面向古籍数字人文的《资治通鉴》自动摘要研究
——以SikuBERT预训练模型为例*
2022-12-15徐润华王东波
徐润华,王东波,刘 欢,梁 媛,陈 康
0 引言
古籍文献是中华文化的璀璨瑰宝,21世纪以来,数字人文(Digital Humanities)开辟了古籍文献信息化处理乃至知识挖掘新思路和途径。目前针对古籍文献的信息处理研究在自动分词、词性标注、命名实体识别等领域取得突破,但对古籍文献特别是篇幅较长的古籍文献进行自动摘要的尚未涉及。通过自动摘要任务可以给古籍文献贴上清晰易懂的标签,降低古文阅读门槛,也为计算机深度挖掘提供便利,促进中华文化传承和发展。学术界针对古籍文献的自动摘要研究尚处于空白阶段,据此,本文提出基于SikuBERT和SikuRoBERTa预训练模型的古籍文献自动摘要方法。
1 研究综述
(1)面向古籍文献信息处理的数字人文研究。数字人文是信息技术与人文学科相交叉、相融合的研究领域,面向古籍文献的数字人文研究中,学者多采取语言计算模型和深度学习方法对古籍文献开展深度挖掘等研究[1]。近年随着数字技术的迅速发展,LSTM、CNN等深度学习模型在古文自动处理领域得到广泛应用[2],但随着模型结构复杂度提升,昂贵的标注成本与时间成本制约模型性能的提升[3]。Devlin等提出深度学习模型BERT[4],能在未标注的大规模语料上自主学习通用文本表示与语言特征,在面向下游任务时仅需要少量标注数据集即可取得超越深度学习模型的表现,因此成为新的研究热点。
(2)古籍文献自动分词及词性标注。自动分词是中文信息处理的基础性应用课题,是计算机理解文本内容的起点。对古籍文献进行自动分词需考虑到古文词汇语法特征,难度很大。在面向古籍文献的自动分词过程中,基于统计机器学习的方法是目前主流的分词方法。比如,刘畅等[5]基于SikuBERT预训练模型对记载春秋至魏晋的6部具有代表性的官修史籍进行多组对比实验,构建古籍文献分词语料库并开发面向古籍文献的分词工具。
词性标注是在自动分词基础上进行的更深一层级的标注,对古籍文献进行词性标注可以为词语标注对应的词性,帮助计算机更好理解古籍文本。比如,耿云冬等[6]使用人工校对后的高质量古籍文献《四库全书》语料作为模型的训练集,利用SikuBERT模型构建预训练语言模型,进行词性标注实验,发现利用SikuBERT模型进行古籍文献的词性标注可以取得优异的效果。
(3)古籍文献实体识别及自动分类。对古籍文献进行自动分词、词性标注等基础的加工标注,是为后续开展更深层面的词汇知识挖掘任务做准备,如命名实体识别、文本自动分类,这些都是古籍文献信息处理过程中的关键环节。随着深度学习技术的发展,基于深度学习的语言计算模型被应用于古籍文献的信息处理。比如,朱锁玲等[7]采用基于规则和基于统计相结合的方法来识别命名实体,以《方志物产》作为实验语料,实现了对物产地名进行命名实体识别的目标。
(4)自动摘要方法研究。自动摘要技术旨在对海量信息进行压缩和提炼,提高知识获取效率。自动摘要技术的产生和发展为信息利用效率低下、阅读成本过高等问题提供了解决途径。自动摘要技术主要有抽取式自动摘要和生成式自动摘要两种。抽取式自动摘要技术研究起步早、成熟度高,随着深度学习技术的发展,生成式自动摘要技术因能达到生成更流畅、更易于阅读和理解的高质量文本摘要的目的,而受到广泛关注。比如,王永成等[8]提出基于OA系统的中文文献自动摘要系统,并归纳中文自动摘要的历史、现状和意义;谭金源等[9]融合多个深度学习模型,分别提出基于BERT和指针生成网络的生成式自动摘要模型,实验表明融合后的模型能改善自动摘要内容的流畅度和准确性。
综上,在数字人文研究浪潮和深度学习技术发展背景下,针对古籍文献的信息处理研究已经进入结构化程度更高的层面且取得丰硕成果,但对古籍文献自动摘要领域的研究鲜有学者涉足。古籍文献的时代语言特点和过长篇幅使得自动摘要研究迫在眉睫。据此,本文面向古籍文献的自动摘要任务,基于SikuBERT 和SikuRoBERTa预训练模型进行《左传》《资治通鉴》的自动摘要实验,探索对古籍文献自动摘要思路。
2 预训练语言模型
2.1 SikuBERT模型
BERT(Bidirectional Encoder Representa-tions from Transformers)[4]模型基于预训练和微调两部分的形式进行构建。在预训练阶段,BERT采用双向语言模型,即通过掩码语言模型(Masked Language Model,MLM)随机遮蔽输入序列中的词汇,以自监督方式使得模型利用前后两个方向的信息预测词汇,从而获得双向深层文本表示。该模型还引入下一句预测(Next SentencePrediction,NSP)任务学习句子关系。BERT的提出在预训练模型发展史上具有里程碑意义[10],催生了大批改型。SikuBERT 模型是基于BERT框架,在BERT-base-Chinese模型上继续训练得到的,使用的训练数据集为文渊阁版的繁体字《四库全书》全文语料。与原始BERT模型相比,在预训练过程中仅保留掩码语言模型任务,移除对性能提升表现不佳的下一句预测任务。图1是SikuBERT模型的预训练过程示例。对输入语句,随机遮蔽15%字符并采用[MASK]标记替代,基于双向Transformer的编码器,使得模型以自监督的方式从前后两个方向同时预测被遮蔽字符,从而更有效地学习到典籍文本的文法、句法、语言风格等特征。
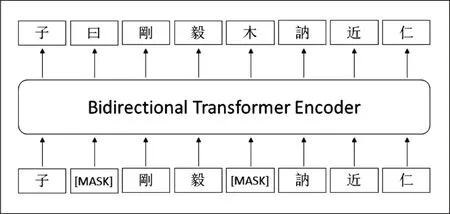
图1 SikuBERT模型预训练示意图
2.2 SikuRoBERTa模型
RoBERTa(Robustly optimized BERT approach)[11]对BERT模型进行三大优化:更深度的训练方法、更有效的掩码方式、更全面的输入表示。在训练中,采用更大的训练集、更长的训练时间,通过FULL-SENTENCES 方式输入更长的连续文本,以动态掩码(Dynamic Masking)替代原始的静态掩码,提升了训练集利用率。该模型还移除BERT的NSP任务,扩充了词表大小。BERT-wwm[12]模型针对中文词汇与英文词汇的不同,将BERT原始字符级别的掩码机制替换为全词掩码(Whole Word Masking,WWM)的方式,即对输入序列中的任意词汇,只要一个汉字被遮蔽剩余全部汉字均会被遮蔽,让模型在预训练阶段预测整个被遮蔽的中文词汇,从而提升模型对中文构词规则的学习能力。ERNIE(Baidu, Enhanced Representation through Knowledge Integration)[13]在 BERT 字 符 掩码的基础上额外增加了中文实体层面掩码和短语层面的掩码,从而引入更多外部知识。ERNIE(THU, Enhanced Language Representation with Informative Entities)[14]将知识图谱中的命名实体信息与原始文本信息对齐后共同作为模型输入,从而引入了外部的实体信息以增强原始的文本表示,最终在知识驱动型等任务上取得了超越BERT 的效果。MASS[15]针对序列到序列的任务,提出了一种序列掩码训练(Masked Sequence to Sequence Pre-training)的方式,对于输入文本序列,直接遮蔽指定长度的连续文本段,通过训练实现对词汇间依赖关系的语言建模。该模型在摘要生成、自动翻译、对话生成等任务上表现较优。
SikuRoBERTa模型是基于中文版RoBERTawwm模型在《四库全书》全文语料上预训练后构建的。与原始RoBERTa模型不同的是,Ro-BERTa-wwm模型在采用掩码语言模型预训练的过程中采用全词遮蔽技术,实现对中文文本词汇层面的遮蔽,从而使得模型能够更进一步学习到深层的中文词义与词法信息。SikuRoBERTa在保留了RoBERTa-wwm模型优势的基础上,进一步从5亿余字的《四库全书》全文语料上学习了古代汉语的遣词造句与语言学信息,并提升了在繁体文本上的表现。
3 《资治通鉴》语料数据
3.1 数据源简介
《资治通鉴》是由司马光主编的多卷本编年体史书,共294 卷,主要以时间为纲、事件为目,上起周威烈王二十三年,下迄后周显德六年。全书按朝代分为十六纪,见表1。本文通过网络爬虫方式获取繁体字版本《资治通鉴》子部全文语料,未经过加注标点符号,也无断句标记。除标题、目录、编撰人信息等,正文文本均以段落作为最小单位进行组织。
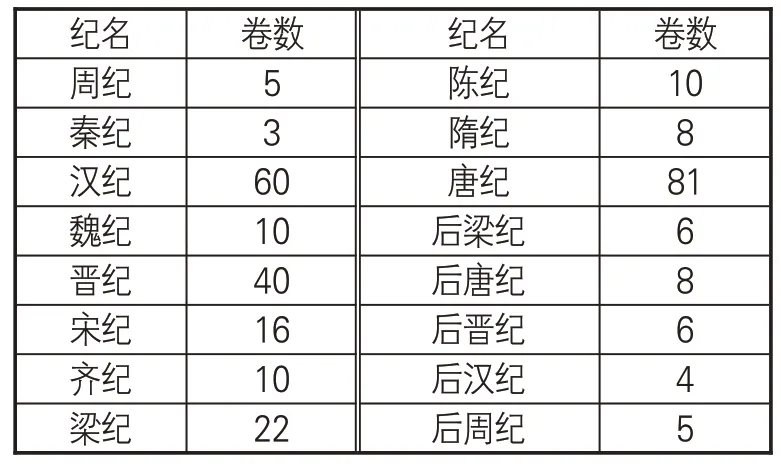
表1 《资治通鉴》十六纪详细信息
3.2 数据标注
使用SikuBERT 预训练模型对《资治通鉴》全文进行自动断句和自动分词,词语间隔标记使用空格。分词结果示例:“/休之/谓/王友/王晞/曰/:/昔/周公/朝/读/百/篇/书/,/夕/见/七十/士/,/犹/恐/不/足/。”根据分词单位的长度,本文将分词结果划分为3种类型:单字词、双字词、多字词(3字及以上)。每种长度词语的数量及占比如表2所示,单字词数量最多,其次为双字词和多字词,多字词多为人名、地名等命名实体词汇。古籍文献中的单字词居多现象给自动摘要任务带来更多困难。
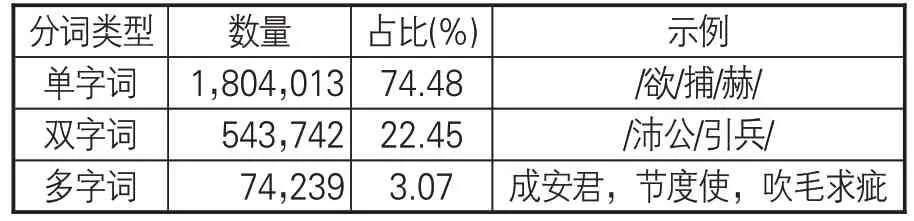
表2 《资治通鉴》分词结果
3.3 语料统计
《资治通鉴》全文数据共包含29,951 个段落、3,151,726 个字符。按照《资治通鉴》全文、十六纪每纪平均、294卷每卷平均分别统计词数、句子数、平均句长、最大句长、段落数、标点数等数据,见表3。《资治通鉴》篇幅长,达到300 万词次规模,平均句长只有20.95849,远低于现代汉语的句长均值区间,较长篇幅和较短的句长使得对《资治通鉴》进行自动摘要任务的难度增加。根据每纪和每卷篇幅情况,每卷篇幅长度更适合作为自动摘要的单篇文档进行处理,且从内容角度每卷记载均为特定年代所发生事情,对其进行摘要抽取也更具有理据性。
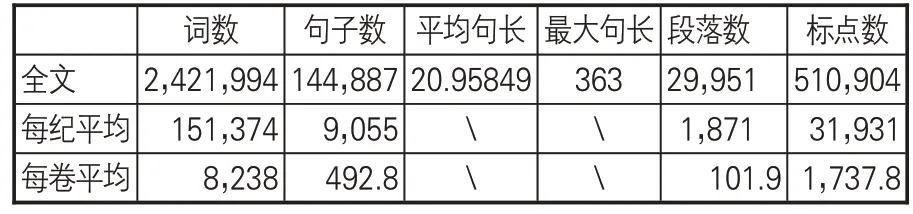
表3 《资治通鉴》词、标点、句子、段落信息统计
4 实验设计及分析
4.1 实验框架和数据预处理
本研究的实验框架见图2。利用SikuBERT和SikuRoBERTa预训练模型对《资治通鉴》进行自动断句和自动分词后,对文本进行内容清洁,包括清除多余空格、空行,以及自动侦测断行位置并合并段落等。由于通过网络获取的《资治通鉴》文本并没有卷名信息,利用每卷的格式特征编写算法自动生成294卷的卷名信息,经过数据预处理后的《资治通鉴》全文语料预览效果见图3。
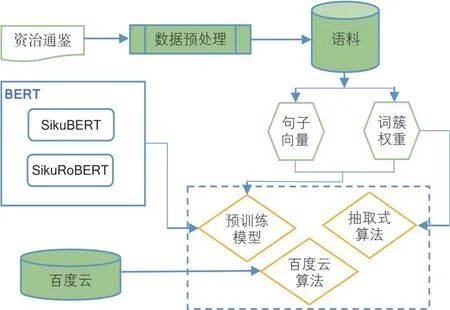
图2 《资治通鉴》自动摘要实验框架
图3 《资治通鉴》全文语料预览效果
4.2 基于抽取式算法的自动摘要实验
本研究中的抽取式自动摘要算法采用的是按词频和簇确定关键词,再通过关键词对所在句打分,分数排序确定最终生成摘要的句子。用簇(cluster)表示关键词的聚类结果,这里的簇即包含多个关键词的句子片段,见图4。通过句子相似度矩阵以及设定的阈值来获得得分较高的句子作为自动摘要结果,这是一种无监督的抽取式自动摘要。
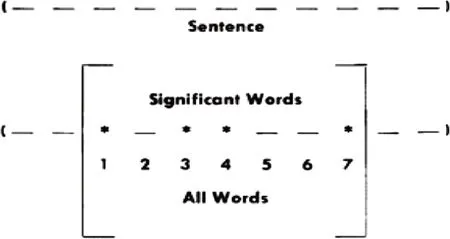
图4 关键词簇聚类示意图
簇权重的计算公式为:

其中,簇长通常指一簇中包含词语的数量,截取本文选取的《资治通鉴》语料为例,“行军总管杞公亮,天元之从祖兄也”,该句分词结果为“行军/总管/杞公/亮/,/天元/之/从/祖兄/也”。设“行军总管杞公亮”为一簇,簇长为4,“行军”“总管”“杞公”“亮”为关键词,“天元之从祖兄也”为另一簇,簇长为5,关键词为“天元”“从”“祖兄”,则两簇权重分别为42/4=4和32/5=1.8。按权重对文本包含的句子进行排序,确定抽取阈值。本文设定的抽取阈值为30,即抽出重要性最高的前30个句子,将这30个句子整合,即为该文本的自动摘要结果。抽取式自动摘要算法实验主要包括6个步骤:一是《资治通鉴》文本预处理,包括去除特殊字符和空格空行等;二是分词,将预处 理 文 本 输 入SikuBERT 典籍智能处理系统中,进行自动分词处理,获得《资治通鉴》分词语料;三是去停用词和词频统计;四是计算句子权重并进行排序;五是选定合适的阈值提取摘要句;六是生成摘要。
4.3 基于预训练模型的自动摘要实验
(1)模型选取。本实验采用的SikuBERT预训练模型是由南京农业大学、南京理工大学、南京师范大学联合发布的面向古文智能处理的预训练模型,其学习能力和泛化能力已在自动标注、实体识别等层次的古籍文献信息处理任务中得到验证。
(2)语料处理。基于预训练模型的自动摘要实验需要对语料进行划分,对于划分颗粒度,如果选择单个句子太过于零散,前后内容缺乏连贯性,摘要结果会有明显的割裂感;如果选择段落,虽然语义层面更完整,但《资治通鉴》原文段落篇幅参差不齐,太长或太短的段落都不适合于自动摘要任务。因此,本实验采用“滑动句子”机制对语料进行划分,每个单句都有作为中心句的机会,向前向后以句子为单位进行滑动,超出阈值范围或者到达段落末尾则结束。以《资治通鉴》“陈纪八”卷的部分原文为例:“又十三环金带遗坚。十三环金带者,天子之服也。坚大悦,遣浑诣韦孝宽述穆意。穆兄子崇,为怀州刺史,初欲应迥。后知穆附坚,慨然太息曰:‘阖家富贵者数十人,值国有难,竟不能扶倾继绝,复何面目处天地间乎!’”表4是针对该部分原文生成的句子向量结果。

表4 滑动句子机制示例
预训练模型在计算摘要句权重的时候会利用到词语的频率信息,统计词频信息需要过滤掉停用词。本研究选取的基础停用词表是包含1,753个词汇的现代汉语停用词表,其中包括数字、符号、标点和无实际意义的词汇。考虑到本研究的文本为古汉语文本,在现代汉语停用词表基础上,根据“齐夫定律”,对《资治通鉴》进行词频统计。将频次出现在100次以上的词汇认定为高频词。高频词并非都是停用词,停用词多为形容词、副词、助词、虚词、代词等,如“之”“乎”“者”“也”“而”“无”等没有实际意义的词汇。经过逐一校对筛选,最终确定将107个词频虽高但不具有实际意义的词语列入停用词表。之后利用算法,在模型读取时自动去除文档中的停用词,以降低对最终结果的影响。过滤掉停用词之后的《资治通鉴》词频统计数据样例见表5。
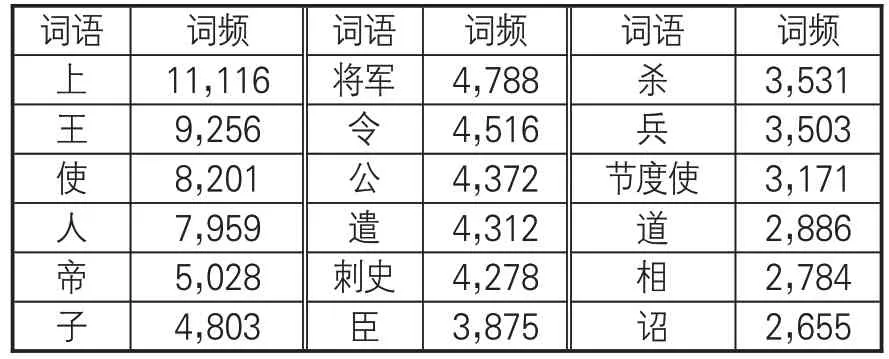
表5 《资治通鉴》词频统计数据样例
(3)实验过程。第一步,获取词向量。将词语转为向量,本研究采取的方法是基于古文领域的 SikuBERT 模型的Tokenizer,并采用transformers 包来直接实现词、句向量的转化。SikuBERT模型融入更多的语法、词法和语义信息,且动态改变词嵌入也能让单词在不同语境下具有不同的词嵌入表示。该词向量获取方法有更强的表达能力,还可以保留原字词的特征,相比其他方法能更好地考虑上下文信息、处理一词多义等问题。
第二步,生成句、篇向量。完成对词语的分词及向量化表示后,依据原始句子将其拼接为句子向量,依次读取后得到一个由句子向量组成的句子列表向量。因后续需进行相似度比较,不同维度的向量无法进行直接计算,因而需对得到的篇章向量进行降维处理。具体来说,将得到的所有句子向量进行求和,得到合并后的篇章向量,同时求出句子数量,将二者进行相除得到最终的篇章平均中心向量,从而可保证获得的平均中心向量和每个句子的向量维度一致。
第三步,计算相似度。在上述步骤中完成了对文档的句向量及中心向量计算后,通过余弦相似度算法,依次计算每一个句向量与文档中心向量的相似度,并将句子按相似度高低进行排序。余弦相似度计算公式如下所示:
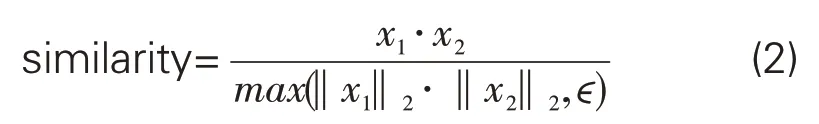
为获得更好的摘要效果,对句子向量的相似度数值进行修正处理,以最大限度降低句子向量规模对相似度的影响。截取句子向量相似度排名前20的句子,设排名前20句子的平均相似度为a,去除标点后的平均句长为b,则修正相似度阈值为a/b。计算每个句子向量的修正相似度数值,高于阈值则作为摘要结果输出。
第四步,输出摘要结果。以《资治通鉴》“宋纪六”卷为例,抽取后的最终摘要结果见图5。

图5 《资治通鉴》“宋纪六”卷自动摘要结果
表6展示基于SikuBERT模型生成《资治通鉴》自动摘要结果的相似度筛选数据,表格列出“宋纪一”至“宋纪十”共10卷文本的数据示例,包括“句子向量平均相似度”“修正相似度筛选阈值”等统计量的值,能直观看出对句子向量进行相似度筛选生成摘要关键句的过程。
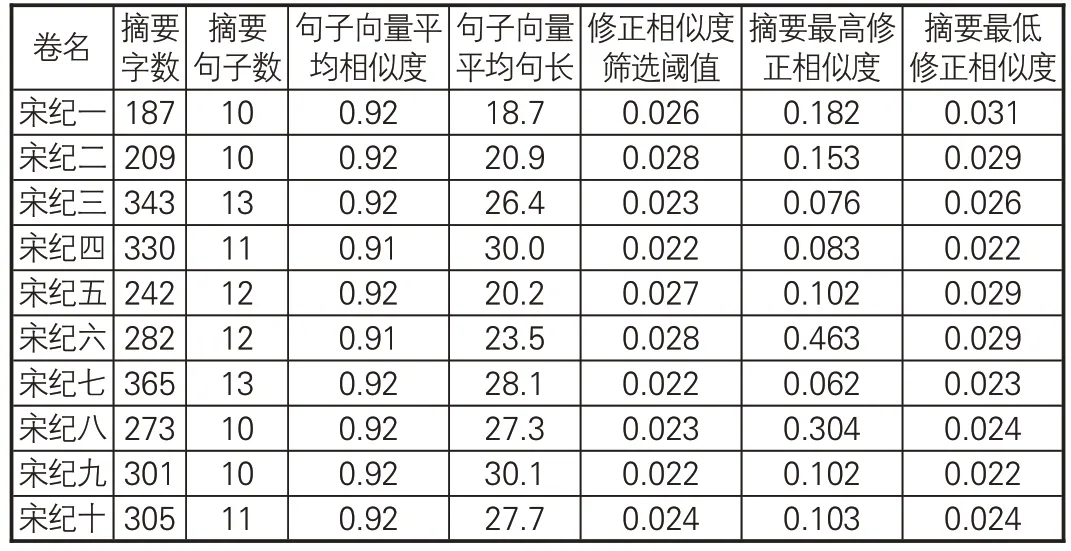
表6 《资治通鉴》自动摘要的相似度筛选数据
4.4 实验数据及分析
本研究分别使用抽取式自动摘要算法和SikuBERT预训练模型对《资治通鉴》全文语料进行自动摘要实验。由于古籍文献自身语言风格的特殊性,为更好地进行摘要效果比对,将《资治通鉴》全文语料输入百度智能云的摘要分析接口,百度智能云的新闻摘要功能可基于深度语义分析模型自动抽取文本中的关键信息并生成指定长度的摘要。由此在《资治通鉴》语料上本实验共生成3 种方法得出的自动摘要结果,示例见表7。

表7 《资治通鉴》自动摘要生成结果样例
本研究共对《资治通鉴》全文294卷文本进行自动摘要实验,按卷生成摘要结果。基于抽取式算法的自动摘要实验共生成256篇有效摘要,抽取摘要失败38篇。基于百度智能云的自动摘要实验共生成280 篇有效摘要,抽取摘要失败14篇。基于SikuBERT预训练模型的自动摘要实验共生成294篇摘要,无抽取摘要失败文本。详细实验结果见表8。

表8 《资治通鉴》自动摘要结果详细数据
由于尚无针对《资治通鉴》全文语料标准摘要资源,因此本实验参考彭敏等[16]采用的1-5级自动摘要人工评测标准及方法对《资治通鉴》的实验结果进行评价。人工评测对象为《资治通鉴》294卷文本的摘要结果,评测者为20位古典文献专业硕博士研究生,评测指标为摘要内容的信息量、流畅度和冗余度,人工评测结果见表9。

表9 《资治通鉴》自动摘要结果人工评测得分
信息量是衡量摘要质量的最重要指标,在计算综合得分时权重也最高。从表9 看到,基于SikuBERT预训练模型的自动摘要结果的信息量得分为4.35,明显高于其他两种方法,综合得分为4.16,也远好于其他两种方法。从内容看,基于抽取式算法生成的自动摘要结果更流畅自然,可读性较高,但也存在摘要篇幅过短、无法完整概括原文信息的问题。例如,第六卷“秦纪一”的抽取式摘要结果中,摘要第一句内容“太子闻卫人荆轲之贤,卑辞厚礼而请见之”。位于原文篇幅过半位置的第55段第1行处,对于此处之前占原文大部分篇幅比例的内容都没有在摘要结果中有所体现,并且抽取式算法对自动摘要的聚类效果有严格要求,因此只生成了256 篇有效摘要,无效摘要比例达到13%。基于百度智能云生成的自动摘要结果也存在篇幅较短的情况,并且由于百度智能云的摘要分析功能主要针对现代汉语的新闻语料,因此由古籍文献语料得到的摘要在内容层面上的表现也并不理想。基于SikuBERT预训练模型生成的自动摘要全部为有效摘要结果,并且每卷摘要的字数都在两三百字,篇幅控制较好,没有出现其他两种实验方法生成摘要的篇幅起伏变化过大的情况。基于SikuBERT预训练模型生成的自动摘要在内容方面虽然有一些生硬和不连贯,但对于《资治通鉴》原文内容的概括更全面更到位,也更契合自动摘要实验最基本、最核心的任务需求。
综上所述,无论是人工打分的结果,还是内容层面的分析,针对《资治通鉴》的3种自动摘要方法中表现最佳的都是基于SikuBERT预训练模型的自动摘要方法。这也进一步验证了使用深度学习模型对古籍文献进行自动摘要任务的可行性和利用SikuBERT 预训练模型对古籍文献进行信息处理的适用性。
5 结语
自动摘要的目的是将长文本提炼为简洁精炼的短文本以降低阅读成本、提高知识利用率。古籍文献的篇幅长而句子短、文字理解门槛高,对古籍文献进行自动摘要任务是古籍数字人文领域研究不断深化的必然需求。本研究选取《资治通鉴》全文语料,使用传统抽取式自动摘要算法、百度智能云摘要分析算法和基于SikuBERT预训练模型的方法对其进行自动摘要的对比实验。实验结果表明:基于SikuBERT预训练模型生成的自动摘要结果在准确性、稳定性、覆盖度等方面均优于其他两种方法。本研究还通过专家人工打分的方式对3种自动摘要方法生成的结果进行评价,基于SikuBERT预训练模型生成的摘要结果平均得分最高。实验验证了数字人文技术在古文自动摘要任务中可行性和利用SikuBERT预训练模型对古文进行信息处理的适用性。
古籍文献由于独特的语言风格特点,使得进行自动摘要任务会遇到比现代汉语更多的困难。目前学术界针对古籍文献的自动摘要研究很少,相关古籍文献摘要资源更是匮乏。本文对《资治通鉴》进行的自动摘要研究是一次全新的探索,后续研究将在建设古籍文献摘要语料资源的基础之上提高算法和模型效果,为古籍数字人文领域的自动摘要研究铺路。
