融合多重注意力机制的人眼注视点预测
2022-12-21孔力胡学敏汪顶刘艳芳张龑陈龙
孔力,胡学敏*,汪顶,刘艳芳,张龑,陈龙
1. 湖北大学计算机与信息工程学院,武汉 430062; 2. 中山大学数据科学与计算机学院,广州 510006
0 引 言
人眼在观察画面时会倾向于关注自己感兴趣的区域,自动忽略一些不重要区域,这种机制称为视觉注意力机制(Borji,2021;Dorta等,2018)。王文冠等人(2019)提出,从人类生理机理的角度而言,人类的视觉注意力机制基于视网膜的特殊生理结构,即高分辨率的视网膜中央凹和较低分辨率的边缘视网膜。视网膜的中央凹区域集中了绝大多数的视锥细胞,负责视力的高清成像。人们关注某一物体时,通过转动眼球将光线集中到中央凹,获取显著区域的更多细节而忽略其他不相关区域的信息。可见,人类视觉注意力机制引导视网膜的生理结构完成对场景信息的选择性收集任务,该机制可将有限的脑资源用于场景中重要信息的处理,是人类视觉高效率和高精度的基础。
显著目标检测的任务通常分为显著区域检测和人眼注视点预测两类(Oyama和Yamanaka,2018)。早期的人眼注视点预测往往是基于人工选择特征方法(Valenti等,2009)。Zhang和Sclaroff(2016)利用在LAB色彩空间(lab color space)中获得的一组特征生成最终的人眼注视概率图。这类方法通常只关注图像的低级特征或只关注图像的高级特征,没有将不同层次的特征结合起来。
随着深度神经网络在计算机视觉任务上的广泛应用,人们在显著目标检测上使用了深度神经网络技术。Vig等人(2014)首次使用深度神经网络技术预测显著概率图。之后,人们开始关注如何有效增加模型深度来提高模型的表达能力。SALICON(saliency in context)(Huang等,2015)将不同分辨率的图像输入同一种神经网络,然后组合这些分辨率图像的高级特征进行预测。Deepfix(Kruthiventi等,2017)使用空洞卷积技术进行预测。上述一些方法直接使用主干网络的高层特征预测显著图,或不加区分地聚合多级特征进行预测,这些方法都未考虑特征之间的冗余,容易导致不佳的预测效果(何伟和潘晨,2022)。
注意力机制的发展为人眼注视点预测提供了新的方向。SAM-Res(saliency attention model)(Cornia等,2018)提出了带有注意力机制的长短期记忆(long short-term memory,LSTM)人工神经网络结构。DINet(dilated inception network)(Yang等,2020)将带有空洞卷积的IncePtion网络用于自下而上的人眼注视点预测。GazeGAN(gaze generative adversarial network)(Che等,2020)采用通道方向的注意力进行人眼注视点预测。尽管这些方法取得了良好的性能,但仍然没有考虑不同层特征对显著目标的贡献差异。
现有基于注意力机制的人眼注视点预测研究往往集中在空间级和通道级注意力的问题上,既忽视了不同层级之间特征的重要性对预测结果的影响,也没有分析和融合空间、通道以及层级多种注意力机制的模型。此外,现有方法较少考虑人眼在观察事物时的中心偏置问题,导致预测精度有限。本文基于ConvLSTM(convolutional LSTM)模型,将层注意力机制与空间、通道注意力机制相融合,提出一种多重注意力机制的网络(multiple attention mechanism network, MAM-Net)进行人眼注视点预测。本文主要工作有以下3点:1)提出一种层注意力机制,并与空间、通道注意力机制相融合,提出基于ConvLSTM的多重注意力模型,从层级、空间和通道多个角度增强模型的表征能力;2)提出一种高斯学习模块,根据当前的特征信息自动选择合适的高斯模糊参数,优化人眼注视点预测概率图,解决人眼视觉的中心偏置问题,提高预测效果;3)在公开数据集上进行多项综合性测试。结果显示,本文方法在多数人眼注视点预测指标上超过了现有主流模型。
1 多重注意力机制与人眼注视点预测
本文提出的基于多重注意力机制的人眼注视点预测模型主要分为3部分,即图像特征提取模块、多重注意力模块和高斯学习模块,如图1所示。
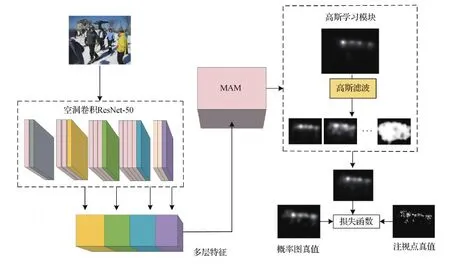
图1 人眼注视点预测总体流程图Fig.1 Overview of eye fixation prediction
1.1 图像特征提取模块
本文提出的MAM-Net中的特征提取模型以ResNet-50作为主干网络。在不减小图像尺寸和增加模型参数的情况下,为缓解传统ResNet-50在显著性预测中特征信息丢失问题,在传统ResNet-50的基础上进行改进,设计了一种基于空洞卷积(Liu和Han,2018)的ResNet-50网络。空洞残差卷积网络(dilated ResNet,DRN)的参数设置如表1所示。为表述方便,将第1个卷积块记做M0,其余4个残差卷积模块分别记做M1、M2、M3和M4,选择每个残差模块的最后一层结果作为特征图。为兼顾模型大小与精确度,本文选取的特征图数量为原网络所提取的1/8。
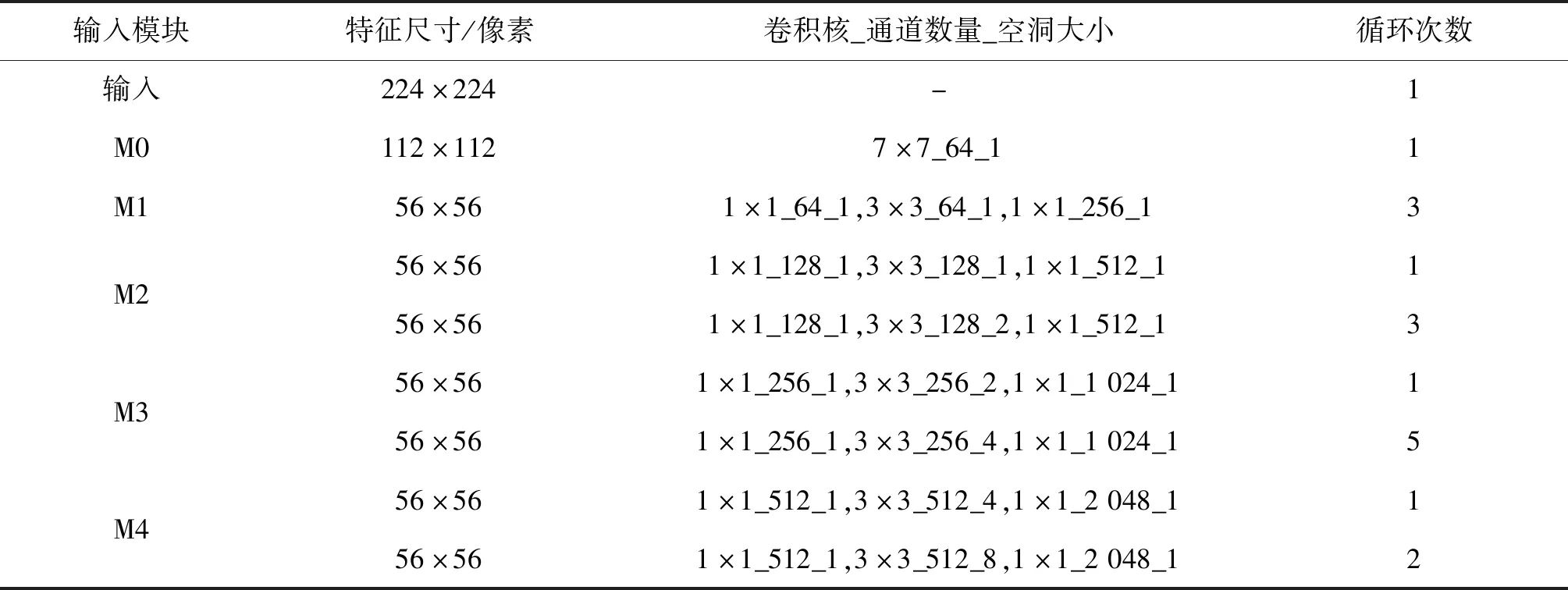
表1 基于空洞卷积的ResNet-50参数设置Table 1 Parameters in the ResNet-50 based on dilated convolution
1.2 多重注意力模块
由于浅层特征对于显著图的细节十分重要,而深层特征提供了抽象的语义信息。所以,初始特征图先经过通道、空间注意力处理,再利用层注意力机制来优化不同层之间的权重,能有效突出特征表达,最后输入ConvLSTM中生成初步预测的特征图Q,该过程如图2所示。
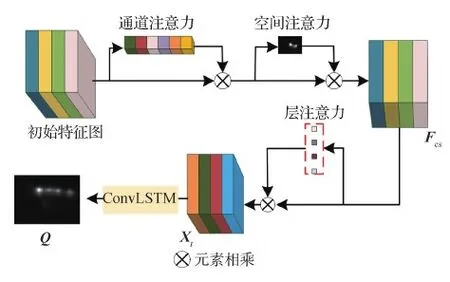
图2 MAM结构Fig.2 Architecture of the MAM
1.2.1 通道注意力机制设计
通道注意力的目的是表达某层卷积中不同通道之间的特征重要性(Hu等,2020),本文设计的通道注意力机制如图3中红色虚线框所示。
F∈RH×W×C为提取到的特征图,其中F可看成F=[F1,F2, …,Fc],Fi∈RH×W表示第i个通道,C为通道的数量。对F同时使用全局最大池化操作和全局平均池化操作,得
Favg=FC(GA(F))
(1)
Fmax=FC(GM(F))
(2)
式中,FC为全连接层(fully connected)函数,GA和GM分别表示全局平均池化(global average pooling)和全局最大池化(global max pooling)。Favg和Fmax分别表示平均池化和最大池化后进行FC后的特征。将大小为R1×1×C的权重向量Favg和Fmax进行对应元素加和操作,经由激活函数生成最终的通道注意力参数Mc,即
Mc=σ(Favg+Fmax)
(3)
式中,σ表示sigmoid函数。
Fc为通道注意力处理后的特征,具体过程为
Fc=Mc⊗F
(4)
式中,⊗代表元素相乘。
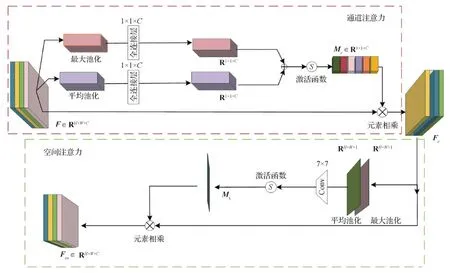
图3 通道注意力与空间注意力模块Fig.3 Channel-spatial attention aggregation module
1.2.2 空间注意力机制设计
空间注意力的目的是表达同一通道图像的不同区域像素点之间的权重关系(Woo等,2018),本文设计的空间注意力结构如图3绿色虚线框所示。
将特征图Fc在通道维度上先后进行平均池化和最大池化操作,得到Fa和Fm∈RH×W×1,具体为
Fa=GA(Fc)
(5)
Fm=GM(Fc)
(6)
式中,Fa和Fm分别为经过平均池化和最大池化后的特征图。
为了将Fa和Fm基于通道维度融合成一个有效的特征图,本文设计大小为7 × 7的卷积进行卷积操作,使其降维为单通道,接着通过激活函数得到空间注意力的特征参数Ms,具体为
Ms=σ(f7×7[Fa;Fm])
(7)
式中,f7×7[Fa;Fm]为卷积操作。
Fcs∈RH×W×C为通道—空间注意力处理后的特征图,过程为
Fcs=Ms⊗Fc
(8)
1.2.3 层注意力机制设计
由于不同层的特征表述的信息不同,信息的重要程度也不同,若无差别地处理不同特征会影响最终的预测效果。本文提出一种层注意力机制,如图4所示。将各个层级划分成独立的块,初始每一个独立的块有相同的层级注意力的权重,层注意力的权重可以表达相对高效的层级特征。通过通道和空间注意力模块后的特征记为Xt=Fcs∈RL×H×W×C,其中L为MAM-Net中提取的特征层数,C为当前特征具有的通道数,W和H分别对应特征图的宽度和高度。层注意力机制计算为
Wt=G*Ht-1
(9)
St=softmax(Wt)⊗L
(10)
(11)
式中,Ht-1是ConvLSTM在t-1时刻生成的隐藏状态,*代表卷积操作,G为卷积模块,利用GA和FC来改变每一层的权重,Wt∈RL×1×1×1。St为RL×H×W×C的权重图。将Xt乘以St作为层注意力机制的输出结果,得到输入ConvLSTM的数据。
1.3 高斯学习模块
人眼观察图像时倾向于图像中心部分,这种中心偏置行为往往导致实际的人眼注视点与预测算法得到的结果不一致(Liang和Hu,2015;Tatler,2007)。
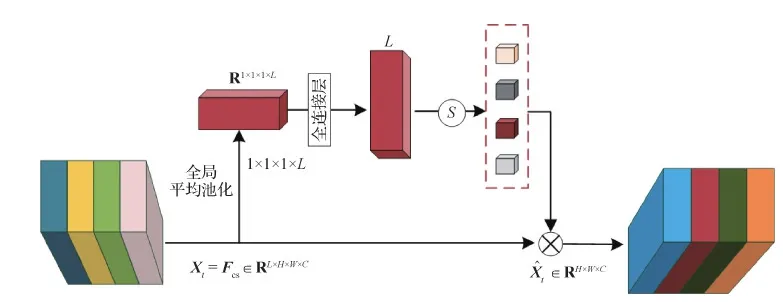
图4 层注意力机制Fig.4 Layer attention
本文提出一种高斯学习模块,通过设置不同的高斯滤波核来处理初步人眼注视点图Q,生成最终的人眼注视点预测图。高斯学习模块由高斯滤波层和卷积层组成,如图5所示。图5中,n为高斯滤波核的数量,本文中n=10,为经验值。
在高斯滤波层中,将特征图Q分别经过n个不同高斯核的模糊处理,得到一组滤波后的图像{Q1,Q2, …,Qn}。高斯滤波核可具体表示为
(12)
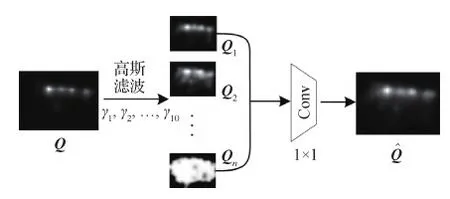
图5 高斯学习模块结构Fig.5 Gussian learning module

图6 不同γ取值的人眼注视点预测图Fig.6 Saliency prediction probability in differentγ((a)original image;(b)fixation maps; (c)saliency maps;(d)γ = 0.01;(e)γ = 0.02;(f)γ = 0.04;(g)γ = 0.06;(h)γ = 0.08;(i)prediction)
1.4 损失函数
SAM-Res模型在人眼注视点预测中取得了较好的结果,本文损失函数系数参照该方法,采用一种组合的损失函数,由3个不同的显著性评估指标线性组合而成,能够有效平衡不同评估指标。具体为
L(y,yden,yfix)=-LNSS-2LCC+10LKLD
(13)
式中,LNSS、LCC和LKLD分别代表计算归一化扫描路径一致性(normalized scanpath saliency,NSS)、线性相关系数(linear correlation coefficient,CC)和相对熵(Kullback-Leibler divergence,KLD)3个指标的损失函数。LNSS用来计算预测值与人眼注视点之间的损失,LCC和LKLD用来计算预测值与注视点概率图之间的损失。yden是数据集标注的人眼注视点概率图标签,yfix是数据集标注的人眼注视点二值图标签。标签数据会被标准化为均值为0、标准差为1的数据分布,y为预测图。
2 实验与结果分析
实验硬件GPU为GeForce GTX 1080TI 11 GB,CPU为Intel Core i7-7700K,深度学习框架选用 PyTorch。
采用公开数据集SALICON(Huang等,2015)和MIT300/1003(Judd等,2009)作为本文的实验数据集。测试SALICON数据集时,先采用在ImageNet上训练好的分类模型的参数,然后在SALICON上进行训练微调。测试MIT300/1003数据集时,使用从SALICON数据集上训练好的模型进行微调。实验选择Adam作为优化器,batch size设置为8,epoch设置为29,采用SAM模型中的损失函数作为训练过程的损失函数。
用于衡量人眼注视点模型预测结果的方法主要包括线性相关系数CC、相似性测度(similarity metric,SIM)、信息增益(information gain,IG)、相对熵KLD、受试者工作特性曲线下面积(area under ROC curve,AUC)及其改进版sAUC(shuffled AUC)、归一化扫描路径一致性NSS(Bylinskii等,2018)。其中,CC用来统计预测图与真实显著图之间的线性相关性;SIM用来衡量预测图与真实显著图的交叉分布,衡量二者分布匹配程度;IG能够估算模型相对于使用中心偏置技巧的信息增量;KLD用来衡量显著性预测结果与真值分布之间的距离;AUC用以将检测显著图作为二值分类器与真值显著图进行比较;sAUC为AUC的变体,为了消除使用中心偏置技巧效应的影响,随机从其他显著图中挑选负类样本;NSS能够衡量人眼注视点固定位置的平均归一化显著性。
CC、NSS和AUC之间具有高相关性,称为相似度量集群。CC、NSS、AUC、sAUC、SIM和IG指标数值越高,表明预测效果越好,KLD指标是衡量二者显著区域分布距离,数值越低表示越好。不同指标在人眼注视点预测中的作用不同,本文采用这些指标对实验结果进行评价。
2.1 不同注意力机制的对比实验
多重注意力机制是本文的核心,在主流的人眼注视点数据集SALICON上进行注意力模型的对比实验。具体方法为分别添加不同的注意力机制,将各个模块拆除分别进行对比实验。将通道、空间和层注意力机制分别简称为CA (channel attention)、SA(spatial attention)和LA (layer attention),真值简称为GT(ground truth)。
图7为可视化实例,加入多重注意力机制后不仅能清晰地预测出目标区域,而且能很好地抑制背景的影响。引入通道注意力机制,可以对图像中特征的种类有所侧重,更好地理解图像中的内容。
表2为在不同注意力机制验证集上的结果对比。表2中CA的CC、AUC和NSS相较于无注意力机制分别提高0.014、0.009和0.048,说明层注意力能够更好地理解图像中的内容,提高预测注视点的位置以及分布精度。SA+CA方法的CC、sAUC和NSS相较于只引入通道机制分别提高0.007、0.005和0.015,显示图像的空间位置信息得到更好区分。在引入层注意力后,区别于传统的使用深层特征作为最后预测,添加层注意力机制能后,模型能更好地提取特征,达到更好的预测效果,相较于添加通道和空间注意力,CC、sAUC和NSS指标分别提高了0.017、0.007和0.034,表明经过层注意力机制处理后的特征图与真实图存在更多的相似位置。
2.2 消融实验
为测试本文提出的多重注意力机制、高斯学习和空洞卷积模块对人眼注视点预测的影响。以ResNet-50为主干网络,在SALICON数据集上进行消融实验。ResNet为原始版本ResNet-50上添加一个上采样层,使模型获得与标签图像同样分辨率的预测人眼注视点结果图;DRN是加了空洞卷积的Res-Net-50;DRN + MAM结构是加了空洞卷积的ResNet-50模型结构后,使用MAM结构优化提取的特征;DRN + GL是在DRN结构后添加一个高斯学习(Gussian learning,GL)模块来优化人眼注视概率图。本文提出的MAM-Net模型是在DRN + MAM的结构上添加高斯学习模块来优化预测结果。

图7 不同注意力机制效果图Fig.7 Result images of different attention mechanisms((a)original image;(b)ground truth;(c)SA + CA + LA;(d)no attention;(e)CA;(f)SA + CA))
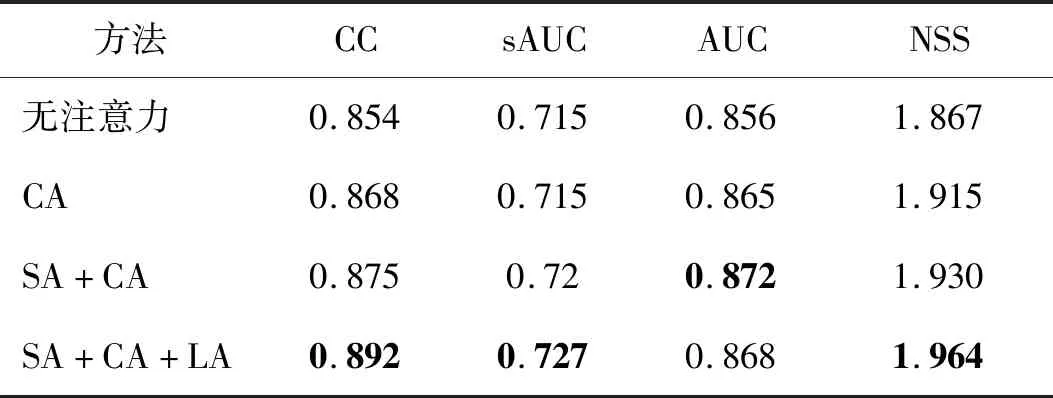
表2 不同注意力机制在SALICON验证集的结果对比Table 2 Comparative results of different attention mechanisms on the SALICON dataset
图8为消融实验中不同模型训练过程的损失函数曲线图,为使曲线更加简洁清晰,采用epoch作为横坐标。可以看出,在训练后期,本文提出的MAM-Net模型和DRN + GL模型在损失值上比较接近,从20个epoch后变化稳定,且比其他模型的损失值明显更小。
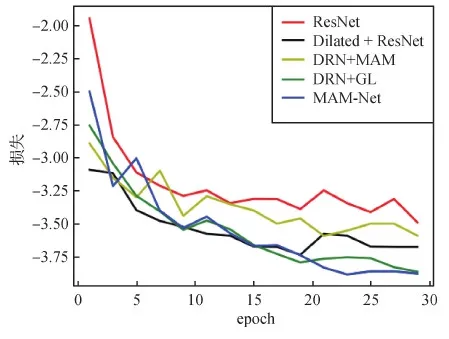
图8 训练过程中不同模型的损失函数曲线图Fig.8 Loss function curves of different models in the training process
图9为添加不同模块的可视化结果。
表3为5种独立模型的对比结果。可以看出,MAM-Net结构在SALICON验证集上有3项评价指标超过了其他组合,分别是AUC、NSS和sAUC,本文将MAM-Net作为人眼注视点预测的最优选择。表3中DRN结构相较于普通的ResNet-50结构得到了更好的结果,可以得知在原始ResNet-50上添加空洞卷积能提高对显著性位置的预测精度;添加MAM模块后,各项指标相较于DRN模型存在一定提升,在CC指标上达到了0.894,优于对比方法,表明MAM模块使用的多重注意力能更有效地提高显著图分布的预测;从表3第3行和第5行的对比中可知高斯学习模块能够提高模型预测精度。MAM-Net的AUC、sAUC和NSS的评分比只添加了MAM的结构分别高出0.004、0.007和0.032,表明高斯学习模块使预测结果更接近于人眼注视点的真实分布。

图9 不同模块处理结果图Fig.9 Result images with different modules((a)original image;(b)ground truth;(c)plain ResNet;(d)Dilated + ResNet;(e)DRN + MAM;(f)DRN + GL;(g)MAM-Net(ours))
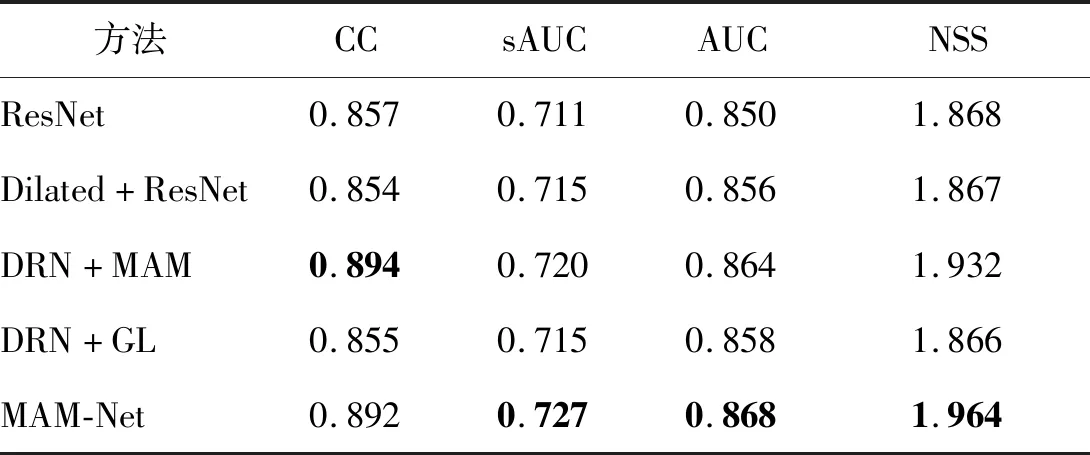
表3 MAM-Net不同模块验证集对比实验Table 3 Ablation analysis of MAM-Net validation sets
2.3 主流模型对比实验
为了验证MAM-Net模型的有效性,将本文方法与目前主流人眼注视点预测模型SAM-Res(Cornia等,2018)和DINet(Yang等,2020)进行对比实验,结果如表4所示。可以看出,在SALICON数据集上,对比相似使用ConvLSTM结构的SAM-Res和DINet模型,本文提出的基于多重注意力机制的方法在sAUC指标上分别高出 0.3%和0.5%,在IG指标上分别提高了6%和192%,在KLD评价指标上分别提高了33%和53%,在3种模型对比中均达到了最优结果。
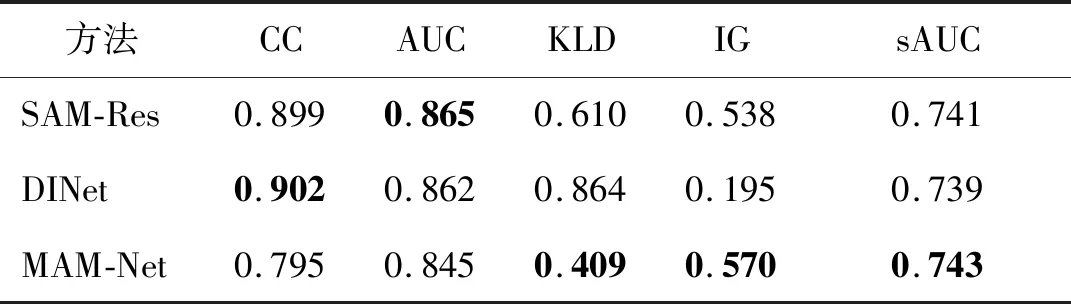
表4 不同模型在SALICON测试数据集的结果对比Table 4 Comparative results of different methods on the SALICON test dataset
为了验证模型的泛化能力,在难度较大的MIT300/MIT1003数据集上与3种基于深度学习的模型DeepGazeI(Kümmerer等,2014)、eDN(ensemble of deep networks)(Vig等,2014)、GoogLeNetCAM(class activation map)(Mahdi和Qin,2019)和基于浅层学习的显著性模型Judd(Judd等,2009),以及3个传统的显著性模型GBVS(graph-based visual saliency)(Harel等,2007)、LGS(local global saliency)(Borji和Itti,2012)和RC(region-based contrast)(Cheng等,2015)进行对比,对比结果如表5所示。可以看出,本文提出的MAM-Net有良好表现,CC指标为0.58,表现最好,其他两个指标也与最好指标相接近。
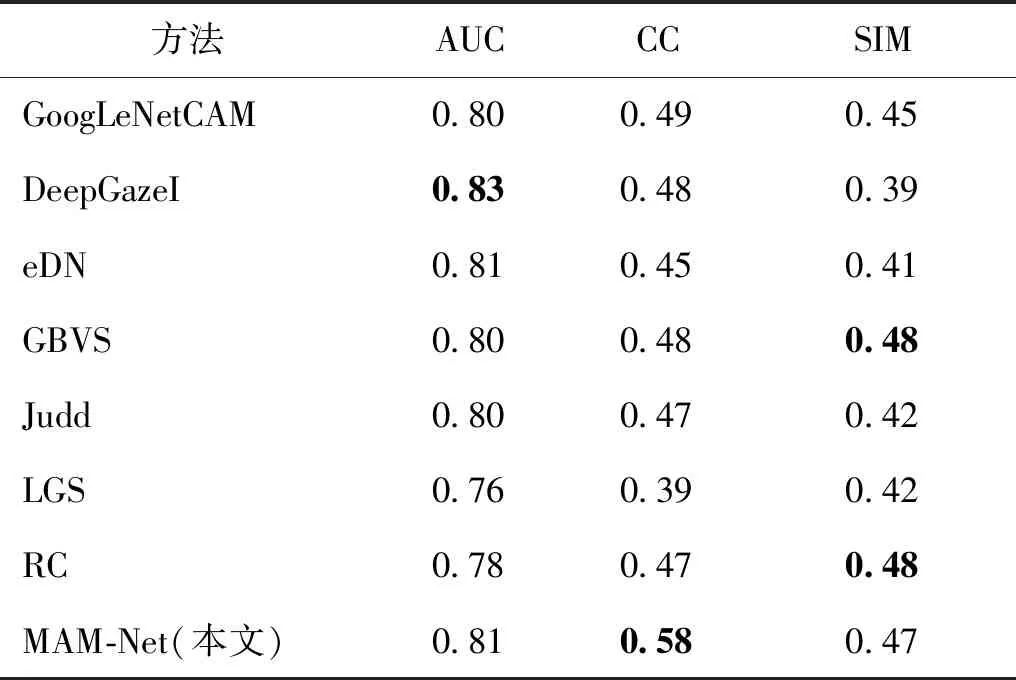
表5 不同模型在MIT300/1003测试集上的结果对比Table 5 Comparative results of different methods on the MIT300/1003 test dataset
使用中心偏置的方法可以提高模型在各项指标上的评分。由于AUC指标会受到中心偏置的影响,sAUC评价方法可有效提高AUC指标的鲁棒性。IG能够估算模型相对于使用中心偏置技巧的信息增量。本文方法在sAUC、IG和KLD等指标上比对比模型更好,体现了高斯学习模块在预测中的作用。
图10和图11为在SALICON和MIT300/1003数据集上的测试结果示例图。可以看出,MAM-Net能够预测人、面部、物体和其他主要的强显著性区域。特别地,当图像中的强显著性区域不明显或图像主体比较分散时,如图10第2、3、4行和图11第3行,与对比方法相比较,MAM-Net能产生更为准确的显著性区域,与真实的人眼注视点更加接近。
本文方法也存在一些局限性。如图12所示,当众多物体集中在一幅图像中,造成图像中显著性对象过于拥挤时,本文方法和对比方法均难以取得较好的预测效果。

图10 SALICON数据集对比测试结果示例Fig.10 Comparative testing results on the SALICON dataset((a)original images;(b)ground truth;(c)DINet;(d)SAM-Res;(e)MAM-Net)
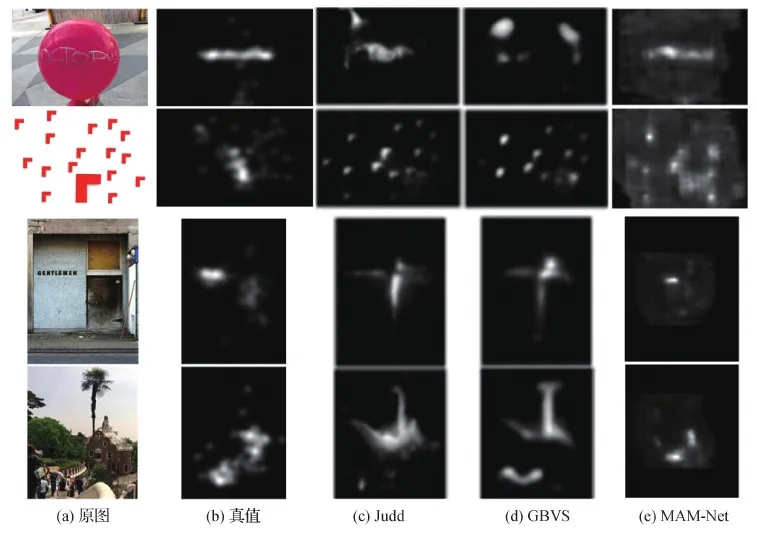
图11 MIT300/1003数据集对比测试结果示例Fig.11 Comparative testing results on the MIT300/1003 dataset((a)original images;(b)ground truth;(c)Judd;(d)GBVS;(e)MAM-Net)

图12 SALICON上的部分效果不佳示例Fig.12 Some poor cases on the SALICON datasets((a)original images;(b)ground truth;(c)DINet;(d)SAM-Res;(e)MAM-Net)
3 结 论
本文提出了一种融合多重注意力机制的人眼注视点预测方法。该方法以ResNet-50为主干网络,一方面通过通道和空间注意力机制优化由ResNet-50提取的特征,用以增强图像中的通道特征和空间特征;另一方面设计层注意力机制,有选择地融合不同层间的特征,解决没有充分利用图像高低层特征的问题。此外,为了解决人眼观察图像产生的中心偏置的行为,提高模型预测性能,本文提出一种高斯学习模块,通过设置不同的高斯核来优化和生成更符合人眼注视规律的预测图。实验结果表明,本文提出的基于MAM-Net的人眼注视点预测方法可以有效优化视觉任务的特征图,在图像上准确预测人眼的视觉区域。与SAM-Res和DINet等对比方法相比,在KLD和sAUC等多项评价指标上取得更优的结果。
本文方法也存在一定的局限性。多重注意力机制可以有效提高人眼注视点的预测结果,但是在语义丰富的场景中,特别是众多目标集中在一起时,造成图像中显著性对象过于拥挤,预测效果会明显下降。在后续工作中,如何提高语义丰富图像的特征表达能力和预测效果是首要研究目标。此外,将人眼注视点预测与特定视觉任务相结合,例如基于视觉的自动驾驶,是另一研究方向。
