基于One-Shot聚合自编码器的图表示学习
2023-02-03袁立宁
袁立宁,刘 钊
(1.中国人民公安大学 信息网络安全学院,北京 100038;2.中国人民公安大学 研究生院,北京 100038)
0 引言
图表示学习将原始图的结构和特征信息嵌入到低维向量空间,从而能够直接应用常见机器学习算法来挖掘网络的潜在特征。图表示学习旨在生成保留拓扑和属性信息的低维表示,用于节点分类[1]、链接预测[2]、聚类[3]等机器学习任务。为了保证图数据挖掘任务的质量,节点向量在尽可能保留编码属性和边缘信息的同时,还要兼顾较小的嵌入维数。由于图数据的复杂性,基于人工设计特征[4]的传统图嵌入方法成本极高,而直接在图上学习节点表示深度学习的方法[5]因其强大的表示能力,受到了越来越多的关注。在最近的文献中,已经有许多研究尝试将深度学习方法用于图表示学习。其中,基于深度学习的无监督模型能够在缺乏先验知识或标记信息有限的情况下,从数据中选出具有代表性的特征,因此常用于生成原始数据低维节点向量表示。
基于深度学习的无监督图嵌入模型主要分为基于随机游 走[6]和基于自编码器(AutoEncoder,AE)[7]的算法。DeepWalk[8]和node2vec[9]模型使用随机游走获取节点序列,然后训练Skip-Gram[10]生成节点向量表示。这类方法通常以整个网络结构为输入,能够有效捕捉邻域相似性,但是未能充分利用提供重要信息的节点特征。基于AE 的图嵌入模型将图的拓扑结构和节点特征信息作为编码器输入生成低维向量表示,再利用解码器重构图结构;但是大部分AE 模型的编码器部分使用图神经网络(Graph Neural Network,GNN)[11]将节点编码到低维向量空间中,导致模型性能会随着编码器深度的增加而降低[12]。
针对上述问题,本文使用One-Shot 聚合(One-Shot Aggregation,OSA)和指数线性单元(Exponential Linear Unit,ELU)函数改进基于图自编码器(Graph AutoEncoder,GAE)和图变分自编码器(Variational Graph AutoEncoder,VGAE)的深层模型,并在3个基准引文数据集上的链路预测实验中验证模型性能。本文主要工作如下:1)提出新的GAE 模型OSA-GAE和新的VGAE模型OSA-VGAE,使用OSA[13]和ELU函数[14]编码图的拓扑结构和节点特征,改善深层模型的表示能力;2)在损失函数中引入正则化项,防止模型在训练过程中参数过拟合;3)在链路预测实验中,OSA-GAE 和OSA-VGAE 的性能始终优于相同深度的基线方法,而且它们的性能不会随着隐藏层数量的增加而降低,并且在部分数据集上呈现出上升趋势。
1 相关工作
1.1 图表示学习
根据不同的策略,常见的无监督图表示学习模型可以分为两类:基于随机游走和基于AE 的模型。
基于随机游走的模型通过随机游走获得训练语料库,然后将语料库集成到Skip-Gram 获得节点的低维嵌入表示。DeepWalk 使用随机游走采样节点序列,再通过Skip-Gram 最大化窗口范围内节点之间的共现概率将节点映射为嵌入向量,由于优化过程中未使用明确的目标函数,使模型保持网络结构的能力有限。node2vec 在DeepWalk 的基础上引入有偏的随机游走,增加邻域搜索的灵活性,但是仍然缺乏一个明确的目标函数来保持全局网络结构。Walklets[15]修改DeepWalk 的采样过程,捕获节点与社区之间不同尺度信息,显式建模多尺度关系,使生成的嵌入能够保留更丰富的节点从属关系信息。
基于AE 的模型使用AE 对图的非线性结构建模,生成图的低维嵌入表示。SDNE(Structural Deep Network Embedding)[16]利用深度自编码器以及一阶和二阶相似度,明确优化目标,使生成的嵌入有效保留全局和局部结构信息,增强了模型在稀疏图上的鲁棒性。DNGR(Deep Neural networks for Graph Representations)[17]使用正点互信息矩阵构建图的高阶相似度,捕获链路预测和节点分类等任务所需的底层结构,同时引入堆叠去噪自编码器增强模型在含噪声图上的鲁棒性。VGAE[18]使用变分自编码器(Variational AutoEncoder,VAE)[19]学习可解释的无向图嵌入表示,与非概率自编码器相比,使用VAE 提升了模型性能。Res-VGAE(Variational Graph AutoEncoders with Residual connections)[20]在VGAE 的基础上引入残差连接[21],改善深层VAE 性能,但是模型性能随着深度的增加仍表现出显著性降低。ANE[22]使用对抗性自编码器[23]生成捕获高度非线性结构信息的低维嵌入,在生成过程中施加对抗性正则化避免流形断裂问题,同时利用一阶和二阶相似度捕捉局部和全局结构。
1.2 深层模型策略
理论上,随着深度增加,神经网络模型能够提取更复杂的特征,获得更好的结果。实际上,模型性能会因深度增加而退化,导致准确度达到饱和甚至下降,并且在训练中出现梯度消失。
为解决上述问题,ResNet[21]引入残差单元,将各层的输入和输出相加,实现跨层连接,改善深层模型的梯度更新。DenseNet[24]使用稠密连接,即每一层的输入来自前面所有层的输出,改善梯度消失问题。与ResNet 相比,DenseNet 能够保留多个感受野的特征图,更加充分地利用特征信息,但是稠密连接使输入通道增加,导致模型计算效率严重降低。VoVnet[13]使用OSA 将全部特征图聚合到最后一层,使模型在继承DenseNet 优点的情况下,解决了稠密连接效率低的问题。OSA 方式如图1 所示。以上方法改善了卷积神经网络(Convolutional Neural Network,CNN)[25]随深度增加加深出现梯度消失的问题,本文借鉴上述建模思路改进深层GNN 编码器模型架构。

图1 One-Shot聚合Fig.1 One-Shot aggregation
此外,选择合适的激活函数,同样能够解决深层神经网络的梯度消失问题。例如,线性整流函数(Rectified Linear Unit,ReLU)[26]:

ReLU 解决了梯度消失问题,能大幅提升模型的计算速度,但是在x<0 时负的梯度被置零,导致神经元坏死,不再对任何数据产生响应。ELU 在ReLU 基础上引入指数函数,使其在负输入值的情况下也能返回信息:

相较于ReLU,在输入为负值的情况下,ELU 有一定的输出,从而消除ReLU 神经元坏死的问题。此外,ELU 的输出均值接近0,减少了偏移效应,使正常梯度接近于自然梯度;在输入较小时负值能够快速饱和,对噪声有一定的鲁棒性。
2 模型与算法
本章提出基于One-Shot 聚合自编码器的图表示学习模型OSA-GAE 和OSA-VGAE 并讨论算法原理,介绍了模型框架及编码器和解码器结构,并讨论了模型的损失函数。
2.1 模型框架
基于One-Shot 聚合自编码器的图表示学习模型框架如图2 所示。OSA-GAE 和OSA-VGAE 以节点特征矩阵和邻接矩阵为输入,重构邻接矩阵为输出,它们的结构分为编码器(Encoder)和解码器(Decoder)两部分。编码器使用基于OSA的多层图卷积网络(Graph Convolutional Network,GCN)[27]进行构建,用于特征提取和数据降维,生成每个节点的低维向量表示。解码器利用编码器生成向量的内积重构邻接矩阵。

图2 OSA-GAE和OSA-VGAE模型结构Fig.2 Model structures of OSA-GAE and OSA-VGAE
2.2 编码器网络结构
GCN 利用卷积运算从图中提取特征,生成包含拓扑结构和节点属性信息的特征向量。具体而言,GCN 使用节点特征矩阵X与邻接矩阵A作为原始输入,其层间传播公式为:

OSA-GAE 编码器使用引入One-Shot 聚合的多层GCN 提取特征,其表达式为:

其中:L为GCN 层数;W(Final)为权重矩阵。
OSA-VGAE 编码器使用引入One-Shot 聚合的多层GCN生成均值向量μ和方差向量σ:

采样层使用μ和σ从高斯先验分布生成样本,构建低维嵌入。最终,将嵌入重新参数化为潜在空间上概率的分布[18]:

其中:X为节点特征矩阵;A为引入自环的邻接矩阵;yi是节点i的低维嵌入,N为节点数。
2.3 解码器网络结构
对于OSA-GAE 模型,解码器是利用两个节点表示内积重构邻接矩阵的非概率模型:

其中:A′表示重构矩阵;φ表示sigmoid 函数。
对于OSA-VGAE 模型,解码器是利用两个节点表示内积重构邻接矩阵的概率模型:

其中:Aij为邻接矩阵A的元素。
2.4 损失函数
OSA-GAE 通过最小化A和A′的重构损失进行训练,表达式为:

OSA-VGAE 通过最大化变分下界以及最小化重构损失进行训练,表达式为:

为了避免参数过拟合,在OSA-GAE 和OSA-VGAE 损失函数中引入L2-norm 正则化项Lreg,使用超参数α控制比重:

在训练过程中,GCN 层的输入和输出维度必须相同,才能使用OSA。此外,OSA-GAE 和OSA-VGAE 均执行全批次梯度下降,并利用重参数化技巧[19]进行训练。
3 实验与结果分析
3.1 数据集
本文使用Cora、CiteSeer、PubMed 这3 个基准引文网络数据集[30]评估OSA-VGAE 和OSA-GAE 生成的低维嵌入表示在链接预测任务中的性能。在数据集中:节点表示论文,边表示一篇论文对另一篇论文的引用,节点特征是论文的词袋表示,节点标签是人工设定的论文的学术主题。表1 为3 个数据集的统计信息。

表1 数据集统计信息Tab.1 Statistics of datasets
3.2 基线模型
本文使用以下模型作为基线:
VGAE:该模型将VAE 迁移到图表示学习,其基本思路是利用GCN 获得节点表示的概率分布,然后在分布中采样生成节点表示,最后使用内积解码重构图的邻接矩阵。
GAE[18]:该模型直接使用GCN 编码器生成节点表示,然后使用内积解码器重构邻接矩阵。
Linear-VGAE[31]:该模型使用归一化邻接矩阵的简单线性模型替换VGAE 中的GCN 编码器,解码器与VGAE 相同。
Linear-GAE[31]:该模型使用归一化邻接矩阵的简单线性模型替换GAE 中的GCN 编码器,解码器与GAE 相同。
Res-VGAE:该模型在VGAE 的基础上引入残差连接,改善深层VAE 模型的性能。
Res-GAE[20]:该模型在GAE 的基础上引入残差连接,改善深层AE 模型的性能。
3.3 实验设置
为了验证模型在链接预测任务中的性能,需要对基准引文网络数据集进行预处理[19]:1)保留所有节点的特征信息,将图中部分边移除;2)随机采样无边的节点对,其数量与先前移除的边数相同;3)利用移除的边和无边节点对构建验证集和测试集,其比例分别为总边的5%和10%。
根据模型正确分类边和非边的能力比较模型性能,使用平均精度(Average Precision,AP)和ROC 曲线下的面积(Area Under ROC Curve,AUC)作为评价指标。模型的隐藏层维度均设置为32,生成嵌入的维度设置为16,学习率设置为0.01,迭代次数设置为200。各模型使用相同的验证集和测试集划分,运行10 次获得平均值。
3.4 实验结果
链接预测任务即预测两个节点之间是否存在边,用于评估生成嵌入在保持拓扑结构方面的性能。表2~4 为各模型不同深度的AP(%)和AUC(%)结果。
表2 比较了不同模型使用1 层GCN 的实验结果。在3 个数据集上,OSA-VGAE 和OSA-GAE 的AUC 和AP 最高,其他基线模型的AUC 和AP 十分接近。对于浅层模型,增加OSA和ELU 激活函数能提升模型的准确度。

表2 1层GCN时各模型的AUC和AP 单位:%Tab.2 AUC and AP of each model with 1-layer GCN unit:%
表3 比较了不同模型使用3 层GCN 的实验结果。在3 个数据集上,引入残差连接的Res-VGAE 和Res-GAE 表现略优于直接叠加GCN 层的模型,而OSA-VGAE 和OSA-GAE 的表现明显优于其他模型,特别是在CiteSeer 数据集上,AUC 和AP 相较单层模型有小幅度提升。

表3 3层GCN时各模型的AUC和AP 单位:%Tab.3 AUC and AP of each model with 3-layer GCN unit:%
表4 比较了不同模型使用6 层GCN 的实验结果。在3 个数据集上,不引入残差连接、OSA 和ELU 函数的VGAE、GAE、Linear-VGAE 和Linear-GAE 的AUC 和AP 明显降低,并且采用线性编码的Linear-VGAE 和Linear-GAE 表现最差。在Cora 数据集上,Res-VGAE 和Res-GAE 与VGAE 和GAE 性能相近;在CiteSeer 和PubMed 数据集上,Res-VGAE 和Res-GAE 表现优于VGAE 和GAE。在3 个数据集上,OSA-VGAE和OSA-GAE 表现最好,深层模型与浅层模型的性能差异不大,尤其是在CiteSeer 上,AUC 和AP 仍有提升。

表4 6层GCN时各模型的AUC和AP 单位:%Tab.4 AUC and AP of each model with 6-layer GCN unit:%
图3~5 为不同模型在引文数据集上1~6 层的AUC 和AP。与原始的VGAE 和GAE 相比,随着深度增加,Linear-VGAE 和Linear-GAE 的精度下降最快,表现最差;引入残差连接的Res-VGAE 和Res-GAE 虽然在一定程度上缓解了深层模型精度下降的问题,但是其表现与原始模型相接近。本文提出的OSA-VGAE 和OSA-GAE 明显好于其他模型,随着深度的增加,模型的性能基本保持稳定,在Cora 和CiteSeer 数据集上其性能呈现随层数的增加而上升的趋势。上述实验结果说明添加OSA 和ELU 函数能够改善深层模型的梯度信息传递问题,提升模型性能。

图3 Cora数据集上的AUC和APFig.3 AUC and AP on Cora dateset
3.5 消融实验
为了验证OSA-VGAE 和OSA-GAE 模型中使用OSA 和ELU 对于算法性能的影响,在Cora 数据集上进行消融实验,对比单独使用OSA 和ELU 函数的模型性能。为了保证实验的公平性,保持学习率、隐层维度和嵌入维度等参数一致。实验结果如表5 所示。相较于单独使用OSA 或ELU 函数,OSA-VGAE 和OSA-GAE 获得了最佳表现,说明同时使用上述两个模块能够显著提升性能。

表5 消融实验结果 单位:%Tab.5 Results of ablation experiments unit:%
3.6 参数分析
为了评估不同嵌入维度和迭代次数对实验结果的影响,在Cora 数据集上对使用1 层GCN 的OSA-VGAE 和OSA-GAE模型进行参数敏感性实验,记录相关数据。图6 显示了不同嵌入维度对模型性能的影响。最初,AUC 随维度的增加而提高,这是因为更多的维度使嵌入中编码了更多有益信息,提升了实验表现。但是,随着维度不断的增加,AUC 开始下降,这是因为训练样本个数有限,对于每一类节点都存在最大化模型性能的最优嵌入维数,当嵌入维数超过最优维数时,模型性能表现出逐渐下降的趋势。此外,从图6 曲线变化可以看出,OSA-VGAE 相比OSA-GAE 对维度更敏感。因此,在生成节点嵌入时选择合适的维度十分重要。

图4 CiteSeer数据集上的AUC和APFig.4 AUC and AP on CiteSeer dateset
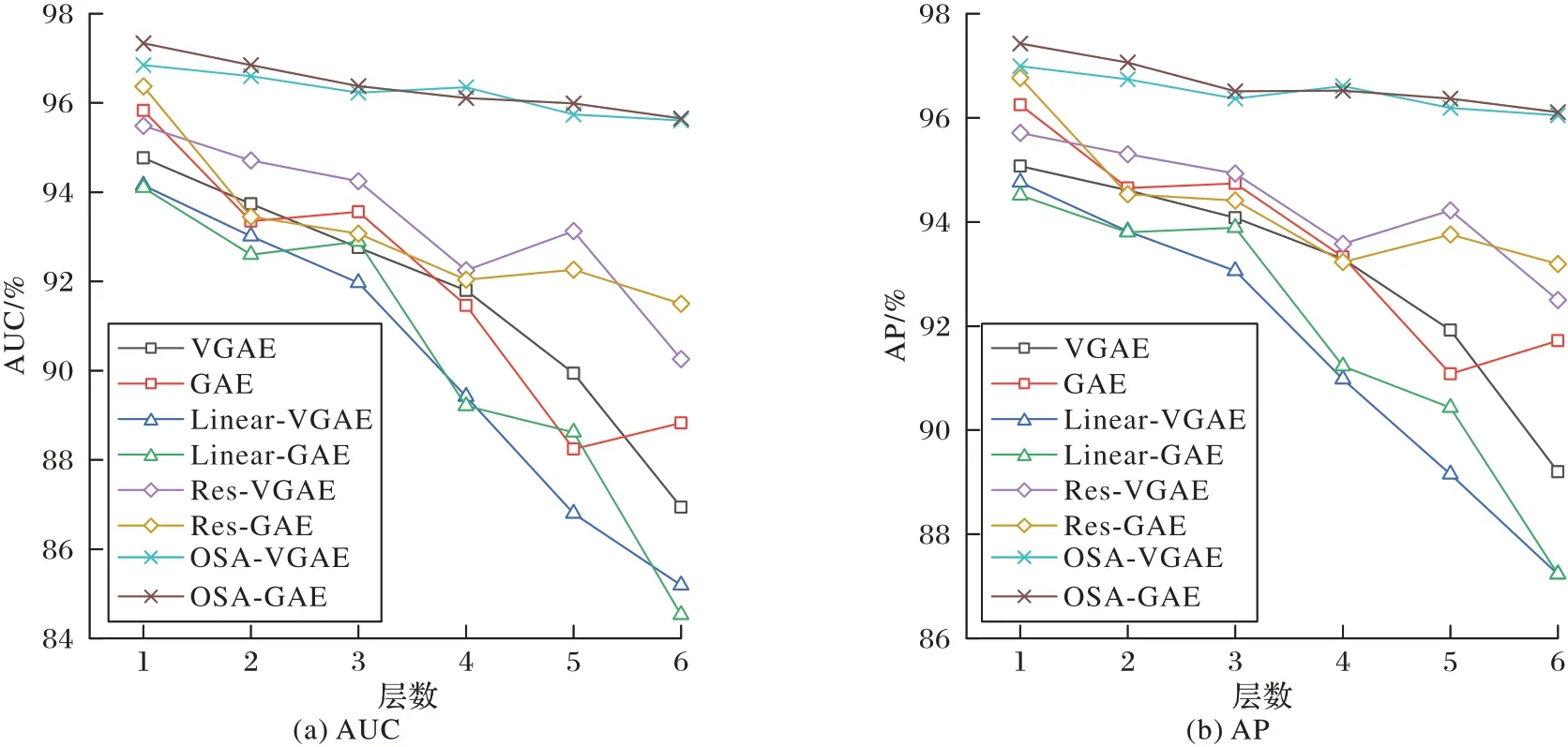
图5 PubMed数据集上的AUC和APFig.5 AUC and AP on PubMed dateset

图6 不同嵌入维度的AUCFig.6 AUCs of different embedding dimensions
图7 记录了OSA-VGAE 和OSA-GAE 每次迭代的训练损失和AUC。随着迭代次数的增加,模型训练损失整体呈下降趋势,并且在200~1 000 的迭代过程中,损失值基本处于稳定状态。在测试集上,初始阶段的AUC 随着迭代次数的增加快速上升,到达一定迭代次数时,模型开始出现过拟合,泛化能力下降,导致AUC 小幅下降并上下震荡。因此,在训练模型时选取200 左右的迭代次数即可获得较为理想的实验结果。

图7 OSA-VGAE和OSA-GAE在不同迭代时的训练损失和AUCFig.7 Training loss and AUC under different iteration for OSA-VGAE and OSA-GAE
4 结语
本文提出了基于One-Shot 聚合和ELU 激活函数的OSAVGAE 和OSA-GAE 模型,改善了模型的梯度信息传递,缓解了基于GCN 编码的自编码器模型深度问题。实验结果表明,将计算机视觉中的深层策略引入到图表示学习中是有益的,能够提升图机器学习任务的表现。此外,消融实验的结果也说明同时使用One-Shot 聚合和ELU 函数对模型性能提升更加显著。在未来工作中,除了对现有编码器模型的结构进行改进,将采用更为高效的邻域聚合和邻域交互编码器建模,如基于注意力机制的方法[32];在解码器部分,将尝试使用不同的解码器和概率分布进行实验。此外,后续工作还将针对模型复杂度、模型泛化能力以及模型避免过拟合能力进行量化和分析。
