考虑多粒度反馈的多轮对话强化学习推荐算法
2023-02-03姚华勇叶东毅陈昭炯
姚华勇,叶东毅,陈昭炯
(福州大学 计算机与大数据学院,福州 350108)
0 引言
随着互联网快速发展,网上购物成为了当今主流的一种购物方式,但海量的商品种类和款式带来了信息爆炸和信息过载的问题,用户难以在纷繁多样的商品中作出选择,推荐系统[1]应运而生。推荐系统致力于为用户提供个性化推荐,提升网购效率,实现用户与商家双赢。随着技术更迭,推荐系统经历了从静态推荐系统到与用户交互的动态对话推荐系统的发展过程。
静态推荐系统通过收集和分析历史数据,挖掘用户与用户、用户与商品间的内在关联,实现个性化推荐,例如协同过滤[2]推荐方法、基于内容的推荐方法[3]。静态推荐系统主要存在两方面局限:1)在缺少新用户行为数据的情况下,系统将面临冷启动这一问题。例如,电影推荐系统刚构建完成时,由于系统中没有任何的用户信息,系统难以为每位新用户推荐他们喜欢的影片,而对于新上映的电影,系统也难以将其准确地推荐给需要的用户。2)用户选购商品时,最终的选择会因商品展示的顺序和方式、所处环境以及周围事物发生改变[4],静态推荐系统无法及时对变化的用户需求作出响应,导致推荐效果不理想。为克服静态推荐系统的不足,学者提出通过与用户交互以捕获用户变化的对话推荐系统。
对话推荐系统[5-8]是支持用户与系统进行多轮对话并推荐相关目标(商品、歌曲、酒店、餐厅等)的系统,挖掘用户实时偏好是其关键,也是难点。目前,多数对话推荐系统在与用户对话过程中引入商品属性信息(商品的颜色、款式、材质等)以挖掘用户实时偏好,并以限制用户应答自由度的方式(如使用多值应答策略)对用户进行商品属性的询问。这种询问方式相较于将注意力更多集中在自然文本生成的对话推荐系统[9-11],获取用户信息的效率更高,能够更全面地挖掘用户实时偏好。例如,Christakopoulou 等[10]基于贪心思想,在每轮对话后都进行商品推荐,直到用户接受商品,与传统方法相比,该方法提升了推荐的成功率,但是频繁的推荐降低了用户的交互体验感。Dhingra 等[12]基于最大熵思想,将对话轮数固定为round,在前round-1 轮选取熵最大的属性作为询问属性,并在第round 轮推荐商品。该方法对商品属性的利用进行了思考,但固定了对话轮数,缺乏灵活性。在之后的研究中,Sun 等[13]针对挖掘用户偏好这一问题,提出对话推荐模型(Coversational Recommendation Model,CRM),使用决策网络生成每轮询问的问题,与最大熵算法相比,CRM 在已获得足够多的信息后主动为用户推荐,提高了灵活性。Lei 等[14]基于CRM 提出EAR(Estimation-Action-Reflection)系统。EAR 将询问的商品属性看作多分类任务的标签,以{用户,历史偏好属性}元组作为预训练数据训练决策网络,提高用户历史偏好属性被选择的概率,在预训练完成后,系统根据与用户在线交互获取的奖励信息,基于策略梯度(policy gradient)优化商品属性的权重。该方法在推荐成功率以及推荐效率(平均推荐成功所需的对话轮数更少)这两方面性能均有所提高,但存在同一商品属性反复询问等问题。
针对上述方法存在的不足,本文就如何利用用户反馈信息使决策网络准确挖掘用户偏好以提升推荐准确率展开研究。一方面,为了解决何时推荐、何时询问这一问题并缩短对话轮数,引入强化学习中适用于对话推荐场景等拥有多种状态(用户状态、对话状态等)以及离散系统动作的DQN(Deep Q-Network)[15-16]算法,通过用户与系统交互中的反馈信息(奖励信号)学习最优动作-价值函数,帮助系统作出恰当的选择;另一方面,为了较为准确地挖掘用户实时偏好信息,与以往工作不同,本文提出多粒度反馈模型,同时分析用户对商品以及商品属性的反馈信息,并根据多粒度反馈信息推理用户购买商品的原因。实验结果表明本文算法通过用户的多粒度反馈信息能够较为准确地挖掘用户的偏好,在缩短对话轮数的同时大幅提升推荐成功率。
1 本文算法
1.1 本文算法思想
本文算法的主要流程如图1 所示。首先根据用户历史交互信息生成用户、商品和商品属性的初始特征;然后计算观测状态向量并将其作为决策模型的输入,若当前决策模型的决策为推荐商品,则计算用户-商品评分生成推荐商品,推荐成功系统自动退出,推荐失败则收集用户的反馈信息;若当前决策模型的决策为询问属性,则计算用户-属性亲和度生成询问的属性,用户接受属性则继续推荐,用户拒绝属性则收集用户的反馈信息;最后根据用户的多粒度反馈信息更新用户、商品以及商品属性特征,为下一轮对话做准备。

图1 本文算法流程Fig.1 Flowchart of the proposed algorithm
1.2 基于DQN的决策模型
以往工作将何时推荐/询问以及询问什么这两类问题进行糅杂,将决策模型看作以商品属性作为输出的多分类任务,直接在决策模型中输出询问的属性以表示当前询问操作,在商品属性数量为千级甚至万级的情况下,模型表现不佳。为了更好地解决这一问题,本文在决策网络中引入无模型(model-free)的DQN 算法,将决策的输出动作简化为推荐动作和询问动作,以解决何时推荐、何时询问这一问题。
在多轮对话场景下,设智能体(系统)与环境(用户)在每轮交互中通过环境获得观测状态向量s并选择最优动作以获取最大奖励,如文献[14],本文在决策网络中设定了suser、sitems、sconver和sattribute共4 种状态向量。suser为用户状态向量,根据用户历史交互记录训练生成,用于刻画用户在对话中的状态;sitems为商品状态向量,表示系统当前可选的候选商品数;sconver为对话状态向量,记录系统与用户交互的过程,询问属性成功用1 表示,询问属性失败用-1 表示,推荐成功用2 表示,推荐失败用-2 表示,超出最大对话论数用0 表示;sattribute为商品属性选择状态向量,系统根据用户对商品属性的反馈信息生成属性选择状态向量,使系统明确当前商品属性的选择状况以及用户对不同属性的偏好程度,帮助系统作出恰当的决策。本文将以上状态组合拼接,以找到最适合的状态组合作为决策网络的最终输入(观测状态向量),在2.4 节展示单个状态以及状态组合的效果。
DQN 作为一种基于价值(value-based)的强化学习方法,期望智能体在与环境的互动中所累积的奖励最大化。本文针对多轮对话推荐场景对智能体获得的奖惩rt进行设定(表1),设未来每一步奖励的折扣因子为γ,截至T时刻,智能体所获得的总奖励为:

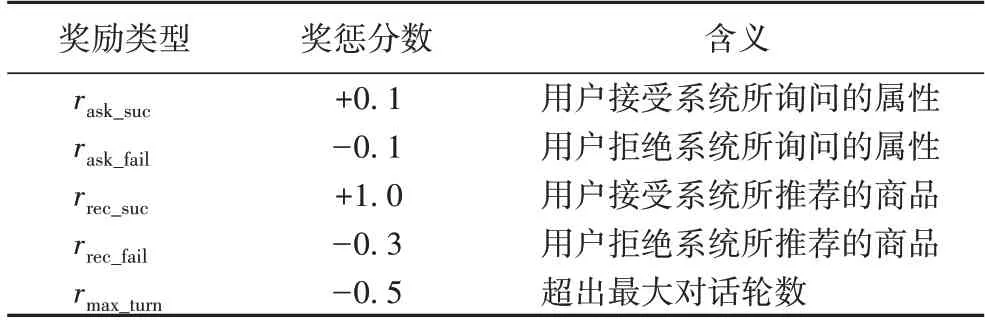
表1 决策网络中的奖励设定Tab.1 Reward setting of decision-making network
本文在决策模型中(图2)以用户组合状态向量作为输入,动作的价值(action value)作为输出,使用两层的全连接神经网络(Fully Convolutional Network,FCN)学习最优动作-价值函数。决策网络的输出单元为推荐动作和询问动作。最优动作-价值函数Q*(s,a)表示在t时刻下,观测到状态s,采取动作a,在所有可能的策略π下所能获得的最大期望回报,根据贝尔曼方程转化为如下形式:
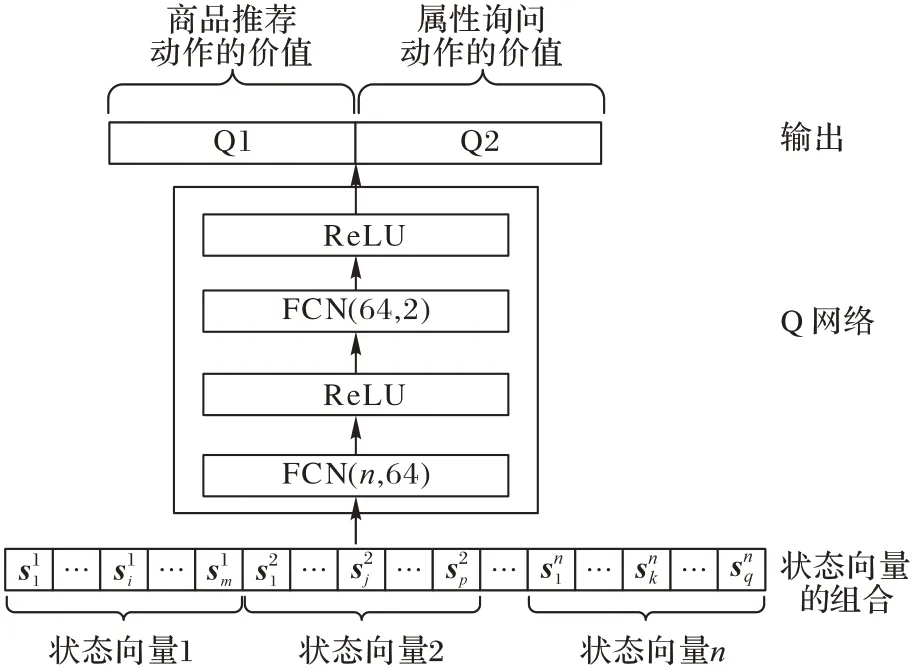
图2 决策模型结构Fig.2 Structure of decision model
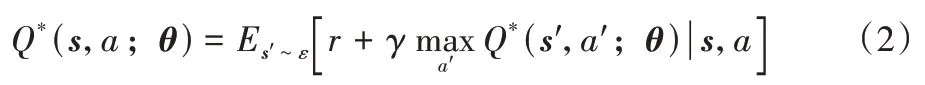
其中:Q*是Q 网络近似的最优动作价值函数,也是决策网络的核心;θ为Q 网络隐藏层中的权值和偏置;r为当前获得的观测状态为s且采取动作a时所获得的奖励;ε表示所有状态的集合;s′表示下一观测状态。
DQN 属于无模型的强化学习方法,需要对数据进行采样。本文使用时序差分(Temporal Difference,TD)对模型采样,在每一时间步(每一次交互)更新模型,相较于蒙特卡洛方法(需要完整的对话过程)更适合于对话推荐场景。模型的损失函数如下:

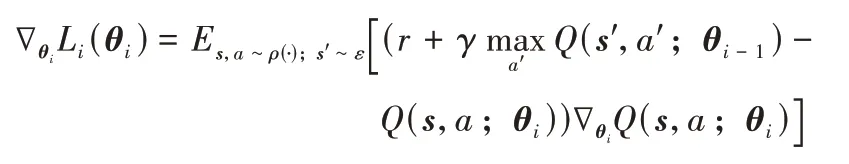
并通过随机梯度下降(Stochastic Gradient Descent,SGD)方法优化模型。
1.3 多粒度反馈模型
为动态地挖掘用户隐藏的偏好信息,更好地了解用户需求,同时解决推荐什么、询问什么这一问题,本文提出多粒度反馈模型,模型利用“商品”和“商品属性”粒度的用户反馈信息在每次交互后动态地更新用户、商品和商品属性特征,在利用商品反馈信息分辨用户心仪商品的同时,进一步分析用户对更细粒度的商品属性的反馈信息,分析用户购买商品的内在原因。

其中:u,c,ai分别为用户、商品和商品属性i的特征向量表示;uTc表示用户对商品的喜爱程度,将用户已接受的商品属性与目标商品作内积运算,表示用户偏好属性集与商品的契合程度,两项之和表示在考虑用户实时偏好的情况下用户对商品的综合评分。
用户-属性亲和度表示在已知用户实时偏好属性集Au的情况下,用户对其他商品属性的亲近程度。例如某用户的偏好属性集中有“周杰伦”,那么该用户对“音乐”这一属性的亲近程度也应该较高。用户-属性亲和度表示如下:
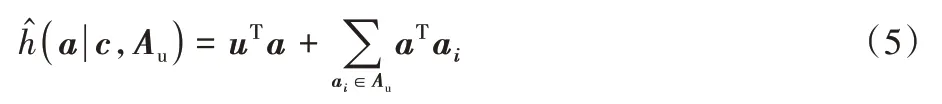
其中:uTa表示用户对商品属性的评分,将用户已接受的商品属性集与目标属性作内积运算,表示用户已接受商品集合中每个商品属性与a向量所对应商品属性的亲近程度,两者之和表示在考虑用户实时偏好的情况下,对a向量所对应属性的评分。
本文使用贝叶斯个性化排序(Bayesian Personalized Ranking,BPR)[17]优化反馈模型。为了有效区分用户拒绝的商品与待推荐商品,期望用户对拒绝商品的评分尽可能低,对待推荐商品的评分尽可能高,将商品损失Litem定义为:

同样地,为了有效区分用户拒绝商品属性与待询问商品属性,期望用户对于拒绝商品属性的亲和度尽可能低,对于待询问商品属性亲和度尽可能高,属性损失Lattribute定义为:

本文使用梯度下降法求解优化函数,最小化L以区分用户拒绝的商品集和用户拒绝商品属性集。在每次交互后,用户的特征表示根据两种粒度的反馈信息在动态地变化,即系统对用户有了更进一步的了解,因此在下一轮推荐或询问时,能够选择更加符合用户偏好的商品和商品属性,即以迭代的方式动态学习用户的购买偏好。
1.4 算法流程
本文算法流程如下。
输入UI表示用户交互记录集,以成对形式表示,例如(bob,cake);Q表示初始化动作-价值网络;D表示初始化经验回放存储器(Replay buffer);M表示最大迭代次数;N表示最大对话轮数;thr∈(0,1):阈值;randomNum∈(0,1)表示随机值;r表示奖励;
输出 更新后的动作-价值网络Q。

特别要说明的是,决策模型(1.2 节)根据收集的多粒度反馈信息获得相应的奖励,同时多粒度反馈模型(1.3 节)根据收集的多粒度反馈信息挖掘用户的实时偏好,即决策模型和多粒度反馈模型在得到用户反馈信息后根据对应的损失函数同时进行参数的更新。
在本文算法中,决策模块解决何时推荐、何时询问这一问题,多粒度反馈模型根据商品评分(式(4))和用户-属性亲和度(式(5))解决询问什么商品属性、推荐什么商品的问题,并根据用户的多粒度反馈信息(接受/拒绝商品属性、拒绝商品)对用户特征等在线更新。当用户接受系统推荐的商品时,根据用户在对话中的反馈信息以推理用户购买该商品的原因。例如,用户在音乐对话推荐场景下接受了属性“周杰伦”和“流行音乐”,拒绝了属性“摇滚”和“乡村”,最后接受了歌曲“稻香”。由整个对话过程,系统推测用户并不喜欢“摇滚”和“乡村”类型的音乐,而是因为喜欢“周杰伦”并且爱听“流行音乐”才接受了歌曲“稻香”。
2 实验与结果分析
2.1 数据集
本文使用2 个真实世界数据集对提出的算法进行验证。Last.fm 是关于用户听歌序列的数据集,数据集中包含每个用户的ID、最受他们欢迎的艺术家的列表、音乐类型以及播放次数。Yelp 是美国著名商户点评网站,其数据集包含了餐馆、购物、酒店等多领域的数据。为了降低稀疏性,本文删除了交互次数少于10 的记录,经过清洗的数据信息如表2 所示。Yelp 数据集中的属性数目(590 个)较多,对其进行二级分类(例如父属性“衣服”的子属性有:“长袖”“T 恤”“衬衫”等)。系统在交互过程中询问父属性,并罗列子属性供用户选择。系统采用多值问答策略收集用户的商品属性反馈。在Last.fm 数据集中属性数为33,系统在交互过程中只询问单个属性,用户进行二值应答(喜欢/拒绝该属性)。

表2 数据集介绍Tab.2 Introduction of datasets
2.2 参数设置
本节介绍模型相关超参数等的设定。本文算法利用Pytorch 深度学习框架实现,在显存为12 GB 的NVIDIA GPU上进行模型训练。决策模型使用了n个输入、m个输出的双隐层全连接网络学习动作价值函数,n为观测状态向量的维度,m为决策网络的动作总数(询问属性或推荐商品),网络结构中隐藏层单元为64,折扣因子(discount factor)为0.995,使用Adam(Adaptive moment estimation)优化器[18]优化模型,批大小设置为128。系统动作获得的奖惩如表1 所示。在多粒度反馈模型中,商品损失优化的学习率λitem设置为0.01,属性损失优化的学习率λattribute设置为0.001,归一化项的权重衰减系数统一设置为0.005。
2.3 基线算法
本文选择以下算法作为基线:
绝对贪心(Absolute Greedy,AG)算法[10]:该算法根据贪心原则,在每轮对话中选择评分最高的k个商品进行推荐。
最大熵(Max Entropy,ME)算法[12]:该算法根据最大熵理论,基于一定规则进行商品推荐和属性询问,其中询问部分选择熵最大的商品属性。
CRM[13]:该算法引入深度强化学习网络帮助系统作出恰当的决策动作,进行多次询问操作,一次推荐操作。
EAR[14]:EAR 设计“估计-动作-反射”的三阶段框架以解决对话推荐问题。
SCPR(Simple Conversational Path Reasoning)[19]:该算法根据历史交互记录构建图,在决策网络作出决策后,根据图中当前用户节点所关联的节点,进行推荐和询问操作。
2.4 实验结果对比分析
本文分别选择5 轮、10 轮以及15 轮作为最长对话轮数进行测试。定义指示函数I(ai)(式(9)),ai为样本i推荐成功时的对话总轮数。算法的评价指标为:SR@k(Success Rate)表示在k轮内,系统在测试集上的推荐成功率;AT@k(Average Turn)表示k轮数内推荐成功的平均轮次,具体计算方式见式(10)~(11)。
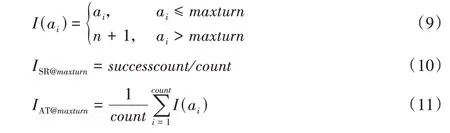
其中:successcount为测试集中推荐成功的总数;count为测试集样本总数。本文算法期望在尽可能少的轮数内为用户成功推荐商品,平均轮数反映了算法在推荐过程中推荐的精准程度,推荐成功所经过的轮数越短,系统对用户的刻画越准确。
由表3 可知,本文算法在Yelp 数据集上的表现优于Last.fm 数据集。随着最大对话轮数的增加,Last.fm 数据集上本文算法的推荐成功率SR 与Yelp 数据集相比,差距不断减小,由5 轮中的48.9 个百分点降低至15 轮的28.5 个百分点;而推荐成功的平均轮数AT 正好相反,由5 轮相差1.412提高至15 轮相差8.086。造成这种现象的原因有两个:1)由于对话轮数的增加,系统能够获取更多与用户相关的信息和偏好,提升推荐成功率,缩小了两个数据集之间推荐成功率的差距;2)Yelp 数据集上用户与商品的交互次数和属性数量都远大于Last.fm 数据集(见表2),与Last.fm 数据集相比,在每轮对话中能够询问多个属性,获得更多的用户信息,因此推荐成功所需的平均轮数更少。
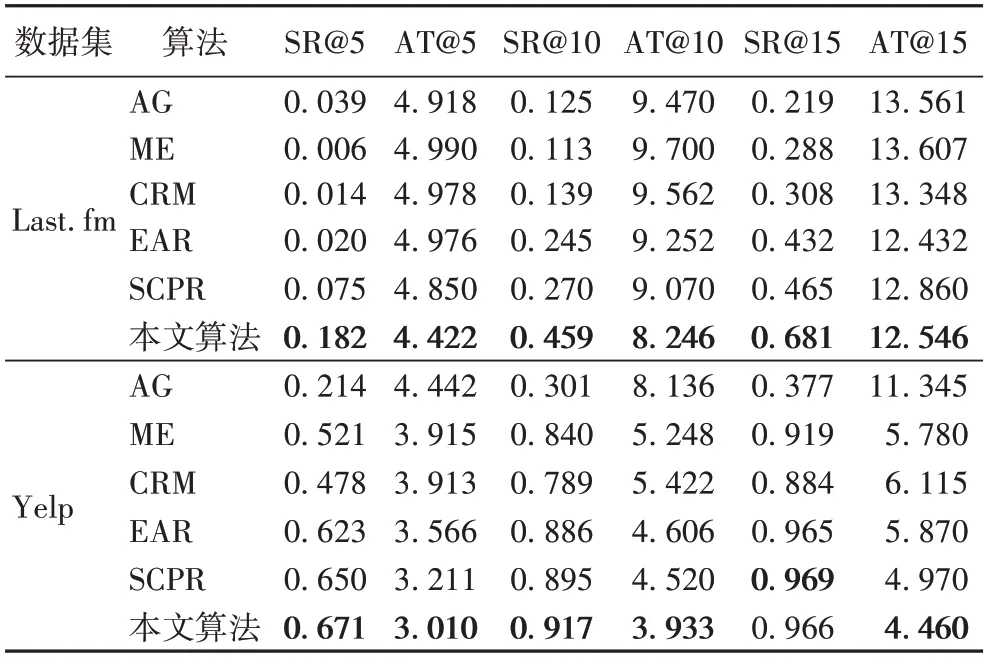
表3 不同算法的比较结果Tab.3 Comparison results of different algorithms
绝对贪心算法、最大熵算法和CRM 这三类算法并未考虑用户的反馈信息,因此难以捕获用户的偏好,在两个数据集上的表现较差;EAR 考虑到了商品粒度的反馈信息,但是忽略了用户对商品属性粒度的反馈信息;SCPR 根据用户历史记录构建静态图,捕获用户、商品和商品属性三者的关系,在决策时根据当前用户节点所连接的邻居节点选择推荐商品和询问属性,在对话轮数较长时相较于其他对比算法有一定提升。本文算法考虑多粒度的用户反馈信息,相较于其他算法能够更加清晰地把握用户购买商品的原因,从实验结果来看,与不考虑反馈信息或只考虑单粒度反馈信息的算法相比,本文算法有一定的优势。
与对话路径推理(SCPR)算法相比,在Last.fm 数据集上,算法在SR@5、SR@10 和SR@15 指标上分别提升了142.7%、70%和86.4%,在AT@5、AT@10 和AT@15 指标上分别缩短了0.428 轮、0.824 轮和0.314 轮;在Yelp 真实数据集上,算法在SR@5 和SR@10 指标上分别提升了3.2% 和2.5%,在AT@5、AT@10 和AT@15 指标上缩短了0.201 轮、0.578 轮和0.51 轮。针对对话轮数较少时成功率有一定提升的现象,可能是本文算法考虑了多粒度的用户反馈信息,不仅考虑用户对于商品的反馈信息,而且考虑更加细致的用户对于商品属性的反馈信息。这使本文算法在前5 轮中,能够捕获到更加精确的用户实时偏好,并且询问的属性更加符合用户需求,从而在较少对话轮次下能够超越其他算法。本文算法的推荐效果在多数情况下,相较于其他算法取得了一定提升,原因是在每一轮交互后,模型根据用户的多粒度反馈信息对用户特征进行在线更新,以迭代的方式不断学习用户的购买偏好,在区分用户心仪商品的同时进一步分析用户购买商品的原因;同时,文本算法分析利用用户的多粒度反馈信息,提升决策的准确性,缩短对话轮次。
2.5 观测状态对推荐结果的影响
为了研究不同状态向量对决策网络的影响,将单个状态、多个状态的组合作为决策网络的观测状态向量(输入),研究不同状态在5 轮、10 轮和15 轮作为最大对话轮数时对系统的影响。由表4知,在Last.fm 数据集中,sitems+sconver作为输入向量得到的实验效果最佳;sattribute和sconver两种状态单独作为输入向量也取得了较为优异的实验结果;三种与四种状态组合的输入向量在实验结果上不及sattribute和sconver单独作为输入向量。在Yelp 数据集上状态的组合数和推荐成功率SR 在整体上呈现正比关系,由表2可知在Yelp数据集上,商品属性数为590,与Last.fm 数据集相比增加了16.9 倍,商品数量为70 311,与Last.fm 数据集相比增加了8.5 倍,在如此庞大的数据集上进行推荐,需要考虑的环境也更为复杂。实验结果表明,将suser、sattribute、sconver和sitems一同作为输入时,推荐准确率SR 和平均推荐轮次AT 指标均优于其他状态向量作为输入的情况。单独的suser作为决策网络的输入,在两个数据集上模型均无法拟合,这是由于用户与用户之间存在着差异,仅将suser作为输入向量而不给予决策网络关于对话的其他信息,决策网络无法作出恰当的判断(例如,系统根据用户特征了解到用户A与用户B之间存在着差异,但并不了解两者在何处存在差异,因此需要引入其他状态帮助系统进行决策)。
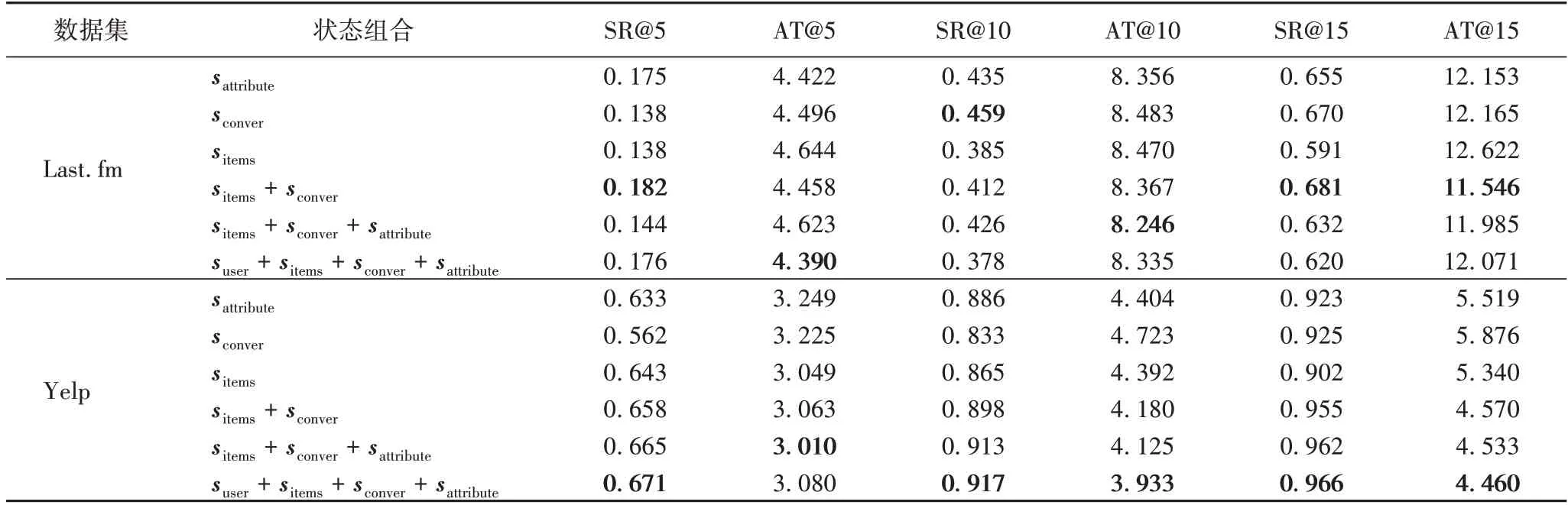
表4 决策网络中不同状态组合作为输入的系统表现Tab.4 System performance of taking different state combinations as inputs in decision network
2.6 多粒度反馈模型对推荐结果的影响
如表5 所示,商品反馈在两个数据集上的表现均优于属性反馈,商品反馈与属性反馈的SR、AT 指标的差距随着最大对话轮数的增加逐渐变大。在Yelp 数据集上,由5 轮中SR 和AT 相差1.6 个百分点和0.309 轮增加至15 轮相差9.4个百分点和0.469 轮;在Last.fm 数据集上,SR 和AT 由5 轮中相差0.6 个百分点和0.126 轮增加至15 轮相差18.3 个百分点和0.662 轮。从直观上看,商品反馈直接反映用户的潜在偏好,而描述商品的更细粒度的商品属性反馈通过商品与用户建立关联,并未直接与用户联系,潜在地反映用户喜好。因此随着对话轮数的增加,商品反馈相较于属性反馈,实验表现更为优异。多粒度反馈模型与商品反馈模型相比,在Last.fm 数据集上,模型在SR@5、SR@10 和SR@15 指标上分别提升了29.5%、7.2%和9.7%,在AT@5、AT@10 和AT@15指标上分别缩短了0.249 轮、0.27 轮和0.633 轮;在Yelp 真实数据集上,模型在SR@5、SR@10 和SR@15 指标上分别提升了28.4%、13%和3.3%,在AT@5、AT@10 和AT@15 指标上缩短了0.26 轮、0.615 轮和1.2 轮。与属性反馈模型相比,在Last.fm 数据集上,模型在SR@5、SR@10 和SR@15 指标上分别提升了36.2%、18.5% 和55.5%,在AT@5、AT@10 和AT@15 指标上分别缩短了0.375 轮、0.783 轮和1.295 轮;在Yelp 真实数据集上,模型在SR@5、SR@10 和SR@15 指标上分别提升了32.4%、24%和14.9%,在AT@5、AT@10 和AT@15 指标上缩短了0.569 轮、1.512 轮 和1.669 轮。实验结果表明商品反馈和属性反馈叠加的多粒度反馈模型在提升准确率的同时缩短了对话轮数。
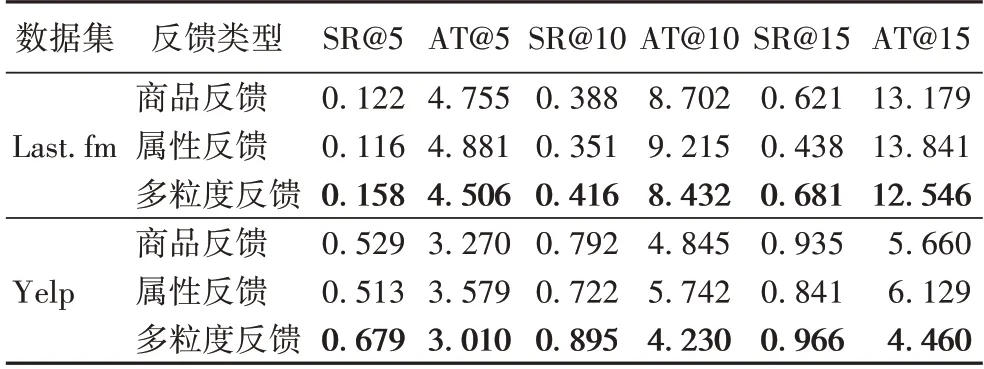
表5 多粒度反馈模型的有效性Tab.5 Effectiveness of multi-granularity feedback model
2.7 决策模型对推荐结果的影响
为了研究决策模型在系统中的影响,使用随机策略代替决策模型中的Q 网络,即在决策时,系统随机作出推荐决策和询问决策。由表6 所示,使用随机策略替代Q 网络之后,系统在每轮无法作出较好的决策以捕获用户的购买偏好,在两个数据集上推荐成功率大幅下降,推荐成功所需的平均对话轮数也更长,说明了本文决策模型中Q 网络的有效性。

表6 消融实验中决策模型的有效性Tab.6 Effectiveness of decision-making models in ablation study
3 结语
本文探讨了如何较为准确地挖掘用户偏好以提升推荐准确率以及缩短对话轮数提升推荐效率的问题,提出利用多粒度的用户反馈信息以更准确地学习用户的购买偏好。引入适用于对话推荐场景的DQN 算法充分利用多粒度的反馈信息实现决策网络,提高决策速度,一定程度上解决了以往的工作挖掘用户兴趣不准确的问题,在提高推荐成功率的同时缩短了对话轮次,并通过实验验证了算法的有效性。
未来,本研究考虑利用用户的评论、点赞、位置和社交等其他信息,同时尝试更加有效的网络代替决策网络中的多层感知机模型,以提升推荐准确率和速度;此外,动作空间过大是强化学习研究中不可避免的一大难点。在今后的工作中,本研究将尝试将属性和商品作为系统动作选择,并引入分层强化学习对该问题进行探索和研究。
