低比特率语音流大容量分层隐写方法
2022-12-21苏兆品张羚张国富
苏兆品,张羚,张国富*
1. 合肥工业大学计算机与信息学院,合肥 230601; 2. 大数据知识工程教育部重点实验室(合肥工业大学), 合肥 230601; 3. 智能互联系统安徽省实验室(合肥工业大学),合肥 230009; 4. 工业安全应急技术安徽省重点实验室(合肥工业大学),合肥 230601
0 引 言
隐写术是将秘密信息隐藏在用户难以察觉的常见媒介(如文本、图像、音频和视频等)中,以实现秘密信息和通讯行为的双重隐蔽,已成为网络空间安全的一个重点研究领域。音频隐写是利用人的听觉冗余和音频载体的统计冗余,在不损坏载体的前提下,将秘密信息嵌入到声音载体中。早期的音频隐写方法大都面向WAV(windows media audio)音频。Ahani等人(2015)利用离散小波变换(discrete wavelet transform,DWT)和稀疏分解将秘密消息嵌入到音频信号的更高语义层中。吴秋玲和吴蒙(2016)利用人耳听觉系统HAS(human audio system,HAS)对语音信号的中高频信息微小变化不敏感的特性,通过调节语音段小波变换的中高频系数,将秘密信息嵌入到小波域中。高瞻瞻等人(2017)基于汉明码设计了适用于低嵌入率隐写的校验矩阵构造方法,进一步提高了隐写效率。
随着VoIP(voice over internet protocol)技术的发展,以VoIP语音为载体的隐写逐渐成为研究热点。Huang等人(2012)发现在G.723.1编解码器中静音帧比活动帧更适合隐藏信息,提出了不同的最低有效位(least significant bit,LSB)匹配解决方案以实现更好的隐藏效果。田晖等人(2016)通过分析参数编码中语音帧的每个比特位对重构语音质量影响的不均衡性,提出一种基于LSB分级的自适应IP(internet protocol)语音隐写方法。高瞻瞻等人(2018)通过分析语音编码过程,建立了固定码本参数的贝叶斯网络模型,并应用矩阵嵌入技术确定载体的修改位置。上述工作均是在压缩编码后的语音码流中嵌入秘密信息,大都基于LSB替换法,仅考虑隐藏在不同样本中的比特位数,没有考虑语音流特征,容易带来可察觉失真,导致语音质量降级,且很难抵抗Chi-square test、RS(regular and singular)和SPA(sample pairs analysis)等混合统计分析方法的检测。
为了解决抗检测性问题,一些研究尝试将秘密信息嵌入与语音压缩编码过程同步进行。Liu等人(2017)基于线性预测编码过程,分别采用矩阵嵌入和量化索引调制(quantization index modulation,QIM)方法实现在G.729和G.723.1中的隐写。吴志军等人(2020)在G.723.1的基音预测编码过程中,通过控制自适应码本的搜索范围,结合随机位置选择和矩阵编码实现秘密信息嵌入。Ren等人(2018)通过将最优脉冲概率和脉冲相关性引入成本函数,并结合加性失真函数提出一种基于固定码本搜索和非零脉冲位置相关性的自适应多码率编码语音(adaptive multi-rate, AMR)自适应隐写方案。Ren等人(2019a)通过分析AMR自适应码本搜索中非静音和静音段的基音延迟分布,将嵌入位置自适应地放置在静音段中,并通过修改基音延迟来嵌入秘密消息。Yi等人(2019)提出一种通用的自适应霍夫曼编码映射框架,首先建立失真受限的可抑制编码空间,并基于等长熵编码实现秘密信息嵌入,然后利用隐秘密钥动态构建每个帧的霍夫曼编码映射,以增强不可感知性和统计抗检测性。Wu和Sha(2016)基于QIM方法,在互联网低比特率编解码器(internet low bit rate codec,iLBC)编码过程中的动态码本搜索阶段,通过构建二叉树的方式将码本分为左子树和右子树,提出一种FCB(fixed-codebook)隐写方法,不仅提升了隐写容量,还提升了语音质量。Huang等人(2017)基于线性频谱频率(linear spectrum frequency,LSF)系数量化进行iLBC语音隐写,用秘密信息控制码本的搜索范围,实现了一种QIMC(QIM-controlled)隐写方法。Su等人(2020)提出一种iLBC语音隐写(gain quantization based steganography,GQS)方法,通过对增益量化表的合理划分嵌入秘密信息,在保证不可感知性的前提下,追求更好的不可感知性和抗检测性。
上述隐写方法虽然在一定程度上能够提升隐写的抗检测性,但通常以牺牲隐写容量为代价。这些方法没有充分挖掘载体的隐藏潜能,很难在隐藏容量与抗检测性之间达到很好的平衡。而且随着基于深度学习的隐写检测技术的快速发展,使得基于压缩域的语音隐写抗检测性能大幅下降,给音频隐写研究带来新的挑战。对此,Lin等人(2018)提出一种有效的在线隐写分析(recurrent neural network based steganalysis model,RNN-SM)方法检测QIM隐写术。Gong等人(2019)针对ARM(adaptive multi-rate)在动态码本搜索阶段的隐写方法,提出一种基于循环神经网络和卷积神经网络的隐写分析器SRCNet(steganalysis based on recurrent convolutional networks),通过结合时域和空域两方面的相关性取得了较好的隐写分析性能。Ren等人(2019b)提出一种通用的音频隐写分析方案SpecResNet(deep residual network of spectrogram),利用语谱图作为通用特征,结合深度残差网络进行隐写分析。Yang等人(2020a)利用注意机制解决压缩流中基于QIM隐写术的隐写分析问题,并设计一种基于多头注意力的轻量级神经网络快速相关提取模型FCEM(fast correlation extract model)。此外,为了满足在线隐写分析,Yang等人(2020b)在RNN-SM的基础上使用一个隐藏层提取载波码字之间的相关性,设计了一种快速VoIP流隐写分析方法 EFSM(extremely fast steganalysis method)。
基于上述背景,本文以iLBC语音为研究对象,提出一种大容量iLBC语音隐写分层方法,根据秘密信息量自动选择嵌入位置,在提升隐写容量的前提下,力求在不可感知性与抗检测性能之间能够达到一个较好的均衡。
1 iLBC语音隐写位置的分层
iLBC是一种专为包交换网络通信设计的语音编解码器,解决了语音传输中网络丢包严重影响通话质量的实际问题,在实时通信系统(如电话系统、视频会议、语音流和及时消息等)领域得到了广泛应用。
iLBC编码支持20 ms和30 ms两种帧长度编码, iLBC语音隐写通常基于QIM方法在LSF系数的矢量量化过程(Huang等,2017)、动态码本搜索过程(Wu和Sha,2016)和增益量化过程(Su等,2020)中进行。以30 ms帧为例,在LSF系数矢量分两组量化的各个子阶段中均能嵌入3 bit,分别记为LQ_1和LQ_2;在动态码本搜索过程,5个矢量分别进行3阶段的搜索,每个阶段可以嵌入5 bit,分别记为BS_1、BS_2和BS_3;在增益量化过程,同样需要对5个矢量分别进行3阶段的增益系数量化,每个阶段可以嵌入5 bit,分别记为GQ_1、GQ_2和GQ_3。
图1为iLBC编码过程与隐写位置分布的关系示意图。在iLBC编码过程中,首先进行线性预测系数(linear predictive coefficient,LPC)分析,得到的LPC系数对每一个语音的子帧计算残差值,除开始状态外,其余5个子帧采用基于动态码本搜索的矢量量化方法进行编码。在矢量量化的每个阶段,在众多的码本中搜索与感知加权矢量最匹配的矢量后,再计算相应的增益值并对其量化。通过对iLBC编码比特流结构的分析,发现LSF系数占据大量最敏感的第1类比特,而矢量量化模块中的增益量化参数占据敏感比特位的数量远少于LSF系数。众所周知,编码参数占据敏感比特位的数量越少,表明对该参数进行修改导致的失真影响也越小。因此,由上述iLBC编码过程可以看出,不同隐写位置所处的阶段和起到的作用差别很大,需要进一步分析其隐写性能。
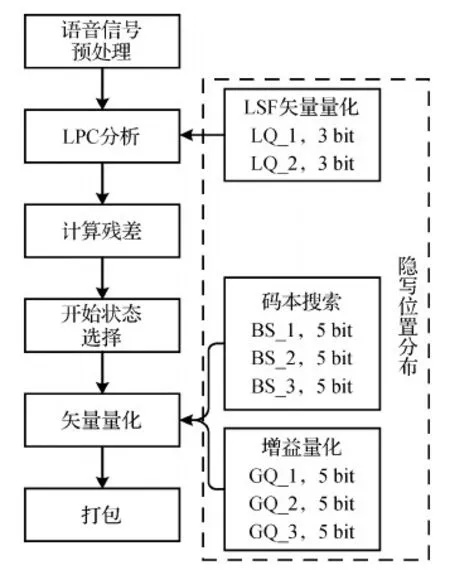
图1 iLBC编码过程与隐写位置分布的关系示意图Fig.1 Relationship between iLBC coding process and embeddable positions
为了分析不同隐写位置对语音不可感知性的影响,以语音主观质量评估PESQ-MOS(perceptual evaluation of speech quality-mean opinion score)和平均梅尔倒谱失真(Mel-cepstral distortion,MCD)为评价指标,在时长为2 s、5 s和10 s的语音上进行测试,每种时长的语音均有440条。
PESQ-MOS是采用ITU-TP.862标准给出的一种客观MOS语音质量评价方法,这是目前与主观语音评价质量相关度最高的方法,该评价方法的结果是一个数值,取值范围在1.0-4.5之间。PESQ-MOS值越大,表明隐写语音的失真越小,不可感知性越好。MCD是在语音数据失真测度基础上,利用距离准则测量隐写前后语音的相似程度。具体为
(1)

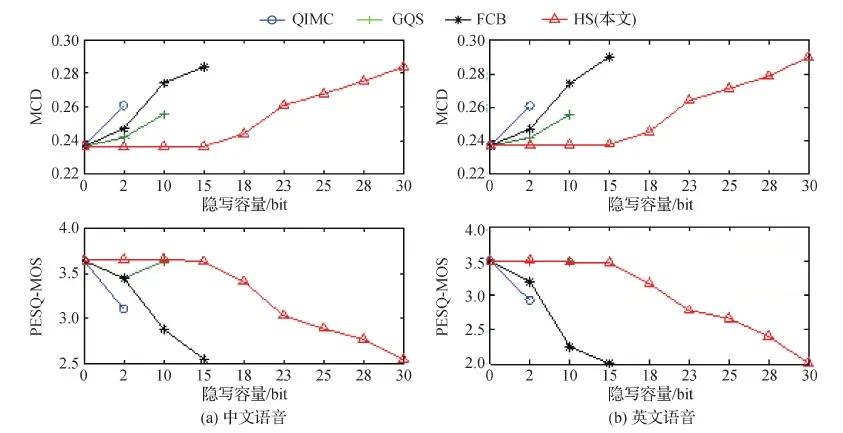
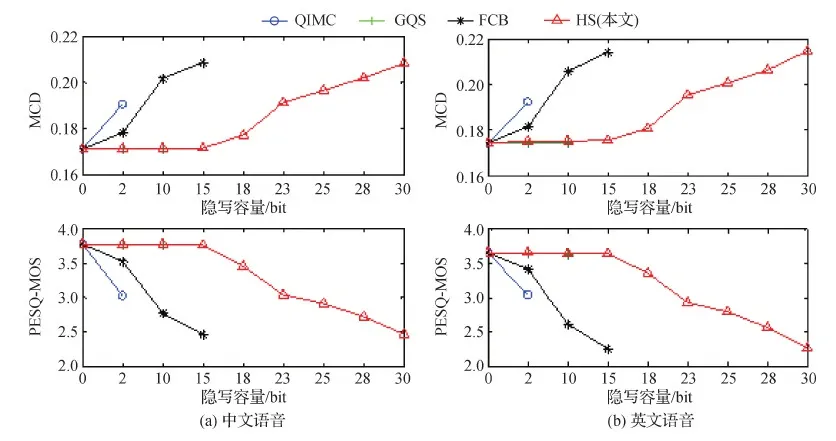
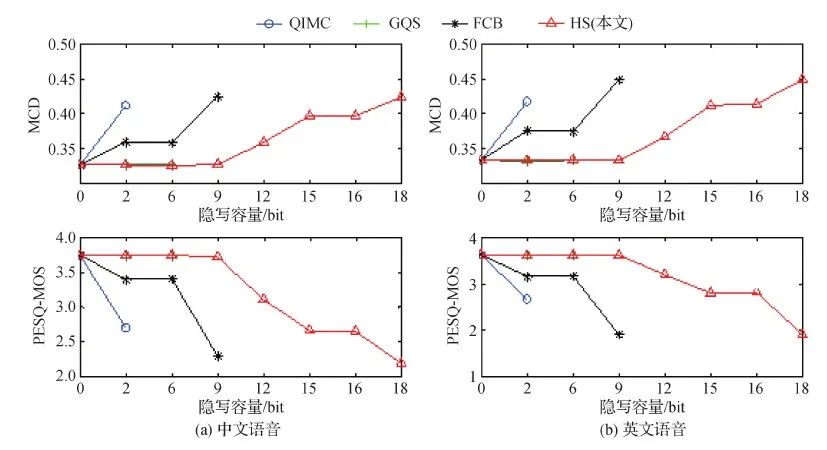
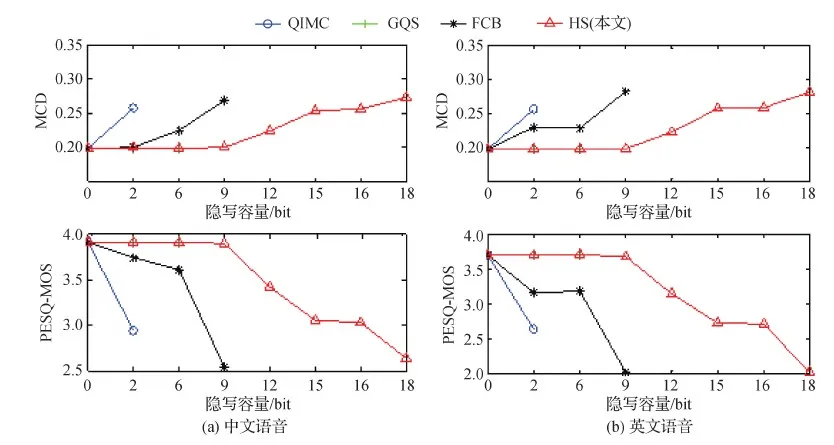
首先,对每种时长取8个语音样本,在不同位置进行隐写,MCD和PESQ-MOS的测试结果分别如图2和图3所示。可以看出,在2 s、5 s和10 s音频上,在GQ_1、GQ_2和GQ_3位置隐写,MCD和PESQ-MOS值均为最佳,具有最好的不可感知性;在BS_3和BS_2上隐写,MCD和PESQ-MOS值也比较理想,不可感知性较好;在BS_1上隐写,MCD和PESQ-MOS值适中,不可感知性较差;而在LQ_1和LQ_2上隐写,MCD和PESQ-MOS值均为最差,不可感知性最差。

图2 不同时长下不同隐写位置的MCD结果Fig.2 MCD test results of different embeddable positions under different speech lengths((a) 2 s speech; (b) 5 s speech; (c) 10 s speech)

图3 不同时长下不同隐写位置的PESQ-MOS结果Fig.3 PESQ-MOS test results of different embeddable positions under different speech lengths((a) 2 s speech; (b) 5 s speech; (c) 10 s speech)
为进一步验证上述分析结果,对每种时长下的440条语音进行测试,分别求MCD和PESQ-MOS的平均值,实验结果如图4所示。可以看出,随着音频时长的增加,不可感知性越来越好。但综合来看,GQ_1、GQ_2和GQ_3对隐写最不敏感,BS_3和BS_2稍有下降,BS_3敏感性适中,LQ_1和LQ_2位置对隐写非常敏感。
根据上述分析结果,对于30 ms 的iLBC语音帧,本文将隐写位置分为3个层次,如图5所示。每一行表示一种隐写位置,每一列VQi(vector quantization)表示一个矢量量化经历的编码过程,每个隐写位置的数字表示该位置在iLBC编码过程中的先后顺序,不同深浅的颜色代表隐写位置的不同层次,颜色越浅,不可感知性越好,颜色越深则不可感知性越差。
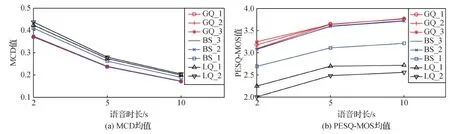
图4 不同时长下不同隐写位置的不可感知性结果Fig.4 Imperceptibility test results of different embeddable positions under different speech lengths((a) average MCD; (b) average PESQ-MOS)

图5 iLBC隐写位置的分层模型Fig.5 Hierarchical model of iLBC embeddable positions
2 大容量iLBC语音分层隐写方法
2.1 分层隐写
基于QIM技术,每个iLBC帧可隐写的最大比特数为30位。当给定隐写比特数n,在满足1≤n≤30时,应尽可能地将秘密信息隐写在对语音影响较小的位置,最大程度降低隐写带来的失真,以保证隐写音频具有最佳的不可感知性。基于上述思想,本文设计了一种分层隐写方法,如图6所示。
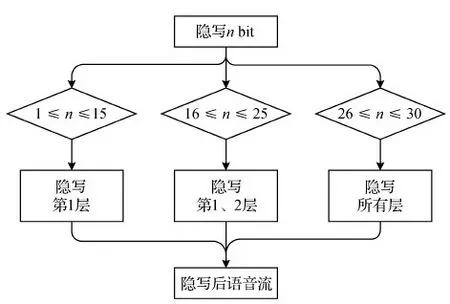
图6 iLBC语音分层隐写方案Fig.6 Hierarchical steganography scheme for iLBC speech
具体来说,优先选择第1层,其次是第2层、第3层。例如,当n=18,首先在第1层GQ_1、GQ_2和GQ_3位置上嵌满15 bit,此时第1层称为满嵌层;剩余3 bit嵌入在第2层BS_2和BS_3中,由于第2层共有10个嵌入位置,不需要嵌满,此时称第2层为未满层。
2.2 未满层嵌入位置选择
在未满层隐写信息时,如果嵌入位置是固定且相邻的,则容易改变语音本身的特征,从而极易检测出秘密信息。为此,本文提出一种基于Logistic混沌映射的嵌入位置选择方法,在未满层通过Logistic混沌映射随机选择嵌入位置,以提升未满层隐写的随机性和安全性。
Logistic混沌映射是来自非线性动力系统的1维混沌系统。具体为
Xm+1=μ×Xm×(1-Xm)
(2)
式中,m表示计算混沌随机数的次数,μ表示混沌映射公式的系数,Xm表示上一个混沌映射值,Xm+1表示由Xm计算得到的下一个混沌映射值。当μ∈(3.6,4)、X0∈(0,1)时,Logistic映射工作处于混沌状态,其产生的序列是非周期的和不收敛的(May,1976)。
本文利用Logistic混沌映射产生的随机序列来选择未满层的隐写位置。设未满层共有L个嵌入位置,基于Logistic混沌映射选择k个嵌入位置的具体步骤如下:
1)为L个嵌入位置设置隐写标签tag(j),j=0,1,…,L-1,并初始化为0。
2)根据Xm-1和μ,基于式(2)得到随机小数Xm,将Xm乘以1 000并取整,得到随机整数X′m。最后将X′m对未满层的隐写总比特数取余,获得该未满层的隐写位置索引j,即j=X′mmodL。
3)如果tag(j)=0,则在该未满层的隐写位置索引j处隐写,并赋值tag(j)←1;否则m=m+1,转步骤2)。
4)继续上述过程,直到找到k个隐写位置为止。
以n=18为例,第2层为未满层,可能隐写的位置共10个,需要从中确定3个位置进行隐写。假设X0=0.52,μ=3.9,在此帧之前已经计算混沌随机数49次,且X49=0.437,根据式(2),可得X50=0.959,X51=0.15,X52=0.498,由此可得嵌入位置9、0和8,对应图5中的29、3和23这3个位置。
2.3 嵌入方法描述
本文所提的大容量iLBC语音分层隐写方法HS(hierarchical steganography)的基本流程如下:
1)初始化。iLBC语音流S帧, 秘密信息M比特,混沌初始值X0,混沌系数μ。
2)计算每帧嵌入比特数:n=M/S。如果n>30,则通过扩展音频帧来实现n≤30。
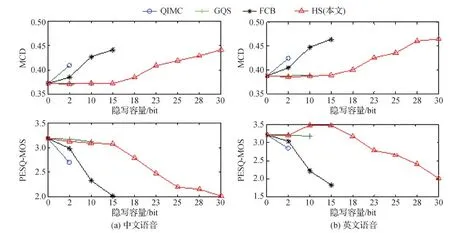
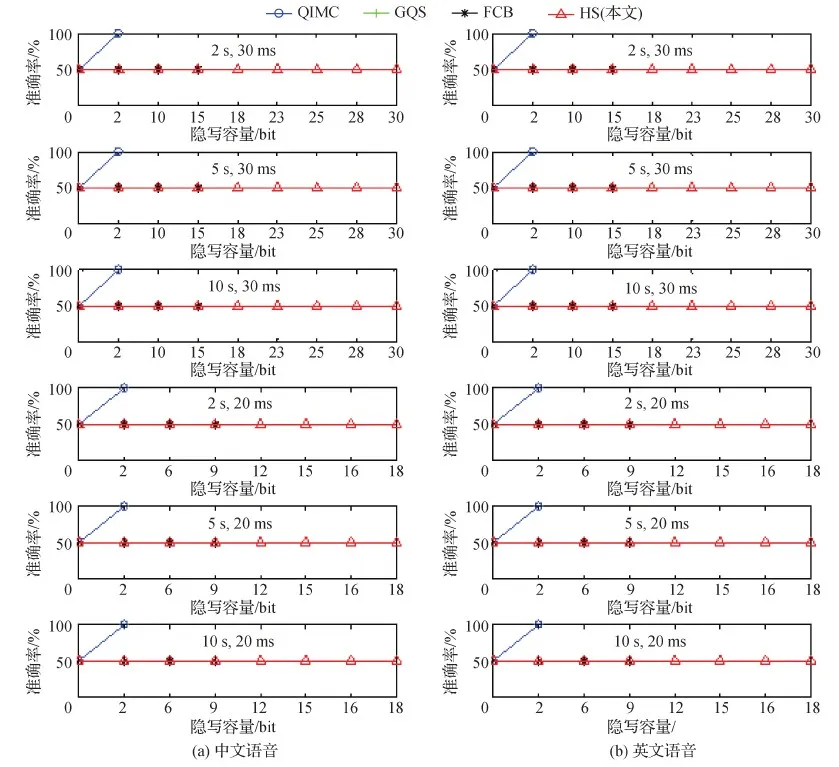
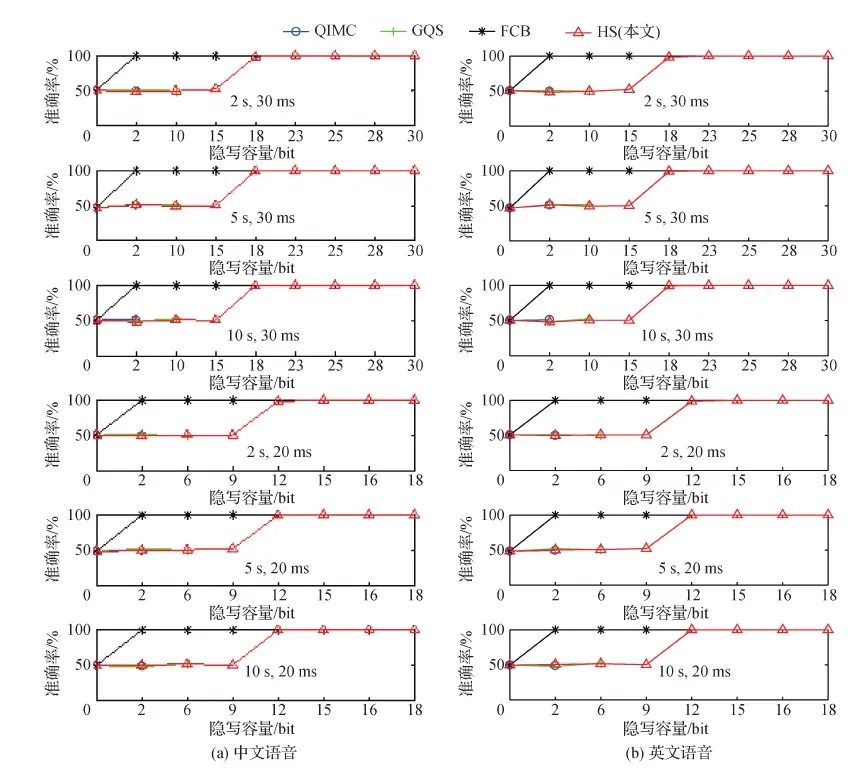
3)对于每一帧,如果0 4)重复步骤3),直至所有帧嵌入完成。 为了验证本文HS方法的有效性,从隐写容量、不可感知性和抗隐写分析3个方面与QIMC(Huang等,2017)、FCB(Wu和Sha,2016)和GQS(Su等,2020)等方法进行对比实验。上述3个方法均可对iLBC语音进行隐写。 测试语音采用Lin等人(2018)制作的中英文语音数据集SSD(steganalysis-speech-dataset)(https://github.com/fjxmlzn/RNN-SM),样本格式均是8 kHz采样、16 bit量化的标准PCM(pulse-code modulation)信号。为了对比的充分性,考虑了30 ms和20 ms两种帧长,以及2 s、5 s和10 s这3种不同的样本长度,每种情况下的语音各440条,共5 280条。 所有对比方法的代码均基于C++ 编写,并在Intel (R) Core (TM) i5-8500 CPU @ 3.00 GHz、RAM 16.0 GB、Windows 10操作系统的个人PC上进行测试。 以30 ms帧为例,LSF系数量化有6次码本搜索,使得QIMC方法最多可以隐藏6 bit;动态码本搜索有15次码本搜索,FCB最多可以隐藏15 bit;GQS在增益量化的后两个阶段嵌入,最多可隐写10 bit; 本文HS方法将上述方法进行融合,最多可以隐写30 bit。表1给出了不同隐写方法在30 ms和20 ms帧格式下每帧可隐写的最大比特数。可以看出,本文HS方法显著提高了隐写容量,在30 ms帧和20 ms帧上均提升了1倍。 表1 不同方法的隐藏容量Table 1 Steganography capacity of different methods /bit 实验对每种情况下的440条语音进行不可感知性测试,并计算PESQ-MOS和MCD的均值。 图7—图9给出了4种隐写方法在30 ms帧长、不同语言、不同时长和不同嵌入量的不可感知性测试结果。可以看出,当本文HS方法每帧嵌入约23 bit的秘密信息时,其不可感知性几乎可以接近QIMC方法嵌入2 bit时的性能,而隐写容量提升了10多倍。当HS方法每帧嵌入30 bit时,其不可感知性与FCB最大隐写时的性能相差无几,而隐写容量提升了1倍;当HS方法每帧嵌入15 bit时,其不可感知性接近GQS最大隐写时的性能,而隐写容量提升了50%。 图7 不同方法在2 s语音、30 ms帧下的不可感知性结果Fig.7 Imperceptibility test results of different methods under 2 s speech and 30 ms frame((a) Chinese speech; (b) English speech) 图8 不同方法在5 s语音、30 ms帧下的不可感知性结果Fig.8 Imperceptibility test results of different methods under 5 s speech and 30 ms frame((a) Chinese speech; (b) English speech) 图9 不同方法在10 s语音、30 ms帧下的不可感知性结果Fig.9 Imperceptibility test results of different methods under 10 s speech and 30 ms frame((a) Chinese speech; (b) English speech) 图10—图12给出了4种隐写方法在20 ms帧长、不同语言、不同时长和不同嵌入量下的不可感知性结果。可以看出,当HS方法每帧嵌入16 bit的秘密信息时,其不可感知性接近QIMC方法隐写2 bit时的性能,而隐写容量提升了7倍。当HS方法每帧嵌入18 bit时,其不可感知性与FCB最大隐写时的性能相差无几,而隐写容量提升了1倍;当HS方法每帧嵌入9 bit时,其不可感知性接近GQS最大隐写时的性能,而隐写容量提升了50%。 图10 不同方法在2 s语音、20 ms帧下的不可感知性测试结果Fig.10 Imperceptibility test results of different methods under 2 s speech and 20 ms frame((a) Chinese speech; (b) English speech) 图11 不同方法在5 s语音、20 ms帧下的不可感知性结果Fig.11 Imperceptibility test results of different methods under 5 s speech and 20 ms frame((a) Chinese speech; (b) English speech) 上述实验结果表明,与QIMC、FCB和GQS方法相比,本文HS方法在显著提升隐写容量的情况下,仍保持了较好的不可感知性,并没有因为写入额外秘密信息而导致音频过度失真。 为了检验本文HS方法抵抗隐写分析的能力,实验基于最新的深度学习隐写分析器SpecResNet(Ren等,2019b)、SRCNet(Gong等,2019)、FCEM(Yang等,2020a)和EFSM(Yang等,2020b)进行测试。 为了对比的充分性,数据集考虑了中、英两种语言、30 ms和20 ms两种帧长,以及2 s、5 s和10 s这3种不同样本长度。在每种情况下,均包含4 000条原始语音和4 000条隐写后的语音,其中75%作为训练集,25%作为测试集。 为了衡量信息隐写的抗检测分析能力,采用检测准确率作为评价指标,即判断正确的样本数(样本实际为载密音频预测为载密音频的个数+样本实际为载体音频预测为载体音频的个数)除以测试的样本总数。 图13给出了4种隐写方法在FCEM分析器上的检测结果。可以看到,对于QIMC方法,在写入。 图14 不同隐写方法在EFSM分析器上的检测结果Fig.14 Detection results of different methods on the EFSM ((a) Chinese speech; (b) English speech) 2 bit时很容易被FCEM分析器检测出来。对于FCB和GQS两种方法,在30 ms帧上,当每帧的隐写比特数小于等于15时,FCEM分析器的检测准确率为50%;在20 ms帧上,当每帧的隐写比特数小于等于9时,FCEM分析器也很难检测出来。而本文HS方法在30 ms帧上0-30 bit范围、在20 ms帧上0-18 bit范围均呈现出很好的抗检测性。上述实验结果表明,FCB、GQS和HS 3种隐写方法对FCEM分析器具有很好的抗检测性,但HS具有更高的隐写容量。究其原因,FCEM提取的是LSF域的索引特征,无法感知到FCB、GQS和HS 3种方法的音频特征。 图14给出了4种隐写方法在EFSM分析器上的检测结果。同样,对于QIMC方法,在写入2 bit时很容易被EFSM分析器检测出来。对于FCB和GQS 两种方法,无论是在30 ms帧还是在20 ms帧上,当每帧的隐写比特数小于等于15或9时,EFSM分析器的检测准确率都为50%,无法区分。此外,本文HS方法在30 ms帧上0-30 bit范围、在20 ms帧上0-18 bit范围也呈现出很好的抗检测性。上述实验结果表明,FCB、GQS和HS 3种隐写方法对EFSM分析器也具有很好的抗检测性。究其原因,EFSM虽然在FCEM的基础上通过精简网络结构提升了计算效率,但提取的仍然是LSF域的索引特征,同样无法感知FCB、GQS和HS的音频特征。 图13 不同隐写方法在FCEM 分析器上的检测结果Fig. 13 Detection results of different methods on the FCEM ((a) Chinese speech; (b) English speech) 图15给出了4种隐写方法在SRCNet分析器上的检测结果。对于FCB方法,在写入2 bit时很容易被SRCNet分析器检测出来。对于QIMC和GQS 两种方法,当每帧的隐写比特数,在30 ms帧上小于等于10,在20 ms帧上小于等于6时,SRCNet分析器的检测准确率都为50%,无法区分。此外,本文HS方法在30 ms帧上0-15 bit范围、在20 ms帧上0-9 bit范围也呈现出很好的抗检测性。上述实验结果表明,QIMC和GQS两种隐写方法对SRCNet分析器具有很好的抗检测性。究其原因,SRCNet是一种专门针对FCB隐写的分析器,而本文HS方法整合了FCB和GQS。但需要指出的是,HS方法在隐写容量上仍然比GQS在30 ms帧上多了5 bit、在20 ms帧上多了3 bit。 图15 不同隐写方法在SRCNet分析器上的检测结果Fig.15 Detection results of different methods on the SRCNet ((a) Chinese speech; (b) English speech) 从上述实验结果可以看出,FCEM和EFSM只能捕获LSF系数的隐写特征,难以检测FCB、GQS和HS 3种方法的隐写样本,而SRCNet只能分析FCB和HS的一部分。为了进一步进行对比,图16给出了4种隐写方法在通用SpecResNet分析器上的检测结果。可以看出,对于QIMC方法,在写入2 bit时同样容易被SpecResNet分析器检测出来。GQS在30 ms帧和20 ms帧上均具有很好的抗检测性。当隐写容量小于等于2 bit时,FCB在30 ms帧和20 ms帧上均具有较好的抗检测性,当隐写容量超过2 bit时,FCB在SpecResNet上的检测准确率达到80%以上,难以抵抗SpecResNet分析器的检测。对于HS方法,在30 ms帧上,当每帧隐写比特数小于等于18时,HS具有很好的抗检测性能;在20 ms帧上,HS在0-12 bit范围内呈现出较好的抗检测性;但随着隐写容量的增加,HS的抗检测性能降低,这是因为SpecResNet提取的是语谱图特征,只要有隐写发生,即使是很小的隐写量,语谱图特征也会发生变化,所以随着隐写容量的增加,语谱图特征变化越来越明显,模型就越容易判别出隐写的音频样本,致使检测准确率不断提升。 图16 不同隐写方法在SpecResNet分析器上的检测结果Fig.16 Detection results of different methods on the SpecResNet((a) Chinese speech; (b) English speech) 综合3种深度学习隐写分析器的检测,QIMC几乎无法抵抗;GQS在30 ms帧上10 bit以内、20 ms帧上6 bit以内可以很好地抵抗;FCB在2 bit以内可以很好地抵抗;本文HS方法在30 ms帧上18 bit以内、20 ms帧上12 bit以内可以很好地抵抗。这表明本文HS方法在进一步提升隐写容量的基础上,保持了较好的抗检测性。 音频隐写术是利用人的听觉冗余和音频码流的统计冗余,将秘密信息隐藏于音频文件之中而不损坏音频的质量,以实现秘密信息的安全传递。但是在辨别微小失真方面,人的听觉系统非常敏感。因此如何在隐写容量、不可感知性和抗检测性之间达到一个理想均衡是音频隐写面临的一个难点。本文针对iLBC语音流,首先分析了LSF系数量化、动态码本搜索和增益量化3个阶段中的QIM隐写对不可感知性的影响,分别设计了一种iLBC语音隐写位置分层方法和一种基于Logistic混沌映射的未满层嵌入位置选择方法,并提出了一种大容量iLBC语音分层隐写方法,可根据嵌入量的多少动态选择隐写的层次。对比实验结果表明,本文方法可以充分挖掘iLBC的隐写潜能,在提升隐写容量的前提下,仍能保证良好的不可感知性和抗检测性。 但是,本文只是针对大容量iLBC语音隐写研究的一个初步尝试,在未来仍有许多工作需要深入研究。首先,需要考虑所提方法的鲁棒性,即需要测试在一些常规信号处理等攻击下,能否有效提取秘密信息。其次,需要深入分析iLBC码流结构,设计一种更加通用的音频隐写方法,以提升在大嵌入量下的抗隐写分析性能。3 实验结果与分析
3.1 隐写容量分析

3.2 不可感知性测试
3.3 抗检测性测试


4 结 论
