭代需要删除节点,如何确定Ci中每个节点p的淘汰概率PD(p);4)如何设置迭代终止条件。
3 本文算法
本文提出了一种基于Monte-Carlo 迭代求解策略的局部社区发现算法,如算法1 所示。Com_Candidates为局部社区C每次发生变动后的点集及其对应社区质量所组成的集合。对于第i轮迭代,根据节点的选择概率PS从Ni中随机选取一个节点Candidate_Node加入至Ci中;同时判断该轮是否需要执行节点的删除操作,若需要,根据节点的淘汰概率PD从Ci中随机选择一个节点Delete_Node删除;重复以上步骤,直至满足迭代终止条件,输出Com_Candidates集合中社区质量最高值对应的点集Result_Com作为局部社区发现的结果。
算法1 基于Monte-Carlo 迭代求解策略的局部社区发现算法。
输入 查询节点q,图G,节点删除条件参数w,迭代终止条件参数h;
输出 查询节点q所在的局部社区Result_Com。

在算法1 中,函数Select_Node()用来计算社区邻接节点集Com_Nb中各个节点的选择概率,并根据选择概率随机选择一个节点(第6)行);函数Cal_Com_Quality()用来计算当前社区的质量(第8)行);函数Judge_Quality()用来判断当前轮次是否需要执行节点的删除操作(第9)行);函数Eliminate_Node()用来计算当前社区点集Current_Com中各个节点的淘汰概率,并根据淘汰概率随机选择一个节点(第10)行);函数Judge_Size()用来判断迭代是否应该终止(第15)行)。
3.1 节点加入阶段的选择策略
局部社区C扩张时,根据其邻接节点集N中各个节点的选择概率随机选择一个节点加入至C中(算法1 Select_Node()函数),这一步的关键是确定N中各节点的选择概率。
选择概率决定了节点被加入到局部社区的可能性大小,选择概率的值越大,则被加入到当前局部社区C的可能性越大。本文根据当前局部社区Ci的邻接节点对目标函数的贡献比例计算选择概率。具体地,以社区紧密度来度量社区质量,并以社区紧密度增益来作为目标函数。其中,社区紧密度[32]通过社区内部相似度与社区外部相似度之比来度量,能够较好地反映社区的结构特性。社区内部相似度是指社区内部节点对的相似度之和,社区外部相似度是指社区内部节点与该社区邻接节点的相似度之和。节点对的相似度用两节点的共同邻居数与其各自度之积的平方根来度量。社区紧密度增益是指邻接节点加入局部社区前产生的社区紧密度差值,在社区紧密度增益的基础上给予候选节点以选择概率,然后根据选择概率随机选取一个节点加入(算法2第4)~6)行):假设第i轮迭代时当前局部社区Ci的邻接候选节点集为Ni,| |Ni表示候选节点的个数,则候选节点vc(vc∈Ni)的选择概率PS(vc)可由式(1)计算得出。在特殊情况下,若邻接节点对目标函数均无贡献,则从邻接节点集中等概率随机选择一个节点加入当前局部社区。

其中:两相连节点(x,y)的相似度sim(x,y)可以通过式(5)计算得出。

其中:N(x)表示节点x的邻接节点集,N(y)表示节点y的邻接节点集。
具体如算法2 所示。
算法2 节点选择函数Select_Node()。

3.2 淘汰轮次i的确定
在算法迭代过程中,为避免随机选择导致扩张方向偏离目标社区,需要在恰当的轮次i执行节点的删除操作。本文根据局部社区C的质量Q(C)变动情况,提出了一种用于确定淘汰轮次i的策略。对于算法1 中的Judge_Quality()函数,在求解目标社区的过程中,记录下其发生的每一次变动及其对应的社区质量值Q(C)。对于已执行过节点选择操作的迭代轮次i,若其相邻前w轮的社区质量值Q与第i轮的社区质量值组成的(w+1)项序列{Qi-w,Qi-w+1,…,Qi-1,Qi}呈非递增状态,则说明当前Ci中可能存在异质节点,此时进行节点的淘汰操作。
3.3 节点淘汰阶段的选择策略
当社区质量连续多次迭代无提升时,需要根据当前社区C内各个节点的淘汰概率随机选择一个节点删除(算法1 Eliminate_Node()函数),这一步的关键是确定C内各节点的淘汰概率。
淘汰概率决定了当前社区内的节点被移除的可能性大小,淘汰概率的值越大,则被移除出当前局部社区C的可能性越大。对于需要执行淘汰操作的轮次i,本文根据Ci内每个候选节点pm与其他节点pn的相似度的总和的倒数计算淘汰概率,然后根据淘汰概率随机选取一个节点删除(算法3第4)~6)行)。对于已执行过节点选择操作的轮次i对应的局部社区集合Ci,候选节点pm的选择概率PD(pm)可由式(6)计算得出。
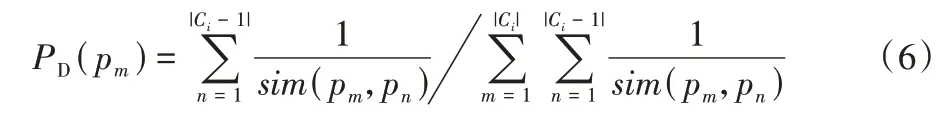
其中:节点相似度sim(pm,pn)可通过式(5)计算得出。
具体如算法3 所示。
算法3 节点删除函数Eliminate_Node()。

3.4 迭代终止条件的设置
相邻两轮迭代后的社区规模大小比较有两种情况:1)后一轮相较前一轮迭代结果的社区规模变大,说明后一轮次只选择节点加入,不满足节点淘汰的条件而未选择节点删除;2)后一轮和前一轮迭代结果的社区规模相同,说明先选择节点加入,因满足节点淘汰条件又选择节点删除。
本文根据局部社区C的规模L(C)变动情况,提出了一种用于设置迭代终止条件的策略。对于算法1 中的Judge_Size()函数,在求解目标局部社区的过程中,统计其每次变动后的社区规模L(C)。若连续h轮迭代的社区规模保持不变,则算法终止迭代。
3.5 时间复杂度分析
算法的时间的耗费主要在计算各轮次的社区邻接节点集中每个节点的社区紧密度增益上。假设网络中所有节点的平均度为d,社区的平均规模为|C|。计算整个算法迭代轮次的时间复杂度为O(|C|),在每一轮迭代中,都需要计算社区邻接节点集中每个候选节点的社区紧密度增益。计算各轮次局部社区邻接节点集平均规模的时间复杂度为O(|C|d),在计算候选节点的紧密度增益时,需要计算社区的内部和外部相似度。其中计算每一对节点相似度的时间复杂度为O(d),计算节点对数量的时间复杂度为O(|C|2d),所以计算各轮次紧密度增益的时间复杂度为O(|C|2d2)。因此,算法的时间复杂度为O(|C|4d3)。
4 实验与结果分析
4.1 实验数据集
为验证所提算法(以下简称Monte-Carlo 算法)的有效性,利用三个真实的公开数据集对传统方法和Monte-Carlo 算法进行比较。数据集描述如下:
1)Karate 数据集[13]。它是由美国大学空手道俱乐部成员之间的关系形成的网络,该网络包含34 个节点和78 条边,其中节点表示俱乐部的成员,边代表成员之间的友谊,网络中包含2 个社区。
2)Dolphin 数据集[14]。它是新西兰海豚之间互动的社交网络,该网络包含62 个节点和159 条边,其中节点表示海豚,边代表海豚之间的频繁互动,网络中包含2 个社区。
3)Citation 数据集[15]。它是关于文献间引用和被引用关系构成的网络。由于该网络是一个不断变动的网络,本文选用某一个时刻的网络作为算法的研究对象。
各数据集的参数如表1 所示。节点度是指和该节点相关联的边的条数,平均度数指网络中所有节点度的平均值。

表1 真实数据集介绍Tab.1 Introduction of real-world datasets
4.2 对比算法与评价指标
本文将所提算法与以下4 个传统局部社区发现算法进行比较。
1)LTE 算法[16]。该算法定义了一种衡量节点对相似程度的指标,并在此基础上提出了使用社区紧密度来衡量社区质量。在保证社区质量的前提下,选择与当前社区内部节点具有最大相似度的节点加入至局部社区以找到给定节点所在的局部社区。
2)Clauset 算法[17]。该算法通过最大化社区模块度R来发现给定节点所在的局部社区。
3)CNWNN 算法[18]。该算法提出共同邻居相似度指标来衡量节点对的相似程度,并在此基础上提出新的局部社区质量度量方式。在保证社区质量的前提下,选择与当前社区嵌入度最大的节点加入至局部社区以找到给定节点所在的局部社区。
4)FSR 算法[19]。该算法利用隶属度函数来衡量节点与社区的紧密程度,在保证隶属度大于阈值的前提下,以最大化候选节点与当前局部社区内节点的隶属度为目标,从候选节点集中选择节点加入局部社区。
本文利用调和均值F-score 值(F1)来衡量算法的性能,如式(7)所示:
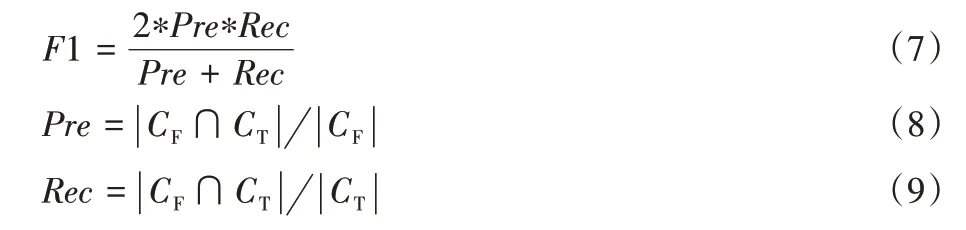
其中:CF是算法检测到的局部社区节点集合;CT是给定查询节点所属的真实社区节点集合;精确率Pre(Precision)表示被正确识别的节点占所有实际被识别节点的比例;召回率Rec(Recall)表示被正确识别的节点占应该被识别出的节点的比例;F1 是召回率和精确率的调和均值。
4.3 实验结果分析
4.3.1 算法性能对比结果
在整个算法的迭代过程中,参数w决定何时触发节点的淘汰机制,设置合适的w能够及时剔除当前局部社区中的异质节点,即控制实验结果的精确率(查准率);参数h决定何时停止算法的迭代,设置合适的h能够给予候选节点更多进入当前局部社区的机会,即控制实验结果的召回率(查全率)。本文以Karate、Dolphin 和Citation 这三个数据集上的实验结果说明算法的有效性。在Karate 数据集上,设置w=1,h=2,实验结果如图2(a)所示;在Dolphin 数据集上,设置w=2,h=3,实验结果如图2(b)所示;在Citation 数据集上,设置w=3,h=4,实验结果如图2(c)所示。

图2 三个数据集上的实验结果对比Fig.2 Comparison of experimental results on three datasets
图2 的实验结果表明,LTE、CNWNN、Clauset、FSR 和Monte-Carlo 算法在三个数据集上的平均F-score 值分别为43.58%、59.02%、55.67%、50.82%和76.33%,相较于其他4种对比算法,Monte-Carlo 算法的平均F-score 值分别提升了32.75、17.31、20.66 和25.51 个百分点,具有最高的精度(即F-score 指标);而相较于其他算法,Monte-Carlo 算法在Karate和Dolphin 数据集上也表现出最高的查全性(即Recall指标)。
4.3.2 查询节点位置对算法性能的影响
为了直观验证Monte-Carlo 算法在解决查询节点位置敏感问题方面的有效性,以LTE 算法和Monte-Carlo 算法为例,验证查询节点分别为core 节点、boundary 节点和inter 节点时算法的执行结果。其中:core 节点是网络中位于社区核心区域的节点;boundary 节点是网络中位于社区边缘的节点,且其度数较小;inter 节点是位于多个社区交界处的节点。以Karate 数据集为例,其真实结构如图3 所示。其中灰色节点和白色节点分别形成两个不同的社区。
当查询节点位置不同时,LTE 算法与Monte-Carlo 算法的执行情况如图4 所示。其中,图4(a)为LTE 算法发现的局部社区,图4(b)为Monte-Carlo 算法发现的局部社区(灰色节点为算法的执行结果)。

图4 不同查询节点位置的算法表现Fig.4 Algorithm performance with different query node locations
图3~4 和实验结果表明,无论查询节点位于何处,Monte-Carlo 算法都能返回较为完整的局部社区。特别是当查询节点为boundary 节点(12 号节点)或inter 节点(29 号节点)时,Monte-Carlo 算法都可以检测到真实局部社区中几乎所有的节点;而对于core 节点(34 号节点),Monte-Carlo 算法的性能提升则较为受限。

图3 Karate数据集中的真实社区结构Fig.3 Real community structure in Karate dataset
5 结语
本文提出了一种基于Monte-Carlo 策略迭代求解局部社区的算法。在社区扩张阶段,为每个社区邻接候选节点赋予选择概率,并据此概率随机选取一个节点加入局部社区;当社区质量连续多次迭代未能提升时,为已加入目标社区的每个节点赋予淘汰概率,并据此概率随机删除一个节点;以上过程迭代执行,直至社区规模连续多次不变。与传统方法相比,该方法给予了各候选节点被选择的可能性,能有效避免算法陷入局部最优而过早收敛的问题,保证了目标局部社区结构的完整性。在真实数据集上的实验结果表明,所提算法的性能相较传统方法有大幅度提升,但相关参数的设定对算法性能的影响还有待进一步研究。
