基于深度学习的电能能耗预测研究
2022-11-16雷俊吴婷
雷 俊 吴 婷
电能能耗预测是电力需求预测的重要组成部分,是智能电网建设的重点关注领域。智能电网效率高、调度灵活、供应稳定[1],是落实国家节能减排政策的行动体现。而能耗预测更是重中之重,能耗预测的准确于公司有利于电力公司合理地安排经营计划,降低成本、提高效益;于社会有利于社会电能得到更加合理的调度,进一步稳定社会的电能供应,从而协调社会的供电需求和供电的关系。传统的短期电能能耗预测方法包括人工神经网络[2~3]、极限学习机[4]和支持向量回归[5]等,这些方法大多以机器学习和人工智能算法为核心,在处理非线性问题方面展现出较大优势,但仍有很多问题,比如很难处理时序相关性、不同数据集预测的稳定性较差、无法适应大规模数据处理等。随着机器学习的进一步发展,深度学习的方法也慢慢被引入能耗预测领域。对比之前的机器学习和人工神经网络,深度学习的方法虽然在精度上有所提升,但仍存在一些不足,比如仍然需要人提取时序特征,忽略了电能能耗数据的超长序列时序性,人工提取特征也可能导致部分数据的连续性被破坏的后果。
一、电能能耗预测模型
(一)RNN神经网络。循环神经网络(RNN)通过使用带自反馈的神经元很适合用来处理时序数据,因为它的每一个单元在处理数据的时候,既能获取当下数据的特征,又能获取前置数据的特征,具有内部记忆性。循环神经网络有很好的可扩展性,由于它是无数小单元的for循环,所以它可以向外扩展到更长的序列数据,而且大多数的RNN可以处理序列长度不同的数据。它可以看作是自循环的一个网络结构。
(二)LSTM神经网络。LSTM网络对比RNN引入一个新的内部状态专门来进行线性的循环信息传递,同时引入门机制来控制信息传递的路径。这些门使LSTM在进行反向传播时能够保持一个更稳定的误差,使神经网络可以在多个时间步上继续学习。
LSTM时刻t的计算过程为:(1)首先利用上一时刻的外部状态和当前时刻的输入xt,计算出三个门,以及候选状态

(三)attention机制。attention机制和人脑有点类似,比如人在看一个句子的时候,一定会有侧重点,即会格外注意句子里的某一些单词或字,人对这个词或字的attention就会“更高”,类比到网络里,也就是网络对于这个词或字的权重更高,权重参数是它最核心的操作。attention机制会使模型学习到从序列中各个元素的重要性权重,然后将元素根据重要性权重合并起来。attention机制可以表示为在输出的部分里,把query、key和对应的value以权重的方式反映出来。
将attention机制引入电能能耗预测模型中,可以选择性地关注不同时间步的输入对预测结果的影响,从而提升能耗预测的效果。在t时刻,得到LSTM层的隐层状态为[ht,1,ht,2,…,ht,i,…,ht,T]T;计算αt,i,即在t时刻,隐层状态hi对当前输出的注意力权重。
(四)Informer模型。
1.模型提出背景。Informer是一个基于transformer的长序列预测(Long Sequence Time-series Forecasting,LSTF)模型。Informer模型主要解决了transformer的三个主要问题:一是Self-attention机制会导致模型的时间复杂度为O(L2),L在这里表示序列长度;二是长序列的encoding输入会占用大量内存,而编码-解码层的堆栈会导致总内存使用量为O(J*L2),所以transformer的内存使用率较高,从而对长序列输入时的伸缩性有一定的限制;三是encoder-decoder结构在解码时step-by-step,动态的decoding会导致step-by-step的预测非常慢,在预测长序列时输出的速度很慢。
2.模型结构。关于Informer模型的结构,先将长序列输入进左侧encoder部分。传统的transformer的结构是自注意力机制,informer提出了ProbSparse self-attention的改进方案来提取主要影响最后结果的注意力部分,从而达到减轻模型规格的效果。而相同层的复制堆叠叠加则增加了模型的鲁棒性。右测的decoder同样是输入,也接受长序列,但是它会将待预测的目标部分填充为零,根据模型的注意力权重,一步输出预测部分,也就是直接生成预测的输出序列。
3.模型创新点。Informer模型的创新点贡献主要有三点。
(1)提出了ProbSparse self-attention机制,时间复杂度为O(L*log L)。
(2)提出了self-attention蒸馏机制来缩短每一层的输入序列长度,序列长度的减小直接导致计算量和储存量的减小,进一步提高了计算速度和性能。
(3)提出了生成式的decoder机制,在预测序列(也包括inference阶段)的时候一步直接得到结果,而不是之前的step-by-step,从而将预测的时间复杂度从O(N)降低至O(1)。
①ProbSparse self-attention。现有很多研究是针对Self-attention的O(L2)二次复杂度问题的研究,但是他们缺少理论分析,而且对于multi-head self-attention中的每个head都采取相同的优化策略。而self-attention中的点积实际上是服从长尾分布的,也就是少数的几个query和key的点积计算结果主导了softmax后的分布。这种稀疏性分布是有现实含义的:因为序列中的某个元素一般只会和少数几个元素具有较高的相似性和关联性。ProbSparse self-attention的核心思想就是找到这些重要的或者稀疏的query,从而只计算这些query的attention值,来优化计算效率。算法流程如表1所示。
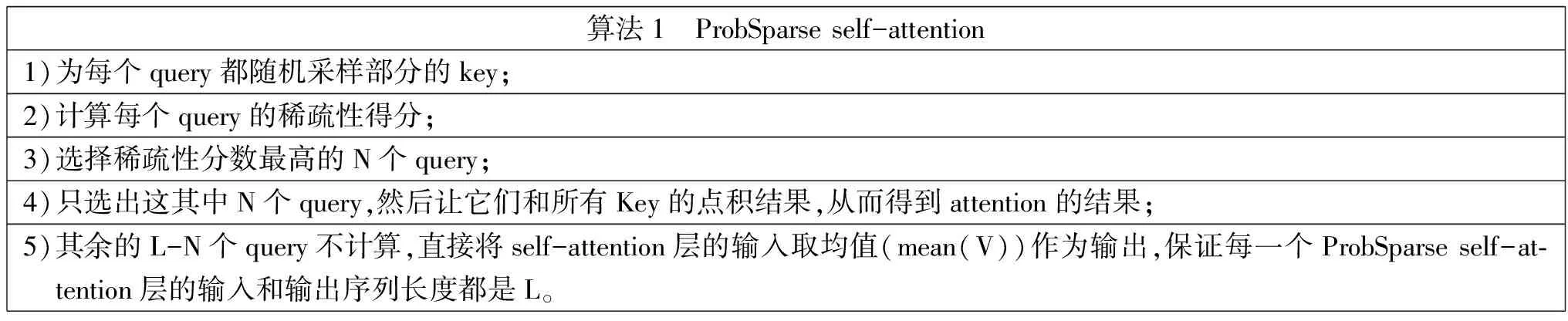
表1
②编码层Self-attention Distilling。随着Encoder层数的加深,由于序列中每个位置的输出已经包含了序列中其他元素的信息,所以输入的序列的长度一定会变短。由于之前的encoder部分采用了ProbSparse Self-attention,这种方法会带来一些特征,表现出来就是V值的冗余组合,利用蒸馏技术对具有决定序列的某些特征进行特权化处理,并在后一层生成更专注的自注意力特征映射。它大大减少了输入的时间维度。
而且编码部分通过每次都删除一层来逐步减少self-attention提取层的数量,从而使它们的输出维度对齐。最后将所有的重复堆叠部分输出结合起来,从而得到编码部分的最终隐藏表示。所以这种矩形的编码器结构其实更像没有顶端的金字塔形。
③Inference里的decoder。Decoder的输入序列包括两部分,一部分是将带预测时间点前的一段已知序列作为Decoder的输入,另一部分是占位符序列,而且它包含了预测序列。将遮盖多注意力头的方法应用于提取主要注意力的部分,然后把负无穷大设置为mask的点积。这样可以限制前置位置上对于后置位置的关注,从而有效避免自回归。其次,除了将时间序列和位置向量作为输入,还加入了每个时间点的时间信息。经过Decoder后,每个placeholder(待预测位置)都有一个向量,然后输入到全连接层FC得到预测结果。
二、实验过程
(一)实验环境。本文实验研究的环境包括Geforce RTX 3090,操作系统:ubuntu20.04,编译平台:Python3.6,框架:TensorFlow2.1,Keras2.3.1,Pytorch1.8.1.
(二)数据集。本文采用Duquesne Light Company电能能耗数据集作为实验数据。DUQ数据集包括了2005年12月31日至2018年01月02日该电力公司真实消耗的电能。能耗数据格式为一天采集24个点,时间间隔为1h。本文将实验任务设置为根据前seq_len天的日总负荷量(seq_len为encoder输入长度),预测第pred_len天的日总负荷量(pred_len为encoder输入长度),一次生成所有预测数据。训练集、验证集、测试集的数据划分如表2所示。

表2 训练集、验证集数据
将数据集进行归一化处理后的整体分布情况如图1所示。从数据分布可以看出,电能消耗负荷数据在以年为单位时呈现周期性,但在以天为单位时表现出剧烈的波动。

图1 电能能耗数据分布(归一化后)

三、实验结果
进行四组对比实验,分别为RNN、LSTM、LSTM+attention和informer(图2)。

图2 RNN、LSTM、LSTM+attention、informer预测结果图
从对比图中可以看出,四个模型在该数据集上的预测值和真实值的变化趋势总体上十分相似,预测序列曲线和真实序列曲线相似度较高,各个模型的预测效果都不错。
运用2.4提出的预测结果评价指标对四种模型进行定量评价,结果如表3所示。
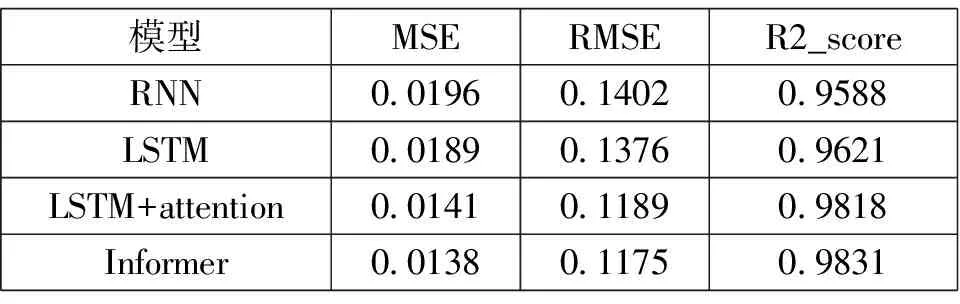
表3
综合来看,针对模拟和实际电能消耗预测,Informer模型预测的结果的R2值是最高的,MSE和RMSE均是最低,预测精确度较RNN和单LSTM有明显提升,能很好地预测电能能耗。同时可以发现LSTM+attention的效果和informer十分接近,但是都比RNN和LSTM有显著的提升。
四、结论
本文将informer模型运用于电能能耗预测,根据现有的能耗数据建立模型进行能耗预测。为验证该网络的优势,采用了RNN、LSTM和引入attention的LSTM模型进行对比实验。从表3可以看出informer模型在三个评价指标上都优于其他三个模型,效果最好。
但是informer对比LSTM+attention在该单变量预测单变量的序列预测任务的提升并不显著,一方面是由于单变量时间序列预测难度较低,四个模型本身的效果都不错,导致informer的效果提升没有非常明显;其次由于是单变量的序列预测任务,所以引入attention机制的LSTM也能很好地学习到序列的特征,效果相对于RNN和LSTM同样也有不错的提升,而informer理论上最适用于多特征的长序列预测,其优势在该预测任务下没有得到很好的体现。但是在现实中电能消耗并不仅仅和时间有关,温度、电费价格等特征都是导致用电量发生变化的原因,后续可以继续探究在多变量多特征情况下informer模型在电能能耗预测方面的效果。
总的来说,本文使用的informer模型在各项评价指标上对比RNN和LSTM都有明显增强,具有明显优势和更高的准确度,能更精确地完成电能能耗预测任务;LSTM+attention也有不错的效果,但是它的局限性在于无法很好地处理多特征预测问题,不能应用到现实中的多特征电能能耗预测中。Informer模型作为transformer的改良,适合进行长序列数据、多特征数据预测,而且也有很好效果和不错的计算性能,更加适合于电能能耗的预测。
